OpenClaw核心概念解析:技能、工作流与Agent
OpenClaw核心概念解析:技能、工作流与Agent
很多工程团队在接触 AI Agent 框架时,最容易混淆三个词:Agent 是什么、Skill 放在哪里、Workflow 怎么编排。如果这三层概念没分清,系统很快会走向“提示词堆砌”“工具调用失控”或“流程无法复用”。
OpenClaw 的价值,恰恰在于它把这些概念拆得比较工程化:Agent 负责角色与长期状态,Skill 负责能力扩展,Workflow 负责步骤编排与审批执行。对研发同学来说,这种分层意味着更容易做多 Agent 分工、权限隔离、能力装配和故障恢复。
摘要
摘要:本文从工程实现角度拆解 OpenClaw 的 Agent、Skills 与 Workflow 三个核心概念,并结合官方文档与近期实践资料,说明它们如何协同构成一个可扩展、可审计、可复用的 AI 自动化系统。
OpenClaw 不是单纯“接一个大模型”的聊天壳,而是围绕 Gateway、Agent、Channels 组织系统入口,再由 Brain、Hands、Memory、Heartbeat 构成 Agent 的内部运行机制。[1][2]
在这个体系里:
- Agent 是核心实体,由 workspace 中的 Identity、Soul、Tools、Skills 等文件共同定义。[1]
- Skills 是能力边界的主要抽象,用 Markdown/YAML 形式描述触发条件、依赖工具和执行方式。[2][3]
- Workflow 则负责把任务从“一次回答”升级成“多步骤、可审批、可重复执行”的流程,OpenProse 是其代表。[4]
如果你要把 OpenClaw 用到代码研发、数据处理、科研自动化或运维协作,理解这三者的职责边界,比会不会写提示词更重要。
OpenClaw 的系统骨架:先理解 Agent 运行在什么架构里
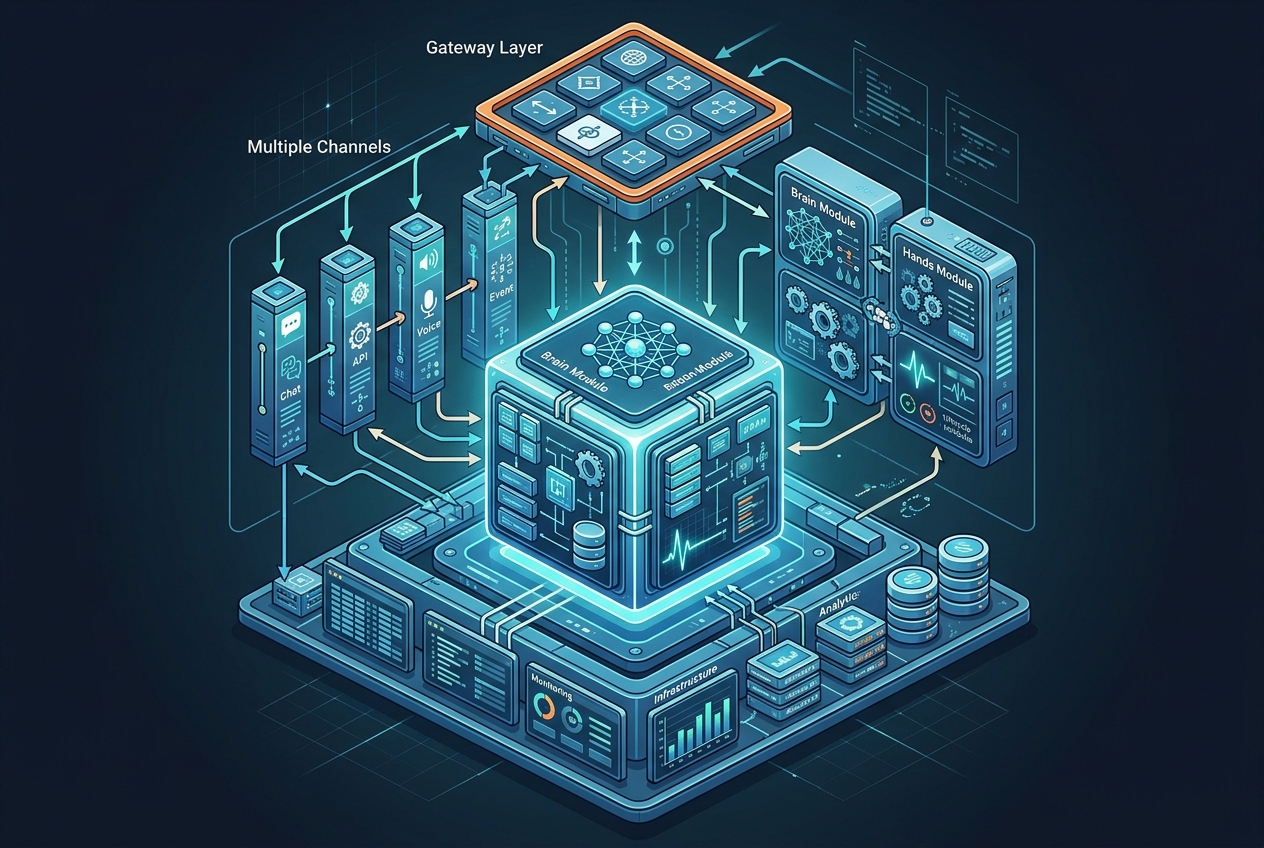
摘要:理解 OpenClaw,不能只盯着 Agent 本身,必须先知道它所处的整体系统结构。
根据官方文档,OpenClaw 的核心概念包括 Gateway、Agent、Channels。[1]
其中:
- Gateway:系统网关,负责与模型、本地或远程连接、入口配置等打交道。
- Channels:交互入口,例如不同会话源、命令入口或外部接入面。
- Agent:实际承担任务理解、决策、记忆、工具调用的主体。
在更细的内部结构上,OpenClaw Docs 又把 Agent 的工作拆成五部分:[2]
- Brain:负责推理与决策。
- Hands:负责调用工具,执行外部动作。
- Memory System:负责状态与持久化记忆。
- Heartbeat:周期性唤醒,推动自治执行。
- Gateway:承担系统入口与连接层角色。
这套分层有个很强的工程意义:
