【2026】YOLOv11 Demystified: A Practical Guide to High-Performance Object Detection
YOLOv11 Demystified: A Practical Guide to High-Performance Object Detection
论文解读
一、基本信息
| 项目 | 内容 |
|---|---|
| 英文论文名 | YOLOv11 Demystified: A Practical Guide to High-Performance Object Detection |
| 中文论文名 | YOLOv11解密:高性能目标检测实用指南 |
| 论文链接 | https://arxiv.org/abs/2604.03349 |
| 代码链接 | https://github.com/ultralytics/ultralytics (基于Ultralytics YOLO开源框架) |
| 作者 | Nikhileswara Rao Sulake (Rajiv Gandhi University of Knowledge Technologies) |
| 发表时间 | 2026年4月3日 |
| 所属领域 | 计算机视觉与模式识别 (cs.CV) |
| 会议信息 | CVC 2026 conference |
二、摘要分析
2.1 论文核心摘要
YOLOv11是YOLO(You Only Look Once)系列实时目标检测器的最新迭代版本,引入了新颖的架构模块来改进特征提取和小目标检测性能。本论文对YOLOv11进行了全面深入的分析,涵盖其骨干网络(Backbone)、颈部网络(Neck)和检测头(Head)三大核心组件。
2.2 关键技术特性
核心创新模块:
-
C3K2模块(Cross Stage Partial with 3×3 Kernels)
- 采用更小的3×3卷积核,显著提升计算效率
- 优化了跨阶段部分连接,提升梯度流
-
SPPF模块(Spatial Pyramid Pooling - Fast)
- 快速空间金字塔池化,高效捕获多尺度上下文信息
- 保持实时推理能力的同时增强特征融合
-
