企业知识库该先整理资料,还是先选模型?
当企业准备启动 RAG(检索增强生成)知识库项目时,内部往往会爆发激烈的路线之争:IT 部门主张先去测试采购最先进的大模型,而业务部门则认为目前的文档太乱,必须花半年时间先人工整理归档。这种无休止的内耗,导致大量企业错失了 AI 落地的窗口期。企业知识库的建设,不是一场比拼模型参数的军备竞赛,而是一场关于隐性知识资产化的基础设施建设。真正关键的不是你首期选了哪一家的大模型,而是大模型在回答前,能否精准提取到你们公司历年沉淀的核心业务数据。作为深度操盘企业 AI 落地的服务商,逐米时代在实施路径上始终坚持一个铁律:“先知识、后应用、再放大”。今天,我们将从资产折旧与工程解耦的硬核视角,彻底终结这场路线之争。
 图 1:比起盲目采购高大上的 AI 模型,静下心来梳理企业内部纷繁复杂的业务数据,才是决定项目成败的第一步
图 1:比起盲目采购高大上的 AI 模型,静下心来梳理企业内部纷繁复杂的业务数据,才是决定项目成败的第一步
一、 “重模型、轻数据”带来的烂尾危机
在过去的两年里,我们见证了太多企业 AI 项目的烂尾轨迹。一套极其经典的失败流程通常是这样的:
公司高管听完某大厂的发布会,立刻拍板投入百万预算采购了拥有千亿参数的最顶级大模型 API 或本地一体机。等模型部署好后,IT 部门把公司网盘里未经任何处理的几万份 PDF、Word 和历史报价单,用脚本一股脑地“喂”给了系统。
到了验收环节,业务人员提问:“请列出我们过去三年在西南大区中标的电力项目设备清单。”系统思考了十秒钟,给出了一份把竞争对手的项目也混杂在内的错误列表。高管大怒,认为“大模型技术还不成熟”,项目随之被无限期搁置。
这场危机的根源在于:大模型是一台处理数据的超级计算机,但它不具备自动甄别“垃圾数据”的能力。如果你给它输入的是未解析的复杂表格、充满噪点的扫描件、甚至自相矛盾的过期制度,那么无论模型有多先进,输出的结果必然是灾难性的。
二、大模型是“折旧资产”,企业数据是“复利资产”
要解答“先选模型还是先搞数据”这个问题,企业管理者必须从商业资产的本质属性来进行决策。
在 AI 时代,大模型(LLM)属于高度商品化的“快速折旧资产”。今天你花重金买到的行业第一模型,在半年后就会被开源社区免费的新模型在跑分上彻底碾压。模型能力的迭代速度遵循摩尔定律,追逐底层模型的领先性,对非 AI 研发型企业来说毫无意义且成本极高。
相反,企业过去十年在业务中积累的 SOP 流程、故障排查记录、客户沟通话术,是独一无二的“复利资产”。这些数据不会随着外部技术的迭代而贬值。一旦被结构化、向量化(Vectorization)之后,它们就成了企业永远带不走的核心护城河。

