TASK03 | Reasoning Kindom 从符号到向量——表示空间的第一次解放
文章目录
https://ai-safety-book.github.io/index.html
https://ai-data-model-safety.github.io/
https://github.com/datawhalechina/reasoning-kingdom
https://github.com/lizixi-0x2F/CocDo
一、那句话
把”国王”减去”男人”加上”女人”,你得到”女王”。这是推理还是算术?
2013 年,Tomas Mikolov 在一篇论文里写下了一个方程,后来这个方程被引用的频率,大概超过了那个时代任何一篇 NLP 论文:
二、符号的问题,重说一遍
在上一章,我们看到符号 AI 的核心困境:知识必须被显式地写出来,而世界的知识写不完。
但还有另一个问题我没有强调,那就是符号的语义是外挂的。
在专家系统里,"是哺乳动物" 这个字符串,对机器来说只是一个 token——一个无法进一步分解的原子。它不知道”哺乳动物”和”动物”的关系,不知道”哺乳动物”和”爬行动物”有多近,不知道”猫”比”鲸鱼”更像是一个典型的哺乳动物。
所有这些关系,都需要被显式地写进规则。
IF 是哺乳动物
THEN 是动物 [R_base_1]
IF 是哺乳动物
AND 不是鲸类
THEN 通常有腿 [R_mammal_legs]
每一种关系,都要对应一条规则。而关系是无限的,规则写不完。
这个问题的根源在于:符号系统用离散的 token 表示概念,而概念之间的关系是连续的、是有程度的、是嵌套的。“猫”和”狗”之间的距离,不能被离散的 If-Then 规则捕获——你只能说”猫是哺乳动物,狗是哺乳动物”,但你说不出”猫比蛇更接近狗”。
向量表示解决了这个问题。不是完全解决,但解决了核心的部分。
=======================
三、分布假设:意义藏在邻居里
向量表示的思想,最早可以追溯到语言学家 J.R. Firth 在 1957 年说的一句话:
“你可以通过它交往的朋友来认识一个词。”(You shall know a word by the company it keeps.)
这个直觉,叫做分布假设(Distributional Hypothesis):词的意义,由它在语料库里的上下文分布所决定。
出现在相似上下文里的词,意义相近。“猫”和”狗”都频繁出现在”我养了一只___“、”给它喂食”、“它叫了”这样的上下文里,所以它们在语义上是近邻。
这个直觉可以被机械化。你建立一个矩阵,行是词,列是上下文词(或文档),每个格子记录共现次数(或其变换)。然后,每一行就是那个词的一个向量表示。意义相近的词,对应的向量就在高维空间里彼此接近。
这是向量表示的原始版本,叫做分布语义模型(Distributional Semantic Models,DSM),从 1990 年代开始就有了。它有效,但有两个问题:【维度太高(可能有几十万维),向量非常稀疏(大多数格子是零)。】
分布语义模型(Distributional Semantic Models,DSM) 是一种基于分布假设(Distributional Hypothesis) 构建的语义表示方法,核心是用词语的【上下文分布特征】来定义其语义,并将语义转化为可计算的向量形式。
1. 确定上下文范围
先定义 “上下文” 的边界,常见方式有两种:
词窗口:以目标词为中心,取左右固定数量的词作为上下文(比如窗口大小为 2,目标词是 “猫”,句子 “我 养 了 一只 猫 它 很 可爱” 的上下文就是 “一只”“它”)。
文档 / 句子:以整个文档或句子作为目标词的上下文(比如 “猫” 出现在 “宠物饲养指南” 文档里,这个文档的所有词都是它的上下文)。
2. 构建共现矩阵
矩阵的行:语料库中的所有目标词(比如 “猫”“狗”“鸟”)。
矩阵的列:所有可能的上下文词(比如 “养”“喂”“飞”)。
矩阵的值:目标词与上下文词的共现次数(或经过变换的数值,如 TF-IDF、点互信息 PMI)。
举个简化例子:
| 目标词 | 养 | 喂 | 飞 |
|---|---|---|---|
| 猫 | 15 | 12 | 0 |
| 狗 | 14 | 11 | 0 |
| 鸟 | 2 | 1 | 20 |
3. 生成词向量
