体系结构论文(115,下):Characterizing Mobile SoC for Accelerating Heterogeneous LLM Inference
Characterizing Mobile SoC for Accelerating Heterogeneous LLM Inference 【SOSP ’25】
【接上篇博文】
四、方法与设计
总设计思想
系统采用的是 stage-specific optimization strategy:
- prefill 阶段:目标是最大化 SoC 的计算吞吐
- decoding 阶段:目标是最大化 memory bandwidth utilization。
这和前面 Section 2、3 是完全对应的:
- prefill 是 computation-intensive
- decoding 是 memory-intensive
作者特别强调:
- 手机有功耗约束;
- 还要给其他并发应用留资源;
- CPU 能效低,而且还承担通用系统任务;
- 因此 CPU 不适合作为主要计算 backend。
所以在 HeteroInfer 里:
- CPU 只做 control plane
- 负责:
- synchronization
- GPU kernel scheduling。
因此 HeteroInfer 的主体计算单元其实是:
- NPU
- GPU
4.1 Layer-level GPU-NPU Execution:第一层粗粒度分工
这一部分先做一个coarse-grained strategy,按 layer 来分工。作者说:
- 根据 GPU 和 NPU 对不同算子的 affinity,按层决定谁执行什么。
1 Prefill 阶段怎么分工
作者给出的基本策略是:
- Matmul operators 分配给 NPU
- RMSNorm 和 SwiGLU 更适合在 GPU 上执行。
为什么这么分
原因直接来自前面的性能刻画:
- NPU 擅长矩阵乘;
- GPU 更适合一些非大规模 matmul 的算子;
- 所以不能简单说“一个 transformer block 全扔给 NPU”。
这说明作者的 layer-level 策略不是按模块名分,而是按operator affinity 分。
2 为什么还要交换计算顺序
因为 LLM 一般 weight tensor 比 user input tensor 更大,所以为了适应 NPU-2:order-sensitive performance,他们会交换 input 和 weight 的计算顺序,利用如下不变量:
[M,N]×[N,K]→([K,N]×[N,M])T
也就是通过数学等价变换,把计算改写成更适合 NPU 的形式。
这一点非常关键
这不是单纯“转置一下方便实现”,而是在主动迎合 NPU 的硬件结构:
- 尽量让更适合驻留的 tensor 处在 weight 一侧;
- 减少频繁加载大权重带来的代价。
利用 algebraic equivalence,去适配 NPU 的 weight-stall 数据流。
3 Decoding 阶段为什么 GPU 反而成主力
作者明确说,在 decoding 阶段,由于 NPU-1: stage performance,GPU 成为主要计算单元,因为它在 matrix-vector operations 上表现更好。
为什么会这样
因为 decoding 时一次只生成一个 token,本质更接近:
- matrix-vector
- 小 batch
- 短 shape
而这正好容易触发 NPU 的 stage performance 问题:
- 阵列利用率低;
- padding / tile 对齐浪费大;
- NPU 未必能把计算单元用满。
相反,GPU 在这种场景下性能更平稳。
4.2 Tensor-level GPU-NPU Parallelism
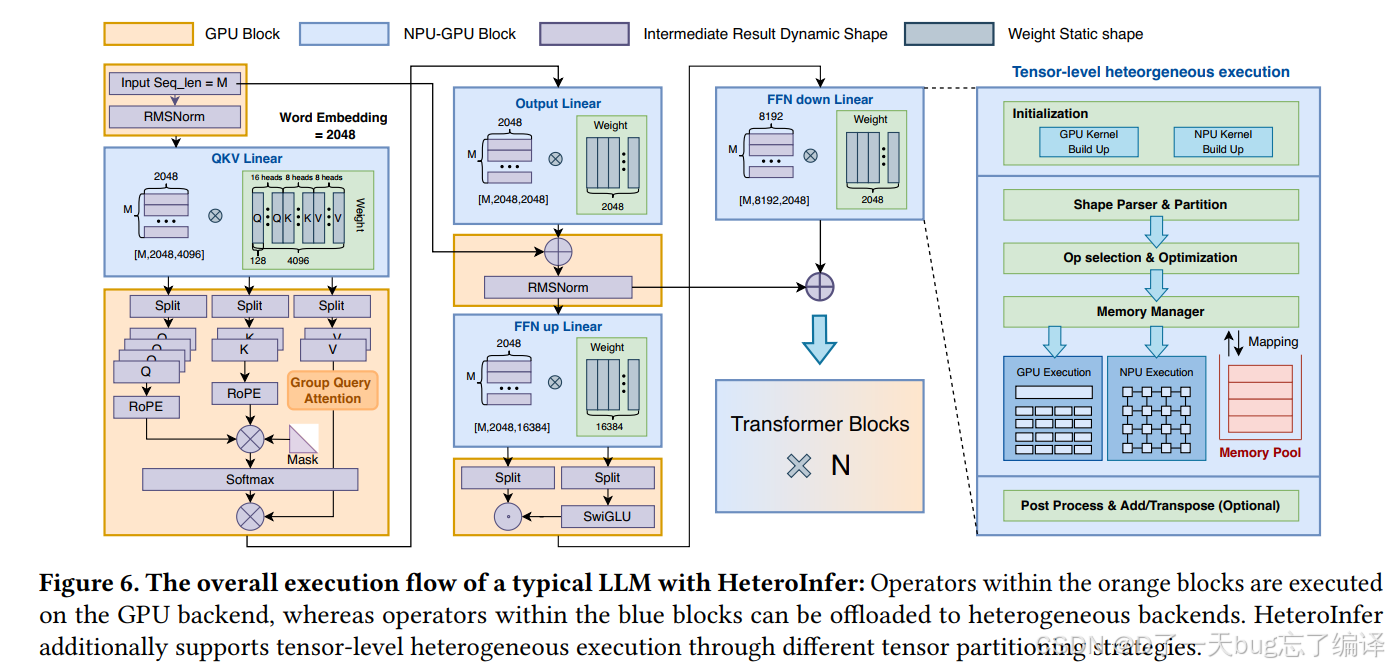
Figure 6 是这几页最核心的总览图。
它把一个典型 LLM 在 HeteroInfer 中的执行流画出来了。作者说明:
- 橙色块:在 GPU backend 上执行
- 蓝色块:可以 offload 到 heterogeneous backends
- HeteroInfer 还支持通过不同 partition strategy 做 tensor-level heterogeneous execution。
这张图表达了两层结构
第一层:LLM operator flow
左边是 transformer block 的执行结构,比如:
- RMSNorm
- QKV Linear
它说明并不是整块统一调度,而是对不同算子有不同去向。
第二层:runtime support
右边则是系统侧支撑模块,包括:
- GPU kernel build up
- NPU kernel build up
- shape parser & partition
- op selection & optimization
- memory manager
- GPU execution / NPU execution
- memory pool
- post process & add/transpose。
这说明 HeteroInfer 不是“硬编码算子切换”,而是有一整套运行时机制去支持异构执行。
为什么 layer-level 还不够,必须进一步做 tensor-level
作者在 4.2 开头直接说:
虽然 layer-level 方法已经用了 GPU 和 NPU,但它仍然不能充分利用 heterogeneous SoC,原因有三个:
- 某些 tensor shape 下 NPU 性能会下降
- SoC memory bandwidth 和 heterogeneous processors 的计算能力利用不足
- NPU static graph 的 graph generation cost 很高。
这三点其实分别对应三类问题:
第一类:性能适配问题
一个层里即使是同一个 matmul,某些 shape 也不适合 NPU。
第二类:资源利用问题
即使 layer-level 分工合理,也可能:
- GPU 没吃满
- NPU 没吃满
- SoC 带宽也没吃满
第三类:动态输入问题
真实用户的输入长度是变化的,但 NPU 偏好 static graph。
所以作者必须从“按层分”进一步升级到“按张量切”。
4.2.1 Weight-centric partition with static shape
这是第一种张量级并行策略。
1 它要解决什么问题
作者说,即便考虑不同 tensor shape,NPU 并不是总比 GPU 快,原因主要有两个:
第一,sequence length 短时,NPU 吃不满资源
这来自 NPU-1: stage performance。
当序列较短时,NPU 利用率不高,可能只和 GPU 差不多,甚至更差。
第二,FFN-down 这种层的 shape 不适合 NPU
由于 FFN-down 是降维矩阵,转置后会出现:
- column size 大于 row size
这种形状对 NPU 不友好,只能比 GPU 快 0.5× 到 1.5×,根源是 NPU-3: shape-sensitive performance。
所以结论是什么
并不是“matmul 就应该全部给 NPU”,而是:
- 某些 matmul shape 下,GPU 也应该参与;
- 甚至要和 NPU 并行,才能更快。
2 Weight-centric partition 怎么做
作者提出:
- 把 weight tensor 按 row dimension 切分
- 一部分给 GPU
- 一部分给 NPU
- 两边同时算。
Figure 7 画的就是这个过程。
为什么按 weight 切
因为在这里作者先考虑的是:
- 固定 sequence length
- 即 static shape 场景
在这种情况下,NPU 可以提前根据静态 tensor shape 构图。
于是最自然的办法就是固定 activation,不动输入,把 weight 切开。
它的本质是:
- 不再让一个后端独占整个算子;
- 而是把同一个 matmul 的不同 weight 子块分给不同后端;
- 再把中间结果 merge 回来。
为什么这种方式适合静态 shape
因为:
- 切分比例可以离线算好;
- NPU 图可以提前生成;
- runtime 开销较低。
作者还说,partition ratio 是由 offline solver 静态决定的。
4 它在 prefill 和 decoding 中的意义不同
