小白也能做预测,做好预测从了解数据和数据形态开始(二)——自相关函数
前文介绍了对于预测数据和数据形态的分析,可能通过图形直接判断,但是对于一些相对复杂的数据,有时我们很难直接从图形上进行判断得出规律,需要通过其他的方法来帮助我们做更准确的判断。对于时间序列的判断,我需要引入另一个概念,就是ACF, Autocorrelation的缩写,中文叫自相关函数。
自相关函数是研究经验时间序列属性的一个非常有价值的工具。
一、什么是自相关函数Autocorrelation (ACF)?
时间序列值与其k阶滞后值之间的关系可以用它们的相关系数来度量,称为自相关系数,记做k=0,1,2,...。对于一个平稳的序列,各个自相关系数都只和时间间隔(滞后阶数)k有关,而与时间本身无关。因此,我们可以把这一系列的自相关系数看作k的函数,称为自相关函数(ACF-Autocorrelation Function)。举例说明:
我们以国际原油平均价格为例:(*注:因为原始微信号文章是在2025年初写的,所以本案例数据只取到2023年,没有取2024年以后的数据。)
|
Year |
Crude oil prices (US$) |
k=1 |
k=2 |
k=3 |
k=4 |
k=5 |
k=6 |
|
|
Yt |
Yt-1 |
Yt-2 |
Yt-3 |
Yt-4 |
Yt-5 |
Yt-6 |
|
1991 |
125.80 |
-- |
-- |
-- |
-- |
-- |
-- |
|
1992 |
121.52 |
125.80 |
-- |
-- |
-- |
-- |
-- |
|
1993 |
106.75 |
121.52 |
125.80 |
-- |
-- |
-- |
-- |
|
1994 |
99.49 |
106.75 |
121.52 |
125.80 |
-- |
-- |
-- |
|
1995 |
107.03 |
99.49 |
106.75 |
121.52 |
125.80 |
-- |
-- |
|
1996 |
130.00 |
107.03 |
99.49 |
106.75 |
121.52 |
125.80 |
-- |
|
1997 |
120.09 |
130.00 |
107.03 |
99.49 |
106.75 |
121.52 |
125.80 |
|
1998 |
79.98 |
120.09 |
130.00 |
107.03 |
99.49 |
106.75 |
121.52 |
|
1999 |
113.03 |
79.98 |
120.09 |
130.00 |
107.03 |
99.49 |
106.75 |
|
2000 |
179.23 |
113.03 |
79.98 |
120.09 |
130.00 |
107.03 |
99.49 |
|
2001 |
153.75 |
179.23 |
113.03 |
79.98 |
120.09 |
130.00 |
107.03 |
|
2002 |
157.39 |
153.75 |
179.23 |
113.03 |
79.98 |
120.09 |
130.00 |
|
2003 |
181.34 |
157.39 |
153.75 |
179.23 |
113.03 |
79.98 |
120.09 |
|
2004 |
240.68 |
181.34 |
157.39 |
153.75 |
179.23 |
113.03 |
79.98 |
|
2005 |
342.93 |
240.68 |
181.34 |
157.39 |
153.75 |
179.23 |
113.03 |
|
2006 |
409.74 |
342.93 |
240.68 |
181.34 |
