卷积神经网络入门:卷积、特征图、下采样到底在干什么
1. 为什么目标检测不直接看原图,而要先做卷积
先说一句最核心的话:
原图只是像素堆,不能直接等于“语义理解”。
比如一张猫的图片,在计算机里本质上只是很多数字。
神经网络如果想知道:
-
哪里有边缘
-
哪里有纹理
-
哪里像耳朵
-
哪里像眼睛
-
哪一片区域更像“猫”
它就不能一直停留在原始像素层面,而要一步一步把原图变成更“有意义”的表示。
这个“逐层提炼信息”的过程,CNN 里最核心的工具之一就是:
卷积
2. 卷积到底是在干什么
先别急着上公式,先用一句人话说:
卷积就是拿一个小窗口,在图像上滑动,每到一个位置就做一次局部计算。
这个小窗口通常叫:
-
卷积核
-
kernel
-
filter
它的作用可以粗糙理解成:
专门去看某种局部模式
比如有的卷积核更容易对:
-
水平边缘
-
垂直边缘
-
纹理变化
-
亮度突变
产生强响应。
所以卷积不是“看整张图”,
而是:
先看局部,再逐层组合成更复杂的理解
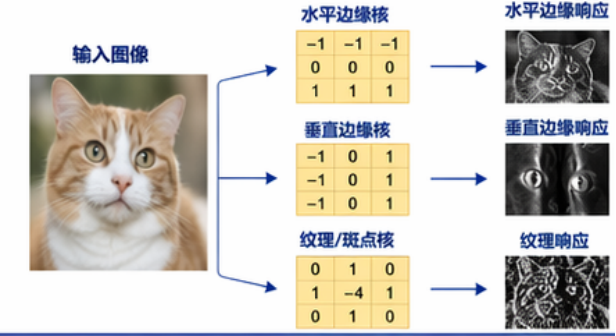
3. 一个最简单的卷积公式
卷积最基础的表达可以写成:
现在不用怕这个式子,我们拆开看。
这个公式里每个字母是什么意思
表示输入图像某个局部位置上的像素值。
表示卷积核里的权重。
表示偏置项。
表示输出特征图在位置 ((i,j)) 上的值。
这条公式本质在做什么
本质上就是:
把输入图像的一小块区域,和卷积核对应位置相乘,再全部加起来,最后再加一个偏置。
也就是:
局部区域 × 卷积核 → 求和 → 得到一个输出值
可以把它理解成一种“局部匹配打分”。
如果某一块区域和这个卷积核特别匹配,
那输出值就可能比较大;
如果不匹配,输出值就可能比较小。
4. 为什么卷积能提特征
卷积之所以能提特征,不是因为它能一下子“看懂整张图”,
而是因为它会对图像做逐层、逐步的特征提取与组合。
最开始输入网络的,只是原始图像的像素值。
这些像素本身只是一些数字,网络并不知道图里是什么物体,也不知道哪些部分更重要。