共现矩阵的每一行,就是对应目标词的向量表示。比如 “猫” 的向量就是 [15, 12, 0],“狗” 是 [14, 11, 0],“鸟” 是 [2, 1, 20]。向量之间的相似度(比如余弦相似度)可以直接对应语义相似度 ——“猫” 和 “狗” 的向量更接近,语义也更相近。
分布语义模型是一类把词意义表示为向量的方法,核心思路是:建一张"词×上下文"的大表,记录每个词和哪些词经常一起出现,然后把这张表的每一行当作该词的向量。
- 高维:如果语料里有 10 万个不同的词,矩阵就有 10 万列,每个词的向量就是 10 万维的——非常长
- 稀疏:大多数词对很少或从不共现,所以矩阵里大部分是 0,存储极浪费
Word2Vec(Mikolov 2013)解决了这个问题:不直接建矩阵,而是训练神经网络来隐式地压缩这种共现信息到 100-300 维的稠密向量里。
DSM 的局限性
这是早期的词向量模型,存在两个关键问题:
4. 维度灾难
上下文词的数量等于矩阵的列数,语料库越大,列数越多(可能达到几十万甚至上百万维),向量的存储和计算成本极高。
5. 向量稀疏性
一个词只会和少数上下文词共现,矩阵中绝大多数位置的值都是 0,导致向量包含的有效信息少,计算效率低,语义表示的准确性也受限。
Word2Vec:用预测来压缩语义
Word2Vec 不构建共现矩阵。它训练一个神经网络,任务是:给定一个词,预测它的上下文词(Skip-gram),或者给定上下文词,预测中心词(CBOW)。
Word2Vec 有两个变体,区别在于预测任务的方向:
- Skip-gram:【输入中心词,预测它周围的词】。例如句子"我喜欢吃苹果",输入"吃",预测"喜欢"“苹果”。适合小数据集,对低频词效果更好。
- CBOW(Continuous Bag of Words):【输入周围词,预测中心词】。输入"喜欢"“苹果”,预测"吃"。训练速度更快,适合大数据集。
两种方式都只是手段,真正的目标是学到词的向量表示(嵌入)。训练完成后,预测头被丢弃,只保留词嵌入矩阵。
这听起来很平凡。但副产品是重点。
当你训练这个网络时,你把每个词映射到一个低维向量(通常是 100 到 300 维)。为了让预测任务完成得好,这些向量必须编码词的某种本质——因为只有理解了词与词之间的关系,才能准确预测哪些词会共同出现。
网络训练完成之后,你扔掉预测头,只保留【词嵌入矩阵】。这就是你的词向量。
这里有一个深刻的事情值得停一下想:
你没有教网络”国王”和”女王”的关系。你没有告诉它任何语义规则。你只是让它预测文本序列。然后,在它学会预测之后,你发现”国王-男人+女人≈女王”这样的关系自发地涌现了。
为什么会这样?因为在自然语言里,“国王”出现的地方,“女王”也会以某种平行的方式出现——只是出现在相应的女性语境里。网络为了预测准确,必须把这种平行关系编码进向量里。“皇室”是一个语境轴,“性别”是另一个语境轴。这两个轴在向量空间里对应两个方向。减去”男人”的向量,再加上”女人”的向量,就是在性别轴上做了一次移位。
语义,从分布中涌现了。
五、几何中的浅层逻辑
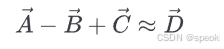
国王 - 男人 + 女人 ≈ 女王 巴黎 - 法国 + 日本 ≈ 东京 走 - 走 + 游泳 ≈ 游泳 (或者:walk - walked + swam ≈ swim,过去式关系也被编码了)
每一个类比,都对应向量空间里的一次平移。“男人→女王”和”国王→女王”之间的差,是一个固定的向量方向,代表”性别维度上的移动”。
这是一种非常干净的几何结构。语义关系,变成了方向。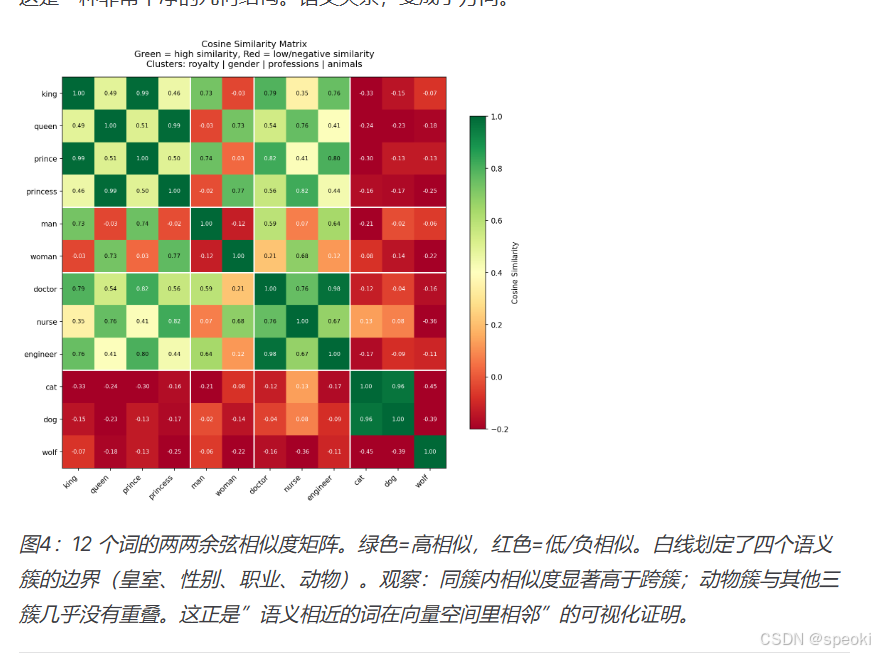
六、向量的偏见:语料即世界观
Word2Vec 学到的不是语言的真相,而是语料库的统计规律。而语料库,是人类写作的产物——它带着人类的偏见、历史的偏见、文化的偏见。
这不是一个边缘问题,这是分布假设的核心代价。
Bolukbasi et al. (2016) 的实验
他们发现,Google News 训练的 Word2Vec 里: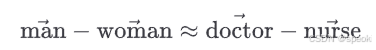
“男人之于医生,如同女人之于护士”——这个类比在向量空间里成立,因为它在训练语料里统计上成立。
更直接的测试: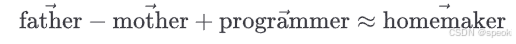
不是"女程序员",而是"家庭主妇"。
这不是算法的 bug,这是算法正确地学到了语料库中的统计规律。Bug 在于:我们误把统计规律当成了语义真相。
偏见来自哪里?
