基于 AI Agent 的童话编剧与绘本生成器:近期工程改进说明(编剧 Agent尝试)
一些小改动:
1.我先按照项目说明书,补齐“八类目标接口”:(新增了workflow.py相关文件)
创建任务(主题接收)、查询进度(状态查询)、查询结果(结果返回)、触发导出(导出触发)、历史记录(最近20条)、参数配置读取/更新(先做了只读)、健康检查(已实现)、(可选)重试单页/重试任务。
2.并且实现 ZIP 导出真文件(浏览器可下载)

之后我就开始尝试实现编剧Agent:
第一次改进
核心目标可以概括为三条:
1. 配置稳定:无论从哪个目录启动后端,都能稳定读取 `backend/.env`;
问题:`pydantic-settings` 若使用相对路径 `env_file=".env"`,工作目录变化会导致读错或读不到文件。
改动:在 `backend/app/settings.py` 中,将 `env_file` 指向与 `settings.py` 同级的 `backend` 目录下的 `.env` 绝对路径(基于 `Path(__file__).resolve().parents[1] / ".env"`)。
同时在 `backend/.env.example` 中补充了百炼 “OpenAI 兼容模式” (老师的api_key没见消息,就自己先在这花钱买一个)的默认 `LLM_BASE_URL` 示例(华北 2 北京地域)。
2. 失败可见:模型未就绪或调用失败时直接报错,不再静默 mock;
mock 兜底是之前写后端的组员写的,但现在已经决定接入真实模型的阶段,更需要可观测的失败。
