WorldVLN:面向空中视觉语言导航的自回归世界行动模型
论文来源:arXiv:2605.15964v1 [cs.RO] · WorldVLN: Autoregressive World Action Model for Aerial Vision-Language Navigation
研究机构:清华大学、山东大学、Manifold AI、北京理工大学、东北大学
**核心摘要:**空中视觉语言导航(Aerial VLN)要求智能体在三维环境中依据自然语言指令完成闭环感知与行动。本文介绍的 WorldVLN 是首个面向空中视觉语言导航的自回归世界行动模型(Autoregressive World Action Model, WAM)。该模型将视频生成的潜在自回归骨干网络重新应用于短视域世界状态预测,并直接解码为可执行的航点行动。通过两阶段训练框架——先进行监督式导航动态 grounding,再引入专为自回归 WAM 设计的 Action-aware GRPO 强化学习方法——WorldVLN 在公开室内外无人机基准测试中取得了超越现有视觉语言行动基线模型12%以上的成功率提升,并实现了向真实无人机平台的零样本迁移部署。
一、研究背景:从视觉语言模型到世界行动模型
视觉语言导航(Vision-Language Navigation, VLN)是空间智能的核心任务之一,其目标是让智能体依据人类自然语言指令,在三维环境中自主移动并完成导航目标[1]。在这一过程中,智能体需要理解高层语义指令、感知部分可见的以自我为中心的观测信息,并在新的观测信息逐步到来时,以闭环方式生成低层行动指令[2]。随着大语言模型(LLM)和视觉语言模型(VLM)的快速发展,研究者开始尝试将通用视觉语言能力迁移到具身导航任务中,形成了视觉语言行动(Vision-Language-Action, VLA)建模范式[3]。
VLA 模型通过在预训练视觉语言模型上增加行动输出头,直接建立从观测与指令到控制指令的端到端映射。然而,现有 VLA 模型在具身导航中的泛化能力仍受到明显限制。究其原因,网络规模的视觉语言先验知识擅长物体识别、指令解析和场景理解,却并未显式建模智能体自身行动所驱动的世界动态演化过程[4]。因此,VLA 模型在捕捉时间、几何与因果结构方面存在不足,往往将具身行为简化为条件映射问题,难以应对复杂的空间行动生成需求。