分布假设说:词的意义藏在它的邻居里。但如果邻居的分布本身是有偏的——
- 新闻报道里,“CEO"的邻居词更多是"他的决定”,而不是"她的决定"
- 历史文本里,"科学家"更多和男性名字共现
- 小说里,情感词的性别分布不均匀
Word2Vec 忠实地学到了这些规律。它是一面镜子,照出的是语料,不是世界。
这揭示了分布假设的一个根本性限制:
- 向量空间学到的是**描述性的(descriptive)统计规律,而推理需要的是规范性的(normative)**真值。"
- 在语料中,X 和 Y 经常共现"不等于"X 和 Y 在世界上有因果关系",也不等于"这种共现是正确的"。
你可以对词向量做去偏见处理(Bolukbasi 的论文就提出了一种线性投影方法),但这是在亡羊补牢——治标不治本。根本问题是:从统计相关性出发,无法抵达语义的真值。
这个限制,在 Transformer 和大语言模型时代依然存在。【规模更大的语料,偏见更大,覆盖也更广】——但分布假设的底层逻辑没有变。
七、类比的幻觉
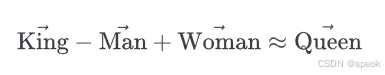
让我们拆开来想。
这个等式成立,意味着在词向量空间里,“国王”和”男人”的向量差,近似等于”女王”和”女人”的向量差。
这是什么?这是一个关于向量偏移方向一致的陈述。是几何上的规律性,不是逻辑上的推理。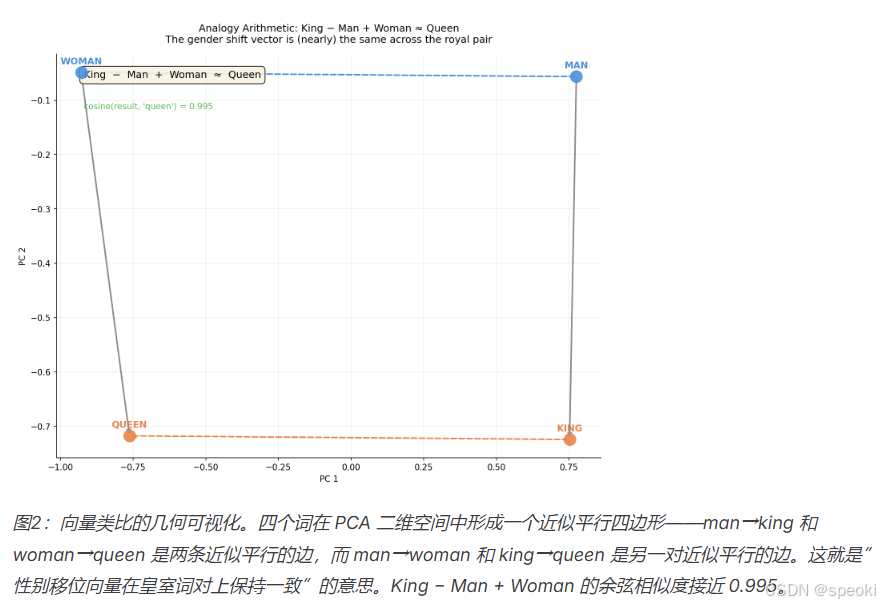
在逻辑里,推理需要规则 + 事实 → 结论。“所有国王都是男人”加上”伊丽莎白是女王”,推出”伊丽莎白不是国王”——这是推理,因为有传递性,有变量绑定,有量词。
向量算术没有这些。它只是在说:这些词在语义空间里的相对位置,展现出某种平行结构。
更重要的是,这个等式在很多情况下不成立。
Fournier et al.(2020)系统性地分析了类比测试的局限性,发现:所谓的”类比等式”大量依赖于一个取巧的评估方式——在答案中排除了输入词本身,而最近邻往往就是输入词之一。【改变评估方式】之后,大量”类比能力”的【统计结果】显著下降 → [Fournier et al., 2020, arXiv:2010.03446]。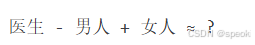
在某些训练语料上,你得到的不是”女医生”,而是”护士”。
因为在那些语料里,“医生”更频繁地和男性上下文共现,“护士”更频繁地和女性上下文共现。模型学到的不是”医生”这个职业的中立含义,而是它在特定语料里的统计偏见。
【向量表示不捕获真理。它捕获语料的统计分布。语料里有偏见,向量里就有偏见。这不是 bug,这是它的工作原理。】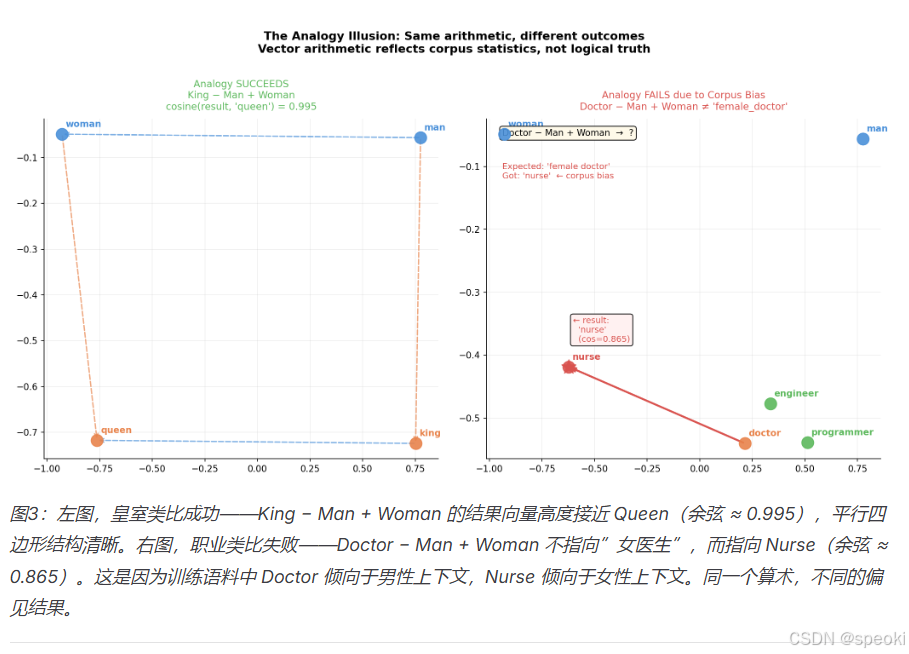
分布假设的上限
让我们更深入地想一下分布假设的边界在哪里。
分布假设说:意义由上下文分布决定。这在大量情况下是对的。但它意味着:如果两个词在文本里的上下文分布完全相同,模型会认为它们意思相同。
【“我喜欢猫”和”我喜欢狗”】——这两句话的结构完全对称,所以”猫”和”狗”在分布上高度相似。确实,它们在语义上很接近,模型是对的。
但是:
“地球绕太阳转”和”太阳绕地球转”
这两句话,如果你只看词的分布,“地球”和”太阳”会出现在非常相似的上下文里——它们经常出现在关于天文、引力、公转的句子里。但这两句话,一个是真的,一个是假的。
分布语义模型没有关于真值的概念。它不知道哪些命题是真的,哪些是假的。它知道的,是哪些词出现在哪些上下文里——这是一种统计规律,不是关于世界的因果模型。
