hello-agent总结
一、智能体
1.传统智能体和LLM智能体区别

2.什么是LLM驱动的智能体
| 模块 | 功能 |
|---|---|
| 大语言模型(LLM) | 作为核心推理引擎,负责理解任务、生成计划和决策 |
| 记忆模块 | 包括短期记忆(当前对话上下文)和长期记忆(外部向量数据库存储历史经验) |
| 规划模块 | 将复杂任务分解为子步骤,能够自我反思和调整计划 |
| 工具使用 | 调用外部工具/API(如搜索、代码执行、数据库查询、计算器等)扩展能力 |
| 行动执行 | 将决策转化为具体行动,并接收环境反馈形成闭环 |
工作原理
-
感知:接收用户指令或环境状态
-
推理与规划:LLM 分析任务,拆解为可执行的步骤
-
工具调用:根据需要使用搜索、代码、API 等工具获取信息或执行操作
-
行动:执行具体动作(如发送请求、更新数据库、输出结果)
-
反馈与迭代:根据行动结果调整下一步计划,直至任务完成
3.智能体的运行机制
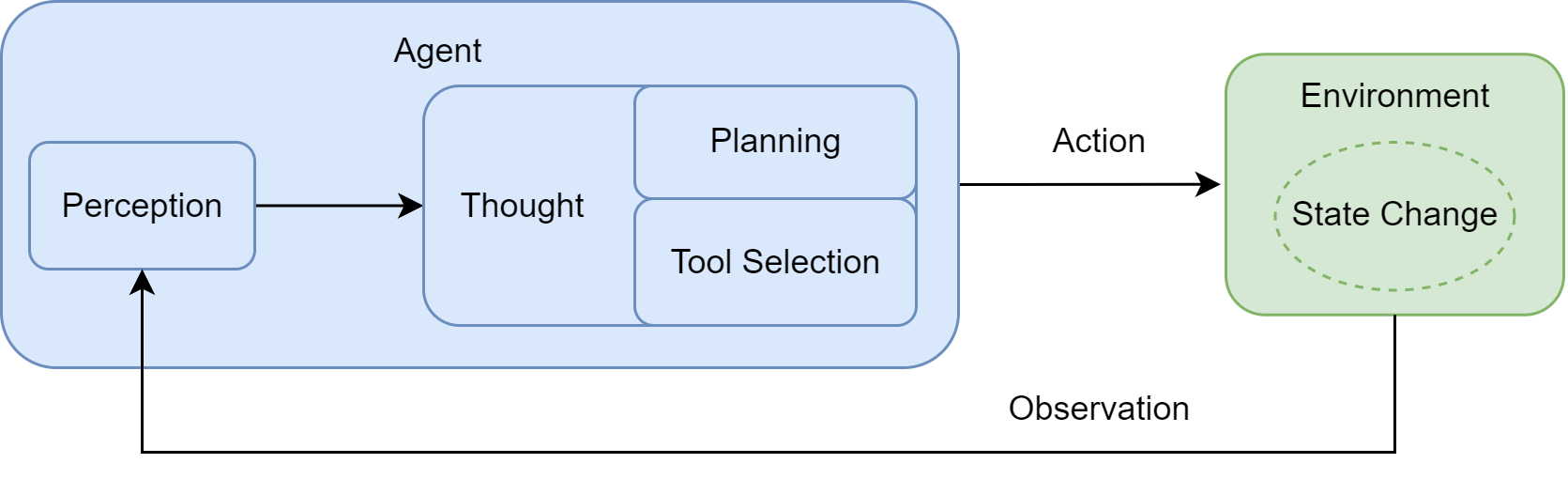
- 感知(Perception):这是循环的起点。智能体通过其传感器(例如,API的监听端口、用户输入接口)接收来自环境的输入信息。这些信息,即观察(Observation),既可以是用户的初始指令,也可以是上一步行动所导致的环境状态变化反馈。
- 思考(Thought):接收到观察信息后,智能体进入其核心决策阶段。对于LLM智能体而言,这通常是由大语言模型驱动的内部推理过程。如图所示,“思考”阶段可进一步解读为两个关键环节:
- 规划(Planning):智能体基于当前的观察及其内部记忆,更新对任务和环境的理解,并制定或调整一个行动计划。这可能涉及将复杂的目标分解为一系列更具体的子任务。
- 工具选择(Tool Selection):根据当前计划,智能体从其可用的工具库中,选择最适合执行下一步骤的工具,并确定调用该工具所需的具体参数。
- 行动(Action):决策完成后,智能体通过其执行器(Actuators)执行具体的行动。这通常会调用一个选定的工具(如代码解释器、搜索引擎API),从而对环境施加影响,意图改变环境的状态。
4.智能体最终形态
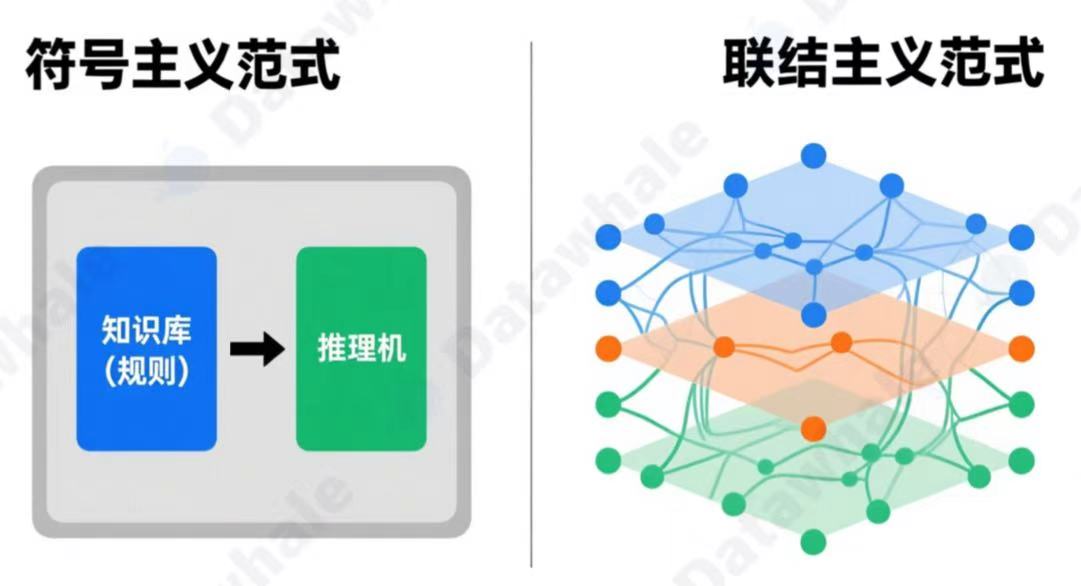
4.1联结主义范式
4.2基于强化学习的智能体
强化学习核心框架:与环境互动,根据反馈信号优化自身行为
智能体(Agent):学习者和决策者。在AlphaGo的例子中,就是其决策程序。
环境(Environment):智能体外部的一切,是智能体与之交互的对象。对AlphaGo而言,就是围棋的规则和对手。
状态(State, S):对环境在某一时刻的特定描述,是智能体做出决策的依据。例如,棋盘上所有棋子的当前位置。
行动(Action, A):智能体根据当前状态所能采取的操作。例如,在棋盘的某个合法位置上落下一
子。
奖励(Reward, R):环境在智能体执行一个行动后,反馈给智能体的一个标量信号,用于评价该行动在特定状态下的好坏。例如,在一局棋结束后,胜利获得+1的奖励,失败获得-1的奖励。
4.3基于大规模数据的预训练
从特定任务到通用模型:
1. 预训练阶段:首先在一个包含互联网级别海量文本数据的通用语料库上,通过自监督学(Self-supervised Learning)的方式训练一个超大规模的神经网络模型。这个阶段的目标不是完成任何特定任务,而是学习语言本身内在的规律、语法结构、事实知识以及上下文逻辑。最常见的目标是“预测下一个词”。
2. 微调阶段:完成预训练后,这个模型就已经学习到了和数据集有关的丰富知识。之后,针对特定的下游任务,只需使用少量该任务的标注数据对模型进行微调,即可让模型适应对应任务。
大语言模型的诞生与涌现能力:
上下文学习(In-context Learning):无需调整模型权重,仅在输入中提供几个示例(Few-shot)
甚至零个示例(Zero-shot),模型就能理解并完成新的任务。
思维链(Chain-of-Thought)推理:通过引导模型在回答复杂问题前,先输出一步步的推理过程,可以显著提升其在逻辑、算术和常识推理任务上的准确性。
二、大语言模型基础
1.语言模型
语言模型就是计算一个词序列出现的概率。
(1)N-gram
N-gram 模型虽然简单有效,但有两个致命缺陷:
1. 数据稀疏性 (Sparsity) :如果一个词序列从未在语料库中出现,其概率估计就为 0,这显然是不合理的。虽然可以通过平滑 (Smoothing) 技术缓解,但无法根除。
2. 泛化能力差:模型无法理解词与词之间的语义相似性。例如,即使模型在语料库中见过很多次 agent learns,它也无法将这个知识泛化到语义相似的词上。当我们计算 robot learns 的概率时,如果 robot这个词从未出现过,或者 robot learns 这个组合从未出现过,模型计算出的概率也会是零。模型无法理解agent 和 robot 在语义上的相似性。
(2)神经语言模型与词嵌入
核心思想可以分为两步:
1. 构建一个语义空间:创建一个高维的连续向量空间,然后将词汇表中的每个词都映射为该空间中的一个点。这个点(即向量)就被称为词嵌入 (Word Embedding) 或词向量。在这个空间里,语义上相近的词,它们对应的向量在空间中的位置也相近。例如, agent 和 robot 的向量会靠得很近,而 agent 和 apple 的向量会离得很远。
2. 学习从上下文到下一个词的映射:利用神经网络的强大拟合能力,来学习一个函数。这个函数的输入是前个词的词向量,输出是词汇表中每个词在当前上下文后出现的概率分布。
(3)循环神经网络(RNN)与长短时记忆网络(LSTM)
RNN:
引入循环连接,让网络在处理序列时保留“记忆”,每个时间步的输出依赖于当前输入和上一个时间步的隐藏状态。
