Hermes 上手指南:AI 编程工作流的新选择
这篇不先堆名词。我们把《Hermes 上手指南:AI 编程工作流的新选择》拆成几级台阶,看完至少知道下一步该学什么、该练什么。
摘要
这篇面向关注 AI 编程工具和自动化开发流程的程序员,但不会把“Hermes 上手指南:AI 编程工作流的新选择”写成概念清单。我会按工具评测 + 实战教程的思路,把它放到真实开发、学习路线和求职准备里看,顺便讲几个容易忽略的取舍。
目录
- Hermes 是什么
- 核心能力
- 模型配置
- 项目协作
- 适合场景
- 总结
Hermes 是什么
很多人聊“Hermes 是什么”,会先把定义背一遍。我的看法稍微不一样:从学习路线看,它必须能解释“Hermes 上手指南:AI 编程工作流的新选择”里一个具体问题,否则就只是好听的词。
拿一个小项目来说,先别急着把框架、平台和插件全接上。我更愿意先画清楚输入是什么、输出给谁看、失败了怎么回滚。这三件事弄明白,后面的代码通常不会散。
这里最容易踩的坑,是把临时方案包装成通用架构。如果只是一次性脚本,就保持直白;如果要长期复用,再抽接口、加日志、补测试。
核心能力
“核心能力”这块不适合只看教程截图。真正有用的学习方式,是把“Hermes 上手指南:AI 编程工作流的新选择”拆成一个可以演示的小流程。
比如先做一个最小版本:一份输入数据,一个处理函数,一个可见结果。跑通以后再考虑缓存、权限、监控和异常处理。这样推进慢一点,但每一步都能留下证据。
如果你准备把它写进简历,也别只写“熟悉”。最好能说清楚你解决了什么问题、用了什么取舍、最后效果怎么验证。
from collections.abc import Callable
def trace_call(name: str) -> Callable:
def decorator(func: Callable) -> Callable:
def wrapper(*args, **kwargs):
print(f"start {name}")
result = func(*args, **kwargs)
