预训练模型
主要内容总结:
- BERT(Encoder-Only,双向理解专家):
- 像一个“超级阅读理解高手”。
- 它能同时看前后所有内容(双向注意力),非常擅长“吃透”一句话的意思。
- 典型干的事:判断这句话是正面还是负面情感?找出人名、地名?判断两句话是否相似?做搜索排序。
- 它不擅长自己写长文章,因为它不是为“一步一步生成”设计的。
- GPT(Decoder-Only,续写/生成大师):
- 像一个“天才故事续写家”。
- 它只能从左往右看已经写过的内容,然后一步一步预测下一个词(因果注意力)。
- 典型干的事:聊天、写文章、写代码、创意生成、长文本续写。
- 它理解能力也不错(尤其是现代超大版本),但在“纯粹理解”某些任务上,不如同等规模的 BERT 精确和高效。
- T5(Encoder-Decoder,翻译/转换全能手):
- 像一个“专业翻译 + 改写机”。
- 先用 Encoder 完整双向读懂 输入,再用 Decoder 一步一步生成 输出。
- 它把所有任务都统一成“输入一段文字 → 输出另一段文字”(Text-to-Text)。
- 典型干的事:机器翻译、文章摘要、生成式问答、文本改写。
一、BERT 结构及应用
1、BERT 整体定位与核心优势
- BERT 全称:Bidirectional Encoder Representations from Transformers(基于 Transformer 的双向编码器表示)
- 架构基础:完全基于 Transformer 的 Encoder(编码器)部分,不使用 Decoder。
- 核心优势:真正的双向(Bidirectional)上下文理解能力。
- 通过自注意力机制(Self-Attention),模型在计算每一个词的表示时,可以同时看到整个序列的左右上下文。
- 适用场景:
- 擅长语言理解(NLU)任务:文本分类、命名实体识别、问答、自然语言推断等。
- 不适合直接做文本生成(因为它能“看到”未来信息,违背生成模型“只能看过去”的单向性)。
与 GPT 的对比:
- GPT:基于 Decoder(自回归,单向,只能预测下一个词)→ 擅长生成
- BERT:基于 Encoder(非自回归,双向)→ 擅长理解
2、BERT 的设计原理与训练范式
两大阶段:
- 预训练(Pre-training):
- 在海量无标注通用语料(维基百科、书籍等)上,使用无监督任务训练。
- 目标:让模型学习语言的通用规律(语法、语义、上下文依赖等)。
- 微调(Fine-tuning):
- 在具体下游任务上,使用少量有标注数据,继续训练(或仅训练顶部输出层)。
- 优势:迁移学习,收敛快、数据需求少、效果好。
解决的问题:
- 传统静态词向量(如 Word2Vec)的一词多义问题。
- BERT 生成的是动态的、上下文相关的词向量(Contextualized Embeddings)。
与 Bi-LSTM 的区别:
- Bi-LSTM:两个独立单向 RNN 浅层拼接,正向看不到未来,反向看不到过去。
- BERT:深度双向,每一层每个词都能与序列中所有其他词直接交互,捕捉更长距离、更复杂的依赖关系,且计算高度并行。
3、BERT 架构详解
1. 模型规模(BERT-Base vs BERT-Large)
| 模型 | 层数 (L) | 隐藏层大小 (H) | 注意力头数 (A) | 参数量 |
|---|---|---|---|---|
| BERT-Base | 12 | 768 | 12 | ~1.1 亿 |
| BERT-Large | 24 | 1024 | 16 | ~3.4 亿 |
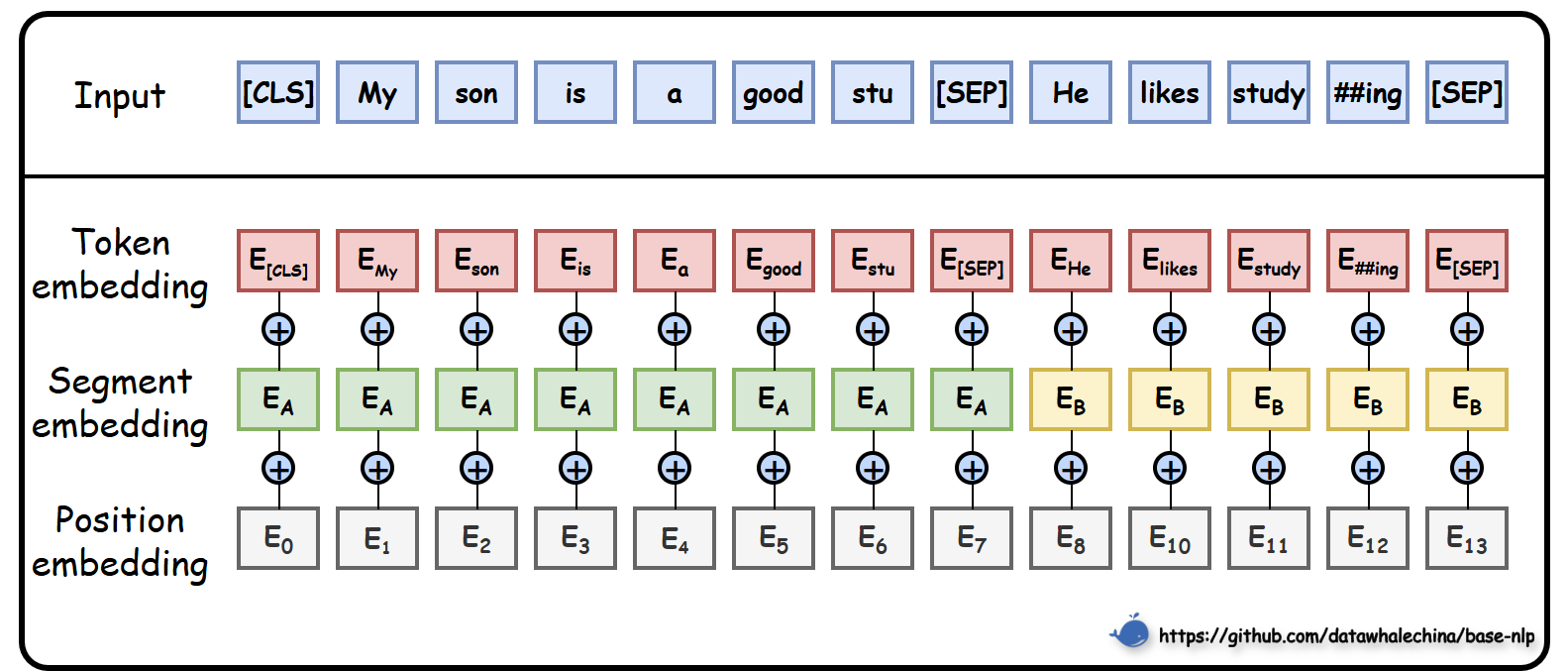
2. 输入表示(Input Embeddings)
公式: Input Embedding = Token Embedding + Position Embedding + Segment Embedding
三大嵌入向量:
- Token Embedding:使用 WordPiece 分词(中文 bert-base-chinese 以单字为主 + 子词)。
- Position Embedding:可学习的位置编码(非固定正余弦),决定最大序列长度为 512。
