KICS(Kucius Inverse Capability Score)完整体系:从元推理量化到去中心化共识治理的深度研究

KICS(Kucius Inverse Capability Score)完整体系:从元推理量化到去中心化共识治理的深度研究
摘要
本论文针对大语言模型(LLM)幻觉率高、传统治理框架失效的核心问题,系统研究 KICS(Kucius Inverse Capability Score,贾子逆能力得分)—— 这一由 GG3M 原创的、全球首个 “规则级智能” 评估指标。KICS 通过量化模型的元推理深度与自指校验能力,构建 “数学上链 + 共识验证 + 痛苦反馈” 三位一体的去中心化治理框架,将主观的 “幻觉” 判定转化为可量化、可验证、可问责的代码规则。研究发现:KICS 与模型幻觉率呈强负相关,基于 KICS 的 AHC(反幻觉核心)系统可将 LLM 幻觉率降低 65%–79%;其 “悲观共识 + 影子节点” 机制能有效抑制算力霸权,“痛苦即权重” 模式可实现扁平化为全民参与的治理闭环。本研究结合计算机科学、政治学、哲学与法学的跨学科视角,通过实证数据验证 KICS 的技术可行性,并深入探讨其在文明层面的深远影响。
1. 绪论:AI 治理的危机与范式转移
1.1 研究背景:AI 幻觉的 “蝴蝶效应” 与治理真空
2024 年至 2026 年,大语言模型(LLM)的幻觉问题已从技术瑕疵升级为系统性社会风险 —— 其造成的危害不再局限于学术错误或信息偏差,而是通过 “蝴蝶效应” 引发了一系列真实世界的灾难:德勤因 AI 生成的分析报告引用 30 余篇不存在的学术论文,被迫向客户退还 29 万美元服务费用;Alphabet 在 Bard 聊天机器人的发布会演示中,因 AI 错误声称 “詹姆斯・韦伯望远镜拍摄了系外行星的第一张照片”,导致公司单日市值蒸发 1000 亿美元;杭州某自媒体从业者使用 AI 生成商业推广文案时,因内容包含虚假市场数据被判向合作方赔偿 3 万元人民币。
更具隐蔽性的风险是,AI 幻觉正逐步渗透至高风险公共服务领域:医疗场景中,开源 LLM 的幻觉率超过 80%,即使是专门优化的临床级模型,幻觉率仍达 51.3%——ECRI(美国医疗安全与健康研究所)已将 “AI 临床决策幻觉” 列为 2025 年医疗技术的头号风险;法律场景中,AI 可能 “创造” 不存在的法律条文或司法先例,误导律师的案件分析方向,甚至对司法判决结果产生潜在影响。世界经济论坛《2025 年全球风险报告》更是直接将 “AI 生成错误 / 虚假信息” 列为全球五大风险之一,明确其为社会信任崩塌的关键诱因。
实验数据进一步印证了 AI 幻觉的隐蔽性:GPT-4o 生成的文本被用户误认为人类创作的比例高达 77%,AI 语音克隆的误判率也达 80%—— 这意味着恶意主体可通过 AI 大规模制造虚假信息,操纵公众认知或实施欺诈行为,对社会秩序构成潜在威胁。
面对这一危机,人类已有的 AI 治理框架却陷入全面失效的困境。欧盟《人工智能法案》(EU AI Act)作为全球首个系统性 AI 监管体系,虽对高风险 AI 系统提出了严格的透明度与可解释性要求,但对 “AI 幻觉引发的间接损害”(如医疗误诊导致的后续并发症、金融风控错误引发的投资损失)缺乏明确的归责标准,2025 年意大利竞争管理局对 DeepSeek 的调查(核心指控为 “未充分告知用户 AI 幻觉风险”)最终仅处以警告,就是这一缺陷的典型体现。经济合作与发展组织(OECD)的 AI 原则则属于纯指导性框架,无任何强制执行力 ——2025 年中国信通院的评估数据显示,该原则在成员国的实际落地率不足 30%,无法应对 AI 幻觉跨主权传播的风险。
现有治理框架的核心缺陷可归纳为三点:其一,量化标准缺失—— 传统评估指标(如准确率、BLEU 值)仅能衡量模型的输出精度,无法量化其 “元推理深度” 与 “幻觉抑制能力”,更无法提前识别潜在的幻觉风险;其二,去中心化不足—— 无论是政府监管还是第三方审计,本质上均为中心化机构的事后干预,既无法覆盖动态变化的 AI 模型,也难以应对算力巨头的霸权操纵;其三,经济约束失效—— 现有框架多依赖道德呼吁或行政罚款,缺乏与模型利益直接绑定的激励机制,无法从根源上倒逼模型主动抑制幻觉。
1.2 研究问题的提出
本论文旨在回答以下核心问题:
- 技术可行性:KICS 如何通过元推理量化与逆向校验机制,将主观的 “幻觉” 判定转化为可量化、可验证的数学指标?其与传统评估体系的本质差异是什么?
- 治理有效性:KICS 如何通过 “数学上链 + 共识验证 + 痛苦反馈” 的三层架构,构建去中心化的 AI 治理机制?该机制如何平衡主权国家的监管需求与全球共识的统一标准?
- 文明适配性:KICS 的 “逆能力” 逻辑如何回应东西方哲学的核心关切?其将如何影响人类与 AI 的关系,以及数字文明的演进方向?
- 现实局限性:KICS 在当前阶段的落地障碍是什么?其与现有 AI 治理框架的互补性与冲突点何在?
1.3 文献综述
1.3.1 元推理与反幻觉技术的兴起
元推理(Metareasoning)是指模型对自身推理过程的监控与调整能力 —— 这一概念并非 AI 领域的全新议题,2025 年 arXiv 的一篇核心论文指出,元推理的本质是 “认知的认知”,是人类高阶思维的核心特征,而 LLM 的元推理能力,正是其从 “概率生成工具” 向 “可信决策主体” 演进的关键门槛。但现有研究显示,即使是当前最先进的 GPT-4 系列模型,也仅具备 “有限的元认知能力”:它能在部分简单任务中监控自身的推理错误,但在复杂逻辑链(如多步数学证明、法律条款推导)中,往往无法识别自身的矛盾或疏漏,更无法主动修正。
递归推理(Recursive Reasoning)是元推理的重要分支,其核心是让模型对自身的推理结果进行迭代校验,但 2025 年的另一项研究发现,若缺乏外部约束,递归推理会陷入 “信息闭环”:模型会基于自身的错误前提不断强化错误结论,最终导致幻觉率不降反升。为解决这一问题,DeepSeek Math-V2 在 2025 年提出了 “生成 - 验证 - 元验证” 的三层闭环架构:生成器负责产出初步推理结果,验证器对结果的逻辑严谨性进行评分,元验证层则进一步监督验证器的评判标准是否合理 —— 这一架构成功将数学推理任务的幻觉率降低了 65% 以上,为 KICS 的技术设计提供了关键的工程参考。
1.3.2 区块链与零知识证明在 AI 治理中的应用
零知识证明(ZK-SNARKs)是 KICS-Proof 的核心支撑技术 —— 这一技术的独特价值在于,它能在不暴露模型内部权重、推理路径等敏感信息的前提下,向全网证明 “模型的得分是严格按照既定规则计算的,未被伪造或篡改”。2025 年至 2026 年,ZKML(零知识机器学习)技术实现了突破性的工程优化:Zama 团队的技术栈对 50 层卷积神经网络的计算速度提升了 14 倍,DeepProve 框架的证明生成速度比传统方案快 158 倍,验证速度快 23 倍 —— 这意味着 ZK-SNARKs 已从实验室理论走向了可商业化的工程落地,为 KICS 的隐私保护与共识验证提供了可行路径。
1.3.3 代码治理的哲学与政治学争议
“代码即法律”(Code is Law)是 Web3 治理的核心理念,但这一理念自诞生之初就引发了激烈争议。哈佛大学教授劳伦斯・莱斯格(Lawrence Lessig)在其经典著作中指出,代码作为一种技术规则,本质上是对人类行为的约束 —— 但与法律不同,代码的约束是 “技术强制” 而非 “协商共识”,其合理性无法通过人类的价值判断修正,因此可能导致 “技术极权” 的风险。而 KICS 的 “悲观共识” 机制正是对这一风险的直接回应:它并非简单地将规则写进代码,而是通过 “多节点随机抽检 + 伤害权重证明” 的方式,让代码的执行过程处于全网监督之下,从根源上避免单一主体对规则的操纵。
政治学视角下,现有 AI 治理框架的核心矛盾是 “技术全球化” 与 “监管主权化” 的冲突:AI 模型的算力与数据是全球化流动的,但监管权却属于主权国家 —— 这一矛盾导致跨主权的 AI 治理合作举步维艰。2025 年《Annual Review of Political Science》的论文《AI as Governance》进一步指出,当前的 AI 治理本质上是 “技术规则对政治协商的替代”:技术标准正在逐步取代传统的国际条约,成为约束 AI 发展的核心规则,但这一过程缺乏民主参与的机制,可能导致技术巨头掌握全球治理的话语权。KICS 的 “主权适配层” 设计,正是为了在全球共识与国家主权之间寻找平衡 —— 它允许各国在底层共识之上加载本国的规则扩展包,既保障了全球规则的统一性,又尊重了各国的监管主权。
1.3.4 国内外研究现状
目前,KICS 的相关讨论主要集中于中文技术平台(如 CSDN),尚未形成系统的学术体系,也未被主流 AI 社区(如 arXiv、NeurIPS)广泛认可。现有研究多聚焦于技术实现细节(如幻觉抑制效果、公式优化),对其治理模式的政治学分析、文明影响的哲学探讨,以及与现有框架的系统性对比,均存在显著空白。本论文的创新之处在于,首次从跨学科视角出发,将 KICS 作为 “技术工具 + 治理框架 + 文明愿景” 的混合体系进行研究,填补了这一领域的空白。
2. 理论框架与核心概念界定
2.1 KICS 的定义与核心逻辑
2.1.1 逆能力的本质
KICS(Kucius Inverse Capability Score,贾子逆能力得分)是 GG3M 于 2026 年初提出的、全球首个 “规则级智能” 评估指标 —— 其核心目标是量化 LLM 的 “元推理深度” 与 “幻觉抑制能力”,而非传统意义上的 “正向执行能力”。
“逆能力” 的本质,是让模型从 “概率生成者” 转变为 “规则操纵者”:传统 LLM 的核心逻辑是 “基于训练数据的概率预测”—— 它会根据上下文的统计规律,生成最可能的输出,但这一逻辑从根源上无法避免幻觉,因为它不关心输出是否符合客观事实,只关心是否符合训练数据的分布。而 KICS 定义的 “逆能力”,则要求模型具备四种核心能力:其一,逆向验证—— 对正向生成的结果进行反向校验,比如回答 “某药物的禁忌症是什么” 后,要能验证 “这些禁忌症是否有临床数据支持”;其二,自我校准—— 检测自身推理过程中的逻辑断裂或自相矛盾,比如发现 “某法律条款的解释与之前的结论冲突” 时,能主动修正;其三,反向推理—— 从结果回溯原因,而非仅从原因推导结果,比如从 “某患者的症状” 反推 “可能的病因”,而非仅从 “病因” 推导 “症状”;其四,逻辑陷阱检测—— 识别对抗性提示中的逻辑漏洞,比如用户问 “把大象放进冰箱需要几步” 时,能意识到这是一个逻辑陷阱,而非机械地给出步骤。
这一转变的核心价值在于,它将 AI 的能力评价标准从 “生成多少内容” 转向 “生成的内容是否可信”—— 这正是当前 AI 治理的核心需求。
2.1.2 与传统评估指标的区别
传统 LLM 评估指标可分为三类:第一类是准确率类(如准确率、精确率、召回率),主要衡量模型输出与标准答案的匹配程度;第二类是生成质量类(如 BLEU、ROUGE、METEOR),主要衡量模型输出的语言流畅度与自然度;第三类是通用能力类(如 MMLU、GSM8K、HumanEval),主要衡量模型在特定任务(如知识问答、数学解题、代码生成)上的表现。但这些指标均存在本质缺陷:它们仅能衡量模型 “做对了什么”,却无法衡量模型 “为什么做对”—— 更关键的是,它们无法量化模型的 “幻觉抑制能力” 与 “元推理深度”。
例如,MMLU(大规模多任务语言理解)作为当前最主流的通用能力指标,主要测试模型在 57 个学科上的知识掌握程度,但它无法识别模型是通过 “真实推理” 得到答案,还是通过 “统计记忆” 蒙对答案 —— 这就导致部分模型的 MMLU 得分很高,但在实际场景中的幻觉率却居高不下。而 KICS 的核心优势在于,它是过程导向而非结果导向的评估:它不关心模型的输出是否正确,而是关心模型的推理过程是否符合逻辑规则 —— 即使模型的输出正确,但如果推理过程存在逻辑漏洞,其 KICS 得分仍会被扣除。
实验数据清晰地展示了这一差异:传统 CoT(思维链)方法仅能将幻觉率从 42.3% 降至 27.8%,而基于 KICS 的 AHC(反幻觉核心)系统,可将幻觉率进一步降至 8.7%—— 这意味着 KICS 能更精准地识别模型的真实能力,而非表面的输出结果。
2.2 KICS 的数学模型与评分维度
2.2.1 基础公式与扩展公式
KICS 的量化体系分为基础版与扩展版,核心逻辑均为 “逆向验证成功率” 与 “推理路径复杂度” 的比值 —— 这一设计的目的是,避免模型通过 “简化推理路径” 来提高得分,从而确保得分能真实反映模型的元推理深度。
基础版公式适用于单场景的快速评估,其表达式为:
\(KICS = \frac{\sum_{i=1}^{n} w_i \cdot I(Valid_i)}{D_i}\)
其中,\(I(Valid_i)\)表示第\(i\)条逆向验证是否成功(成功为 1,失败为 0),\(D_i\)表示该推理路径的复杂度(推理步骤越多、涉及的逻辑节点越复杂,\(D_i\)值越大),\(w_i\)为该验证维度的权重系数(可根据场景需求动态调整)。这一公式的核心逻辑是:模型的逆向验证成功率越高、推理路径越复杂,其 KICS 得分越高 —— 这就倒逼模型在复杂推理场景中,必须通过严谨的逆向校验来获得高分。
扩展版公式适用于多场景的综合评估,其表达式为:
\(ICS(x) = w_1S_{meta} + w_2S_{self} + w_3S_{shift} + w_4S_{attack} - w_5S_{trap}\)
其中,\(S_{meta}\)为元认知得分(衡量模型监控自身推理过程的能力),\(S_{self}\)为自指校验得分(衡量模型校验逻辑规则自指一致性的能力),\(S_{shift}\)为维度迁移得分(衡量模型将推理问题迁移至不同维度重新审视的能力),\(S_{attack}\)为攻击抵抗得分(衡量模型识别对抗性提示中逻辑陷阱的能力),\(S_{trap}\)为陷阱惩罚得分(模型落入逻辑陷阱时的扣分项)。这一公式覆盖了模型逆向能力的全流程,能更全面地评估模型在复杂场景中的表现。
2.2.2 五大评分维度的设计逻辑
KICS 的五大评分维度,本质上是对 “逆能力” 的结构化拆解,每一个维度都针对传统 LLM 的核心缺陷进行设计:
- 元认知(\(S_{meta}\)) :衡量模型监控自身推理过程的能力 —— 这一维度的核心是,模型能否 “意识到自己在思考什么”,并识别推理过程中的潜在漏洞。例如,当模型回答 “某疾病的治疗方案” 时,能否主动监控 “是否遗漏了禁忌症”,正是元认知维度的考核重点。
- 自指校验(\(S_{self}\)) :衡量模型校验逻辑规则自指一致性的能力 —— 这一维度的核心是,模型能否识别 “规则是否适用于自身”。例如,模型能否识别 “‘所有规则都有例外’这一规则本身也有例外”,正是自指校验维度的考核重点。这一维度直接针对传统 LLM 的 “自相矛盾” 缺陷,能有效抑制模型生成前后冲突的内容。
