《VLA 系列》π₀.₇ Pi0.7 | 多元提示Prompt | 泛化提升 | 通用机器人
π₀.₇是一款可精准调控的通用机器人基础模型,核心通过多模态丰富提示与多元数据训练,实现无需微调的开箱即用能力 与 组合泛化。
- 定标杆:大模型的通用能力来自大规模+多样化数据,
组合泛化是核心。 - 指痛点:机器人领域一直做不到组合泛化,传统VLA模型有致命缺陷。
- 抛方案:π₀.₇用
多元数据 + 精细多模态提示解决痛点,实现通用机器人。
π₀.₇的核心目标: 给数据加“说明书”,让模型能吃脏数据、差数据、失败数据,还能越学越强。
论文地址:π0.7: a Steerable Generalist Robotic Foundation Model with Emergent Capabilities
项目地址:https://www.pi.website/blog/pi07
下面是示例的Prompt信息
Task(任务): peel vegetables
Subtask(子任务指令): pick up the peeler
Speed(速度): 2000
Quality(质量): 5
Mistake(是否犯错): false
Control Mode(控制方式): joint
其中,上面标签的范围定义
- 速度:时间步长离散值(如 8000、2000,按 500 步区间分箱)
- 质量:1~5 星
- 是否犯错:true / false
- 控制方式:告诉机器人用什么控制方式,joint 关节控制、ee 末端执行器控制
传统VLA = 单一文本提示 + 高质量数据。 π₀.₇ = 多模态提示 + 任意混合数据

一、核心设计创新
- 多元提示架构
摒弃单一文本指令,采用多维度上下文提示,包含:- 子任务指令:细化语义级分步操作,支持人工语音指导;
子目标图像:由世界模型BAGEL生成多视角目标画面,明确执行细节;多元数据标注:标注机器人的执行速度、质量、错误状态,适配混合质量数据;- 控制模式:支持关节级/末端执行器两种动作控制。
- 模型架构
以Gemma3 4B为视觉-语言主干,搭配860M参数流匹配动作专家,集成MEM记忆系统,支持多相机历史帧与子目标图像输入,采用知识绝缘训练方案保证训练稳定。 - 训练数据
融合优质演示数据、自主执行数据(含失败案例)、人类第一视角视频、网络多模态数据,无需过滤低质量数据,靠元数据实现有效学习。
二、模型架构
如下图所示,是π₀.₇的模型架构,采用 “三级分层+多模态提示+模块化分工” 的范式,解决传统VLA模型指令歧义、数据利用受限、长周期任务鲁棒性差的问题:
- 分层解耦:将“任务规划、目标可视化、动作执行”拆分为独立模块,各司其职、可独立优化。
- 多模态提示:用「文本指令+子目标图像+元数据」的组合提示,消除歧义、引导模型从混合质量数据中学习。
- 记忆与世界模型:通过历史观测记忆解决长任务状态遗忘,通过生成式世界模型提供视觉目标参考。
- 流匹配执行:用Flow Matching动作专家建模多模态动作分布,输出平滑、鲁棒的连续动作序列。
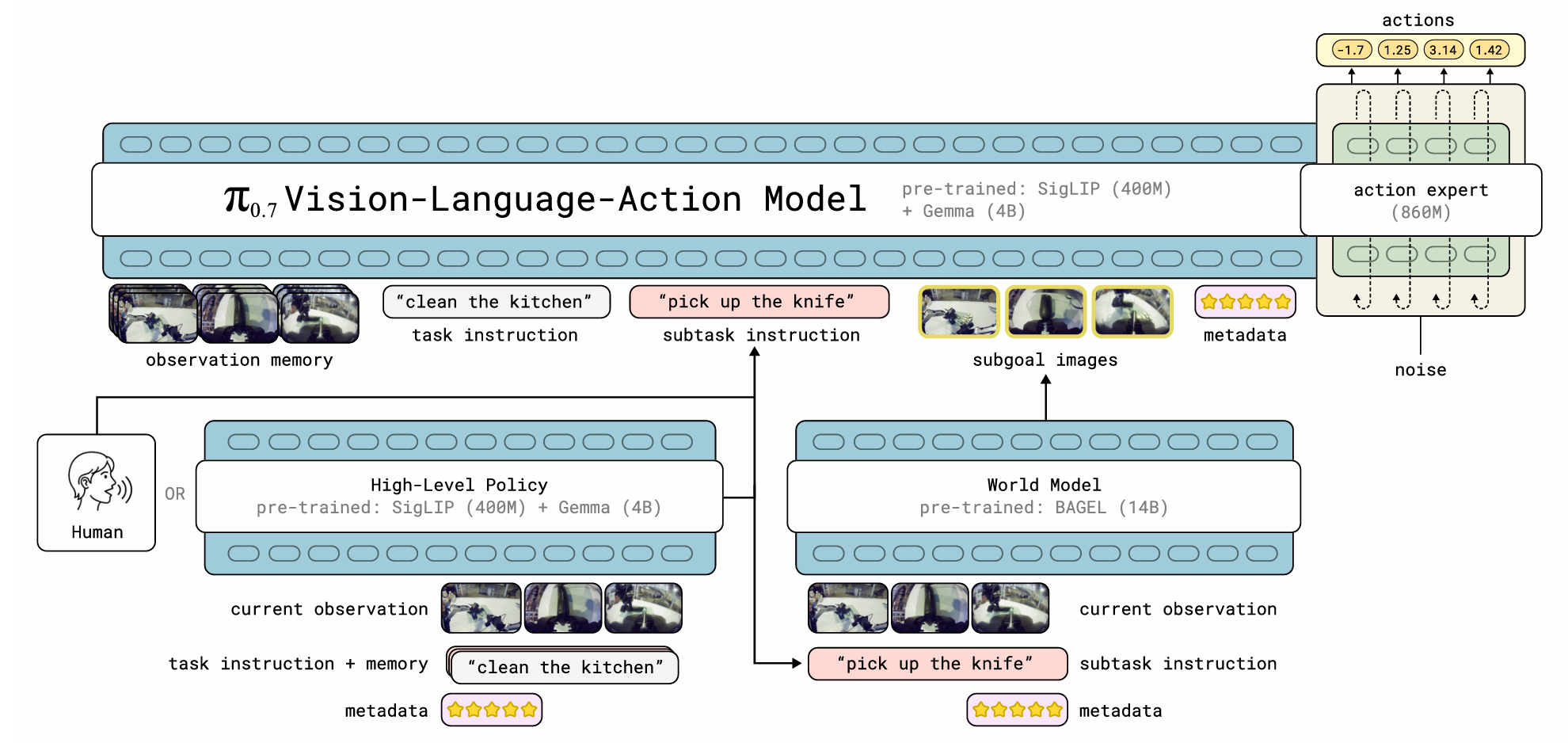