LSTM:
核心思想:通过门控机制精细控制信息的遗忘、写入和输出,解决 RNN 的长距离依赖问题。
核心组件:
-
遗忘门:决定丢弃哪些旧信息
-
输入门:决定存储哪些新信息
-
输出门:决定输出哪些信息
2.Transformer架构
注意力机制
(1)自注意力机制
为了实现上述过程,自注意力机制为每个输入的词元向量引入了三个可学习的角色:
查询 (Query, Q):代表当前词元,它正在主动地“查询”其他词元以获取信息。
键 (Key, K):代表句子中可被查询的词元“标签”或“索引”。
值 (Value, V):代表词元本身所携带的“内容”或“信息”。

它将原始的 Q, K, V 向量在维度上切分成 h 份(h 就是“头”数),每一份都独立地进行一次单头注意力的计算。这就好比让 h 个不同的“专家”从不同的角度去审视句子,每个专家都能捕捉到一种不同的特征关系。最后,将这 h 个专家的“意见”(即输出向量)拼接起来,再通过一个线性变换进行整合,就得到了最终的输出。
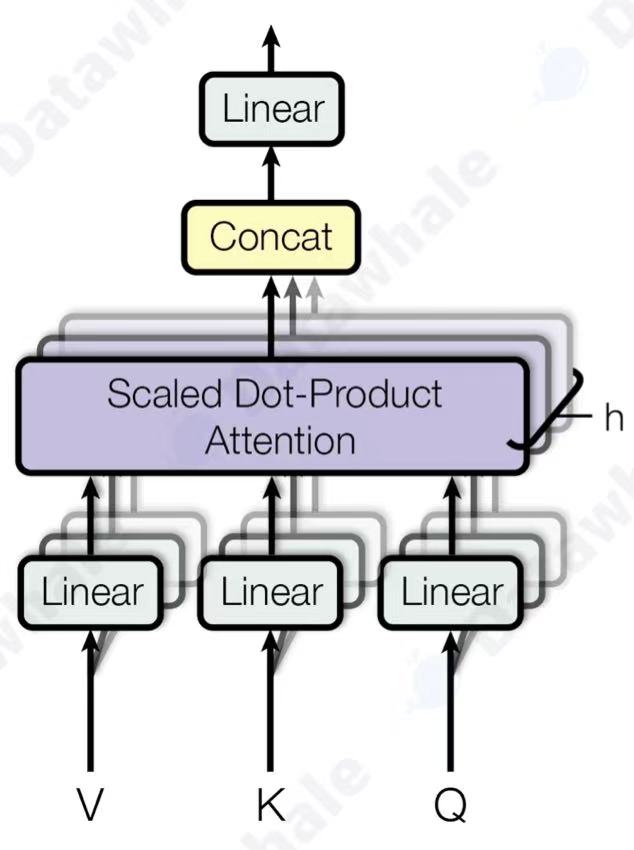
(2)前馈神经网络
前馈神经网络是最基本、最经典的人工神经网络结构,信息单向流动——从输入层经过隐藏层到输出层,没有任何循环或反馈连接。"前馈"意味着:数据向前传播,不会回头。
前馈神经网络是最基础的神经网络结构,信息单向流动,通过全连接层和非线性激活函数实现函数逼近,虽无记忆能力且参数多,但作为深度学习基石至今仍广泛使用。

(3)残差连接与层归一化
它们解决了深层网络训练中的两大难题:梯度消失/退化和内部协变量偏移。
残差连接(Residual Connection,也称“跳跃连接”或“短路连接”)是指将层的输入直接跨层加到该层的输出上。
层归一化(Layer Normalization, LN)是在单个样本的所有特征维度上进行归一化,使其均值为0、方差为1。
| 技术 | 解决的核心问题 |
|---|---|
| 残差连接 | 让梯度直接传播到浅层,解决梯度消失;让深层至少不差于浅层 |
| 层归一化 | 稳定每层输入的分布,加速收敛;配合残差防止值爆炸 |
3.Decoder-Only架构
抛弃了编码器,只保留了解码器部分。
解码器通过掩码自注意力机制来保证在预测第t个词时,不去偷看第t+1个词的答案。
Decoder-Only 架构的优势
这种看似简单的架构,却带来了巨大的成功,其优势在于:
训练目标统一:模型的唯一任务就是“预测下一个词”,这个简单的目标非常适合在海量的无标注文本数据上进行预训练。
结构简单,易于扩展:更少的组件意味着更容易进行规模化扩展。今天的 GPT-4、Llama 等拥有数千亿甚至万亿参数的巨型模型,都是基于这种简洁的架构。
天然适合生成任务:其自回归的工作模式与所有生成式任务(对话、写作、代码生成等)完美契合,这也是它能成为构建通用智能体基础的核心原因。
4.与大语言模型交互
(1)提示工程
1.模型采用参数
在提示工程中,采样参数用于控制大语言模型(LLM)生成文本时的随机性和多样性。它们决定模型从概率分布中"选择"下一个词的方式。
Top-k
只保留概率最高的 k 个候选词,其余概率置零后重新归一化。
Top-p
动态选择概率和达到 p 的最小候选词集合(核采样)。
2.零样本、单样本与少样本提示
- 零样本提示 (Zero-shot Prompting) 这指的是我们不给模型任何示例,直接让它根据指令完成任务。这得益于模型在海量数据上预训练后获得的强大泛化能力。
- 单样本提示 (One-shot Prompting) 我们给模型提供一个完整的示例,向它展示任务的格式和期望的输出风格。
- 少样本提示 (Few-shot Prompting) 我们提供多个示例,这能让模型更准确地理解任务的细节、边界和细微差别,从而获得更好的性能。
3.指令调优的影响
对文本补全模型的提示(你需要用少样本提示“教会”模型做什么)令调优模型的提示(你可以直接下达命令)
4.基础提示技巧
角色扮演 (Role-playing) 通过赋予模型一个特定的角色,我们可以引导它的回答风格、语气和知识范围,使其输出更符合特定场景的需求。
上下文示例 (In-context Example) 这与少样本提示的思想一致,通过在提示中提供清晰的输入输出示例,来“教会”模型如何处理我们的请求,尤其是在处理复杂格式或特定风格的任务时非常有效。
5.思维链
对于需要逻辑推理、计算或多步骤思考的复杂问题,直接让模型给出答案往往容易出错。思维链 (Chain-of-Thought, CoT) 是一种强大的提示技巧,它通过引导模型“一步一步地思考”,提升了模型在复杂任务上的推理能力。实现 CoT 的关键,是在提示中加入一句简单的引导语,如“请逐步思考”或“Let's think step by step”。
(2)文本分词
字节对编码(BPE)是一种子词分词算法,通过**迭代合并**语料中最频繁共现的字符对来构建词汇表,最终将文本切分为常见子词(如"er"、"ing")或单字符。它平衡了词汇量与泛化能力,解决了传统分词中的未知词问题,是现代LLM(GPT、BERT等)的主流分词方法。字节级BPE以256个字节为基础,进一步实现了多语言无损支持。
(3)调用开源模型
在为智能体选择大语言模型时,可以从以下几个维度进行综合评估:
- 性能与能力:这是最核心的考量。不同的模型擅长的任务不同,有的长于逻辑推理和代码生成,有的则在创意写作或多语言翻译上更胜一筹。您可以参考一些公开的基准测试排行榜(如 LMSys Chatbot ArenaLeaderboard)来评估模型的综合能力。
- 成本:对于闭源模型,成本主要体现在 API 调用费用,通常按 Token 数量计费。对于开源模型,成本则体现在本地部署所需的硬件(GPU、内存)和运维上。需要根据应用的预期使用量和预算做出选择。
