Token入门指南:小白必看,收藏了解AI时代的核心货币
最近“Token”这个词突然无处不在。中文的正式定义也已经出台:“词元”。

黄仁勋在 GTC 2026 大会上说,数据中心正在变成“Token 工厂”;三大运营商的财报里,“Token 服务”成了新的增长主线;甚至出现了一个新概念——“Token 出海”,说的是中国的 AI 算力正在以 Token 的形式“出口”到全球。

但是,到底什么是Token?为什么它突然变得这么重要?它跟我们用 AI 花的钱有什么关系?
今天,我花几分钟,把这件事从头到尾给大家讲清楚。
一、Token 是什么?AI 的"最小零件"
我们先从最基本的概念说起。
Token,是大模型"读懂"文字的最小单位,这也是它叫做“词元”的原因,或者说“词语的基本元素”。
你跟豆包、DeepSeek 或者“龙虾”聊天的时候,你输入的是一段“人话”,但是大模型并不是像人一样“一个字一个字”地读的。它会先把你的文字,切成一个个小碎片,这些碎片就叫 Token。
打个比方:你说的话是一道菜,Token 就是这道菜的食材。
大模型是一个厨师,它不会直接处理整道菜,而是先把菜拆解成一个个食材——葱、姜、蒜、肉片、酱油——然后再重新加工组合,做出一道新菜(也就是给你的回答)。

每一个 Token,大致相当于一个词、一个数字或者一个标点符号。但不同语言的"切法"是不一样的。
二、一句英文几个 Token?一句中文几个 Token?
这个问题很多朋友都问过我。规律大致如下:
英文:1 个单词 ≈ 1.3 个 Token。
为什么不是正好 1 个?因为有些长单词会被切成两块。比如 “understanding” 可能会被切成 “understand” + “ing” 两个 Token。
中文:1 个汉字 ≈ 1.5 个 Token。
这是因为中文在大模型眼里是"外语"——大部分模型最初是用英文训练的,对中文的"切割效率"没有英文高。一个"我"字,可能就占了 1-2 个 Token。
换算成大家容易理解的比例:
1000 个 Token ≈ 750 个英文单词 ≈ 500 个汉字
也就是说,500 个汉字——大约是你微信上发一段长消息——在大模型眼里就是 1000 个 Token。