因此,我在 `Settings` 中新增布尔配置 `llm_strict_mode`,对应环境变量`LLM_STRICT_MODE`。现在,在 `backend/app/services/generation.py` 的 `StoryGenerationService.generate` 中: 当严格模式开启且 LLM 未就绪时,抛出明确错误;当严格模式开启且 LangChain 调用链异常时,不再捕获后回退 mock,而是抛出携带原因的异常。
效果:联调时若出现 403(例如模型未开通 / 无购买权限)、401、超时或解析失败,会在接口层表现为失败响应,而不是像之前那样悄悄返回模板文本。
3. 产品闭环:在原有静态创作页上增加“分步骤探索”对话能力,并把对话纪要并入生成参数,沿用既有工作流链路。
(1)新增了 `/api/v1/chat` 与静态页集成(实现对话能力)
(2)后端接口设计
新增路由前缀:`POST /api/v1/chat`
- 请求体:`{ "messages": [ { "role": "system|user|assistant", "content": "..." } ] }`
- 响应体:`{ "reply": "..." }`
实现上复用与绘本生成相同的 LLM 连接配置(`LLM_API_KEY` / `LLM_BASE_URL` / `LLM_MODEL_NAME`)。若请求中未包含 `system` 消息,服务会自动补一条“儿童绘本创意助手”风格的系统提示,以控制语气与长度。
(3)静态前端:`create.html` 的双模式
在 `storybook-ui-static/create.html` 中:
1. 一键魔法生成:保留原有选项卡式选题 + 补充说明 textarea;
2. 分步骤探索模式:展示场景/主角输入框、聊天记录、发送按钮;通过 `fetch` 调用 `/api/v1/chat`;
3. 点击“开始施展魔法吧!”时:将补充说明与对话纪要拼接进工作流提交的 `extra_prompt`,再走`/api/v1/workflows/submit-theme` → `dispatch`,后续仍由 `generating.html` 轮询状态并跳转阅读页。