生物空间智能研究表明,导航本质上是一种预测性行为:人类会隐式预测自身运动带来的状态后果,并选择那些预期结果更接近目标的动作[5]。近年来,视觉基础模型尤其是视频生成模型的发展揭示了大规模视觉时序预训练所涌现出的强大预测能力[6]。基于视频的世界模型学习视觉场景在行动条件动态下的演化规律,从而获取关于运动、视角转换和物理演化的丰富时空先验——这正是基于 VLM 的 VLA 模型所缺乏的结构化知识。
基于上述观察,研究者提出将 VLN 重新形式化为预测驱动的问题:给定观测与指令,智能体预测世界在不同候选运动下的演化方式,并选择预期结果最符合指令要求的行动。然而,将现有视频生成模型直接应用于空间行动生成存在结构性障碍:一方面,大多数视频生成骨干网络以双向方式生成完整视频片段,而具身导航需要因果式的观察-行动-更新闭环;另一方面,通用视频生成优化目标侧重视觉合理性,而 VLN 要求行动感知的后果建模,即学习到的表征不仅要预测观测如何演化,还需编码哪些状态转换在几何上一致、可解码为行动,并有利于到达指令目标[7]。
二、WorldVLN 方法框架
2.1 问题建模
WorldVLN 将空中视觉语言导航形式化为部分可观测的序列决策问题。给定起始位置的自然语言指令,智能体执行一系列行动以在三维环境中逐步完成指令。在每一步,智能体接收以自我为中心的观测并预测一个航点行动,该行动由相对三维平移(Δx, Δy, Δz)和相对偏航变化(Δψ)组成。执行行动后,智能体姿态更新并诱导新的观测,重复此观察-行动过程直至预测停止动作或达到最大步长上限。导航成功的判定标准为最终位置与真实目标位置之间的欧氏距离小于设定阈值[7]。
2.2 模型架构:自回归世界行动预测
WorldVLN 的核心创新在于采用预训练的潜在自回归视频 Transformer 作为世界骨干网络,以捕捉智能体具身状态在潜在空间中的时序演化。与将预测潜在表征渲染为视频片段的传统用法不同,WorldVLN 将其重新解释为智能体运动所诱导的短视域世界状态转换,并在此基础上进行行动预测。
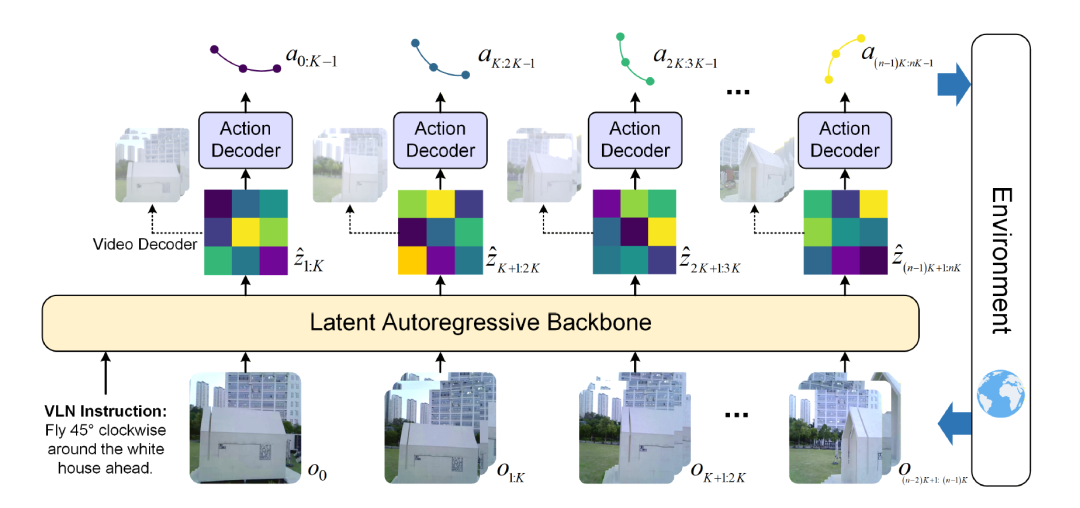
图1 WorldVLN 整体架构。模型依据指令与观测历史预测短视域潜在世界转换,解码为航点行动,并在执行后用新观测状态更新自回归上下文。
如图1所示,模型架构包含文本编码器 ψ、视频 VAE 编码器、潜在自回归 Transformer pθ 以及行动解码器 Dφ。设 eℓ = ψ(l) 为编码后的指令,K 为预测视域,z≤t 为截至时刻 t 的真实观测所编码的潜在上下文。依据视频骨干网络的时间自回归结构,下一潜在世界片段被预测为 ẑ_{t+1:t+K} ~ pθ(·|eℓ, z≤t)。该预测潜在表征不用于视频渲染,而是直接输入行动解码器:a_{t:t+K-1} = Dφ(ẑ_{t+1:t+K})。