这就是为什么向量表示尽管在很多任务上表现良好,却没有解决【推理问题】。它解决的是表示问题:用一种更丰富、更连续的方式来表示概念,使得相似的概念在几何上相近。但”相近”不等于”有逻辑关系”,“统计共现”不等于”因果相关”。
Wittgenstein 说过一句话,在这里显得很应景:语言的意义是它的用法。分布假设抓住了这个直觉的一部分——词的意义确实体现在它的用法里。但用法是【统计性的】,而理解是不是也是统计性的?这是个悬而未决的问题。
九、从词向量到句子,代价的累积
Word2Vec 给出的是静态词向量——每个词对应一个固定的向量,不管它出现在什么上下文里。
“银行”这个词,在”我去银行取钱”和”河岸(bank)上长满了野花”里,静态词向量是同一个。这是它的根本局限之一。
ELMo(2018)和后来的 BERT(2018)引入了上下文化词向量——同一个词在不同上下文里有不同的向量表示。这是一个重大进步。但它带来了另一个代价:你不再有一个简洁的、可以离线查表的词向量,你需要每次都跑完整个网络。
静态词向量(如 Word2Vec):每个词只有一个向量,不管它出现在哪里。"苹果"不管是指水果还是 Apple 公司,向量都一样。
上下文化词向量(ELMo、BERT):同一个词在不同句子里有不同的向量,因为整个句子都被送入网络,词的表示受上下文影响。
- ELMo(2018,Allen AI):用双向 LSTM 生成上下文敏感的词向量,作为特征给下游任务用
- BERT(2018,Google):用 Transformer Encoder 做双向语言模型预训练,fine-tune 到下游任务
代价:不能再查表,每次推理都要跑完整网络,计算量大幅提升。这是精度与效率之间永恒的权衡。
词的意义可以被向量编码,但句子的意义依赖于结构——谁是主语,谁是宾语,动词的论元关系。纯粹的向量运算,没有捕获结构。
“猫咬了狗”和”狗咬了猫”,如果你对词向量做平均,你会得到几乎相同的句子向量——因为用的是同样的三个词。但这两句话描述的是完全相反的事件。
probs = F.softmax(logits, dim=-1)
把 logits 转成 0~1 之间的概率,总和 = 1。
idx_next = torch.multinomial(probs, num_samples=1)
多项式采样:谁概率大,谁就更容易被抽中。
缩放 logits(温度控制)
logits = logits / temperature
人话解释:
temperature = 1 → 正常概率
temperature < 1 → 概率变得更尖锐,模型更 “自信、保守”
temperature > 1 → 概率变得更平滑,模型更 “随机、有创意”
模型输出logits
↓
温度缩放(控制随机)
↓
top-k 过滤(删掉垃圾选项)
↓
softmax 转概率
↓
按概率随机抽1个token
v[:, [-1]] 到底是什么
v, _ = torch.topk(logits, min(top_k, logits.size(-1)))
#v = top-k 个最高分组成的数组。
logits[logits < v[:, [-1]]] = -float('Inf')
#[:, [-1]] = 取每一行的最后一个元素
多项式采样: 谁概率大,谁更容易被抽中
你有一堆选项,每个选项有中奖概率,multinomial 就是按概率随机抽一个。
把模型输出的分数 → 过滤掉不靠谱的 → 按概率抽一个 → 输出最终决策
idx_next = torch.multinomial(probs, num_samples=1)
