LLM到Agent&RAG——AI概念概述 第三章:RAG
RetrievalArgumentedGeneration——检索增强生成
LLM局限性
幻觉问题——一本正经胡说八道
大模型可能生成一个看起来很合理但实际上完全错误的内容。

使用编纂的人名去问,回答的也是一个公司中不存在的人。当前,较高版本ai结合联网搜索功能降低了幻觉问题
原因:LLM本身预测概率最高的词,并不理解真正的事实。当其对问题不确定时,它不懂得说不知道,而是生成一个符合问题的编纂内容。
知识时效性——活在过去
大模型知识是冻结在训练截止日期的。
当我们关闭联网搜索就会看见:
对企业应用而言,这个问题很严重——产品在更新迭代、政策实时变化、价格在调整,而LLM一无所知。
专业领域深度不足
大模型训练量是海量级别的,但是特定专业区域不够深入。
训练数据当中针对特定领域专业内容很有i按,模型对领域的深度了解远不如专家。
私有数据无法获取
大模型是在公开数据上进行访问,训练时它不可能访问:
-
公司内部文档
-
客户数据
-
未公开的研究资料
-
个人私有信息
也不应该获取得到。但是这样也导致了大模型对较为私密的问题回答起来很局限。
黑盒不可追溯
大模型回答无法追溯来源(早期)

在很多场景下(医疗、法律、金融、时政),我们需要知道答案的来源,以便验证和追责。大模型做不到这一点。
RAG架构:开卷考试
概念
Retrieval-Argumented Generation 检索增强生成
与其让LLM记住所有知识点,不如教大模型先查资料再回答。这样一来,模型的回答就有据可依了——既利用了大模型理解语义的能力,又能接入最新的、私有的知识库数据。
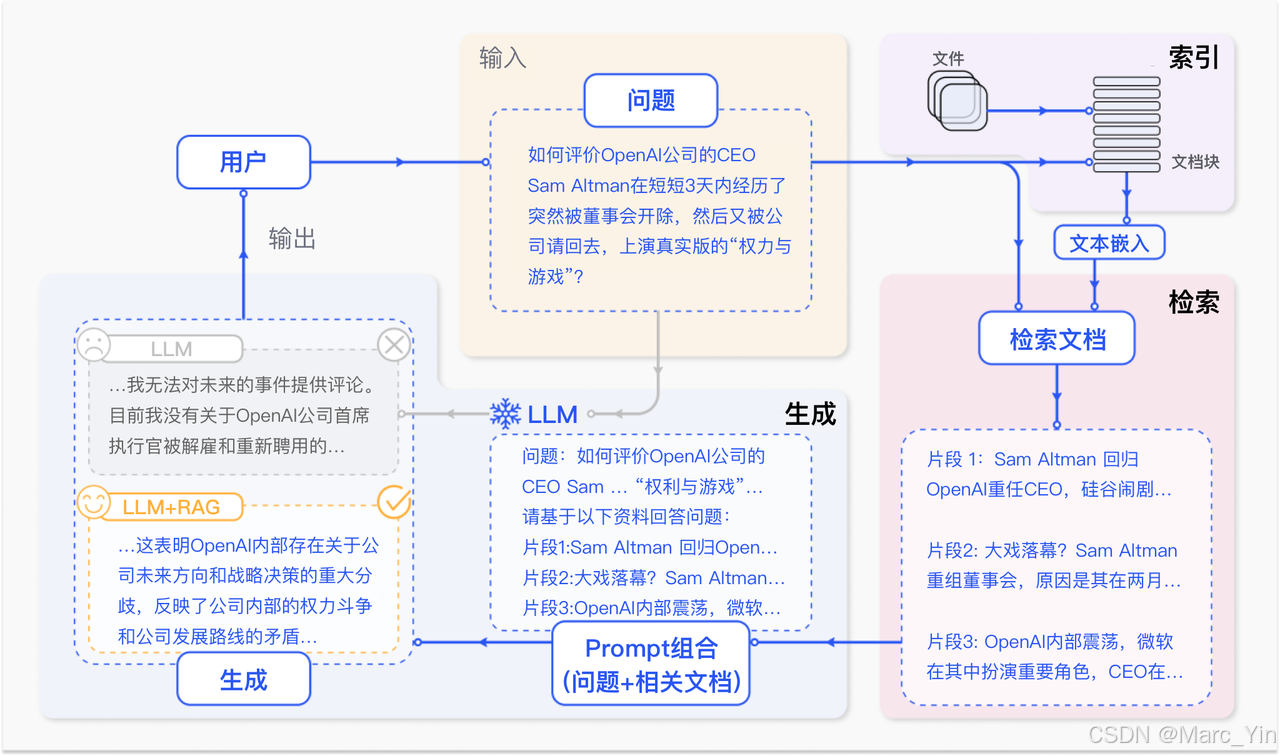
思路简述:
-
公司产品文档数据存储到能理解语义的知识库当中
-
用户提问时,从知识库检索相关内容
-
检索到的内容和用户问题一起发给大模型
-
大模型基于参考资料和用户问题进行回答
无需记住所有知识,只要能找到并理解即可
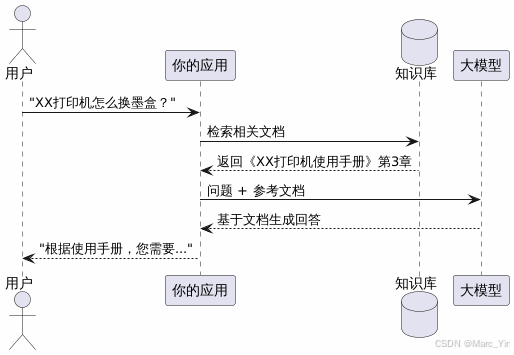
核心流程
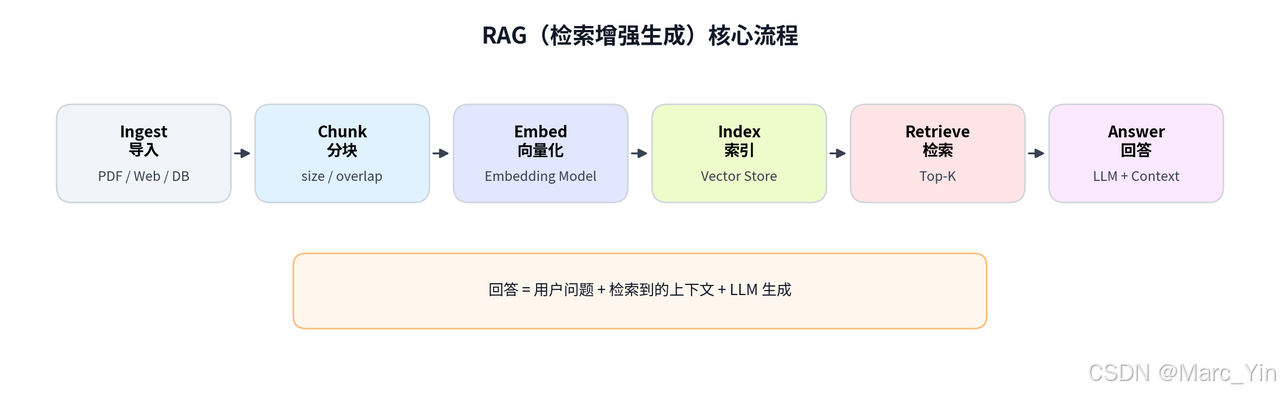
