收藏!小白程序员必懂:Token(词元)是AI时代的“硬通货”!
前几天刷朋友圈,我发现一个特别有意思的现象:一半人还在晒养“龙虾”的截图,一半人在问“Token到底啥意思”,甚至有人把它念成“套肯”,闹了不少笑话。

直到23日中国发展高层论坛2026年年会上,国家数据局局长刘烈宏一锤定音,我才恍然大悟——原来我们天天挂在嘴边的Token,有了官方中文名:词元!更颠覆认知的是,它不只是AI圈的“黑话”,更是智能时代的“硬通货”,不懂它,以后用大模型、聊AI,大概率要被人笑话外行!
说真的,在官方定调之前,我对Token的理解也一直是模糊的。我一度以为它是区块链专属的“代币”,是游戏里的“点券”,甚至觉得和我们普通人没关系,直到我用ChatGPT写方案、用文心一言做总结,频繁被提示“Token不足”“上下文超出限制”,才发现自己错得离谱。
Token(词元)不是玄学,是你用AI的“入门钥匙”,更是智能时代的“结算单位”,你每用一次大模型,都在和它打交道。
先给大家挖个悬念:你有没有想过,为什么你输入“我爱人工智能”,大模型能秒懂你的意思?为什么同样是100字,中文和英文在AI里的“计价”不一样?为什么有的句子能生成几百字,有的刚输一半就提示超限?
答案只有一个——全看Token!它就像AI世界里的“小积木”,不管是输入的文字,还是输出的内容,都要先拆成这种“小积木”,AI才能看懂、才能工作,而这“小积木”,现在有了官方名字:词元。
先跟大家唠唠Token的出身,说出来你可能不信,它可不是AI圈的“新贵”,而是早就渗透在我们生活里的“老熟人”。
Token源自英语,本意是“令牌、标记、代券”,核心就是“代表某种价值、权限的最小单元”。比如你登录微信时的验证码,就是一种Token;你玩游戏买的点券,也是Token;甚至你去健身房的通行卡、超市的积分券,本质上都是Token。
以前我只知道这些用途,从没想过,它会摇身一变,成为AI时代的“核心主角”。

这里必须插一句,很多人把Token和区块链里的“代币”搞混,包括我之前也犯过这个错,今天一次性说清楚,避免大家再闹笑话!
区块链里的Token,确实是“数字资产”,可以交易、可以增值,有点像虚拟货币;但我们今天说的、官方定调的Token(词元),和交易、增值没关系,它只负责“翻译”——把我们说的话、写的字,翻译成AI能看懂的语言。

同样是Token,一个是“资产”,一个是“工具”,搞混了,不仅闹笑话,还可能踩坑!
最颠覆我认知的,还是国家数据局局长的那句定位:Token(词元)是智能时代的价值锚点,更是连接技术供给与商业需求的“结算单位”。这句话听起来有点抽象,我用大白话给大家翻译一下:以后不管是大模型计费、算力分配,还是商业模式落地,都要靠Token来量化。
比如你用大模型生成一篇文案,收费不是按字数算,而是按Token算;企业用大模型做服务,成本也是按Token来核算,它就像AI世界里的“人民币”,没有它,AI就无法“正常交易”。
可能有人会问:“既然Token这么重要,为什么以前不叫‘词元’,非要用个英文单词?”这里就有一个隐藏的冲突点:其实在官方定调之前,行业里对Token的翻译乱七八糟,有人叫“令牌”,有人叫“词元”,还有人直接用英文,导致很多普通人一听就头大,甚至不敢接触AI。
国家这次统一命名,就是要打破AI的“专业壁垒”——把晦涩的英文术语,变成我们能听懂、能记住的中文,让每个人都能看懂AI、用好AI,这才是最关键的目的!
聊完了Token的来源和官方定位,再跟大家说说最核心的问题:在大模型里,Token(词元)到底是什么?