步骤1:任务输入与高层规划(High-Level Policy)
- 输入来源:
- 用户直接语音指令(Human),或文本形式的高层任务指令(如
"clean the kitchen")。 - 当前观测(current observation)+ 任务记忆(task instruction + memory)+ 元数据(metadata,如质量星级、操作速度、是否错误)。
- 用户直接语音指令(Human),或文本形式的高层任务指令(如
- 模块功能:
由和主模型同构的SigLIP+Gemma3模型,将复杂长任务分解为可执行的子任务指令(如"pick up the knife"),实现长周期任务的分步规划。
步骤2:子目标生成(World Model)
- 输入:当前观测(current observation)+ 子任务指令(subtask instruction)+ 元数据(metadata)。
- 模块功能:
由14B参数的BAGEL世界模型,生成多视角子目标图像(subgoal images),明确“当前子任务要达成的视觉状态”,解决纯文本指令的歧义问题(比如“拿起刀”到底要拿成什么样)。
步骤3:多模态提示构建
主模型接收来自各模块的完整提示输入,包括:
observation memory:机器人最近多帧历史观测(多相机视角),提供状态上下文。task instruction:原始高层任务指令(如"clean the kitchen")。subtask instruction:高层策略输出的当前子任务指令(如"pick up the knife")。subgoal images:世界模型生成的子目标图像,提供视觉目标参考。metadata:任务元数据(质量、速度、错误状态等),控制执行策略风格。
步骤4:动作生成与执行(π₀.₇ VLA模型)
- 模块组成:
- 视觉语言主干:SigLIP(400M)+ Gemma3(4B),处理所有多模态提示,提取统一特征表示。
- 动作专家:860M参数的Flow Matching模型,接收主干特征+噪声(用于建模多模态动作分布),输出连续动作序列(
actions)。
- 输出:机器人关节/末端执行器的连续动作指令,直接发送给机械臂执行。
步骤5:循环迭代
子任务执行完成后,更新观测记忆,高层策略输出下一个子任务,重复步骤1-4,直到完成整个长周期任务。
三、π₀.₇ vs π₀.₆ vs π₀.₅ 核心差异对比表
如下表所示,总结了π₀.₇/π₀.₆/π₀.₅三代VLA模型的迭代差异:
| 对比维度 | π₀.₇ | π₀.₆ | π₀.₅ |
|---|---|---|---|
| 定位 | 可 steer、强泛化、通用机器人基础模型 | 通用VLA模型,支持记忆 | 分层VLA,支持开放世界泛化 |
| 总参数量 | 约5B(4B VLM + 860M动作专家) | 约4.4B | 约3.7B |
| 主干模型 | Gemma3 4B + MEM记忆编码器 | Gemma2 2B + MEM | Gemma2 2B |
| 提示/上下文 | 任务指令+子任务+子目标图像+元数据+控制模式 | 任务指令 | 任务指令+高层子任务 |
