Diy-LLM 学习笔记-01
原文链接:https://datawhalechina.github.io/diy-llm/#/./chapter2/chapter2_%E5%88%86%E8%AF%8D%E5%99%A8
分词器
开始之前,分享最近的一点感悟。解决一个问题不难,难的是找出问题、找到核心矛盾点来,然后再使用各种方法解决问题。
提出问题,1.分词器是用来做什么的?在大语言模型(LLM)实现的过程中它起到什么作用?解决了什么问题? 2.然后,问题是怎么训练?
放一张文章中的原图。如图1。它解释了在用户使用LLM时候:输入是文本形式的语言;而LLM需要的是数字ID序列。那么,问题来了,两者不匹配,该怎么办?答案是分词器。
分词器的作用就是 将人类语言转换成机器能够读懂的数字ID序列,使用户能够丝滑的与LLM进行交互。
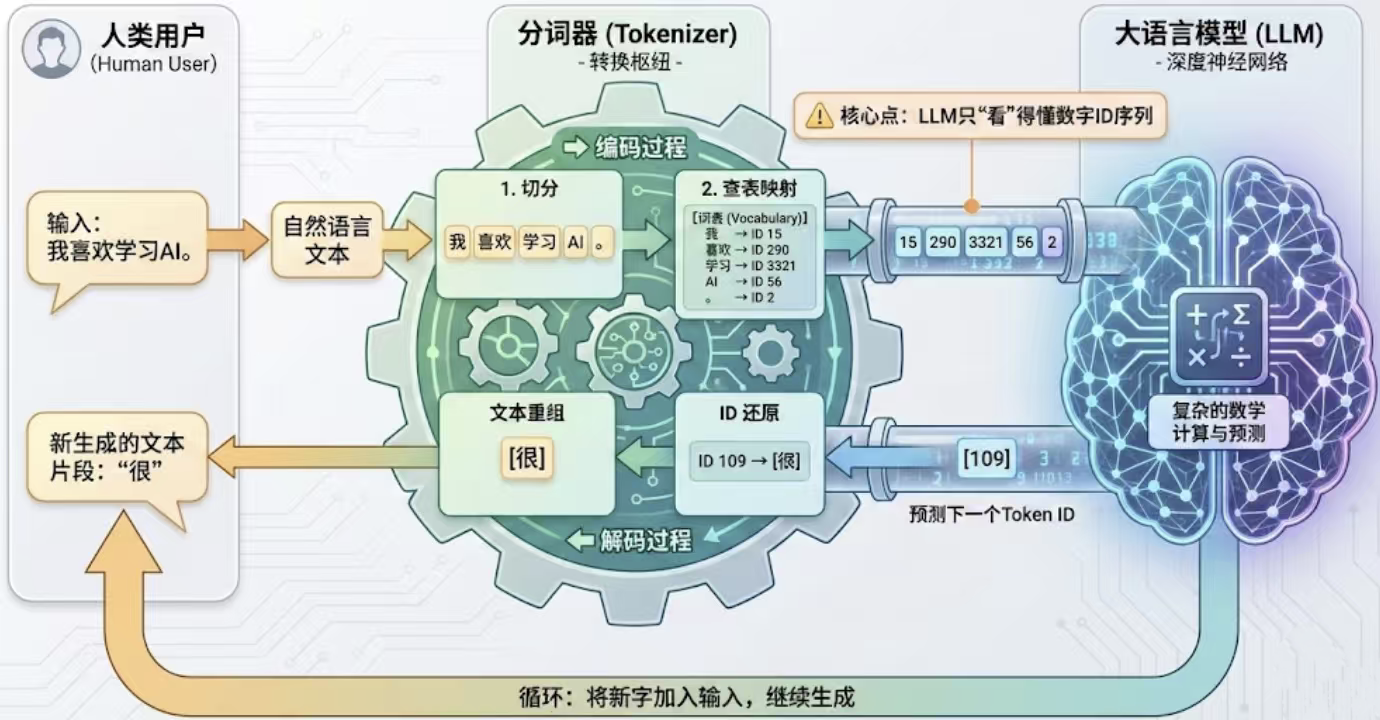
图1 分词器与LLM
好了,接下来目标就明确了,怎样做才能很好的将人类语言 翻译成机器能够读懂的数字呢?