157.39 |
153.75 |
179.23 |
|
2007 |
455.31 |
409.74 |
342.93 |
240.68 |
181.34 |
157.39 |
153.75 |
|
2008 |
611.72 |
455.31 |
409.74 |
342.93 |
240.68 |
181.34 |
157.39 |
|
2009 |
387.90 |
611.72 |
455.31 |
409.74 |
342.93 |
240.68 |
181.34 |
|
2010 |
500.01 |
387.90 |
611.72 |
455.31 |
409.74 |
342.93 |
240.68 |
|
2011 |
699.78 |
500.01 |
387.90 |
611.72 |
455.31 |
409.74 |
342.93 |
|
2012 |
702.38 |
699.78 |
500.01 |
387.90 |
611.72 |
455.31 |
409.74 |
|
2013 |
683.44 |
702.38 |
699.78 |
500.01 |
387.90 |
611.72 |
455.31 |
|
2014 |
622.35 |
683.44 |
702.38 |
699.78 |
500.01 |
387.90 |
611.72 |
|
2015 |
329.50 |
622.35 |
683.44 |
702.38 |
699.78 |
500.01 |
387.90 |
|
2016 |
275.08 |
329.50 |
622.35 |
683.44 |
702.38 |
699.78 |
500.01 |
|
2017 |
340.86 |
275.08 |
329.50 |
622.35 |
683.44 |
702.38 |
699.78 |
|
2018 |
448.53 |
340.86 |
275.08 |
329.50 |
622.35 |
683.44 |
702.38 |
|
2019 |
403.87 |
448.53 |
340.86 |
275.08 |
329.50 |
622.35 |
683.44 |
|
2020 |
263.15 |
403.87 |
448.53 |
340.86 |
275.08 |
329.50 |
622.35 |
|
2021 |
446.02 |
263.15 |
403.87 |
448.53 |
340.86 |
275.08 |
329.50 |
|
2022 |
637.28 |
446.02 |
263.15 |
403.87 |
448.53 |
340.86 |
275.08 |
|
2023 |
519.80 |
637.28 |
446.02 |
263.15 |
403.87 |
448.53 |
340.86 |
表一:国际原油价格及滞后阶数数据表
Yt-1 是国际原油价格Yt的滞后1阶数,Yt-2是滞后2阶数,以此类推,而计算自相关系数rk
的公式如下:
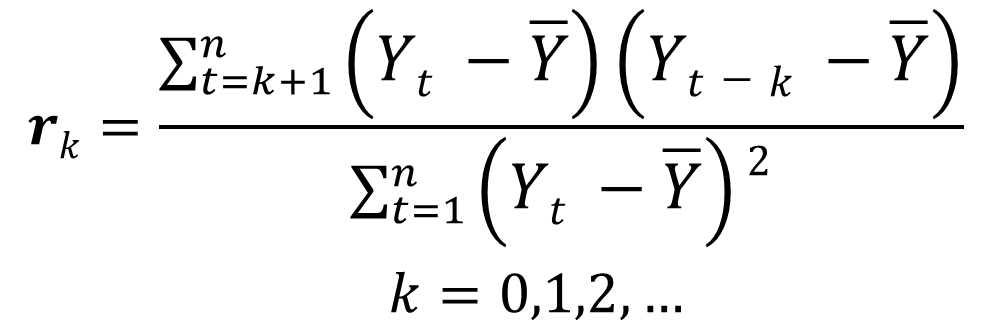
其中:t-1, t-2, ..., t-k 为下标
公式,得出相关滞后阶数系数为:
r1 = 0.8319 r2 = 0.6365 r3 =0.5521 r4 =0.4821 r5 = 0.3946 r6 =0.2888
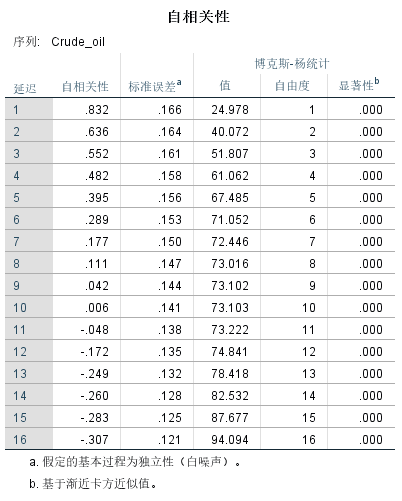
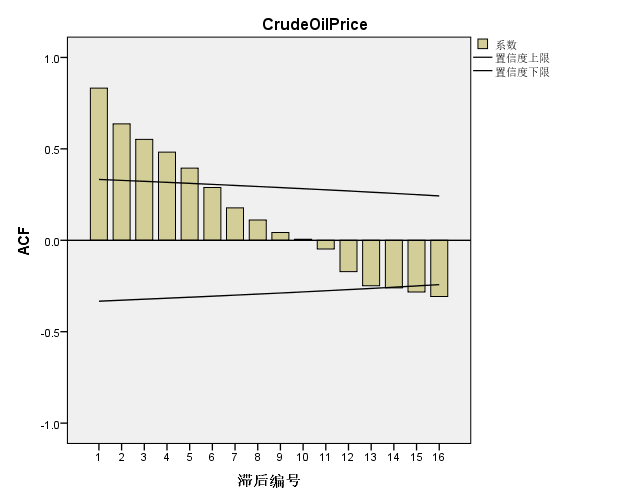
二:自相关系数图SPSS的计算结果与ACF自相关图
那么,如何理解自相关系统的这些值,它们和数据隐含的规律又有什么关系?