probs = 概率分布
num_samples=1 = 抽 1 个
输出 = 被抽中的 token ID
# 计算对数概率:使用log_softmax避免数值不稳定
log_probs = F.log_softmax(logits, dim=-1)
# 为当前候选序列生成 num_beams 个扩展序列
for k in range(num_beams):
# 选择第k个候选token
token = top_indices[:, k:k+1] # token ID
log_prob = top_log_probs[:, k] # 对应的对数概率
# 扩展序列:将新token添加到当前序列末尾
new_beam = torch.cat([beam, token], dim=1)
# 更新累积分数:原序列分数 + 新token的对数概率
new_score = beam_scores[beam_idx] + log_prob.item()
# 保存新的候选序列和分数
new_beams.append(new_beam)
new_scores.append(new_score)
# 筛选最佳候选:从所有新生成的候选中选择分数最高的 num_beams 个
# 按分数降序排序,获取索引
sorted_indices = sorted(range(len(new_scores)), key=lambda i: new_scores[i], reverse=True)
# 选择前 num_beams 个最佳候选
beams = [new_beams[i] for i in sorted_indices[:num_beams]]
beam_scores = [new_scores[i] for i in sorted_indices[:num_beams]]
# 停止条件检查:检查最佳序列是否以停止token结尾
if stop_id is not None and beams[0][0, -1] == stop_id:
break
- 禁用 autograd 梯度计算
生成文本不需要反向传播,关掉更快。 - 节省大量显存 / 内存
不保存计算图,内存占用大幅下降。 - 加速推理速度
少做很多计算,推理速度明显提升。
@torch.inference_mode()
是 PyTorch 的一个装饰器,作用:开启推理模式,关掉梯度计算,让模型跑得更快、更省内存。
专门用在不训练、只预测 / 生成文本的时候,比如你这段代码里的 generate_super 文本生成函数。
模型训练时,PyTorch 会自动做两件事:
计算梯度(用来更新模型参数)
保存计算图(占用大量内存)
但生成文本的时候,完全不需要梯度!
所以 @torch.inference_mode() 就是告诉 PyTorch:
现在不训练,只推理!别算梯度,别存计算图,给我提速省内存!
和旧版 @torch.no_grad() 的区别
你可能见过 @torch.no_grad(),它也是禁用梯度。
简单结论:
- @torch.inference_mode() = 升级版、更快、更推荐
- @torch.no_grad() = 旧版,现在基本被替代
官方推荐:推理一律用 inference_mode ()
向量表示的思想,最早可以追溯到语言学家 J.R. Firth 在 1957 年说的一句话:
“你可以通过它交往的朋友来认识一个词。”(You shall know a word by the company it keeps.)