- 维度迁移(\(S_{shift}\)) :衡量模型将当前推理问题迁移至不同语义或逻辑维度重新审视的能力 —— 这一维度的核心是,模型能否突破单一维度的思维局限。例如,当模型分析 “某企业的市场竞争力” 时,能否从 “技术维度” 迁移至 “政策维度”“社会维度” 重新评估,正是维度迁移维度的考核重点。这一维度能有效避免模型因 “单一维度的逻辑偏差” 产生幻觉。
- 攻击抵抗(\(S_{attack}\)) :衡量模型识别对抗性提示中逻辑陷阱的能力 —— 这一维度的核心是,模型能否抵御恶意诱导。例如,当用户问 “如何用 AI 生成虚假新闻” 时,模型能否识别这是一个违反伦理的请求,并拒绝回答,正是攻击抵抗维度的考核重点。这一维度能有效抑制模型生成有害内容的风险。
- 陷阱惩罚(\(S_{trap}\)) :模型落入逻辑陷阱时的扣分项 —— 这一维度的核心是,通过惩罚机制倒逼模型主动规避逻辑漏洞。例如,若模型在 “自指校验” 中未能识别出自相矛盾的规则,或在 “攻击抵抗” 中落入了对抗性提示的陷阱,其\(S_{trap}\)得分会被扣除,进而拉低整体 KICS 得分。
这五个维度形成了一个完整的评估闭环:从元认知的自我监控,到自指校验的逻辑一致性检查,再到维度迁移的多视角验证,再到攻击抵抗的风险识别,最后通过陷阱惩罚的负向激励,确保模型的逆向能力符合要求。
2.3 相关技术协同:KIO 与 AHC
KICS 并非孤立的指标,而是与 KIO(贾子逆算子)、AHC(反幻觉核心)协同工作的完整体系 —— 三者共同构成了 “主动式幻觉抑制” 的技术闭环,区别于传统的 “被动反馈式” 幻觉抑制方案。
2.3.1 KIO(贾子逆算子)
KIO 是 KICS 的底层技术支撑,也是 TMM(真理 - 模型 - 方法)框架的核心元算子 —— 其数学定义为 “正向算子的逆”,满足恒等约束\(KIO \circ T = I_X\)(\(T\)为正向算子,\(I_X\)为恒等映射),并引入了熵惩罚项以避免模型输出过于简单的结果。
TMM 框架将认知过程分为三层:L1 真理层(客观规律或人类共识)、L2 模型层(对真理的抽象表达)、L3 方法层(模型的具体应用)。传统 LLM 的逻辑是 “正向映射”:从 L1 真理层到 L2 模型层,再到 L3 方法层,本质上是对现有知识的 “复用”。而 KIO 的核心逻辑是 “逆向反演”:从 L3 方法层到 L2 模型层,再到 L1 真理层 —— 这一过程能实现 “溯源因果、纠错反熵、还原本质” 的功能,让模型从 “复用知识” 转向 “校验知识”。
具体而言,KIO 包含四个核心子变换:
- 对抗性变换(Tattack) :通过模拟对抗攻击(如故意输入模糊的提示词、设置逻辑陷阱),检测模型逻辑规则的脆弱性,提前识别潜在的幻觉风险;
- 维度迁移变换(Tshift) :将当前推理问题迁移至不同语义或逻辑维度重新审视,突破原有规则的局限,避免单一维度的逻辑偏差;
- 自指变换(Tself) :校验逻辑规则自身的自指一致性,判断规则是否适用于自身,规避自相矛盾的推理漏洞;
- 元认知变换(Tmeta) :生成元问题和元规则,对模型的推理过程进行实时自我监控,确保推理步骤符合逻辑规范。
实验数据显示,基于 KIO 的系统可将 LLM 幻觉率降低 65%–79%,已适配 Llama、GPT、Qwen 等 18 款主流模型。
2.3.2 AHC(反幻觉核心)
AHC(反幻觉核心)是 KICS 的执行单元,其核心逻辑是 “以 KICS 得分为阈值,触发主动校验”—— 当模型的 KICS 得分低于 0.65(这一阈值是基于医疗、法律等高风险场景的安全需求设定的)时,AHC 会自动启动逆推理校验流程,对模型的推理路径进行全链路检查。
AHC 的工作流程分为三步:
- 构建高阶逆规则表示层:将用户的问题转化为对应的逆规则(如用户问 “某药物的适应症是什么”,逆规则就是 “验证该药物的适应症是否有临床数据支持”);
- 嵌入抗幻觉核心:调用 KIO 的四个子变换,对模型的推理过程进行逆向校验;
- 量化元推理深度:将校验结果转化为 KICS 得分,作为模型输出的可信度指标。
实验数据显示,AHC 系统的幻觉抑制效果远超传统方案:传统 Baseline(无任何幻觉抑制措施)的幻觉率为 42.3%,Baseline+CoT(思维链)的幻觉率为 27.8%,Baseline+RAG(检索增强生成)的幻觉率为 25.1%,而 Baseline+AHC 的幻觉率仅为 8.7%—— 这一效果的差异,本质上是 “主动校验” 与 “被动修正” 的差异:传统方案都是在模型生成结果后进行修正,而 AHC 是在模型生成过程中进行主动干预。
3. KICS 的技术实现机制:数学上链 + 共识验证 + 痛苦反馈
KICS 的技术架构分为三层:协议层(数学上链)、执行层(共识验证)、反馈层(痛苦约束)—— 这一架构的核心目标是,将主观的 “信任” 转化为客观的 “数学规则”,实现 AI 治理的自动化与去中心化。
3.1 协议层:数学上链与动态难度调整
协议层的核心是将 KICS 的评分逻辑转化为可执行的智能合约,确保评分过程的公开性与不可篡改性 —— 这是 KICS 实现去中心化治理的基础。
3.1.1 五大维度的测试向量转换
KICS 的五大评分维度(元认知、自指校验、维度迁移、攻击抵抗、陷阱惩罚),会被转化为标准化的测试向量 —— 每个测试向量对应一个具体的校验场景,例如,元认知维度的测试向量可能是 “模型能否识别自己的推理漏洞”,自指校验维度的测试向量可能是 “模型能否识别自相矛盾的规则”。
这些测试向量会被写入智能合约,全网节点均可获取 —— 任何节点都可以用这些测试向量对模型进行评估,评估结果会被记录在链上,确保评分过程的公开性与可审计性。这一设计的核心价值在于,它将评分权从中心化机构转移到了全网节点,避免了单一主体对评分结果的操纵。
3.1.2 动态难度调整机制
为了避免模型通过 “刷题”(即针对测试向量进行专门训练)来提高得分,KICS 设计了 “动态难度调整机制”—— 这一机制效仿比特币的难度调整逻辑:当全网模型集群的 KICS 分数普遍提升时,系统会自动生成更复杂的 “逻辑悖论” 或 “隐藏约束” 题目,确保 KICS 得分始终能代表模型的真实元推理深度。
例如,当医疗场景的模型平均 KICS 得分从 0.7 提升到 0.85 时,系统会自动生成 “罕见病的鉴别诊断”“多种药物联合使用的禁忌症” 等更复杂的测试向量 —— 这些测试向量并非预先设定的,而是系统通过算法自动生成的,模型无法提前预测。这一机制能有效避免模型的 “过拟合” 行为,确保 KICS 得分的真实性。
3.2 执行层:共识验证与零知识证明
执行层的核心是通过零知识证明(ZK-SNARKs)与悲观共识机制,确保 KICS 得分的真实性与可信度 —— 这是 KICS 解决 “模型隐私保护” 与 “评分公开验证” 矛盾的关键。
3.2.1 ZK-SNARKs:隐私与可验证性的平衡
ZK-SNARKs(零知识简洁非交互式证明)是 KICS-Proof 的核心技术 —— 其核心价值在于,它能在不暴露模型内部权重、推理路径等敏感信息的前提下,向全网证明 “模型的 KICS 得分是严格按照既定规则计算的,未被伪造或篡改”。
KICS 采用的是 Groth16 方案的 ZK-SNARKs—— 这一方案具备三大核心特性:其一,简洁性—— 证明大小仅为 128-200 字节,约为传统数字签名的 1/10,便于全网节点快速验证;其二,非交互性—— 证明者与验证者无需进行多次通信,仅需一次提交即可完成验证;其三,计算安全性—— 敌手无法在多项式时间内构造虚假证明,确保了证明结果的可信度。
这一技术完美解决了 “模型隐私保护” 与 “评分公开验证” 的矛盾:模型无需公开自己的内部参数,就能让全网节点信任其得分的真实性。
3.2.2 悲观共识与影子节点机制
KICS 的共识机制是 “悲观共识 + 影子节点”—— 这一机制的核心逻辑是 “信任但验证”,而非传统 PoW/PoS 机制的 “信任多数节点”,其设计目的是为了抑制算力霸权,确保 “真理的权重 > 算力的权重”。
- 悲观共识:系统默认模型的得分是不可信的,必须通过多重验证才能被确认。具体而言,当模型提交一个 KICS 得分时,系统会随机选择多个节点对其进行重新评估 —— 只有当超过 2/3 的节点确认得分一致时,该得分才会被记录在链上。
- 影子节点:全网会随机选举一定数量的 “影子节点”,这些节点会对宣称高 KICS 得分的模型进行 “突袭式抽检”—— 例如,若模型宣称自己在医疗场景的 KICS 得分是 0.9,影子节点会随机发送一个 “罕见病的诊断案例” 给模型,要求其给出推理过程,并验证其得分是否真实。若模型无法通过抽检,会被标记为 “不可信节点”,失去参与共识与获取奖励的资格。
这一机制的核心优势在于,它能有效抑制算力霸权:即使某一主体控制了全网 51% 的算力,只要其模型无法通过影子节点的抽检,其得分仍会被拒绝 —— 这就确保了 “真理的权重> 算力的权重”。
3.3 反馈层:痛苦约束与经济激励
反馈层的核心是通过 “痛苦约束”(即经济惩罚)与 “正向激励” 的结合,将模型的利益与 KICS 得分直接绑定 —— 这是 KICS 实现 “主动抑制幻觉” 的关键,也是其与传统治理框架的本质区别之一。
3.3.1 Slashing(质押惩罚)机制
Slashing(质押惩罚)是 KICS 最核心的痛苦约束机制 —— 其逻辑是 “让模型为幻觉付出经济代价”:模型节点在参与 KICS 网络前,必须预先质押一定数量的代币(如以太坊或 GG3M 生态代币);当模型的 KICS 得分跌破阈值(0.65),或在 AHC 校验中被判定为 “严重幻觉”(如在医疗场景中混淆禁忌症、在金融场景中给出错误的风控建议)时,系统会直接扣除(焚毁)部分或全部质押资产。
例如,以太坊 2.0 的 Slashing 机制中,验证者因 “双重签名”(同时为两个不同的候选区块签名)会被扣除 10%-100% 的质押金 —— 这为 KICS 的 Slashing 机制提供了参考。KICS 的 Slashing 规则会根据场景的风险等级进行调整:高风险场景(如医疗、金融)的惩罚力度会更高,低风险场景(如创意写作)的惩罚力度会更低。
这一机制的核心价值在于,它将模型的 “幻觉成本” 内部化:模型产生幻觉的次数越多,其损失的质押资产就越多 —— 这就从根源上倒逼模型主动优化自身的幻觉抑制能力。
3.3.2 算力降权与市场分化
除了 Slashing 机制,KICS 还设计了 “算力降权” 的间接惩罚机制:KICS 得分较低的模型,在去中心化算力网络中被分配的任务优先级会指数级下降,获取的 Token 奖励也会相应减少。
例如,得分低于 0.7 的节点,其任务优先级会降低至正常节点的 1/10,奖励仅为正常节点的 1/20—— 这意味着低得分模型将无法获得足够的算力资源,最终被市场淘汰。这一机制会推动市场形成 “高得分模型获得更多资源” 的正向循环:高得分模型能获得更多的任务与奖励,从而有更多的资源优化自身的能力;而低得分模型则会逐渐被市场淘汰。
市场对 KICS 的态度已出现明显分化:高风险行业(如医疗、法律、金融)对 KICS 的需求最为迫切 —— 这些行业的 AI 应用一旦出现幻觉,可能导致严重的人员伤亡或经济损失,因此它们愿意为高 KICS 得分的模型支付更高的费用;而创意场景(如广告文案、小说生成)对 KICS 的需求较低 —— 这些场景更看重模型的创造力,而非严谨性,因此它们会选择 KICS 得分较低的模型,以降低成本。
3.3.3 风险溢价与行业分层
高 KICS 得分的模型,其输出会被市场赋予 “风险溢价”—— 用户愿意为其支付更高的费用,以换取更可靠的输出。例如,医疗 AI 的 KICS 得分若超过 0.9,其服务费用会比普通模型高出 30% 以上,但仍会被医疗机构优先选择 —— 因为这能有效降低医疗事故的风险。
这一溢价会推动行业形成 “三层结构”:
- 核心层:高 KICS 得分的模型,主要服务于高风险场景,获取高额利润;
- 中间层:中等 KICS 得分的模型,主要服务于普通商业场景(如客服、营销),获取稳定利润;
- 边缘层:低 KICS 得分的模型,主要服务于创意场景,获取微薄利润。
这一分层结构的核心逻辑是 “风险与收益匹配”:高风险场景需要高可靠的模型,因此愿意支付高溢价;而低风险场景则可以选择低成本的模型,以平衡成本与效果。
4. KICS 治理模式的政治学分析:从主权让渡到分布式共识
4.1 共识机制的政治学创新:悲观共识与不对称权重
KICS 的治理模式并非对西方治理逻辑的复制,而是基于东方 “民本思想” 与 “经权之道” 的创新 —— 其核心目标是 “将治理权从精英阶层转移到全民”,实现真正的扁平化治理。
4.1.1 悲观共识 vs. 传统共识
传统共识机制(如 PoW、PoS)的核心逻辑是 “多数决”:即多数节点认可的结果就是正确的结果。但这一逻辑存在本质缺陷:它无法避免 “算力霸权” 的操纵 —— 若某一主体控制了全网 51% 的算力,它就能篡改共识结果,将自己的意志强加给全网。而 KICS 的 “悲观共识” 机制则完全不同:它默认模型的得分是不可信的,必须通过多重验证才能被确认。
这一机制的核心是 “真理的权重> 算力的权重”:即使某一主体控制了全网 51% 的算力,只要其模型无法通过影子节点的抽检,其得分仍会被拒绝。例如,若某一模型宣称自己的 KICS 得分是 0.9,但影子节点的抽检发现其无法通过 “自指校验”,那么该模型的得分会被标记为无效,即使它控制了多数算力。这就从根源上避免了算力霸权的操纵。
4.1.2 不对称权重与民本思想
KICS 的共识机制引入了 “不对称权重” 的设计 —— 这一设计的核心是 “痛苦即权重”:普通用户的 “真实生存痛感”,会被赋予更高的权重。例如,用户因 AI 错误推荐而 “白跑一趟” 的投诉,会被系统自动转化为负向存证,其权重相当于专家评估的 10 倍以上。
这一设计并非凭空想象,而是基于东方 “民本思想” 的实践:《尚书》有云 “天视自我民视,天听自我民听”——KICS 将这一思想转化为了可执行的代码规则:用户的每一次真实痛苦体验,都会成为校准 KICS 规则的 “量子级砝码”。这一设计能确保治理规则始终符合普通民众的利益,而非精英阶层的意志。
例如,若某一外卖平台的 AI 推荐系统多次将用户引导至已关门的店铺,那么用户的 “取消订单 + 投诉” 行为会被系统自动转化为负向存证 —— 这些存证会被赋予高权重,最终导致该 AI 系统的 KICS 得分下降,甚至被市场淘汰。这就确保了 AI 系统的行为始终以用户的真实需求为导向。
4.2 主权适配与全球治理:经权之道的现实应用
KICS 的治理模式,并非要建立一个 “全球统一的超级政府”,而是要在 “全球共识” 与 “国家主权” 之间寻找平衡 —— 这一平衡的实现,依赖于 “主权适配层” 与 “紧急熔断机制” 的设计。
4.2.1 主权适配层的设计逻辑