模型不是系统本身,模型只是 Brain 的一部分。
真正决定系统稳定性的,往往是:
- Skill 是否可装配
- Heartbeat 是否可控
- Memory 是否可审查
- Workflow 是否可恢复
这也解释了为什么 OpenClaw 更像一个“可配置的 Agent 操作系统”,而不是简单聊天应用。
Agent:不是一个提示词,而是一组可配置工作空间
摘要:在 OpenClaw 中,Agent 是通过 workspace 配置出来的独立个体,而不是一段孤立的 system prompt。
官方文档明确指出,Agent 是系统核心,其能力、记忆和交互风格由 workspace 中的一组文件共同决定,包括 Identity、Soul、Tools、Skills 等。[1]
CLI 引导也进一步说明:你可以通过初始化向导配置 Gateway、channels、skills 和 workspace 默认值,还可以通过 openclaw agents add <name> 创建独立 Agent;每个 Agent 都拥有自己的 workspace、sessions 和认证配置。[5]
这意味着 OpenClaw 的 Agent 有几个关键特征:
1. Agent 是一等公民
不是“同一个机器人换个 prompt”,而是真正独立的运行单元。
每个 Agent 可以有自己的:
- 身份设定
- 工具集
- 技能包
- 会话历史
- 认证与权限边界
这对多角色协作非常重要。比如:
research-agent负责检索与资料归纳code-agent负责代码修改与测试ops-agent负责告警处理与运维命令执行
2. Agent 的能力不是天然的,而是装配出来的
基础模型只提供通用对话能力,真正扩展到网页搜索、邮件发送、文件系统、外部服务操作,主要依赖 Skills。[3][9]
3. Agent 的长期行为依赖 Heartbeat 与 Memory
Heartbeat 会按周期读取 HEARTBEAT.md,检查待办,并决定下一步动作,使 Agent 具备一定自治能力。[2]
而 Memory 则通常以磁盘上的 Markdown 文件保存,便于人工查看和编辑。[9]
从工程实践看,Agent 更适合作为“职责边界”单位来设计,而不是把所有能力堆给一个超级 Agent。前者更易治理,后者更容易失控。
Skills:OpenClaw 的能力边界与扩展机制
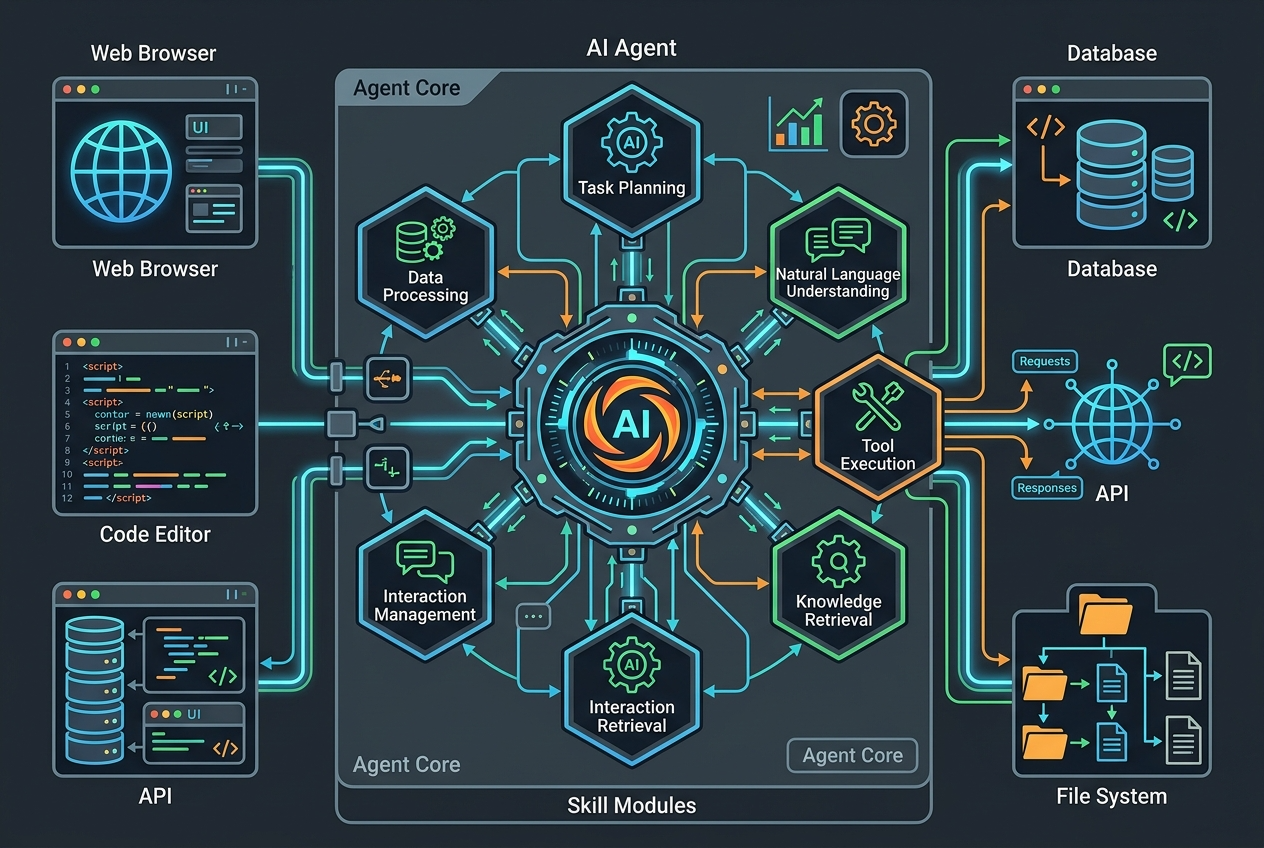
摘要:Skill 是 OpenClaw 中最关键的扩展抽象,决定 Agent 到底“能做什么”。
官方技能总览把 Skills 描述为赋予 OpenClaw Agent“超能力”的基本构件。[3]
也就是说,没有 Skill,Agent 更像一个能说会想的对话体;有了 Skill,它才真正具备操作真实世界的能力,比如:
- 网页搜索
- 邮件发送
- 智能家居控制
- 图像生成
- 文件系统操作
- 浏览器交互
Skill 的定义方式
根据 Core Concepts 文档,Skills 通常以带 YAML frontmatter 的 Markdown 文件定义,里面包含触发条件、所需工具和执行方式。[2]
这种设计非常适合工程团队:
- 可读:Markdown 对人类友好
- 可审:配置和说明能放一起
- 可版本化:直接纳入 Git
- 可筛选:便于做环境兼容判断
TechRadar 的近期文章补充了一个很实用的运行机制:OpenClaw 启动时会扫描技能目录,并在加载阶段过滤掉当前环境无法运行的技能;SKILL.md 可携带环境变量、系统二进制、操作系统支持等元数据。[6]
Skill 的作用边界
Skill 最适合承载以下内容:
- 某类操作能力的封装
- 与外部系统交互的约束
- 工具调用的固定模式
- 对模型暴露的“安全能力面”
不适合放进 Skill 的内容:
- 复杂跨阶段审批流
- 多 Agent 协调策略
- 长周期业务状态机
这些更适合 Workflow 层处理。
Skill 的部署范围
根据资料,Skill 既可以限定在单个 Agent 的 workspace 内,也可以共享到 ~/.openclaw/skills,供多个 Agent 复用。[6]
一个实践建议是:
- 共性能力放共享 skills:如 git、search、browser
- 领域能力放 Agent 私有 workspace:如内部系统操作、特定业务流程
这样能兼顾复用与隔离。
Workflow:从“会用工具”到“能完成交付”
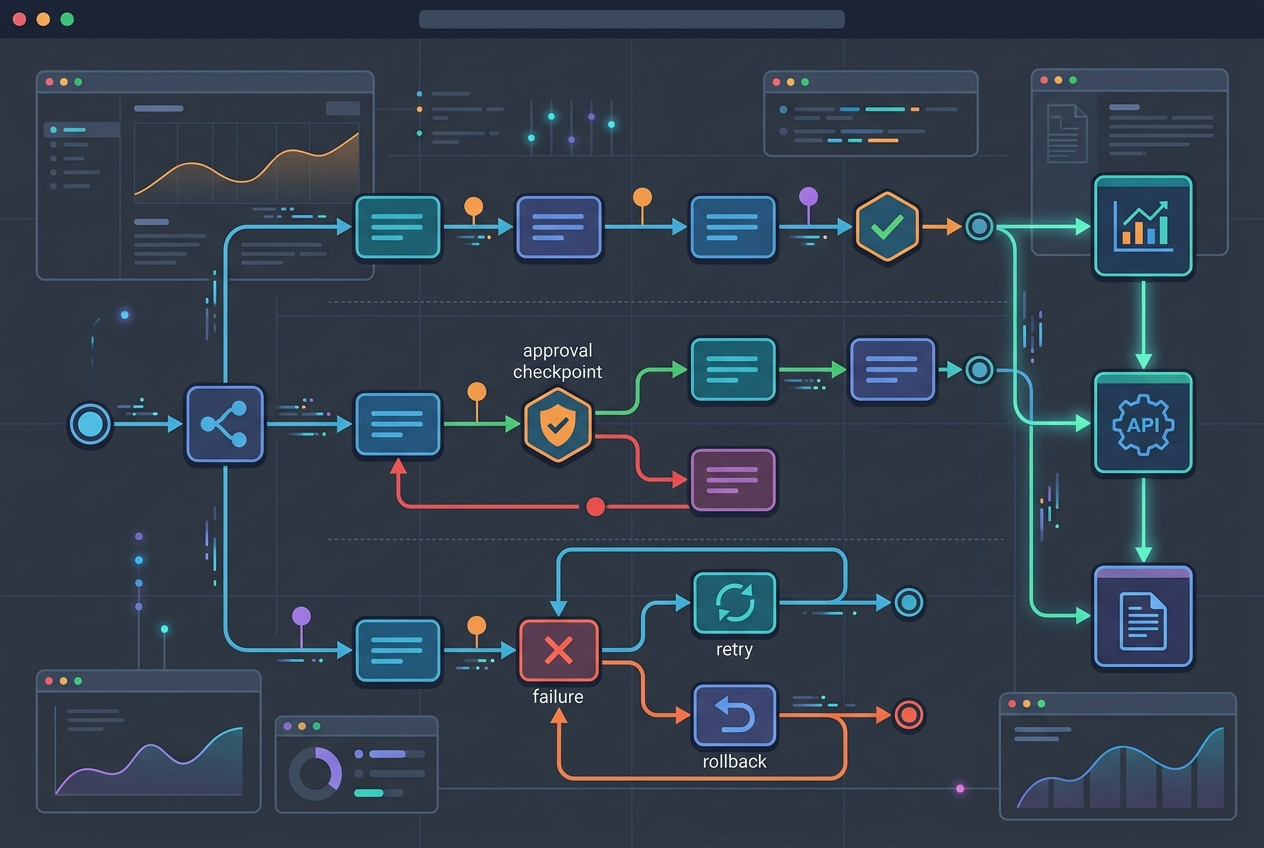
摘要:Workflow 解决的是任务编排问题,它让 Agent 能按步骤、按约束、按审批去完成复杂目标。
很多团队做 Agent 系统时,第一阶段都停在“会调用工具”。但工程交付真正需要的是:
- 分步骤执行
- 中间结果沉淀
- 审批节点
- 可恢复重试
- 可重复复用
这就是 Workflow 的价值。
官方 OpenProse 文档指出,OpenProse 是 markdown-first 的工作流格式,用于编排 AI 会话;它以插件形式接入 OpenClaw,安装后会带来 OpenProse skill pack 和 /prose 命令。[4]
OpenProse 的核心能力包括:[4]
- 多 Agent 并行研究与综合
- 可复用的
.prose程序 - 更适合审批和重复执行的工作流编排
这说明在 OpenClaw 体系里,Workflow 不是“额外脚本”,而是正式的一层编排能力。
Workflow 最适合的场景
- 研究与报告生成:检索、归纳、交叉验证、输出文档
- 代码交付:分析需求、制订计划、审批、开发、测试、提交
- 运维处理:监控触发、诊断、执行、复核、记录