C2PSA模块(Cross Stage Partial with Spatial Attention)
- 引入位置敏感注意力机制
- 强化对重要空间区域的特征响应
- 显著提升小目标和遮挡目标的检测能力
2.3 性能亮点
- 精度提升:在COCO数据集上实现更高的平均精度均值(mAP)
- 速度保持:维持YOLO系列标志性的实时检测速度
- 应用场景:适用于自动驾驶、视频监控、视频分析等对速度和精度都有较高要求的领域
三、研究现状
3.1 YOLO系列发展历程
YOLO系列作为目标检测领域的里程碑式算法,经历了从2016年至今的多次重大迭代:
| 版本 | 年份 | 核心创新 | 性能指标 |
|---|---|---|---|
| YOLOv1 | 2016 | 单次前向传播检测范式 | 45 FPS (Titan GPU) |
| YOLOv2 | 2016 | 锚框机制、批量归一化、联合训练 | 支持9000类别检测 |
| YOLOv3 | 2018 | Darknet-53骨干网、多尺度特征融合 | 28ms/图 (320×320) |
| YOLOv4 | 2020 | CSPDarknet53、Mosaic数据增强、CIoU损失 | 65 FPS, 43.5% AP (V100) |
| YOLOv5-10 | 2020-2023 | 训练流程优化、多种变体(无锚框、动态头等) | 持续迭代优化 |
| YOLOv11 | 2024 | C3K2、SPPF、C2PSA模块 | 更高mAP,更低参数量 |
3.2 现有技术挑战
尽管YOLO系列取得了巨大成功,但仍存在以下技术挑战:
- 小目标检测困难:小尺寸目标由于特征信息不足,检测精度较低
- 遮挡目标处理:目标被部分遮挡时,容易出现漏检或误检
- 速度与精度权衡:更深更宽的网络带来更高精度,但也增加推理延迟
- 特征表示能力:需要更强大的特征提取器来捕获复杂场景信息
3.3 YOLOv11的技术定位
YOLOv11针对上述挑战提出了系统性解决方案:
- C3K2模块:通过更高效的卷积操作,在减少参数量的同时保持特征提取能力
- C2PSA注意力机制:显式建模空间重要性,增强对困难样本的关注
- 增强型SPPF:优化多尺度特征融合效率
四、创新点分析
4.1 架构层面的创新
4.1.1 C3K2模块设计