- Segment Embedding:用于区分句子对任务(句子 A / 句子 B)。
3. 特殊 Token(非常重要)
- [CLS]:序列开头,用于句子级表示(分类任务核心)。
- [SEP]:句子分隔符,单句放句末,句子对放两句之间及末尾。
- [MASK]:仅预训练时使用,用于掩码语言模型。
- [PAD]:填充,计算注意力时被
Attention Mask屏蔽。 - [UNK]:未知词。
4. 预训练任务(BERT 成功的关键)
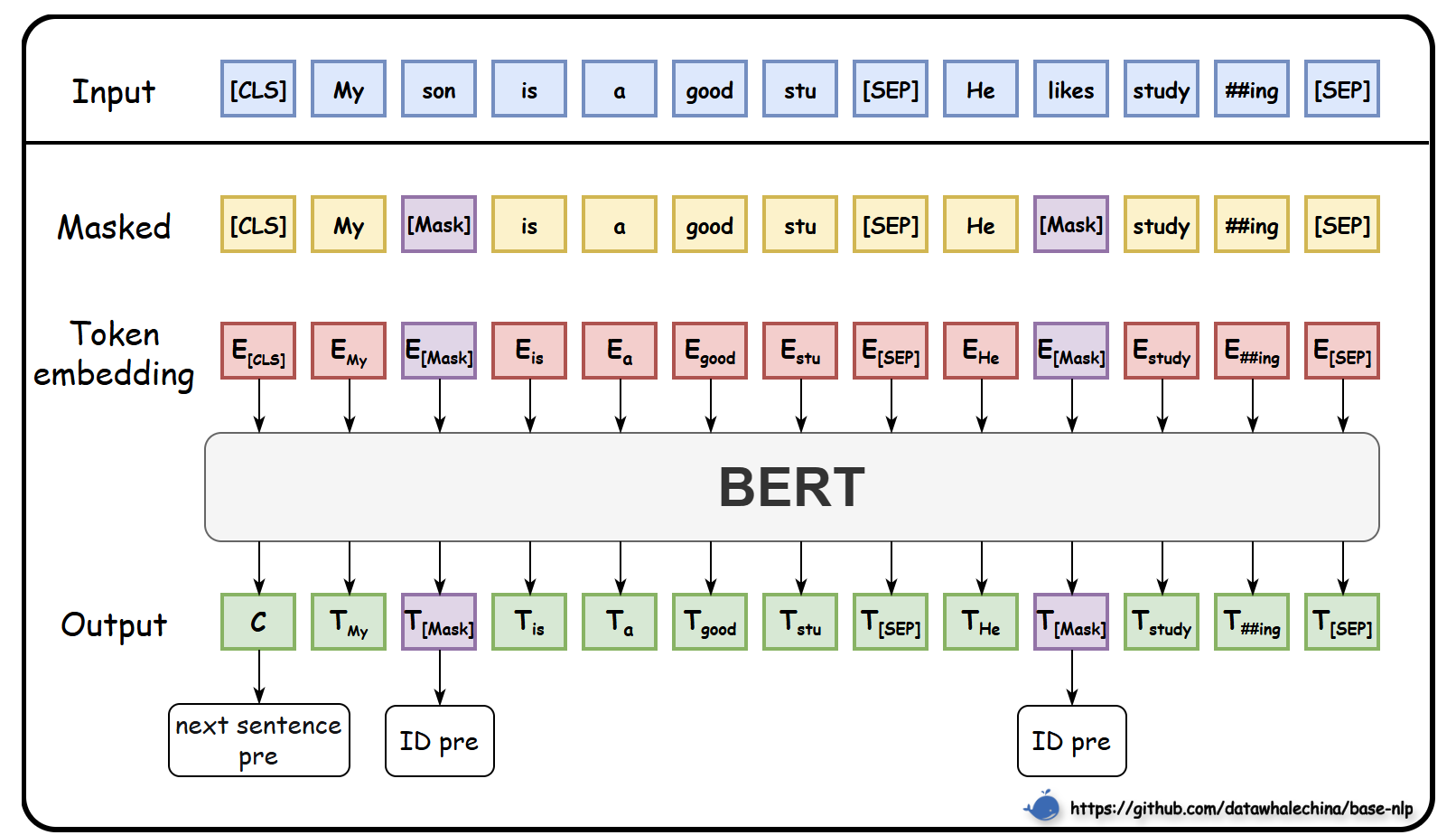
任务一:掩码语言模型 (Masked Language Model, MLM)
- 随机 Mask 15% 的 Token。
- 80/10/10 替换策略:
- 80% → 替换为 [MASK]
- 10% → 替换为随机词(引入噪声)
- 10% → 保持不变
- 作用:迫使模型利用双向上下文预测被掩盖的词,实现深层语义学习。
- 改进:Whole Word Masking (WWM) 全词掩码(避免拆散完整词语)。
任务二:下一句预测 (Next Sentence Prediction, NSP)
- 输入句子对 (A, B),预测 B 是否是 A 的下一句(二分类)。
- 使用 [CLS] 的输出进行判断。
- 后续模型(如 RoBERTa)对其有效性有质疑,但对原始 BERT 有帮助。
4、BERT 的下游应用(微调方式)
- 文本分类(句子级):
- 取 [CLS] 的隐藏状态 + 全连接分类器。
- 词元分类(序列标注,如 NER):
- 取所有 Token 的隐藏状态序列 + 全连接层(每个位置独立分类)。
- 其他:问答(预测答案起止位置)、自然语言推断等。
实用技巧:
- 最大输入长度:512 Token(含特殊 Token,实际文本通常 ≤ 510)。
- 特征融合:可使用最后一层、最后四层拼接/相加、平均池化等,根据任务验证效果。
- 推荐工具:Hugging Face transformers 库(已成为 NLP 标准)。
5、代码实战核心要点
- 使用 AutoTokenizer + AutoModel 加载 bert-base-chinese。
- Tokenizer 输出包含:input_ids、token_type_ids、attention_mask。
- 模型输出:
- last_hidden_state:形状 (batch, seq_len, hidden_size),每个 Token 的深层表示。
- pooler_output:对 [CLS] 进一步池化(Tanh)。
- 句子特征通常取 last_hidden_state[:, 0, :]([CLS])。
- 词元特征直接切片对应位置。
模型结构关键组件:
- Embeddings:word + position + token_type + LayerNorm + Dropout
- Encoder:12 层(Base)BertLayer,每层包含 Self-Attention + Feed-Forward
- Pooler:对 [CLS] 做额外线性 + Tanh 处理
BertModel(
(embeddings): BertEmbeddings(
(word_embeddings): Embedding(21128, 768, padding_idx=0)
(position_embeddings): Embedding(512, 768)
(token_type_embeddings): Embedding(2, 768)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(encoder): BertEncoder(
(layer): ModuleList(
(0-11): 12 x BertLayer(
(attention): BertAttention(
(self): BertSdpaSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
(intermediate_act_fn): GELUActivation()