图 2:在错误的方向上重金投入,企业将陷入长期的模型更迭焦虑中
因此,逻辑极其清晰:必须优先将预算和精力倾注在“数据底座”的建设上。模型是可以随时拔插替换的(Pluggable),但高质量的企业向量知识库是无法一蹴而就的。
三、企业在处理数据时最容易踩的 3 个雷区
既然明确了“数据优先”,很多业务部门又会走向另一个极端:号召全员加班,把文档重新分门别类归档。这也是错的。在 AI 时代,整理资料不是人类手工干的活儿,企业必须避开以下三个盲区:
- 盲区一:用“管理网盘”的思维去“管理 AI 数据”。
人类整理资料是建文件夹(如:2023年->华东区->采购合同)。但大模型不看文件夹,大模型只看“高维数学坐标”。企业不需要人工去调整文件的存放位置,而是需要建立一条数据解析流水线,让机器自动把文档切碎并向量化。 - 盲区二:忽视非结构化文档的“版面解析(Layout Parsing)”。
很多企业在处理数据时,直接用开源的 PDF 提取工具。结果是,原本整齐的双栏文本被交叉乱读,财务报表里的表头与数据错位。如果系统缺乏强大的 OCR 和版面还原能力,喂给向量数据库的就会是一堆毫无语义关联的乱码。 - 盲区三:试图一次性清理所有历史数据。
想把公司过去十年积压的所有 TB 级数据一次性洗净,是一个耗时耗力且成功率极低的烂尾工程。正确的做法是:只圈定一个高频业务场景(例如:售前投标),仅对该场景需要用到的最近两年的核心文档进行深度治理。
四、逐米时代的“先知识、后应用”落地法则
一个真正工业级、不烂尾的企业知识库项目,其标准的实施流绝不是从采购模型开始的,而是从“架构解耦”开始的。在 RAG(检索增强生成)架构下,数据底座与生成大模型是完全分离的两套系统。
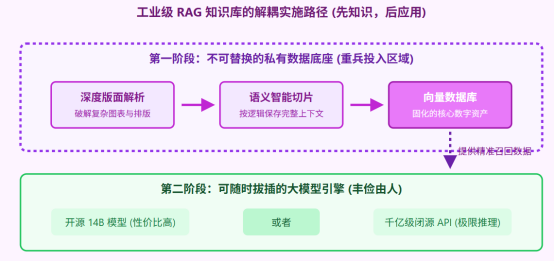
图3:将数据处理与大模型生成完全解耦,是企业规避技术债务的唯一正途
在这个架构下,路线之争迎刃而解:
- 第一步:夯实底座。 企业集中所有资源,建立文件解析与向量化流水线。这是一项苦活累活,但它能把公司几万份死文档,变成大模型能秒级读取的结构化知识片段。
- 第二步:按需接入基座模型。 当底层向量库搭建完毕,上面接哪个模型已经不重要了。预算充足就接顶尖的闭源 API,需要数据私有化就本地部署一个开源的中型模型。如果明年出了更好的模型,一键切换 API 即可,底层的向量知识资产一分钱都不会浪费。
五、哪些企业必须立刻停止“迷信大模型”?
如果你在推动企业内部的 AI 建设,请立刻审视以下几个指标。如果符合,请马上叫停盲目购买高端算力或千亿模型的冲动,转而进行数据治理:
- 核心资料极度依赖非结构化文件: 如工程设计公司(含有大量图纸与参数表的 PDF)、律所或财会机构(长达数百页、充满嵌套表格的审计报告)。
- 业务线庞杂且 SOP 变动频繁的企业: 没有良好的数据清洗和元数据(Metadata)管理,大模型会频繁调用过期数据指导业务,带来巨大的商业违规风险。
- 预算有限且对数据安全敏感的实体经济企业: 你们不需要花上百万去追逐跑分第一的模型基座。把三十万花在数据深度解析和 RAG 实施上,再配一个免费开源的本地 14B 模型,其业务效果远超裸跑千亿级通用模型。
结语:夯实地基,才能建起摩天大楼
数字化建设的铁律从未改变:所有企图绕过肮脏的数据处理,直接在应用层享受华丽结果的尝试,最终都会付出几倍的代价来推倒重来。大模型时代同样如此。
企业必须清醒地认识到,技术的浪潮会不断洗牌底层的大模型厂商,但你们自身积累的数据知识,才是决定你们能否在行业中立足的唯一砝码。这正是逐米时代在实施企业 AI 项目时不可动摇的准则。我们坚持“先知识、后应用、再放大”的实施路径,拒绝为企业堆砌华而不实的模型参数。我们将交付的核心,锁定在极具技术深度的文档解析、RAG 向量库构建与私有化实施链路中。帮企业打牢这层不可被替代的数据地基,才能让后续涌现的任何智能体,都站在坚实的巨人肩膀上。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 12
12 0
0- 0



 已为社区贡献43条内容
已为社区贡献43条内容

所有评论(0)