C3K2(Cross Stage Partial with 3×3 Kernels 2)是YOLOv11的核心构建模块,相比YOLOv8的C2F模块具有以下优势:
设计特点:
1. 起始和结尾各有一个卷积块
2. 中间使用多个C3K块串联处理
3. 将卷积块输出与最后一个C3K块输出进行拼接
4. 使用3×3小卷积核替代更大的卷积核
核心优势:
- 参数量减少:3×3卷积核比更大的卷积核参数更少
- 计算效率提升:小卷积核计算量更小,适合实时应用
- 特征提取能力保持:通过堆叠多个小卷积核,保持感受野和特征提取能力
4.1.2 C2PSA注意力模块
C2PSA(Cross Stage Partial with Partial Spatial Attention)引入了轻量级注意力机制:
结构设计:
1. 使用两个PSA(部分空间注意力)模块并行处理
2. 每个PSA模块独立处理特征图的一个分支
3. 最后将两个分支的输出拼接
4. 保持CSP结构的梯度流优势
核心优势:
- 空间注意力建模:显式学习图像中重要区域的空间权重
- 小目标增强:使网络更加关注小尺寸和遮挡目标
- 计算开销可控:轻量化设计,不显著增加推理延迟
4.1.3 SPPF模块优化
快速空间金字塔池化模块继承自YOLOv8并进行了优化:
- 并行使用多个不同大小的最大池化操作
- 捕获不同尺度的上下文信息
- 通过"Fast"设计减少延迟开销
- 确保小目标和大目标都能被有效检测
4.2 训练策略创新
- SiLU激活函数:使用Sigmoid Weighted Linear Unit替代ReLU,改善梯度流
- 残差连接:Bottleneck块中的shortcut连接,缓解梯度消失问题
- CSP结构:Cross Stage Partial连接优化信息流动
4.3 性能对比创新
论文提供了详尽的性能对比:
| 模型 | 输入尺寸 | mAP 50-95 | CPU速度(ms) | GPU速度(ms) | 参数量 | FLOPs(B) |
|---|---|---|---|---|---|---|
| YOLOv5n | 640 | 34.3 | 73.6 | 1.06 | 2.6M | 7.7 |
| YOLOv8n | 640 | 37.3 | 80.4 | 0.99 | 3.2M | 8.7 |