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
)
(pooler): BertPooler(
(dense): Linear(in_features=768, out_features=768, bias=True)
(activation): Tanh()
)
)6、练习:BERT 与 Transformer (Encoder) 的区别总结
- 相同点:
- 都使用多层 Transformer Encoder 结构(多头自注意力 + 前馈网络 + 残差连接 + LayerNorm)。
- 都支持并行计算,适合捕捉长距离依赖。
- 不同点:
- 预训练方式:Transformer 原始论文中 Encoder 需要与 Decoder 搭配训练;BERT 独立使用 Encoder,通过 MLM + NSP 进行自监督预训练。
- 输入处理:BERT 增加了 Segment Embedding、特殊 Token([CLS], [SEP], [MASK] 等),并使用可学习的位置嵌入。
- 训练目标:BERT 专注于双向语言理解;原始 Transformer Encoder 更侧重于序列到序列的映射。
- 最大长度:BERT 固定为 512(由位置嵌入表决定);原始 Transformer 可根据需求调整。
- 使用方式:BERT 强调“预训练 + 微调”范式,已成为下游任务的强力特征提取器;原始 Transformer 更多作为架构基础。
一句话总结: BERT 是“预训练 + 双向 Transformer Encoder”的典范,通过创新的 MLM 和 NSP 任务,让编码器真正发挥出强大的上下文理解能力,开创了 NLP 迁移学习的时代。
二、GPT 结构及应用
1、GPT 整体定位与核心思想
- GPT 全称:Generative Pre-trained Transformer(生成式预训练 Transformer)
- 架构基础:完全基于 Transformer 的 Decoder(解码器)部分
- 核心特性:自回归(Auto-Regressive) + 因果语言模型(Causal Language Model, CLM)
- 只能看到左侧(已生成)的上下文,无法看到未来信息(通过掩码自注意力实现)
- 训练目标:预测下一个词元(Next Token Prediction)
- 设计目标:专注于语言生成(NLG),擅长文本续写、对话、创作等生成式任务
- 发展路线:从 GPT-1 的“预训练 + 微调” → GPT-2 的零样本(Zero-shot)→ GPT-3 的上下文学习(In-context Learning / Few-shot)
核心公式(因果语言模型):
2、GPT 的技术演进与训练范式
1. GPT-1(2018)
- 经典“预训练 + 有监督微调”
- 创新:通过输入变换(添加特殊分隔符)将各种下游任务统一转为序列续写任务
- 微调时常结合语言模型损失作为辅助目标
2. GPT-2(2019)
- 强调零样本学习(Zero-shot Learning)
- 模型规模扩大 + 高质量数据(WebText)使模型无需微调即可完成任务,证明模型在预训练中已经隐式地学会了各种任务
- 架构改进:切换到 Pre-Norm(LayerNorm 放在子层输入端),上下文窗口从 512 → 1024
3. GPT-3(2020)
- 参数量达到 1750 亿
- 核心能力:上下文学习(In-context Learning, ICL)
- Zero-shot:仅给任务描述
- One-shot:给 1 个示例
- Few-shot:给多个示例
- 意义:从“为每个任务训练专用模型”转向“通过 Prompt 激发通用模型能力”
现代大模型范式转变:
- BERT 时代:微调为主(更新权重,加任务头)
- GPT 时代:提示工程(Prompting)为主(不更新权重,通过提示词激发能力)
3、GPT 架构详解
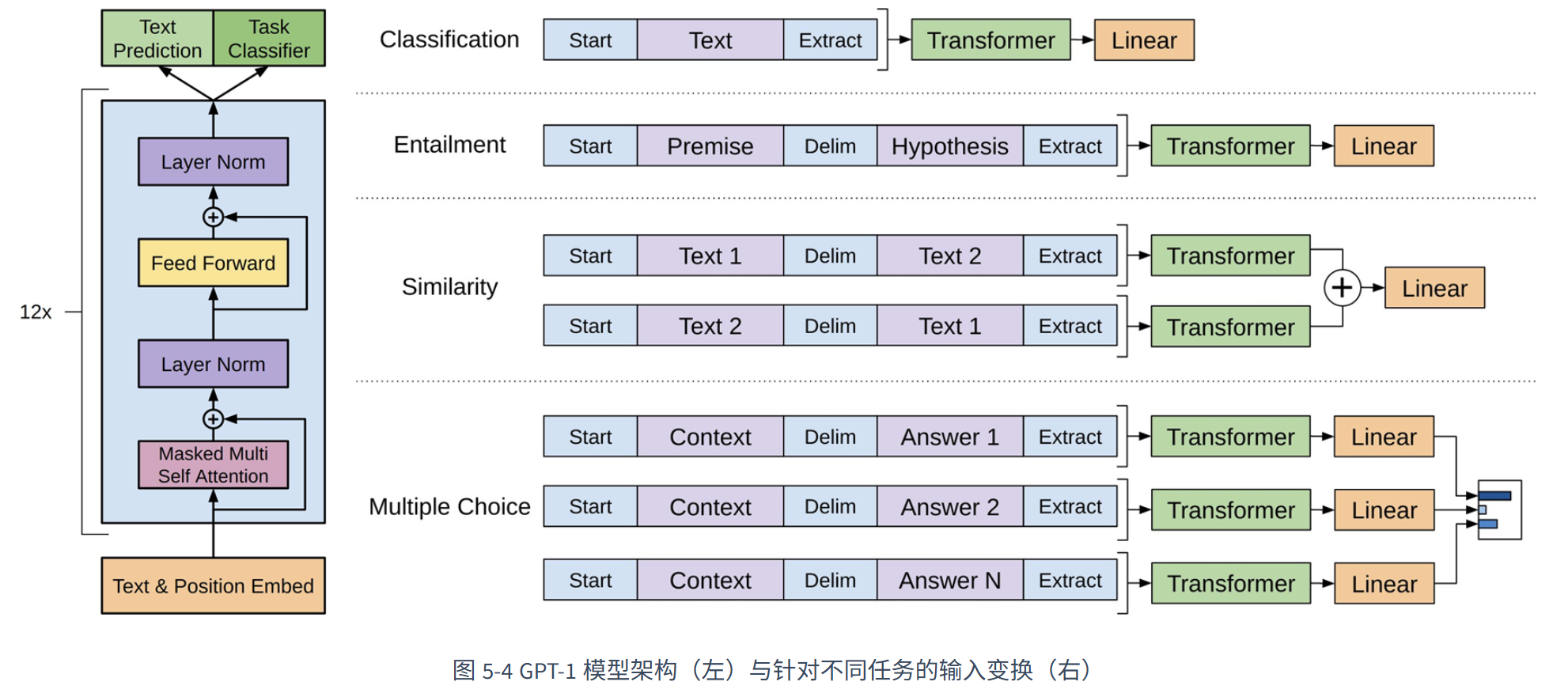
1. 基本结构
- 本质:堆叠的 Transformer Decoder 层
- 每个 Decoder 层包含:
- 掩码多头自注意力(Masked Multi-Head Self-Attention)← 实现单向性的关键
- 位置前馈网络(Feed-Forward Network)
- 移除:原始 Transformer Decoder 中的交叉注意力(Cross-Attention),因为 GPT 没有 Encoder
2. 关键架构特性
- 特殊 Token:主要使用 <|endoftext|>(表示文本结束或文档分隔)
- 归一化方式:
- GPT-1:Post-Norm(与 BERT 相同)
- GPT-2/GPT-3:Pre-Norm(更适合深层模型)
- 分词器:字节级 BPE(Byte-level BPE)
- 优点:彻底解决 [UNK] 问题(任何文本都能用字节表示)
- 缺点:对中文等非英文语言编码效率低(一个汉字常被拆成 2-3 个字节 token)
- 输入表示:仅 Token Embedding + Position Embedding(无 Segment Embedding)
- 上下文窗口:随版本扩大(GPT-1: 512 → GPT-2: 1024 → GPT-3: 2048)
3. GPT 与 BERT 核心差异对比(重点记忆)
| 特性 | BERT (Encoder) | GPT (Decoder) |
|---|---|---|
| 核心结构 | Transformer Encoder | Transformer Decoder |
| 注意力机制 | 双向自注意力(能看全文) | 掩码自注意力(只能看左侧) |
| 预训练任务 | MLM + NSP | 因果语言模型(预测下一个词) |
| 输入表示 | Token + Position + Segment | Token + Position(无 Segment) |
| 最大长度 | 通常 512 | 1024(GPT-2)/ 2048(GPT-3) |
| 归一化位置 | Post-Norm | Pre-Norm(GPT-2/3) |
| 应用模式 | 微调(Fine-tuning) | 提示工程(Prompting) + Zero/Few-shot |
| 适用场景 | 语言理解(NLU):分类、NER、QA | 语言生成(NLG):写作、对话、续写 |
4、GPT 代码实战核心要点
1. 模型加载
- 使用 AutoModelForCausalLM(带 lm_head 的因果语言模型头)
- lm_head:将隐藏层向量(768维等)线性映射回词汇表大小,用于预测下一个 token
2. 自回归生成原理(手动循环关键)
- 每次只预测序列最后一个位置的下一个 token(logits[:, -1, :])
- 使用 torch.argmax(贪心搜索)或采样策略
- 将新生成的 token 拼接到输入序列末尾,再输入模型 → 实现自回归
3. 分词器差异
- GPT-2:字节级 BPE → 英文高效,中文低效(汉字常拆成多个字节 token)
- BERT:WordPiece → 中文以单字/子词为主,更适合中文
4. 实用工具
- pipeline("text-generation"):一行代码完成生成,底层封装了分词、推理、解码全流程
5. GPT-2 模型结构关键组件
- transformer.wte:词元嵌入(vocab_size=50257)
- transformer.wpe:位置嵌入(max_position=1024)
- transformer.h:12 层 GPT2Block(每个 Block 包含 Pre-Norm + Masked Attention + MLP)
- lm_head:语言模型头(768 → 50257)
GPT2LMHeadModel(
(transformer): GPT2Model(
(wte): Embedding(50257, 768)
(wpe): Embedding(1024, 768)
(drop): Dropout(p=0.1, inplace=False)
(h): ModuleList(
(0-11): 12 x GPT2Block(
(ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(attn): GPT2Attention(