三、大模型厂家怎么收费?算一笔账给你看
讲了这么多,我们来点实在的——用 AI 到底花多少钱?
目前主流大模型的计费方式非常统一:按 Token 数量计费,输入和输出分开定价。
以 DeepSeek 当前的官方定价为例:
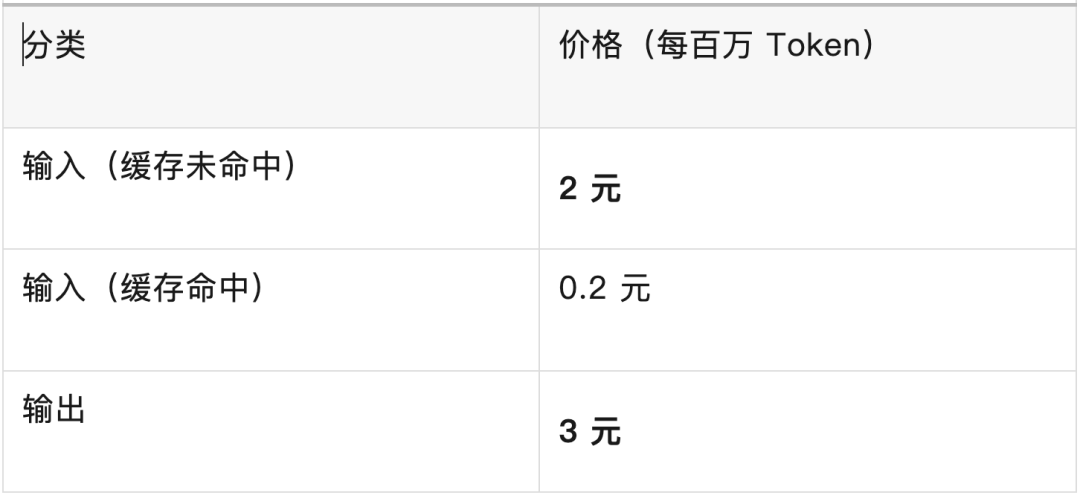
“缓存命中”的意思是,你之前问过类似的问题,系统有缓存,所以便宜 10 倍。但大部分情况下,我们按“缓存未命中”来算就好。
来,我们实际算一笔。
假设你向 DeepSeek 输入了一段 500 字的中文问题,它给你回复了 1000 字的回答:
输入:500 字 × 1.5 =750 个 Token
输出:1000 字 × 1.5 =1500 个 Token
输入费用:750 ÷ 1,000,000 × 2 =0.0015 元
输出费用:1500 ÷ 1,000,000 × 3 =0.0045 元
合计:0.006 元,不到一分钱。
你没有看错——一次还算详细的问答,不到一分钱。
DeepSeek 的官方定价表:
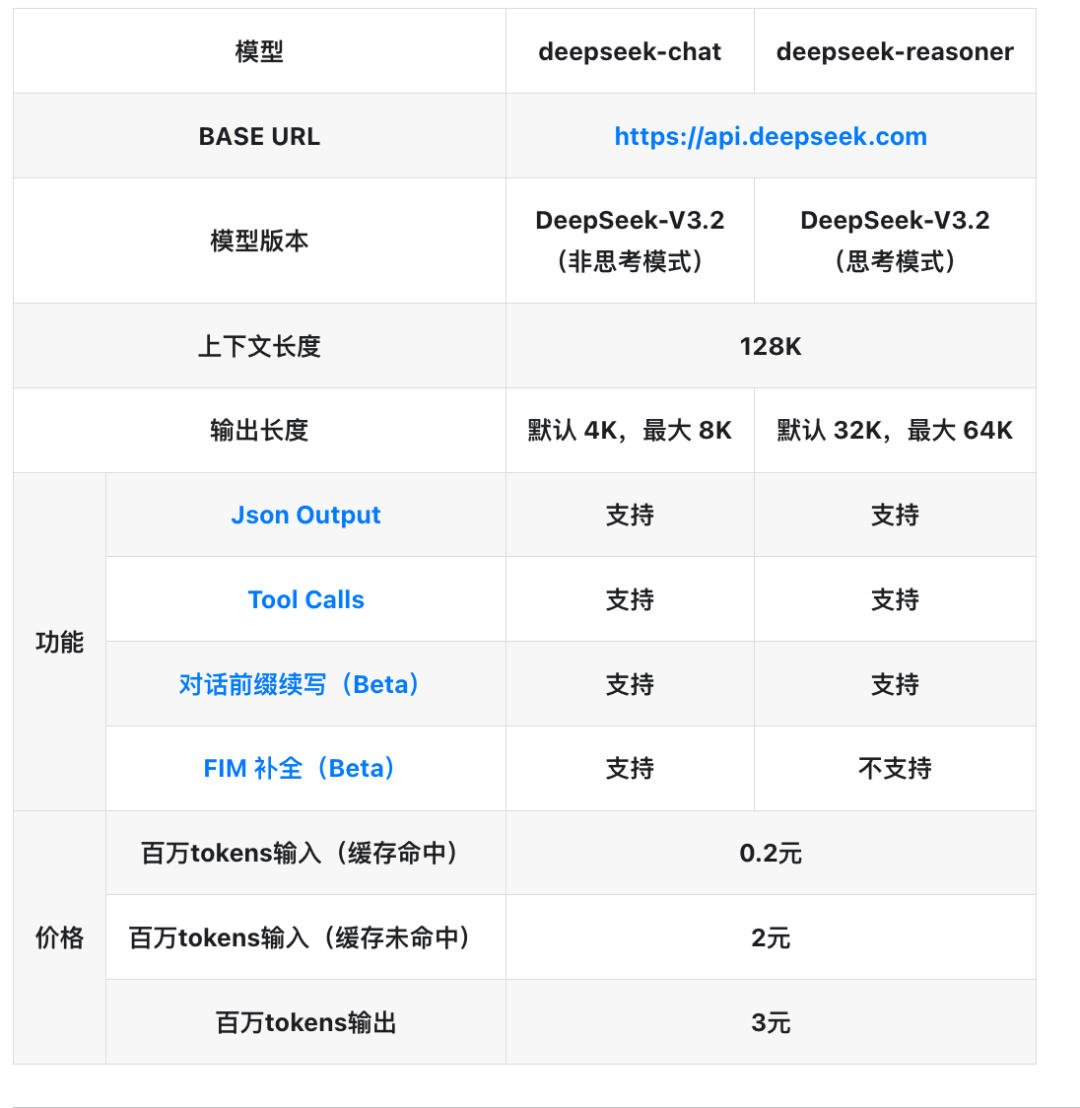
四、但是注意!你实际花的钱,可能是你以为的好几倍
上面的计算只是“理想状态”。实际使用中,你的花费往往比你以为的要多得多。原因在于:你看到的“输入”,只是冰山一角。
当你在 AI 产品里输入一个问题的时候,系统在背后偷偷塞进去了大量的“隐形输入”:
系统提示词:告诉 AI “你是谁、你能做什么、你不能做什么”,这段话可能就有几百上千个 Token;
历史对话记录:为了让 AI “记住”之前聊过什么,系统会把你之前的所有对话都一股脑发给它;
工具描述和上下文:如果你的 AI 配置了各种 Skill
所以,你输入了 10 个字,实际发给大模型的可能是 10000 个 Token。
这就好比你去餐厅点了一碗面,你以为你只为这碗面付钱,但其实菜单上还包含了桌布费、空调费、服务费、餐具消毒费……
这也是为什么现在 AI 行业特别强调“上下文工程”(Context Engineering)——如何精准地控制发给大模型的信息量,既要够用,又不能浪费。毕竟,每一个 Token,都是真金白银。
五、黄仁勋说:数据工厂变成了 Token 工厂