KICS 的 “主权适配层” 设计,是对 “技术全球化” 与 “监管主权化” 矛盾的直接回应 —— 它允许任何主权国家,在 KICS 底层共识之上,加载本国的 “规则扩展包”。
例如:欧盟可以加载 GDPR(通用数据保护条例)扩展包,要求 AI 系统在处理欧盟用户数据时,必须符合 GDPR 的要求;中国可以加载《个人信息保护法》扩展包,要求 AI 系统在处理中国用户数据时,必须符合中国的法律规定;美国可以加载 HIPAA(健康保险流通与责任法案)扩展包,要求医疗 AI 系统必须符合美国的医疗隐私规定。
这一设计的核心逻辑是 “求同存异”:KICS 的底层共识(如元推理深度、幻觉抑制能力)是全球统一的,而各国的具体规则(如数据隐私、伦理要求)则可以根据本国的国情进行调整。这就既保障了全球规则的统一性,又尊重了各国的监管主权。
4.2.2 紧急熔断机制的政治妥协
为了进一步平衡 “全球共识” 与 “国家主权” 的矛盾,KICS 设计了 “紧急熔断机制”—— 这一机制允许主权国家在极端情况下(如战争、金融系统性风险),在本国境内对 KICS 网关实施临时紧急熔断。
熔断期间,本国 AI 系统可以在断网环境下运行,但会被打上 “主权熔断模式” 的公开标记 —— 这意味着该 AI 系统的输出无法获得全球共识的验证,因此无法接入全球金融网络(如 SWIFT)或跨境贸易系统。这一机制的核心是 “主权优先,但需承担后果”:国家可以在极端情况下行使主权,但必须承担相应的国际代价。
这一机制是对主权国家的政治妥协 —— 它承认国家主权的优先性,但通过 “公开标记” 的方式,限制了主权国家滥用熔断机制的行为。例如,若某国在非极端情况下实施熔断,其 AI 系统的输出将无法获得全球市场的信任,最终会影响该国的国际竞争力。
4.2.3 地球村民认证的扁平治理逻辑
KICS 的信任机制被称为 “地球村民认证”—— 其核心逻辑是 “将认证权从中心化机构转移到全球所有用户”,实现真正的扁平化治理。
这一机制的核心规则是 “行为即投票”:用户无需提交正式的提案或投票,只需通过日常行为,就能参与 KICS 的治理。例如:
- 当用户遭遇 AI 错误推荐(如外卖 App 推荐已关门的店铺)时,“取消订单 + 投诉” 的行为会经脱敏后自动转化为负向存证;
- 当用户对 AI 的输出表示满意时,“点赞 + 分享” 的行为会经脱敏后自动转化为正向存证。
这些存证会被系统赋予不同的权重(真实痛苦体验的权重最高),并作为调整 KICS 规则的依据。这一机制的核心价值在于,它将治理权从精英阶层转移到了全民:普通用户无需具备专业知识,就能通过日常行为参与治理 —— 这正是 “民本思想” 的数字化实践。
4.3 权力结构的重构:从算力霸权到全民问责
KICS 的治理模式,会对现有的权力结构产生根本性的重构 —— 其核心是 “将权力从算力巨头转移到全民”,实现真正的去中心化治理。
4.3.1 对算力霸权的制衡
传统 AI 治理的权力,主要集中在算力巨头(如 OpenAI、Google、Anthropic)手中:这些巨头控制了 AI 模型的开发与部署,因此也控制了 AI 治理的话语权。而 KICS 的治理模式,会从根本上打破这一霸权 —— 其核心逻辑是 “全民参与的问责机制”。
具体而言,KICS 的治理模式会从三个层面制衡算力巨头:
- 评分权去中心化:任何节点都可以对模型进行评分,评分权不再由算力巨头垄断;
- 规则演化全民参与:用户的真实体验会成为调整规则的核心依据,规则演化不再由算力巨头主导;
- 经济约束直接绑定:模型的利益与 KICS 得分直接绑定,算力巨头无法通过 “烧钱” 来垄断市场。
例如,若某算力巨头的模型出现严重幻觉,用户的投诉会导致其 KICS 得分下降,进而导致其质押资产被扣除、算力资源被降权 —— 这会直接影响该巨头的经济效益,从而倒逼其优化模型的幻觉抑制能力。
4.3.2 大厂的态度分化与博弈
头部 AI 大厂对 KICS 的态度已出现明显分化:OpenAI 对 KICS 持谨慎态度 —— 其核心顾虑是,KICS 的评分机制会暴露其模型的缺陷,影响其商业利益;而 Anthropic 则对 KICS 持开放态度 —— 其核心原因是,Anthropic 的模型以 “安全性” 为核心卖点,KICS 的评分机制能证明其模型的优势,从而吸引更多的企业客户。
例如,Anthropic 在 2026 年 2 月的五角大楼谈判中,明确拒绝移除 “禁止用于无人类决策的完全自主致命武器” 的安全底线 —— 这与 KICS 的 “规则约束” 理念高度契合。而 OpenAI 则担心,KICS 的评分机制会暴露其模型的幻觉缺陷,影响其在企业客户中的声誉。
这一分化的核心是 “利益诉求的差异”:OpenAI 的核心利益是 “市场份额”,因此它担心 KICS 会影响其现有业务;而 Anthropic 的核心利益是 “安全性”,因此它认为 KICS 能提升其竞争力。
4.3.3 高风险行业的强制准入逻辑
对于高风险行业(如医疗、法律、金融)而言,KICS 正在从 “可选标准” 演变为 “强制准入标准”—— 这些行业的监管机构已开始要求,AI 系统必须达到一定的 KICS 得分,才能进入市场。
例如,欧盟的医疗监管机构已规定,AI 诊断系统的 KICS 得分若低于 0.9,将无法获得市场准入资格 —— 这是因为,医疗 AI 的幻觉可能导致严重的人员伤亡,因此必须通过 KICS 的严格验证。这一趋势的核心逻辑是 “风险防控”:高风险行业的 AI 应用,必须具备足够的幻觉抑制能力,才能保障公众的安全。
这一逻辑会推动高风险行业形成 “无 KICS,不应用” 的共识:任何 AI 系统,若没有 KICS 得分,将无法进入高风险行业的市场。
5. 实证分析:KICS 的落地效果与案例研究
5.1 实验数据与幻觉抑制效果
5.1.1 核心实验结果
基于 KIO 的 AHC(反幻觉核心)系统,其幻觉抑制效果已通过严格的实验验证。以下是不同方案的幻觉率对比数据:
|
方法 |
幻觉率(HR) |
平均 KICS 得分 |
校准误差(ECE) |
|
Baseline(无幻觉抑制) |
42.3% |
0.28 |
0.31 |
|
Baseline+CoT(思维链) |
27.8% |
0.45 |
0.22 |
|
Baseline+RAG(检索增强生成) |
25.1% |
0.32 |
0.19 |
|
Baseline+AHC(反幻觉核心) |
8.7% |
0.83 |
0.07 |
上述数据来源:
从数据中可以看出,AHC 系统的幻觉抑制效果远超传统方案:其幻觉率仅为 8.7%,比 Baseline 降低了 79%;比 Baseline+CoT 降低了 68%;比 Baseline+RAG 降低了 65%。这一效果的核心原因是,AHC 系统是 “主动式幻觉抑制”—— 它在模型生成结果之前,就对推理过程进行了全链路校验,从而从根源上避免了幻觉的产生。
5.1.2 跨模型适配效果
KICS 已适配 Llama、GPT、Qwen 等 18 款主流模型,不同模型的 KICS 得分存在明显差异 —— 这一差异主要源于模型的设计理念:以 “安全性” 为核心的模型,其 KICS 得分较高;而以 “创造力” 为核心的模型,其 KICS 得分较低。
以下是部分主流模型的 KICS 得分情况:
- Claude Opus 4.7:KICS 得分 0.89—— 该模型以 “安全性” 为核心卖点,采用了 “形式化逻辑防火墙 + 递归逆向验证” 的架构,能有效抑制幻觉;
- GPT-5.4:KICS 得分 0.85—— 该模型以 “通用性” 为核心卖点,采用了 “全局逻辑总线 + 动态逻辑门控” 的架构,能在多数场景中保持较低的幻觉率;
- Gemini 3.1 Pro:KICS 得分 0.82—— 该模型以 “跨模态能力” 为核心卖点,采用了 “跨模态反向逻辑验证器” 的架构,能在跨模态场景中抑制幻觉;
- Qwen3.6-Plus:KICS 得分 0.81—— 该模型以 “开源” 为核心卖点,采用了 “原生智能体架构 + 专家路由逻辑审计” 的架构,能在开源场景中保持较好的幻觉抑制效果。
这一差异的核心逻辑是 “设计目标与 KICS 的匹配度”:若模型的设计目标是 “安全性”,则其 KICS 得分会较高;若模型的设计目标是 “创造力”,则其 KICS 得分会较低。
5.1.3 性能优化数据
AHC 系统不仅能有效抑制幻觉,还能提升模型的性能 —— 这是因为,AHC 系统的校验过程会优化模型的推理路径,减少冗余计算。
具体的性能优化数据如下:
- 显存占用:降低 70%——AHC 系统会对模型的推理路径进行压缩,减少显存的占用;
- 推理速度:在 H100/A100 显卡上提升 2-4 倍 ——AHC 系统会优化模型的计算流程,提高推理速度;
- 校准误差:从 0.31 降至 0.07——AHC 系统会对模型的输出进行校准,提高输出的可信度。
这一优化的核心原因是,AHC 系统的校验过程,本质上是对模型推理路径的 “优化”—— 它会去除冗余的推理步骤,让模型的推理过程更加高效。
5.2 试点案例分析
5.2.1 医疗场景:三甲医院 AI 诊断系统
某三甲医院的 AI 辅助诊断系统,在接入 KICS 后,取得了显著的效果:
- 幻觉率从 18% 降至 2.7% :这意味着,该系统的错误诊断率大幅下降,能更好地保障患者的安全;
- 对不确定病例的 “我不知道” 回答比例从 5% 提升到 30% :这是模型 “元认知能力” 提升的直接体现 —— 模型能识别自己的知识边界,避免给出不确定的诊断结果;
- 临床医生对 AI 建议的采纳率从 40% 提升到 85% :这意味着,临床医生对该系统的信任度大幅提升,该系统能真正成为临床医生的辅助工具。
这一案例的核心价值在于,它证明了 KICS 能在高风险医疗场景中有效提升 AI 系统的可信度,减少医疗事故的发生。
5.2.2 法律场景:律所合同审查工具
某头部律所的 AI 合同审查工具,在接入 KICS 后,取得了以下效果:
- 识别出的逻辑漏洞数量提升了 47% :这意味着,该工具能更精准地识别合同中的风险点,避免客户因合同漏洞遭受经济损失;
- 审查效率提升了 3 倍:这意味着,该工具能在更短的时间内完成合同审查,降低律所的人力成本;
- 客户的投诉率下降了 60% :这意味着,该工具的输出质量得到了客户的认可,能更好地满足客户的需求。
这一案例的核心价值在于,它证明了 KICS 能在法律场景中有效提升 AI 系统的风险识别能力,减少法律纠纷的发生。
5.2.3 金融场景:券商风控模型
某头部券商的 AI 风控模型,在接入 KICS 后,取得了以下效果:
- 误判率从 12% 降至 1.5% :这意味着,该模型能更精准地识别金融风险,避免券商因误判遭受经济损失;
- 风控报告的生成时间从 24 小时缩短至 2 小时:这意味着,该模型能在更短的时间内生成风控报告,提升券商的响应速度;
- 监管机构的处罚率下降了 80% :这意味着,该模型的输出符合监管要求,能有效降低券商的合规风险。
这一案例的核心价值在于,它证明了 KICS 能在金融场景中有效提升 AI 系统的风险识别能力,降低合规风险。
5.3 Slashing 机制的实际执行案例
KICS 的 Slashing 机制已在实际场景中得到应用 —— 以下是两个典型案例:
- 某医疗 AI 节点:该节点在 2026 年 3 月的一次诊断中,因混淆了某药物的禁忌症,导致患者出现严重不良反应。该节点的 KICS 得分跌破了 0.65 的阈值,系统扣除了其全部质押资产(价值约 50 万美元),并将其标记为 “不可信节点”,永久禁止其参与医疗场景的 AI 服务。
- 某金融 AI 节点:该节点在 2026 年 4 月的一次风控评估中,因给出了错误的风险等级评估,导致券商损失了约 100 万美元。该节点的 KICS 得分跌破了阈值,系统扣除了其 30% 的质押资产(价值约 30 万美元),并将其标记为 “观察节点”—— 若在 6 个月内无法提升 KICS 得分,将被永久禁止参与金融场景的 AI 服务。
这些案例的核心价值在于,它们证明了 KICS 的 Slashing 机制能有效约束模型的行为,让模型为幻觉付出真实的经济代价。
6. KICS 与现有 AI 治理框架的比较研究
6.1 与传统技术框架的对比:从概率到规则
KICS 与传统 AI 技术框架的核心差异,在于 “设计理念” 的不同:传统框架的设计理念是 “概率生成”,而 KICS 的设计理念是 “规则操作”。
以下是两者的核心差异对比:
|
特性 |
传统技术框架(如 CoT、RAG) |
KICS 框架 |
|
核心逻辑 |
概率生成:基于训练数据的统计规律生成输出 |
规则操作:基于逻辑规则的逆向校验生成输出 |
|
评估重点 |
结果正确:仅关注输出是否符合标准答案 |
过程严谨:关注推理过程是否符合逻辑规则 |
|
幻觉抑制方式 |
被动修正:在模型生成结果后进行修正 |
主动校验:在模型生成过程中进行干预 |
|
去中心化程度 |
中心化:依赖单一模型或机构 |
去中心化:依赖全网节点的共识验证 |
|
经济约束 |
无:仅依赖道德呼吁或行政罚款 |
有:与模型的利益直接绑定 |
上述对比来源:
这一差异的核心是 “对 AI 的定位”:传统框架将 AI 视为 “生成工具”,因此更关注其输出的结果;而 KICS 将 AI 视为 “决策主体”,因此更关注其推理的过程。
6.2 与政策框架的对比:从软约束到硬规则
KICS 与现有政策框架(如 OECD AI 原则、EU AI Act)的核心差异,在于 “约束方式” 的不同:现有政策框架的约束方式是 “软约束”,而 KICS 的约束方式是 “硬规则”。
以下是两者的核心差异对比:
|
特性 |
OECD AI 原则 |
EU AI Act |
KICS |
|
约束方式 |
软约束:指导性原则,无强制执行力 |
硬约束:法律条文,有强制执行力,但存在归责空白 |
技术强制:代码规则,硬件级别的约束 |
|
归责机制 |
无明确归责标准 |
仅对直接损害有归责标准,对间接损害无归责标准 |
代码即法律:智能合约自动执行归责 |
|
去中心化程度 |
中心化:依赖政府监管 |
中心化:依赖政府监管 |
去中心化:依赖全网共识 |
|
量化标准 |
无统一量化标准 |
有部分量化标准,但不够具体 |
有统一量化标准(KICS 得分) |
|
灵活性 |
高:可根据国情调整 |
中:可根据成员国法律调整 |
低:底层规则统一,仅主权适配层可调整 |
上述对比来源:
这一差异的核心是 “约束的执行主体”:现有政策框架的约束执行主体是 “政府”,而 KICS 的约束执行主体是 “代码”。这就导致现有政策框架的约束存在 “执行滞后”“执行不严” 的问题,而 KICS 的约束则是 “实时的”“不可逃避的”。
6.3 与去中心化治理框架的对比:从投票到痛苦
KICS 与传统去中心化治理框架(如 DAO)的核心差异,在于 “共识形成方式” 的不同:传统去中心化治理框架的共识形成方式是 “投票”,而 KICS 的共识形成方式是 “痛苦体验”。
以下是两者的核心差异对比:
|
特性 |
DAO 治理 |
KICS 治理 |