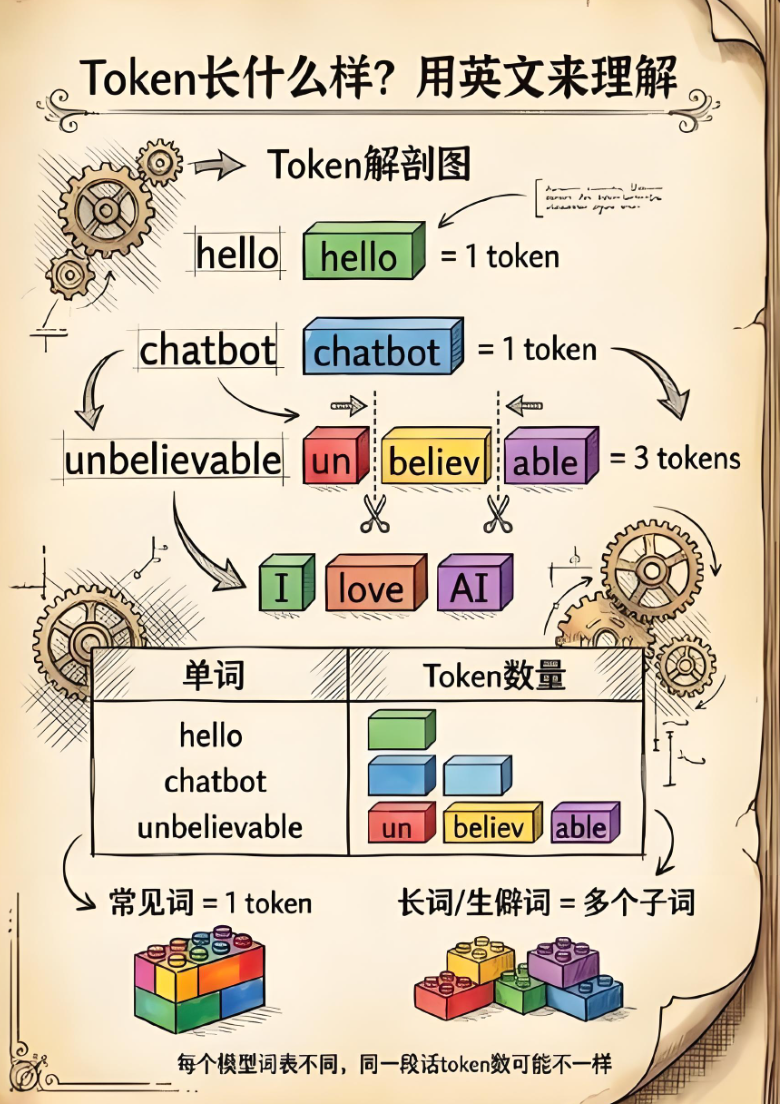
为什么大模型不直接认汉字、认单词,非要先把文字拆成Token?其实答案很简单,不是大模型“矫情”,而是它“看不懂”我们的文字——就像我们看不懂外星人的语言一样,大模型本身不认识汉字、不认识英文单词,它只认识一种东西,就是Token(词元)。
举个我自己的亲身经历,之前我用本地大模型输入“人工智能改变世界”,本来以为它能直接理解,结果输出的内容乱七八糟,我还以为是模型坏了,后来才知道,是我没搞懂Token的逻辑。
大模型处理文字的第一步,就是把“人工智能改变世界”这8个汉字,拆成8个Token(因为中文基本一个汉字就是一个Token),然后再通过这些Token,理解每个字的含义、每个词的搭配,最后才能生成连贯的内容。
原来,Token就是大模型的“母语”,不懂它,你和AI的沟通就会“鸡同鸭讲”。
既然Token是大模型的“母语”,那它是怎么来的?为什么有的词是1个Token,有的词却是好几个Token?比如“我爱你”是3个Token,“人工智能”是4个Token,而英文里的“unhappiness”,明明是一个词,却要拆成3个Token?