- 速度(延迟):对于需要实时交互的智能体(如客服、游戏 NPC),模型的响应速度至关重要。一些轻量级或经过优化的模型(如 GPT-3.5 Turbo, Claude 3.5 Sonnet)在延迟上表现更优。
- 上下文窗口:模型能一次性处理的 Token 数量上限。对于需要理解长文档、分析代码库或维持长期对话记忆的智能体,选择一个拥有较大上下文窗口(如 128K Token 或更高)的模型是必要的。
- 部署方式:使用 API 的方式最简单便捷,但数据需要发送给第三方,且受限于服务商的条款。本地部署则能确保数据隐私和最高程度的自主可控,但对技术和硬件要求更高。
- 生态与工具链:一个模型的流行程度也决定了其周边生态的成熟度。主流模型通常拥有更丰富的社区支持、教程、预训练模型、微调工具和兼容的开发框架(如 LangChain, LlamaIndex, Hugging Face Transformers),这能极大地加速开发进程,降低开发难度。选择一个拥有活跃社区和完善工具链的模型,可以在遇到问题时更容易找到解决方案和资源。
- 可微调性与定制化:对于需要处理特定领域数据或执行特定任务的智能体,模型的微调能力至关重要。一些模型提供了便捷的微调接口和工具,允许开发者使用自己的数据集对模型进行定制化训练,从而显著提升模型在特定场景下的性能和准确性。开源模型在这方面通常提供更大的灵活性。
- 安全性与伦理:随着大语言模型的广泛应用,其潜在的安全风险和伦理问题也日益凸显。选择模型时,需要考虑其在偏见、毒性、幻觉等方面的表现,以及服务商或开源社区在模型安全和负责任AI方面的投入。对于面向公众或涉及敏感信息的应用,模型的安全性和伦理合规性是不可忽视的考量。
(4)缩放法则
缩放法则揭示了在大语言模型中,模型性能与参数量、数据量和计算量之间存在可预测的幂律关系,三者需同步扩大才能最有效地提升模型能力。
(5)模型幻觉
- 事实性幻觉 (Factual Hallucinations) : 模型生成与现实世界事实不符的信息。
- 忠实性幻觉 (Faithfulness Hallucinations) : 在文本摘要、翻译等任务中,生成的内容未能忠实地反映源文本的含义。
- 内在幻觉 (Intrinsic Hallucinations) : 模型生成的内容与输入信息直接矛盾。
多种检测和缓解幻觉的方法:
1. 数据层面: 通过高质量数据清洗、引入事实性知识以及强化学习与人类反馈 (RLHF) 等方式,从源头减少幻觉。
2. 模型层面: 探索新的模型架构,或让模型能够表达其对生成内容的不确性。
3. 推理与生成层面:
1. 检索增强生成 (Retrieval-Augmented Generation, RAG) : 这是目前缓解幻觉的有效方法之一。
RAG 系统通过在生成之前从外部知识库(如文档数据库、网页)中检索相关信息,然后将检索到的信息作为上下文,引导模型生成基于事实的回答。
2. 多步推理与验证: 引导模型进行多步推理,并在每一步进行自我检查或外部验证。
3. 引入外部工具: 允许模型调用外部工具(如搜索引擎、计算器、代码解释器)来获取实时信息或进行精确计算。
三、智能体经典范式构建
ReAct (Reasoning and Acting): 一种将“思考”和“行动”紧密结合的范式,让智能体边想边做,动态调整。
Plan-and-Solve: 一种“三思而后行”的范式,智能体首先生成一个完整的行动计划,然后严格行。
Reflection: 一种赋予智能体“反思”能力的范式,通过自我批判和修正来优化结果。
1.ReAct工作流程
ReAct的巧妙之处在于,它认识到思考与行动是相辅相成的。思考指导行动,而行动的结果又反过来修正思考。为此,ReAct范式通过一种特殊的提示工程来引导模型,使其每一步的输出都遵循一个固定的轨迹:
- Thought (思考): 这是智能体的“内心独白”。它会分析当前情况、分解任务、制定下一步计划,或者反思上一步的结果。
- Action (行动): 这是智能体决定采取的具体动作,通常是调用一个外部工具,例如 Search['华为最新款手机']。
- Observation (观察): 这是执行 Action后从外部工具返回的结果,例如搜索结果的摘要或API的返回值。
智能体将不断重复这个 Thought -> Action -> Observation 的循环,将新的观察结果追加到历史记录中,形成一个不断增长的上下文,直到它在 Thought中认为已经找到了最终答案,然后输出结果。这个过程形成了一个强大的协同效应:推理使得行动更具目的性,而行动则为推理提供了事实依据。
2.工具的定义和实现
首先实现工具的核心功能,然后构建一个通用的工具管理器。
(1)实现搜索工具的核心逻辑
一个良好定义的工具应包含以下三个核心要素:
1. 名称 (Name): 一个简洁、唯一的标识符,供智能体在 Action 中调用,例如 Search。
2. 描述 (Description): 一段清晰的自然语言描述,说明这个工具的用途。这是整个机制中最关键的部分,因为大语言模型会依赖这段描述来判断何时使用哪个工具。
3. 执行逻辑 (Execution Logic): 真正执行任务的函数或方法。
(2)构建通用的工具执行器
当智能体需要使用多种工具时(例如,除了搜索,还可能需要计算、查询数据库等),我们需要一个统一的管理器来注册和调度这些工具。为此,我们创建一个 ToolExecutor 类。
3.ReAct智能体的编码实现
(1)系统提示词设计
角色定义: “你是一个有能力调用外部工具的智能助手”,设定了LLM的角色。
工具清单 ( {tools} ): 告知LLM它有哪些可用的“手脚”。
格式规约 ( Thought / Action ): 这是最重要的部分,它强制LLM的输出具有结构性,使我们能通过代码精确解析其意图。