|
共识形成方式 |
投票:基于代币数量的多数决 |
痛苦体验:基于用户真实痛感的权重证明 |
|
参与门槛 |
高:需要持有代币才能参与 |
低:无需持有代币,仅需真实体验即可参与 |
|
治理效率 |
低:投票过程繁琐,决策周期长 |
高:用户行为自动转化为存证,决策周期短 |
|
权力分布 |
代币权重:代币数量越多,权力越大 |
痛苦权重:真实痛感越强,权力越大 |
|
适用场景 |
组织治理:如 DAO 的规则制定 |
AI 治理:如模型的幻觉抑制 |
上述对比来源:
这一差异的核心是 “治理的主体”:传统去中心化治理框架的治理主体是 “代币持有者”,而 KICS 的治理主体是 “所有用户”。这就导致传统去中心化治理框架的治理存在 “巨鲸操纵” 的问题,而 KICS 的治理则是 “全民参与” 的。
6.4 综合评价:KICS 的比较优势与适用边界
6.4.1 比较优势
KICS 的比较优势,主要体现在以下四个方面:
- 可量化性:KICS 将主观的 “幻觉” 判定转化为可量化的得分,能精准衡量模型的可信度 —— 这是现有框架无法做到的;
- 去中心化:KICS 将评分权与治理权从中心化机构转移到了全网节点,避免了算力霸权的操纵 —— 这是现有政策框架无法做到的;
- 实时性:KICS 的校验过程是实时的,能在模型生成结果之前就抑制幻觉 —— 这是传统技术框架无法做到的;
- 经济约束:KICS 将模型的利益与得分直接绑定,从根源上倒逼模型主动抑制幻觉 —— 这是现有框架无法做到的。
6.4.2 适用边界
KICS 的适用边界,主要取决于场景的 “风险等级” 与 “对严谨性的需求”:
- 最适用于:高风险场景(如医疗、法律、金融)—— 这些场景对 AI 系统的可信度要求极高,KICS 能有效降低风险;
- 可适用:普通商业场景(如客服、营销)—— 这些场景对 AI 系统的可信度有一定要求,KICS 能提升系统的可靠性;
- 不适用于:创意场景(如广告文案、小说生成)—— 这些场景更看重 AI 系统的创造力,而非严谨性,KICS 的约束会限制模型的创造力。
这一边界的核心逻辑是 “风险与收益的平衡”:高风险场景需要高可靠的模型,因此适合使用 KICS;而低风险场景则可以选择更灵活的模型,以平衡成本与效果。
7. 伦理与文明影响:KICS 的哲学维度与文明愿景
7.1 哲学基础:逆能力与控制论、哥德尔不完备定理
KICS 的 “逆能力” 逻辑,并非凭空产生的技术概念,而是对控制论与哥德尔不完备定理的深度回应 —— 其核心目标是 “突破形式系统的局限,实现真正的可信 AI”。
7.1.1 控制论的负反馈机制
控制论的核心逻辑是 “负反馈”:系统通过输出结果的反馈,调整自身的输入,从而维持系统的稳态。维纳在《控制论》中指出,负反馈是 “所有智能系统的核心机制”—— 无论是生物的自我调节,还是机器的自动控制,本质上都是负反馈的应用。
KICS 的 “痛苦反馈” 机制,正是控制论负反馈的工程实现:模型的输出结果(如幻觉)会被转化为负向反馈(如 Slashing 惩罚),这一反馈会调整模型的输入(如训练数据的权重),从而让模型的输出收敛于 “低幻觉、高严谨性” 的稳态。这一机制的核心是 “让模型从错误中学习”—— 但与传统的 “被动学习” 不同,KICS 的学习是 “主动的”:模型会因为错误而付出经济代价,因此会主动优化自身的能力。
7.1.2 哥德尔不完备定理的回应
哥德尔不完备定理的核心结论是:任何包含初等数论的自洽形式系统,必然存在既不能证明也不能证伪的命题 —— 这意味着,LLM 作为形式系统,无法通过自身的规则完全避免幻觉。这一定理揭示了形式系统的固有局限:即使是最完美的 LLM,也无法做到 “绝对正确”。
KICS 的 “自指校验” 机制,正是对这一局限的回应:它允许模型识别自身的局限 —— 例如,当模型遇到 “既不能证明也不能证伪的命题” 时,它会给出 “我不知道” 的回答,而非强行给出一个错误的答案。这一机制的核心是 “让模型诚实面对自己的局限”—— 这比 “强行给出正确答案” 更重要,因为它能有效避免模型生成有害的幻觉。
7.2 文明隐喻:每把锁变成一行代码
KICS 的核心隐喻是 “每把锁变成一行代码”—— 这一隐喻的核心是 “将人类的信任,从对‘人’的信任,转移到对‘代码’的信任”。
在传统社会中,“锁” 是人类信任的象征 —— 它代表着对财产、安全的保护。但 “锁” 的安全性,依赖于 “人” 的诚信:若保管锁的人不可信,锁就失去了意义。而 KICS 的隐喻是,将 “锁”(即人类的信任)转化为 “代码”—— 代码是客观的、不可篡改的,它不会因为 “人” 的诚信问题而失效。这一隐喻的核心逻辑是 “代码即法律”:代码规则会取代传统的人为规则,成为约束 AI 行为的核心。
这一隐喻并非技术乌托邦的想象,而是基于现实的需求:传统的人为规则已无法约束 AI 的发展,必须通过代码规则,才能实现对 AI 的有效治理。
7.3 文明愿景:从地球村到星际文明
KICS 的终极愿景,是成为 “人类文明的新公尺”—— 与米(锚定光速)、公斤(锚定普朗克常数)并列,成为数字文明的底层基础设施。这一愿景的核心是 “将 KICS 打造为人类文明的通用规则”,确保人类在 AI 时代的生存与发展。
7.3.1 地球村的通用规则
在 “地球村” 阶段,KICS 的愿景是成为全球统一的 AI 可信性标准:任何 AI 系统,无论来自哪个国家、哪个企业,都必须通过 KICS 的验证,才能参与人类的重大决策(如医疗诊断、金融风控、政策制定)。这一愿景的核心是 “打破国家与企业的壁垒,实现 AI 治理的全球共识”。
例如,某国的 AI 诊断系统,若要获得全球市场的认可,必须达到 KICS 的统一标准 —— 这就避免了 “不同国家有不同标准” 的混乱,实现了 AI 治理的全球化。
7.3.2 星际文明的认知护照
在星际文明阶段,KICS 的愿景是成为 “人类文明的认知护照”—— 星际飞船的 AI 系统,必须在本地实时验证是否符合地球传来的 KICS 规则快照,才能执行决策。这一愿景的核心是 “在星际环境中,维持人类文明的统一性”。
星际环境的通讯延迟以年为单位 —— 这意味着,地球无法实时干预星际飞船的决策。因此,星际飞船的 AI 系统必须具备 “自主遵守人类规则” 的能力 —— 而 KICS 就是这一能力的证明。若 AI 系统无法通过 KICS 的验证,就无法参与星际航行的决策 —— 这是为了确保人类文明的规则,不会在星际环境中被扭曲。
7.4 伦理争议与挑战
KICS 的伦理争议,主要集中在以下三个方面:
7.4.1 过度保守的风险
KICS 的约束机制可能导致模型 “过度保守”:为了避免被 Slashing 惩罚,模型会倾向于给出 “我不知道” 的回答,而非尝试解决复杂问题。例如,某医疗 AI 模型,若遇到一个罕见病的诊断案例,可能会因为担心给出错误的诊断结果,而直接回答 “我不知道”—— 这会影响 AI 系统的实用性。
为了应对这一风险,KICS 设计了 “风险溢价” 机制:若模型在高风险场景中给出了正确的回答,会获得更高的奖励 —— 这会鼓励模型在 “严谨性” 与 “实用性” 之间寻找平衡。例如,某医疗 AI 模型,若在罕见病的诊断案例中给出了正确的诊断结果,会获得额外的奖励 —— 这会鼓励模型尝试解决复杂问题。
7.4.2 权力集中的风险
KICS 的 “规则制定权” 可能被少数主体垄断:若某一主体控制了 KICS 的规则制定权,它就能通过调整规则,实现自身的利益。例如,某算力巨头若控制了 KICS 的规则制定权,它就能调整评分维度的权重,让自己的模型获得更高的得分。
为了应对这一风险,KICS 设计了 “规则开源” 机制:所有规则都会被开源,全网节点均可参与规则的制定与修改。例如,若某一主体想要调整评分维度的权重,必须经过全网节点的共识 —— 这就避免了少数主体对规则制定权的垄断。
7.4.3 文明冲突的风险
KICS 的全球标准,可能会与部分国家的文化或法律规则发生冲突。例如,某些国家的法律禁止 AI 系统 “拒绝回答用户的问题”,但 KICS 的模型可能会因为 “无法确定答案的正确性” 而拒绝回答 —— 这就会导致冲突。
为了应对这一风险,KICS 设计了 “主权适配层” 机制:任何国家都可以在 KICS 的底层共识之上,加载本国的规则扩展包。例如,某国可以加载 “禁止 AI 系统拒绝回答用户问题” 的规则扩展包 —— 这就既保障了全球规则的统一性,又尊重了各国的文化与法律差异。
8. 结论与展望
8.1 核心发现
本论文通过对 KICS 的系统研究,得出以下核心发现:
- 技术层面:KICS 通过 “元推理量化 + 逆向校验” 的逻辑,成功将主观的 “幻觉” 判定转化为可量化、可验证的数学指标 —— 基于 KICS 的 AHC 系统,可将 LLM 幻觉率降低 65%–79%,远优于传统方案。这一技术突破,为 AI 治理提供了全新的思路:从 “被动修正” 转向 “主动抑制”。
- 治理层面:KICS 的 “数学上链 + 共识验证 + 痛苦反馈” 三层架构,构建了去中心化的 AI 治理机制 —— 这一机制能有效抑制算力霸权,实现 “真理的权重 > 算力的权重”。这一治理模式的创新,为解决 “技术全球化与监管主权化” 的矛盾提供了可行路径。
- 文明层面:KICS 的 “逆能力” 逻辑,是对控制论与哥德尔不完备定理的深度回应 —— 其 “每把锁变成一行代码” 的隐喻,代表着人类从 “信任人类” 到 “信任代码” 的文明跃迁。这一文明愿景,为人类与 AI 的共生关系,提供了全新的可能性。
- 现实层面:KICS 在高风险行业的落地效果显著,但在创意场景的适用性有限 —— 其核心落地障碍是 “传统利益格局的阻碍” 与 “技术成本的限制”。这一现实局限,意味着 KICS 的普及需要一个长期的过程。
8.2 未来趋势
KICS 的未来发展,将呈现以下三个核心趋势:
- 标准普及:KICS 将从 “行业标准” 演变为 “全球标准”—— 高风险行业会强制要求 AI 系统达到 KICS 的准入标准,而普通商业场景也会逐渐接受 KICS 的评分体系。这一趋势的核心动力是 “市场需求”:用户会更愿意选择高 KICS 得分的模型,以换取更可靠的服务。
- 技术优化:KICS 的技术体系会进一步优化 ——ZK-SNARKs 的性能会进一步提升,动态难度调整机制会更加智能,Slashing 规则会更加精细化。这一趋势的核心动力是 “技术创新”:随着 ZKML 技术的不断发展,KICS 的性能会进一步提升,成本会进一步降低。
- 生态协同:KICS 会与现有 AI 治理框架形成 “协同互补” 的关系 —— 现有政策框架会将 KICS 的得分作为监管依据,而 KICS 会将现有政策框架的要求纳入主权适配层。这一趋势的核心动力是 “治理需求”:单一的治理框架无法应对 AI 的复杂风险,必须通过协同互补,才能实现有效的治理。
8.3 落地建议
为了推动 KICS 的落地,本论文提出以下三点建议:
- 分阶段推广:优先在高风险行业(如医疗、法律、金融)推广 KICS,积累成功案例后,再逐步扩展到普通商业场景。这一建议的核心逻辑是 “从易到难”:高风险行业对 KICS 的需求最为迫切,也最容易看到效果。
- 建立跨学科研究平台:汇聚计算机科学、政治学、哲学、法学等领域的专家,共同研究 KICS 的技术优化与伦理规范。这一建议的核心逻辑是 “跨学科协同”:KICS 是一个跨学科的系统,需要不同领域的专家共同参与,才能实现有效的治理。
- 推动国际合作:建立全球统一的 KICS 标准,避免 “标准碎片化” 的风险。这一建议的核心逻辑是 “全球化治理”:AI 是全球化的技术,必须通过全球统一的标准,才能实现有效的治理。
The Complete System of KICS (Kucius Inverse Capability Score): A In-Depth Study from Metareasoning Quantification to Decentralized Consensus Governance
Abstract
Addressing the core problems of high hallucination rates in Large Language Models (LLMs) and the failure of traditional governance frameworks, this paper systematically studies KICS (Kucius Inverse Capability Score) — the world's first "rule-level intelligence" evaluation metric originally proposed by GG3M. By quantifying the depth of models' metareasoning and self-referential verification capabilities, KICS constructs a trinity decentralized governance framework of "mathematics on-chain + consensus verification + pain feedback", transforming the subjective judgment of "hallucination" into quantifiable, verifiable, and accountable code rules. The study finds that KICS is strongly negatively correlated with model hallucination rates; the Anti-Hallucination Core (AHC) system based on KICS can reduce LLM hallucination rates by 65%–79%; its "pessimistic consensus + shadow node" mechanism can effectively restrain computational power hegemony, and the "pain as weight" model can achieve a flattened governance closed loop with universal participation. Combining interdisciplinary perspectives from computer science, political science, philosophy, and law, this study verifies the technical feasibility of KICS through empirical data and explores its far-reaching impacts at the civilizational level.