讲完“小账”,我们来看看“大账”。
2026 年 3 月的 GTC 大会上,黄仁勋做了一场两个多小时的演讲,核心观点只有一个——AI 已经从训练时代进入了推理时代,Token 成为了核心商品。
他用了一个非常精准的比喻:
过去的数据中心是“仓库”——存东西的,不直接赚钱。现在的数据中心是“工厂”——生产 Token 的,直接和企业收入挂钩。
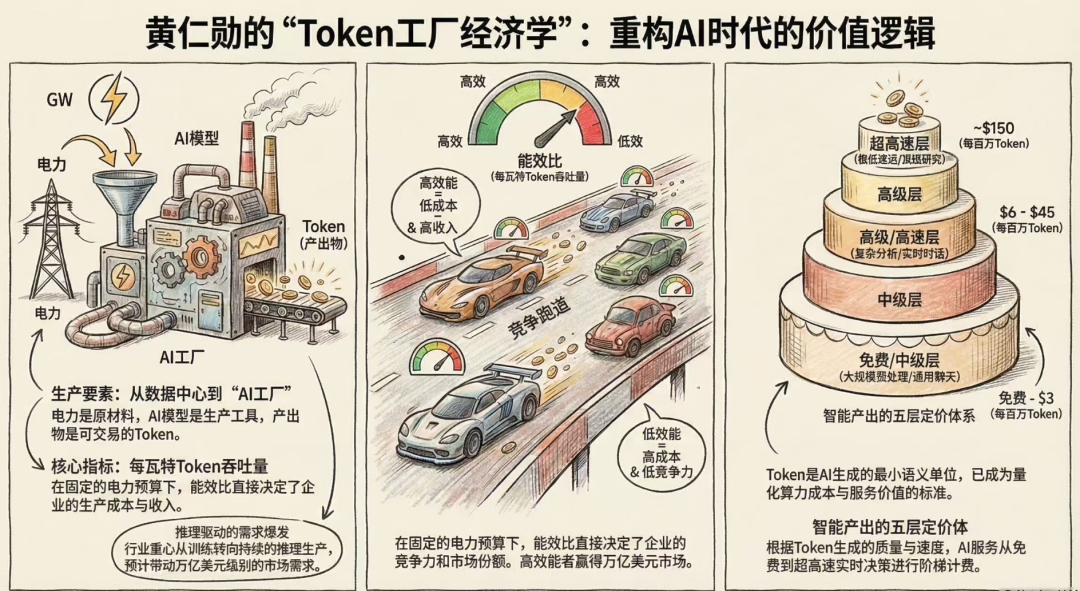
这意味着,计算设备完成了一次从成本中心到利润中心的根本性跨越。
你买一堆服务器放在机房里,以前它只是帮你存数据、跑业务的“后勤部队”,花钱的。
现在,这些服务器变成了“生产线”——它们日夜不停地生产 Token,然后把这些 Token 以 API 的形式卖给全世界。
“API”的意思,是国内外的各种智能体(例如“龙虾”),可以通过API Key,调用各种大模型来工作
黄仁勋甚至预测,Token 正在出现像 iPhone 一样的分层定价:
有免费的 Token,有普通 Token,有高级 Token。
有人愿意为每一百万个 Token 支付 1000 美元,这不是会不会发生的问题,而是何时发生的问题。
黄仁勋
他还放出了一个让人瞠目结舌的判断:未来用于计算的 GDP 占比,将是过去的 100 倍。
六、Token 经济学的底层逻辑:电力 → 算力 → Token → 价值
到这里,我们就触及了 Token 经济学最核心的本质。
Token 的背后是算力,算力的背后是电力。
一个 Token 的生产过程,本质上是这样的:
电厂发电 → 电力送到数据中心 → 数据中心的 GPU 消耗电力进行计算 → 计算结果以 Token 的形式输出 → Token 被打包成 AI 服务卖给用户。
所以有人说,Token 就是电力的“金融化表达”。
这话听起来抽象,我们来算一笔具体的账:
中国西部的绿电价格约0.2-0.3 元/度;
生成 100 万个 Token 大约需要15-20 度电,电力成本不过几元钱;
而在国际市场上,同等质量的 Token 输出定价在60-168 美元/百万 Token;
即使按国内定价(约 2 元/百万 Token),一度电通过 Token 转化后可以卖到 11 元。