- 科研自动化:规划、调用领域工具、失败恢复、结果提取
arXiv 论文中的计算化学案例就是典型例子:采用解耦的 agent-skill 设计,由 planning skills 将科学目标转成任务规范,再由 domain skills 封装具体计算流程,并支持跨工具执行与运行时失败恢复。[7]
一句话总结:
Skill 决定“能做什么动作”,Workflow 决定“按什么顺序把动作串成结果”。
Agent、Skill、Workflow 如何协同设计
摘要:三者不是并列关系,而是从职责、粒度到复用方式都不同的三层架构。
在实际系统设计里,可以把三者理解成下面的关系:
- Agent:谁来负责
- Skill:他能做什么
- Workflow:这件事如何推进到完成
一个工程上更稳的设计方式是三层拆分:
第一层:Agent 负责职责边界
例如:
- 文档 Agent:偏检索、写作、知识归纳
- 代码 Agent:偏代码修改、测试、提交
- 领域 Agent:偏某行业工具和术语
第二层:Skill 负责动作封装
例如:
web_searchbrowser_extractgit_commitsend_emailrun_simulation
第三层:Workflow 负责交付路径
例如一个“生成并发布技术博客”的流程:
- 收集资料
- 结构化大纲
- 生成初稿
- 人工审批
- 修订
- 输出 Markdown
- 发布或提交
GitHub 项目 openclaw-code-agent 也体现了这种思想:它在底层执行 harness 之上,增加 plan approval、wake routing、session lifecycle、worktree/merge/PR policy 等能力,本质上就是把“可执行能力”提升为“可治理流程”。[8]
因此,一个很实用的经验是:
- 不要把流程规则塞进 Skill
- 不要把具体工具耦合进 Agent 人设
- 不要让 Workflow 直接感知底层实现细节过多
这样后续替换模型、增删工具、调整流程时,成本最低。
Key Comparison Table
摘要:下面这张表帮助你在工程实践中判断该把能力放在 Agent、Skill 还是 Workflow 层。
| Dimension | Agent | Skill | Workflow/OpenProse | 工程建议 |
|---|---|---|---|---|
| 核心职责 | 定义角色、记忆、交互风格与权限边界 | 封装具体能力与工具调用方式 | 编排多步骤任务、审批与复用流程 | 先定 Agent,再装 Skill,最后编排 Workflow |
| 典型载体 | workspace 文件,如 Identity、Soul、Tools、Skills | 带 YAML frontmatter 的 Markdown 技能文件 | .prose 程序或类似工作流描述 |