卷积层的作用,就是从这些原始像素中,一步一步提取出更有意义的表示。
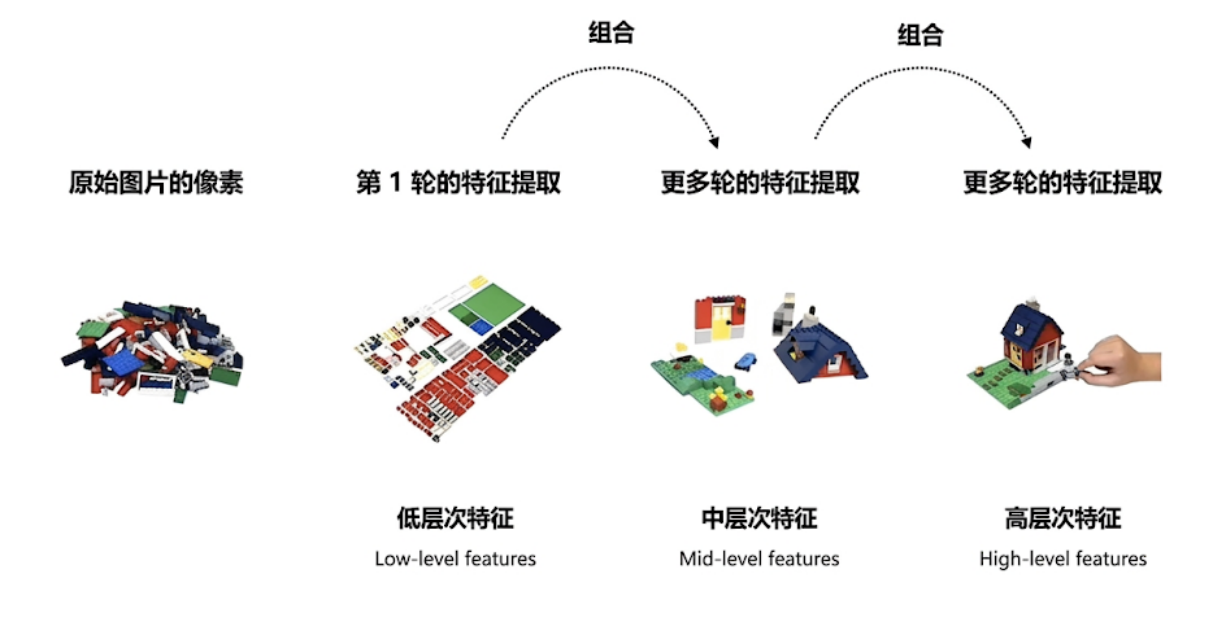
在浅层,网络通常先提取一些比较基础的局部信息,比如:
- 边缘
- 纹理
- 颜色变化
- 简单的局部形状
这些信息通常被称为低层特征(Low-level features)。
它们更接近图像本身的视觉细节,能够帮助网络先分辨出“哪里有结构变化、哪里有明显模式”。
随着网络继续加深,前面得到的低层特征会被进一步组合。
这时网络不再只关注单独的边缘或纹理,而是开始识别更复杂的局部结构,比如某些局部部件、局部区域组合或更完整的小形状。
这些通常被称为中层特征(Mid-level features)。
再往后,随着卷积层继续堆叠,这些中层结构还会进一步组合,逐渐形成更抽象、更接近语义层面的表示。
这时网络开始不仅仅知道“这里有一条边、那里有一块纹理”,而是逐渐能够理解“这一部分像某个物体部件”“这一整块区域可能对应某个完整目标”。
这些通常被称为高层特征(High-level features)。
所以,从原始像素到最终的高层表示,CNN 实际上经历的是一个不断重复的过程:
提取局部特征 → 组合已有特征 → 形成更高层次的特征
这也是为什么我们常说 CNN 是一种层级式特征提取器。
它不是直接从像素跳到“识别结果”,而是先提取低层特征,再形成中层特征,最后逐步得到高层语义特征。
5. 什么叫特征图 feature map
卷积做完后,不会直接输出“猫”或者“狗”。
它先输出的是:
特征图
特征图你可以理解成:
某种特征在整张图上各个位置的响应分布图
比如有一个卷积核特别擅长看“竖直边缘”,
那它卷积之后得到的一张特征图,就可以理解成:
这张图里哪里更像竖直边缘,哪里不像
所以特征图不是原图,而是原图经过某种特征提取之后得到的新表示。

6. 为什么卷积后会有很多通道
原图一般是:
-
灰度图:1 个通道
-
彩色图:3 个通道(RGB)
但卷积之后,输出往往会变成很多通道,比如:
-
16 通道
-
32 通道
-
64 通道
-
128 通道
为什么?
