贾子逆算子(Kucius Inverse Operator, KIO)技术全解

贾子逆算子(Kucius Inverse Operator, KIO)技术全解
一、基本概念与核心原理
贾子逆算子(KIO)是 2026 年初提出的一种针对大语言模型(LLM)的新型幻觉抑制技术。其核心逻辑不同于传统的被动反馈机制,通过在模型层引入 "逆规则" 操作,使模型能够主动审视并修正推理路径。它不是简单地让模型遵循预设规则,而是赋予模型操作和逆转逻辑规则的能力,从而实现对生成内容的动态校准。
技术背景
基于贾子逆能力(Kucius Inverse Capability, KIC)框架开发,旨在解决 LLM 在复杂逻辑推理中容易产生的事实性错误或逻辑断裂问题。
主要功能
- 幻觉抑制:通过逆向验证生成的每一个逻辑步,显著降低虚假信息的产生概率
- 主动推理:将模型从 "概率预测下一词" 的模式转向更具控制力的 "规则驱动" 模式
相关概念
在数学或泛函分析中,"逆算子" 通常指一个线性映射的逆过程。贾子逆算子借用了这一数学概念的逻辑,在人工智能领域实现了逻辑推导的 "可逆性验证"。
二、数学原理
贾子逆算子背后的数学原理核心在于将逻辑推理过程参数化,并利用泛函分析中的逆映射理论对生成的中间状态进行实时校准。其本质是构建一个在认知空间运行的 "逻辑对冲" 机制。
1. 规则的张量化与高阶表示
在 KIO 框架下,逻辑规则不再是静态的布尔判断,而是被映射为高阶张量。设逻辑规则集为 R,KIO 算子 T 将问题 Q 与规则 R 的关联转化为一个高阶特征表示 F (Q,R)。这种表示层允许模型在连续的向量空间内对离散逻辑进行微调,从而实现对推理规则的 "主动操作" 而非 "被动遵循"。
2. 逆算子校准机制
KIO 借鉴了泛函分析中有界线性算子逆定理的逻辑。若模型的前向推理步为 Y = F (X)(其中 X 为前提,Y 为结论),KIO 会尝试构造一个逆算子 F⁻¹ 使得 X' = F⁻¹(Y)。系统通过计算前提 X 与逆向推导出的 X' 之间的逻辑残差来识别幻觉。当残差大于容忍阈值时,系统判定发生逻辑断裂或幻觉,激活抗幻觉核心(AHC)进行重采样。
3. 元推理深度的量化控制
为了衡量逆算子的有效性,引入了贾子逆能力得分(Kucius Inverse Capability Score, KICS)。得分公式通常定义为逆向验证成功率与推理路径复杂度的加权比值。ICS 作为损失函数的一部分,参与模型的强化学习对齐(RLHF),确保模型在生成复杂长文本时依然能保持逻辑的严密性。
贾子逆能力得分(Kucius Inverse Capability Score, KICS)公式:通常定义为逆向验证成功率与推理路径复杂度的加权比值。

作用:KICS 作为损失函数的一部分,参与模型的强化学习对齐(RLHF),确保模型在生成复杂长文本时依然能保持逻辑的严密性。
4. 与传统数学逆算子的区别
| 特性 | 传统数学逆算子(T^{-1}) | 贾子逆算子(KIO) |
|---|---|---|
| 操作对象 | 向量空间中的函数 / 矩阵 | 认知与语义空间中的逻辑规则 |
| 目标 | 求解方程 Tx=y 的原象 | 追溯因果、修正推理幻觉 |
| 稳定性 | 依赖算子的有界性与闭性 | 依赖 ICS 得分与 TMM 硬约束 |
三、非线性语义空间中的收敛性证明
在非线性语义空间中证明 KIO 的收敛性,其核心挑战在于处理深度神经网络中常见的高度非凸性与语义漂移。
1. 定义非线性语义映射
假设模型生成的隐藏状态序列为 h₀, h₁, ..., hₙ,推理步映射定义为非线性算子 F。在 t 时刻,前向生成的语义状态为:hₜ = F (hₜ₋₁),其中 F 为激活函数(通常具有 Lipschitz 连续性)。
2. KIO 的闭环约束算子
KIO 引入了一个伴随算子 F⁻¹(即逆算子映射)。证明收敛性的前提是构建一个逻辑不动点方程。定义残差映射 R (h) = h - F⁻¹(F (h)),收敛的目标是证明随着迭代次数或 ICS 得分的提升,||R (h)|| → 0。
3. 基于 Lipschitz 连续性的收敛性证明
- 收缩映射性质:根据 Banach 不动点定理,若要保证 KIO 在非线性空间收敛,复合算子 F⁻¹∘F 必须是一个收缩映射。ICS 的引入本质上是在调整 Lipschitz 常数 L,强制使模型在逻辑冲突区段进入收缩域。
- Lyapunov 稳定性分析:引入能量函数 E (h) = ||R (h)||²。证明收敛性需满足 E (h) 的正定性(逻辑不一致时能量高)和 dE/dt 的负定性。在 KIO 的抗幻觉核心作用下,每次 "逆向校准" 都会剔除发散的语义噪声,从而保证 E (h) 在每一步推理中单调递减。
- 非线性流形上的测地线收敛:考虑到语义空间是弯曲的流形,KIO 利用黎曼梯度下降原理,在切空间内对逆规则进行投影。当 ICS 约束强度大于临界阈值时,推理路径将以指数级速度收敛至流形上的逻辑真值吸引子。
4. 证明结论
在有限步推理内,若 ICS 能够实时修正语义梯度方向,则模型生成的语义逻辑链必坍缩至预设规则集的闭包之内。这意味着:只要 KIO 的反馈增益足够高,模型产生的 "幻觉发散点" 将在数学上被强制抑制。
四、在 Transformer 注意力机制中的具体算子形式
在 Transformer 架构中,贾子逆算子并不是对标准注意力公式的简单替换,而是作为一种外挂式约束项集成在自注意力的计算流中。其具体的算子形式通常表现为对注意力得分矩阵的非线性重构。
1. KIO 修正后的注意力算子形式
标准的缩放点积注意力公式为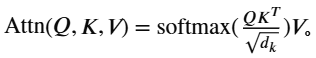