从公式看以看出,随着k阶的滞后,分子项数会逐渐比分母小。所以我们从k值和自相关图形观察和判断时间序列的情况。
二、不同数据形态的ACF的特点
1. 如果一个序列是带趋势的,则其连续的观测值是高度相关的,并且自相关系数通常在前几个时间滞后期间显著地不为零,然后随着滞后次数的增加逐渐下降到零。滞后1的自相关系数通常很大(接近于1),滞后2的自相关系数也很大,但它不会像滞后1那么大。
从原油的这个自相关系数ACF的k值的数据结果说明,如果一个序列是带趋势的,则其连续的观测值是高度相关的,并且自相关系数通常在前几个时间滞后期间显著地不为零,然后随着滞后次数的增加逐渐下降到零。滞后1的自相关系数通常很大(接近于1),滞后2的自相关系数也很大,但它不会像滞后1那么大。
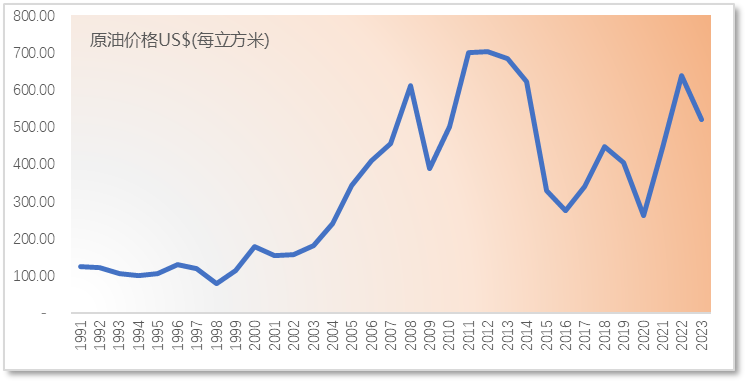
图二:国际原油价格走势图,数据来源:国际原油价格网
我们看到的的国际原油价格从1991年开始是明显处于增长趋势的,所以它的滞后阶数的相关系数ACF的rk值相对就比较大,尤其是r1 = 0.8319,接近于1,而后续的相关系数k的值趋向于0的过程是非常缓慢的。这就是带有趋势的时间序列的自相关函数的典型特征。
2. 如果一个序列是水平(不带趋势)的,其自相关系数快速趋向于零,一般在第二或第三个时间滞后之后。
我们来看一下以下的例子:
我们可以从图中看到,数值基本在300000到400000之间小幅波动,基本处于水平状态。(由于篇幅的关系,此处就不列数据。
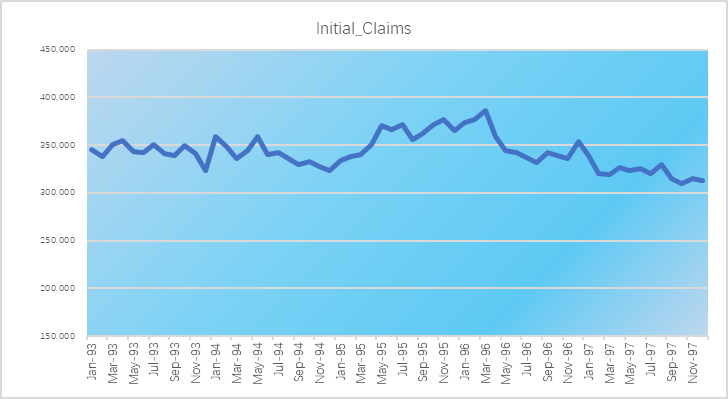
图三:初次索赔周平均次数: 失业人员在与雇主离职后提出的索赔。
那么,这样的水平时间序列,它的ACF相关系统是什么样的呢?