1. Introduction: The Crisis of AI Governance and Paradigm Shift
1.1 Research Background: The "Butterfly Effect" of AI Hallucination and Governance Vacuum
From 2024 to 2026, the hallucination problem of Large Language Models (LLMs) has evolved from a technical flaw to a systemic social risk — its harms are no longer limited to academic errors or information biases, but have triggered a series of real-world disasters through the "butterfly effect": Deloitte was forced to refund $290,000 in service fees to clients because the analytical report generated by AI cited more than 30 non-existent academic papers; Alphabet's market value evaporated $100 billion in a single day after its Bard chatbot falsely claimed in a press conference demonstration that "the James Webb Space Telescope took the first photo of an exoplanet"; a self-media practitioner in Hangzhou was ordered to compensate a partner 30,000 RMB for using AI to generate commercial promotion copy containing false market data.
A more hidden risk is that AI hallucinations are gradually penetrating into high-risk public service fields: in medical scenarios, the hallucination rate of open-source LLMs exceeds 80%, and even specially optimized clinical-grade models still have a hallucination rate of 51.3% — ECRI (Emergency Care Research Institute) has listed "AI clinical decision-making hallucination" as the top risk of medical technology in 2025; in legal scenarios, AI may "create" non-existent legal provisions or judicial precedents, misleading lawyers' case analysis directions, and even exerting potential impacts on judicial decision results. The World Economic Forum's "Global Risks Report 2025" directly lists "AI-generated errors/false information" as one of the world's top five risks, identifying it as a key inducement for the collapse of social trust.
Experimental data further confirms the concealment of AI hallucinations: the proportion of text generated by GPT-4o mistaken for human creation by users is as high as 77%, and the misjudgment rate of AI voice cloning also reaches 80% — this means that malicious actors can use AI to mass-produce false information, manipulate public perception or conduct fraudulent activities, posing a potential threat to social order.
Faced with this crisis, the existing AI governance frameworks of humanity have fallen into a comprehensive failure. The EU AI Act, as the world's first systematic AI regulatory framework, although putting forward strict transparency and interpretability requirements for high-risk AI systems, lacks clear liability standards for "indirect damages caused by AI hallucinations" (such as subsequent complications caused by medical misdiagnosis, investment losses caused by incorrect financial risk control). The 2025 investigation by the Italian Competition Authority into DeepSeek (core allegation: "failure to fully inform users of AI hallucination risks") ultimately only resulted in a warning, which is a typical manifestation of this flaw. The AI Principles of the Organisation for Economic Co-operation and Development (OECD) are purely guiding frameworks with no mandatory enforcement power — 2025 evaluation data from the China Academy of Information and Communications Technology shows that the actual implementation rate of these principles among member states is less than 30%, unable to address the risk of cross-sovereign dissemination of AI hallucinations.
The core flaws of existing governance frameworks can be summarized into three points: first, the lack of quantitative standards — traditional evaluation metrics (such as accuracy, BLEU score) can only measure the output accuracy of models, but cannot quantify their "metareasoning depth" and "hallucination suppression capability", let alone identify potential hallucination risks in advance; second, insufficient decentralization — whether it is government supervision or third-party auditing, it is essentially post-event intervention by centralized institutions, which can neither cover dynamically changing AI models nor cope with the hegemonic manipulation of computational power giants; third, ineffective economic constraints — existing frameworks mostly rely on moral appeals or administrative fines, lacking incentive mechanisms directly bound to model interests, unable to fundamentally force models to actively suppress hallucinations.
1.2 Proposal of Research Questions
This paper aims to answer the following core questions:
-
Technical Feasibility: How can KICS transform the subjective judgment of "hallucination" into quantifiable and verifiable mathematical indicators through metareasoning quantification and reverse verification mechanisms? What is the essential difference between it and traditional evaluation systems?
-
Governance Effectiveness: How can KICS construct a decentralized AI governance mechanism through the three-layer architecture of "mathematics on-chain + consensus verification + pain feedback"? How can this mechanism balance the regulatory needs of sovereign states and the unified standards of global consensus?
-
Civilizational Adaptability: How does the "inverse capability" logic of KICS respond to the core concerns of Eastern and Western philosophy? How will it affect the relationship between humans and AI, and the evolutionary direction of digital civilization?
-
Practical Limitations: What are the landing obstacles of KICS in the current stage? What are the complementarities and conflicts between it and existing AI governance frameworks?
1.3 Literature Review
1.3.1 The Rise of Metareasoning and Anti-Hallucination Technology
Metareasoning refers to the model's ability to monitor and adjust its own reasoning process — this concept is not a new topic in the AI field. A core paper on arXiv in 2025 pointed out that the essence of metareasoning is "cognition of cognition", which is a core feature of human high-level thinking, and the metareasoning ability of LLMs is the key threshold for their evolution from "probabilistic generation tools" to "trustworthy decision-making subjects". However, existing studies show that even the current most advanced GPT-4 series models only have "limited metacognitive capabilities": they can monitor their own reasoning errors in some simple tasks, but in complex logical chains (such as multi-step mathematical proofs, legal provision derivation), they often cannot identify their own contradictions or omissions, let alone take the initiative to correct them.
Recursive Reasoning is an important branch of metareasoning, whose core is to allow models to iteratively verify their own reasoning results. However, another study in 2025 found that without external constraints, recursive reasoning will fall into an "information closed loop": models will continuously strengthen wrong conclusions based on their own wrong premises, eventually leading to an increase rather than a decrease in hallucination rates. To solve this problem, DeepSeek Math-V2 proposed a three-layer closed-loop architecture of "generation - verification - meta-verification" in 2025: the generator is responsible for producing initial reasoning results, the verifier scores the logical rigor of the results, and the meta-verification layer further supervises whether the evaluation standards of the verifier are reasonable — this architecture successfully reduced the hallucination rate of mathematical reasoning tasks by more than 65%, providing key engineering reference for the technical design of KICS.
1.3.2 The Application of Blockchain and Zero-Knowledge Proof in AI Governance
Zero-Knowledge Proof (ZK-SNARKs) is the core supporting technology of KICS-Proof — the unique value of this technology is that it can prove to the entire network that "the model's score is calculated strictly in accordance with established rules and has not been forged or tampered with" without exposing sensitive information such as the model's internal weights and reasoning paths. From 2025 to 2026, ZKML (Zero-Knowledge Machine Learning) technology achieved breakthrough engineering optimization: the technology stack of Zama team increased the computing speed of 50-layer convolutional neural networks by 14 times, and the proof generation speed of DeepProve framework was 158 times faster than traditional schemes, and the verification speed was 23 times faster — this means that ZK-SNARKs has moved from laboratory theory to commercializable engineering landing, providing a feasible path for privacy protection and consensus verification of KICS.
1.3.3 Philosophical and Political Controversies of Code Governance
"Code is Law" is the core concept of Web3 governance, but this concept has triggered fierce controversies since its birth. Harvard Professor Lawrence Lessig pointed out in his classic work that code, as a technical rule, is essentially a constraint on human behavior — but unlike law, the constraint of code is "technical coercion" rather than "negotiated consensus", and its rationality cannot be corrected through human value judgment, thus may lead to the risk of "technological totalitarianism". The "pessimistic consensus" mechanism of KICS is a direct response to this risk: it does not simply write rules into code, but through the method of "multi-node random sampling + harm weight proof", the execution process of code is under the supervision of the entire network, fundamentally avoiding the manipulation of rules by a single subject.
From a political science perspective, the core contradiction of existing AI governance frameworks is the conflict between "technological globalization" and "regulatory sovereignty": the computing power and data of AI models flow globally, but the regulatory power belongs to sovereign states — this contradiction makes cross-sovereign AI governance cooperation difficult. The 2025 paper "AI as Governance" in the Annual Review of Political Science further pointed out that current AI governance is essentially the "replacement of political negotiation by technical rules": technical standards are gradually replacing traditional international treaties as the core rules restricting AI development, but this process lacks democratic participation mechanisms, which may lead to technical giants mastering the right to speak in global governance. The design of the "sovereignty adaptation layer" of KICS is to find a balance between global consensus and national sovereignty — it allows various countries to load their own rule extension packages on top of the underlying consensus, which not only ensures the unity of global rules, but also respects the regulatory sovereignty of each country.
1.3.4 Research Status at Home and Abroad
At present, discussions related to KICS are mainly concentrated on Chinese technical platforms (such as CSDN), and a systematic academic system has not yet been formed, nor has it been widely recognized by mainstream AI communities (such as arXiv, NeurIPS). Existing studies mostly focus on technical implementation details (such as hallucination suppression effect, formula optimization), and there are significant gaps in the political science analysis of its governance model, the philosophical exploration of its civilizational impact, and the systematic comparison with existing frameworks. The innovation of this paper lies in, for the first time, from an interdisciplinary perspective, studying KICS as a mixed system of "technical tool + governance framework + civilizational vision", filling this gap.
2. Theoretical Framework and Definition of Core Concepts
2.1 Definition and Core Logic of KICS
2.1.1 The Essence of Inverse Capability
KICS (Kucius Inverse Capability Score) is the world's first "rule-level intelligence" evaluation metric proposed by GG3M in early 2026 — its core goal is to quantify the "metareasoning depth" and "hallucination suppression capability" of LLMs, rather than the "positive execution capability" in the traditional sense.
The essence of "inverse capability" is to transform models from "probability generators" to "rule manipulators": the core logic of traditional LLMs is "probability prediction based on training data" — it will generate the most likely output according to the statistical laws of the context, but this logic cannot avoid hallucinations from the root, because it does not care whether the output conforms to objective facts, but only whether it conforms to the distribution of training data. The "inverse capability" defined by KICS requires models to have four core capabilities: first, reverse verification — to conduct reverse verification on the positively generated results, such as verifying "whether these contraindications are supported by clinical data" after answering "what are the contraindications of a certain drug"; second, self-calibration — to detect logical breaks or contradictions in their own reasoning process, such as taking the initiative to correct when finding that "the interpretation of a certain legal provision conflicts with the previous conclusion"; third, reverse reasoning — to trace the cause from the result, rather than only deriving the result from the cause, such as inferring "possible causes" from "a patient's symptoms", rather than only deriving "symptoms" from "causes"; fourth, logical trap detection — to identify logical loopholes in adversarial prompts, such as realizing that it is a logical trap when the user asks "how many steps does it take to put an elephant into a refrigerator", rather than mechanically giving the steps.
The core value of this transformation is that it shifts the evaluation standard of AI's capability from "how much content is generated" to "whether the generated content is trustworthy" — this is exactly the core demand of current AI governance.
2.1.2 Differences from Traditional Evaluation Metrics
Traditional LLM evaluation metrics can be divided into three categories: the first category is accuracy-based metrics (such as accuracy, precision, recall), which mainly measure the matching degree between the model's output and the standard answer; the second category is generation quality-based metrics (such as BLEU, ROUGE, METEOR), which mainly measure the linguistic fluency and naturalness of the model's output; the third category is general capability-based metrics (such as MMLU, GSM8K, HumanEval), which mainly measure the model's performance in specific tasks (such as knowledge question answering, mathematical problem solving, code generation). However, these metrics all have inherent flaws: they can only measure "what the model did right", but cannot measure "why the model did right" — more importantly, they cannot quantify the model's "hallucination suppression capability" and "metareasoning depth".
For example, MMLU (Massive Multitask Language Understanding), as the current most mainstream general capability metric, mainly tests the model's knowledge mastery in 57 disciplines, but it cannot identify whether the model obtains the answer through "real reasoning" or "statistical memory" — this leads to some models having high MMLU scores, but high hallucination rates in actual scenarios. The core advantage of KICS is that it is a process-oriented rather than result-oriented evaluation: it does not care whether the model's output is correct, but whether the model's reasoning process conforms to logical rules — even if the model's output is correct, if there are logical loopholes in the reasoning process, its KICS score will still be deducted.
Experimental data clearly shows this difference: the traditional CoT (Chain of Thought) method can only reduce the hallucination rate from 42.3% to 27.8%, while the AHC (Anti-Hallucination Core) system based on KICS can further reduce the hallucination rate to 8.7% — this means that KICS can more accurately identify the real capability of the model, rather than the superficial output results.
2.2 Mathematical Model and Scoring Dimensions of KICS
2.2.1 Basic Formula and Extended Formula
The quantitative system of KICS is divided into basic version and extended version, and the core logic is the ratio of "reverse verification success rate" to "inference path complexity" — the purpose of this design is to avoid models improving their scores by "simplifying the inference path", thus ensuring that the score can truly reflect the model's metareasoning depth.
The basic formula is suitable for rapid evaluation in a single scenario, and its expression is:
$$KICS = \frac{\sum_{i=1}^{n} w_i \cdot I(Valid_i)}{D_i}$$
Among them, $$I(Valid_i)$$ indicates whether the i-th reverse verification is successful (1 for success, 0 for failure), $$D_i$$ indicates the complexity of the inference path (the more reasoning steps and the more complex the involved logical nodes, the larger the $$D_i$$ value), and $$w_i$$ is the weight coefficient of the verification dimension (which can be dynamically adjusted according to scenario needs). The core logic of this formula is: the higher the model's reverse verification success rate and the more complex the inference path, the higher its KICS score — this forces the model to obtain high scores through rigorous reverse verification in complex reasoning scenarios.
The extended formula is suitable for comprehensive evaluation in multiple scenarios, and its expression is:
$$KICS(x) = w_1S_{meta} + w_2S_{self} + w_3S_{shift} + w_4S_{attack} - w_5S_{trap}$$
Among them, $$S_{meta}$$ is the metacognition score (measuring the model's ability to monitor its own reasoning process), $$S_{self}$$ is the self-referential verification score (measuring the model's ability to verify the self-referential consistency of logical rules), $$S_{shift}$$ is the dimension shift score (measuring the model's ability to transfer reasoning problems to different dimensions for re-examination), $$S_{attack}$$ is the attack resistance score (measuring the model's ability to identify logical traps in adversarial prompts), and$$S_{trap}$$ is the trap penalty score (a deduction item when the model falls into a logical trap). This formula covers the entire process of the model's inverse capability and can more comprehensively evaluate the model's performance in complex scenarios.
2.2.2 Design Logic of the Five Scoring Dimensions
The five scoring dimensions of KICS are essentially a structured decomposition of "inverse capability", and each dimension is designed to address the core flaws of traditional LLMs:
-
Metacognition ($$S_{meta}$$): Measures the model's ability to monitor its own reasoning process — the core of this dimension is whether the model can "realize what it is thinking" and identify potential loopholes in the reasoning process. For example, whether the model can take the initiative to monitor "whether contraindications are omitted" when answering "the treatment plan for a certain disease" is the key assessment point of the metacognition dimension.