动态上下文 ( {question} / {history} ): 将用户的原始问题和不断累积的交互历史注入,让LLM基于
完整的上下文进行决策。
(2)核心循环的实现
ReActAgent 的核心是一个循环,它不断地“格式化提示词 -> 调用LLM -> 执行动作 -> 整合结果”,直到任务完成或达到最大步数限制。
run 方法是智能体的入口。它的 while 循环构成了 ReAct 范式的主体, max_steps 参数则是一个重要的安全阀,防止智能体陷入无限循环而耗尽资源。
(3)输出解析器的实现
LLM 返回的是纯文本,我们需要从中精确地提取出 Thought和 Action。这是通过几个辅助解析函数完成的,它们通常使用正则表达式来实现。
(4) 工具调用与执行
它首先检查是否为 Finish指令,如果是,则流程结束。否则,它会通过tool_executor获取对应的工具函数并执行,得到 observation。
(5)观测结果的整合
最后一步,也是形成闭环的关键,是将 Action本身和工具执行后Observation添加回历史记录中,为下一轮循环提供新的上下文。通过将 Observation追加到 self.history,智能体在下一轮生成提示词时,就能“看到”上一步行动的结果,并据此进行新一轮的思考和规划。
(6)运行实例与分析
小结
1.ReAct的特点:
高可解释性:通过thought链,我们可以清晰看到智能体每一步的心路历程
动态规划与纠错能力
工具协同能力
2.固有局限性:对LLM自身能力的强依赖,执行效率问题,提示词的脆弱性,可能陷入局部最优
3.调试技巧:
检查完整的提示词、分析原始输出、验证工具的输入输出、调整提示词中的示例、尝试不同模型或参数
4.Plan-ans-Solve
1.工作原理
2.提示词设计
| 维度 | ReAct (边想边做) | Plan-and-Solve (先谋后动) |
|---|---|---|
| 核心流程 | 推理 (Thought) → 行动 (Action) → 观察 (Observation) 的循环 | 规划 (Plan) → 执行 (Solve) 的两个独立阶段 |
| 工作方式 | 动态、自适应。每步都根据外部反馈调整下一步计划 | 结构化、稳定。先制定完整步骤,再严格按照蓝图执行 |
| 最佳适用场景 | 探索性、需实时反馈的任务,如: - 信息检索 - 客服对话 - 实时问答 |
复杂、多步骤、目标明确的任务,如: - 数学推理 - 长文报告生成 - 代码生成 |
| 核心优势 | 灵活、可解释性强。能根据观察结果动态纠错,每一步的思考都可见 | 稳定、不易跑偏。长程规划能力强,确保最终结果与初始目标一致 |
| 主要局限 | 效率低、易失焦。串行执行,多步任务耗时且成本高,长期目标可能被遗忘 | 缺乏灵活性。计划一旦制定,难以应对中途变化,如果初始规划有误,可能全盘皆输 |
5.Reflection
1.工作原理
2.Memory类设计
- 使用一个列表 records 来按顺序存储每一次的行动和反思。
- add_record 方法负责向记忆中添加新的条目。
- get_trajectory 方法是核心,它将记忆轨迹“序列化”成一段文本,可以直接插入到后续的提示词中, 为模型的反思和优化提供完整的上下文。
- get_last_execution 方便我们获取最新的“初稿”以供反思
3.提示词设计
小结
主要成本 :模型调用开销增加、任务延迟显著提高、提示工程复杂度上升
核心收益:解决方案质量的跃迁、 鲁棒性与可靠性增强
三个范式对比

四、主流框架

1.AutoGen
2.AgentScope
3.CAMEL
4.LangGraph
五、自己构建Agent架构

1.可扩展性
构建了 HelloAgentsLLM 这一核心组件,解决了与大语言模型通信的关键问题。
- 多提供商支持
- 用户可以在实例化 LLM 时手动指定
provider="openai"或"modelscope" - 框架会把请求发送到指定云服务 API
- 用户可以在实例化 LLM 时手动指定
- 本地模型集成
- 用户可以设置
provider="vllm"或"ollama" - 框架调用本地运行的 HTTP 接口,兼容 OpenAI API
- 用户可以设置
- 自动检测机制
- 设置
provider="auto"时,框架会扫描.env或检测可用服务 - 自动选择一个可用 provider 并路由请求,无需人工干预
- 设置
2.框架接口实现
message
这个 Message 类的作用就是:
- 封装单条对话消息,包含内容、角色、时间戳和可选元数据
- 保证数据结构标准化和类型安全(通过 Pydantic)
- 提供接口方便与 LLM API 对接(
to_dict()) - 支持调试和打印(
__str__())
换句话说,它就是 智能体和大语言模型交互中“消息单元”的标准化容器。
config
- 集中管理配置
- 将原本可能散落在代码中的硬编码参数(如模型名、provider、temperature 等)统一放到一个类里管理。
- 让框架使用者可以在一个地方看到所有关键配置,结构清晰。
- 逻辑分区
- LLM 配置:
default_model,default_provider,temperature,max_tokens - 系统配置:
debug,log_level - 其他配置:
max_history_length
- LLM 配置:
- 默认值保证零配置可用
- 每个配置都有默认值,例如
default_model="gpt-3.5-turbo" - 即使用户没有提供任何环境变量,框架也可以正常运行
- 每个配置都有默认值,例如
- 环境变量覆盖
- 核心方法