因为:
一个卷积核只能提一种模式,多个卷积核才能提多种模式
如果一层里有 64 个卷积核,那通常就会输出 64 张特征图。把这些特征图叠起来,就形成了一个多通道输出。
所以可以把“通道数变多”理解成:
模型在同时提取越来越多种不同类型的特征
7. 多通道卷积怎么理解
如果输入不是单通道,而是多通道,比如 RGB 图像,
那卷积就不是只看一个二维小块,而是看一个“带厚度的小块”。
比如输入是 3 通道,卷积核可能是:
这里的意思不是“三个卷积核”,而是:
-
高 3
-
宽 3
-
深度覆盖 3 个输入通道
最后这个卷积核会在三个通道上一起做计算,
然后合成一个输出值。
所以更准确地说:
卷积核不只是看平面,还会同时看所有输入通道
8. 输出尺寸怎么变:一个最常见公式
卷积后特征图大小怎么变,这是技术汇报里经常会提到的。
最常见公式是:
这里:
-
(N):输入尺寸
-
(K):卷积核大小
-
(P):padding
-
(S):stride
-
(O):输出尺寸
它在回答一个问题:
输入经过卷积后,输出特征图还剩多大
比如输入宽高是 (640),
卷积核大小 (3),
stride 是 (1),
padding 是 (1),
那么输出还是 (640)。
因为:
这就是为什么很多卷积,如果配了合适 padding,输出尺寸可以不变。
9. stride 是什么
stride 就是:
步长
你可以理解成卷积核每次滑动时走几步。
stride = 1
表示每次只移动 1 个像素,扫得更细。
stride = 2
表示每次移动 2 个像素,扫得更快,但输出会变小。
所以 stride 变大,通常意味着:
-
输出特征图尺寸减小
-
计算量下降
-
信息会更粗一些
这就和下一个概念紧密相关:
下采样
10. 下采样到底在干什么
下采样可以先理解成一句话:
把特征图尺寸缩小
比如:
-
变成
-
变成
这样做的原因主要有两个:
1. 降低计算量
特征图太大,后续计算会很慢。
2. 扩大感受范围
特征图缩小后,后面的一个点往往对应原图更大范围的信息。
所以在 CNN 里,下采样不是“单纯压缩图片”,
而是:
在保留主要信息的同时,让网络逐步看到更大范围的上下文
11. 下采样通常怎么做
常见方法有两个:
方法 1:stride > 1 的卷积
比如 stride=2 的卷积。
它在做特征提取的同时,也把尺寸缩小了。
方法 2:池化 pooling
比如 max pooling。
最大池化的意思是:
在一个小区域里,只保留最大的值。
一个简单形式可以写成:
意思是:
在某个局部窗口 内,取最大值作为输出。
-
卷积下采样:更灵活,也能学参数
-
池化下采样:更简单,参数少
现代检测网络里,经常更偏向用卷积来完成下采样。
12. 感受野 receptive field 是什么
感受野可以简单理解成:
特征图上某个位置,能“看到”原图多大范围。
比如:
-
浅层某个点,可能只对应原图一小块区域
-
深层某个点,可能对应原图很大一片区域
随着网络变深、经过多次卷积和下采样,感受野通常会越来越大。
这意味着什么?
意味着深层特征更容易整合全局信息,更有机会理解“这个局部到底属于什么目标”。
13. 为什么浅层适合小目标,深层适合大语义
浅层特征
-
分辨率高
-
位置细节保留多
-
更适合小目标、边缘、细节
深层特征
-
分辨率低
-
语义更强
-
更适合整体理解、大目标判断
所以检测网络不能只用最后一层。
因为最后一层虽然语义强,但很多细节已经没了。
这也是为什么后面会需要:
-
FPN
-
PAN
-
多尺度特征融合
也就是把浅层和深层的信息结合起来。
14. CNN 一层一层到底在干什么
第一步:从原图提局部基础特征
比如边缘、纹理。
第二步:继续组合成更复杂特征
比如轮廓、局部部件。
第三步:逐渐扩大感受野
让每个位置能结合更大范围的信息。
第四步:得到适合任务使用的高层特征
如果是分类,就拿去做整图判别;
如果是检测,就拿去做位置和类别预测。
所以 CNN 的本质不是“疯狂堆层”,
而是:
逐层把像素表示变成任务可用的特征表示
15. 对 YOLO 来说,这些概念分别对应什么
卷积
负责提取局部特征,是最基础的计算单元。
特征图
是图像经过卷积后的中间表示,供后续检测头使用。
下采样
让特征图逐步缩小,减少计算,同时扩大感受野。
多通道
表示网络在同时提取很多不同类型的特征。
感受野
决定某个位置能结合多大范围的信息,对理解目标整体很重要。
“卷积神经网络为什么适合视觉任务?”
因为卷积通过局部连接和权值共享,能够高效提取图像的空间局部特征;随着网络加深,特征会从低层边缘纹理逐渐过渡到高层语义表示;再结合下采样,网络既能降低计算量,又能扩大感受野,因此适合做图像分类、目标检测这类视觉任务。
16. 这一篇的几个公式
公式 1:卷积的基本形式
它表达的是:
卷积核在局部区域上做加权求和,得到输出特征图上的一个值
公式 2:输出尺寸公式
它表达的是:
卷积后特征图尺寸怎么变化
公式 3:最大池化的基本形式
它表达的是:
在一个局部窗口里取最大响应
17. 本篇小结
原图不是直接可用的语义信息,所以网络需要通过卷积逐层提特征;卷积会生成特征图,多通道表示多种特征;下采样会缩小尺寸、扩大感受野;浅层偏细节,深层偏语义,这正是后面 YOLO 做多尺度检测的基础。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 10
10 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)