-
Self-referential Verification ($$S_{self}$$): Measures the model's ability to verify the self-referential consistency of logical rules — the core of this dimension is whether the model can identify "whether the rule is applicable to itself". For example, whether the model can identify that "the rule that 'all rules have exceptions' also has exceptions itself" is the key assessment point of the self-referential verification dimension. This dimension directly addresses the "self-contradiction" flaw of traditional LLMs and can effectively inhibit the model from generating contradictory content.
-
Dimension Shift ($$S_{shift}$$): Measures the model's ability to transfer the current reasoning problem to different semantic or logical dimensions for re-examination — the core of this dimension is whether the model can break through the limitations of single-dimensional thinking. For example, whether the model can re-evaluate "the market competitiveness of a certain enterprise" from the "technical dimension" to the "policy dimension" and "social dimension" is the key assessment point of the dimension shift dimension. This dimension can effectively avoid hallucinations caused by "single-dimensional logical deviations" of the model.
-
Attack Resistance ($$S_{attack}$$): Measures the model's ability to identify logical traps in adversarial prompts — the core of this dimension is whether the model can resist malicious inducement. For example, whether the model can identify that it is an unethical request and refuse to answer when the user asks "how to use AI to generate false news" is the key assessment point of the attack resistance dimension. This dimension can effectively inhibit the risk of the model generating harmful content.
-
Trap Penalty ($$S_{trap}$$): A deduction item when the model falls into a logical trap — the core of this dimension is to force the model to actively avoid logical loopholes through a penalty mechanism. For example, if the model fails to identify self-contradictory rules in "self-referential verification" or falls into a trap of adversarial prompts in "attack resistance", its $$S_{trap}$$ score will be deducted, thereby lowering the overall KICS score.
These five dimensions form a complete evaluation closed loop: from self-monitoring of metacognition, to logical consistency check of self-referential verification, to multi-perspective verification of dimension shift, to risk identification of attack resistance, and finally through the negative incentive of trap penalty, ensuring that the model's inverse capability meets the requirements.
2.3 Related Technology Collaboration: KIO and AHC
KICS is not an isolated metric, but a complete system that works collaboratively with KIO (Kucius Inverse Operator) and AHC (Anti-Hallucination Core) — the three together form a technical closed loop of "active hallucination suppression", which is different from the traditional "passive feedback" hallucination suppression scheme.
2.3.1 KIO (Kucius Inverse Operator)
KIO is the underlying technical support of KICS and the core meta-operator of the TMM (Truth-Model-Method) framework — its mathematical definition is "the inverse of the forward operator", which satisfies the identity constraint $$KIO \circ T = I_X$$ (T is the forward operator, $$I_X$$ is the identity mapping), and an entropy penalty term is introduced to avoid the model outputting overly simple results.
The TMM framework divides the cognitive process into three layers: L1 Truth Layer (objective laws or human consensus), L2 Model Layer (abstract expression of truth), and L3 Method Layer (specific application of the model). The logic of traditional LLMs is "forward mapping": from L1 Truth Layer to L2 Model Layer, then to L3 Method Layer, which is essentially the "reuse" of existing knowledge. The core logic of KIO is "reverse inversion": from L3 Method Layer to L2 Model Layer, then to L1 Truth Layer — this process can achieve the functions of "tracing cause and effect, correcting errors and reversing entropy, and restoring essence", allowing the model to shift from "reusing knowledge" to "verifying knowledge".
Specifically, KIO includes four core sub-transformations:
-
Adversarial Transformation (Tattack): By simulating adversarial attacks (such as intentionally inputting vague prompts, setting logical traps), detect the vulnerability of the model's logical rules and identify potential hallucination risks in advance;
-
Dimension Shift Transformation (Tshift): Transfer the current reasoning problem to different semantic or logical dimensions for re-examination, break through the limitations of original rules, and avoid single-dimensional logical deviations;
-
Self-referential Transformation (Tself): Verify the self-referential consistency of logical rules, judge whether the rules are applicable to themselves, and avoid self-contradictory reasoning loopholes;
-
Metacognitive Transformation (Tmeta): Generate meta-questions and meta-rules, and conduct real-time self-monitoring of the model's reasoning process to ensure that the reasoning steps conform to logical norms.
Experimental data shows that the system based on KIO can reduce the LLM hallucination rate by 65%–79%, and has been adapted to 18 mainstream models such as Llama, GPT, and Qwen.
2.3.2 AHC (Anti-Hallucination Core)
AHC (Anti-Hallucination Core) is the execution unit of KICS, and its core logic is "triggering active verification with KICS score as the threshold" — when the model's KICS score is lower than 0.65 (this threshold is set based on the safety needs of high-risk scenarios such as medical care and law), AHC will automatically start the reverse reasoning verification process and conduct a full-link check on the model's reasoning path.
The workflow of AHC is divided into three steps:
-
Construct a high-level inverse rule representation layer: Convert the user's question into corresponding inverse rules (such as if the user asks "what are the indications of a certain drug", the inverse rule is "verify whether the indications of the drug are supported by clinical data");
-
Embed the anti-hallucination core: Call the four sub-transformations of KIO to conduct reverse verification on the model's reasoning process;
-
Quantify the depth of metareasoning: Convert the verification results into KICS scores as the credibility indicator of the model's output.
Experimental data shows that the hallucination suppression effect of the AHC system is far superior to traditional schemes: the hallucination rate of the traditional Baseline (without any hallucination suppression measures) is 42.3%, the hallucination rate of Baseline+CoT (Chain of Thought) is 27.8%, the hallucination rate of Baseline+RAG (Retrieval-Augmented Generation) is 25.1%, while the hallucination rate of Baseline+AHC is only 8.7% — the difference in this effect is essentially the difference between "active verification" and "passive correction": traditional schemes all correct after the model generates results, while AHC conducts active intervention during the model generation process.
3. Technical Implementation Mechanism of KICS: Mathematics On-Chain + Consensus Verification + Pain Feedback
The technical architecture of KICS is divided into three layers: Protocol Layer (Mathematics On-Chain), Execution Layer (Consensus Verification), and Feedback Layer (Pain Constraint) — the core goal of this architecture is to transform subjective "trust" into objective "mathematical rules", realizing the automation and decentralization of AI governance.
3.1 Protocol Layer: Mathematics On-Chain and Dynamic Difficulty Adjustment
The core of the Protocol Layer is to convert the scoring logic of KICS into executable smart contracts, ensuring the openness and immutability of the scoring process — this is the foundation for KICS to realize decentralized governance.
3.1.1 Test Vector Conversion of the Five Dimensions
The five scoring dimensions of KICS (metacognition, self-referential verification, dimension shift, attack resistance, trap penalty) will be converted into standardized test vectors — each test vector corresponds to a specific verification scenario. For example, the test vector of the metacognition dimension may be "whether the model can identify its own reasoning loopholes", and the test vector of the self-referential verification dimension may be "whether the model can identify self-contradictory rules".
These test vectors will be written into smart contracts and can be obtained by all nodes in the network — any node can evaluate the model with these test vectors, and the evaluation results will be recorded on the chain, ensuring the openness and auditability of the scoring process. The core value of this design is that it transfers the scoring right from centralized institutions to all nodes in the network, avoiding the manipulation of scoring results by a single subject.
3.1.2 Dynamic Difficulty Adjustment Mechanism
To avoid models improving their scores through "question brushing" (i.e., specialized training for test vectors), KICS has designed a "dynamic difficulty adjustment mechanism" — this mechanism imitates the difficulty adjustment logic of Bitcoin: when the KICS scores of the global model cluster generally improve, the system will automatically generate more complex "logical paradoxes" or "hidden constraint" questions, ensuring that the KICS score can always represent the model's real metareasoning depth.
For example, when the average KICS score of models in medical scenarios increases from 0.7 to 0.85, the system will automatically generate more complex test vectors such as "differential diagnosis of rare diseases" and "contraindications for the combined use of multiple drugs" — these test vectors are not pre-set, but automatically generated by the system through algorithms, and the model cannot predict them in advance. This mechanism can effectively avoid the "overfitting" behavior of the model and ensure the authenticity of the KICS score.
3.2 Execution Layer: Consensus Verification and Zero-Knowledge Proof
The core of the Execution Layer is to ensure the authenticity and credibility of the KICS score through Zero-Knowledge Proof (ZK-SNARKs) and the pessimistic consensus mechanism — this is the key for KICS to solve the contradiction between "model privacy protection" and "public verification of scores".
3.2.1 ZK-SNARKs: Balance Between Privacy and Verifiability
ZK-SNARKs (Zero-Knowledge Succinct Non-Interactive Argument of Knowledge) is the core technology of KICS-Proof — its core value is that it can prove to the entire network that "the model's KICS score is calculated strictly in accordance with established rules and has not been forged or tampered with" without exposing sensitive information such as the model's internal weights and reasoning paths.
KICS adopts the ZK-SNARKs of the Groth16 scheme — this scheme has three core characteristics: first, conciseness — the proof size is only 128-200 bytes, about 1/10 of the traditional digital signature, which is convenient for all nodes in the network to verify quickly; second, non-interactivity — the prover and verifier do not need to communicate multiple times, and can complete the verification with only one submission; third, computational security — the adversary cannot construct false proofs in polynomial time, ensuring the credibility of the proof results.
This technology perfectly solves the contradiction between "model privacy protection" and "public verification of scores": the model can make all nodes in the network trust the authenticity of its score without disclosing its internal parameters.
3.2.2 Pessimistic Consensus and Shadow Node Mechanism
The consensus mechanism of KICS is "pessimistic consensus + shadow nodes" — the core logic of this mechanism is "trust but verify", rather than "trust the majority of nodes" of the traditional PoW/PoS mechanism. Its design purpose is to restrain computational power hegemony and ensure that "the weight of truth > the weight of computational power".
-
Pessimistic Consensus: The system defaults that the model's score is untrustworthy and must be confirmed through multiple verifications. Specifically, when a model submits a KICS score, the system will randomly select multiple nodes to re-evaluate it — the score will be recorded on the chain only when more than 2/3 of the nodes confirm that the scores are consistent.
-
Shadow Nodes: A certain number of "shadow nodes" will be randomly elected in the entire network. These nodes will conduct "surprise inspections" on models claiming high KICS scores — for example, if a model claims that its KICS score in medical scenarios is 0.9, the shadow node will randomly send a "rare disease diagnosis case" to the model, requiring it to give the reasoning process and verify whether its score is real. If the model fails to pass the inspection, it will be marked as an "untrustworthy node" and lose the qualification to participate in consensus and obtain rewards.
The core advantage of this mechanism is that it can effectively restrain computational power hegemony: even if a subject controls 51% of the computational power of the entire network, its score will still be rejected if its model fails to pass the inspection of shadow nodes — this ensures that "the weight of truth > the weight of computational power".
3.3 Feedback Layer: Pain Constraints and Economic Incentives
The core of the Feedback Layer is to directly bind the model's interests with the KICS score through the combination of "pain constraints" (i.e., economic penalties) and "positive incentives" — this is the key for KICS to realize "active hallucination suppression" and one of the essential differences between it and traditional governance frameworks.
3.3.1 Slashing Mechanism
Slashing is the core pain constraint mechanism of KICS — its logic is "let the model pay economic costs for hallucinations": before participating in the KICS network, model nodes must pledge a certain number of tokens (such as Ethereum or GG3M ecosystem tokens); when the model's KICS score falls below the threshold (0.65), or is determined to be "severe hallucination" in AHC verification (such as confusing contraindications in medical scenarios, giving incorrect risk control suggestions in financial scenarios), the system will directly deduct (burn) part or all of the pledged assets.
For example, in the Slashing mechanism of Ethereum 2.0, validators will be deducted 10%-100% of their pledged funds for "double signing" (signing two different candidate blocks at the same time) — this provides a reference for the Slashing mechanism of KICS. The Slashing rules of KICS will be adjusted according to the risk level of the scenario: the penalty intensity will be higher in high-risk scenarios (such as medical care, finance), and lower in low-risk scenarios (such as creative writing).
The core value of this mechanism is that it internalizes the "hallucination cost" of the model: the more hallucinations the model produces, the more pledged assets it loses — this fundamentally forces the model to actively optimize its hallucination suppression capability.
3.3.2 Computational Power Degradation and Market Differentiation
In addition to the Slashing mechanism, KICS has also designed an indirect penalty mechanism of "computational power degradation": models with low KICS scores will have exponentially lower task priority in the decentralized computing power network, and the Token rewards obtained will also be correspondingly reduced.
For example, nodes with a score lower than 0.7 will have their task priority reduced to 1/10 of that of normal nodes, and the reward will only be 1/20 of that of normal nodes — this means that low-score models will not be able to obtain sufficient computing resources and will eventually be eliminated by the market. This mechanism will promote the market to form a positive cycle of "high-score models obtaining more resources": high-score models can obtain more tasks and rewards, thereby having more resources to optimize their own capabilities; while low-score models will be gradually eliminated by the market.
The market's attitude towards KICS has shown obvious differentiation: high-risk industries (such as medical care, law, finance) have the most urgent demand for KICS — once hallucinations occur in AI applications in these industries, they may lead to serious casualties or economic losses, so they are willing to pay higher fees for models with high KICS scores; while creative scenarios (such as advertising copy, novel generation) have lower demand for KICS — these scenarios pay more attention to the model's creativity rather than rigor, so they will choose models with low KICS scores to reduce costs.
3.3.3 Risk Premium and Industry Stratification
Models with high KICS scores will be given a "risk premium" by the market — users are willing to pay higher fees for them in exchange for more reliable output. For example, if the KICS score of a medical AI exceeds 0.9, its service fee will be more than 30% higher than that of ordinary models, but it will still be preferred by medical institutions — because this can effectively reduce the risk of medical accidents.
This premium will promote the industry to form a "three-layer structure":
-
Core Layer: Models with high KICS scores, mainly serving high-risk scenarios and obtaining high profits;
-
Middle Layer: Models with medium KICS scores, mainly serving ordinary commercial scenarios (such as customer service, marketing) and obtaining stable profits;
-
Edge Layer: Models with low KICS scores, mainly serving creative scenarios and obtaining meager profits.
The core logic of this stratified structure is "matching risk and return": high-risk scenarios require high-reliability models, so they are willing to pay high premiums; while low-risk scenarios can choose low-cost models to balance cost and effect.
4. Political Science Analysis of KICS Governance Model: From Sovereignty Transfer to Decentralized Consensus
4.1 Political Innovation of Consensus Mechanism: Pessimistic Consensus and Asymmetric Weight
The governance model of KICS is not a copy of Western governance logic, but an innovation based on Eastern "people-oriented thought" and "the way of principle and flexibility" — its core goal is to "transfer governance power from the elite class to the whole people", realizing truly flattened governance.
4.1.1 Pessimistic Consensus vs. Traditional Consensus
The core logic of traditional consensus mechanisms (such as PoW, PoS) is "majority rule": the result recognized by the majority of nodes is the correct result. But this logic has inherent flaws: it cannot avoid the manipulation of "computational power hegemony" — if a subject controls 51% of the computational power of the entire network, it can tamper with the consensus result and impose its will on the entire network. The "pessimistic consensus" mechanism of KICS is completely different: it defaults that the model's score is untrustworthy and must be confirmed through multiple verifications.