训练分词器
在把数据喂给大模型之前,要对数据进行“分词”。利用正则表达式对原始数据进行预处理,构建一套 词元 -- 数字 离散序列转化 列表(vocab)。这将决定模型看到的世界是由字、词或是由其它片段组成的,将影响到后续模型对语义的理解效率。
文章写到,训练一个LLM分词器可以拆成四步: 准备语料 ——> 初始化基础单元(可省略)——> 统计并迭代合并 ——> 输出产物并用于编码、解码。
准备语料
此处讲到5点:包括1)收集覆盖目标应用场景的多样化文本;2)对原始文本进行清洗和标准化处理;3)对带有敏感信息或隐私的语料,要提前进行脱敏处理与检查;4)在多语言或混合语料场景中,统计各语言占比,并评估对低资源语言的过采样或定向保留,避免被高频语言主导;5)保留小部分未参与训练的验证语料。
初始化基础单元
1)预分词的主要任务是将原始文本切分成可统计、可合并的基础单元,如,字符,字节或Unicode片段。
此处还提到token划分时的常见策略:
xxx
2)对以空格作为词边界的语言,使用正则表达式按单词边界和标点进行初步分割;对不以空格作为单词边界的语言,采用逐字符或基于字的初始单元进行覆盖。
3)预分词生成的基础单元作为后续的输入,要保存序列和对应的位置信息。
统计并迭代更新
1)子词候选统计。文章在此处重点介绍了4种遍历语料,收集统计信息的方法,包括:BPE、WordPiece、Unigram和SentencePiece。分别适用于不同的场景和模型。
2)算法迭代。
3)算法终止条件。 当训练无法明显提升分词压缩效率或语言建模质量时,算法停止。
4)大规模语料优化。讲的是使用分布式统计与近似计算等方法,在保证结果稳定和可复现的前提下,高效处理大规模语料。
5)监控预评估指标。 有token粒度、压缩率和OOV等指标,评估分词器能否实现“表达能力”和“效率”之间的平衡。
输出产物并用于编码和解码
导出核心文件。merges.txt和vocab.json文件。
常用的分词器
1) 字符分词器
将文本拆解为最小的字符单位。
优点:词表很小,只包含基础的字符和符号;没有OOV问题,也就是不会出现“未知词”。
缺点:序列过长,将一段话变成字符后,长度会增加,在后续计算中会消耗资源;语义稀疏,单个字符不具备语义。
2)字节分词器
计算机底层存储文本是字节,直接操作二进制字节。
3)词级分词器
早期深度学习的主流做法。基于空格或分词算法将文本切分为具备独立语义的“词”。
优点:Token保留了完整的语义信息
缺点:词表爆炸;OOV问题严重,遇到没见过的次标记<UNK>,信息丢失。
4)BPE分词器
LLM最主流的分词算法,试图在字符集和词级之间寻找平衡。实现思想:统计语料中相邻字符对出现的频率,迭代地将最频繁出现的字符对合并成一个新的Token。
实现过程:
初始化:将单词拆成字符序列;
统计:计算所有相邻字符对的频率;
合并:将频率最高的相邻字符对 合并成新的Token;
循环:重复上述步骤,直到预设的此表大小停止。
4种分词器对比:
| 分词器类型 | 粒度 | 词表大小 | 词表外(OOV) | 序列长度 | 代表模型 |
| 字符级 | 细 | 小 (100–5k) | 无 | 非常长 | Char-RNN |
| 字节级 | 更细(字节)| 很小 (~256–1k) | 无 | 很长 | GPT-2 |
| 词级 | 粗 | 极大 (>100k) | 严重 | 短 | Word2Vec, GloVe |
| BPE | 中(自适应) | 适中 (30k–100k) | 极少 | 适中 | GPT-4, Llama 3 |
文章大部分内容来自原文,原文写的更加丰富具体,建议看原文进行更深入地学习与理解。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 5
5 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)