作者专门解释了一个很容易忽略的点:
虽然同样是 weight-centric partition,但它在两个阶段的作用不一样。
在 prefill 中
作用是:
- 借助 GPU 计算资源,弥补 NPU 在某些不利 tensor shape 下的性能下降;
- 本质还是偏 算力补强。
在 decoding 中
作用是:
- 解决单个处理器导致的 memory bandwidth underutilization;
- 核心目标变成最大化 SoC 总带宽利用率,同时尽量减少 contention。
4.2.2 Activation-centric partition with dynamic shape
这是第二种策略,专门解决动态输入长度问题。
1 这个问题为什么存在
作者说,真实用户输入通常是 dynamic sequence length,但当前 mobile-side NPU 大多只支持:
- static graph execution。
原因在于它们普遍采用 dataflow graph compilation 方法。
如果遇到新 shape,一个直觉做法是:
- 运行时重新生成 computation graph
但问题是 graph generation overhead 很高,而且和 tensor size 成正比。
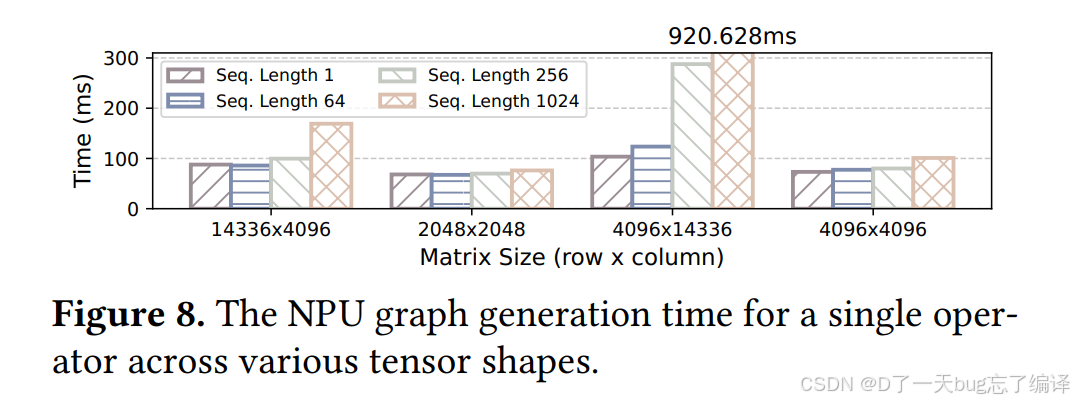
Figure 8 就展示了这一点:
某些单个 operator 的 NPU graph 生成时间甚至能达到 920.628 ms 量级。
这个代价有多严重
接近 1 秒的 graph generation 在端侧几乎不可接受。
因为用户感知的不是 kernel 多快,而是整体响应时间。
2 现有常见做法:padding 到标准 shape
作者说,一个常见办法是:
- 预选一组标准 shape,比如 2 的幂;
- 遇到新长度时,把 activation pad 到最近的标准 shape。
例如输入长度 300,就 pad 到 512。
这样可以避免生成新图,但会带来:
- 多余计算
- padding overhead。
3 Activation-centric partition 怎么做
作者提出的办法是:
- 把 dynamic-shape activation tensor 切开;
- 标准 shape 的部分交给 NPU;
- 不规则剩余部分交给 GPU。
例如 sequence length = 300 时:
- 切成 256 + 44
- 256 这部分符合标准 shape,直接走 NPU 预构图
- 剩下 44 不符合 NPU 标准 shape,就由 GPU 并行处理。
为什么 GPU 来处理剩余部分
因为根据前面 GPU-1 的结论:
- GPU 对动态 shape 更友好;
- 它不用像 NPU 那样为每个 shape 单独构图;
- runtime 更灵活。
4 为什么还要 multi-tensor activation partition
作者进一步说,为了平衡 GPU 和 NPU 的负载,他们会采用:
- multi-tensor activation partitioning。
做法是:
- 把 activation 沿 sequence length 切成多个标准 shape 子块;
- 再加一个任意 shape 子块;
- 标准块都顺序放到 NPU 上;
- 剩下那个动态块交给 GPU。
这样做的目的
因为 GPU 通常还是比 NPU 慢,所以不能把太多活给 GPU。
这个策略的目标就是:
- 把 GPU 的工作量压到最小但又不为空
- 让 GPU 和 NPU 执行时间更接近
- 从而减少一边等另一边。
这其实是一个典型的异构负载均衡问题。
大家可能会觉得后边俩方法像是一样的,但是有一定的差别:
1. 先看 activation-centric partition
假设序列长度是 300,标准 shape 里有 256。
它会这样切:
- 256 → 给 NPU
- 44 → 给 GPU
也就是:
300 = 256 + 44
这里的特点是:
- NPU 只吃 一个标准块
- GPU 吃剩下那一块动态 shape
所以它更像是:
“先拿一个最大能对齐的标准块给 NPU,剩下边角料给 GPU。”
2. 再看 multi-tensor activation partition
它不是只切一次,而是继续往下拆。
还是举个例子。
假设序列长度是 700,标准 shape 可以是 256。普通 activation-centric 可能会想成:
- 256 → NPU
- 444 → GPU
也就是:
700 = 256 + 444
但这样会有问题:
- GPU 那块 444 太大了
- GPU 可能干太多活
- NPU 很快算完,GPU 还在慢慢跑
- 最后整体时间被 GPU 拖住
所以 multi-tensor activation partition 会改成:
- 256 → NPU
- 256 → NPU
- 188 → GPU
也就是:
700 = 256 + 256 + 188
这里的特点是:
- NPU 不再只吃一个标准块,而是吃多个标准块
- GPU 只接手最后那一小块动态部分
所以它更像是:
“尽量把更多工作塞给 NPU,只把最后没法标准化的那一小段留给 GPU。”
3. 区别是什么
activation-centric
- 目标是:支持动态 shape
- 思路是:
标准部分给 NPU,剩余部分给 GPU- 更关注“能跑起来”
multi-tensor activation partition
- 目标是:进一步平衡 GPU 和 NPU 负载
- 思路是:
把标准部分拆成多个 NPU 子块,尽量压缩 GPU 的工作量- 更关注“跑得更均衡、更快”
4.2.3 Hybrid partition
这是第三种策略,用来解决 activation-centric 的不足。
1 Activation-centric 的问题是什么
作者说,虽然 activation-centric 支持 dynamic tensor shapes,但它可能导致 GPU 和 NPU 两边的资源利用都不理想,原因是 NPU-3: shape-sensitive performance。
具体来说:
- 分给 GPU 的那块 tensor 可能过大或过小,不能把 GPU 用好;
- 分给 NPU 的那块 tensor shape 也可能并不适合高效 NPU 计算。
也就是说,activation-centric 只解决了“动态 shape 支持”,但没完全解决“shape 适配硬件”。
2 Hybrid partition 怎么做
作者提出 hybrid partition:
- 用 activation-centric + padding 处理 dynamic tensor shape;
- 再结合 weight-centric partition,把 tensor 同时分配给 GPU 和 NPU。
它为什么更灵活
因为 weight tensor 通常比 activation tensor 大,所以在 weight 上做切分,有更大自由度去把 shape 调整成更适合 NPU 的形式。
因此 hybrid 的优势是两头兼顾:
- 既支持动态输入;
- 又能让切出来的子张量形状更符合 NPU 偏好;
- 同时还能更充分利用 GPU 和 NPU 的计算能力。
简单来说
hybrid partition 是把两种机制结合起来:
- activation-centric partition + padding
用来处理动态输入长度;- weight-centric partition
用来把计算进一步分给 GPU 和 NPU,并把 shape 调整得更适合 NPU。所以 hybrid 不是第三条完全独立的路,而是:
先按 activation 维度把动态问题搞定,再按 weight 维度细调性能。
第一步:先把动态 sequence length 拆开
假设输入长度不是标准长度,比如:
- sequence length = 300
activation-centric 会先做类似这样的处理:
256这一段是标准块,适合 NPU;44这一段是动态残余,原本倾向交给 GPU。到这里,问题只是“这玩意能跑了”。
第二步:再看这两部分的实际 shape 是否真的最优
这时作者进一步想:
256那块给 NPU,shape 真的好吗?44那块全给 GPU,GPU 会不会干太多或太少?- 能不能再沿着 weight 维 切一下,让:
- NPU 拿到更友好的 tensor shape
- GPU 负载更合理
- 两边更接近同时结束
为什么要在 weight 上再切一次??
