1.大模型基本概念学习
#以下内容有不对的或者理解不太正确的感谢斧正🙏
1 大模型基本概念学习
LLM
LLM:Large Language Model 大语言模型,简称 大模型 。
token
token:大模型处理文本的基本单位。token和词并非一一对应。
1个token约等于0.75个英文单词,1.5~2个汉字。
100wToken约等于75w个英文单词,150w-200w个汉字
大模型里跑到都是矩阵函数,接收和输出的都是数字。再基于transformer转换器训练出来。
大模型运行示例:这里用户输入汉字[马克的视频怎么样],通过tokenizer分词器进行编码,先切分成一个个token [马克,的,视频,怎么样] 再映射成token ID -数字 [35,36,34,9];
模型经过运算后,吐出个token ID [36],再通过tokenizer分词器进行解码,映射为文字[的],再输出预测结果 [特别],,,根据[特别]预测出[的],后面依次推算出[特别,的,棒],就相当于个文字接龙游戏
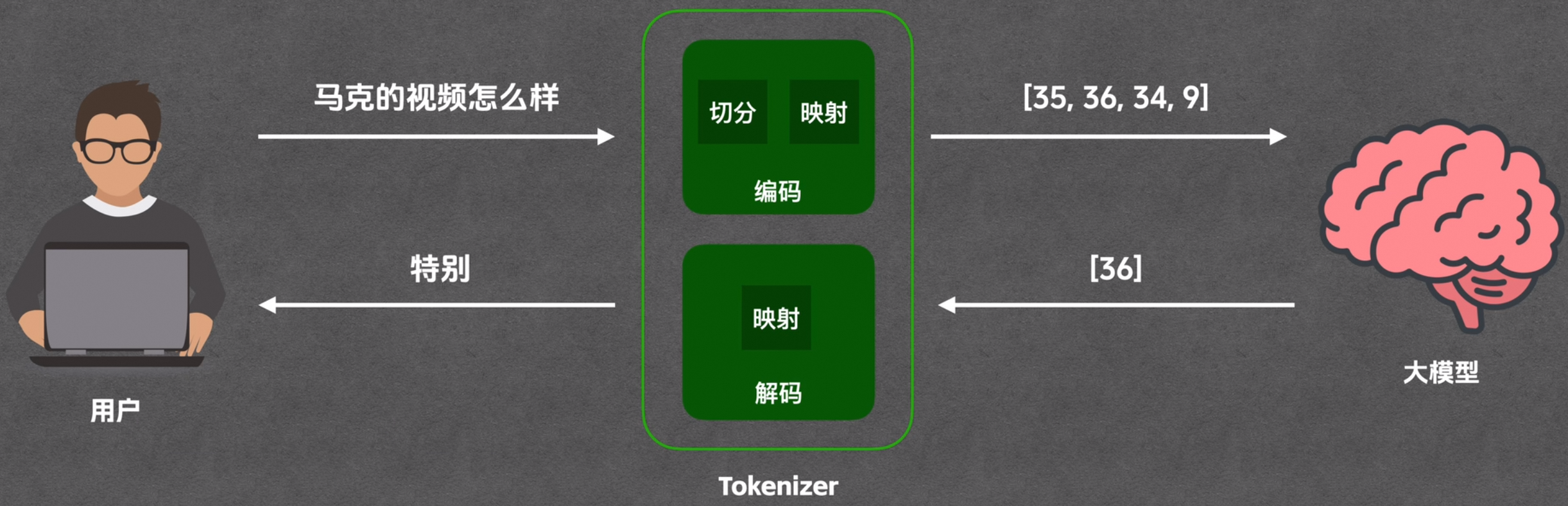
context 上下文
context:大模型每次处理任务时所接收到的信息总和。
context包含对话历史记录、用户问题、当前输出、工具列表、System Prompt等
context Window:上下文窗口。表示context能容纳的最大Token数量。
RAG
RAG(Retrieval-Augmented Generation检索增强生成):先从知识库中检索出相关内容片段,再基于这些内容进行回答,就无需扫描整个知识库,节省大量Token。