Ingest:导入数据
将数据源接入系统。
数据可能是任何类型:PDF、Word文档、网页html、数据库的结构化数据、代码等。不同格式使用不同解析方式:PDF 要提取文字,Word 要读取内容,网页要爬取并清洗。
目标:获取干净的纯文本
Chunk:长文档切成小文档
文档一般较长,直接使用存在的问题:
-
大模型上下文窗口有限,塞不下整篇文档
-
检索时只需要最相关的文档,而不是整篇文章
所以我们进行切块。
常见做法:500-1000字为一块。相邻块之间有重叠部分(例如100字),防止重要文字被切断导致信息丢失、语义不明。
Embed:文字向量化
RAG核心。
传统关键字搜索并不了解语义,更不用说同义词、反义词等。
如何让机器了解“这个产品怎么用”≈“产品说明手册”?
将文字转换为机器能理解的参数——向量
向量——很大一串数字,比如 [0.23, -0.45, 0.67, ...],可能有几百上千维。这串数字编码了文字的语义信息,意思相近的文字向量空间中就越近。
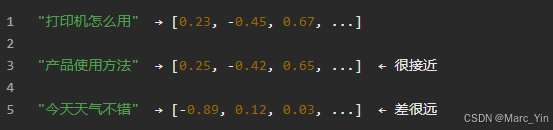
这种将文本转化为向量的工作由专门的Embedding模型完成,例如Qwen3-Embedding-8B或者开源的bge、m3e
Index:存进向量数据库
向量算出来的,我们同样需要数据库对其进行存储。向量数据库专门用于存储向量,做相似度搜索的时候:给一个向量,找出距离最近的N个。
存储的时候,向量和原文需要一起存储。后续检索出来之后将原文给大模型看。同时需要对应的元数据(后续讲解),方便检索时进行筛选。
Retrieve: 检索相关内容
用户提问"打印机墨盒怎么换"
这个时候我们需要做两件事情:
-
将用户问题向量化
-
将这个向量拿到数据库当中比对,找出最相近的几个文档块。
Answer:大模型生成回答
最后一步,把检索到的内容和用户问题打包发给大模型。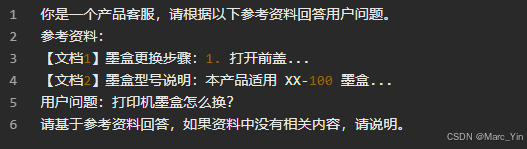
大模型根据资料作出回答。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)