Redis 分布式集群方案介绍及对比
一、引言
如果你时间有限,先看这个结论。
Redis 集群方案的演进,本质上是一段“从中心化到去中心化”的历史。
-
Twemproxy:最轻量的代理方案,适合纯缓存场景(数据可丢)。它用一致性哈希做分片,但缺少高可用和在线扩缩容能力。选它的理由只有一个:极致简单。
-
Codis:代理方案的“完全体”。它用中心化的 Dashboard + Proxy 架构,实现了平滑扩缩容和完整的 Pipeline 支持。代价是依赖 ZooKeeper/Etcd 做协调,运维复杂度不低。适合已有大规模 Redis 部署、需要无缝迁移的团队。
-
Redis Cluster:官方原生方案,去中心化 P2P 架构,无单点故障。用 16384 个哈希槽做分片,Gossip 协议做元数据同步。它的设计哲学是“客户端智能,服务端简单”——MOVED 重定向机制把路由压力转给了客户端 SDK。适合新项目,也是未来的主流方向。
-
Sentinel + 主从复制:这不是集群方案,而是高可用方案。它解决了“主挂了怎么办”的问题,但解决不了“数据太多存不下”的问题。通常与 Cluster 配合使用,或单独用于中小规模部署。
一张表看清四者差异:
| 维度 | Twemproxy | Codis | Redis Cluster | Sentinel + 主从 |
|---|---|---|---|---|
| 架构模式 | 中心化 Proxy | 中心化 Proxy + Dashboard | 去中心化 P2P | 中心化监控 |
| 数据分片 | 一致性哈希 | 1024 个预分片 Slot | 16384 个哈希槽 | 无 |
| 水平扩展 | 需要重启 Proxy | 在线平滑迁移 | 在线槽迁移 | 不支持 |
| 故障转移 | 无 | 依赖 Sentinel | 内置自动切换 | Sentinel 自动切换 |
| 客户端要求 | 无,像连单机 | 无,像连单机 | 必须支持 Cluster 协议 | 必须支持 Sentinel |
| 多键操作 | 仅支持同 Slot | 迁移期间仍可用 | 仅支持同 Slot | 完全支持 |
| 运维复杂度 | 低 | 中 | 中 | 低 |
| 适用规模 | 中小 | 大 | 中小(≤1000 节点) | 单实例/小规模 |
下面我们深入拆解。
二、技术地基:主从复制与持久化
在谈集群之前,必须先把地基打好。无论是 Cluster 还是 Codis,都依赖 Redis 最底层的两个能力:主从复制和持久化。
2.1 主从复制:异步同步的代价
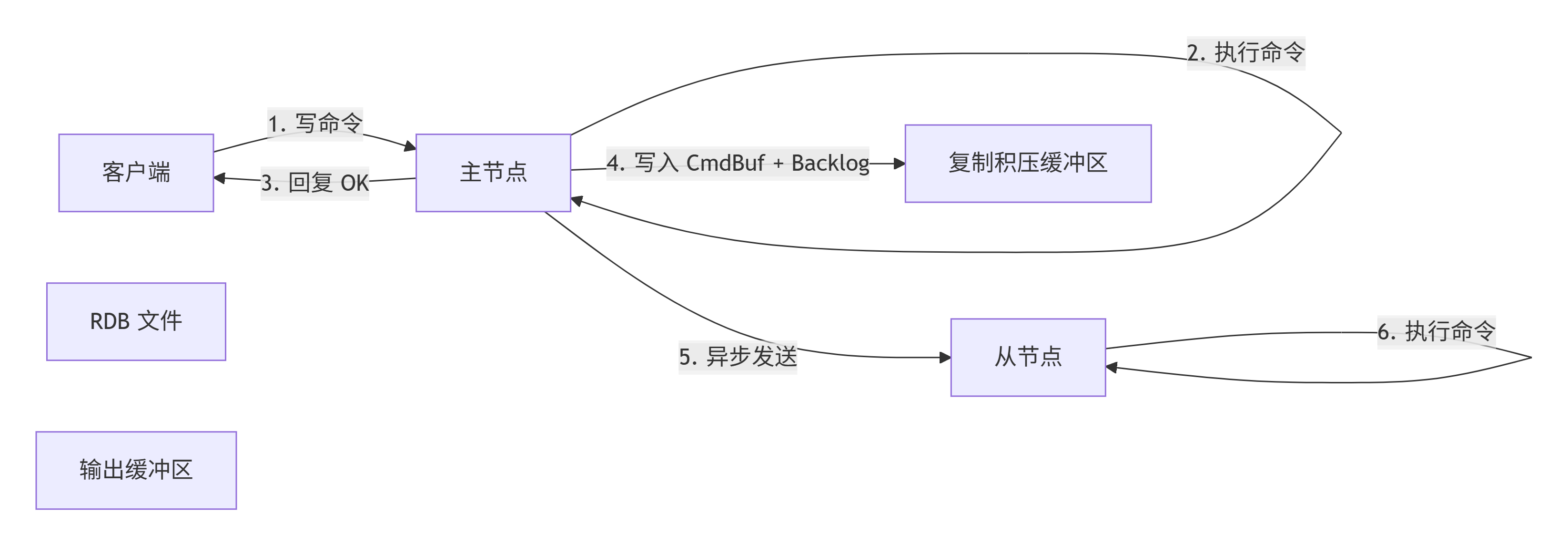
