目前时间序列预测的方向,基本走不通!
目前,许多时间序列预测(TSF)领域的研究者依然将 ETT、交通、电力或天气等公开数据集视为该领域的“ImageNet”。他们热衷于在这个标准测试集上反复打磨,试图继 Informer 之后,通过不断推出 PatchTST、iTransformer、DLinear 或 ModernTCN 等模型,来寻找到一个“无所不能的终极通用骨干网络(Backbone)”。
虽然之前也有学者察觉到了这种趋势的弊端(例如模型对参数极度敏感、实际效果常常被传统统计学方法吊打等),但主流给出的解法依然停留在“清洗数据”、“增加数据集规模”或“优化评估指标”等修修补补的层面上。
然而,最近的一篇立场论文(Position Paper)提出了一个极为尖锐且颠覆性的观点:寻找时序预测通用网络架构的这条路,从根本上就是死胡同。

该论文指出,这并非因为学术界暂时的算力不够或者调参不佳,而是因为“通用时序预测(General Domain TSF)”这个概念本身就包含着无法调和的固有矛盾。
另外我整理了TSF高价值研究方向清单资料包,感兴趣的dd,希望能帮到你!
基于底层冲突破析当前时序社区的显著现状
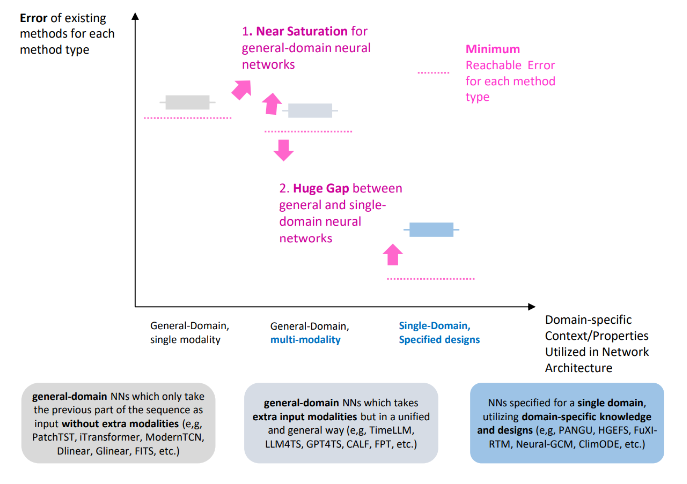
该论文进一步指出,若从上述“不可调和的通用性与专业性冲突”视角审视,近年来时间序列预测(TSF)领域出现的诸多反常规现象便有了符合逻辑的解释:
1. 深度学习架构未能对传统统计方法形成维度打击
在广泛的通用基准测试中,复杂的深度神经网络时常表现出不及 ARIMA 或 ETS 等经典统计模型的结果。其根本原因在于,为了使模型能够接纳特征差异巨大的多领域输入,提取的数据维度被极度简化。在如此受限且缺乏辅助特征的任务设定下,传统方法仅凭对趋势与周期的捕捉即可达到较佳效果,且凭借低参量特性规避了神经网络容易陷入的过拟合风险。
2. 评估基准趋于饱和且高度依赖超参数调节
近期通用骨干网络的研究似乎面临创新瓶颈,核心问题并非算法进入盲区,而是剥离了垂直领域知识的任务上限极低。在触及性能天花板后,很多所谓“超越前人”的榜单提升,实际上严重依赖于特定的数据预处理流程或是极限的超参数网格搜索。这种现象削弱了模型架构创新的科学价值,使性能比拼呈现出不稳定性和随机性。
3. 各垂直领域的应用层面对“通用网络SOTA”反应冷淡
通过对近三年气象观测、医疗健康以及交通规划等领域的顶级学术期刊进行样本考证可以发现,如果通用TSF模型真的具备类似NLP大模型的泛化能力,垂直行业的学者理应大量复用这些基座网络。但事实恰好相反,真实应用场景中的研究人员依然倾向于开发带有浓厚行业背景定制色彩的框架。这表明,时序学术社区探索通用骨干的努力,与各行业优化实际预测精度的需求存在严重的路线脱节。
4. 试图利用“海量异构数据”弥补模型缺陷的策略并不奏效
不同于自然语言处理(NLP)可通过无监督抓取海量互联网文本来扩充训练集,真实且高质量的时序数据面临显著的可用性瓶颈,且多数专业领域的数据量级分布极不均衡。单纯将不同领域的少量数据简单堆叠形成混合数据集,并不能从根本上解决单一架构在特征解析能力上的先天不足。
该结构性冲突不可调和的内在根源
原因一:跨域时间序列的基础生成机制异质性极强
各类时间序列所蕴含的物理规则与演化规律存在本质区别。例如,城市温度演变遵循流体动力学与热力学方程,而股票资产波动则深受市场微观交易机制、宏观经济事件乃至人类群体情绪的干扰。将这些底层逻辑互不兼容的数据集强制归位到同一评估基准中,并期望单套注意力机制或卷积模块加以完整拟合,必然导致特征映射层面的严重错位。
原因二:时间物理属性切断了“模型规模扩展法则(Scaling Law)”的有效路径
由于时序数据的采集具有不可跨越的时间延展性,研究者无法通过极度充沛的数据输入去强行抹平模型本身对先验知识的欠缺。理论层面指出,受限于既定的数据观测窗口 ,纵使进行高频采样,其底层过程逼近误差也存在理论下限 。既然无法像大语言模型那样单纯用数据量来突破瓶颈,引入人类的行业先验规律便成为了提高预测精度的必选项。而一旦引入这些特定约束,模型也就彻底丧失了跨领域通用性,从而形成逻辑悖论。
未来研究方向建议:分发取代统一,深耕取代泛化
确立该立场后,论文明确呼吁时序研究社区应停止针对通用数据集无意义的微小精度攀比,并提出了两条切实可行的后续发展路径:
方向一:专注于特定领域神经网络(Domain-Specific TSF)系统研发
建议研究者正视垂直场景的需求,将目标行业的因果驱动、多模态外生变量及特定的数学或物理边界条件深度融合到网络设计之中。其核心理念是舍弃虚无的全局泛化指标,转而在单一复杂的专业领域内打造真正经得起检验、可落地的最优模型(SOTA)。
方向二:基于元学习(Meta-Learning)构建自适应模型调度系统
如果研究焦点仍希望涵盖高通用性,其着力点应当从“构建一个万能底层架构”转变为“搭建智能化的自适应调度枢纽”。例如,利用大模型作为智能代理(LLM Agent),或是基于数据规律开发元选择(Meta-selection)机制,让系统在接收到陌生时序数据时自动分析其统计特征,进而在模型库中动态匹配最适宜处理该序列的“专家级架构”。这兼顾了系统的广度,同时保留了预测的深度。
总结: 该论文最终呼吁,通用时序预测(General Domain TSF)正越来越沦为一门“特征工程”和“刷榜学”。但这绝非研究者不够努力或不够聪明,而是目前的路线本身违背了时序数据的物理法则。社区必须正视域间差异的不可逾越性,要么去追求真正可用的单域突破(真 SOTA),要么把格局提升到系统层面的元学习(真通用),这才是时序研究走出泥潭的科学途径。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 4
4 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)