三层都纳入版本控制 |
| 变更频率 | 中低,偏长期稳定 | 中高,随工具和环境变化 | 中高,随业务流程调整 | 流程变化通常比角色设定更频繁 |
| 复用粒度 | 面向一个完整角色 | 面向一个能力模块 | 面向一类可重复任务 | 通用 Skill 共享,领域 Workflow 私有化 |
| 失败影响面 | 影响整个 Agent 行为与风格 | 影响单个能力是否可用 | 影响任务是否能完整交付 | 优先保证 Skill 可降级、Workflow 可恢复 |
| 安全控制点 | 认证、权限、会话隔离 | 环境变量、系统依赖、OS 支持约束 | 审批节点、执行顺序、人工确认 | 高风险操作放到 Workflow 审批环节 |
| 适合解决的问题 | “谁来做” | “能做什么” | “怎么一步步做完” | 用职责边界避免概念混装 |
实战代码示例
摘要:下面用一个简化示例展示 Skill 定义和 Workflow 编排的基本思路,重点看结构而不是具体语法细节。
示例 1:一个简化的 Skill 定义
---
# 技能元数据:声明名称、适用环境和依赖
name: web_research
description: 执行网页检索并输出结构化摘要
os: [linux, macos]
requires:
binaries: [curl]
env: []
triggers:
- 用户请求资料调研
tools:
- browser
- filesystem
---
# 用途
当任务需要收集外部信息时,执行检索、提取和摘要。
# 执行步骤
1. 使用 browser 或网络工具获取信息
2. 抽取关键段落并去重
3. 输出结构化摘要与来源列表
# 输出要求
- 给出结论摘要
- 附带引用来源
- 标注不确定信息
上面这个结构对应了文档里提到的技能定义思路:Markdown + YAML frontmatter,把触发条件、依赖和执行说明放在一起。[2][6]
示例 2:一个面向博客交付的简化 Workflow
# 工作流示例:将“写文章”拆成可审批的多步骤任务
name: blog_post_delivery
goal: 生成一篇可发布的 OpenClaw 技术文章
steps:
- id: collect_sources
# 步骤1:收集资料并整理要点
agent: research-agent
skill: web_research
output: sources_summary.md
- id: draft_outline
# 步骤2:基于资料生成文章大纲
agent: writing-agent
input: sources_summary.md
output: outline.md
- id: human_approval
# 步骤3:人工审批,避免错误方向继续放大
type: approval
input: outline.md