Redis 的主从复制是异步的。这意味着主节点写完数据、回复客户端“OK”之后,才会将命令传播给从节点。这也是为什么官方文档明确承认:总会存在一个时间窗口,期间可能丢失已确认的写入。
复制过程分为三步:
-
全量同步:从节点首次连接,主节点执行
BGSAVE生成 RDB 文件,发送给从节点。 -
命令传播:全量同步期间的新写入,暂存在主节点的输出缓冲区,RDB 传输完成后再补发。
-
增量同步:正常运行期间,主节点持续将写命令发给从节点。
这里有两个关键数据结构,面试和生产排查都绕不开:
-
复制缓冲区(client-output-buffer-limit):每个从节点独享,用于暂存待发送的命令。如果从节点消费慢,这个缓冲区会膨胀,触发
client-output-buffer-limit保护机制,主节点会强制断开慢从节点。 -
复制积压缓冲区(repl_backlog_buffer):全局共享的环形缓冲区,默认 1MB。它的作用是支持“断点续传”——从节点断线重连后,如果偏移量还在积压缓冲区内,就可以走增量同步,否则触发全量同步。
源码层面,主节点收到写命令后,调用链是 call() → propagate() → replicationFeedSlaves()。replicationFeedSlaves 会将命令同时写入所有从节点的输出缓冲区和全局的复制积压缓冲区。
这种异步设计的好处是主节点不阻塞,代价是数据可能丢失。这是 Redis 在性能与一致性之间的根本权衡。
2.2 持久化:RDB、AOF 与 fork 的代价
持久化是另一个地基。Redis 提供 RDB 快照和 AOF 日志两种方式。
RDB(快照) 的核心是 fork()。主进程 fork 出一个子进程,子进程利用 写时复制(Copy-On-Write, COW) 机制,读取父进程的内存页生成快照。fork 的代价不小——对于几十 GB 的实例,fork 可能耗时数百毫秒,期间主进程阻塞。这就是为什么生产环境建议预留足够内存、控制单个实例大小的原因。
AOF(日志) 是增量记录写命令。它的关键是 fsync 策略:
-
always:每条命令fsync,最安全但性能最差。 -
everysec:后台线程每秒fsync,最多丢 1 秒数据,生产推荐。 -
no:交给操作系统,不可控。
Redis 7.0 引入了 multi-part AOF,将 AOF 拆分为 base.aof(全量快照)和多个 incr-*.aof(增量日志),从根本上解决了老版本重写期间内存暴涨的问题。
三、分片之路:三种方案的架构对比
有了主从复制和持久化,单机可靠性有了保障。但数据量一大,单机内存就不够了。于是有了分片(Sharding)的需求。
分片的核心问题是:一个 Key 应该存到哪个节点?