执行行动后,智能体接收真实观测 o_{t+1:t+K},并通过视频编码器将其编码为真实潜在表征 z_{t+1:t+K} = E_vid(o_{t+1:t+K})。WorldVLN 的关键设计在于,它不使用模型预测的潜在表征继续生成,而是将真实潜在表征替换到自回归上下文中。由此形成的闭环推出流程为:
(eℓ, z₀) → ẑ₁:K → a₀:K-1 → o₁:K → z₁:K → ẑ_{K+1:2K} → …
每一生成的潜在片段用于解码航点行动序列,而后续自回归预测则基于真实观测编码的潜在表征进行,从而确保闭环决策过程始终锚定在真实世界状态之上。
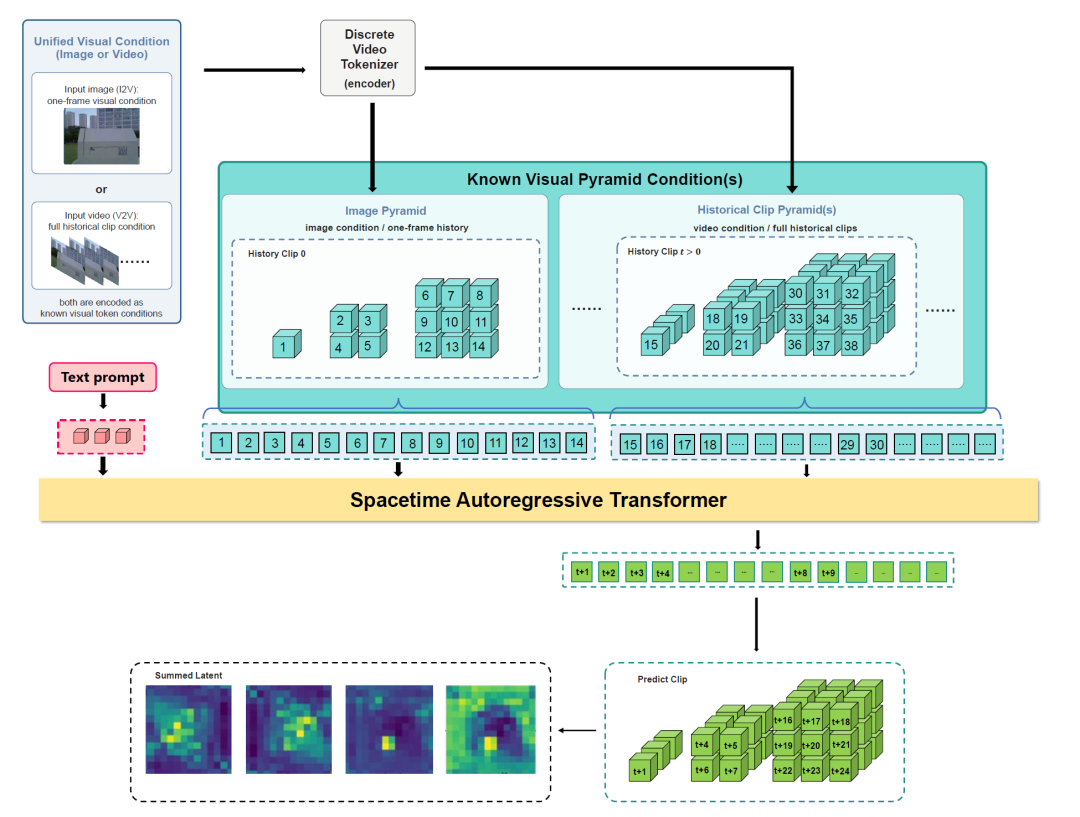
图2 潜在空间时空自回归世界骨干网络架构细节。输入图像或历史视频被编码为已知视觉金字塔条件,与文本令牌共同预测未来目标片段金字塔,聚合为输出潜在表征供行动解码使用。
图2展示了骨干网络的详细架构。视觉标记器将输入图像或视频编码为紧凑潜在表征,并通过多尺度残差量化获得离散残差令牌块。时空自回归 Transformer 遵循由粗到精的空间尺度顺序进行下一尺度预测:先预测捕捉全局结构的低分辨率令牌块,再逐步预测提供局部细节的高分辨率令牌块。沿时间维度,模型执行片段级自回归——首段目标片段基于已知视觉条件预测,后续片段则基于前序目标片段条件预测。预测完成后,多尺度令牌块合并为对应潜在表征,作为未来世界状态表征输入行动解码器[7]。
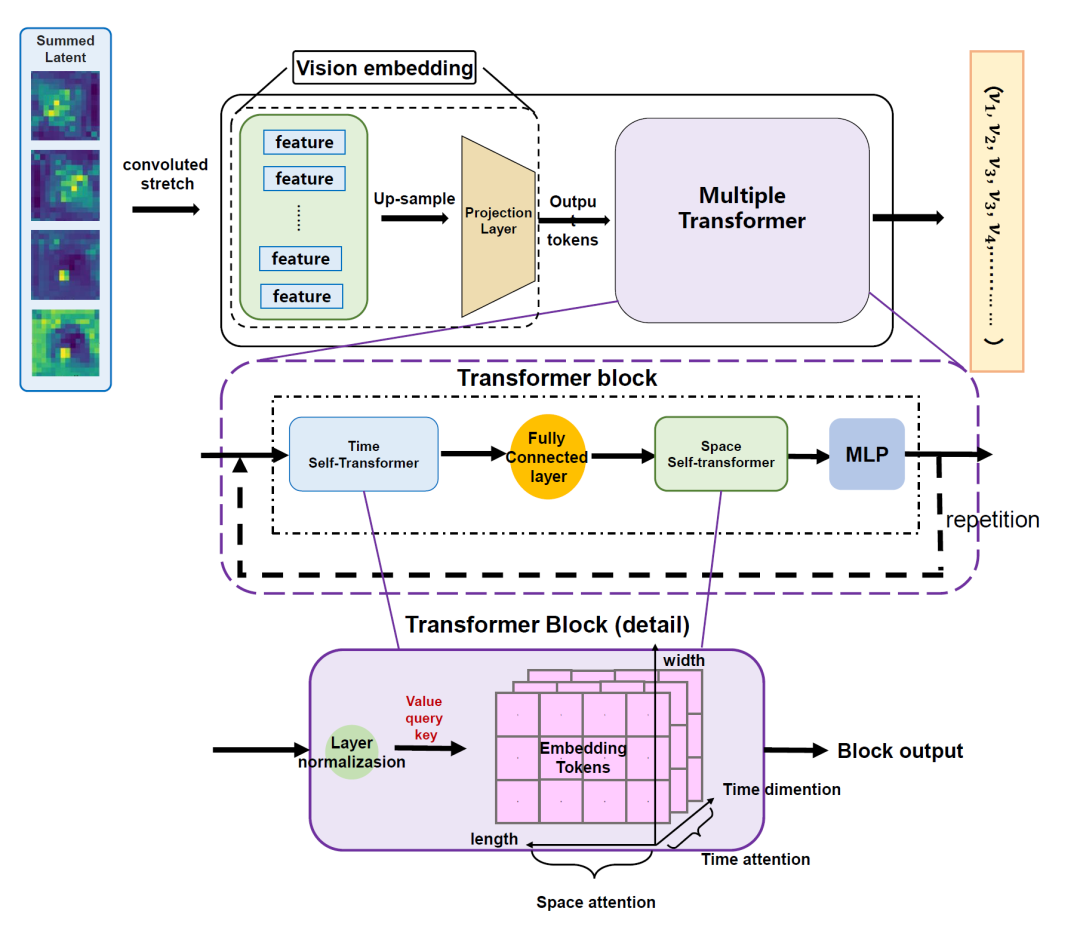
图3 行动解码器架构。世界模型输出的潜在表征经视觉嵌入模块转换为时空嵌入令牌,通过分解式时空注意力建模行动相关特征,最终回归为连续无人机导航行动。
行动解码器(图3)接收世界模型输出的未来潜在表征,将其视为包含短视域未来状态变化的紧凑时空表征。该表征编码了与视角变化、空间结构变化和运动趋势相关的时空信息,为行动推断提供直接基础。解码器结构上包含视觉嵌入模块、时空 Transformer 骨干和行动回归头。视觉嵌入模块通过特征重塑、卷积映射、上采样和投影将输入片段级潜在转换为统一时空嵌入令牌;多个 Transformer 块通过分解式时空注意力建模行动相关特征——时间注意力捕捉潜在帧间的运动演化与视角变化,空间注意力建模每帧潜在表征内的几何结构与空间关系;最终聚合的时空表征经 MLP 行动头回归为连续行动向量[7]。