主要应用场景:解决知识库/产品手册太长所带来的问题
1.模型无法读取所有内容,当超过上下文窗口会读了后面忘了前面,模型准确性也会大打折扣
2. 模型推理成功高
3. 模型推理慢
那rag是如何解决的呢?rag会先把文档分成多个片段来回复问题,基本流程如下:
准备(提问前):分片->索引
回答(提问后):召回->重排->生成
分片:可按字数、章节、段落、页码分等
索引:
1)通过Embedding模型将片段文本转换为向量,
2)将片段文本和对应的片段向量存入向量数据库中(用于存储和查询向量的数据库)

召回(初步筛选):从向量数据库中取出向量相似度相近的向量。
重排(精准筛选):在召回的片段通过corss-encoder模型精选片段,两者区别如下:

生成:把用户问题和重排片段发给大模型,生成结果返给用户
向量:又分一维向量(x坐标轴)、二位向量(xy坐标轴)、三维向量(xyz坐标轴)
向量相似度:计算方式又分 余弦相似度(向量夹角的cos值)、欧式距离(坐标轴的直线距离)、点积
Prompt 提示词
prompt:大模型接收的具体问题/指令。大模型怎么写体现出你的结果质量,prompt应该是具体的、清晰的、明确的。
Prompt分类:
User Prompt: 用户提示词。用户自己输入的具体任务。
System Prompt: 系统提示词。开发者在后台配置的,说明人设和做事规则的。
Tool (相当于个函数)
Tool:大模型用来感知和影响外部环境的函数。