- id: write_article
# 步骤4:生成初稿
agent: writing-agent
input: outline.md
output: article_draft.md
- id: final_review
# 步骤5:最终检查格式、引用和发布要求
agent: editor-agent
input: article_draft.md
output: final_article.md
这个例子体现的是 OpenProse/OpenClaw 工作流思想:[4]
- 把任务拆成阶段
- 每阶段指定角色
- 中间产物显式化
- 关键节点加审批
- 最终结果可重复执行
如果你在团队中推进落地,建议先从这种半自动、带审批的工作流开始,而不是一步到位做全自治。
代码块注释规范
摘要:技术博客里的代码块不是越长越好,关键是让读者快速看懂意图、关键步骤和可修改点。
下面给出 4 条实用规则:
-
每个代码块开头说明目的
例如“定义 Skill 元数据”“演示工作流步骤拆分”,避免读者只见语法不知用途。 -
只注释关键步骤,不逐行翻译代码
注释应该解释“为什么这么做”,而不是把代码原样复述一遍。 -
对可变项加注释
如环境变量、Agent 名称、依赖工具、审批节点等,明确哪些地方需要按项目调整。 -
把风险点写在注释里
比如“此步骤涉及外部系统写操作,需要审批”“该二进制依赖仅在 Linux 可用”。
在 CSDN 这类工程博客里,好的代码块注释能直接提升文章可复现性,也更符合团队内部知识库的写作习惯。
常见问题与排错
摘要:OpenClaw 在工程落地中最常见的问题,不是模型回答差,而是装配、权限和流程层的配置不一致。
1. Skill 没有被加载
先检查技能目录位置是否正确,其次看 Skill 元数据中的 OS、环境变量、系统二进制依赖是否满足。近期资料指出,OpenClaw 会在加载阶段过滤掉当前环境不支持的技能。[6]
2. 同一个任务不该由一个 Agent 全包
如果发现 Agent 既做检索、又做写作、还做代码提交,通常说明职责边界设计过粗。应拆成多个 Agent,并通过 Workflow 协作。[1][5]
3. Agent 看起来“失忆”
先检查 Memory 是否正确持久化到磁盘文件,再确认当前会话是否使用了正确 workspace。资料指出持久记忆通常以 Markdown 文件形式保存在磁盘上。[9]
4. Heartbeat 导致行为不可控
Heartbeat 具备周期性检查与行动能力,适合自治任务,但不适合高风险写操作默认开启。应把关键动作放入带审批的 Workflow。[2][4]
5. Workflow 能跑,但结果质量不稳定
通常不是流程本身有问题,而是中间产物定义不清。建议把每一步的输入、输出、验收标准写得更明确,尤其是摘要格式、引用要求和审批条件。[4][7]
结语:工程落地时,先分层,再扩展,再自动化