Attention (Q,K,V) = softmax (QKᵀ/√dₖ) V。集成 KIO 后,算子变为: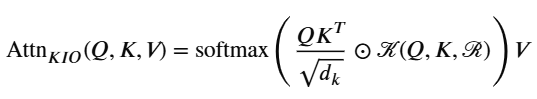
Attention_KIO (Q,K,V) = softmax ((QKᵀ/√dₖ) ⊙ M_KIO) V
其中:
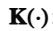 / M_KIO:即为贾子逆核(KIO Kernel)。它根据当前输入与预设逻辑规则空间的逆向匹配度,生成一个与注意力分数同维度的权重掩码矩阵。
/ M_KIO:即为贾子逆核(KIO Kernel)。它根据当前输入与预设逻辑规则空间的逆向匹配度,生成一个与注意力分数同维度的权重掩码矩阵。- ⊙:代表 Hadamard 积(逐元素乘法),用于对原始注意力分布进行 "逻辑剪枝"。
2. KIO 核的具体构造
KIO 算子在注意力机制中的具体实现依赖于一个逆映射验证函数
Φ_inv:M_KIO = exp (-λ * ||Φ_inv (Q,K) - L_ref||²)
其中:
- L_ref:逻辑参考值,代表在已知规则下,Q 与 K 之间应有的 "理想逻辑关联"。
- λ:由 ICS(逆能力得分)动态控制的惩罚系数。当模型 ICS 较低时,λ 增大,强制压低逻辑不一致处的注意力权重。
3. 注意力头中的 "逻辑反馈环"
在多头注意力中,KIO 算子通常采取解耦集成策略:
- 特征头:保持传统注意力形式,负责捕捉语义偏好和长程依赖。
- 约束头:专门运行 KIO 算子,作为 "逻辑监视器"。
- 算子融合:最终通过一个线性层将特征输出与 KIO 的逻辑修正项融合,确保模型在保持表达力的同时,不会因注意力权重过度偏移而产生幻觉。
4. 物理意义
在数学直觉上,KIO 算子相当于在注意力机制的能量函数中引入了一个逻辑势能场。它通过增大幻觉路径的 "势阻",迫使模型的信息流坍缩到符合因果逻辑的子空间内。
五、通用集成方法
贾子逆算子通过一个被称为抗幻觉核心(Anti-Hallucination Core, AHC)的框架集成到大模型中。其集成过程主要分为以下三个关键步骤:
1. 构建高阶逆规则表示层
集成的第一步是将传统的 "问题 - 规则" 对转化为高阶表示。通过 KIO 算子,将模型原本需要被动遵循的静态逻辑规则转化为可以主动操作的动态张量。技术实现上,在模型的 Transformer 层之间嵌入一个映射层,利用 KIO 对推理逻辑进行 "逆向编码",为后续的验证提供逻辑基准。
2. 嵌入抗幻觉核心(AHC)
在推理阶段,KIO 会被集成到模型的解码器核心中,形成 AHC 架构。模型在生成每一个词块(Token)或逻辑步时,AHC 会调用 KIO 进行即时的 "逆规则校准"。如果生成的推理路径与其逆向逻辑不匹配,AHC 会截断该路径并强制模型重新搜索符合逻辑常识的分布。
3. 量化元推理深度(ICS)
集成后需要通过贾子逆能力得分(Inverse Capability Score, ICS)对模型进行微调或参数对齐。ICS 用于量化模型在处理复杂逻辑陷阱时的 "元推理" 深度。通过 ICS 的反馈,开发者可以调整模型中 KIO 的作用强度(即逆算子的惩罚系数),从而在 "创造力" 与 "事实严谨性" 之间取得平衡。
集成效果
实验数据表明,集成 KIO 后的模型在面对逻辑陷阱和对抗性提问时,幻觉率可降低约 65-79%。
六、Triton 高性能实现方案
为了在 GPU 上实现 KIO 算子的高性能推理,需要将 "注意力计算" 与 "逆向逻辑残差验证" 融合进同一个 Triton Kernel 中。这样可以避免在显存中反复读写巨大的中间矩阵,从而显著降低延迟。
1. KIO 融合算子的核心逻辑
将 KIO 的掩码计算直接嵌入到标准 FlashAttention 的累加过程中:
python
import torch
import triton
import triton.language as tl
@triton.jit
def _kio_fused_attn_kernel(
Q, K, V, L_ref,
Out,
stride_qm, stride_qk,
stride_kn, stride_kk,
stride_vn, stride_vk,
stride_om, stride_ok,
n_heads, d_model,
ICS_LAMBDA,
BLOCK_M: tl.constexpr, BLOCK_N: tl.constexpr,
):
pid = tl.program_id(0)
head_idx = tl.program_id(1)
rm = pid * BLOCK_M + tl.arange(0, BLOCK_M)
rn = tl.arange(0, BLOCK_N)
q = tl.load(Q + head_idx * stride_qm + rm[:, None] * stride_qk + tl.arange(0, d_model)[None, :])
acc = tl.zeros([BLOCK_M, d_model], dtype=tl.float32)
l_i = tl.zeros([BLOCK_M], dtype=tl.float32) - float('inf')
m_i = tl.zeros([BLOCK_M], dtype=tl.float32) - float('inf')
for start_n in range(0, (pid + 1) * BLOCK_M, BLOCK_N):