作者特别提到一个原因:
- weight tensor 通常比 activation tensor 更大
- 所以在 weight 上做 partition,灵活度更高,更容易切出适合 NPU 的 shape。
因为如果只盯着 activation 切,你能调的空间有限;
但 weight 更大、更“厚”,你在它上面切分时:
- 更容易控制最终子问题的长宽比;
- 更容易适应 NPU 的 shape-sensitive 特性;
- 更容易平衡 GPU/NPU 的工作量。
所以 hybrid 的深层逻辑是:
动态问题在 activation 侧解决,性能最优化在 weight 侧解决。
举个例子
假设有个 matmul:
- activation 长度是动态的,不是标准 shape;
- 先经过 activation-centric 处理后,得到:
- 一块标准 activation 给 NPU
- 一块动态 activation 给 GPU
如果停在这里,可能出现:
- GPU 那一小块对应的 weight 很“胖”,导致 GPU 并不轻松;
- NPU 那边虽然是标准图,但 weight/activation 的比例不理想,NPU 也没跑到最佳。
于是 hybrid 会继续做:
- 不只是把 activation 分成 “NPU块 + GPU块”
- 还会把对应的 weight tensor 再切开,
- 让 NPU 那一侧拿到更符合它偏好的 weight sub-tensor,
- GPU 那侧只处理更合适的一部分。
这样做之后:
- NPU 的 shape 更好看了;
- GPU 的活也更合适了;
- 两边更容易并行结束。
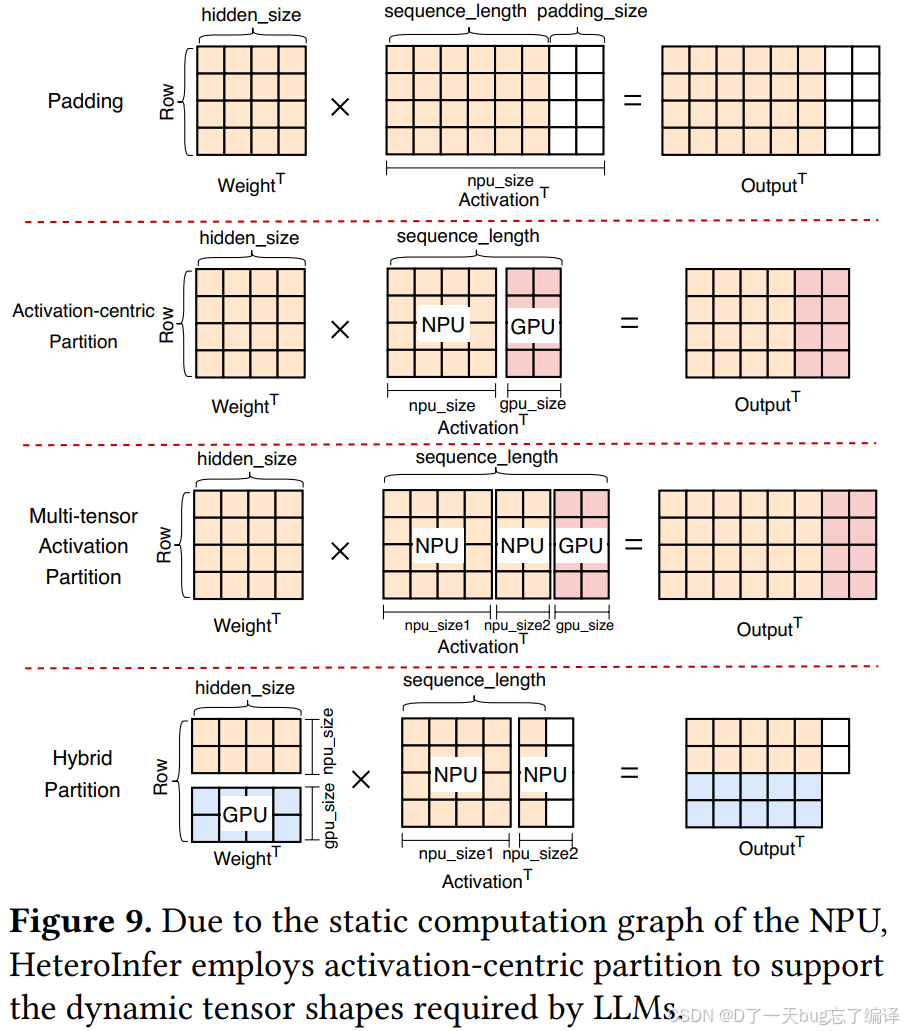
Figure 9 很好地把几种方案摆在一起:
- Padding
- Activation-centric partition
- Multi-tensor activation partition
- Hybrid partition。
Padding
最简单,但算冗余太大。
Activation-centric
能处理动态 shape,但 GPU 上那块可能 shape 很差,或者大小不合适。
Multi-tensor activation
进一步平衡 GPU/NPU 负载。
Hybrid
再进一步同时考虑 dynamic shape 和 NPU shape 友好性。
所以这不是拍脑袋列了三种 partition,而是一个逐步逼近更优解的设计过程。
4.3 Fast Synchronization
作者一开始就强调:
虽然 GPU-NPU parallelism 能减少某些 operator 的执行时间,但它也会带来额外开销,尤其是:
- GPU 和 NPU 之间的同步成本。
而且这个问题在 decoding phase 尤其严重,因为此时 Matmul 的执行时间已经只有:
- 几百微秒 量级。
这意味着:
- 如果同步本身也在几百微秒量级,
- 那么“并行”几乎没有意义,
- 因为你省下的计算时间会被等待和同步完全抵消。
1. 作者用的第一种同步优化:利用 UMA,尽量不拷贝
作者的第一个策略是利用 mobile SoC 的:
- unified address space / unified memory architecture。
具体做法是:
- 把 memory buffer 同时映射到 host 和 device address spaces;
- 从而避免额外的数据传输。
前面文章已经指出,传统 GPU 软件栈经常会有:
- host buffer → device buffer 的显式数据拷贝;
- 再加上 clFinish 这类同步。
如果这里仍沿用这种做法,那么即使计算切分合理,也会因为:
- copy
- 映射/解除映射
- driver 接管 buffer
带来大量额外成本。
所以作者这里做的是从底层 buffer 管理开始减同步成本。
HeteroInfer 的具体实现:memory pool
作者说在 HeteroInfer runtime 中,他们专门预留了一个:
- dedicated memory pool
用于分配每个 operator 的:
- input tensors
- output tensors。
为什么 memory pool 可以做得很小
因为 LLM 各层共享相同 decoder block 结构,所以:
- 不同层对 buffer 的需求模式相似;
- 不需要为每层都单独维护一套 buffer;
- 只要少量 buffer slots 就可以在层与层之间复用。
这其实很像经典 systems 里的 object pool / buffer reuse 思路。
这里其实不难理解,
作者说,mobile SoC 有一个好处:
- CPU、GPU、NPU 之间是 统一地址空间 / 统一内存架构。
通俗说就是:
大家可以看同一片“共享仓库”。
所以作者的第一个想法是:
- 不要 GPU 算完后,再专门把数据拷一份给 CPU;
- CPU 再拷一份给 NPU;
- 这样太折腾了。
而是直接准备一块共享内存,让:
- GPU 往这里写结果
- NPU 直接从这里读。
2. predictable waiting time + polling
第二个策略。作者利用的是 LLM workload 的一个结构特征:
- 不同 layer 执行的是相同或高度相似的操作;
- 因此 GPU kernel 的等待时间在不同层之间具有较强一致性和可预测性。
1 核心想法是什么
作者没有直接每次都调用昂贵的同步原语,而是让 synchronization thread:
- 先根据预测等待一段时间;
- 再进入 polling;
- 一旦 GPU 完成,立刻触发后续 NPU 执行。
这可以理解为:
- 粗粒度靠预测;
- 细粒度靠轮询。
所以它不是纯 sleep,也不是全程 busy wait,而是一个折中方案。
为什么?