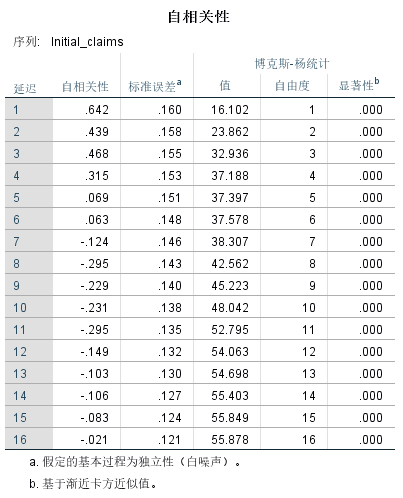
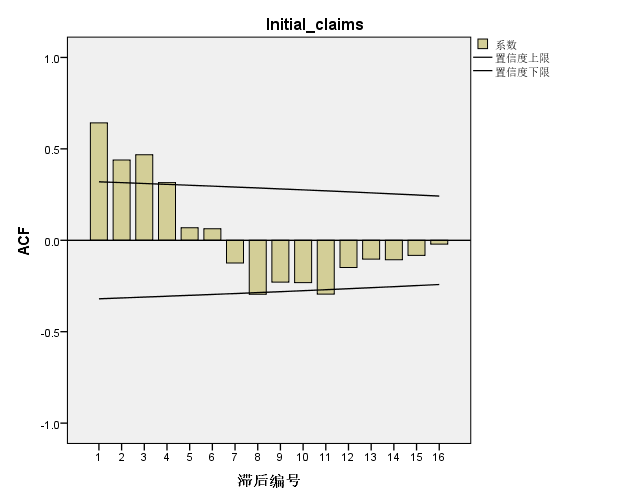
图四:Initial Claims的自相关性分析结果图
r1 = 0.642, r2 = 0.439, r3 = 0.468, r4 = 0.315, r5 = 0.069,….
我们可以看到它在经过三、四阶滞后k系数就接近于零,有些水平序列会在1到2阶滞后然后就很快就接近于零。其实这种现象叫截尾,而含有趋势的过程是非常缓慢的,缓慢逐渐趋向于零的现象叫拖尾,如我们前面提到的原油价格的ACF, 系数在8、9阶后才接近于0。
3. 如果是周期性或者季节性,则显著的自相关系数会呈现季节数或季节倍数的规律,如果是一年4个季度为季节变化,则滞后数k的变化规律是4的倍数,如果是以每个月为季节变化,则季节性滞后数k以12为倍数进行周期变化。
我们以下面的季节性的时间序列为例:
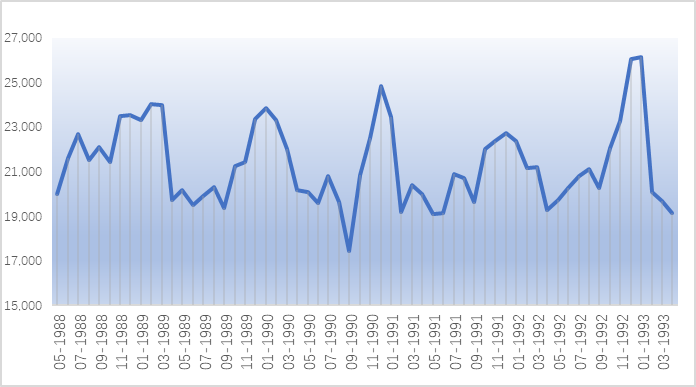
图五:季节性时间序列图
这是一个以12个月为周期的季节性时间序列,虽然数据并不十分规则(或未做清洗),但是我们还是能看到,每年的12月到第二年的1月是销售高峰,而4月份到9月份是相对低谷。
我们通过IPSS相关性分析计算得到的24阶的自相关系数如下表和图:
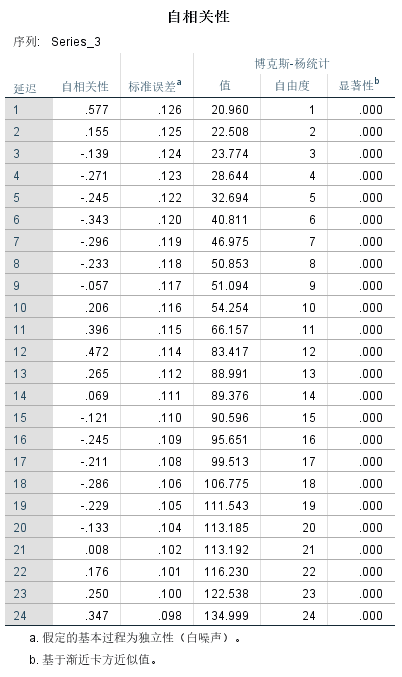
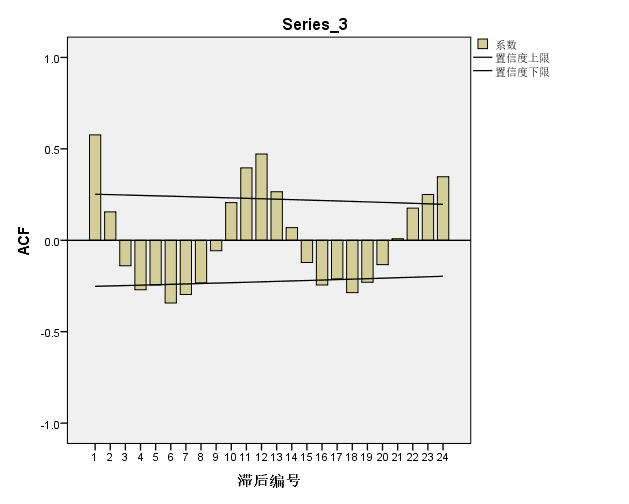
图五:季节模型的自相关性分析结果图
我们从左表,可以看到第1,11,12,13,23,24期是高峰,值最大,这是每年的11,12,1,2月份,而4-8期以及16到19期值最小,为负数,这是每年的4-9月份左右但是它们都远不等于0。
如果我们从右图观察可以看到,这就像是我们初中数学里所学的三角函数的正弦函数图,这是季节性时间序列的特点,我们可以根据这个图直观判断。
4. 有的时候,我们还需要判断这个时间序列是否这随机序列,随机序列又叫白噪声序列。如果一个序列是随机的, 时间序列的连续值彼此之间没有关联,其观测值Yt 与其任何时间滞后k 之间的自相关性都是接近于零的。