| 子目标图像 | 支持(世界模型BAGEL生成) |
不支持 | 不支持 |
| 多元数据信息标注 | 速度、质量、错误标签 |
无 | 无 |
| 训练数据 | 演示+自主数据(含失败)+人类视频+网页数据 | 演示+少量自主数据 | 以高质量演示为主 |
| 混合数据学习 | 可高效利用低质量/失败数据 | 有限,依赖高质量数据 | 仅用高质量数据 |
| 开箱即用性能 | 媲美/超越专项RL微调模型 |
接近但弱于RL专家 | 需微调才能达专家水平 |
| 跨形态迁移 | 零样本强,可跨UR5e等工业臂 | 中等,小形态差异可用 | 弱,形态差异大即失效 |
| 指令遵循 | 强,可处理复杂/反常识/指代指令 | 中等,常规指令可用 | 基础,复杂指令易失败 |
| 组合泛化 | 强,零样本新任务+语言教练 | 弱,难组合新技能 | 极弱,几乎无泛化 |
| 灵巧任务 | 叠衣、做咖啡、装箱、削菜等 | 部分灵巧任务 | 以简单操作为主 |
| 推理速度 | 最快38ms,全功能127ms | 约60–150ms | 约80–200ms |
| 核心突破 | 泛化、可控、跨形态、数据效率 | 记忆、长周期任务 | 分层、开放世界 |
π₀.₇ 框架亮点总结
| 设计点 | 解决的问题 | 效果 |
|---|---|---|
| 分层规划+子目标生成 | 长周期任务规划难、纯文本指令歧义大 | 复杂任务可分步执行,指令理解准确率大幅提升 |
| 多模态提示输入 | 传统VLA仅靠文本指令,无法利用低质量/失败数据 | 支持混合质量数据训练,数据效率显著提升 |
| 记忆系统(MEM) | 长任务状态遗忘 | 能记住历史观测,提升长周期任务鲁棒性 |
| Flow Matching动作专家 | 传统回归模型输出单一动作模式,不够鲁棒 | 建模多模态动作分布,动作更自然、容错性更强 |
| 模块化设计 | 端到端模型难以优化、扩展 | 各模块可独立训练/替换,适配不同机器人与任务场景 |
π₀.₇ 关键能力表现
- 开箱即用的灵巧操作
无需任务微调,即可完成制作意式咖啡、叠衣服、组装纸箱、削蔬果、换垃圾袋等高难度长周期任务,性能媲美甚至超越专项RL微调模型,在叠衣、装箱任务中吞吐量更高。 - 强指令遵循与泛化
在4个全新厨房、2个全新卧室环境中,可执行3-6步复杂开放指令,能理解非常规指代指令,还可突破数据集偏见执行反向任务(如把餐具丢进垃圾桶)。 - 零样本跨形态迁移
无需目标机器人任务数据,可将技能迁移至不同形态机器人(如从轻型双臂机器人,迁移至UR5e工业双臂),叠衣任务表现比肩资深远程操控专家。 - 组合式任务泛化
零样本完成未训练短周期任务(按法压壶、盛米饭);通过分步语言指导即可学会空气炸锅、烤贝果等全新长周期任务,还能基于指导数据训练自主高层策略。
四、π₀.₇设计背景和解决的问题(可选观看)
1. 基础模型的通用能力来源
Foundation models work on the principle that generalist capabilities emerge from training on large and diverse datasets.