作者说,在 mobile SoC 上,
usleep的最小粒度大约是:
- 80 到 100 微秒。
因此它不能作为精确同步机制。
如果你只用 sleep:
- 可能醒得太晚;
- 错过 GPU 刚刚结束的那个瞬间;
- 额外损失几十到上百微秒。
而在 decoding 里,这个量级已经很大了。
2 具体怎么 polling
作者的做法是:
- synchronization thread 睡到接近预期结束时间;
- 醒来后用一个 small/middle CPU core 持续监视上一层的 output tensor;
- 在 output tensor 旁边加一个 flag bit;
- 当 GPU 完整写完 output tensor 后,更新这个 flag;
- CPU 只需要 polling 这个 flag 几微秒,就能立刻知道 GPU 已结束,并通知 NPU 继续执行。
它把原来需要 heavyweight driver/runtime synchronization 的事情,简化成了一个共享 buffer 上的标志位监控。
作者发现,LLM 每一层干的事情都差不多,所以:
- GPU kernel 的执行时间通常比较规律;
- 大概多久算完,是可以预测的。
于是他们的做法不是:
- 从头到尾一直死盯着 GPU 看它什么时候结束
因为这样会浪费 CPU。
也不是:
- 一觉睡很久,醒了再看
因为那样可能错过最佳时机。
而是采用一个折中方法:
方法是:
- 先预测 GPU 大概多久干完
- CPU 线程先睡到差不多那个时刻
- 醒来后再快速轮询几下
- 一看到 GPU 真干完了,就马上通知 NPU 开工。
4.3 是两层配合:
- 第一层:用共享地址空间 + memory pool,尽量减少数据搬运和 buffer 管理开销;
- 第二层:在这个基础上,再用“预测等待时间 + 短时 polling”来做快速同步。
prefill 和 decoding 的同步流程为什么不一样
Figure 10 专门画了两条 timeline:
- prefill phase
- decoding phase。
作者说虽然两阶段都用了 fast synchronization,但二者仍有明显区别。
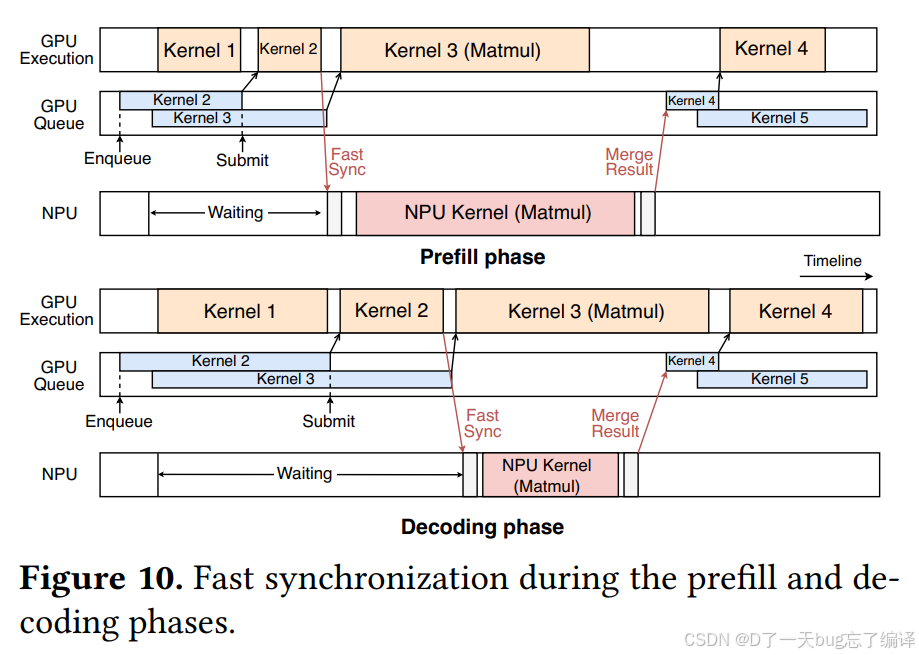
Prefill:NPU-dominant
在 prefill 中:
- NPU 的计算能力更强;
- 所以整个阶段是 NPU-dominant。
作者说在这种情况下,HeteroInfer 做的是:
- 尽量把 GPU 执行时间隐藏在 NPU 执行时间里面;
- 但下一次 GPU kernel 的提交,要等到 NPU 执行结束后再进行。
prefill 里的主路径是 NPU,GPU 更多是辅助加速。
因此关键是:
- NPU 不要等 GPU;
- GPU 的工作尽量“塞进”NPU 的长执行窗口里。
作者还提到,这样会带来一点 task submission overhead,但只有:
- 几十微秒,
Decoding:GPU-dominant
相反,在 decoding 中:
- GPU 比 NPU 更占优,
- 因为 GPU kernel implementation 能拿到更稳定、更高的 memory bandwidth;
- 所以 decoding 是 GPU-dominant。
此时作者的策略变成:
- 把 NPU 执行重叠到 GPU 执行窗口里;
- 一旦 NPU 完成,就立刻 enqueue 下一条 GPU kernel。
而且 GPU 自身的队列顺序能保证 GPU kernels 的正确同步,不需要额外 submission overhead。
prefill
- 瓶颈在算力;
- NPU 更强;
- 所以 GPU 去贴合 NPU 的时间轴。
decoding
- 瓶颈在带宽;
- GPU 在 matvec / bandwidth usage 上更稳;
- 所以 NPU 去贴合 GPU 的时间轴。
4.4 Putting It All Together
前面作者已经讲了:
- layer-level strategy
- tensor-level partition
- fast synchronization
但如果没有 4.4,这些只是分散机制。
4.4 的作用是把它们统一成一个完整系统架构。
Offline 阶段
包括:
Profiler
在真实 NPU/GPU 上测 profile
Solver
结合 model structure analysis
结合 SoC profiling results
选择最优 plan
生成 sub-graph / strategy。
Online 阶段
包括一个异构推理引擎,内部有:
kernel scheduler
decider
partitioning strategies
fast sync
GPU execution
NPU execution
merge result
memory pool。
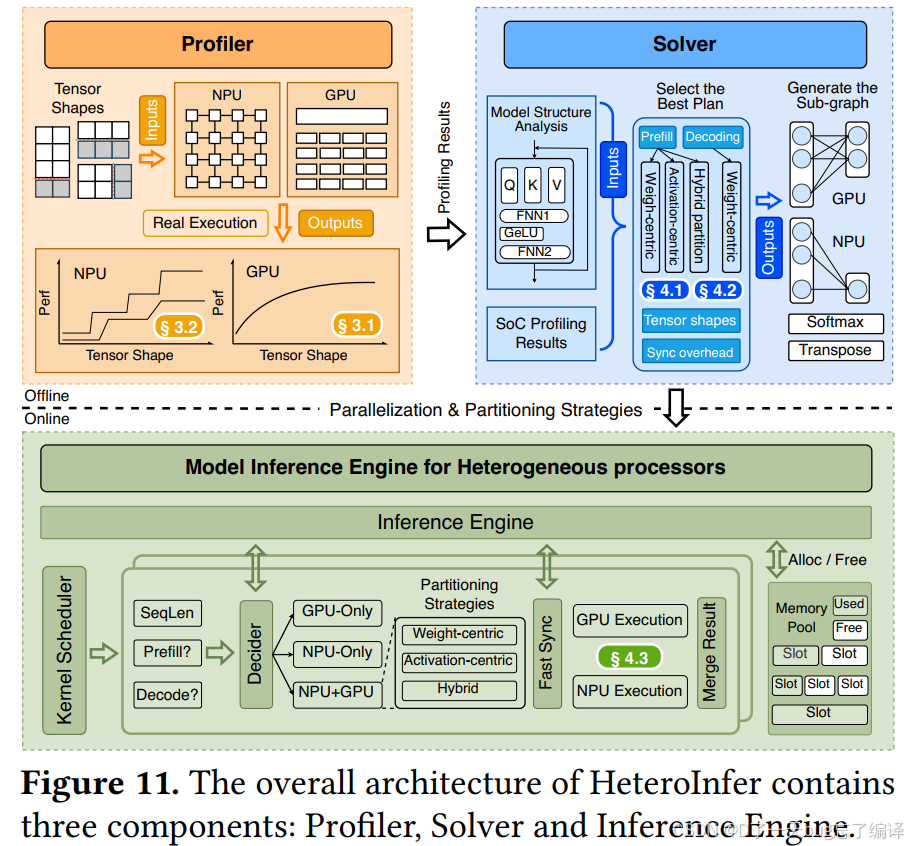
作者说,Figure 11 展示了 HeteroInfer 的 overall architecture,包含三部分:
- Profiler
- Solver
- Inference Engine。
Profiler
作者说,给定一个目标 SoC,performance profiler 会先在真实 GPU 和 NPU 上执行操作,测出:
- execution time
- memory bandwidth
- synchronization overhead 等 performance matrices。
这篇文章最大的前提就是:
- GPU/NPU performance highly hardware-dependent;
- 尤其 NPU 对 tensor shape/order 极其敏感。
所以不能靠“经验规则”直接决定 partition。
必须基于目标 SoC 的真实 profile 结果来决策。