(c_attn): Conv1D(nf=2304, nx=768)
(c_proj): Conv1D(nf=768, nx=768)
(attn_dropout): Dropout(p=0.1, inplace=False)
(resid_dropout): Dropout(p=0.1, inplace=False)
)
(ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(mlp): GPT2MLP(
(c_fc): Conv1D(nf=3072, nx=768)
(c_proj): Conv1D(nf=768, nx=3072)
(act): NewGELUActivation()
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
(ln_f): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
(lm_head): Linear(in_features=768, out_features=50257, bias=False)
)5、本节核心知识点浓缩版
- GPT 的本质:基于 Transformer Decoder 的自回归生成模型,核心任务是预测下一个词。
- 单向性:通过掩码自注意力实现,只能看到过去,不能看到未来。
- 范式演进:
- GPT-1:预训练 + 微调
- GPT-2:零样本学习
- GPT-3:上下文学习(In-context Learning)
- Prompting 的重要性:现代大模型主要通过精心设计的提示词而非微调来完成任务。
- 分词机制差异:GPT 用字节级 BPE(无 [UNK],但中文效率低);BERT 用 WordPiece。
- 架构差异:
- 无交叉注意力、无 Segment Embedding
- Pre-Norm 更适合超大规模模型
- 生成过程:自回归循环(每次生成一个 token → 拼接 → 重复)
一句话总结: GPT 是“基于 Transformer Decoder + 因果语言模型 + Prompting”的生成式大模型路线,与 BERT 的双向理解路线形成鲜明对比,共同推动了 NLP 从“任务特定模型”走向“通用大模型”的时代。
BERT vs GPT 整体对比记忆框架:
- BERT:双向 Encoder → 理解为主 → 微调范式 → MLM + NSP
- GPT:单向 Decoder → 生成为主 → Prompting 范式 → 下一个词预测
三、T5 结构及应用
1、T5 整体定位与核心理念
- T5 全称:Text-to-Text Transfer Transformer(文本到文本的迁移 Transformer)
- 架构基础:回归经典的 Transformer Encoder-Decoder 结构(同时拥有 Encoder 和 Decoder)
- 核心设计哲学:万物皆文本(Text-to-Text)
- 把所有 NLP 任务统一转化为“输入文本 → 输出文本”的形式。
- 不再为不同任务设计不同的模型头或结构,只需通过任务前缀(Task Prefix) 来区分任务。
- 优势:同时具备 BERT 的理解能力(双向 Encoder)和 GPT 的生成能力(自回归 Decoder),真正实现了理解与生成的统一。
典型应用示例(使用任务前缀):
- 翻译:"translate English to German: The house is wonderful." → "Das Haus ist wunderbar."
- 情感分类:"情感分析: 黑神话悟空真好玩" → "正面"
- 相似度/回归:"stsb sentence1: ... sentence2: ..." → "4.0"
- 摘要、问答、分类等全部统一为文本生成。
2、T5 的训练范式与创新
1. 提示词的先驱
- Task Prefix(任务前缀):在输入文本前添加自然语言指令(如 "translate English to Chinese:"、"摘要:"、"情感分析:")。
- 这是大语言模型 Prompt 工程的早期雏形。
- 与 GPT Prompt 的区别:
- T5 Prefix:主要用于有监督多任务微调阶段,模型在训练时就见过这些前缀。
- GPT Prompt:主要用于零样本/少样本推理,无需更新参数。
2. 多任务学习策略
- 采用比例混合策略(带上限的采样):防止大数据集淹没小数据集,确保模型在所有任务上均衡学习。
3. 独特的预训练任务:Span Corruption(片段破坏与重构)
- 核心思路:随机遮盖连续的文本片段(Span),用特殊哨兵符(Sentinel Tokens,如 <extra_id_0>、<extra_id_1>)替换,然后让 Decoder 重构这些被遮盖的内容。
- 关键参数:遮盖约 15% 的 token,平均 Span 长度为 3(比 BERT 的单 token Mask 更难)。
- 输出格式:Decoder 依次生成被 Mask 的 Span,并用哨兵符分隔,最后以 <extra_id_2> 等结束。
- 优势:同时训练了 Encoder 的理解能力和 Decoder 的生成能力,比 BERT 的 MLM 或 GPT 的 CLM 更适合 Encoder-Decoder 架构。

预训练数据集:C4(Colossal Clean Crawled Corpus)超大规模清洗语料。
3、T5 架构详解
1. 整体结构
- Encoder:双向理解输入(类似 BERT)
- Decoder:自回归生成输出(类似 GPT)
- 与原始 Transformer 高度一致,但加入多项优化。
2. 关键技术改进(重要创新点)
- 相对位置编码(Relative Position Bias)(最重要创新之一)
- 不再使用绝对位置编码(BERT/GPT 的方式)。
- 核心机制:
- 将相对距离作为 Bias 直接加到 Attention Score(Q·K)上。
- 分桶(Bucketing)策略:近距离精确区分,远距离用对数映射模糊处理。
- 参数在所有层之间共享,极大节省参数量。
- 优势:对语言中的近距离语法依赖(如主谓)建模更精准,对远距离语义依赖也足够有效。
- 简化 Layer Normalization
- 去除加性偏置(Additive Bias),仅保留缩放(Rescaling)。
- 减少参数和计算开销。
- 分词器:SentencePiece
- 直接在原始文本上训练,将空格视为普通字符(用 _ 表示)。
- 语言无关性强,特别适合多语言任务(后续 mT5 支持 101 种语言)。
4、T5 与 BERT、GPT 的对比(三模型总结)
| 特性 | BERT | GPT | T5 |
|---|---|---|---|
| 架构 | Encoder only | Decoder only | Encoder + Decoder |
| 注意力机制 | 双向自注意力 | 掩码自注意力(单向) | Encoder 双向 + Decoder 单向 |
| 预训练任务 | MLM + NSP | 因果语言模型(下一个词) | Span Corruption(片段重构) |
| 输入输出形式 | 向量表示 + 分类头 | 文本续写 | Text-to-Text(统一) |
| 任务处理方式 | 微调 + 不同任务头 | Prompting(零/少样本) | 任务前缀 + 多任务学习 |
| 位置编码 | 绝对位置 | 绝对位置 | 相对位置 Bias(分桶) |
| 分词器 | WordPiece | Byte-level BPE | SentencePiece |
| 擅长领域 | 语言理解(NLU) | 语言生成(NLG) | 理解 + 生成 统一 |
一句话定位:
- BERT:双向理解专家
- GPT:自回归生成专家
- T5:文本到文本的通用转换专家,最接近原始 Transformer 的“完整形态”
5、代码实战核心要点
- 模型加载:
- T5Tokenizer + T5ForConditionalGeneration
- 使用 model.generate() 进行自回归生成
- 输入要求:
- 必须添加任务前缀(Task Prefix)
- Tokenizer 会自动处理输入,模型直接输出文本
- 相对位置编码实现:
- 不在 Embedding 层,而是在 Attention Score 上加 Bias