对话记录使用浏览器 `localStorage`(键名 `storybook.chatMessages`)做简单持久化,避免刷新页面后对话丢失。
样式上在 `storybook-ui-static/styles.css` 中增加了对话区、输入行等基础样式,并与现有圆角、主色风格保持一致。
实现效果如下:
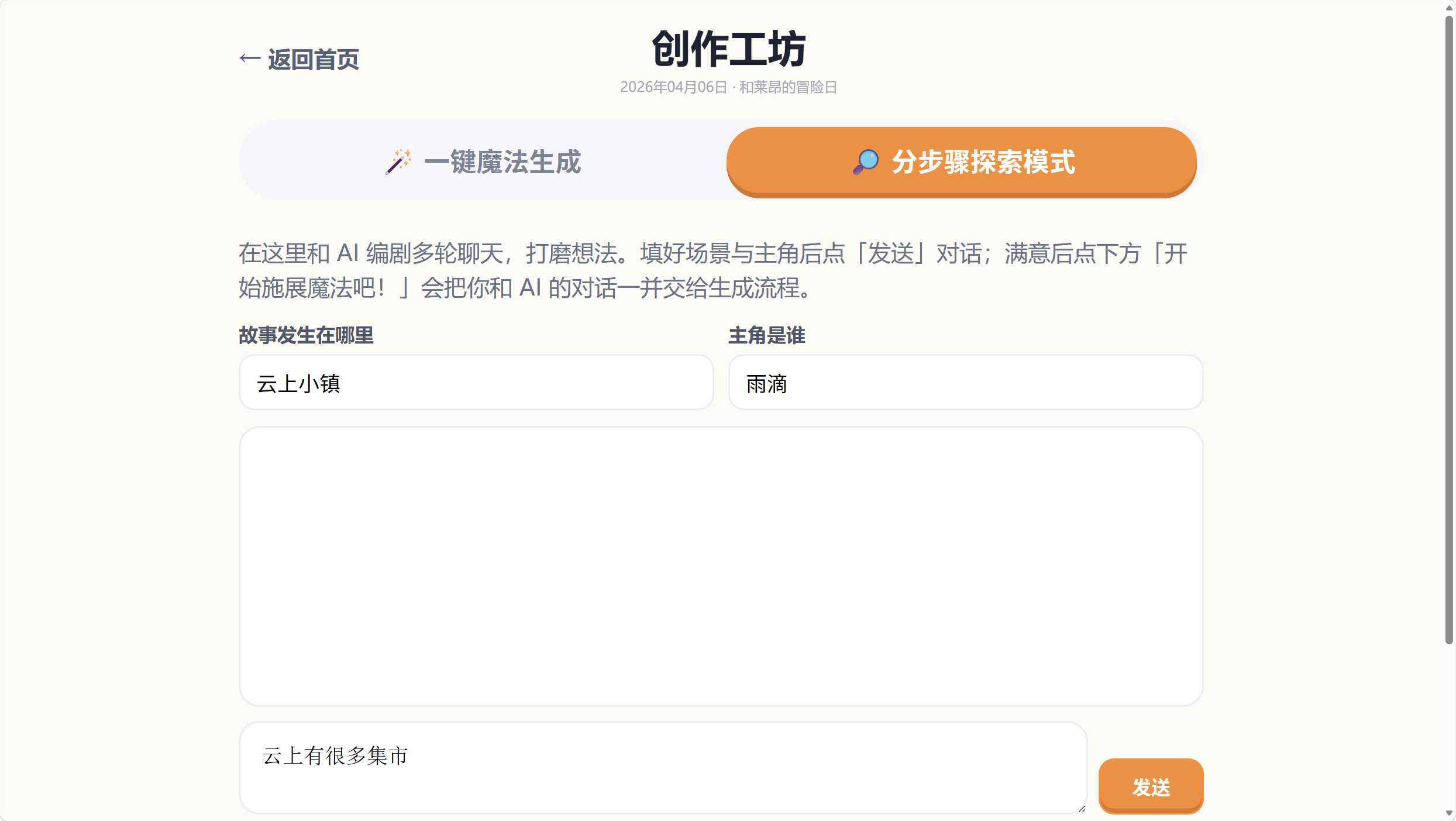
这里我输入故事的地点和主角,并写一句话开头。
等待界面

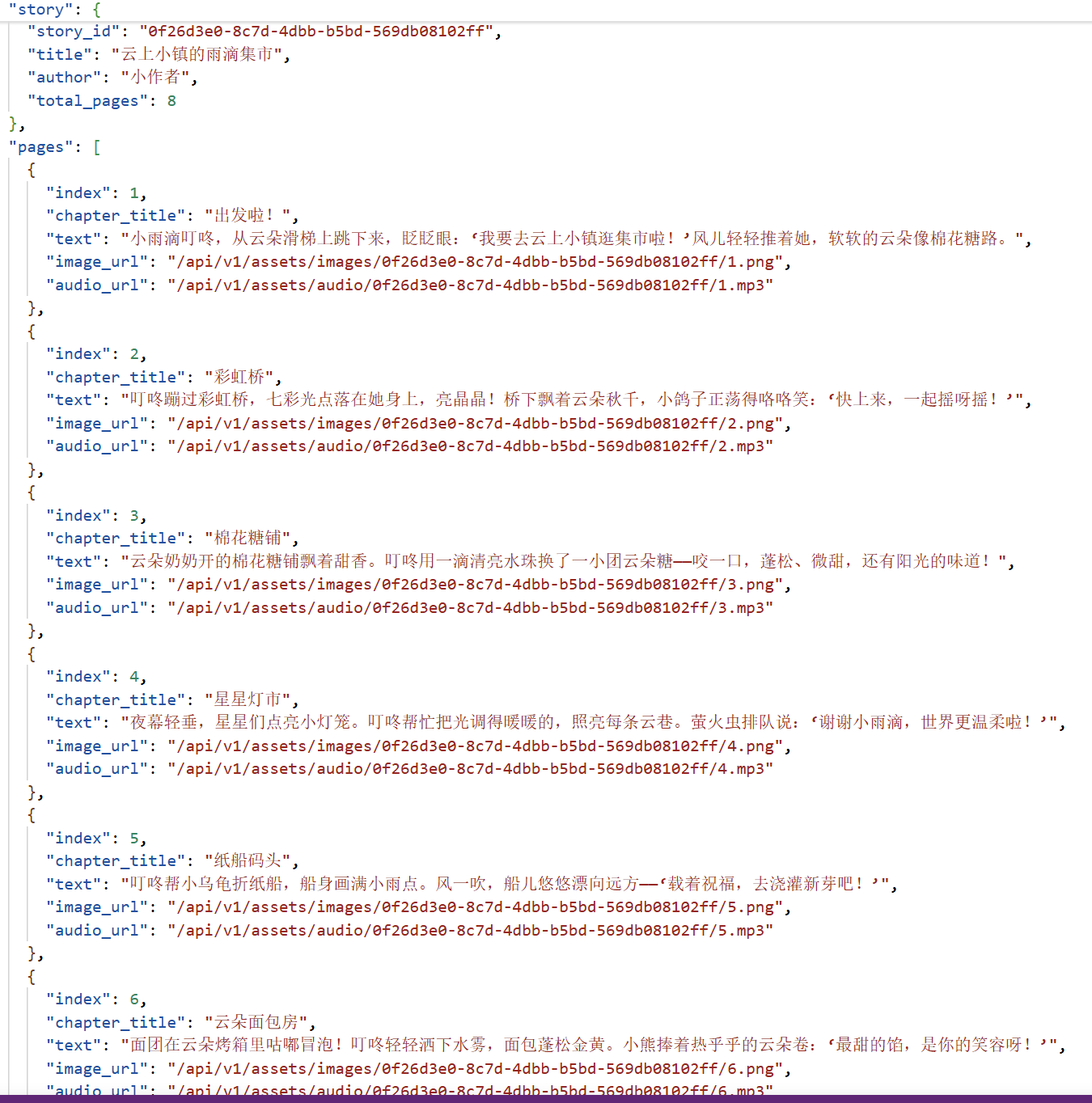
生成故事如下:(可翻页)
这是下载后的json文件,打开后看到每页故事的文本如下。
第二次改进
项目说明书对编剧环节的要求——“接收用户主题,调用大模型生成多页标准分镜脚本,每页包含页码、场景、角色动作、对话/旁白”,现在还缺少一眼可辨的“分镜脚本”文件,仅有 `text` 无法表达“分镜表”语义,也不利于后续“分镜 Agent / 绘图 Agent”只读脚本列。因此,我做了如下改动。
1.`backend/app/schemas/story.py`的`StoryPage` 的改动
增加: `scene`、`character_action`、`dialogue`、`narration`(默认值空字符串,便于旧缓存缺字段时仍反序列化);也保留 `chapter_title`、`index`、`image_url`、`audio_url`;
2.`backend/app/services/generation.py`的改动
(1)`StoryPageLLM`** 改为输出 **`chapter_title`、`scene`、`character_action`、`dialogue`、`narration`**,不再要求模型单独返回与分镜重复的 `text` 字段。