Profiler 的 profiling 空间为什么不会爆炸
作者说他们通过三个限制,压缩了 profiling 空间:
- 只考虑来自 LLM 的 weight tensor shapes;
- NPU 的 stage performance 会对 sub-tensor 有最小尺寸要求;
- activation tensor 只限制在预定义的一组标准 sequence lengths。
因此 profiling 可以在:
- 20 分钟以内
完成。
Solver
作者说,solver 的任务是:
- 根据 profiling 结果,
- 为给定 LLM 决定最优 tensor partitioning strategy。
Solver 的第一步:看模型结构
它先分析整体 model structure,定位哪些 operator 适合跨 heterogeneous processors 切分,比如:
- attention projection
- FFN up/gate/down。
Solver 的第二步:枚举所有可行策略
对于每个 operator,它会枚举所有 feasible parallelization strategies,然后选择那个:
- 最能 overlap computation 和 synchronization,
- 从而最小化 total latency 的方案。
作者给了一个公式:

这个公式的核心意思是系统决策逻辑:
方案一:异构并行
如果把任务切成两部分:
- 一部分 GPU 跑
- 一部分 NPU 跑
那么总时间大约由:
- 两边较慢那一边的时间
- 加上同步开销
- 加上拷贝/组织开销
决定。
方案二:不切,直接单后端跑
也可能:
- 全 GPU 更快
- 或者全 NPU 更快
所以 solver 真正做的是:
比较“切分后并行”与“直接单后端执行”谁更划算。
动态长度怎么估计
作者还说,由于 prefill 的实际 sequence length 可以任意变化,而 profiler 只测了标准长度,因此 solver 会借助:
- GPU-1: linear performance
- NPU-1: stage performance
去估计 variable-length sequences 的 latency。
这说明 solver 并不是纯查表,而是:
- profile + performance model 结合。
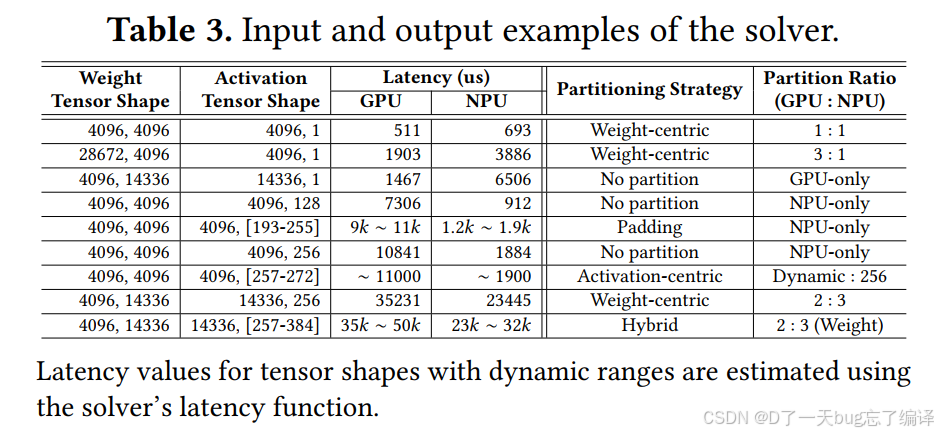
Table 3 给了 solver 的输入输出例子,非常重要。
它展示了对于不同的:
- weight tensor shape
- activation tensor shape
solver 会给出不同的:
- GPU latency
- NPU latency
- partitioning strategy
- partition ratio。
作者明确说:
- 对 decoding 中的 tensor shapes,
- 常采用 weight-centric partition,
- 并且 GPU 执行大部分计算。
理由是:
- GPU 通常在 matrix-vector multiplication 上优于 NPU。
这和前面 decoding 是 GPU-dominant 完全一致。
在 prefill shape 下,策略更依赖具体 shape
作者说在 prefill 中,最优 partitioning strategy 更具可变性、且 shape-dependent。
比如表中可以看到:
- 有的 shape 直接 GPU-only
- 有的 NPU-only
- 有的用 padding
- 有的用 activation-centric
- 有的用 weight-centric
- 有的用 hybrid。
没有统一最优策略,策略必须由 shape + hardware profiling 共同决定。
表后面两段例子
作者给了两个解释性例子:
例子一:weight shape = [4096,4096]
这里 GPU 和 NPU 之间存在显著性能差异,所以当 input sequence length 落在 257–272 时,会用:
- activation-centric partition。
例子二:weight shape = [4096,14336]
这里 GPU 和 NPU 的计算能力相对接近,约 3:2,主要因为:
- NPU-3: shape-sensitive performance。
当动态部分比较小,也就是 prefill length 只略大于标准长度时,activation-centric 可能导致 GPU 利用不足,此时:
- hybrid partition 更优。
它们说明 solver 的决策不仅看:
- dynamic or static
还看:
- shape 是否适合 NPU
- GPU/NPU 的相对速度差
- 动态剩余部分到底大不大
策略选择是细粒度的、上下文相关的,而不是“动态长度就 activation-centric”这么简单。
Inference Engine:在线阶段到底做什么
作者最后说,运行时由一个 control plane decider 决定:
- kernel 是在 NPU 上执行
- 在 GPU 上执行
- 还是用 GPU-NPU parallelism
这个决策依据是:
- solver 的输出
- 当前运行状态。
当相邻 kernel 落在不同 backend 上时怎么办
此时 inference engine 会使用:
- fast synchronization
保证数据一致性。
当两边都执行完后怎么办
如果有需要,它会:
- merge intermediate results。
内存怎么管
Inference engine 还负责 host-device shared buffers 的 memory pool 管理:
- buffer 分配与回收;