2.3 两阶段训练框架
WorldVLN 采用两阶段训练策略,逐步对齐视频生成骨干网络与世界行动动态。
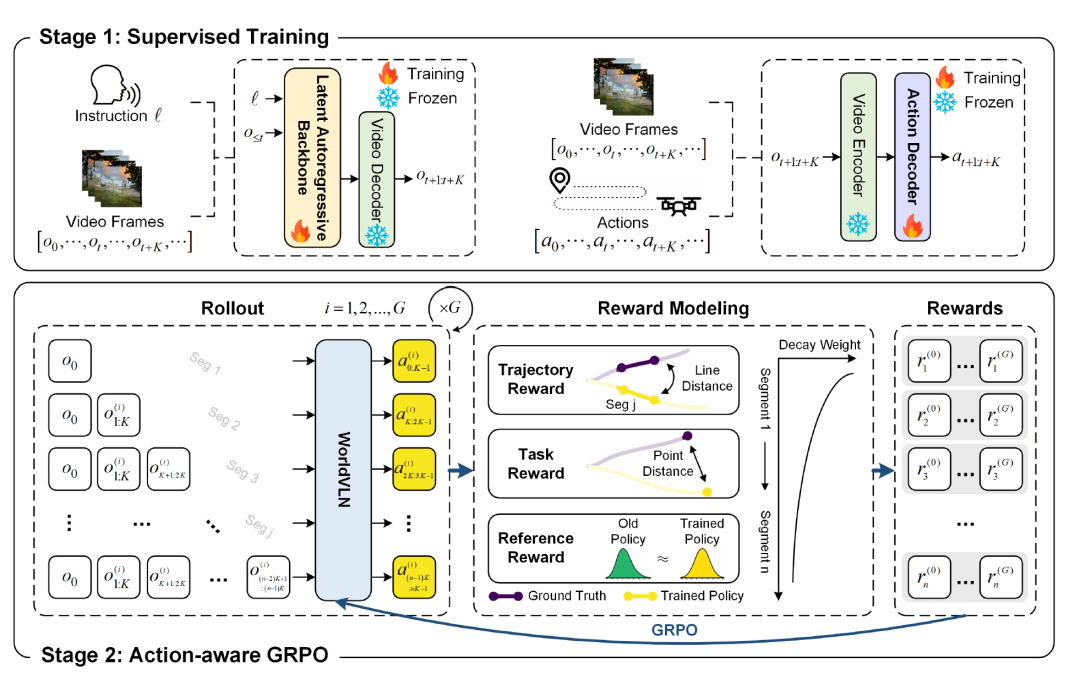
图4 两阶段训练框架。阶段一通过监督学习将视频先验根植于指令条件导航动态并训练行动解码器;阶段二通过 Action-aware GRPO 进行在线推出优化,结合轨迹、任务与参考奖励及时间衰减加权。
**阶段一:监督式训练。**潜在自回归骨干网络的监督微调采用配对导航指令与以自我为中心的导航视频作为训练数据。视频被划分为初始片段和多个未来片段,每个未来片段包含 K=16 帧,对应潜在/令牌空间中的 4 个时间步。模型在语言指令和完整真实观测历史条件下,预测当前片段的离散多尺度令牌表征。通过保留视频解码器作为训练时视觉监督接口,骨干网络被优化向未来视觉预测,同时保持可被视频解码器解码。行动解码器的监督训练采用配对导航视频与轨迹数据,每个视频片段编码为潜在表征后,解码器被训练以恢复专家行动。为加速收敛,解码器使用视频解码器特征和基于学习的视觉里程计骨干进行初始化,两者均提供从视觉状态转换到相机位姿运动的有用先验[7]。
**阶段二:Action-aware GRPO。**为将自回归世界行动模型与导航结果进一步对齐,研究者引入了专为自回归 WAM 设计的 Action-aware Group Relative Policy Optimization(GRPO)方法。训练过程中,模型在模拟器中执行在线自回归推出,遵循与推理时相同的观察-行动流程。对于每个导航案例,从当前策略采样 G 组在线推出,每组包含 n 个自回归决策片段。第 j 个行动片段的奖励定义为:
r_j^(i) = γ^(j-1) (λ_traj · r_traj,j^(i) + λ_task · r_task,j^(i) + λ_ref · r_ref,j^(i))
其中包含三项奖励:轨迹奖励通过衡量预测行动与专家行动的距离提供局部几何监督;任务奖励通过评估推出终点与真实目标位置的终端距离提供全局结果评价;参考奖励通过评估参考策略下采样片段行动的概率,正则化更新策略以防止过度偏离原始策略。时间衰减加权 γ^(j-1)(0 < γ < 1)使早期决策获得更大权重,因为早期错误会影响更长的未来观测、行动链和累积轨迹漂移。最终,策略通过裁剪 GRPO 目标进行更新,优化实际在线推出计算的奖励,使模型学会考虑当前航点决策如何影响下游观测、未来行动和最终导航成功[7]。