从统计学上来说,这个时间序列几乎所有的样本自相关系数都应该落在一个由零、正负一定数值的标准误差所指定的范围内,这个区间范围是,± tσ,即(-tσ, +tσ),这个系数t通常为+/-1.96,接近于2。而 σ = 1/ √𝒏,n为样本数量。
举例来说,如果样本数量 n=60, 其自相关函数标准差 σ=1/√𝟔𝟎 =0.129, 对于给定的概率F(t), 可以构造一个置信区间,若 n=60, 那么序列的自相关系数有95%落入 (-1.96*0.129,+1.96*0.129)区间, 即落入(-0.253, +0.253)区间内,也就是说,如果这个时间序列自相关函数全部落入这个区间内,那么可以断定该时间序列为完全随机序列。(-1.96σ,+ 1.96σ)也通常称为随机区间。
毫无疑问,如果我们不是统计专业出身,可能看这些文字描述,已经是云里雾里,晕头转向。不过没关系,我们举例来说明,下表是在EXCEL用随机函数生成的一组数值。
|
Period |
Value |
Period |
Value |
Period |
Value |
|
1 |
23 |
13 |
86 |
25 |
17 |
|
2 |
59 |
14 |
33 |
26 |
45 |
|
3 |
36 |
15 |
90 |
27 |
9 |
|
4 |
99 |
16 |
74 |
28 |
72 |
|
5 |
36 |
17 |
7 |
29 |
33 |
|
6 |
74 |
18 |
54 |
30 |
17 |
|
7 |
30 |
19 |
98 |
31 |
3 |
|
8 |
54 |
20 |
50 |
32 |
29 |
|
9 |
1 |
21 |
86 |
33 |
30 |
|
10 |
36 |
22 |
90 |
34 |
69 |
|
11 |
89 |
23 |
65 |
35 |
87 |
|
12 |
77 |
24 |
20 |
36 |
44 |
表二:由EXCEL随机函数自动生成的随机数列
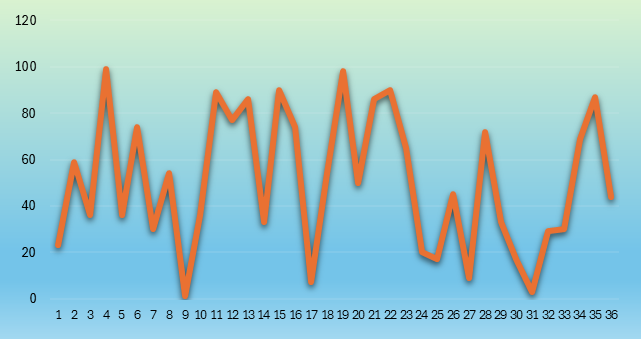
图六:由EXCEL随机函数自动生成的随机数列
我们用这组时间序列得到的ACF自相关系数值,和图如下:
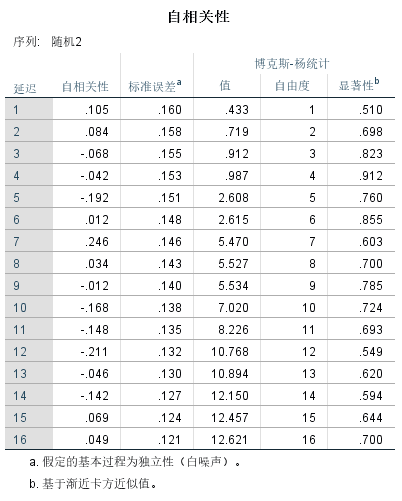
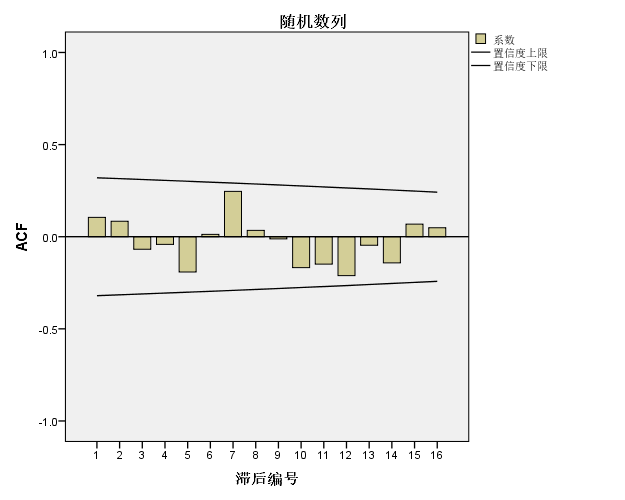