- 作为每个 GPU/NPU kernel 的输入输出 tensor;
- 并绕开 device driver 原本的组织方式。
五、实验
5.1 Experimental Setup
作者说他们实现的是一个 industrial-grade edge LLM engine: HeteroInfer,主要包括:
- 用 OpenCL 写优化后的 GPU kernels;
- 通过 QNN-NPU library 接入 NPU 支持;
- 同时支持:
- layer-level heterogeneous execution
- tensor-level heterogeneous execution。
这是在真实商业手机 SoC 软件栈上实现的系统。
量化方式
作者说模型量化采用的是:
- W4A16(weight-only quantization)
也就是:
- 权重存成 INT4
- 实际计算仍然使用 FLOAT / FP16 路径。
他们这么做是为了平衡:
- 模型精度
- 存储开销。
因为前面 related work 已经反复提到:
- 许多移动端方案靠更激进的低精度计算换速度;
- 但会损伤精度。
而 HeteroInfer 想证明的是:
即使不靠激进低精度算子,也能通过系统协同拿到很强性能。
实验平台
作者主要在两类平台上评测:
- Snapdragon 8 Gen 3
- Snapdragon 8 Elite。
但为了和已有工作公平比较,除非特别说明,论文中的结果主要都基于:
- Snapdragon 8 Gen 3。
baselin
作者比较的都是当前移动端典型 LLM inference engine,涵盖:
- llama.cpp(CPU)
- MLC / MNN(GPU)
- llm.npu / PowerInfer-2(NPU)等。
5.2 End-to-End Performance
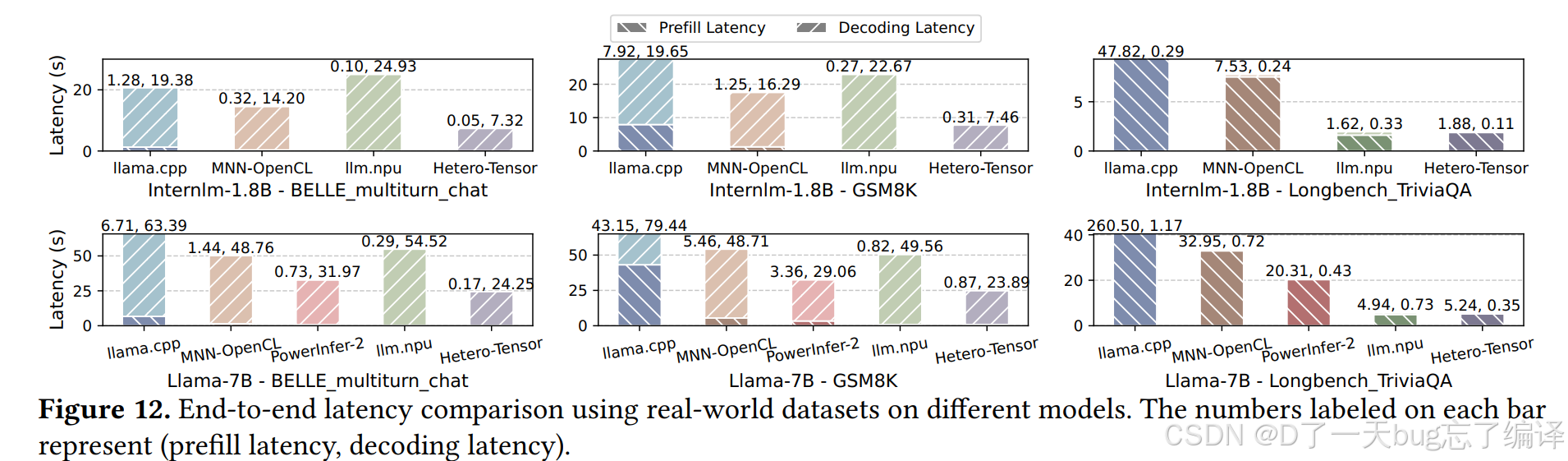
这一节先给最重要的总结果。
作者说,在 mobile platform 上的 end-to-end LLM workload test 中,HeteroInfer 相比其他 SOTA 方案整体提升:
- 1.34× 到 6.02×。
更细一点地看:
- prefill:提升 3.29× 到 24.9×
- decoding:提升 1.50× 到 2.53×。
Figure 12 比较的是不同模型、不同真实数据集上的端到端 latency,柱子上标了两个数:任务类型大致包括三类:
- multi-turn dialogue
- simple QA
- long text processing。
第一类:多轮对话(decoding-heavy)
作者指出,在 Llama-7B 的多轮对话任务上,Hetero-tensor 相比:
- MNN 提升 2.06×
- llm.npu 提升 3.40×
- 相比 PowerInfer-2 也仍快 1.34×。
第二类:平衡型任务(如 GSM8K)
作者说在 GSM8K 这类 prefill / decoding 更平衡的任务上,Hetero-tensor 平均提升:2.62×。
第三类:prefill-dominant 任务(如 LongBench)
在长文本处理、prefill 更占主导的任务中,HeteroInfer 相比 MNN-OpenCL 最高提升:6.02×。
并且作者特别强调:
- 即便 llm.npu 用了 mixed-precision 和 per-dataset quantization,
- Hetero-tensor 仍能持平甚至超越。
5.3 Prefill Performance
这一节作者把 prefill 单独拎出来分析,并且分成两个子场景:
- 固定 sequence length
- 动态、且不对齐 NPU 标准 graph 的 sequence length。
这对应前面设计里的:
- static shape
- dynamic shape
5.3.1 Fixed Sequence Length

Figure 13 比较了多个 framework 在固定序列长度 64、256、1024 下的 prefill speed。
结果一:Hetero-layer 已经很强
作者以 Llama-8B、seq=256 为例,Hetero-layer 相比:
- MNN-OpenCL:5.85×
- MLC:5.64×
- llama.cpp:24.9×
- PowerInfer-2 FP16:3.29×。
为什么 layer-level 就有这么大收益
作者解释主要来自:
- 正确考虑 NPU / GPU 对不同 operators 的 affinity;
- 对 Matmul 做了等价的 tensor order exchange。
也就是说,哪怕还没进入更细的 tensor partition,仅仅是:
- 算子映射更合理
- Matmul 顺序更适合 NPU
就已经能大幅提升 prefill。
结果二:Hetero-tensor 比 Hetero-layer 还更进一步
作者说 Hetero-tensor 在此基础上平均再提升:
- 30.2%
- 在 sequence length = 32 时甚至可到 40.8%。
在 Llama-8B 上,prefill speed 可达:247.9 tokens/s
在 InternLM-1.8B 上更高达:1092 tokens/s。
为什么 tensor-level 还能进一步提速
作者解释是因为 Hetero-tensor:
- 通过切分 weight 和 activation,尤其是 FFN-down;
- 让一部分 tensor 变成更适合 NPU 的 shape;
- 同时把剩余部分交给 GPU。
本质上,Hetero-layer 解决了“层的分工”,
而 Hetero-tensor 进一步解决了“同一层内部 tensor shape 仍然不友好”的问题。
结果三:相比只用 NPU INT 方案,HeteroInfer 仍更强