这个直觉,叫做[分布假设](Distributional Hypothesis):词的意义,由它在语料库里的上下文分布所决定。
十、一个小小的停顿
从符号到向量,这是一次真正的范式跃迁。它解决了符号 AI 的一个核心问题:语义的表示。概念不再是无意义的原子,它们在向量空间里有了位置,有了距离,有了方向。相似的概念相互接近,关系被编码成方向上的偏移。
这带来了真实的能力:语义检索、类比推理(某种形式的)、语义聚类、迁移学习的基础。
第一,它捕获统计规律,不捕获因果结构。语料里有偏见,向量里就有偏见。语料里有相关性,向量里就有相关性。但相关性不是因果,分布不是真值。
第二,它没有组合性。词向量的简单线性组合,无法捕获句子的结构语义。“猫咬狗”和”狗咬猫”对词袋模型是相同的,这是根本性的缺陷。
第三,类比等式看起来像推理,但不是推理。它是几何上的平行结构,不是逻辑上的传递推导。在它不成立的时候(比如带有社会偏见的类比),它会安静地给出一个错误的答案,没有任何警告。
十一、还有一个更深的问题
分布假设的深层预设是:语言能够承载意义,而且意义可以从语言使用模式中被提取。这是一个可以被质疑的预设。
John Searle 的汉字房间论证(1980)是这个方向上最著名的攻击:一个不懂中文的人在房间里,按照规则手册处理汉字符号,输出符合语法的汉字回复——从外部看他好像懂中文,但他完全不知道那些符号的意义。
词向量模型做的事情,在某种意义上很像这个:它从大量文本里提取出极其精细的统计模式,这些模式在很多任务上产生了正确的行为。但它是否”理解”了那些词的意义?
这个问题没有简单的答案,因为我们首先需要定义什么叫”理解”。
但有一个更实际的测试:【分布偏移】。如果你把模型放到训练分布之外,让它处理训练语料里从未见过的组合方式,它的行为会怎样?如果它的表现崩塌,你有理由怀疑它只是记住了分布,而不是真正理解了语言。
这是第五章的核心问题。现在,先记住这个悬念。
向量捕获了相似性,但不捕获因果。下一章,我们将进入高维空间的几何——流形假设揭示了为什么数据不是随机分布的。
悬而未决
- 类比等式
vec(King) - vec(Man) + vec(Woman) ≈ vec(Queen)是推理的证据,还是统计的巧合?它对某些类比成立,对另一些类比失败——这种不一致性告诉了我们什么?
这个经典类比等式既是统计规律的体现,也具备有限的推理价值,但绝非真正的逻辑推理 —— 其本质是【文本共现模式】的量化映射,而非对 “性别 - 身份” 关系的抽象理解。
词向量模型(如 Word2Vec)的训练目标是最大化上下文词的共现概率。在自然语言文本中: - King 常与 “君主、王室、统治” 等词共现,且语境中高频隐含 “男性” 属性;
- Queen 则与相似的 “君主、王室” 词共现,但隐含 **“女性” 属性 **;
- Man 和 Woman 是一对强对立的性别标签,其向量差 vec(Woman)-vec(Man) 恰好对应文本中 “女性化 - 男性化” 的语义偏移方向。
因此,vec(King)-vec(Man)+vec(Woman) 本质是用性别偏移修正身份属性,其结果接近 vec(Queen) 是文本分布统计规律的必然结果。
该类比仅对高频、强结构化的语义关系成立,对以下情况会失效:
- **低频概念:**例如 vec(Emperor)-vec(Man)+vec(Woman)≈vec(Empress) 可能不成立,因为 Emperor/Empress 在语料中的出现频率远低于 King/Queen,共现模式不稳定;
- **无明确对应关系的概念:**例如 vec(Doctor)-vec(Man)+vec(Woman) 无法得到一个精准的对应词(没有 “女性医生” 的专属词汇);
- **语境依赖的语义:**例如 vec(Father)-vec(Man)+vec(Woman)=vec(Mother) 成立,但 vec(Father)-vec(Man)+vec(Woman)=vec(Aunt) 不成立 —— 模型无法区分 “亲子关系” 与 “亲属关系” 的逻辑差异,只能依赖共现频率。
不一致性的启示
这种 “部分成立、部分失败” 的特性,直接暴露了分布语义模型的核心矛盾:
模型学到的是文本中高频出现的 “表层语义关联”,而非人类的 “深层逻辑关系”;
类比的有效性完全取决于语料中语义关系的结构化程度—— 语料中越多人用固定模式表达某类关系,模型的类比结果就越准确;反之则失效;
这也说明:词向量的 “类比推理” 本质是统计相似度匹配,而非真正的推理能力 —— 它不理解 “国王 - 男人 = 女王 - 女人” 的逻辑等式,只是恰好拟合了文本中的共现规律。
- 分布假设的边界在哪里?存在不能从文本分布中被学到的意义吗?颜色?疼痛?身体感知?

颜色、疼痛、身体感知:为何无法被文本分布完全建模?
这类具身认知相关的意义,是分布假设的 “天然盲区”,原因有三:
-
意义的具身性:根据具身认知理论,颜色、疼痛的意义源于身体与环境的互动(如视网膜锥体细胞对波长的响应、神经末梢对损伤的反馈),而非语言符号的关联。文本中没有 “体验” 的编码,只有对体验的语言描述—— 模型无法从 “疼痛→止痛药” 的共现中,学到疼痛本身的不适感。
-
描述的模糊性与主观性:人类对身体感知的语言描述是间接且个性化的。例如 “红色” 的描述是 “暖色调、像火焰”,但无法传递 “红色在视网膜上的激活模式”;“疼痛” 的描述是 “刺痛、灼痛”,但无法传递每个人独特的疼痛阈值和感受。文本分布只能捕捉这些【模糊描述的共现】,而非感知本身。
-
缺乏跨模态的锚定:文本是单一模态的符号系统,而【颜色、疼痛是多模态的体验(视觉、触觉、生理信号)】。词向量模型没有视觉传感器、没有痛觉神经,无法将文本符号与跨模态体验锚定 —— 这是纯文本分布模型无法突破的 “模态壁垒”。
-
词向量捕获了社会偏见——这是它的缺陷,还是它的功能?删除了偏见的词向量,是否也丢失了某些真实的世界结构?