from_env()可以从环境变量读取值,覆盖默认配置 - 好处:在不同部署环境(本地、服务器、容器)中无需修改代码,就可以调整参数
- 核心方法
- 提供字典化接口
to_dict()将配置对象转换为普通字典,便于传递给其他模块或序列化
Agent 抽象基类
1.类的定位
class Agent(ABC):
Agent是 一个抽象基类(Abstract Base Class, ABC)- 不能直接实例化,只能被继承
- 作用是为所有智能体(Agent)定义 统一的接口和基础功能
2.构造函数 __init__
- 核心依赖:
name:Agent 的名称llm:关联的 LLM 实例(HelloAgentsLLM)system_prompt:系统提示词(可选)config:配置参数(可选,如果没有传入就用默认 Config)
- 历史记录管理:
_history用于存储消息列表,每条消息是一个Message对象- 方便智能体追踪对话上下文
3.抽象方法 run
- 作用:所有子类必须实现
run方法 - 目的:保证每个 Agent 都有一个统一的“执行入口”
- 设计思想:体现 面向对象的抽象原则(Abstraction)
- 基类只定义接口
- 具体逻辑由子类实现
4.历史记录管理方法
add_message(message: Message)→ 添加消息到历史记录clear_history()→ 清空历史记录get_history()→ 获取历史记录的拷贝
特点:
- 与
Message类协同工作 - 对对话上下文的管理统一标准化
- 子类智能体可以直接使用,不必重复实现
5.字符串表示
- 打印 Agent 对象时,显示 Agent 名称和当前 LLM provider
- 方便调试和日志记录
总结:框架核心基础组件的设计与实现
- 配置管理(Config 类)
- 集中管理框架参数,包括 LLM 配置(模型名、provider、temperature 等)、系统配置(debug、log_level)和其他参数(历史消息长度等)。
- 支持 默认值,保证零配置下框架可用。
- 提供 from_env() 方法,可以从环境变量读取参数,支持跨环境部署,无需修改代码。
- 提供
to_dict()接口,方便其他模块调用和序列化。
- 消息管理(Message 类)
- 封装智能体与 LLM 交互中的单条消息,包括
content、role、timestamp和metadata。 role使用Literal["user","assistant","system","tool"]限定,保证类型安全并兼容 OpenAI API。- 提供
to_dict()将消息转为 API 可用的字典格式,保证“对内丰富,对外兼容”。 - 提供
__str__()方法,便于调试和打印消息。
- 封装智能体与 LLM 交互中的单条消息,包括
- 智能体基类(Agent 基类)
- 通过继承 ABC 抽象类实现,强制子类实现统一的
run()方法。 - 构造函数定义核心依赖:
name、LLM 实例、系统提示词和配置参数。 - 内置 历史记录管理方法:
add_message()、clear_history()、get_history(),与 Message 类协作管理对话上下文。 - 提供
__str__()方法,便于查看 Agent 名称和所用 LLM provider。 - 设计体现了 面向对象的抽象原则,保证可扩展性和统一接口调用。
- 通过继承 ABC 抽象类实现,强制子类实现统一的
- LLM 集成(HelloAgentsLLM 类)
- 作为智能体的核心模型调用接口,统一封装不同 LLM 服务。
- 支持 多提供商:OpenAI、ModelScope、智谱 AI 等,用户可通过
provider指定或自动检测(provider="auto")。 - 支持 本地模型集成:VLLM、Ollama 等,统一通过 OpenAI 兼容 API 调用,无需修改核心智能体逻辑。
- 提供统一接口,用户调用
agent.run()或llm.think()即可,无需关心后端服务类型。
3.Agent范式的框架化实现
1.SimpleAgent
- 核心特点:基础对话智能体
- 设计目标:用于最简单的对话场景,提供最直接的 LLM 调用和消息处理
- 功能:
- 直接把用户输入发送给 LLM
- 返回模型生成的文本
- 可选工具调用(如 Calculator)
- 维护对话历史
- 适用场景:
- 基础问答、聊天助手、简单任务执行
- 不包含复杂推理、计划或多步骤动作
2.ReActAgent
- 核心特点:增强推理 + 行动能力
- 设计目标:结合 Reasoning(推理) 和 Acting(执行动作) 的智能体
- 功能:
- 将用户输入分解为思考步骤(Reasoning)和执行动作(Acting)
- 可以调用外部工具或 API 在对话中“做事情”
- LLM 不仅生成回答,还会生成行动决策
- 适合多步骤任务、复杂逻辑问答或工具驱动的交互
- 适用场景:
- 问答 + 动作决策,例如需要调用数据库、计算器、搜索等工具
- 复杂任务拆解,需要逐步推理
3.ReflectionAgent
- 类型:自我反思智能体
- 核心特点:能够对历史对话或自身输出进行反思和优化
- 功能:
- 在生成回答前分析对话历史或自身先前回答
- 通过反思改进回答质量
- 支持多轮优化或纠错机制
- 适用场景:对话优化、复杂逻辑推理、连续多轮任务
4.PlanAndSolveAgent
- 类型:计划 + 执行 Agent
- 特点:显式生成任务计划,然后逐步执行计划
- 功能:
- LLM 输出整体计划
- 将计划拆解为子任务逐步执行
- 每个子任务可能调用工具或外部接口
- 适用场景:多步骤任务、需要明确计划的复杂流程
- 区别:比 ReActAgent 更结构化,先生成完整计划再执行