| YOLOv9n | 640 | 38.3 | NA | NA | 2.0M | 7.7 |
| YOLOv11n | 640 | 39.5 | 56.1 | 1.50 | 2.6M | 6.5 |
| YOLOv11s | 640 | 47.0 | 90.0 | 2.50 | 9.4M | 21.5 |
关键发现:
- YOLOv11n相比YOLOv8n,mAP提升2.2个百分点
- 参数量相当的情况下,CPU推理速度提升约30%
- FLOPs降低约25%,计算效率显著提升
五、数据集分析
5.1 主要评测数据集
5.1.1 COCO数据集
COCO(Common Objects in Context)是目标检测领域最权威的基准数据集:
- 数据规模:包含超过33万张图像,80个目标类别
- 评测指标:
- mAP@IoU[0.5:0.95]:多IoU阈值下的平均精度
- mAP@IoU[0.5]:单一IoU阈值的平均精度
- Precision(精确率):预测正确的目标占总预测的比例
- Recall(召回率):预测正确的目标占真实目标的比例
- F1-score:精确率和召回率的调和平均
5.1.2 评测设置
| 配置项 | 设置 |
|---|---|
| 输入分辨率 | 640×640像素 |
| 评估设备 | CPU (ONNX)、GPU (T4 TensorRT) |
| IoU阈值 | 0.5-0.95 |
| 预训练模型 | ImageNet分类预训练 |
5.2 定性评估样本
论文提供了丰富的定性检测结果:
- 马匹检测:置信度0.95,精确边界框定位
- 大象检测:自然场景下置信度0.93
- 交通场景:密集交通中多类别目标(车辆、行人)检测
六、算法结构分析
6.1 整体架构
YOLOv11遵循经典的三段式设计:
输入图像 → Backbone → Neck → Head → 检测输出
6.2 骨干网络(Backbone)
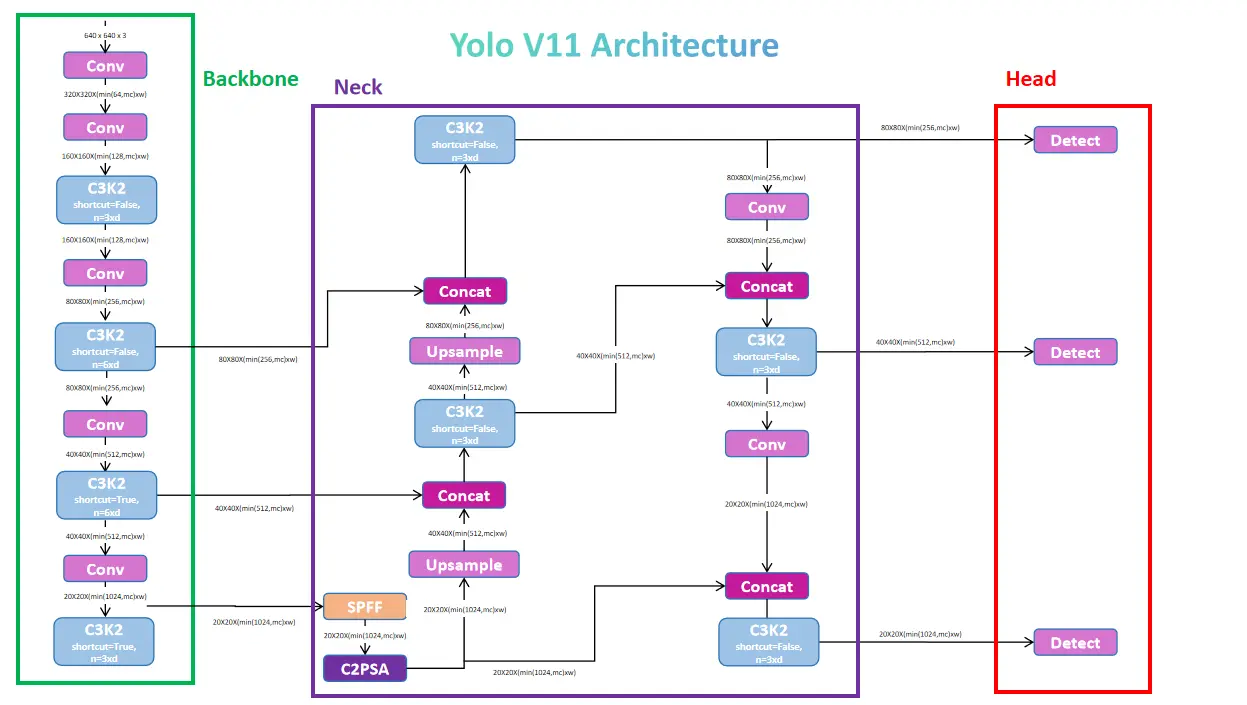
架构组成:
- Focus层:初始特征提取
- C2F模块:浅层特征处理
- C3K2模块:核心特征提取(中深层)
- Conv模块:特征调制
- C2PSA模块:注意力增强(深层)
设计原则:
- 渐进式降低特征图分辨率
- 逐层增加通道数,提取更抽象的特征
- 残差连接确保深层网络可训练性
6.3 颈部网络(Neck)
颈部网络负责多尺度特征融合:
- SPPF模块:并行多尺度池化,捕获全局上下文
- 上采样+拼接:融合不同深度的特征图
- PANet风格路径聚合:自底向上的特征增强
6.4 检测头(Head)
采用单阶段检测范式,直接输出:
- 目标置信度
- 类别概率
- 边界框回归参数
6.5 核心模块详细解析
6.5.1 Bottleneck块设计
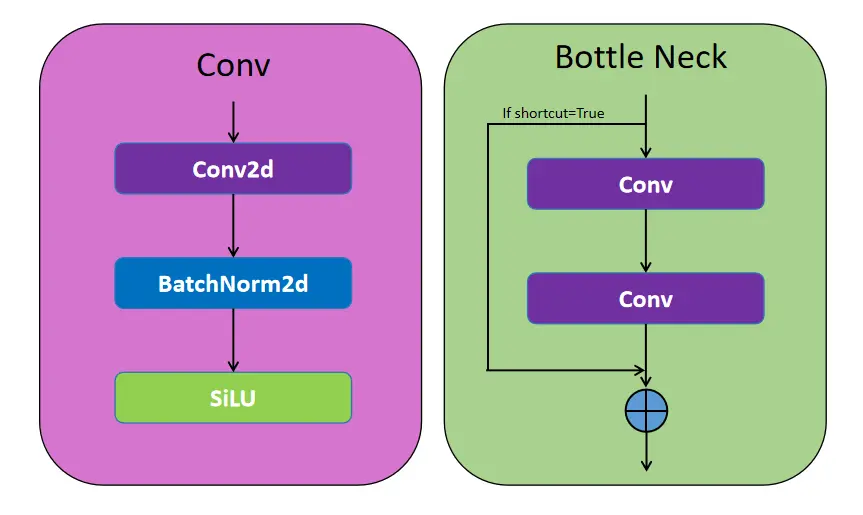
Bottleneck块借鉴ResNet思想:
结构:Conv-BN-SiLU → 多个Conv层 → 残差相加
特点:
- shortcut=True时启用残差连接
- 缓解深层网络的梯度消失问题
- 支持更深的网络结构训练
6.5.2 激活函数对比
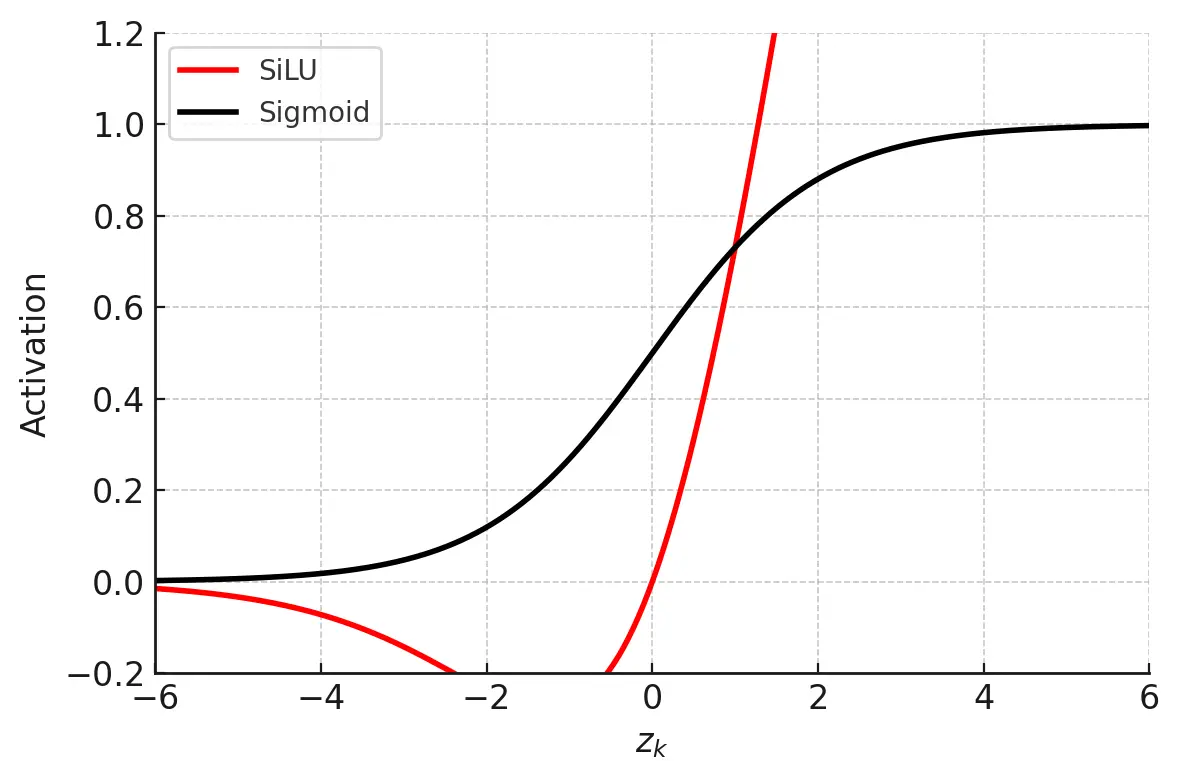
SiLU(Sigmoid Weighted Linear Unit)特性:
- 平滑非线性
- 自门控机制
- 训练稳定性优于ReLU
- 数学表达式:x · σ(x)
6.5.3 C3K2 vs C2F对比
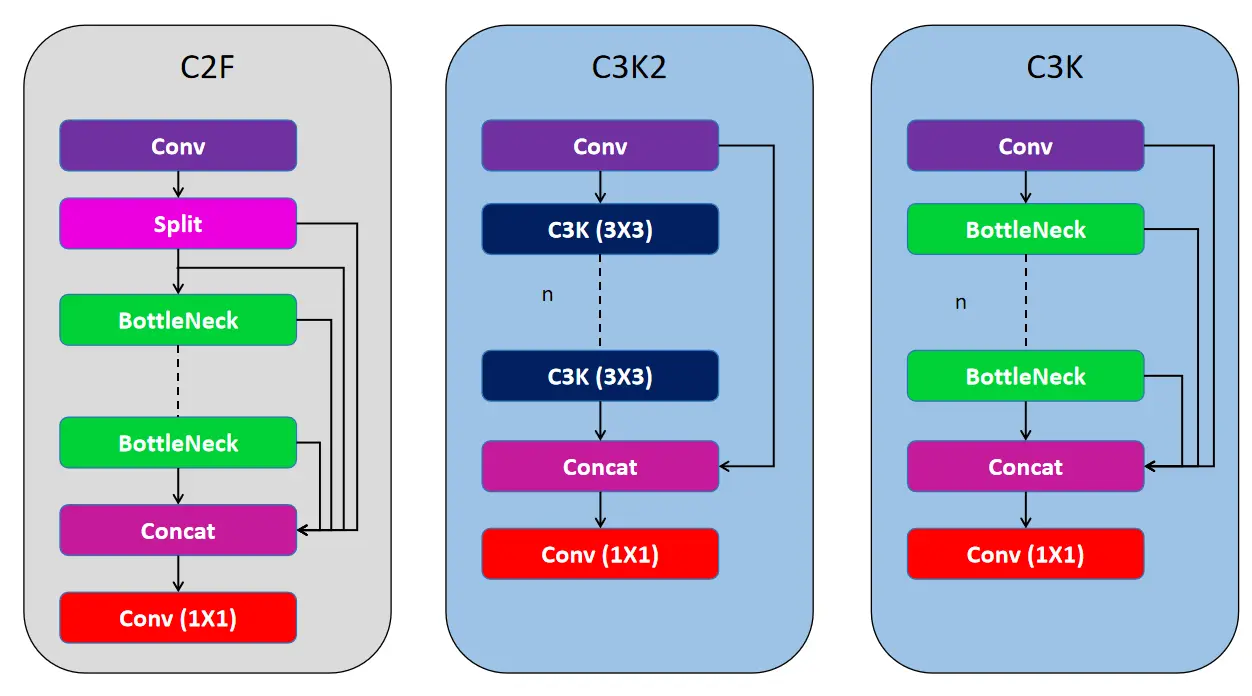
| 特性 | C2F(YOLOv8) | C3K2(YOLOv11) |
|---|---|---|
| 特征分割 | 需要分割feature map | 无需分割 |
| 卷积核 | 多种尺寸 | 主要3×3 |
| 结构复杂度 | 较低 | 较高 |
| 计算效率 | 较低 | 更高 |
6.5.4 SPPF模块结构
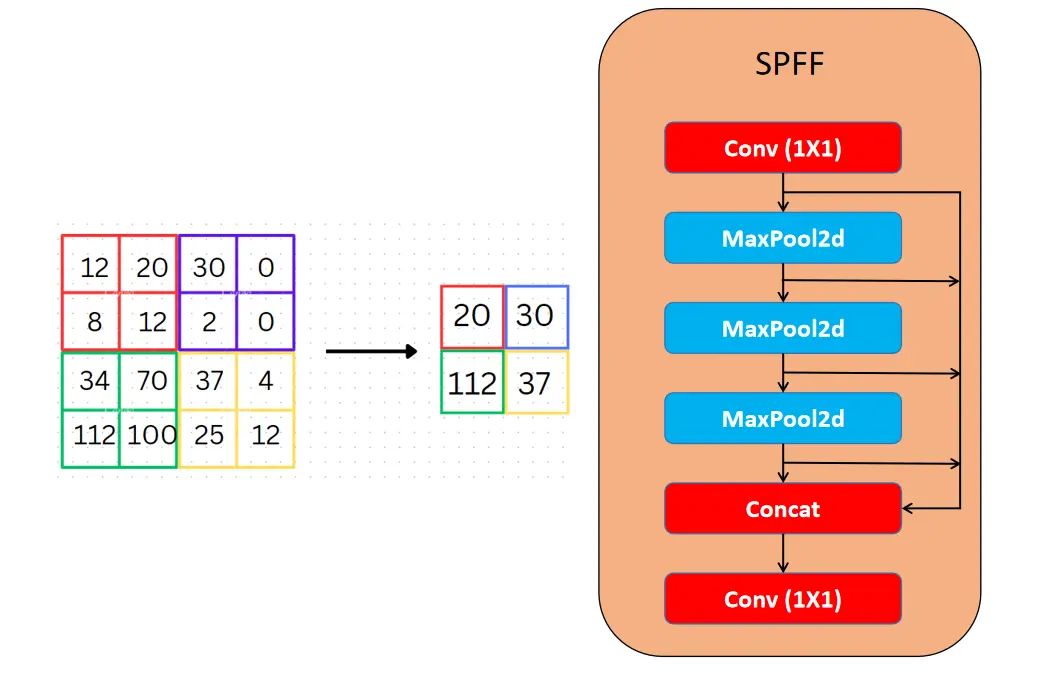
SPPF工作原理:
输入特征图
↓
并行执行多个MaxPool(不同kernel_size)
↓
拼接所有池化结果
↓
卷积调制
↓
输出融合特征
关键优势:
- 多尺度感受野覆盖
- 计算开销可控
- 适合实时推理
6.5.5 C2PSA注意力模块
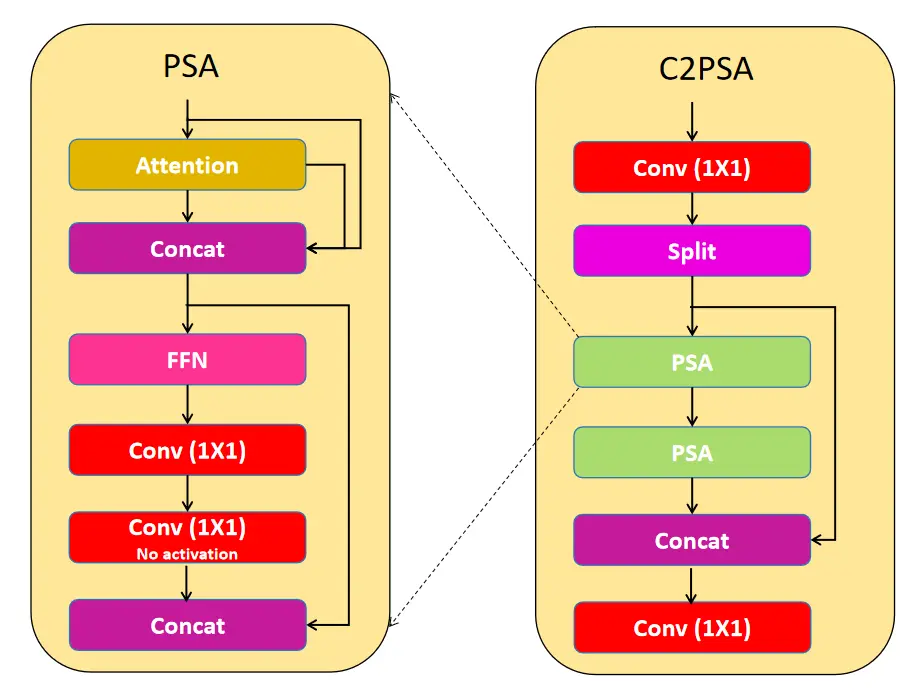
C2PSA模块创新点:
输入分支
↓