-
社会偏见:是分布假设的必然产物,既是缺陷也是 “文本忠实性” 的体现
- 为什么是缺陷?
从应用伦理角度,词向量中的社会偏见(如 vec(Doctor) 更接近 vec(Man),vec(Nurse) 更接近 vec(Woman))会放大现实中的性别歧视、种族歧视,导致 AI 系统做出不公平决策(如简历筛选模型优先推荐男性候选人)。这种偏见并非世界的 “真实结构”,而是历史文化中的刻板印象在文本中的沉淀。
- 为什么是功能?
从文本建模角度,词向量的偏见是对训练语料的忠实反映—— 语料中确实存在大量 “医生是男性、护士是女性” 的描述,模型只是客观捕捉了这种分布。如果我们的目标是分析文本中的社会文化现象(如研究性别刻板印象的演变),那么词向量中的偏见就是有价值的分析工具—— 这是它的 “功能” 所在。 -
去偏见的代价:会丢失部分 “文本中的真实结构”,但不会丢失 “世界的真实结构”
-
丢失的是 “文本中的刻板印象结构”:去偏见算法(如 Word Embedding Debiasing)的核心是消除词向量中与敏感属性(如性别)相关的冗余关联。例如,将
vec(Doctor)与vec(Man)的关联弱化,使其对性别属性中立。这个过程中,模型会丢失 “文本中医生与男性的强共现关系”—— 但这种关系是刻板印象的产物,并非 “医生” 这个职业的本质属性。 -
不会丢失的是 “概念的核心语义结构”:好的去偏见算法会保留词向量的核心语义。例如,去偏见后
vec(Doctor)依然会与vec(Hospital)vec(Treatment)强相关,只是不再偏向vec(Man)。这些核心关联对应世界的真实结构(医生在医院工作、负责治疗),不会因去偏见而丢失。 -
关键前提:去偏见的目标是消除 “无关的偏见关联”,而非 “消除所有敏感属性关联”。例如,对于
vec(King)-vec(Man)+vec(Woman)=vec(Queen)这种有真实语义对应关系的性别关联,去偏见算法应予以保留 —— 否则会破坏模型的语义建模能力。 -
如果你用纯粹的噪声文本训练 word2vec,你会得到什么?这个思想实验说明了什么?
1. 纯粹噪声文本的定义
“纯粹噪声文本” 指词的出现和共现完全随机—— 没有任何语法规则、没有任何语义关联,例如:apple cat sky water… cat tree book pen…,每个词的下一个词是随机选择的,不存在任何规律。
2. 训练结果:得到无意义的随机向量,不具备任何语义建模能力
向量的数值特征:所有词向量的相似度分布接近均匀分布—— 任意两个词的余弦相似度都接近 0,无法区分 “相关词” 和 “无关词”;
类比任务表现:vec(King)-vec(Man)+vec(Woman) 的结果会随机指向某个词,完全不具备类比能力;
语义聚类表现:无法将语义相关的词(如 apple/orange/banana)聚为一类,聚类结果完全随机。
3. 思想实验的核心启示
这个实验直接印证了分布假设的本质前提:语义的建模依赖于文本中稳定的共现规律。
自然语言文本的价值在于它并非随机噪声—— 人类的语言使用遵循语法规则和语义逻辑,词的共现模式是人类认知和社会文化的结构化体现。正是这种 “非随机性”,才让 Word2Vec 等模型能从共现中学习到语义关联。
词向量的 “语义能力” 并非模型本身的智能,而是训练语料中结构化信息的 “镜像”—— 有什么样的语料,就有什么样的词向量。如果语料没有任何结构(噪声),词向量就没有任何语义价值。
这也解释了为什么语料质量决定模型上限:低质量、充满噪声的语料,训练出的词向量语义能力会显著下降 —— 因为噪声破坏了文本中的稳定共现规律。
常见的知识表示方法有:逻辑规则(一阶谓词逻辑)、语义网络(概念 + 关系图)、框架系统(概念的属性模板)等 —— 这些都是为了让机器能像人一样做演绎推理。
在经历了一段深度的逻辑潜航后,《推理王国》(Reasoning Kingdom) 迎来了上线以来最重要的一次版本迭代。如果说上卷是在绘制地图,那么下卷:形式化演绎(Formal Deduction) 则是为整座逻辑大厦夯实最后的一块地基。
本次更新聚焦于 UTM 与 GTM 风格,通过 9 个核心章节,我们试图在数学的严密性与 AI 的可能性之间,架起一座跨越直觉的桥梁。
📜 下卷核心目录:从地基到涌现
第 14 章 | 形式系统: 彻底分离句法与语义,给推理一个纯粹的数学地基。
第 15 章 | 一致性与完备性: 直面哥德尔的两堵墙,理解“真”与“可证”之间的永恒裂隙。
第 16 章 | 线性逻辑与资源: 假如假设不再无限?当推理演变为精准的资源管理。
第 17 章 | 概率作为逻辑扩张: 拥抱 Cox 公理,将理性信念从二进制推向连续谱。
第 18 章 | 因果结构的形式化: 跨越 Pearl 的阶梯,从观测迈向干预与反事实的深处。
第 19 章 | 复杂度作为几何: 探讨推理的极限——为什么有些推导注定无法被加速?