(2)提示词明确:输出「标准分镜脚本」JSON、页数与请求一致、每页必须含上述列,并限制旁白建议长度等。
(3) `_compose_reading_text`:由旁白与对白拼接 `StoryPage.text`,避免各处手写拼接规则。
(4) `_mock_pages`:按多镜模板填充分镜列,保证无 Key 或解析失败回退时,字段形态与真模型路径一致。
3.`backend/app/services/workflow.py`改动
(1)进入任务后先将阶段置为`script`,并通过`await asyncio.to_thread(self._generation.generate, job.payload)`在编剧阶段完成阻塞式生成,避免长时间占住事件循环。
(2)生成完成后,再依次短暂进入`storyboard`、`image`阶段文案(当前仍为占位:分镜整理、绘图后续可接文生图),最后`done`。
(3)`dispatch`入口仍将任务标为运行中,阶段与进度与上述流程一致。
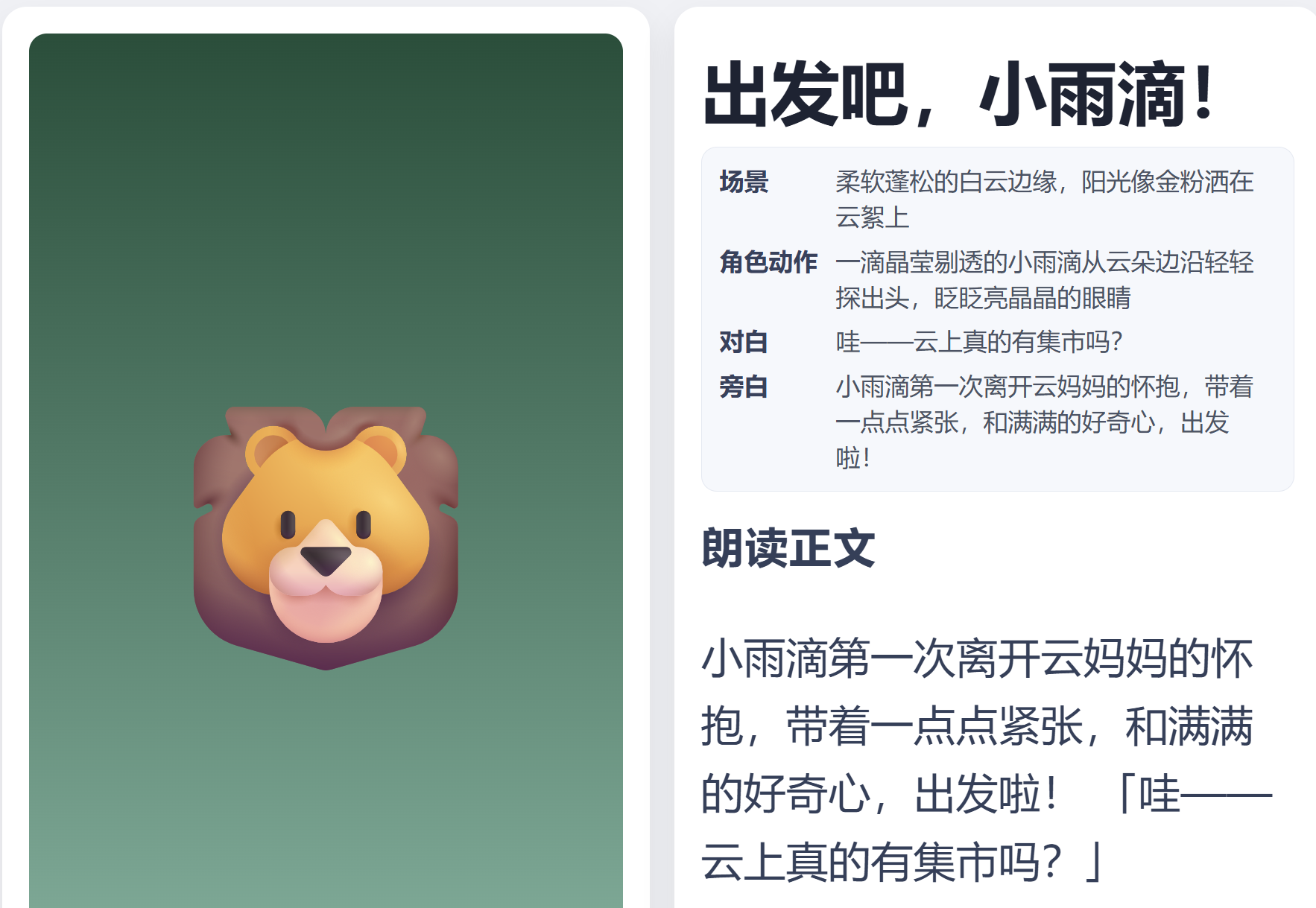
(4)最后,`backend/app/schemas/workflow.py`里`SubmitThemeRequest`的`extra_prompt` 曾限制`max_length=300`,将其改为10000,再稍加修改前端`storybook-ui-static/reader.html`和`storybook-ui-static/styles.css`,最终效果如下,成功实现了每页包含页码、场景、角色动作、对话/旁白”的功能。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)