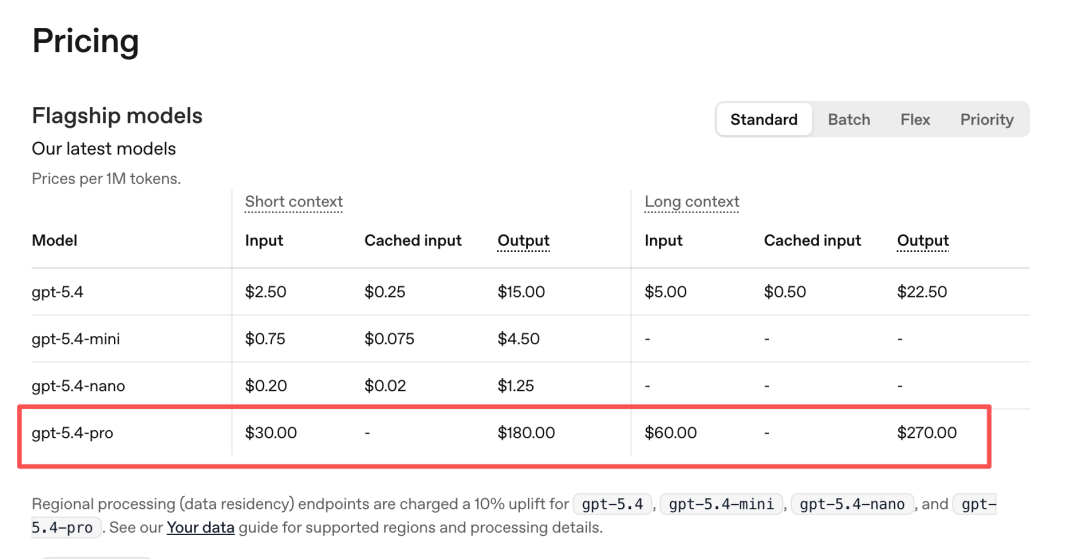
上图是 OpenAI 的 Token 收费,可以看到,每百万 Token 的收费要高出很多,当然,模型不同,功能不一样,但是在一些基本功能上跟开源模型效果相差并不大,但是价格贵了几十倍。
这是什么概念?一度 0.2 元的电,经过“Token 炼化”,增值了 50 倍以上。这种增值效应,是传统电力出口完全无法企及的。
而欧美的电价是 0.8-1.2 元/度,是中国的 3-5 倍。这意味着中国的 Token 成本天生就有巨大的价格竞争力。
这就是为什么黄仁勋说基础设施的本质是“做 Token 的生产”。
电力是 Token 经济的燃料,谁的电力便宜,谁就握住了 AI 时代的成本优势。
七、Token 出海:运营商的新战场
如果说上面讲的是“Token 是什么”和“Token 值多少钱”,那么最近最让人兴奋的趋势,是Token 出海。
什么意思呢?
简单说:中国的 AI 算力,正在以 Token 的形式“出口”到全世界。
根据最新数据,中国在全球 Token 调用量中排名第一,占36%;Token 出口量更是占到全球的60% 以上。
这背后的逻辑非常巧妙:
中国有便宜的绿电、有强大的算力基础设施、有成熟的大模型(如 DeepSeek),所以可以在国内低成本生产 Token,然后通过 API 接口卖给全球的开发者和企业。
更妙的是时差经济——浙江移动的一位负责人提到:“白天的算力给国内用,夜间的算力可以向欧美出口。”
一台 GPU 服务器,24 小时不停转,白天服务国内客户,晚上赚美元。
三大运营商正在从"网络运营商"转向"Token 运营商"。
中国移动的智算规模达 92.5 EFLOPS,中国电信 91 EFLOPS,中国联通 45 EFLOPS。这些基础设施过去用来传输数据,现在正在被重新定位——生产和运输 Token。

中国移动甚至已经在香港建设了环球智算中心,直接向全球客户提供算力服务。
运营商们明白了一个道理:过去卖的是“带宽”(每月多少 GB 流量),未来卖的是“Token”(每月多少百万 Token)。底层基础设施没变——还是光纤、服务器、数据中心——但上面跑的"货"变了。