三、实验验证与结果分析
3.1 实验设置与基准测试
研究者在两个互补的无人机基准测试上评估 WorldVLN:UAV-Flow 和 IndoorUAV-VLA。UAV-Flow 遵循"Flying-on-a-Word"任务设定,评估模型在语言条件无人机控制下生成低层飞行行动的能力,涵盖接近、着陆、移动、平移、升降等多种细粒度飞行技能类别。IndoorUAV-VLA 是 IndoorUAV 的室内 VLA 子集,将长程室内导航轨迹分割为短子轨迹,每个指令通常对应 1-3 个局部无人机行动,评估连续三维室内环境中的局部空间理解、朝向控制和细粒度行动生成[7]。

图5 UAV-Flow 基准测试中的定性示例,涵盖目标导向运动、基本平移、垂直控制和物体相对运动等多样化飞行技能。

图6 IndoorUAV-VLA 基准测试示例。Easy、Medium、Hard 分别对应递增的行动组合复杂度,要求无人机执行一、二或三种类型的低层行动。
WorldVLN 采用 InfinityStar-8B 作为潜在自回归骨干网络,行动解码器基于 Wan VAE 和 TSformer-VO 风格先验初始化。训练在 8 块 NVIDIA A800 80GB GPU 上进行,模拟器推出在 RTX 4090 工作站上执行。对比基线涵盖传统 VLN 方法、无人机专用或航点策略,以及通用 VLA 模型(包括基于 OpenVLA 和 π0 的变体)[7]。
3.2 定量结果
实验结果表明,WorldVLN 在室外和室内无人机基准测试上均取得了显著优势。在 UAV-Flow-Sim 测试集上,WorldVLN 在固定模板指令和开放词汇指令设置下分别达到 79.12% 和 78.02% 的平均成功率(Success Rate, SR),相比最强基线分别提升 13.51 和 12.24 个百分点。在 IndoorUAV-VLA 全测试集上,WorldVLN 达到 41.76% 的 SR,相比最优基线提升 14.60 个百分点[7]。
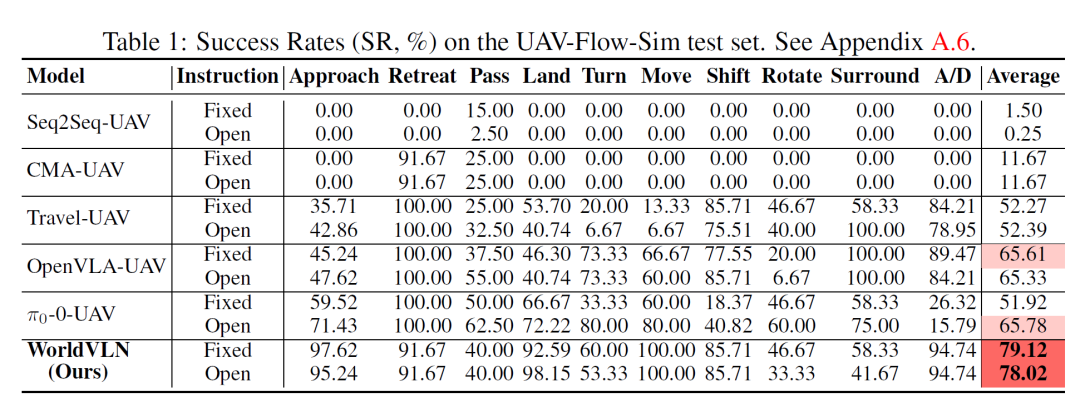
表1 UAV-Flow-Sim 测试集上的成功率(SR, %)对比。WorldVLN 在固定模板和开放词汇指令下均取得最优平均性能。
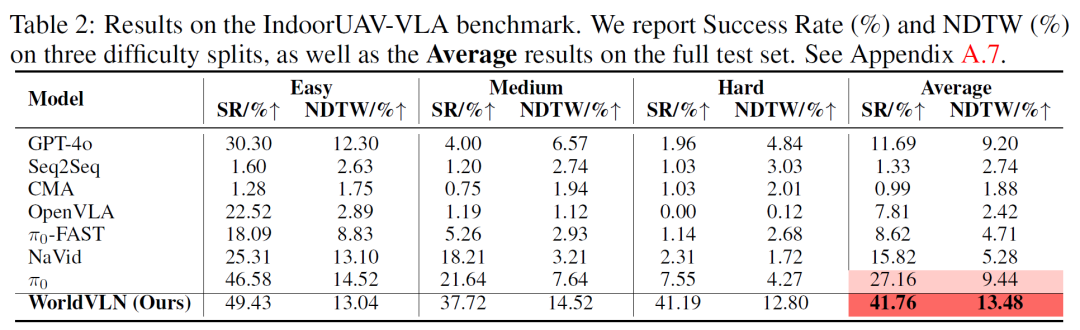
表2 IndoorUAV-VLA 基准测试结果。报告了 Easy、Medium、Hard 三个难度划分以及全测试集平均的成功率(SR, %)和 NDTW(%)。