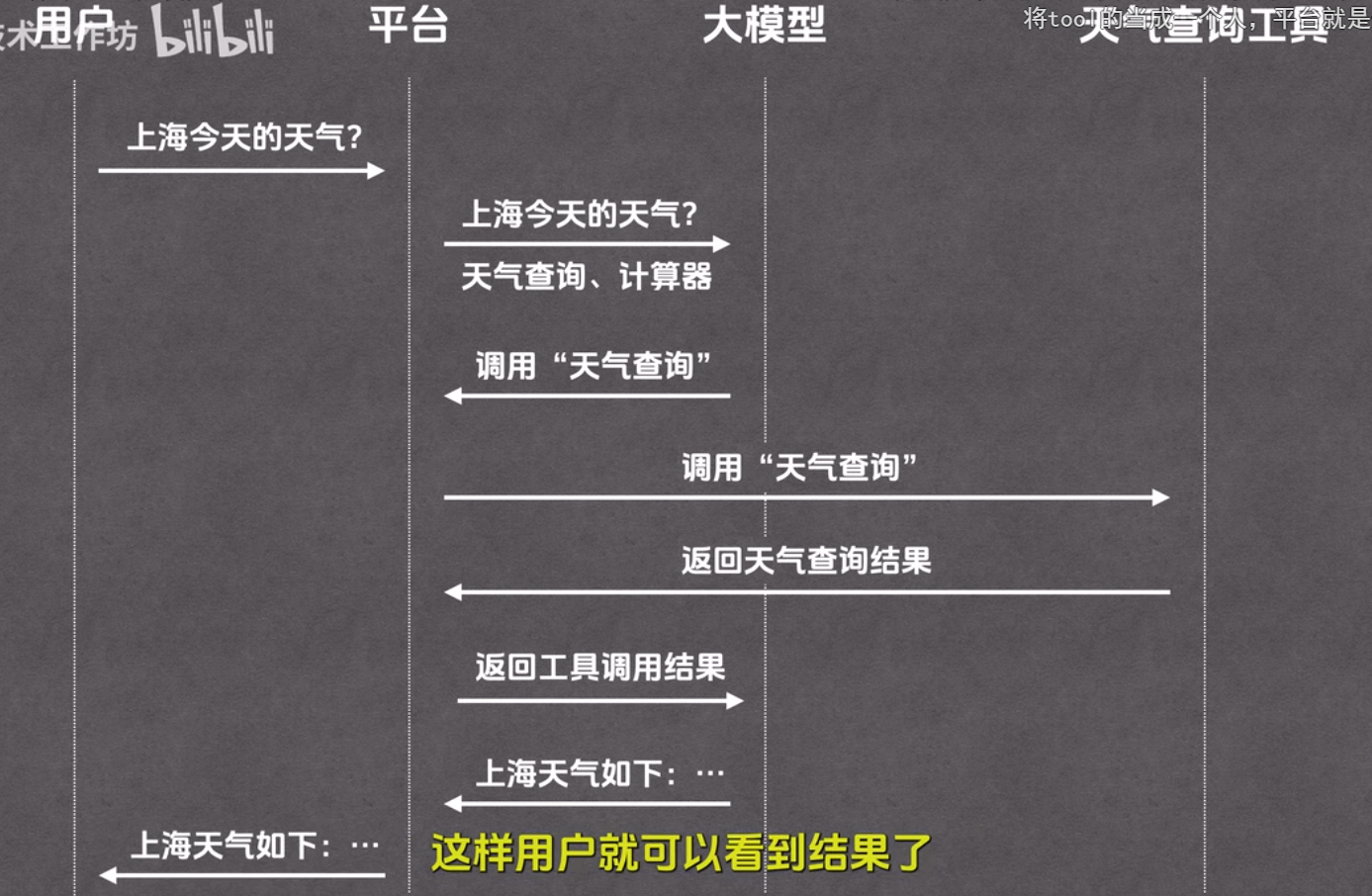
例[天气查询工具] :涉及用户、大模型、天气查询工具、平台(例如Qwen,chatgpt)。
大模型:选择工具、归纳总结
工具:查询天气
平台:串联流程
MCP
MCP(Model Context Protocol)模型上下文协议:统一的工具接入标准协议(接入平台)。就无需为每个平台调整了。
Agent、AgentSkill
Agent:能自自主规划和调用工具、直至解决用户问题的程序。
例如:我们想知道今天天气怎么样,附近是否有卖雨伞的呢?
那么我们需要调用的工具就有多个了,包含定位,天气,店铺。流程如下:
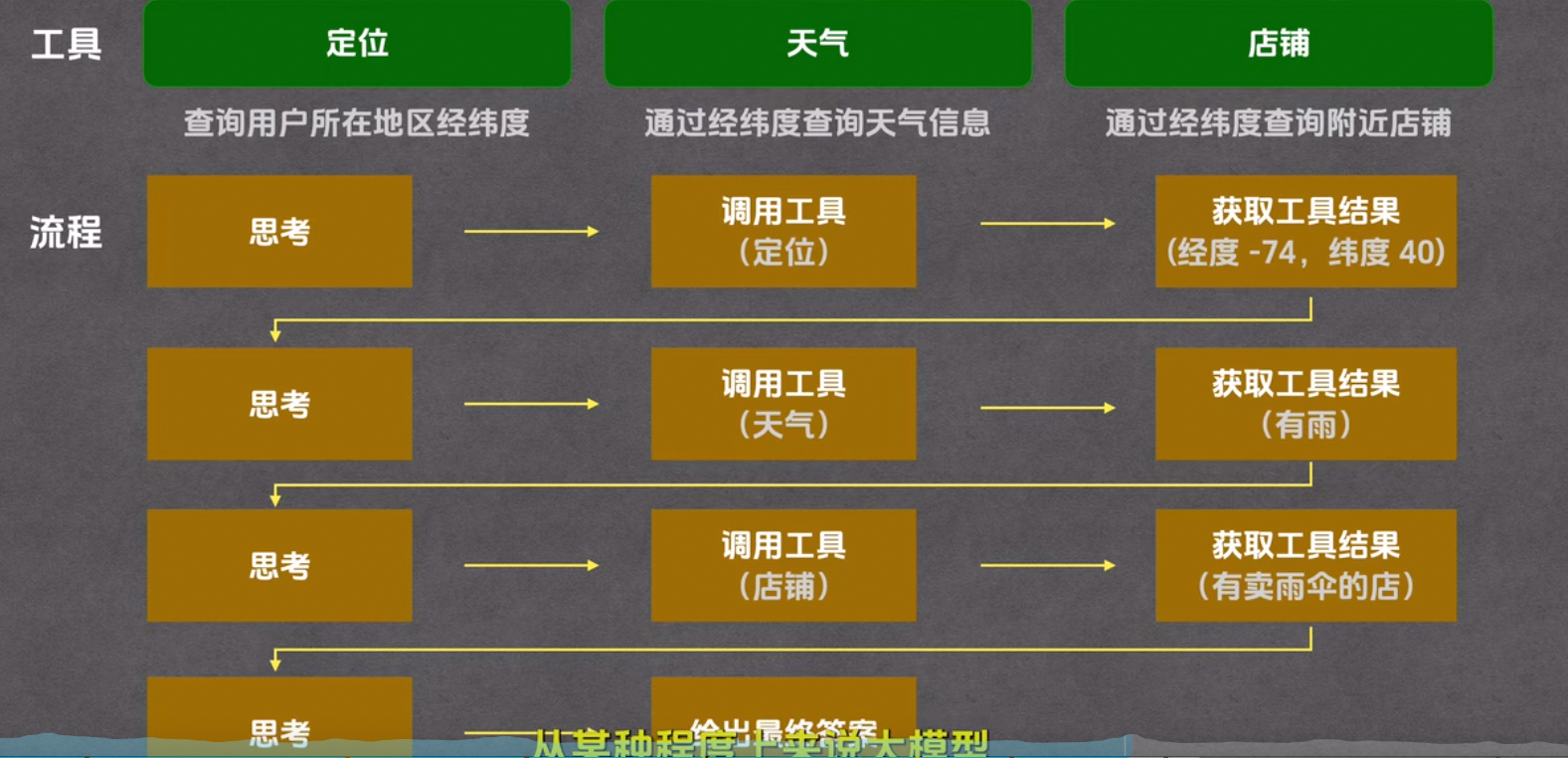
Agent产品:Claude Code、Codex、Gemini CLI
Agent Skill:Agent看的 ‘说明文档/知识库,根据说明文档内容解答 (相当于打包好的系统提示词)。
内容基于B站视频 [【从 LLM 到 Agent Skill,一期视频带你打通底层逻辑!】 https://www.bilibili.com/video/BV1E7wtzaEdq/?share_source=copy_web&vd_source=200aa8216be176c5be22fa3f36c2e0bf] 整理
趣味问答
1.token这么贵,其成本是哪来的
Token的成本并非凭空产生,而是由以下几个核心要素构成,可以形象地理解为生产“智能”所需的原材料:
1. 芯片(算力基石)