其实这背后,藏着一个被称为“大模型分词密码”的算法——BPE(字节对编码),也是现在所有主流大模型(GPT、Llama、文心一言、通义千问)都在使用的核心算法。
可能有人一听到“算法”就头疼,别怕,我用最通俗的话,把BPE算法讲明白,保证你一听就懂。早期的自然语言处理,是直接按“字、词、句子”来处理的,但很快就遇到了两个致命问题:一是生僻词、网络词无法处理,比如“yyds”“绝绝子”,模型根本不认识;二是词汇表无限膨胀,模型装不下,比如中文有几十万个汉字、几百万个词语,模型根本记不住。这时候,Google在2018年提出了BPE算法,一下子解决了所有问题。
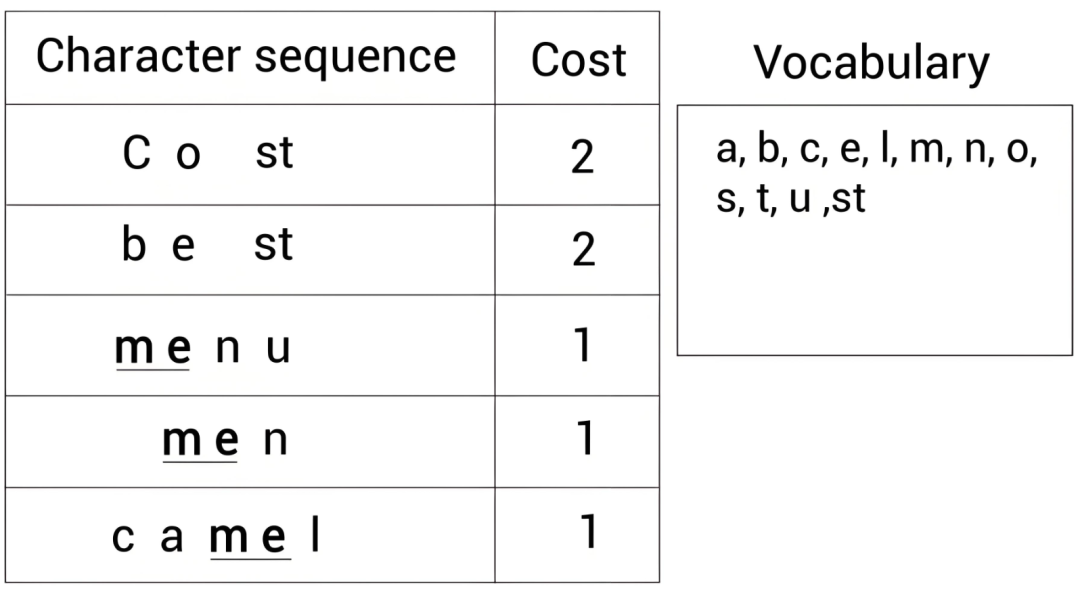
BPE算法的核心逻辑,说穿了就是“抱团取暖”——把高频出现的字、字母组合,打包成一个Token。比如中文里“的”“是”“我”这些字出现频率极高,就单独作为一个Token;“人工智能”这个词经常一起出现,就把它打包成一个Token(不过不同模型分词规则不同,有的模型会拆成“人工”“智能”两个Token)。英文里“un”“happy”“ness”这些组合出现频率高,就把它们分别打包,所以“unhappiness”会拆成“un”“happy”“ness”3个Token。金句来了:Token的生成,本质上就是“高频组合抱团,低频组合拆分”,怎么高效怎么来。
再给大家举个具体的例子,让大家更直观地理解Token的生成过程。假设我们有一段文本:“我爱吃苹果,苹果很甜,我每天都吃苹果”。第一步,模型会把这段文字拆成最细的粒度——单个汉字:我、爱、吃、苹、果、,、苹、果、很、甜、,、我、每、天、都、吃、苹、果。第二步,统计哪些组合出现次数最多,这里“苹果”出现了3次,“我吃”出现了2次。第三步,把高频组合合并成一个Token,比如把“苹果”合并成一个Token,“我吃”合并成一个Token。第四步,不断重复这个过程,直到达到模型设定的词汇表大小,最终就形成了我们看到的Token。
聊到这里,就必须说说中英文Token的差异——这可是关系到我们每个人用AI的“性价比”,尤其是经常用大模型写文案、做翻译的朋友,一定要认真看!先给大家一个核心结论:中文用户太赚了!因为中文基本是“一个汉字=一个Token”,而英文是“一个词可能拆成多个Token”,同样的内容,中文的Token数量比英文少,计费也更便宜,这也是为什么很多国内大模型,对中文用户更友好。
我做过一个真实的测试,同样是“国家数据局正式定义Token为词元,它是智能时代的价值锚点”这句话,中文有24个汉字,对应的Token数量就是24个;而把它翻译成英文“The National Data Bureau officially defines Token as Word Unit.”,只有11个单词,对应的Token数量却是11个?不对,等一下,我再核对一下,其实英文的11个单词,对应的Token数量是11个,但如果是更长的英文单词,比如“programmable”(可编程的),一个单词就会拆成2个Token,而中文的“可编程”,就是3个汉字,3个Token。这样一对比,大家就明白了:中文的Token计数更直观,也更“划算”。
再给大家分享一个实用的小技巧,也是我自己经常用的:如何快速计算一段文本的Token数量?毕竟我们用大模型的时候,经常会遇到“Token不足”的问题,提前算好Token数量,就能避免尴尬。最常用、最准确的工具,就是OpenAI官方推出的tiktoken库,它和GPT、国内主流大模型的分词逻辑几乎一致,不管是中文还是英文,都能快速算出Token数量,而且操作非常简单,哪怕你是编程小白,也能一键上手。
很多人一听到“编程”“代码”就打退堂鼓,其实真的不用怕,我把代码整理好了,大家只要复制粘贴,就能直接运行,甚至不用懂任何编程知识。
首先,我们需要安装tiktoken库,打开电脑的命令行,输入“pip install tiktoken”,等待几分钟就能安装完成。
pip install tiktoken
然后,复制我下面的代码,粘贴到Python编辑器里,替换掉测试文本,点击运行,就能快速得到Token数量,非常方便。
import tiktoken
def count_tokens(text: str, model_name: str = "gpt-3.5-turbo") -> int:
"""
计算文本的Token数量
:param text: 输入文本
:param model_name: 模型名称(决定分词规则)
