AI核心知识128—大语言模型之 向量嵌入(简洁且通俗易懂版)
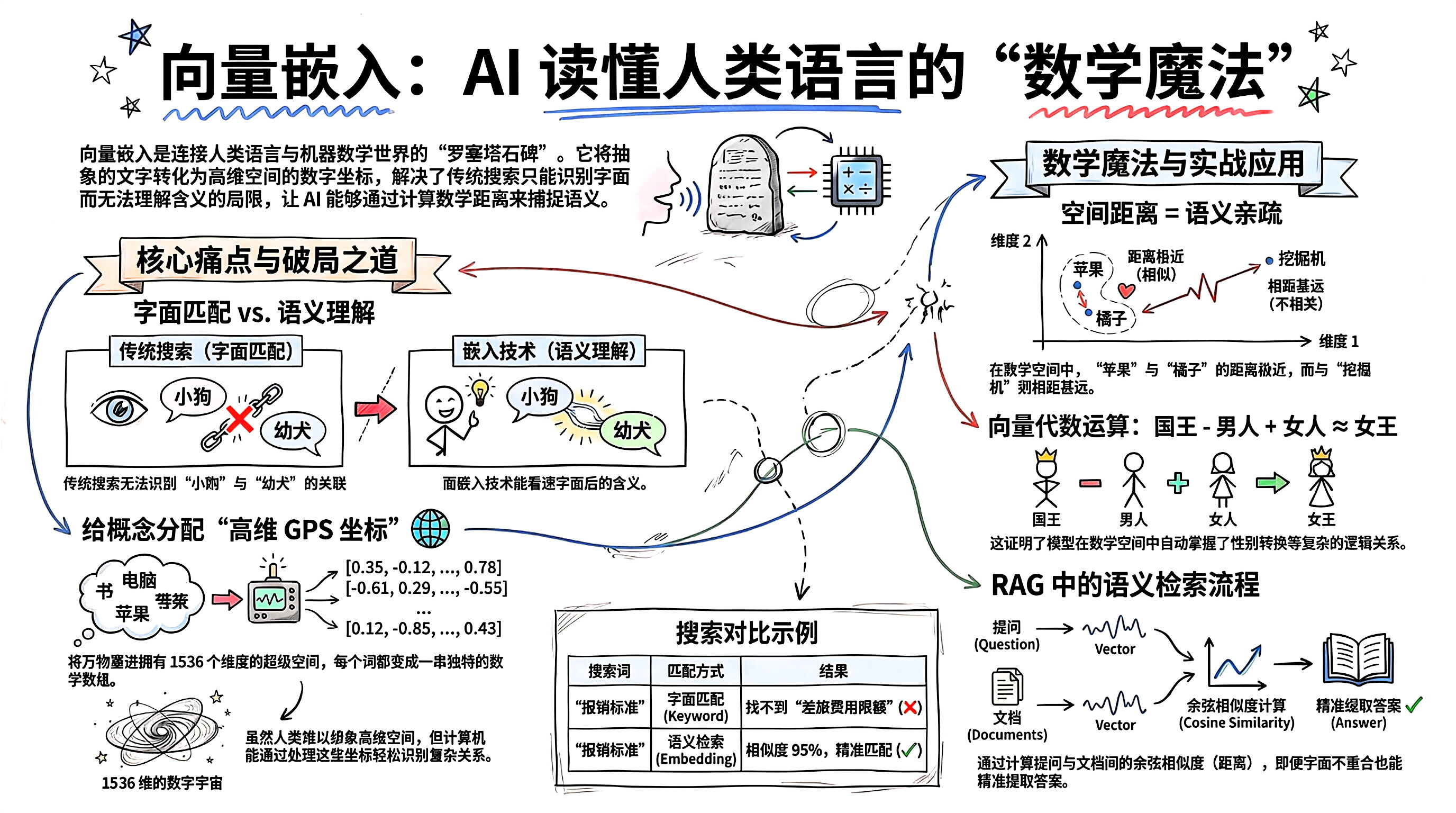
Vector Embedding (向量嵌入 / 词向量) 是整个人工智能领域(特别是自然语言处理)的“罗塞塔石碑” 。
如果说我们人类的通用语言是汉语或英语,那么计算机的通用语言只有一种:数字。
Vector Embedding 就是将人类复杂、抽象、充满多义词的语言,翻译成计算机能直接进行加减乘除的“数学坐标”的极致魔法。
正是有了它,上一条聊到的 RAG 才能做到“懂你意思”,而不是死板地“匹配关键字”。
1.🛑 核心痛点:为什么传统的搜索“搜不到”?