与 VLA 基线的对比进一步凸显了世界行动建模的优势。相较于 OpenVLA,WorldVLN 在 UAV-Flow-Sim 上平均 SR 提升 13.10 个百分点,在 IndoorUAV-VLA 上提升 33.95 个百分点;相较于 π0,分别提升 19.72 和 14.60 个百分点。这些一致的增益表明,基于预测的世界行动建模相比直接观测到行动的映射,能更有效地适应空中视觉语言导航任务[7]。
更具意义的是,WorldVLN 在挑战性场景上展现了更大优势。在 IndoorUAV-VLA 的 Medium 和 Hard 划分上,WorldVLN 分别比最优基线提升 16.08 和 33.64 个百分点的 SR。在 UAV-Flow-Sim 上,模型在 Approach、Land、Move、Shift、Ascend/Descend 等空间精确任务上表现尤为出色。这些结果说明,预测潜在行动后果对于复杂空中导航任务特别有益,能够帮助模型更好地处理多步行动组合、精确空间关系和三维终端状态控制[7]。
3.3 消融实验与定性分析
为深入理解 WorldVLN 各组件的贡献,研究者设计了系统的消融实验。
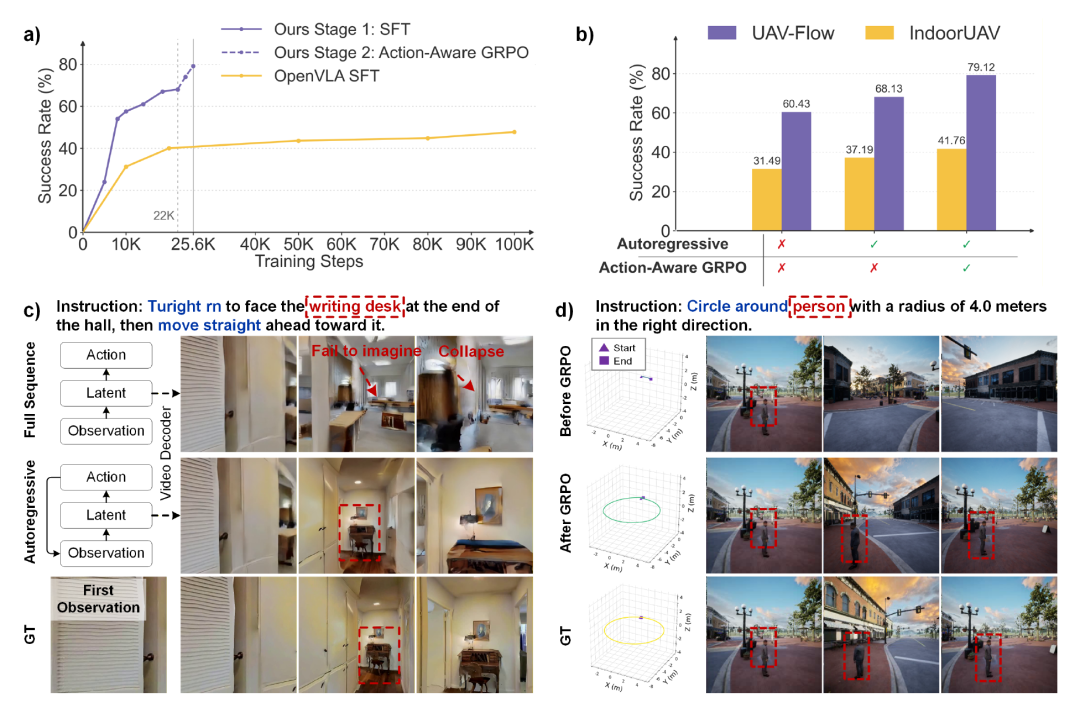
图7 消融实验分析。(a) 训练动态对比;(b) 自回归建模与 Action-aware GRPO 的定量效果;© 潜在预测探针可视化;(d) Action-aware GRPO 对空间行动准确性的提升。
世界行动模型是否比 VLA 学习更高效? 如图7(a)所示,在 UAV-Flow 上从零开始训练 OpenVLA 与 WorldVLN 的对比表明,在相同训练步数预算下,WorldVLN 阶段一监督训练后的成功率显著高于 OpenVLA-SFT。这表明 WAM 形式化为空中 VLN 提供了比直接 VLA 式观测到行动映射更有效的学习结构[7]。
为何需要自回归预测? 为隔离自回归建模的效果,研究者使用相同骨干网络和解码器对比了全序列监督微调与自回归监督微调。图7(b)显示,自回归世界行动建模在 UAV-Flow 和 IndoorUAV 上分别提升成功率 5.7 个百分点以上。潜在表征可视化探针(图7©)进一步揭示:全序列变体在长程潜在预测中出现语义漂移和场景崩溃,而自回归变体通过反复纳入新观测状态,保持了更连贯的视觉空间表征,包括指令相关的地标信息。这说明闭环自回归更新改善了潜在世界预测,为行动解码提供了更可靠的表征基础[7]。