:return: token数量
"""
获取模型对应的分词器 encoding = tiktoken.encoding_for_model(model_name) # 编码得到token列表 token_list = encoding.encode(text) # 返回数量 return len(token_list)# ==================== 测试 ====================if name == "main": # 中文测试 chinese_text = "国家数据局正式定义Token为词元,它是智能时代的价值锚点。" zh_tokens = count_tokens(chinese_text) # 英文测试 english_text = "The National Data Bureau officially defines Token as Word Unit." en_tokens = count_tokens(english_text) print(f"中文文本:{chinese_text}") print(f"Token 数量:{zh_tokens}\n") print(f"英文文本:{english_text}") print(f"Token 数量:{en_tokens}")
这里给大家展示一下运行结果,我用中文文本“国家数据局正式定义Token为词元,它是智能时代的价值锚点。”测试,得到的Token数量是24个;用英文文本“The National Data Bureau officially defines Token as Word Unit.”测试,得到的Token数量是11个。
中文文本:国家数据局正式定义Token为词元,它是智能时代的价值锚点。
Token 数量:24
英文文本:The National Data Bureau officially defines Token as Word Unit.
Token 数量:11
大家可以发现,中文的Token数量和汉字数量基本一致,而英文的Token数量和单词数量也差不多,但如果是更长的英文单词,Token数量就会明显增加。
聊到这里,相信大家对Token(词元)已经有了一个全面的了解,但我还是要再强调几点,避免大家踩坑。
第一,Token(词元)不是区块链代币,不要把两者搞混,不然很容易被割韭菜;
第二,中文一个汉字≈一个Token,英文一个单词可能拆成多个Token,用大模型的时候,要注意控制Token数量;
第三,Token是大模型的核心,不管是计费、上下文窗口,还是生成内容,都和Token有关,不懂Token,就无法真正用好AI。
AI时代,不懂Token(词元),就像互联网时代不懂“流量”,迟早会被淘汰!
其实,Token(词元)没有我们想象中那么晦涩,它就是AI世界里的“小积木”,是我们和AI沟通的“桥梁”。
随着AI的不断发展,Token(词元)的作用会越来越重要,它不仅会影响我们用AI的体验,还会推动整个智能时代的发展。
现在,国家已经给它定了调,我们也该跟上节奏,读懂Token、用好Token,不然以后用AI,真的会吃亏!
AI时代,认知决定差距,看懂Token(词元),才能抓住智能时代的风口。
从今天起,别再把Token念成“套肯”,别再把它和区块链代币搞混,记住它的官方名字——词元,它会成为你用AI的“加分项”,帮你在智能时代少走弯路、高效前行。如果觉得这篇文章对你有帮助,记得点赞、收藏、转发,让更多人看懂Token,一起拥抱AI时代!
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。
随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:
人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】
大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:
04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)
05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!
06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 14
14 0
0- 0



 已为社区贡献67条内容
已为社区贡献67条内容

所有评论(0)