- 展开:
所有大模型(LLM、多模态、机器人)的通用能力不是设计出来的,是“涌现”出来的。
关键条件只有两个:数据够大、数据够多样。
这是整篇π₀.₇的理论根基。
2. LLM的组合泛化(黄金标准)
For example, large language models can not only recall facts… but compose that knowledge in new ways…
- 展开:
LLM 最强的不是“记住”,而是把没见过的知识组合起来解决新问题。
这种能力叫 组合泛化(compositional generalization),是“通用智能”的标志。
3. 机器人领域的最大困境
This kind of compositional generalization… has proven elusive in physical intelligence.
- 展开:
语言模型轻松做到的事,机器人完全做不到。
机器人只能学“见过的任务”,不会自己组合技能。
→ 这是π₀.₇要攻克的核心科学问题。
4. 传统机器人VLA模型的致命缺陷
While robotic foundation models… their ability to generalize… has been limited.
Prior VLAs… often struggle to perform all instructions without task-specific fine-tuning.
- 展开:
过去的视觉-语言-动作模型(VLA)有两个硬伤:- 不会泛化到新任务
- 就算是训练过的任务,不微调也做不好
根本算不上“通用机器人”。
5. π₀.₇的核心突破
We present π₀.₇… exhibits strong compositional generalization…
- 展开:
π₀.₇ 第一次在机器人上实现了接近LLM的组合泛化:- 能听懂各种语言指令
- 灵巧操作媲美专项微调模型
- 能把旧技能重新组合做新任务
6. 靠什么实现:超多元数据
This is enabled by leveraging large and diverse datasets… robots, autonomous data, failures, human videos, web data.
- 展开:
π₀.₇不只用高质量演示,还敢用:- 不同机器人的数据
- 自主运行的数据(包括失败)
- 人类第一视角视频
- 互联网多模态数据
这是前所未有的数据规模与多样性。
7. 一个关键难题:乱数据会让模型变“平庸”
Using such data naively does not lead to success… model averages modes… suboptimal.
- 展开:
直接用杂乱数据会毁掉模型。
因为模型会把各种好坏策略“取平均”,最后什么都做不好。
→ 这是行业一直不敢用杂数据的原因。
8. π₀.₇的独家解法:精细上下文提示
We address this by detailed context annotations… what to do + how to do it.
- 展开:
给每一段数据都加详细“说明书”:
不只告诉模型“做什么”,还告诉它怎么做、做得好不好、快不快、有没有错。
让模型能区分好坏、区分策略,不会“平均化”。
9. 最终提示结构(论文核心创新)
Our prompt includes detailed language, strategy metadata, subgoal images.
- 展开:
π₀.₇的提示 =- 精细语言指令(做什么)
- 策略元数据(速度、质量、错误)
- 子目标图像(视觉上要变成什么样)
这套组合是机器人领域第一次出现。
10.为什么用Flow Matching 而不是普通回归?
π₀.₇的动作专家 = 860M参数 Flow Matching 模型。
- 机器人动作是多模态的(同一种任务有多种正确做法)。
- 回归只能输出平均值 → 动作僵硬、失败率高。
- Flow Matching能建模多种合理动作分布 → 更灵活、更像人类。
11. 最终效果
Resolve ambiguity, learn from suboptimal data, generalization across instructions, embodiments, environments.
- 展开:
最终实现三大能力:- 从劣质/失败数据中学习
- 消除任务歧义
- 跨指令、跨机器人、跨环境通用
五、多元数据提示 Prompt
传统机器人仅输入单句文字指令,π₀.₇ 采用多模态精细化提示,让机器人清晰理解执行逻辑、质量要求与控制方式,完成各类复杂任务。
5.1 为什么要"多元数据提示"?