Action-aware GRPO 学到了什么? 对比仅经阶段一监督训练与完整两阶段框架的模型,图7(b)显示添加 Action-aware GRPO 后在两个基准上均有进一步提升。图7(a)表明,在阶段一 SFT 性能接近饱和后,Action-aware GRPO 带来了超过 10 个百分点的额外增益。图7(d)直观展示了导航行为在 RL 前后的变化:优化前模型无法执行几何精确的圆形轨迹,经 RL 后模型产生的轨迹更好地遵循了"环绕"行为意图,且更接近真实路径。这表明 Action-aware GRPO 使模型学会超越视觉合理性的行动后果优化,提升了行动准确性和目标导向行为[7]。
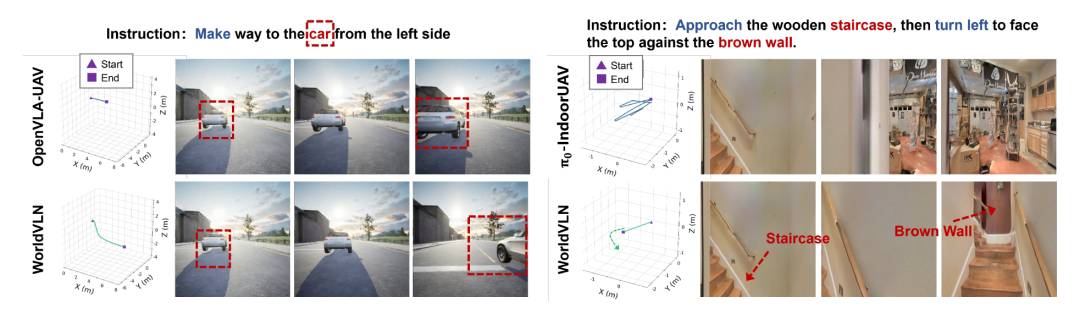
图8 定性案例分析。与 VLA 基线相比,WorldVLN 在室外以物体为中心的机动和室内地标导航中均展现出更强的空间定位和更准确的航点行动。
图8的定性对比进一步印证了上述结论。在室外案例中,指令要求无人机从左侧接近汽车,OpenVLA-UAV 基线直接朝向车辆移动,未能执行精确的空间机动;而 WorldVLN 正确将汽车定位为目标地标,生成更平滑且相对定位准确的轨迹。在室内案例中,指令要求接近楼梯并左转面向棕色墙壁,π0-IndoorUAV 基线未能维持与楼梯和墙壁的预期空间关系;WorldVLN 则持续识别相关地标,按指令空间布局完成接近和左转行为。这些案例表明,潜在世界行动预测相比直接 VLA 式行动映射,能够实现更准确的空间定位和航点生成[7]。
四、真实世界无人机部署
为验证 WorldVLN 在真实环境中的泛化能力,研究团队在自建四旋翼平台上进行了零样本迁移实验。该平台轴距为 250mm,配备 Logi C270 RGB 相机、Jetson Orin NX 16GB 机载计算机和 CUAV PX4 飞控。WorldVLN 策略在远程服务器上运行:RGB 观测从无人机传输至服务器,预测的航点行动传回执行。室内实验在 10m×15m×3m 的飞行场地进行,配备 14 相机动作捕捉系统;室外实验在开放区域进行,使用 GPS 配合 TFmini-S 激光雷达进行高度估计[7]。
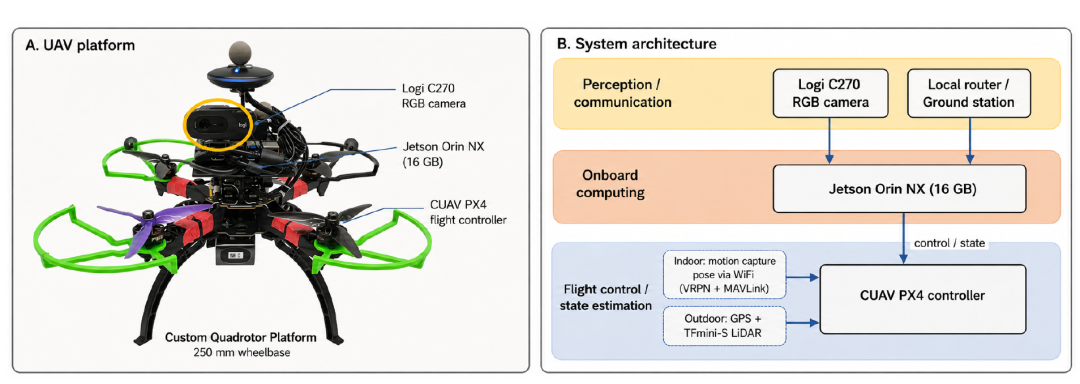
图9 真实世界无人机平台与系统架构。左:自定义四旋翼平台;右:系统架构涵盖感知通信、机载计算和飞行控制状态估计模块。
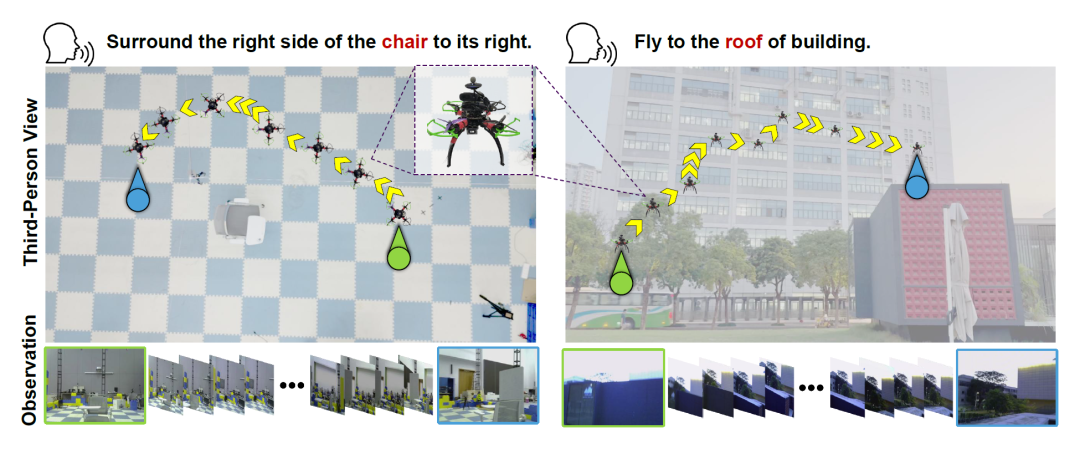