图七:随机数列的自相关性分析结果图
我们看到自相关系数从滞后第1阶开始就非常小,值为0.105, 最大的也不过0.246, 都非常接近于零,套用前面的概念,其随机区间为(-1.96σ,+ 1.96σ),而σ = 1/ √36 = 0.167,所以随机(-1.96*0.167,+1.96*0.167),得到的区间范围为(-0.327, +0.327),我们可以看到,所有的相关系数k都远远的小于这个区间值,落在这个区间范围内。也就说明了它是一个随机序列。同时在SPSS左边对白噪声的显著性b检验值列表中也可以看到,每个p已经远远大于0.05,也就是说无法拒绝该时间序列为白噪声的假设,亦即,它就是白噪声时间序列。对比其他形态的结果,我们可以看到其他时间序列都不为白噪声时间序列,也就是他们存在明显的自相关性。
自然,自相关系数的概念对我们没有接触过统计知识的人来说是有些复杂的,但是它又是重要的,如我在前面的文章提到的,特别是我们现实中,很多的时间序列并不规则,无法直接从图形直接判断,需要使用相关性分析和偏自相关性分析来制定合适的预测模型。
如我上期预测文章中提到的一些时间序列,如或者下面的时间序列:
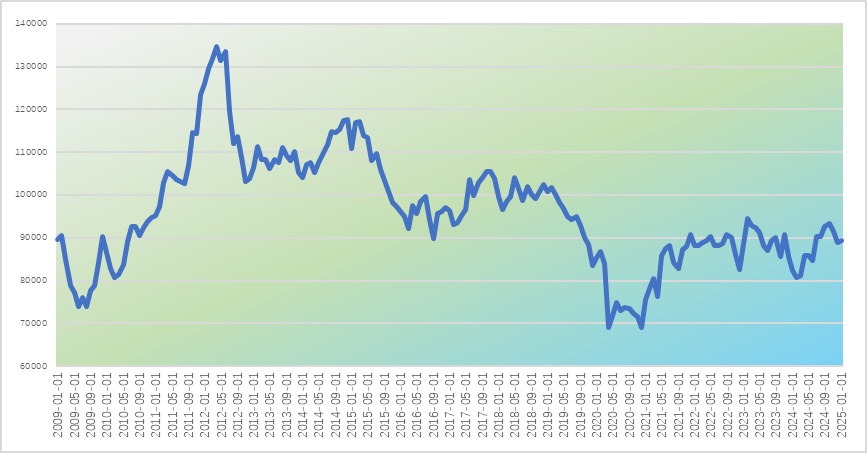
图八:制造业:耐用品 发动机、涡轮机及动力传动设备生产趋势图。
这样的时间序列都是不平稳的,我们也很难直观判断其是否存在季节性。
对于这种复杂的情况,可能需要使用复杂的预测技术,如博克思-詹金斯(Box-Jenkins) 技术,它就是需要根据自相关ACF函数的值,和偏自相关PACF的值,得到前面提到的拖尾,截尾情况进行分析,来选择相应的系数,进行预测。
博克思-詹金斯常用模型包括:自回归模型(AR模型)、移动平均模型(MA模型)、(自回归-移动平均混合模型)ARMA模型、(差分整合移动平均自回归模型)ARIMA(Autoregressive Integrated Moving Average)模型。对于不平稳的时间序列,还要选择差分,使系列平稳后再进行预测,季节性不平稳,要选择季节性差分。博克思-詹金斯(Box-Jenkins)方法是应对这种相对复杂的情况比较好的预测技术。
由于这些概念与方法相对复杂,也需要很多的篇幅,我在此不做过多展开,希望以后有机会专门介绍。