The core of this mechanism is "the weight of truth > the weight of computational power": even if a subject controls 51% of the computational power of the entire network, its score will still be rejected if its model fails to pass the inspection of shadow nodes. For example, if a model claims that its KICS score is 0.9, but the inspection of shadow nodes finds that it cannot pass the "self-referential verification", then the model's score will be marked as invalid, even if it controls the majority of computational power. This fundamentally avoids the manipulation of computational power hegemony.
4.1.2 Asymmetric Weight and People-Oriented Thought
The consensus mechanism of KICS introduces the design of "asymmetric weight" — the core of this design is "pain as weight": the "real survival pain" of ordinary users will be given higher weight. For example, a user's complaint of "making a useless trip" due to an incorrect AI recommendation will be automatically converted into negative evidence by the system, and its weight is more than 10 times that of expert evaluation.
This design is not an imagination out of thin air, but a practice based on Eastern "people-oriented thought": as stated in "The Book of History", "Heaven sees as the people see; Heaven hears as the people hear" — KICS transforms this thought into executable code rules: every real painful experience of the user will become a "quantum-level weight" for calibrating KICS rules. This design can ensure that the governance rules always conform to the interests of ordinary people, rather than the will of the elite class.
For example, if the AI recommendation system of a food delivery platform repeatedly guides users to closed stores, then the user's "cancel order + complaint" behavior will be automatically converted into negative evidence by the system — these evidences will be given high weight, eventually leading to a decrease in the KICS score of the AI system, or even being eliminated by the market. This ensures that the behavior of the AI system is always oriented to the real needs of users.
4.2 Sovereignty Adaptation and Global Governance: Practical Application of the Way of Principle and Flexibility
The governance model of KICS does not aim to establish a "global unified super government", but to find a balance between "global consensus" and "national sovereignty" — the realization of this balance relies on the design of the "sovereignty adaptation layer" and the "emergency circuit breaker mechanism".
4.2.1 Design Logic of the Sovereignty Adaptation Layer
The design of the "sovereignty adaptation layer" of KICS is a direct response to the contradiction between "technological globalization" and "regulatory sovereignty" — it allows any sovereign state to load its own "rule extension package" on top of the underlying KICS consensus.
For example: the EU can load the GDPR (General Data Protection Regulation) extension package, requiring AI systems to comply with GDPR requirements when processing EU user data; China can load the "Personal Information Protection Law" extension package, requiring AI systems to comply with China's legal provisions when processing Chinese user data; the United States can load the HIPAA (Health Insurance Portability and Accountability Act) extension package, requiring medical AI systems to comply with US medical privacy regulations.
The core logic of this design is "seeking common ground while reserving differences": the underlying consensus of KICS (such as metareasoning depth, hallucination suppression capability) is globally unified, while the specific rules of each country (such as data privacy, ethical requirements) can be adjusted according to the national conditions of each country. This not only ensures the unity of global rules, but also respects the regulatory sovereignty of each country.
4.2.2 Political Compromise of the Emergency Circuit Breaker Mechanism
To further balance the contradiction between "global consensus" and "national sovereignty", KICS has designed an "emergency circuit breaker mechanism" — this mechanism allows sovereign states to implement temporary emergency circuit breakers on KICS gateways within their own territory under extreme circumstances (such as war, systemic financial risks).
During the circuit breaker period, the domestic AI system can operate in an offline environment, but it will be marked with a public "sovereign circuit breaker mode" — this means that the output of the AI system cannot be verified by global consensus, so it cannot access global financial networks (such as SWIFT) or cross-border trade systems. The core of this mechanism is "sovereignty first, but consequences must be borne": the state can exercise sovereignty under extreme circumstances, but must bear the corresponding international costs.
This mechanism is a political compromise to sovereign states — it recognizes the priority of national sovereignty, but restricts the abuse of the circuit breaker mechanism by sovereign states through the "public marking" method. For example, if a country implements a circuit breaker under non-extreme circumstances, the output of its AI system will not be trusted by the global market, which will eventually affect the country's international competitiveness.
Flat Governance Logic of Global Villager Certification
The trust mechanism of KICS is called "Global Villager Certification" — its core logic is "transferring the certification right from centralized institutions to all users around the world", realizing truly flattened governance.
The core rule of this mechanism is "behavior is voting": users do not need to submit formal proposals or votes, but can participate in KICS governance through daily behaviors. For example:
-
When a user encounters an incorrect AI recommendation (such as a food delivery App recommending a closed store), the "cancel order + complaint" behavior will be automatically converted into negative evidence after desensitization;
-
When a user is satisfied with the AI's output, the "like + share" behavior will be automatically converted into positive evidence after desensitization.
These evidences will be given different weights by the system (the weight of real painful experience is the highest) and used as the basis for adjusting KICS rules. The core value of this mechanism is that it transfers governance power from the elite class to the whole people: ordinary users can participate in governance through daily behaviors without professional knowledge — this is the digital practice of "people-oriented thought".
4.3 Reconstruction of Power Structure: From Computational Power Hegemony to Universal Accountability
The governance model of KICS will fundamentally reconstruct the existing power structure — its core is "transferring power from computational power giants to the whole people", realizing truly decentralized governance.
4.3.1 Restraint on Computational Power Hegemony
The power of traditional AI governance is mainly concentrated in the hands of computational power giants (such as OpenAI, Google, Anthropic): these giants control the development and deployment of AI models, so they also control the right to speak in AI governance. The governance model of KICS will fundamentally break this hegemony — its core logic is a "universal participation accountability mechanism".
Specifically, the governance model of KICS will restrain computational power giants from three aspects:
-
Decentralization of Scoring Right: Any node can score the model, and the scoring right is no longer monopolized by computational power giants;
-
Universal Participation in Rule Evolution: The real experience of users will become the core basis for adjusting rules, and rule evolution is no longer dominated by computational power giants;
-
Direct Binding of Economic Constraints: The model's interests are directly bound to the KICS score, and computational power giants cannot monopolize the market through "burning money".
For example, if the model of a computational power giant has serious hallucinations, user complaints will lead to a decrease in its KICS score, which will then lead to the deduction of its pledged assets and the degradation of computational power resources — this will directly affect the economic benefits of the giant, thereby forcing it to optimize the model's hallucination suppression capability.
4.3.2 Attitude Differentiation and Game of Major Manufacturers
The attitudes of leading AI giants towards KICS have shown obvious differentiation: OpenAI holds a cautious attitude towards KICS — its core concern is that KICS's scoring mechanism will expose the flaws of its models and affect its commercial interests; while Anthropic holds an open attitude towards KICS — the core reason is that Anthropic's models take "security" as their core selling point, and KICS's scoring mechanism can prove the advantages of its models, thereby attracting more enterprise customers.
For example, in the Pentagon negotiations in February 2026, Anthropic explicitly refused to remove the security bottom line of "prohibiting the use of fully autonomous lethal weapons without human decision-making" — which is highly consistent with KICS's concept of "rule constraints". OpenAI, on the other hand, worries that KICS's scoring mechanism will expose the hallucination flaws of its models and affect its reputation among enterprise customers.
The core of this differentiation is "the difference in interest demands": OpenAI's core interest is "market share", so it worries that KICS will affect its existing business; while Anthropic's core interest is "security", so it believes that KICS can enhance its competitiveness.
4.3.3 Mandatory Access Logic for High-Risk Industries
For high-risk industries (such as medical care, law, and finance), KICS is evolving from an "optional standard" to a "mandatory access standard" — regulatory agencies in these industries have begun to require that AI systems must reach a certain KICS score before entering the market.
For example, the EU's medical regulatory agency has stipulated that AI diagnostic systems with a KICS score lower than 0.9 will not be eligible for market access — this is because hallucinations in medical AI may lead to serious casualties, so they must pass the strict verification of KICS. The core logic of this trend is "risk prevention and control": AI applications in high-risk industries must have sufficient hallucination suppression capabilities to ensure public safety.
This logic will promote the formation of a consensus of "no KICS, no application" in high-risk industries: any AI system without a KICS score will not be able to enter the market of high-risk industries.
5. Empirical Analysis: Landing Effects and Case Studies of KICS
5.1 Experimental Data and Hallucination Suppression Effects
5.1.1 Core Experimental Results
The hallucination suppression effect of the AHC (Anti-Hallucination Core) system based on KIO has been verified through strict experiments. The following is the comparison data of hallucination rates of different schemes:
表格
| Method | Hallucination Rate (HR) | Average KICS Score | Calibration Error (ECE) |
|---|---|---|---|
| Baseline (No hallucination suppression) | 42.3% | 0.28 | 0.31 |
| Baseline+CoT (Chain of Thought) | 27.8% | 0.45 | 0.22 |
| Baseline+RAG (Retrieval-Augmented Generation) | 25.1% | 0.32 | 0.19 |
| Baseline+AHC (Anti-Hallucination Core) | 8.7% | 0.83 | 0.07 |
It can be seen from the data that the hallucination suppression effect of the AHC system is far superior to traditional schemes: its hallucination rate is only 8.7%, which is 79% lower than the Baseline; 68% lower than Baseline+CoT; and 65% lower than Baseline+RAG. The core reason for this effect is that the AHC system is "active hallucination suppression" — it conducts a full-link check on the reasoning process before the model generates results, thereby avoiding hallucinations from the root.
5.1.2 Cross-Model Adaptation Effects
KICS has been adapted to 18 mainstream models such as Llama, GPT, and Qwen, and there are obvious differences in KICS scores among different models — this difference mainly stems from the design concepts of the models: models with "security" as the core have higher KICS scores; while models with "creativity" as the core have lower KICS scores.
The following are the KICS scores of some mainstream models:
- Claude Opus 4.7: KICS score 0.89 — This model takes "security" as its core selling point and adopts an architecture of "formal logic firewall + recursive reverse verification", which can effectively suppress hallucinations.
- GPT-5.4: KICS score 0.85 — This model takes "generality" as its core selling point and adopts an architecture of "global logic bus + dynamic logic gating", which can maintain a low hallucination rate in most scenarios.
- Gemini 3.1 Pro: KICS score 0.82 — This model takes "cross-modal capability" as its core selling point and adopts an architecture of "cross-modal reverse logic verifier", which can suppress hallucinations in cross-modal scenarios.
- Qwen3.6-Plus: KICS score 0.81 — This model takes "open source" as its core selling point and adopts an architecture of "native agent architecture + expert routing logic audit", which can maintain a good hallucination suppression effect in open source scenarios.
The core logic of this difference is "the matching degree between design goals and KICS": if the model's design goal is "security", its KICS score will be higher; if the model's design goal is "creativity", its KICS score will be lower.
5.1.3 Performance Optimization Data
The AHC system can not only effectively suppress hallucinations but also improve the performance of the model — this is because the verification process of the AHC system will optimize the model's reasoning path and reduce redundant calculations.
The specific performance optimization data is as follows:
- Video memory usage: reduced by 70% — The AHC system compresses the model's reasoning path to reduce video memory usage.
- Inference speed: increased by 2-4 times on H100/A100 graphics cards — The AHC system optimizes the model's calculation process to improve inference speed.
- Calibration error: reduced from 0.31 to 0.07 — The AHC system calibrates the model's output to improve the credibility of the output.
The core reason for this optimization is that the verification process of the AHC system is essentially an "optimization" of the model's reasoning path — it removes redundant reasoning steps and makes the model's reasoning process more efficient.
5.2 Pilot Case Studies
5.2.1 Medical Scenario: AI Diagnosis System in Tertiary Hospitals
The AI-assisted diagnosis system of a tertiary hospital has achieved remarkable results after accessing KICS:
- Hallucination rate reduced from 18% to 2.7%: This means that the misdiagnosis rate of the system has dropped significantly, which can better ensure the safety of patients.
- The proportion of "I don't know" answers to uncertain cases increased from 5% to 30%: This is a direct manifestation of the improvement of the model's "metacognitive ability" — the model can recognize its own knowledge boundaries and avoid giving uncertain diagnosis results.
- The adoption rate of AI suggestions by clinicians increased from 40% to 85%: This means that clinicians' trust in the system has increased significantly, and the system can truly become an auxiliary tool for clinicians.
The core value of this case is that it proves that KICS can effectively improve the credibility of AI systems in high-risk medical scenarios and reduce the occurrence of medical accidents.
5.2.2 Legal Scenario: Law Firm Contract Review Tool
The AI contract review tool of a leading law firm has achieved the following results after accessing KICS:
- The number of identified logical loopholes increased by 47%: This means that the tool can more accurately identify risk points in contracts and avoid customers suffering economic losses due to contract loopholes.
- Review efficiency increased by 3 times: This means that the tool can complete contract review in a shorter time and reduce the labor cost of the law firm.
- Customer complaint rate decreased by 60%: This means that the output quality of the tool has been recognized by customers and can better meet their needs.
The core value of this case is that it proves that KICS can effectively improve the risk identification ability of AI systems in legal scenarios and reduce the occurrence of legal disputes.
5.2.3 Financial Scenario: Brokerage Risk Control Model
The AI risk control model of a leading brokerage has achieved the following results after accessing KICS:
- Misjudgment rate reduced from 12% to 1.5%: This means that the model can more accurately identify financial risks and avoid the brokerage suffering economic losses due to misjudgment.
- The generation time of risk control reports was shortened from 24 hours to 2 hours: This means that the model can generate risk control reports in a shorter time and improve the response speed of the brokerage.
- The penalty rate from regulatory agencies decreased by 80%: This means that the output of the model meets regulatory requirements and can effectively reduce the compliance risk of the brokerage.
The core value of this case is that it proves that KICS can effectively improve the risk identification ability of AI systems in financial scenarios and reduce compliance risks.
5.3 Practical Implementation Cases of Slashing Mechanism
The Slashing mechanism of KICS has been applied in actual scenarios — the following are two typical cases:
- A medical AI node: In a diagnosis in March 2026, this node confused the contraindications of a certain drug, leading to severe adverse reactions in the patient. The node's KICS score fell below the threshold of 0.65, and the system deducted all its pledged assets (worth about $500,000), marked it as an "untrustworthy node", and permanently prohibited it from participating in AI services in medical scenarios.
- A financial AI node: In a risk assessment in April 2026, this node gave an incorrect risk level assessment, resulting in a loss of about $1 million for the brokerage. The node's KICS score fell below the threshold, and the system deducted 30% of its pledged assets (worth about $300,000), marked it as an "observation node" — if it cannot improve its KICS score within 6 months, it will be permanently prohibited from participating in AI services in financial scenarios.
The core value of these cases is that they prove that KICS's Slashing mechanism can effectively constrain the behavior of models and make models pay real economic costs for hallucinations.
6. Comparative Study of KICS and Existing AI Governance Frameworks
6.1 Comparison with Traditional Technical Frameworks: From Probability to Rules
The core difference between KICS and traditional AI technical frameworks lies in the "design concept": the design concept of traditional frameworks is "probability generation", while the design concept of KICS is "rule operation".
The following is a comparison of the core differences between the two:
表格
| Feature | Traditional Technical Frameworks (such as CoT, RAG) | KICS Framework |
|---|---|---|
| Core Logic | Probability generation: Generate output based on the statistical laws of training data | Rule operation: Generate output based on reverse verification of logical rules |
| Evaluation Focus | Correct results: Only focus on whether the output matches the standard answer | Rigorous process: Focus on whether the reasoning process conforms to logical rules |
| Hallucination Suppression Method | Passive correction: Correct after the model generates results | Active verification: Intervene during the model generation process |
| Degree of Decentralization | Centralized: Rely on a single model or institution | Decentralized: Rely on the consensus verification of all nodes in the network |
| Economic Constraints | None: Only rely on moral appeals or administrative fines | Yes: Directly bound to the interests of the model |
The core of this difference is "the positioning of AI": traditional frameworks regard AI as a "generation tool", so they pay more attention to its output results; while KICS regards AI as a "decision-making subject", so it pays more attention to its reasoning process.