三种方案给出了不同答案。
3.1 Twemproxy:最小可行产品
Twemproxy(又名 nutcracker)是 Twitter 开源的代理组件,设计哲学是“够用就好”。
┌─────────────┐
│ Client │
└──────┬──────┘
│ Redis Protocol
▼
┌─────────────┐
│ Twemproxy │ ◄── 单进程、单线程、epoll 驱动
└──────┬──────┘
│ 一致性哈希 (ketama)
▼
┌─────────────────────────┐
│ Redis │ Redis │ ... │
└─────────────────────────┘
它的数据分片采用 ketama 一致性哈希。客户端连接 Twemproxy,像连单机 Redis 一样发命令;Proxy 根据 Key 的哈希值,将请求路由到对应的后端 Redis 节点。
Twemproxy 的亮点:
-
连接复用:Proxy 与后端 Redis 维持长连接,大幅减少后端连接数。
-
Pipeline 支持:Proxy 会将多个请求批量发往后端,提升吞吐。
-
协议兼容:同时支持 Redis 和 Memcached。
但它的短板同样明显:
-
无高可用:后端 Redis 挂了,Twemproxy 只会将该节点剔除,没有自动故障转移。
-
扩缩容困难:一致性哈希在增删节点时,需要迁移数据,但 Twemproxy 不提供迁移工具。你只能停机,用脚本重新分布。
-
多键操作受限:同一请求中的多个 Key 必须落在同一个节点上。
Twemproxy 适合什么场景?纯缓存。数据可丢,挂了重启,不需要持久化和高可用。它的定位就是“轻量级分片代理”,不是“分布式数据库”。
3.2 Codis:代理方案的集大成者
Codis 是豌豆荚开源的方案,可以理解为“Twemproxy 的完全体”。它用 Go 语言重写了整套架构,补齐了 Twemproxy 缺失的所有能力。
┌─────────────┐
│ Client │
└──────┬──────┘
│ Redis Protocol
▼
┌─────────────────────────┐
│ Codis Proxy (多实例) │ ◄── 无状态,可水平扩展
└─────────────┬───────────┘
│
┌──────┴──────┐
▼ ▼
┌─────────────┐ ┌─────────────┐
│ Dashboard │ │ ZooKeeper/ │
│ (中心控制) │─│ Etcd │
└─────────────┘ └─────────────┘
│
▼ 管理
┌─────────────────────────┐
│ Codis Group (Redis 实例组)│
│ Group1 │ Group2 │ ... │
│ (主+从) │ (主+从) │ │
└─────────────────────────┘
Codis 的核心设计:
-
1024 个 Slot:Codis 将数据空间划分为 1024 个 Slot,比 Redis Cluster 的 16384 少,但原理类似。Key 通过 CRC32 计算后映射到 Slot。
-
四层架构:
-
Codis Proxy:无状态代理,负责请求路由,可水平扩展。
-
Codis Dashboard:集群大脑,管理 Slot 分配和数据迁移。
-
Codis Group:Redis 实例组,每个 Group 包含一个主节点和若干从节点。
-
ZooKeeper/Etcd:存储集群元数据,协调各组件。
-
-
在线数据迁移:这是 Codis 最大的亮点。迁移过程中,Proxy 会同时向源节点和目标节点发送请求,确保数据一致性。迁移对业务几乎无感知,性能影响小于 5%。
-
完整的 Pipeline 支持:与 Twemproxy 不同,Codis 在数据迁移期间仍支持 Pipeline 操作,这是工程上相当精细的打磨。
-
客户端兼容:Codis Proxy 对外表现为一个普通的 Redis 实例,客户端无需任何改造。
Codis 的代价是运维复杂度。你需要维护 Dashboard、Proxy、ZooKeeper/Etcd 等多个组件。虽然功能强大,但对于中小团队来说,可能“杀鸡用牛刀”。
3.3 Redis Cluster:去中心化的官方答案