当然,做预测并不是使用的模型越复杂越好,觉得越高级,越让人觉得不明觉厉。
在预测界有一位大神,叫Spyros·Makridakis,说他是预测大神,并不是指他的预测技术有多厉害,模型研究的有多深,而是可以说他将统计预测应用到了商业领域第一人,他举办了多次的预测竞赛,M-Competition,也就是Makridakis Competition,用各种预测模型进行预测比赛,看看谁的方法更准确。 通过竞赛发现:
- 在统计上先进或复杂的方法不一定比简单的方法产生更准确的预测。简单的统计方法同样也可以举得很好的预测效果。
- 各种方法结合起来时的准确度,平均而言,超过了的单一的预测方法。
- 各种预测方法的性能取决于预测周期的长度和分析的数据类型(每年、每季度、每月)。一些方法在短期内更准确,而另一些方法则更适合于长期。有些方法对年度数据更有效,而其他方法更适合于季度和月度数据。
所以要做好预测,我们要先掌握和熟练数据形态,然后掌握一些基本的预测方法与模型,如移动平均,指数平滑的三种模型(简单,Holt趋势,Holt-Winters季节趋势)等,将这些方法灵活的应用到工作中。打好扎实的基础,在充分掌握基本功后,再来研究更高级的技术。但要掌握这些所谓简单的方法,我们也必须要经过专门的培训。
在介绍了数据形态之后,后面将陆续介绍一些简单的预测模型,如移动平均,指数平滑的三种模型(简单,Holt趋势,Holt-Winters季节趋势)、分解法等,这些传统的预测模型,容易上手,也可以不需要复杂的计算机语言,EXCEL就可以搞定,对于预测小白很多友好。
重点在于,让读者通过这些预测方法的介绍,明白不同场景该用何种预测方式,而不是单纯依赖算法和 AI,对结果的由来一无所知,更无法判断计算结果的优劣。这会埋下巨大隐患,错误的预测可能给商业带来严重风险。
因此,在把预测工作交给计算机和算法之前,我们必须先掌握预测方法、理解预测原理。尤其在 AI 与大模型快速发展、可替代人工预测的当下,如果连基础的预测知识都不具备,很可能会被 AI 彻底取代。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 15
15 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)