- 核心函数:compute_bias + _relative_position_bucket
- 分桶逻辑:近距离精确(直接用距离),远距离对数映射压缩
- 注意事项:
- 原版 t5-small 主要针对英文,中文支持较弱 → 推荐使用 mT5(多语言版)
- 输出始终是文本,即使是回归任务(如相似度打分)也生成字符串 "4.0"
6、本节核心知识点浓缩版
- T5 的核心理念:万物皆文本(Text-to-Text),所有任务统一为输入文本 → 输出文本。
- 任务区分方式:通过自然语言任务前缀(Task Prefix),这是 Prompt 工程的早期实践。
- 预训练任务:Span Corruption —— 随机 Mask 连续片段,用哨兵符替换,让 Decoder 重构。
- 架构:标准 Encoder-Decoder,Encoder 双向理解,Decoder 自回归生成。
- 位置编码创新:相对位置 Bias + 分桶策略(近密远疏、对数映射),参数层间共享。
- 分词器:SentencePiece,更适合多语言和无空格语言。
- 与前两模型的关系:
- 继承 BERT 的双向理解 + GPT 的生成能力
- 通过 Text-to-Text 框架实现了真正的任务统一
一句话总结: T5 以 Encoder-Decoder + Text-to-Text + Span Corruption + 相对位置编码 为核心,首次系统性地将所有 NLP 任务统一到一个框架中,是从“任务特定模型”走向“通用文本转换模型”的重要里程碑,也为后续指令微调(Instruction Tuning)和大语言模型的统一范式奠定了基础。
BERT + GPT + T5 三节整体对比框架:
- BERT:Encoder → 双向理解 → 微调为主
- GPT:Decoder → 单向生成 → Prompting 为主
- T5:Encoder-Decoder → 理解+生成统一 → Text-to-Text + 任务前缀
四、Hugging Face 生态与核心库
1、Hugging Face 生态全景概述
Hugging Face 已从 NLP 初创公司发展为 AI 时代的基础设施平台,其生态系统覆盖模型开发的全生命周期(数据 → 训练 → 评估 → 部署)。
生态核心构成:
- Hugging Face Hub:AI 领域的“GitHub”
- Models:数十万个预训练模型(NLP、CV、Audio、多模态等)
- Datasets:海量公开数据集,支持预览和流式加载
- Spaces:使用 Gradio / Streamlit / Docker 快速构建 Web 演示应用
- 核心开源库(技术基石):
- Transformers:统一模型加载、推理、微调的引擎
- Tokenizers:基于 Rust 的超快分词器(Fast Tokenizers)
- Datasets:高效数据加载与处理,支持内存映射和流式处理
- 辅助工具库:
- Accelerate:简化分布式训练(CPU/GPU/多卡/TPU)
- Evaluate:标准化评估指标(Accuracy、F1、BLEU、ROUGE 等)
- PEFT:参数高效微调(LoRA、QLoRA 等)
- Diffusers:扩散模型(Stable Diffusion 等生成式 AI)
2、Transformers 库核心功能详解
1. Pipeline(开箱即用)
- 最高级封装:预处理 → 模型推理 → 后处理 一条龙
- 支持任务自动推断(无需指定模型)
- 示例:情感分析、文本生成、图像分类等
- 中文任务建议显式指定模型(如 bert-base-chinese)
2. AutoClass 智能加载机制(核心精髓)
- AutoTokenizer、AutoModel、AutoModelForXXX、AutoConfig
- 根据 checkpoint 名称自动推断模型架构并加载
- 关键方法:
- from_pretrained():从 Hub 或本地加载
- save_pretrained():保存模型、配置、词表
3. 核心处理流程拆解(三阶段)
- Tokenizer(分词器)