作者特别强调:
- 与只利用 NPU INT 计算、可能牺牲精度的方案相比,
- HeteroInfer 充分利用了 NPU 的 FLOAT capability,
- 再加上高效 GPU-NPU 协作,
- 性能可以达到甚至超过这些方案。
例如在 InternLM-1.8B、seq=256 的 prefill 下:
- Hetero-tensor:1092 tokens/s
- llm.npu:564 tokens/s。
5.3.2 Dynamic Sequence Length
作者再次强调:
- 现在移动端 NPU 只支持 static graph;
- 不可能为每个 sequence length 都预生成图。
所以需要和几类替代方案对比:
- Online-prepare
- Padding
- NPU-pipe
- 以及文中的 Hetero-tensor。

Figure 14 画的是在动态且不对齐的 sequence lengths 下,不同方法的 prefill latency。
图中把 Online-prepare 进一步拆成:
- graph preparation
- computation。
这能直接看出不同方法的时间到底花在哪。
Online-prepare 为什么最差
作者说 Online-prepare 通常 latency 最高,因为:
- graph preparation overhead 非常大;
- 且会随着 sequence length 和 NPU graph 数量增长。
例如:
- 在长度 135 时,preparation 就占 408.4 ms
- 到长度 1000 时,上升到 2050 ms。
Padding 为什么也不好
Padding 会导致 latency 呈台阶式增长,并造成额外低效。
作者说当 sequence length 轻微超过某个标准 size 时,padding 平均会比 Hetero-tensor 多出:1.91× overhead。
NPU-pipe 比 Padding 好,但仍不如 Hetero-tensor
NPU-pipe 的思路是把动态图分成多个标准 size 子图。
这确实减轻了 padding 问题,但作者说 Hetero-tensor 相比它仍能减少 prefill latency:13.2% 到 30.1%。
Hetero-tensor 对动态长度的最终收益
作者说在 sequence length = 525 时,Hetero-tensor 相比:
- Online-prepare:2.24×
- Padding:2.21×
- NPU-pipe:1.35×。
5.4 Decoding Performance
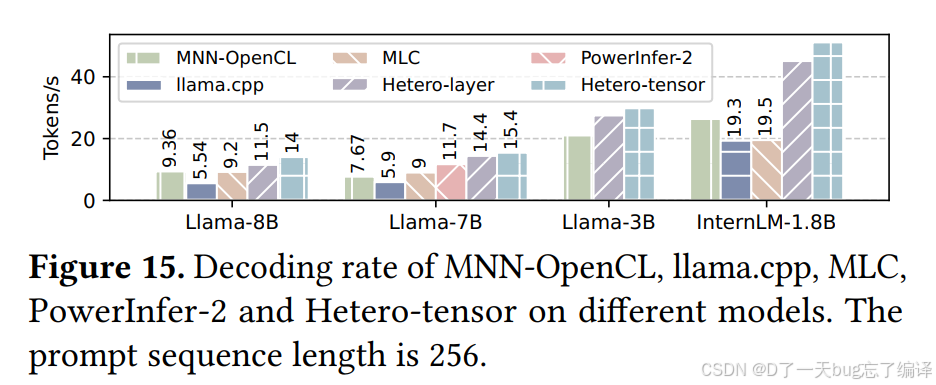
Figure 15 比较不同方案在 decoding 阶段的 tokens/s,prompt sequence length 设为 256。
结果
Hetero-tensor 的 decoding 速度达到:
- 14.01 tokens/s on Llama-8B
- 29.9 tokens/s on Llama-3B
- 51.12 tokens/s on InternLM-1.8B。
在 Llama-8B 上,相比:
- MNN-OpenCL:1.50×
- llama.cpp:2.53×
- MLC:1.52×。
即便相比 PowerInfer-2(使用 sparse model),Hetero-tensor 也还有:
- 1.32× 提升。
为什么 decoding 能赢过 sparse model
作者解释,虽然 sparse computation 减少了计算量,但它会引入:
- 大量随机且更小粒度的 memory accesses,
- 从而损害总体 memory bandwidth。
这其实和论文前面的主张完全一致
decoding 的主瓶颈不是单纯算术量,而是:
- memory bandwidth
Hetero-tensor 为什么是 decoding 中唯一真正吃满带宽的方案
作者说 Hetero-tensor 是唯一一个在 decoding 中同时利用:GPUNPU的框架。
当 GPU 和 NPU 并发时,memory bandwidth 从:43.3 GB/s(仅 GPU)提升到 59.5 GB/s
已经达到最大可用带宽的:96%。
这几乎直接验证了论文在 Section 3 的分析
5.5 Effect of Fast Synchronization
5.1 Prefill 中的收益(Figure 16)
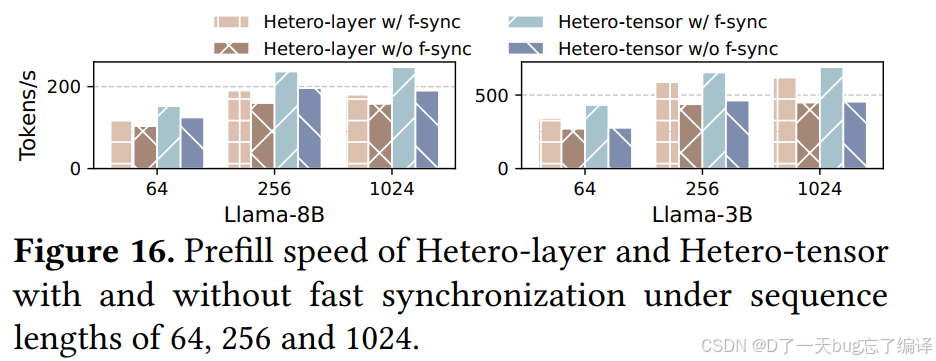
作者比较 Hetero-layer 和 Hetero-tensor 在:
- 有 fast sync
- 无 fast sync
两种情况下的 prefill speed。
结果是:
- 对 Hetero-layer,fast sync 平均提升 15.8%
- 对 Hetero-tensor,平均提升 24.3%。
在 Llama-8B、seq=256 上,Hetero-tensor 从:
- 196.44 tokens/s
- 提升到 236.92 tokens/s。
为什么 Hetero-tensor 对同步更敏感
作者解释,因为 GPU-NPU 并行更强时,若同步不够快,就会更容易打破 GPU 与 NPU 之间的计算平衡。
5.2 Decoding 中的收益(Figure 17)
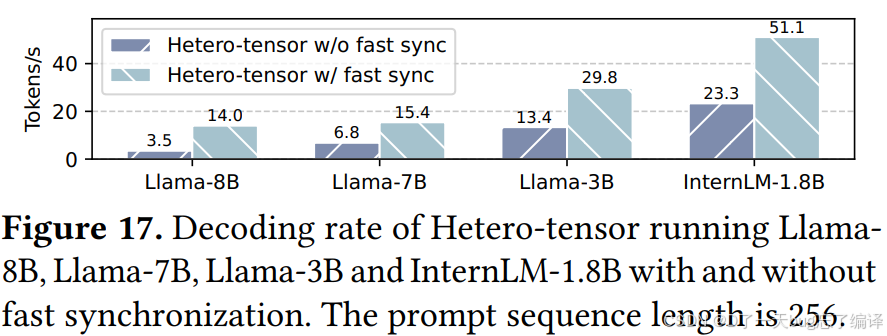
在 decoding 中,fast synchronization 的作用更大。
作者说:
- 在 Llama-8B 上,Hetero-tensor 的 decoding rate 有 4.01× 提升;
- 在其他模型上,也能观察到约 2.2× 的增益。
为什么 decoding 的收益更夸张
作者解释得很清楚:
- decoding 中单个 kernel 的执行时间更短;
- 因此同步开销和 GPU kernel submission overhead 变得不可忽略。
5.6 Ablation Study:每个组件到底各贡献多少
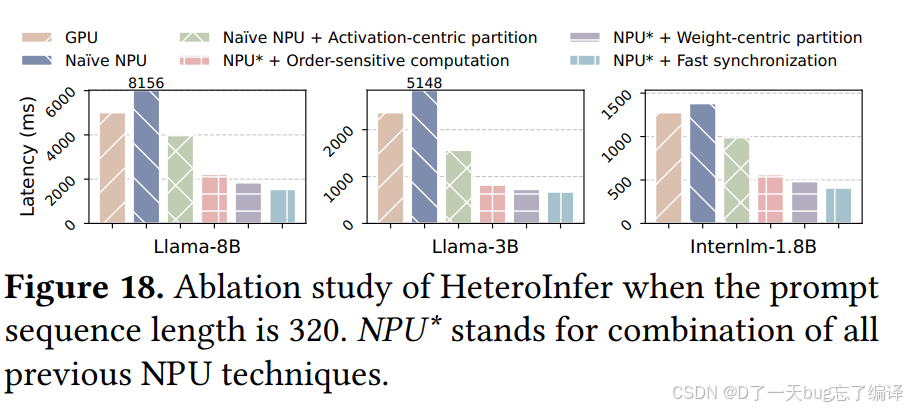
基线:naive NPU implementation 甚至比 GPU 更慢
作者说在 Llama-8B 上,naive NPU implementation 甚至比 GPU baseline 慢:62.5%。
它直接说明:
“NPU 理论更强”不等于“直接搬过去就更快”。
加 activation-centric partition:2.05×
加入 activation-centric partition 后:
- 去掉了运行时 graph generation 的开销,
- 带来 2.05× 提升。
再加 order-sensitive 处理:再提升 1.79×
进一步通过 rearranging tensor ordering 处理 NPU 的 order-sensitive 性质,又带来:
- 1.79× 改进。
再加 weight-centric partition:再提升 1.20×
考虑到 NPU 的 shape-sensitive performance,启用 weight-centric partition 后,又获得:
- 1.20× 提升。
最后加 fast synchronization:再提升 1.19×
最后加入高效同步,又带来:
- 1.19× 提升。
5.7 GPU Performance Interference:会不会影响别的应用
这是移动端系统论文非常重要的一项测试。
作者并发运行了:
- GPU-only
- Hetero-layer
- Hetero-tensor
以及一个高性能手机游戏:
- League of Legends: Wild Rift。
Prefill 阶段的干扰
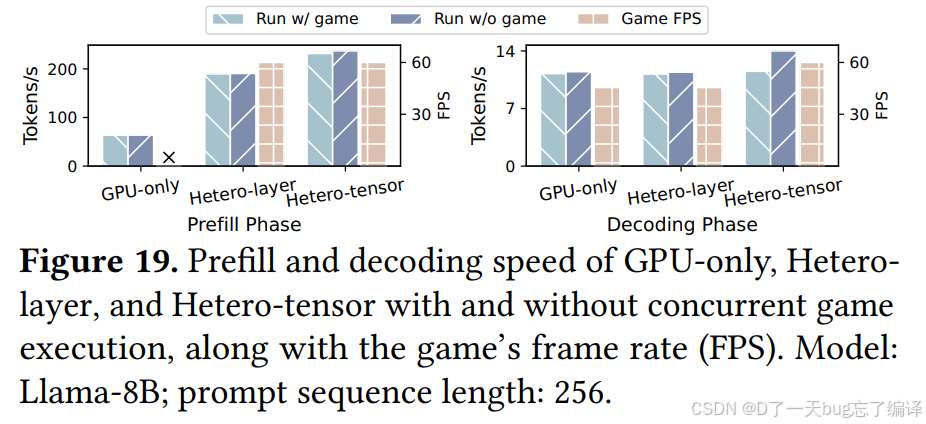
Figure 19 显示,在与游戏并发运行时:
- Hetero-layer prefill speed 只下降 0.5%
- Hetero-tensor 只下降 2.2%
- 游戏 FPS 基本不受影响。
相比之下,GPU-only baseline 会导致:
- 严重 FPS drop to zero。
为什么 GPU-only 会这么糟
因为 OpenCL runtime 发射的 GPU kernels 会把 GPU submission queue 占满,导致游戏渲染任务无法及时完成。
而 Hetero-layer / Hetero-tensor 由于只把一小部分计算放到 GPU,保留了足够 GPU 资源给游戏渲染。
Decoding 阶段的干扰
在 decoding 中,GPU-only baseline 的问题有所缓解,游戏还能维持:
- 46 FPS
主要因为 decoding 阶段 GPU workload 本来就更轻。
但 Hetero-tensor 仍然对 FPS 没有影响,而其 decoding speed 只下降:
- 17.7%,原因是 GPU kernel 延迟导致 NPU 与 GPU 不能完全 overlap。
5.8 Energy Consumption
Figure 20 比较了:
- GPU-only
- Hetero-layer
- Hetero-tensor
在 prefill / decoding 下的功耗和端到端能耗。
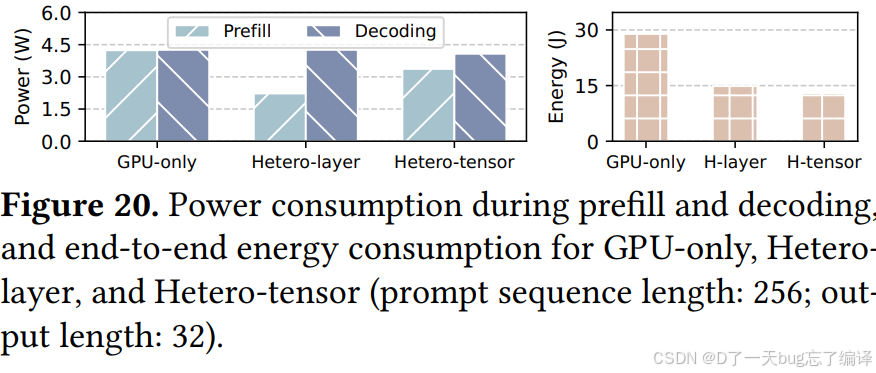
Prefill 阶段
在 prefill 中,Hetero-layer 的功耗最低:
- 2.23 W
主要因为它大多数计算都交给了 NPU。
Decoding 阶段
在 decoding 中,Hetero-tensor 的功耗最低,因为它把工作分给了:NPU、GPU。
端到端能耗
就整体能耗而言,Hetero-tensor 最节能:
- 比 GPU-only 少 55%
- 比 Hetero-layer 少 12.8%。
为什么它反而更省电
核心原因不是瞬时功耗绝对最低,而是:
- 执行更快
- 完成得更早
- 因而总能量消耗更低。
六、 Discussion
1 Platform and Model Generality
作者说现代 mobile SoC 通常都具有类似特征:
- unified memory architecture
- asynchronous GPU execution model
- systolic-array-based NPU。
因此 HeteroInfer 的观察和设计可以较容易迁移到其他 mobile SoC。
对于模型,即使 architecture 变成如 MoE,只要底层算子类型类似,设计仍有适用性。
2 对未来 edge AI accelerator / system 的启示
作者提出了三个改进方向:
第一,统一的 GPU-NPU scheduling
未来复杂边缘场景里,GPU-only、NPU-only、GPU-NPU 并行任务可能并存。
如果没有统一调度机制,一个处理器上的任务可能阻塞另一个处理器上的任务。
第二,统一的 memory management
虽然有 UMA,但当前 CPU/GPU/NPU 之间通常没有一致的共享内存管理。
作者认为如果有统一 API 和统一 memory management layer,会显著减少开发复杂度和同步开销。
第三,轻量级异构同步库
他们认为未来需要更轻量的 heterogeneous synchronization library,帮助计算和通信更高效 overlap。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 33
33 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)