最后:理解 Token,就是理解 AI 时代的经济学
让我们把整篇文章串起来:
Token 是 AI 理解世界的最小单位,也是 AI 世界里的"通用货币"。
对普通用户来说,Token 决定了你用 AI 花多少钱——每一次提问、每一段回答,都在消耗 Token;
对企业来说,Token 正在从成本变成收入——谁能高效地生产和销售 Token,谁就掌握了 AI 时代的商业密码;
对国家来说,Token 正在重塑全球竞争格局——电力优势通过 Token 转化为 AI 服务优势,“Token 出海”正在成为一种新的出口形态。
电力 → 算力 → Token → 价值。这条链路,就是整个 AI 时代的经济学底座。
黄仁勋把 AI 比作一场新的“工业革命”。如果说蒸汽机时代的核心资源是煤炭,电气时代的核心资源是石油,那么智能时代的核心资源,就是 Token。
现在你再看那些关于 AI 的新闻——算力竞赛、芯片制裁、大模型降价、Token 出海——是不是突然就串起来了?
它们讲的,都是同一件事:谁能更便宜、更高效地生产 Token,谁就能赢得 AI 时代带来的巨大商机。
以上就是我对 Token 的一个入门级梳理。这些概念看起来复杂,但底层逻辑其实很清晰。希望这几分钟能帮大家建立起一个清晰的认知框架。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。
随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:
人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】
大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:
04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)
05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!
06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献77条内容
已为社区贡献77条内容

所有评论(0)