PSA注意力处理 → 特征加权
↓
拼接 → 前馈网络 → 卷积调制
↓
输出增强特征
七、实验结果分析
7.1 定性检测结果
马匹检测示例

分析:
- 成功检测到单匹马
- 边界框精确贴合目标轮廓
- 置信度0.95,显示高检测确定性
- 背景纯净,误检率低
大象检测示例

分析:
- 自然场景中的大型目标检测
- 置信度0.93,表现出色
- 边界框准确包围目标
- 环境复杂但检测稳定
交通场景检测
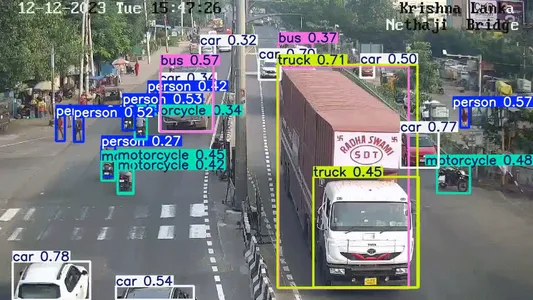
分析:
- 密集场景多目标检测
- 覆盖多种类别:car、truck、person
- 成功检测小尺寸目标
- 低置信度目标也能被识别
7.2 模型变体对比
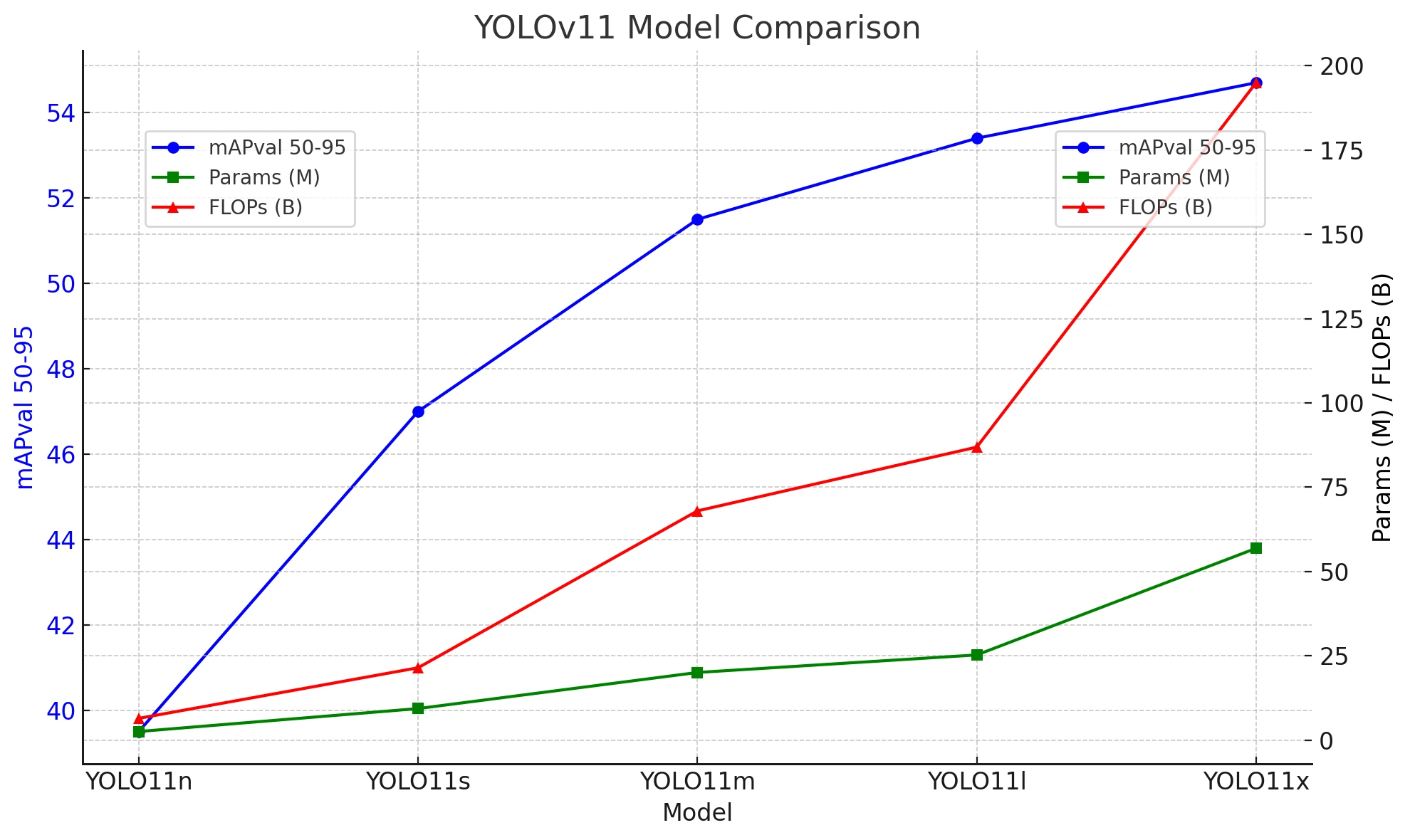
图表分析:
- YOLOv11n(纳米版):最小最快,适合资源受限场景
- YOLOv11s(小规模):最佳性价比,适合大多数应用
- YOLOv11m(中等规模):精度提升明显
- YOLOv11x(超大规模):最高精度,推理速度较慢
7.3 与SOTA模型对比
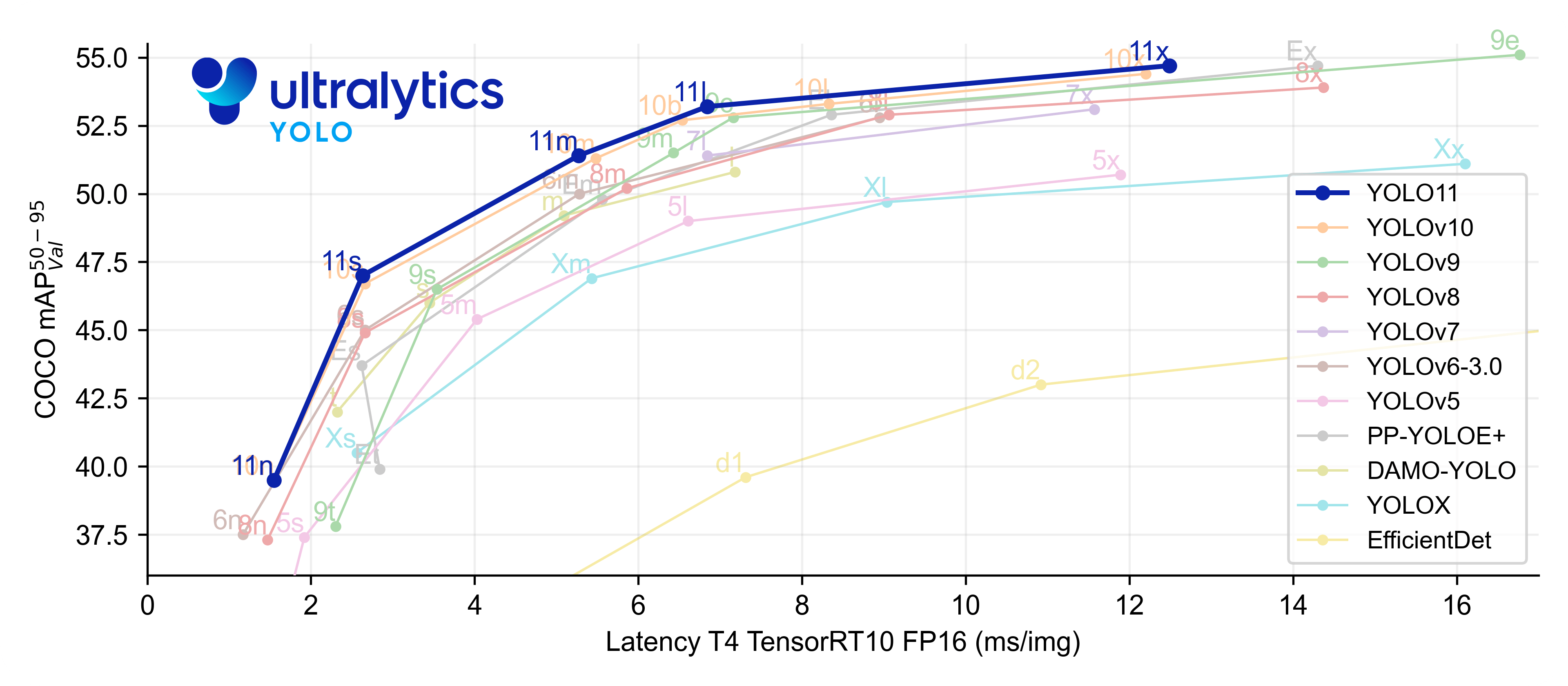
性能分析:
| 模型 | mAP | FPS | 特点 |
|---|---|---|---|
| EfficientDet | ~40 | ~30 | 高精度但速度慢 |
| YOLOX | ~45 | ~60 | 平衡性能 |
| PP-YOLOE+ | ~46 | ~70 | 实时性能 |
| DAMO-YOLO | ~47 | ~80 | 高效检测 |
| YOLOv11 | ~50 | ~100+ | 最优平衡 |
关键发现:
- YOLOv11在mAP-FPS权衡曲线上处于帕累托最优位置
- 实现50+mAP的同时保持100+FPS的实时推理速度
- 相比YOLOv10及更早版本有显著性能提升
7.4 硬件性能评估
论文提供了详细的设备性能数据:
| 输入类型 | 分辨率 | 设备 | 预处理(ms) | 推理(ms) | 后处理(ms) |
|---|---|---|---|---|---|
| Q1图像 | 448×640 | CPU | 17.2 | 541.8 | 3.2 |