在 Embedding 出现之前,所有的搜索引擎和数据库都在用“字面匹配” (Keyword Matching) ,比如大家熟悉的 Ctrl+F 或者 BM25 算法。
-
尴尬的场景:
-
你搜:“小狗”。
-
文档里写的是:“幼犬” 或者 “Puppy”。
-
结果:传统系统会告诉你“找不到”。因为从计算机的视角来看,“小”和“幼”的字形完全不同,代码的 ASCII 码也毫不相干。它根本不知道这两个词是一回事。
-
我们需要一种技术,让计算机明白“词语背后的含义”,而不是盯着字形看。
2.💡 破局之道:给概念分配“高维 GPS 坐标”
科学家想出了一个绝妙的办法:把全宇宙所有的概念,都塞进一个拥有上千个维度的“超级空间”里,给它们挨个分配坐标。
-
一维空间 (一根线):如果只有一个维度“温度”,那么“冰”在左边,“火”在右边。
-
二维空间 (一张纸):加上一个维度“是否是活物”。“冰”和“火”在下方,“企鹅”和“骆驼”在上方。
-
高维空间 (大模型的宇宙):像 OpenAI 的
text-embedding-3-small模型,拥有 1536 个维度。虽然人类的大脑无法想象 1536 维的空间长什么样,但计算机可以轻松处理。
当我们把一个词放进这个空间时,它就会变成一串包含 1536 个小数的数组(这就是向量 Vector),比如:
[0.12, -0.45, 0.89, ... (还有 1533 个数字)]
3.📏 奇妙的数学魔法:距离即“懂你”
当所有的词语都变成了空间里的坐标点后,奇迹发生了:在这个空间里,意思越相近的词,它们之间的物理距离就越近!
-
“苹果”和“橘子”的坐标可能紧挨在一起(因为它们都是水果)。
-
“苹果”和“电脑”的坐标可能在另一个方向也有交集(因为它们都是科技品牌)。
-
而“苹果”和“挖掘机”的坐标则十万八千里。
更令人震撼的是,这些坐标之间甚至可以进行代数运算。自然语言处理界有一个极其著名的公式,完美展示了模型是如何学到“逻辑”的:
$$V(\text{国王}) - V(\text{男人}) + V(\text{女人}) \approx V(\text{女王})$$
(V 代表该词组对应的向量坐标)
这意味着,计算机在阅读了海量文本后,自动在那个 1536 维的空间里,发现并固定了“性别转换”这个维度的方向和距离!
4.⚙️ 它在 RAG 中是如何大显神威的?(语义检索)
回到我们上一个关于 RAG 的悬念:系统是怎么知道“报销标准”和“差旅费用限额”是同一个意思的?
-
文本向量化:系统先把公司制度里的“差旅费用限额为 500 元”这句话,扔进 Embedding 模型,变成了一个 1536 维的坐标点。
-
提问向量化:你问“报销标准是多少?”,系统也把这句话扔进 Embedding 模型,变成另一个坐标点。
-
计算距离 (Cosine Similarity):系统在多维空间里一量,发现这两个坐标点的距离极其接近(相似度高达 95%)。
-
提取答案:系统瞬间明白,“哦!虽然这两个句子连一个重合的字都没有,但它们在数学宇宙里指代的是同一个地方!”于是,它把正确答案揪出来发给了大模型。
这就是传说中的语义检索 (Semantic Search)。
总结
Vector Embedding 就是为人类知识绘制的星图。
它把语言中极其微妙的“语义”、“情感”和“逻辑关系”,全部浓缩成了冰冷的浮点数矩阵。大模型之所以显得这么有文化、懂人情世故,正是因为它们在训练的第一天,就已经把整个世界的规律,死死地钉在了一个高维的数学空间里。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 2
2 0
0- 0



 已为社区贡献27条内容
已为社区贡献27条内容

所有评论(0)