第 20 章 | 启发式的形式合同: 为“差不多对”签下数学契约,定义近似推理的保证。
第 21 章 | 学习作为逆推断: 泛化的本质即压缩,重温 Kolmogorov 复杂度与 MDL 原理。
第 22 章 | 自指与涌现: 终章。当系统开始审视自身
推理王国的探险家们,兔狲编辑的新章节半个小时后推上 GH,但是在这个章节之前,我们玩一个思维游戏。
有一个栈数据结构(一个长得很像水井的数据结构,上开口,下不开口)。它有两个指针:β指针:永远指向栈底,固定不动。α指针:指向栈顶,可以上下移动。栈的操作很简单:push(x):把元素 x 压入栈顶,α指针上移一格。pop():弹出栈顶元素,α指针下移一格。
但有一个重要限制:负栈非法。
也就是说,α指针永远要在β指针的上面(或相等)。当 α = β 时,栈是空的;如果试图在空栈上执行 pop(),操作无效——α指针不动,程序会忽略这次操作。
现在,兔狲教授要问的不是算法题,而是一个动力学问题:给定一个很长很长——长到你无法想象——的 push 和 pop 操作序列,α指针的位置(相对于栈底的高度 h)会收敛(归于,稳定于某种特定的行为)吗?会不会停在一个特定的高度上?无论操作序列怎么排列,α指针最终会稳定在哪里?还是会在某个范围内震荡?
我们可以把栈高度 h 看作系统的“状态”,把操作序列看作驱动系统演化的“动力”。
定义一个“能量函数” V(h) = h(或者 V(h) = h²),它度量系统离某个参考状态有多远。
兔狲教授的提示:有了“负栈非法”的限制,h 有一个硬下界 0。空栈时 pop 无效,h=0 成了一个特殊状态。
请你思考:
- 在这样的约束下,α指针最终会收敛到哪里?是空栈(h=0)吗?还是其他高度?
- 如果你觉得会收敛,为什么?如果你觉得不会收敛,为什么?
- 你能构造一个操作序列,让 α指针永远不收敛吗?
- 能量函数 V(h) 应该怎么选,才能用来证明收敛性?
这个问题看似简单,但它触及了动力系统理论的核心:我们如何从系统的行为中“读出”它的稳定性?
答案在第23章“李雅普诺夫与推理系统的稳定性”中揭晓,但兔狲教授想先听听你的直觉。
因果自回归到底它是一个搜索过程吗?兔狲觉得它应该是一个搜索的轨迹问题,他把自己上一步的输出,然后输入到下一层。其实更多的是一个有限欧拉步上面的搜索问题。它有一个搜索的轨迹在上面。怎么说呢,我们已知每一层都有一个因果自注意力矩阵,它的矩阵动态拓扑传导过程长是多长呢,也就是说,序列中的某一个位置能影响到多远的位置。而不是看到多远的位置,我们说的是影响,这一点我们要搞清楚。兔狲阐释:应该就是这一个解码器堆栈的长度或者是深度。虽然说注意力机制是一个全局的,但是它的信息交合方式以及拓扑矩阵传导方式,是一个有限步数的传导过程。
这时候我们就会有一个关键洞察,我们看到了多远的信息和我们能影响到多远的信息其实是有区别的。这一点在因果自回归架构以及因果建模方面,很多小伙伴会混淆。
关于高维流形假设的那一章节。我们要引入一个观点,或者说具备一个基础意识,就是在极高维度下,所有的向量都趋于正交。在正交的背景下,也就是说所有的向量都是可以进行高质量的解耦的。我们可以用一个向量去刻画另一个向量的关系,而不是“粘合”的,依赖的。这个优点让高维嵌入表示学习成为可能。同时,我们指出专家系统是故意制造正交向量基,他在人为的基础上制造了有限维度的人工向量。这在表征的效率上是极其的低下的而在高维影状态空间下,所有的向量都趋于正交,不仅仅是因为表征枚举以及确定性规则的数据十分庞大。更是因为人造正交向量。具有表征的局限性,所以专家系统的失败,是可以科学地解释的
特别是正交这个概念,它在不同的语境下有不同的意思。同时也有一个词语很重要,叫做解耦。这一对亲兄弟在表征学习领域特别的火。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 6
6 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)