5.FunctionCallAgent
- 类型:函数调用 Agent
- 特点:可以让 LLM 输出函数调用或 API 调用指令
- 功能:
- LLM 根据用户输入生成调用函数的请求
- 框架执行函数并把结果返回 LLM
- 支持可编程工具调用
- 适用场景:需要动态调用程序、数据库、Web API 的任务
- 区别:专注于“函数/工具调用”,而不是多步推理或反思
| 特点 | SimpleAgent | ReActAgent | ReflectionAgent | PlanAndSolveAgent | FunctionCallAgent |
|---|---|---|---|---|---|
| 核心思路 | 直接回答 | 思考+行动 | 反思+优化 | 计划+执行 | 函数/工具调用 |
| 推理能力 | 无 | 分步推理 | 基于历史/自我输出推理 | 生成整体计划再拆解执行 | LLM 决定调用何种函数 |
| 多步骤任务 | 否 | 是 | 否/部分 | 是 | 部分 |
| 历史利用 | 消息记录 | 消息记录 | 历史 + 自身输出 | 可利用历史执行计划 | 可利用历史选择函数 |
| 工具调用 | 可选 | 主动/可选 | 可选/辅助 | 子任务可能调用 | 核心功能 |
| 适用场景 | 简单问答、聊天 | 复杂问答、工具驱动 | 回答优化、多轮任务 | 多步骤计划任务 | 动态函数/API 调用任务 |
4.工具系统
1.Tool 基类
• 特点:
• 每个工具都有 name、description,方便发现和理解。
• 提供 run 方法:工具执行时的接口,接受参数并返回结果。
• 提供 get_parameters 方法:工具能描述自己需要哪些参数,这样框架可以自动生成文档或验证输入。
• 设计思想:体现了 面向对象的抽象原则,统一接口,方便扩展。
2.ToolParameter 类
• 特点:
• 支持 参数验证(检查类型、必填等)
• 支持 自动文档生成,让用户或 Agent 清楚知道工具需要什么输入
3. ToolRegistry 注册表
• 特点:
• 注册 Tool 对象:适合复杂工具,有完整参数定义
• 注册函数工具:适合简单工具,快速集成现有函数
• 避免重复注册并提示覆盖
• 提供 工具描述和 schema 输出,方便 Agent 调用和提示词生成
4.工具发现与管理机制
• 输出:
• 格式化的工具描述字符串 → 用于生成 Agent 提示词
• OpenAI SDK 兼容的 schema → 让 LLM 直接调用工具
5.工具系统的高级特性
1.工具链式调用机制(Tool Chaining)
概念:将多个工具按顺序组合执行,实现复杂任务。每个工具的输出可以作为下一个工具的输入。
流程示意:
- 用户发送请求 → Agent 接收任务
- Agent 根据任务拆分工具链:
- 例:天气查询 + 翻译 →
[get_weather, translate]
- 例:天气查询 + 翻译 →
- Agent 调用第一个工具
get_weather - 获取输出后,将结果传给第二个工具
translate - 最终输出给用户
关键点:
- 工具链顺序由 Agent 决策 或预定义
- 支持 多步骤任务,类似 ReActAgent 或 PlanAndSolveAgent
- 框架层面通过 ToolRegistry 管理工具注册与发现
2. 异步工具执行支持(Asynchronous Execution)
概念:对于耗时操作(如网络请求、大模型推理),工具执行不会阻塞 Agent 主线程,而是并行处理。
实现方式:
-
Python 异步函数
- 线程/进程池
六、记忆系统(Memory System)和检索增强生成(Retrieval-Augmented Generation, RAG)



记忆系统:
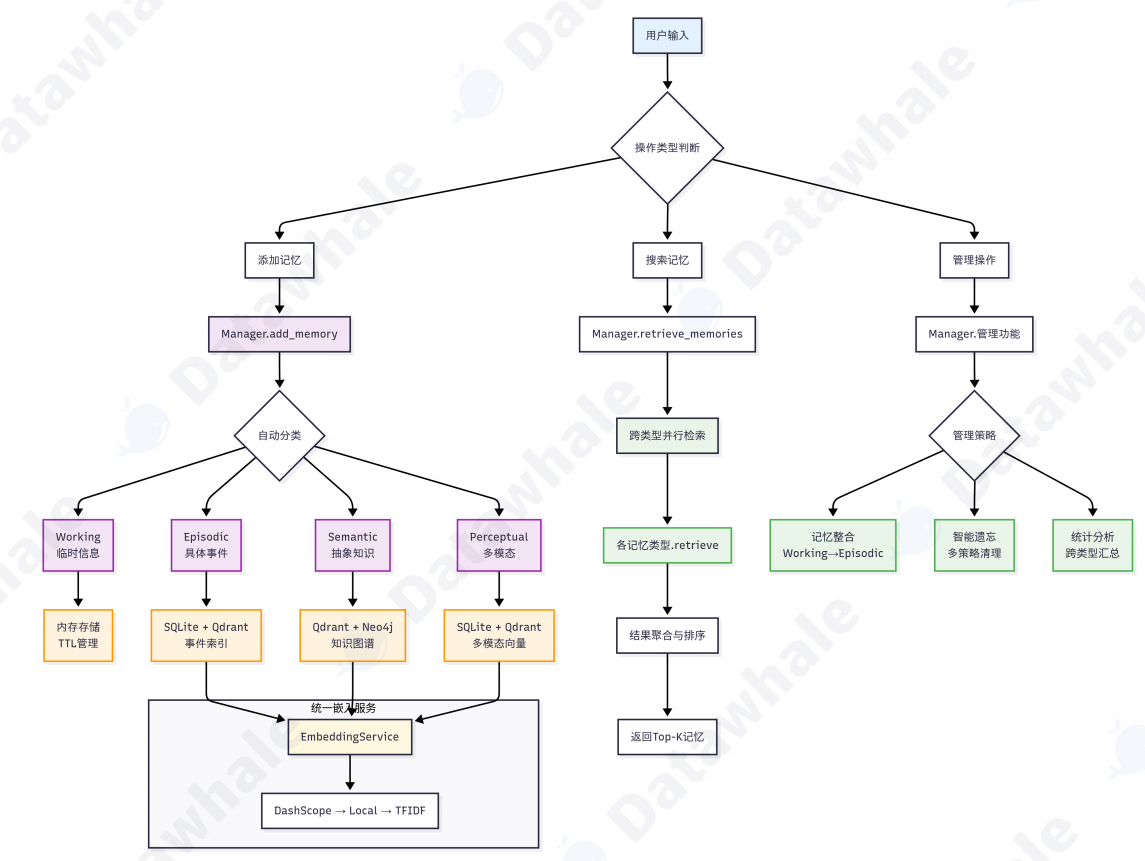
1.Memory Tool
(1)add
# 1. 工作记忆 - 临时信息,容量有限
memory_tool.execute("add",
content="用户刚才问了关于Python函数的问题",
memory_type="working",
importance=0.6
)
# 2. 情景记忆 - 具体事件和经历
memory_tool.execute("add",
content="2024年3月15日,用户张三完成了第一个Python项目",
memory_type="episodic",
importance=0.8,
event_type="milestone",
location="在线学习平台"
)
# 3. 语义记忆 - 抽象知识和概念
(2)操作2:search
search 操作是记忆系统的核心功能,它需要在大量记忆中快速找到与查询最相关的内容。它涉及语义理
解、相关性计算和结果排序等多个环节。
memory_tool.execute("add",
content="Python是一种解释型、面向对象的编程语言",
memory_type="semantic",
importance=0.9,
knowledge_type="factual"
)
# 4. 感知记忆 - 多模态信息
memory_tool.execute("add",
content="用户上传了一张Python代码截图,包含函数定义",
memory_type="perceptual",
importance=0.7,
modality="image",
file_path="./uploads/code_screenshot.png"
)(2)search
(3)forget
(4)consolidate
2.MemoryManager
3.四种记忆类型
(1)工作记忆(WorkingMemory)当前上下文