print(f"finish {name}")
return result
return wrapper
return decorator
@trace_call("calculate")
def calculate_score(values: list[int]) -> int:
return sum(value * 2 for value in values)模型配置
我不建议把“模型配置”理解成一个孤立知识点。它更像是“Hermes 上手指南:AI 编程工作流的新选择”里的一段连接层:前面接需求,后面接实现,中间全是取舍。
实际开发时,我会先保留最朴素的版本,哪怕代码看起来没那么漂亮。等需求稳定、调用频率上来,再去做抽象。过早设计通常不是专业,很多时候只是给自己增加维护成本。
检查这部分有没有做好,可以看三个信号:别人能不能接手,线上出错能不能定位,需求变化时要不要大面积重写。
在复杂度估算中,可以把一次批处理抽象为:
$$T(n)=O(n)+O(k)$$
其中 n 表示输入规模,k 表示固定的框架调度成本。这个表达式提醒我们,优化时既要关注算法,也要关注运行时环境。
项目协作
很多人聊“项目协作”,会先把定义背一遍。我的看法稍微不一样:从学习路线看,它必须能解释“Hermes 上手指南:AI 编程工作流的新选择”里一个具体问题,否则就只是好听的词。
拿一个小项目来说,先别急着把框架、平台和插件全接上。我更愿意先画清楚输入是什么、输出给谁看、失败了怎么回滚。这三件事弄明白,后面的代码通常不会散。
这里最容易踩的坑,是把临时方案包装成通用架构。如果只是一次性脚本,就保持直白;如果要长期复用,再抽接口、加日志、补测试。
适合场景
“适合场景”这块不适合只看教程截图。真正有用的学习方式,是把“Hermes 上手指南:AI 编程工作流的新选择”拆成一个可以演示的小流程。
比如先做一个最小版本:一份输入数据,一个处理函数,一个可见结果。跑通以后再考虑缓存、权限、监控和异常处理。这样推进慢一点,但每一步都能留下证据。
如果你准备把它写进简历,也别只写“熟悉”。最好能说清楚你解决了什么问题、用了什么取舍、最后效果怎么验证。