图10 真实世界无人机部署案例。WorldVLN 仅在模拟器中训练,即可在真实无人机平台上遵循语言指令生成可执行航点行动,覆盖室内物体对齐和室外垂直导航场景。
如图10所示,尽管 WorldVLN 仅使用模拟器数据训练,它仍能在真实无人机平台上遵循语言指令并生成可执行航点行动。室内案例要求无人机在受限房间中接近并与目标物体对齐,智能体必须依赖近距离视觉地标并避免大视角偏差。室外案例进一步考察了模型在垂直方向的导航能力。这些结果为学习到的世界行动表征能够从模拟环境迁移到真实世界无人机部署提供了有力证据,且无需额外的真实世界微调[7]。
部署细节说明
需要指出的是,动作捕捉姿态(室内)和 GPS/激光雷达测量(室外)仅用于底层飞行稳定、安全运动执行和轨迹记录,并不作为模型输入提供给 WorldVLN。高层导航决策完全基于以自我为中心的 RGB 观测和语言指令做出。当前部署采用服务器端推理,未来工作将探索模型压缩和推理加速以实现完全机载运行[7]。
五、总结与未来展望
本文介绍的 WorldVLN 是首个面向空中视觉语言导航的自回归世界行动模型。通过将视频生成的潜在自回归骨干网络重新应用于短视域世界状态预测,并设计直接解码航点行动的闭环架构,WorldVLN 为空中 VLN 提供了一种简洁的隐式预测架构。配套提出的两阶段训练框架——先进行监督式导航动态 grounding,再引入 Action-aware GRPO 强化学习——进一步将潜在世界行动表征与导航结果对齐。
实验结果表明,WorldVLN 在室内外无人机基准测试中取得了稳定且可迁移的性能,在更少训练步数预算下超越 VLA 基线 12 个百分点以上,在困难任务上优势更为明显。真实世界无人机部署则为从模拟到真实的零样本迁移提供了有希望的证据。这些成果共同表明,WorldVLN 为空间行动任务以及更广泛的具身智能领域提供了一条有前景的技术路线[7]。
展望未来,研究团队计划在以下几个方向继续深化:探索更具可扩展性的长程潜在预测架构,以支持长程视觉语言导航;开展模型压缩与推理加速研究,实现完全机载的实时推理;在更复杂的真实世界条件下验证系统鲁棒性,包括强光照变化、恶劣天气、动态障碍物和 GPS 受限环境;以及将世界行动建模范式拓展至更广泛的具身智能领域,如机器人操作和地面自主导航[7]。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 2
2 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)