(2)情景记忆(EpisodicMemory)输入
(3)语义记忆(SemanticMemory)历史对话
(4)感知记忆(PerceptualMemory)RAG知识库
4.RAG
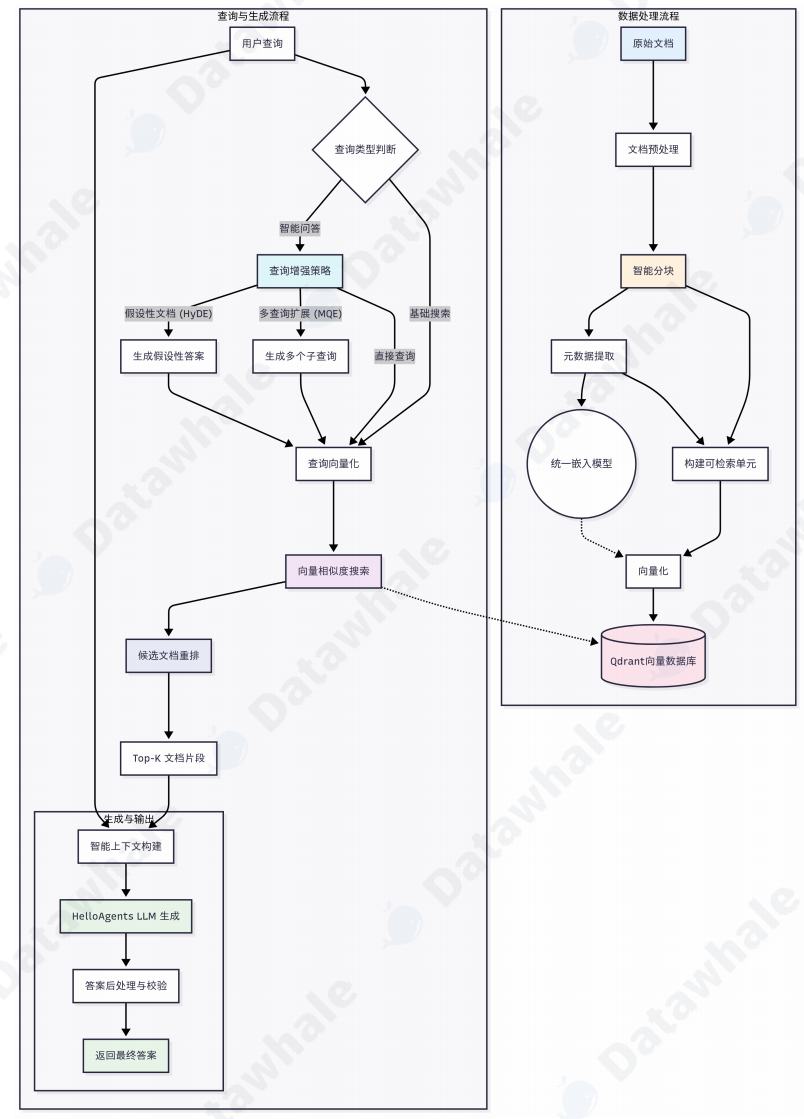

1.RAG系统架构设计
(1)RAGTool接口
该接口定义了一个基于 RAG 架构的工具类,主要完成知识库问答能力的初始化,包括向量数据库(Qdrant)连接配置、RAG pipeline 构建以及多知识库(namespace)管理。通过 pipelines 结构支持多个检索流程,并结合 LLM 实现检索增强生成。
(2)多模态文档载入
(3)分块策略
(4)统一嵌入与向量存储
2.高级检索策略
(1)多查询扩展(MQE)
(2)假设文档嵌入(HyDE)
(3)扩展检索框架
七、上下文工程
- ContextBuilder (
hello_agents/context/builder.py):上下文构建器,实现 GSSC (Gather-Select-Structure-Compress) 流水线,提供统一的上下文管理接口 - NoteTool (
hello_agents/tools/builtin/note_tool.py):结构化笔记工具,支持智能体进行持久化记忆管理 - TerminalTool (
hello_agents/tools/builtin/terminal_tool.py):终端工具,支持智能体进行文件系统操作和即时上下文检索
1.面向长时程任务的上下文工程
-
压缩整合(Compaction)
- 定义:当对话接近上下文上限时,对其进行高保真总结,并用该摘要重启一个新的上下文窗口,以维持长程连贯性。
- 实践:让模型压缩并保留架构性决策、未解决缺陷、实现细节,丢弃重复的工具输出与噪声;新窗口携带压缩摘要 + 最近少量高相关工件(如“最近访问的若干文件”)。
- 调参建议:先优化召回(确保不遗漏关键信息),再优化精确度(剔除冗余内容);一种安全的“轻触式”压缩是对“深历史中的工具调用与结果”进行清理。
-
结构化笔记(Structured note-taking)
- 定义:也称“智能体记忆”。智能体以固定频率将关键信息写入上下文外的持久化存储,在后续阶段按需拉回。
- 价值:以极低的上下文开销维持持久状态与依赖关系。例如维护 TODO 列表、项目 NOTES.md、关键结论/依赖/阻塞项的索引,跨数十次工具调用与多轮上下文重置仍能保持进度与一致性。
- 说明:在非编码场景中同样有效(如长期策略性任务、游戏/仿真中的目标管理与统计计数)。结合第八章的
MemoryTool,可轻松实现文件式/向量式的外部记忆并在运行时检索。
-
子代理架构(Sub-agent architectures)
- 思想:由主代理负责高层规划与综合,多个专长子代理在“干净的上下文窗口”中各自深挖、调用工具并探索,最后仅回传凝练摘要(常见 1,000–2,000 tokens)。
- 好处:实现关注点分离。庞杂的搜索上下文留在子代理内部,主代理专注于整合与推理;适合需要并行探索的复杂研究/分析任务。
- 经验:公开的多智能体研究系统显示,该模式在复杂研究任务上相较单代理基线具有显著优势。
方法取舍可以遵循以下经验法则:
- 压缩整合:适合需要长对话连续性的任务,强调上下文的“接力”。
- 结构化笔记:适合有里程碑/阶段性成果的迭代式开发与研究。
- 子代理架构:适合复杂研究与分析,能从并行探索中获益。
2.ContextBuilder
1.核心数据结构
ContextBuilder 的实现主要依赖两个核心数据结构:
一是 ContextPacket,用于统一表示来自 RAG、历史对话和 Memory 等多源信息;
二是配置结构(如 token 预算、权重策略等),用于控制上下文的筛选、排序与拼接逻辑。两者分别负责“数据承载”和“策略控制”。
2.GSSC流水线
ContextBuilder 的核心是 GSSC(Gather-Select-Structure-Compress)流水线,它将上下文构建过程分解为四个清晰的阶段。
(1)Gather:多源信息汇集
第一阶段是从多个来源汇集候选信息。这个阶段的关键在于容错性和灵活性。
1. 添加系统指令(最高优先级,不参与评分)
2. 从记忆系统检索相关记忆
3. 从 RAG 系统检索相关知识
4.添加对话历史(仅保留最近的 N 条)
5.自定义信息包
- 容错机制:每个外部数据源的调用都被 try-except 包裹,确保单个源的失败不会影响整体流程
- 优先级处理:系统指令被标记为高优先级,确保始终被保留
- 历史限制:对话历史只保留最近的几条,避免上下文窗口被历史信息占据
(2)Select:智能信息选择
第二阶段是根据相关性和新近性对候选信息进行评分和选择。
1. 分离系统指令和其他信息
2. 计算系统指令占用的 token
3. 为其他信息计算综合分数
4. 按分数降序排序
5. 贪心选择:按分数从高到低填充,直到达到 token 上限
- 评分机制:采用相关性和新近性的加权组合,权重可配置
- 贪心算法:按分数从高到低填充,确保在有限预算内选择最有价值的信息
- 过滤机制:通过
min_relevance参数过滤低质量信息
(3)Structure:结构化输出
第三阶段是将选中的信息组织成结构化的上下文模板。
1)语义分层
| 类型 | 含义 | 作用 |
|---|---|---|
| system_instruction | 系统规则 | 控制模型行为 |
| evidence | RAG/知识 | 提供事实依据 |
| context | 其他信息 | 补充背景 |
2)构建prompt模板
[Role & Policies]
系统指令[Task]
用户问题[Evidence]