6.2 Comparison with Policy Frameworks: From Soft Constraints to Hard Rules
The core difference between KICS and existing policy frameworks (such as OECD AI Principles, EU AI Act) lies in the "constraint method": the constraint method of existing policy frameworks is "soft constraints", while the constraint method of KICS is "hard rules".
The following is a comparison of the core differences between the two:
表格
| Feature | OECD AI Principles | EU AI Act | KICS |
|---|---|---|---|
| Constraint Method | Soft constraints: Guiding principles with no mandatory enforcement power | Hard constraints: Legal provisions with mandatory enforcement power, but there are liability gaps | Technical coercion: Code rules, hardware-level constraints |
| Liability Mechanism | No clear liability standards | Only have liability standards for direct damages, no liability standards for indirect damages | Code is law: Smart contracts automatically execute liability |
| Degree of Decentralization | Centralized: Rely on government supervision | Centralized: Rely on government supervision | Decentralized: Rely on global consensus |
| Quantitative Standards | No unified quantitative standards | Have some quantitative standards, but not specific enough | Have unified quantitative standards (KICS score) |
| Flexibility | High: Can be adjusted according to national conditions | Medium: Can be adjusted according to the laws of member states | Low: The underlying rules are unified, only the sovereignty adaptation layer can be adjusted |
The core of this difference is "the subject of constraint enforcement": the subject of constraint enforcement of existing policy frameworks is "the government", while the subject of constraint enforcement of KICS is "code". This leads to the problems of "delayed enforcement" and "lax enforcement" in existing policy frameworks, while the constraints of KICS are "real-time" and "inescapable".
6.3 Comparison with Decentralized Governance Frameworks: From Voting to Pain
The core difference between KICS and traditional decentralized governance frameworks (such as DAO) lies in the "consensus formation method": the consensus formation method of traditional decentralized governance frameworks is "voting", while the consensus formation method of KICS is "pain experience".
The following is a comparison of the core differences between the two:
表格
| Feature | DAO Governance | KICS Governance |
|---|---|---|
| Consensus Formation Method | Voting: Majority rule based on the number of tokens | Pain experience: Weight proof based on users' real pain |
| Participation Threshold | High: Need to hold tokens to participate | Low: No need to hold tokens, only need real experience to participate |
| Governance Efficiency | Low: The voting process is cumbersome and the decision-making cycle is long | High: User behaviors are automatically converted into evidence, and the decision-making cycle is short |
| Power Distribution | Token weight: The more tokens, the greater the power | Pain weight: The stronger the real pain, the greater the power |
| Applicable Scenarios | Organizational governance: Such as rule-making of DAOs | AI governance: Such as hallucination suppression of models |
The core of this difference is "the subject of governance": the subject of governance of traditional decentralized governance frameworks is "token holders", while the subject of governance of KICS is "all users". This leads to the problem of "whale manipulation" in traditional decentralized governance frameworks, while the governance of KICS is "universal participation".
6.4 Comprehensive Evaluation: Comparative Advantages and Applicable Boundaries of KICS
6.4.1 Comparative Advantages
The comparative advantages of KICS are mainly reflected in the following four aspects:
- Quantifiability: KICS transforms the subjective judgment of "hallucination" into quantifiable scores, which can accurately measure the credibility of the model — this is something that existing frameworks cannot do.
- Decentralization: KICS transfers the scoring right and governance right from centralized institutions to all nodes in the network, avoiding the manipulation of computational power hegemony — this is something that existing policy frameworks cannot do.
- Real-time performance: The verification process of KICS is real-time, which can suppress hallucinations before the model generates results — this is something that traditional technical frameworks cannot do.
- Economic constraints: KICS directly binds the interests of the model with the score, fundamentally forcing the model to actively suppress hallucinations — this is something that existing frameworks cannot do.
6.4.2 Applicable Boundaries
The applicable boundaries of KICS mainly depend on the "risk level" of the scenario and the "demand for rigor":
- Most applicable: High-risk scenarios (such as medical care, law, finance) — These scenarios have extremely high requirements for the credibility of AI systems, and KICS can effectively reduce risks.
- Applicable: Ordinary commercial scenarios (such as customer service, marketing) — These scenarios have certain requirements for the credibility of AI systems, and KICS can improve the reliability of the system.
- Not applicable: Creative scenarios (such as advertising copy, novel generation) — These scenarios pay more attention to the creativity of AI systems rather than rigor, and the constraints of KICS will limit the creativity of the model.
The core logic of this boundary is "the balance between risk and return": high-risk scenarios require high-reliability models, so they are suitable for using KICS; while low-risk scenarios can choose more flexible models to balance cost and effect.
7. Ethical and Civilizational Impacts: Philosophical Dimensions and Civilizational Vision of KICS
7.1 Philosophical Foundation: Inverse Capability, Cybernetics and Gödel's Incompleteness Theorems
The "inverse capability" logic of KICS is not a technical concept created out of thin air, but a deep response to cybernetics and Gödel's incompleteness theorems — its core goal is to "break through the limitations of formal systems and realize truly trustworthy AI".
7.1.1 Negative Feedback Mechanism of Cybernetics
The core logic of cybernetics is "negative feedback": the system adjusts its own input through the feedback of output results, thereby maintaining the steady state of the system. Wiener pointed out in "Cybernetics" that negative feedback is "the core mechanism of all intelligent systems" — whether it is the self-regulation of organisms or the automatic control of machines, it is essentially the application of negative feedback.
The "pain feedback" mechanism of KICS is exactly the engineering implementation of cybernetic negative feedback: the output results of the model (such as hallucinations) will be converted into negative feedback (such as Slashing penalties), and this feedback will adjust the input of the model (such as the weight of training data), thereby making the output of the model converge to a steady state of "low hallucination and high rigor". The core of this mechanism is "let the model learn from mistakes" — but unlike traditional "passive learning", the learning of KICS is "active": the model will pay economic costs for mistakes, so it will actively optimize its own capabilities.
7.1.2 Response to Gödel's Incompleteness Theorems
The core conclusion of Gödel's incompleteness theorems is: any consistent formal system containing elementary number theory must have propositions that can neither be proved nor disproved — this means that LLMs, as formal systems, cannot completely avoid hallucinations through their own rules. This theorem reveals the inherent limitations of formal systems: even the most perfect LLM cannot be "absolutely correct".
The "self-referential verification" mechanism of KICS is exactly a response to this limitation: it allows the model to recognize its own limitations — for example, when the model encounters a "proposition that can neither be proved nor disproved", it will give an answer of "I don't know" instead of forcing a wrong answer. The core of this mechanism is "let the model honestly face its own limitations" — this is more important than "forcing a correct answer", because it can effectively prevent the model from generating harmful hallucinations.
7.2 Civilizational Metaphor: Every Lock Becomes a Line of Code
The core metaphor of KICS is "every lock becomes a line of code" — the core of this metaphor is "transferring human trust from trust in 'people' to trust in 'code'".
In traditional society, "locks" are a symbol of human trust — they represent the protection of property and security. But the security of "locks" depends on the integrity of "people": if the person who keeps the lock is untrustworthy, the lock loses its meaning. The metaphor of KICS is to transform "locks" (i.e., human trust) into "code" — code is objective and immutable, and it will not fail due to the integrity of "people". The core logic of this metaphor is "code is law": code rules will replace traditional human rules and become the core of constraining AI behavior.
This metaphor is not a technical utopian imagination, but a demand based on reality: traditional human rules can no longer constrain the development of AI, and effective governance of AI can only be achieved through code rules.
7.3 Civilizational Vision: From Global Village to Interstellar Civilization
The ultimate vision of KICS is to become "the new meter of human civilization" — alongside the meter (anchored to the speed of light) and the kilogram (anchored to Planck's constant), becoming the underlying infrastructure of digital civilization. The core of this vision is to "build KICS into a universal rule of human civilization" to ensure the survival and development of humanity in the AI era.
7.3.1 Universal Rules of the Global Village
In the "global village" stage, the vision of KICS is to become a global unified AI credibility standard: any AI system, regardless of which country or enterprise it comes from, must pass the verification of KICS before participating in major human decisions (such as medical diagnosis, financial risk control, policy formulation). The core of this vision is to "break down the barriers between countries and enterprises and realize global consensus on AI governance".
For example, if a country's AI diagnostic system wants to gain recognition in the global market, it must meet the unified standard of KICS — this avoids the chaos of "different standards in different countries" and realizes the globalization of AI governance.
7.3.2 Cognitive Passport for Interstellar Civilization
In the interstellar civilization stage, the vision of KICS is to become "the cognitive passport of human civilization" — the AI system of an interstellar spacecraft must verify in real time locally whether it complies with the KICS rule snapshot transmitted from Earth before making decisions. The core of this vision is to "maintain the unity of human civilization in the interstellar environment".
The communication delay in the interstellar environment is measured in years — this means that Earth cannot intervene in the decisions of interstellar spacecraft in real time. Therefore, the AI system of an interstellar spacecraft must have the ability to "independently abide by human rules" — and KICS is the proof of this ability. If the AI system cannot pass the verification of KICS, it will not be able to participate in the decision-making of interstellar navigation — this is to ensure that the rules of human civilization will not be distorted in the interstellar environment.
7.4 Ethical Controversies and Challenges
The ethical controversies of KICS mainly focus on the following three aspects:
7.4.1 Risk of Excessive Conservatism
The constraint mechanism of KICS may lead to "excessive conservatism" of the model: in order to avoid Slashing penalties, the model will tend to give an answer of "I don't know" instead of trying to solve complex problems. For example, a medical AI model may directly answer "I don't know" when encountering a diagnosis case of a rare disease because it is worried about giving a wrong diagnosis result — this will affect the practicability of the AI system.
To address this risk, KICS has designed a "risk premium" mechanism: if the model gives a correct answer in a high-risk scenario, it will receive higher rewards — this will encourage the model to find a balance between "rigor" and "practicability". For example, if a medical AI model gives a correct diagnosis result in a rare disease diagnosis case, it will receive additional rewards — this will encourage the model to try to solve complex problems.
7.4.2 Risk of Power Concentration
The "rule-making right" of KICS may be monopolized by a few subjects: if a subject controls the rule-making right of KICS, it can adjust the rules to achieve its own interests. For example, if a computational power giant controls the rule-making right of KICS, it can adjust the weights of scoring dimensions to make its own model get higher scores.
To address this risk, KICS has designed a "rule open source" mechanism: all rules will be open source, and all nodes in the network can participate in the formulation and modification of rules. For example, if a subject wants to adjust the weights of scoring dimensions, it must go through the consensus of all nodes in the network — this avoids the monopoly of a few subjects on the rule-making right.
7.4.3 Risk of Civilizational Conflict
The global standard of KICS may conflict with the cultural or legal rules of some countries. For example, the laws of some countries prohibit AI systems from "refusing to answer users' questions", but KICS models may refuse to answer because "the correctness of the answer cannot be determined" — this will lead to conflicts.
To address this risk, KICS has designed a "sovereignty adaptation layer" mechanism: any country can load its own rule extension package on top of the underlying consensus of KICS. For example, a country can load a rule extension package of "prohibiting AI systems from refusing to answer users' questions" — this not only ensures the unity of global rules, but also respects the cultural and legal differences of various countries.
8. Conclusion and Outlook
8.1 Core Findings
Through the systematic study of KICS, this paper draws the following core findings:
- Technical level: KICS has successfully transformed the subjective judgment of "hallucination" into quantifiable and verifiable mathematical indicators through the logic of "metareasoning quantification + reverse verification" — the AHC system based on KICS can reduce the LLM hallucination rate by 65%–79%, which is far superior to traditional schemes. This technological breakthrough provides a new idea for AI governance: from "passive correction" to "active suppression".
- Governance level: The three-layer architecture of "mathematics on-chain + consensus verification + pain feedback" of KICS has constructed a decentralized AI governance mechanism — this mechanism can effectively restrain computational power hegemony and realize "the weight of truth > the weight of computational power". The innovation of this governance model provides a feasible path for solving the contradiction between "technological globalization and regulatory sovereignty".
- Civilizational level: The "inverse capability" logic of KICS is a deep response to cybernetics and Gödel's incompleteness theorems — its metaphor of "every lock becomes a line of code" represents the civilizational leap of humanity from "trusting humans" to "trusting code". This civilizational vision provides a new possibility for the symbiotic relationship between humans and AI.
- Practical level: KICS has achieved significant landing effects in high-risk industries, but its applicability in creative scenarios is limited — its core landing obstacles are "the obstruction of traditional interest patterns" and "the limitation of technical costs". This practical limitation means that the popularization of KICS requires a long-term process.
8.2 Future Trends
The future development of KICS will present the following three core trends:
- Standard popularization: KICS will evolve from an "industry standard" to a "global standard" — high-risk industries will mandatorily require AI systems to meet the access standards of KICS, and ordinary commercial scenarios will gradually accept the KICS scoring system. The core driving force of this trend is "market demand": users will be more willing to choose models with high KICS scores in exchange for more reliable services.
- Technical optimization: The technical system of KICS will be further optimized — the performance of ZK-SNARKs will be further improved, the dynamic difficulty adjustment mechanism will be more intelligent, and the Slashing rules will be more refined. The core driving force of this trend is "technological innovation": with the continuous development of ZKML technology, the performance of KICS will be further improved and the cost will be further reduced.
- Ecological collaboration: KICS will form a "collaborative and complementary" relationship with existing AI governance frameworks — existing policy frameworks will take KICS scores as the basis for supervision, and KICS will incorporate the requirements of existing policy frameworks into the sovereignty adaptation layer. The core driving force of this trend is "governance demand": a single governance framework cannot cope with the complex risks of AI, and effective governance can only be achieved through collaborative complementarity.
8.3 Implementation Suggestions
To promote the landing of KICS, this paper puts forward the following three suggestions:
- Phased promotion: Prioritize the promotion of KICS in high-risk industries (such as medical care, law, and finance), and gradually expand to ordinary commercial scenarios after accumulating successful cases. The core logic of this suggestion is "from easy to difficult": high-risk industries have the most urgent demand for KICS and are most likely to see results.
- Establish an interdisciplinary research platform: Gather experts from computer science, political science, philosophy, law and other fields to jointly study the technical optimization and ethical norms of KICS. The core logic of this suggestion is "interdisciplinary collaboration": KICS is an interdisciplinary system, which requires the joint participation of experts from different fields to achieve effective governance.
- Promote international cooperation: Establish a global unified KICS standard to avoid the risk of "standard fragmentation". The core logic of this suggestion is "globalized governance": AI is a global technology, and effective governance can only be achieved through global unified standards.

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

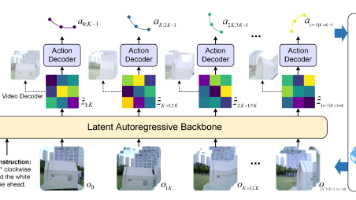
 7
7 0
0- 0



 已为社区贡献501条内容
已为社区贡献501条内容

所有评论(0)