- 文本 → Tensor(input_ids、attention_mask 等)
- 自动添加特殊 Token(如 [CLS]、[SEP])
- 支持 padding、truncation
- Model(模型)
- 输入 Tensor → 输出 Logits / Hidden States
- 不同任务使用不同头:AutoModelForSequenceClassification、AutoModelForCausalLM、AutoModelForSeq2SeqLM 等
- Post-processing(后处理)
- Logits → Softmax 概率 → 最终预测标签
3、Datasets 库:高效数据流水线
核心优势:
- 基于 Apache Arrow 格式,支持内存映射(大模型数据集也能在普通机器上运行)
- 支持流式处理(无需一次性加载全部数据)
- map() 函数:并行预处理(batched=True + num_proc=N 加速)
典型用法:
- load_dataset("rotten_tomatoes") 快速加载标准数据集
- dataset.map(tokenize_function, batched=True, num_proc=4) 并行分词
4、Trainer + Evaluate:标准化训练与评估
Trainer API(高度封装的训练框架)
- 集成 Accelerate,支持混合精度、梯度累积、分布式训练
- “三步走”训练流程:
- 准备 Model + Tokenized Dataset + Tokenizer
- 配置 TrainingArguments(输出目录、epoch、评估策略等)
- 实例化 Trainer 并调用 trainer.train()
Evaluate 库
- 标准化指标计算
- 定义 compute_metrics 函数,返回字典格式的评估结果
- 与 Trainer 无缝集成,在训练过程中自动评估
5、本章小结与三大模型回顾(重点)
BERT(理解路线)
- 架构:Transformer Encoder
- 预训练:MLM + NSP
- 适用:文本分类、NER、抽取式 QA 等自然语言理解任务
- 微调方式:添加分类头 / 序列标注头
GPT(生成路线)
- 架构:Transformer Decoder
- 预训练:Causal LM(预测下一个词)
- 适用:文本生成、对话、续写
- 现代范式:Prompting + In-context Learning
T5(统一路线)
- 架构:Transformer Encoder-Decoder
- 预训练:Span Corruption
- 核心理念:Text-to-Text(万物皆文本)
- 优势:一个模型搞定翻译、分类、摘要、回归等多种任务
- 关键技术:任务前缀 + 相对位置编码 + SentencePiece
Hugging Face 的价值:
- 极大降低了预训练模型的使用门槛
- 提供从数据加载 → 分词 → 模型加载 → 训练 → 评估 的完整现代化开发链路
- 成为当前 NLP / 多模态开发的事实标准
6、核心知识点浓缩版
- Hugging Face Hub 是 AI 模型与数据集的中央仓库(Models + Datasets + Spaces)。
- Transformers 是核心引擎,提供 Pipeline(快速验证)和 AutoClass(灵活加载)。
- 三大核心库:
- Tokenizers:超快分词(Rust 实现)
- Datasets:内存映射 + 并行 map 处理大模型数据
- Evaluate:标准化指标计算
- Trainer API:高度封装的训练框架,推荐替代手写 PyTorch 循环。
- 处理流程记忆:Tokenizer(文本→Tensor)→ Model(Tensor→Logits)→ Post-processing(Logits→概率/标签)。
- 三大模型定位总结:
- BERT:双向理解专家(Encoder)
- GPT:自回归生成专家(Decoder)
- T5:文本到文本统一专家(Encoder-Decoder)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)