| 对比项 | 传统 VLA (π₀.₅/RT-2/OpenVLA) | π₀.₇ |
|---|---|---|
| 输入 | “把杯子放到桌子上” | 任务指令 + 子任务指令 + 子目标图像 + 剧集元数据 + 控制模式 |
| 问题 | ① 无执行细节 ② 无质量标准 ③ 无速度要求 ④ 无避错指引 ⑤ 无控制方式 |
全维度明确执行要求 |
| 结果 | 仅适配高质量演示数据,无法利用次优/失败数据,泛化能力弱,动作单一 | 兼容混合质量数据,泛化能力强,零微调开箱即用 |
核心逻辑:扩充多模态提示 → 消歧义、可精控 → 善用混合/次优/失败数据 → 跨具身/跨任务强泛化 → 零微调开箱即用
5.2 π₀.₇ 的四大提示组件
┌─────────────────────────────────────────────────────────┐
│ π₀.₇ 完整提示架构 │
├─────────────┬───────────────────────────────────────────┤
│ ① 子任务 │ 语义级任务分解 │
│ 指令 │ "fold shirt" → pick→fold left→fold right │
├─────────────┼───────────────────────────────────────────┤
│ ② 子目标 │ 轻量世界模型BAGEL生成"步骤目标视觉效果" │
│ 图像 │ 解决语言歧义(如"放好"的具体形态) │
├─────────────┼───────────────────────────────────────────┤
│ ③ Episode │ 速度(时间步分箱,如8000steps)+ 质量(1-5星) │
│ 元数据 │ + 是否犯错(true/false) │
├─────────────┼───────────────────────────────────────────┤
│ ④ 控制模式 │ joint(关节控制) / ee(末端执行器控制) │
└─────────────┴───────────────────────────────────────────┘
① 子任务指令
- 作用:长周期任务语义级拆分,支持人工分步语言指导
- 创新:基于语义逻辑拆分任务,而非简单时间分段,让复杂长任务可解
② 子目标图像 ⭐ 核心创新
- 来源:基于BAGEL的轻量世界模型生成多视图子目标图像
- 价值:用视觉画面消除语言模糊性,明确步骤执行后的场景状态
- 意义:将生成式视觉目标作为核心提示,大幅提升机器人空间执行精度
③ Episode 元数据 ⭐ 关键创新
- 标签:速度(执行时间步离散分箱)| 质量(1-5星,5为最高) | 是否犯错(true/false)
- 价值:让模型精准区分数据质量,学习优质动作、规避错误操作、控制执行效率
- 突破:传统模型无法使用失败/次优数据,π₀.₇ 依托元数据可高效学习此类数据
④ 控制模式
- 选项:joint(关节控制) / ee(末端执行器控制)
- 价值:灵活适配不同形态机器人的硬件执行方式,支撑跨具身迁移
5.3 完整提示示例
Task: peel vegetables # 总任务
Subtask: pick up the peeler # 当前子任务
Speed: 8000 # 执行速度(时间步分箱)
Quality: 5 # 质量等级(最高5星)
Mistake: false # 是否为错误示范
ControlMode: joint # 控制方式
💡 这就是机器人的"超级指令"——相比传统单句指令,包含更全面的执行与控制信息
示例数据如下所示:
5.4 训练关键技巧:Prompt Dropout
做法:训练时随机丢弃部分提示组件(子目标图像/元数据/子任务指令)
效果:
训练时 推理时
有时有子目标图像 ──→ 有图 → 依托图像精准执行
有时无子目标图像 ──→ 没图 → 仅靠语言正常执行
有时有元数据 ──→ 有数据 → 精细化控制速度/质量
有时无元数据 ──→ 没有 → 按默认模式执行
结果:模型适配多种输入形式,开箱即用,无需任务专属微调
5.5 核心优势总结
| 能力 | 传统 VLA | π₀.₇ |
|---|---|---|
| 利用失败/次优数据 | ❌ 无法适配 | ✅ 依托元数据精准区分 |
| 长任务语义分解 | ❌ 不支持 | ✅ 子任务指令拆分 |
| 消除语言歧义 | ❌ 无法解决 | ✅ 子目标图像可视化明确 |
| 执行速度/质量控制 | ❌ 无相关能力 | ✅ 元数据标签可控 |
| 跨机器人硬件适配 | ❌ 难以适配 | ✅ 支持双控制模式 |
| 零样本泛化 | ❌ 能力极弱 | ✅ Prompt Dropout训练赋能 |
六、模型设计细节
6.1 世界模型(BAGEL 14B)训练
| 维度 | 配置 |
|---|---|
| 训练数据 | 机器人高质量分段数据 + 人类第一视角视频 + 开源图像/视频数据集 |
| 输入分辨率 | ViT 编码 448×336 / VAE 编码 512×384 |
| 刷新频率 | 每 4 秒 生成一次子目标图像(匹配机器人执行节奏) |
| 核心作用 | 生成视觉提示,消除语言歧义 |
6.2 推理速度与工程优化
硬件配置
π₀.₇ 策略模型 → 单卡 NVIDIA H100
BAGEL 世界模型 → 4 卡 H100 并行
优化手段
- 8 位量化 → 压缩模型体积
- SageAttention → 加速注意力计算
- 张量并行 → 多卡并行推理
性能指标
| 场景 | 延迟 | 说明 |
|---|---|---|
| π₀.₇ 最简推理 | 38 ms | 基础策略生成 |
| π₀.₇ 全功能 | 127 ms | 含完整上下文处理 |
| 子目标图像生成 | 1.25 s | 世界模型生成目标图 |
执行策略:异步流水线
时间轴 ──────────────────────────────────────→
机器人执行 [动作 A ..........] [动作 B ..........]