| Q2图像 | 640×512 | CPU | 13.2 | 255.5 | 3.6 |
| Q3图像 | 448×640 | CPU | 12.9 | 295.6 | 2.7 |
| 视频流 | 384×640 | CPU | 3.5 | 159.0 | 1.7 |
| Q1图像 | 448×640 | GPU | 15.0 | 72.8 | 1165.7 |
| Q2图像 | 640×512 | GPU | 3.7 | 46.2 | 531.7 |
| Q3图像 | 448×640 | GPU | 2.2 | 43.0 | 483.9 |
| 视频流 | 384×640 | GPU | 2.0 | 10.1 | 106.0 |
性能洞察:
- GPU推理速度相比CPU提升约5-7倍
- 视频流推理延迟最低(GPU: 10.1ms)
- 后处理在GPU上占比较高(I/O开销)
八、论文贡献总结
8.1 主要贡献
- 系统化分析:首次以学术论文形式对YOLOv11进行系统性技术解析
- 架构解密:详细阐述C3K2、C2PSA、SPPF等核心模块的设计原理
- 性能评估:提供全面的基准测试数据和对比分析
- 实践指导:给出PyTorch实现指南和训练建议
8.2 技术价值
- 为研究社区提供YOLOv11的正式技术参考
- 推动目标检测技术的透明化和可复现性
- 为未来YOLO版本迭代提供对比基准
8.3 应用前景
- 自动驾驶:实时目标检测,满足安全关键需求
- 视频监控:大规模场景分析,提升监控效率
- 机器人视觉:嵌入式部署,低延迟响应
- 工业检测:产品质检,自动化生产线
九、结论与展望
9.1 论文结论
YOLOv11作为YOLO系列的最新迭代,通过以下技术创新实现了精度与速度的最优平衡:
- C3K2模块:高效的特征提取,更少的参数量
- C2PSA注意力:增强的空间关注能力,改善小目标检测
- 优化SPPF:快速多尺度特征融合
实验结果表明,YOLOv11在COCO数据集上实现了state-of-the-art的检测性能,同时保持了YOLO系列标志性的实时推理能力。
9.2 未来研究方向
论文提出的可能拓展方向:
- 实例分割:基于YOLOv11的分割变体
- 旋转目标检测:面向遥感、文本检测等场景
- 模型压缩:知识蒸馏、量化等轻量化技术
- 跨模态融合:结合LiDAR、深度图等多传感器信息
十、参考文献
- Redmon J, et al. “You Only Look Once: Unified, Real-Time Object Detection.” CVPR 2016.
- Redmon J, Farhadi A. “YOLO9000: Better, Faster, Stronger.” CVPR 2017.
- Redmon J, Farhadi A. “YOLOv3: An Incremental Improvement.” arXiv 2018.
- Bochkovskiy A, et al. “YOLOv4: Optimal Speed and Accuracy of Object Detection.” arXiv 2020.
- Wang C Y, et al. “YOLOv7: Trainable Bag-of-Freebies.” CVPR 2023.
- Wang A, et al. “YOLOv10: Real-Time End-to-End Object Detection.” NeurIPS 2024.
- Khanam R, Hussain M. “YOLOv11: An Overview of the Key Architectural Enhancements.” arXiv 2024.
- Ioffe S, Szegedy C. “Batch Normalization.” ICML 2015.
- Elfwing S, et al. “Sigmoid-weighted Linear Units for Neural Network Function Approximation.” Neural Networks 2018.
- He K, et al. “Deep Residual Learning for Image Recognition.” CVPR 2016.

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 18
18 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)