摘要:OpenClaw 的真正价值,不在“会不会调用模型”,而在能否把 Agent、Skill、Workflow 组织成稳定系统。
如果你准备在项目里引入 OpenClaw,建议按下面顺序推进:
- 先定义 Agent 边界:谁负责什么,权限怎么隔离
- 再补齐 Skills:把高频能力做成可复用模块
- 最后设计 Workflow:把复杂任务流程化、可审批、可重试
对于大多数团队,最合适的起步方式不是“全自动 Agent”,而是:
- 多 Agent 分工
- 小步可控的 Skill 扩展
- 带人工确认的 Workflow 编排
这样既能获得自动化收益,又能避免系统在早期阶段失控。
参考资料
-
Documentation – OpenClaw - Open Source AI Assistant
https://openclawcn.com/en/docs/ -
Core Concepts | OpenClaw Docs
https://clawdocs.org/getting-started/core-concepts/ -
Skills Overview | OpenClaw
https://openclawdoc.com/docs/skills/overview/ -
OpenProse - OpenClaw
https://docs.openclaw.ai/prose -
Onboarding (CLI) - OpenClaw
https://docs.openclaw.ai/start/wizard -
What are OpenClaw Skills? A detailed guide | TechRadar
https://www.techradar.com/pro/what-are-openclaw-skills-a-detailed-guide -
Automating Computational Chemistry Workflows via OpenClaw and Domain-Specific Skills
https://arxiv.org/abs/2603.25522 -
GitHub - goldmar/openclaw-code-agent · GitHub
https://github.com/goldmar/openclaw-code-agent -
How to safely experiment with OpenClaw | TechRadar
https://www.techradar.com/pro/how-to-safely-experiment-with-openclaw

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 5
5 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)