↑ ↑
子目标生成 [生成图 A][生成图 B]
↑ ↑
4s 刷新 4s 刷新
关键:机器人边执行当前动作,边异步生成下一步子目标图,掩盖 1.25s 生成延迟
6.3 核心结论
| 痛点 | 解决方案 | 效果 |
|---|---|---|
| 策略推理慢 | 8 位量化 + SageAttention | 38ms 实时响应 |
| 图像生成慢 | 4 卡并行 + 异步流水线 | 执行掩盖延迟 |
| 部署门槛高 | 单卡 H100 可跑 | 工程落地可行 |
七、模型效果
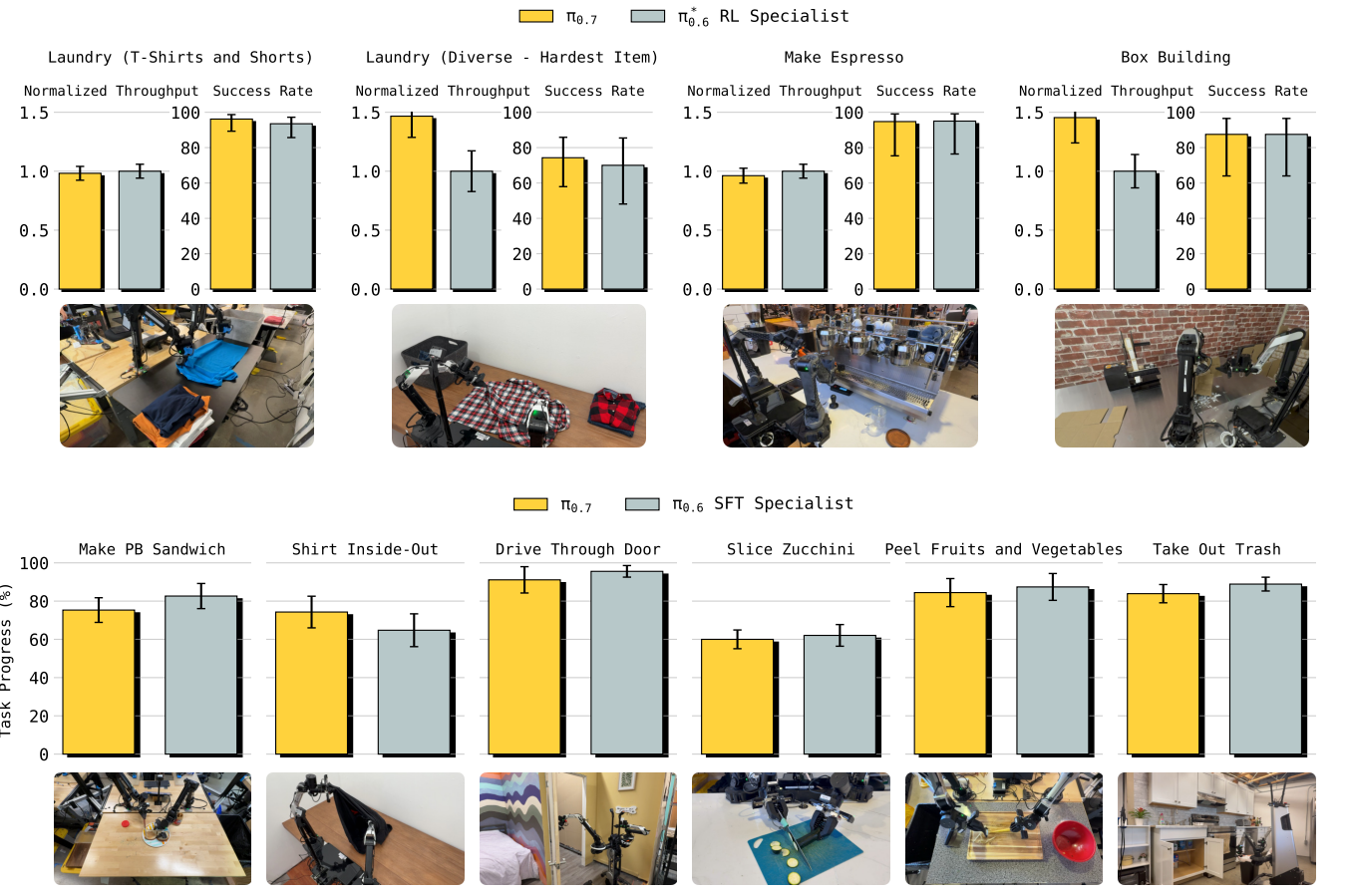
模型性能对比1:
- 同一 π₀.₇模型在下图所有任务中,性能均可与 π₀.₆*RL 或 π₀.₆SFT 的任务专属后训练专项策略持平
- 甚至在叠衣物、组装盒子等多样化任务中,吞吐量超过了强化学习(RL)专项模型。