总结
回到“Hermes 上手指南:AI 编程工作流的新选择”这个主题,最重要的不是把名词背全,而是知道它该放在什么场景里用。能跑起来的小项目、说得清楚的技术取舍、能展示的结果,比泛泛而谈更有说服力。后面真做的时候,可以先挑一个小场景验证,再把代码、笔记和复盘整理成自己的作品集。
延伸实践
如果你准备拿这个方向做作品集,我建议先做一个小而完整的 Demo。不要一开始就追求功能很多,先保证输入、处理、输出、日志这四件事闭合。面试时能把这条链路讲清楚,比只说自己看过多少教程更有说服力。
代码层面可以保留两类文件:一类是最小可运行版本,方便别人快速复现;另一类是增强版本,用来展示缓存、重试、权限和监控这些工程细节。这样写简历时也更好描述,不会只剩几个空泛关键词。
学习顺序上,先把基础调用、数据结构和异常处理补齐,再考虑复杂框架。很多同学一上来就追新工具,结果调通了示例,却解释不清为什么要这么设计。这类项目真正拉开差距的地方,往往在取舍和排错过程。
如果团队里要推广这套方案,最好提前约定输入格式、输出格式和错误码。这些东西看起来不酷,但后面接更多模块时会省很多沟通成本。一个能长期维护的项目,通常不是靠某个复杂技巧撑起来的。
最后再补一句现实建议:不要把学习成果只放在本地。可以写一篇复盘文章,配上运行截图、关键代码和遇到的问题。这种材料既能帮助自己复习,也能让别人判断你是不是认真做过。
资料展示
下面是我整理的大模型学习资料和工具包预览,适合收藏后按主题逐步学习。
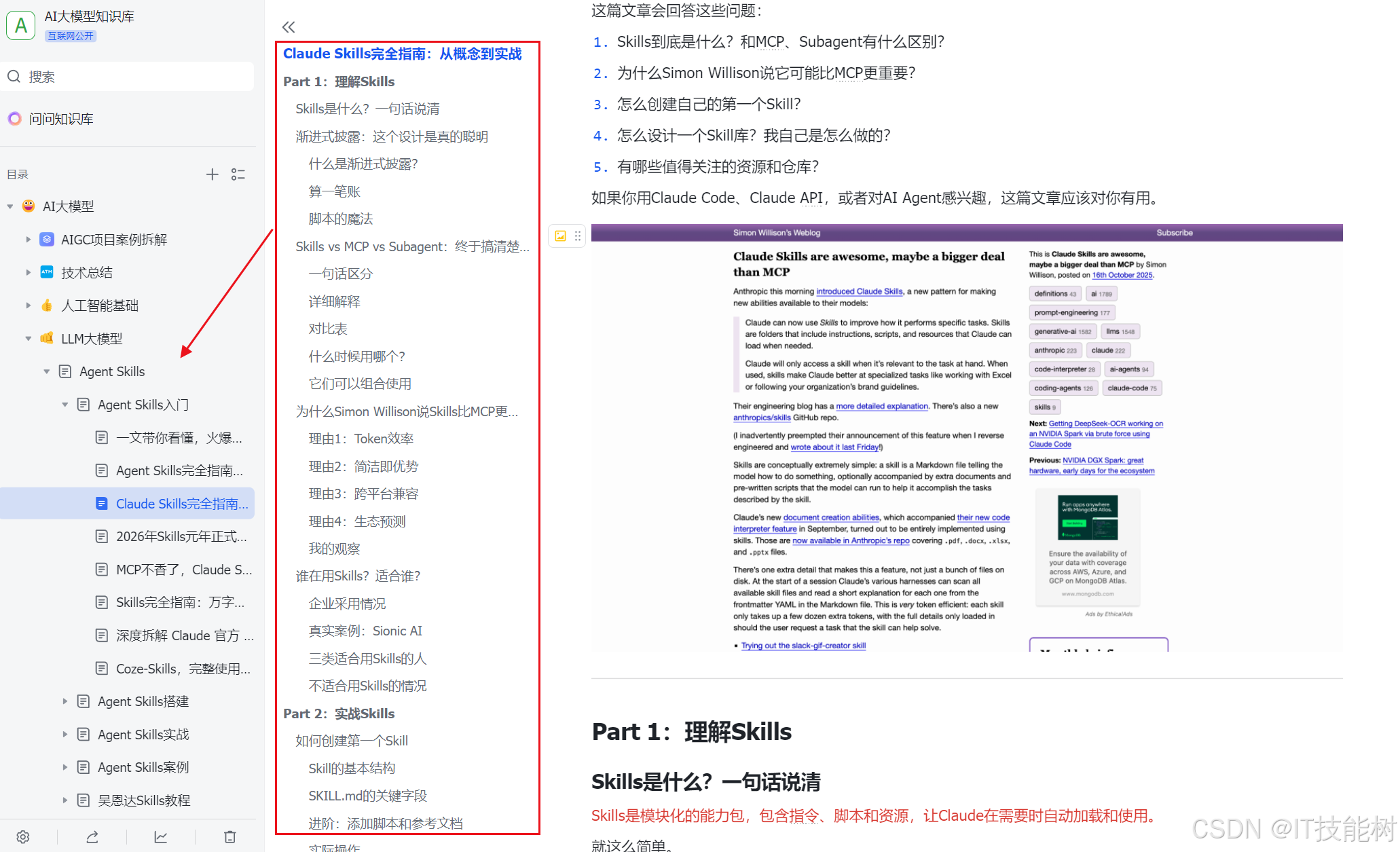
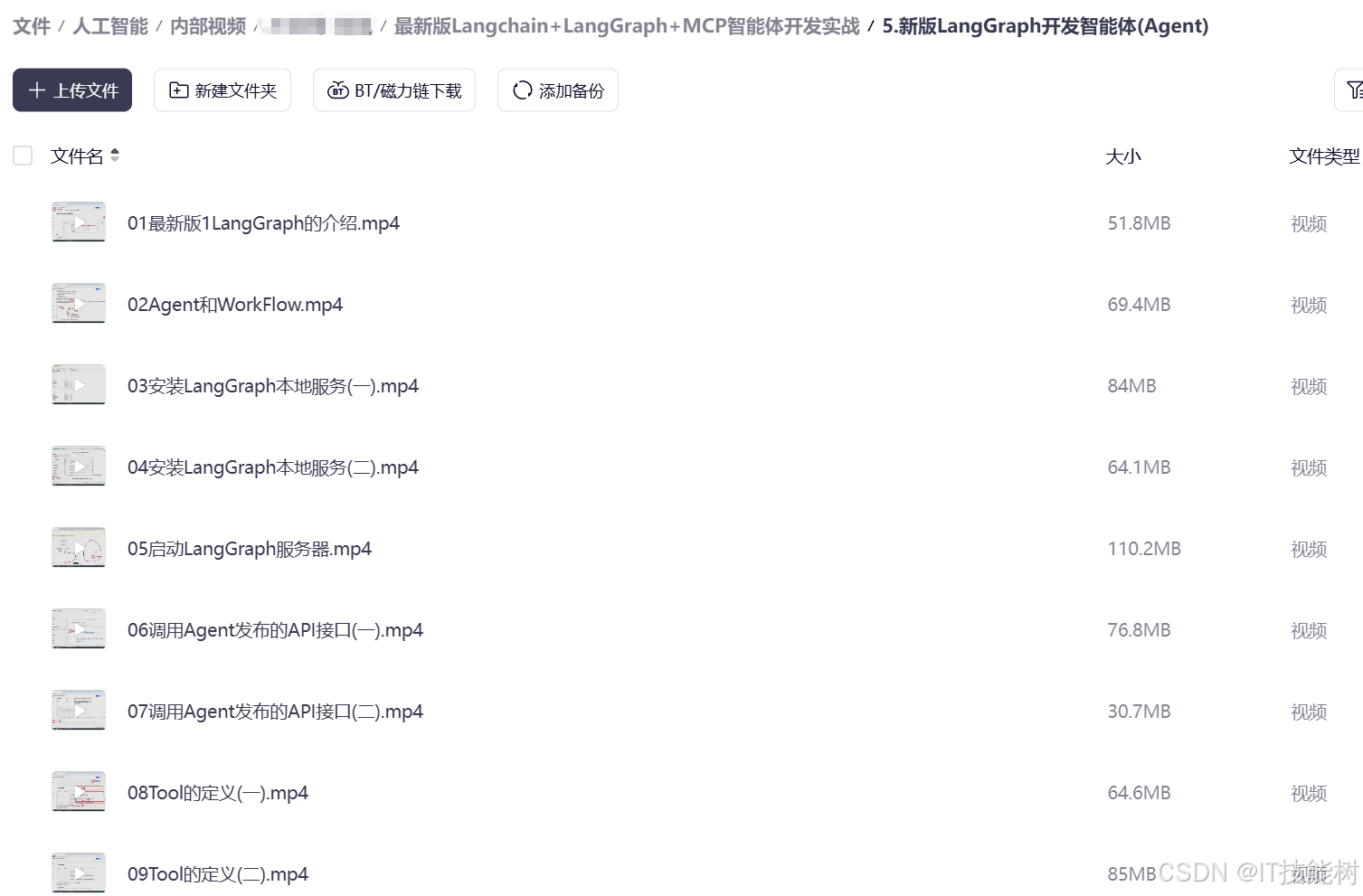
如果你想看完整资料目录,可以在评论区留言「资料」;也欢迎告诉我你更关注就业路线、项目实战还是面试题。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 3
3 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)