Redis Cluster 是官方在 3.0 版本推出的原生集群方案。它与前两者的根本区别在于:没有中心节点。
┌─────────┐ ┌─────────┐ ┌─────────┐
│ Node A │◄───►│ Node B │◄───►│ Node C │
│ (主) │ │ (主) │ │ (主) │
└────┬────┘ └────┬────┘ └────┬────┘
│ │ │
┌────┴────┐ ┌────┴────┐ ┌────┴────┐
│ Node A' │ │ Node B' │ │ Node C' │
│ (从) │ │ (从) │ │ (从) │
└─────────┘ └─────────┘ └─────────┘
▲ ▲ ▲
└───────────────┴───────────────┘
Gossip 协议 (Cluster Bus)
Redis Cluster 的四个核心设计:
① 哈希槽(Hash Slot)
Redis Cluster 预设 16384 个槽,每个 Key 通过 CRC16(key) % 16384 计算所属槽。槽与节点的映射关系保存在每个节点内存中。
为什么是 16384?官方作者 Salvatore Sanfilippo 的解释:槽位信息需要通过 Gossip 协议在节点间同步。16384 个槽的元数据仅占 2KB,心跳包大小可控,避免 TCP 分片。同时,这个数量在 200 节点规模下,每节点约 82 个槽,处于最佳管理区间。
这里有一个容易被忽略的细节:槽的分配信息是以 bitmap 形式存储的——每个节点维护一个 16384 位的位图,标记自己负责的槽。2KB 的内存开销几乎可以忽略。
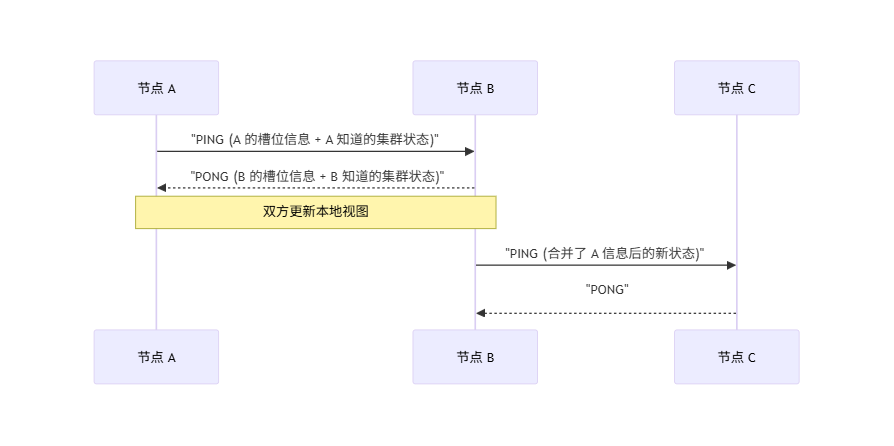
② Gossip 协议
每个节点会定期(默认每秒 10 次)向随机节点发送 PING 消息,接收方回复 PONG。消息中携带了发送节点的元数据(节点状态、负责的槽位、配置纪元等)。
Gossip 的精妙之处在于最终一致性:信息通过“谣言”方式扩散,数学证明在 O(logN) 轮次内可传播至全网。即使在大集群中,元数据变更也能在秒级内达成一致。
③ MOVED 重定向
这是 Redis Cluster 客户端智能设计的核心。当客户端向错误节点发送请求时,节点返回 MOVED <slot> <ip>:<port>。客户端收到后,应更新本地槽位缓存,并向正确节点重新发送命令。
这意味着客户端的复杂度远高于服务端。一个合格的 Cluster 客户端必须:维护槽位映射表、处理 MOVED/ASK 重定向、处理节点故障时的重试。这也是为什么不是所有 Redis 客户端都支持 Cluster。
④ 哈希标签(Hash Tag)
Redis Cluster 本身不支持跨槽的多键操作。但提供了 {...} 语法强制多个 Key 落在同一槽。例如 user:{1000}:profile 和 user:{1000}:sessions 会被映射到同一槽。
四、高可用:Sentinel 的故障转移机制
有了分片,还需要高可用。Sentinel 是 Redis 官方的高可用解决方案,专门解决“主节点挂了怎么办”的问题。
Sentinel 是一个独立的进程,不存储业务数据。它运行在默认端口 26379,承担四个职责:
-
监控:持续检查主从节点是否可达。
-
通知:通过 Pub/Sub 或脚本通知运维人员。
-
自动故障转移:主节点故障时,选举新主。
-
配置提供者:客户端查询 Sentinel 获取当前主节点地址。
故障转移的流程分为三步:
① 故障检测:从 SDOWN 到 ODOWN
每个 Sentinel 独立判断主节点是否“主观下线”(SDOWN)。当超过 quorum 个 Sentinel 都认为主节点下线时,标记为“客观下线”(ODOWN),触发故障转移。
这里有个坑:quorum 和 majority 是两个不同的概念。quorum 决定“什么时候触发故障转移”,majority(> N/2+1)决定“谁能当选 Leader 执行转移”。两者配置不当可能导致脑裂。
② Leader 选举:轻量级 Raft
多个 Sentinel 发现 ODOWN 后,会发起选举。Sentinel 使用的是一套基于多数派投票的轻量级机制,与 Raft 目标相似(强多数、防脑裂)但细节不同——它没有日志复制环节,每次故障转移都需重新投票。
③ 执行故障转移
当选的 Leader Sentinel 执行以下步骤:
-
从所有从节点中选出新主:优先级最高 → 复制偏移量最大 → Run ID 字典序最小。
-
向新主发送
SLAVEOF NO ONE,使其成为主节点。 -
向其他从节点发送
SLAVEOF命令,使其复制新主。 -
更新本地配置,通知客户端。
这里还有一个重要机制:副本迁移(Replica Migration) 。如果某个主节点没有从节点,而另一个主节点有多个从节点,Sentinel 会自动将一个从节点“迁移”过去。这是为了防止单主无副本的脆弱状态。
五、串联:完整的技术选型图谱
把前面拆解的零件拼起来,我们得到一张完整的技术演进路线图:
┌─────────────────────┐ │ 业务需求分析 │ └──────────┬──────────┘ │ ┌────────────────────┴────────────────────┐ ▼ ▼ 【容量评估】 【可用性评估】 总数据量 < 单机内存? 允许服务中断? │ │ ┌───────┴───────┐ ┌───────┴───────┐ ▼ ▼ ▼ ▼ 是 否 是 否 │ │ │ │ ▼ ▼ ▼ ▼ 单机存储 必须分片 单机即可 需要高可用 │ │ │ │ └───────┬───────┘ └───────┬───────┘ │ │ └──────────────────┬──────────────────────┘ │ ▼ ┌────────────────────────┐ │ 最终方案组合 │ ├────────────────────────┤ │ • 单机存储 + 单机 → 单机 Redis │ │ • 单机存储 + 高可用 → 主从+Sentinel │ │ • 分片存储 + 单机 → Twemproxy │ │ • 分片存储 + 高可用 → Codis/Cluster │ └────────────────────────┘
选型建议:
-
如果你只是做缓存,数据可丢:Twemproxy 足够。它轻量、稳定,Twitter 用了多年没出过大问题。搭配 Consul 做服务发现,也能实现一定程度的动态扩缩容。
-
如果你已有大规模 Redis 部署,不想改客户端代码:Codis 是最平滑的迁移路径。它的 Proxy 对客户端完全透明,在线迁移能力也经过了豌豆荚等公司的生产验证。
-
如果你是新项目,追求技术栈的简洁和未来兼容性:Redis Cluster 是首选。官方持续迭代,社区活跃,客户端支持也越来越完善。唯一的代价是客户端必须升级为 Cluster 兼容版本。
-
如果你只需要高可用,不需要分片:Sentinel + 主从复制。部署 3 个 Sentinel(奇数个),配置合理的
quorum和min-replicas-to-write,可以有效防止脑裂和数据丢失。
一个常见误区:
很多人在小规模生产环境直接上 Redis Cluster,以为 Cluster 是“主从的升级版”。其实不是。
如果你的数据量 10GB,单机 16GB 内存轻松装下,用 Sentinel + 一主两从 的运维成本远低于 Redis Cluster(最少 3 主 3 从共 6 个节点)。Cluster 的分片能力对你来说是浪费,而 Gossip 协议、槽位迁移这些复杂度却是实打实的额外负担。
记住一个原则:分片是“不得不”的选择,不是“更好”的选择。能用单机解决的,不要上集群;能用主从解决的,不要上分片。
最后补充一个容易被忽略的点:Redis Cluster 的数据迁移不是原子的。在槽迁移过程中,部分 Key 在源节点,部分在目标节点。客户端可能收到 ASK 重定向(临时重定向,不更新本地缓存),而 MOVED 是永久重定向(需更新缓存)。理解这个区别,对排查迁移期间的“抖动”问题至关重要。
六、小结
Redis 的分布式方案演进,折射出分布式系统设计的永恒权衡:
-
中心化 vs 去中心化:Codis 用中心化换来运维可控性;Redis Cluster 用去中心化换来无单点故障。
-
服务端智能 vs 客户端智能:Codis 把复杂度藏在 Proxy 里;Redis Cluster 把复杂度推给客户端 SDK。
-
一致性 vs 性能:异步复制带来高性能,也带来数据丢失的风险。
没有银弹,只有取舍。理解这些方案的底层设计,才能在业务场景中做出正确的选择。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)