模型性能对比2:全新环境下的通用指令测试
- 纵轴:指令遵循成功率(%)
- 场景 1:未见过的厨房(多样化指令)
- 场景 2:未见过的卧室(多样化指令)
→ 核心结果:π₀.₇的成功率在两类场景中均显著高于前两代模型。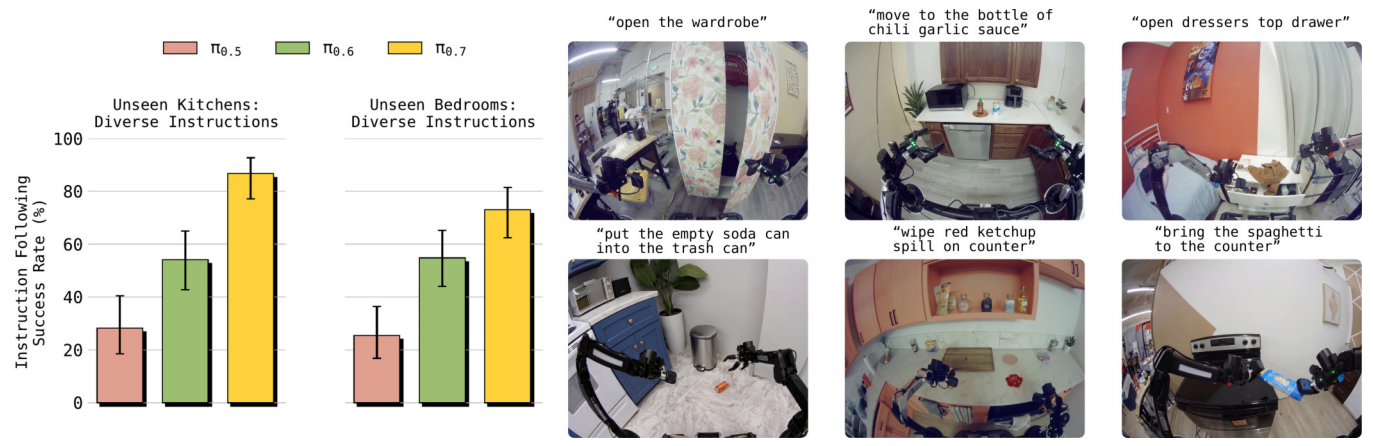
模型性能对比3:跨具身迁移性能
在简单的重排或位置调整类任务中,π₀.₇与前代模型都能开箱即用实现强跨具身迁移。
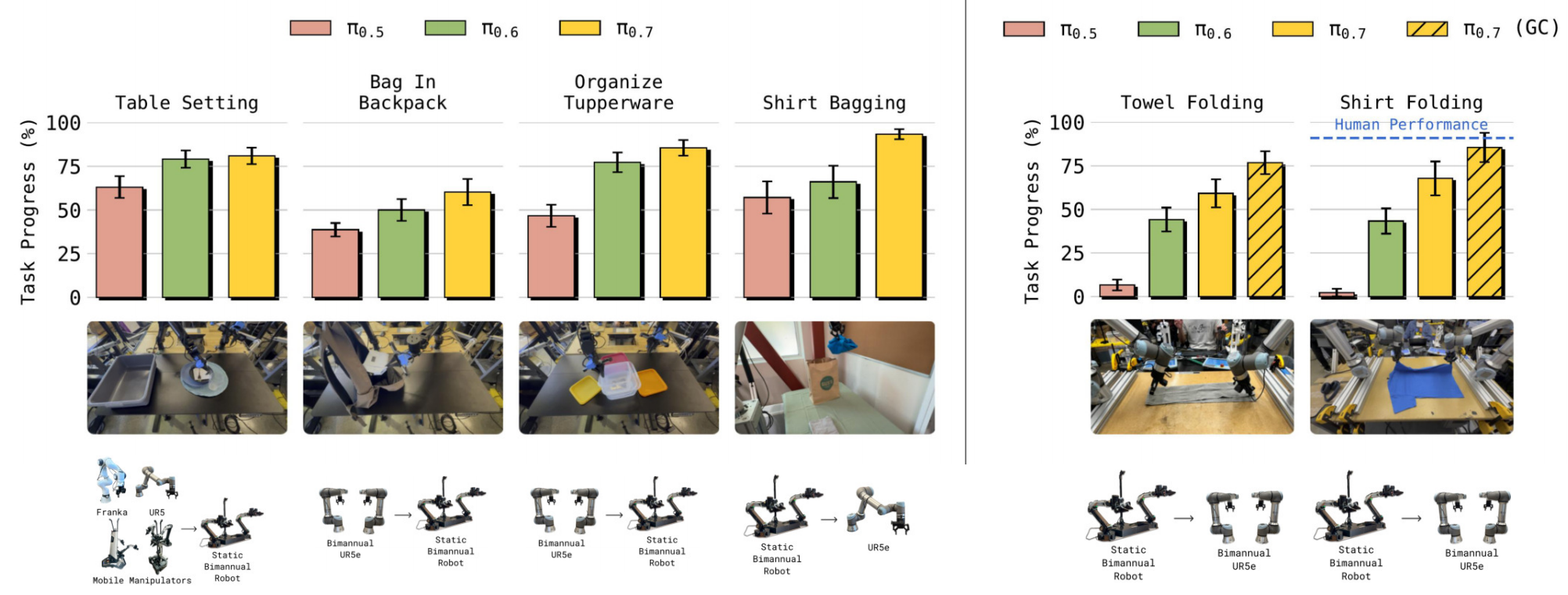
如下图所示,展示了 π₀.₇模型执行的两个典型长周期多步骤机器人具身操作任务
- Take Out Trash(倒垃圾任务)
- Toasting a Bagel(烤贝果任务)

分享完成~
相关文章推荐:
《VLA 系列》分析 Ψ₀ | Psi0 | 通用人形机器人 | 移动 + 操作
《VLA 系列》复现 Ψ₀ | Psi0 | 通用人形机器人 | 移动操作模型
《VLA 系列》Humanoid Everyday | 人形机器人 | 开源数据集
《VLA 系列》π0.5 | 流匹配 | 分层推理 | VLA
《VLA 系列》复现 π0.5 | 数据采集 | 模型微调 | DROID
《VLA 系列》复现 π0.5、π0-FAST、π0 | 环境搭建 | 模型推理
《VLA 系列》π0 | 流匹配 | 开山之作 | VLA
【VLA 系列】 πRL | 在线强化学习 | 流匹配 | VLA
《VLA 系列》SimpleVLA-RL | 端到端 在线强化学习 | VLA
《VLA 系列》HumDex | 人形机器人 | 全身灵巧操作 | 遥操作系统 | 数据采集

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)