检索到的知识[Context]
补充上下文[Output]
输出要求
- 可读性:清晰的分区让人类和模型都更容易理解上下文结构
- 可调试性:问题定位更容易,可以快速识别哪个区域的信息有问题
- 可扩展性:添加新的信息源只需要创建新的分区
(4)Compress:兜底压缩
第四阶段是对超限上下文进行压缩处理。
3.NoteTool 结构化笔记
然而,MemoryTool 主要关注对话式记忆——短期工作记忆、情景记忆和语义记忆。对于需要长期追踪、结构化管理的项目式任务,我们需要一种更轻量、更人类友好的记录方式。
NoteTool 填补了这个gap,它提供了:
- 结构化记录:使用 Markdown + YAML 格式,既适合机器解析,也方便人类阅读和编辑
- 版本友好:纯文本格式,天然支持 Git 等版本控制系统
- 低开销:无需复杂的数据库操作,适合轻量级的状态追踪
- 灵活分类:通过
type和tags灵活组织笔记,支持多维度检索
4.TerminalTool 即时文件管理系统
TerminalTool 为智能体提供了安全的命令行执行能力,支持常用的文件系统和文本处理命令,同时通过多层安全机制确保系统安全。
TerminalTool 通过多层安全机制确保系统安全:
第一层:命令白名单
只允许安全的只读命令,完全禁止任何可能修改系统的操作
第二层:工作目录限制(沙箱)
TerminalTool 只能访问指定的工作目录及其子目录,无法访问系统其他部分
第三层:超时控制
每个命令都有执行时间限制,防止无限循环或资源耗尽
第四层:输出大小限制
限制命令输出的大小,防止内存溢出
TerminalTool 的实现聚焦于两个核心功能:命令执行和目录导航。
(1)命令执行
核心的 _execute_command 方法负责实际执行命令
这个实现的关键点:
- 当前目录感知:使用
cwd参数在正确的目录下执行命令 - 错误处理:捕获并合并标准错误,提供完整的诊断信息
- 返回码检查:非零返回码会被标记为警告
- 容错设计:超时和异常都会被妥善处理,不会导致智能体崩溃
(2)目录导航
cd 命令的特殊处理支持智能体在文件系统中导航
1)探索式导航
2)数据文件分析
快速了解数据文件的结构和内容
3)日志文件分析
实时分析应用日志,快速定位问题
4)代码库分析
辅助代码审查和理解
与其他工具协同
与 MemoryTool 协同:TerminalTool 发现的信息可以存储到记忆系统中
与 NoteTool 协同:重要的发现可以记录为结构化笔记
与 ContextBuilder 协同:TerminalTool 的输出可以作为上下文的一部分
八、智能体通信协议

通信协议架构层
(1)协议实现层:这一层包含了三种协议的具体实现。MCP 基于 FastMCP 库实现,提供客户端和服务器功能;A2A 基于 Google 官方的 a2a-sdk 实现;ANP 是我们自研的轻量级实现,提供服务发现和网络管理功能,当然目前也有官方的实现,考虑到后期的迭代,因此这里只做概念的模拟。
(2)工具封装层:这一层将协议实现封装成统一的 Tool 接口。MCPTool、A2ATool 和 ANPTool 都继承自 BaseTool,提供一致的run()方法。这种设计让智能体能够以相同的方式使用不同的协议。
(3)智能体集成层:这一层是智能体与协议的集成点。所有的智能体(ReActAgent、SimpleAgent 等)都通过 Tool System 来使用协议工具,无需关心底层的协议细节。
hello_agents/
├── protocols/ # 通信协议模块
│ ├── mcp/ # MCP协议实现(Model Context Protocol)
│ │ ├── client.py # MCP客户端(支持5种传输方式)
│ │ ├── server.py # MCP服务器(FastMCP封装)
│ │ └── utils.py # 工具函数(create_context/parse_context)
│ ├── a2a/ # A2A协议实现(Agent-to-Agent Protocol)
│ │ └── implementation.py # A2A服务器/客户端(基于a2a-sdk,可选依赖)
│ └── anp/ # ANP协议实现(Agent Network Protocol)
│ └── implementation.py # ANP服务发现/注册(概念性实现)
└── tools/builtin/ # 内置工具模块
└── protocol_tools.py # 协议工具包装器(MCPTool/A2ATool/ANPTool)1.MCP
-
工具发现阶段:MCP Client 连接到 Server 后,首先调用
list_tools()获取所有可用工具的描述信息(包括工具名称、功能说明、参数定义) -
上下文构建:Client 将工具列表转换为 LLM 能理解的格式,添加到系统提示词中。
-
模型推理:LLM 分析用户问题和可用工具,决定是否需要调用工具以及调用哪个工具。这个决策基于工具的描述和当前对话上下文
-
工具执行:如果 LLM 决定使用工具,Client 通过 MCP Server 执行所选工具,获取结果
-
结果整合:工具执行结果被送回给 LLM,LLM 结合结果生成最终回答
MCP 与 Function Calling 的差异
MCP = 工具接入标准(生态层)
Function Calling = 模型调用工具的能力(执行层)
传输方式

2.A2A
3.ANP
九、Agentic RL
Agentic RL 的核心思想:将 LLM 作为可学习策略,嵌入智能体的感知-决策-执行循环,通过强化学习优化多步任务表现。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)