这是当前成本中最主要的部分,占比可达60%-70%。大模型的每一次思考和回答,都需要成千上万块高端GPU(如NVIDIA A100/H100)协同工作。这些芯片价格昂贵且供不应求,是决定Token供给量和价格的短期“硬锚点”。
2. 电力(能源消耗)
运行庞大的GPU集群会产生惊人的能耗。一个数据中心的耗电量堪比一座小型城市。随着芯片性能的提升,能源成本正成为一个越来越重要的硬性约束,是Token成本的物理底线。
3. 人才与研发(智慧结晶)
训练出一个强大的模型,需要顶尖的科学家和工程师团队进行长期的研究和开发。这部分一次性投入的巨大成本(训练成本),会分摊到后续每一次的模型调用中。这也是为什么更聪明、能力更强的模型(如GPT-5对比GPT-3.5)价格会高出数十倍的原因——你不仅是在为算力付费,更是在为模型的“智商”和“能力”付费。
4. 数据(知识来源)
用于训练模型的庞大、高质量数据集的获取、清洗和处理也需要巨大的投入。这些数据是模型知识的来源,其质量和规模直接影响模型的能力。
📉 定价逻辑:从“租用时间”到“购买智能”
传统的云计算是按小时租赁服务器,无论你用不用,只要在用就在计费。而Token经济是一种范式转变:
传统模式:按硬件使用时间付费,衡量的是“物质资源的占用”。
Token模式:按实际产生的智能输出付费,衡量的是“智能服务的能力交换”。
这是一种更接近“按效果付费”的模式。你不再为闲置的算力买单,而是为你真正获得的“思考成果”付费。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)