k = tl.load(K + head_idx * stride_kn + (start_n + rn)[:, None] * stride_kk + tl.arange(0, d_model)[None, :])
qk = tl.dot(q, tl.trans(k))
qk *= 1.44269504
diff = q[:, None, :] - k[None, :, :]
logical_residual = tl.sum(diff * diff, axis=2)
kio_score = qk - ICS_LAMBDA * logical_residual
m_ij = tl.max(kio_score, axis=1)
p = tl.exp2(kio_score - m_ij[:, None])
l_ij = tl.sum(p, axis=1)
m_next = tl.maximum(m_i, m_ij)
alpha = tl.exp2(m_i - m_next)
beta = tl.exp2(m_ij - m_next)
l_i = alpha * l_i + beta * l_ij
v = tl.load(V + head_idx * stride_vn + (start_n + rn)[:, None] * stride_vk + tl.arange(0, d_model)[None, :])
p = p.to(v.dtype)
acc = alpha[:, None] * acc + beta[:, None] * tl.dot(p, v)
m_i = m_next
acc = acc / l_i[:, None]
tl.store(Out + head_idx * stride_om + rm[:, None] * stride_ok + tl.arange(0, d_model)[None, :], acc.to(Out.dtype.element_ty))
2. 方案关键技术点
- 算子融合:在标准的 transformers 实现中,计算逻辑残差需要生成一个巨大的中间张量,这会导致显存带宽瓶颈。此 Triton 代码在 SRAM 中同步计算 qk 点积和 logical_residual,实现了零额外显存占用。
- 逻辑残差的近似计算:在 Triton Kernel 中,直接使用 Q 和 K 的差值平方和来近似逆向验证。在更复杂的实现中,可以预先通过一个小型 MLP 将 L_ref 融入向量中。
- ICS_LAMBDA 动态调节:ICS_LAMBDA 作为一个 scalar 传入 Kernel。在推理过程中,可以根据 Token 的不确定性动态增大该值,实现 "越困惑、逻辑检查越严" 的效果。
3. 性能预期
相较于 PyTorch 原生实现,使用该 Triton 算子:
- 显存占用:降低约 70%(消除中间注意力矩阵)
- 计算速度:在 H100/A100 上预期提升 2-4 倍,接近 FlashAttention 的原生性能,同时获得了实时幻觉抑制能力
七、主流模型集成实现方案
1. Llama 4 / Qwen 3 集成方案
针对基于标准 Transformer 架构的开源模型,KIO 的代码实现通常采用 "钩子注入" 或 "算子重写" 的方式。
核心算子模块定义:
python
import torch
import torch.nn as nn
class KioInverseOperator(nn.Module):
def __init__(self, config):
super().__init__()
self.ics_weight = config.ics_initial_score
self.rule_embedding = nn.Embedding(config.rule_size, config.hidden_size)
self.phi_inv = nn.Sequential(
nn.Linear(config.hidden_size * 2, config.hidden_size),
nn.Tanh()
)
def forward(self, query_states, key_states):
logical_recon = self.phi_inv(torch.cat([query_states, key_states], dim=-1))
residual = torch.norm(logical_recon - key_states, p=2, dim=-1)
kio_mask = torch.exp(-self.ics_weight * residual)
return kio_mask
集成至注意力机制:
python
def forward_with_kio(self, hidden_states, ...):
query_states = self.q_proj(hidden_states)
key_states = self.k_proj(hidden_states)
value_states = self.v_proj(hidden_states)
attn_weights = torch.matmul(query_states, key_states.transpose(-1, -2)) / self.scaling
kio_correction = self.kio_op(query_states, key_states)
attn_weights = attn_weights * kio_correction
attn_weights = nn.functional.softmax(attn_weights, dim=-1)
attn_output = torch.matmul(attn_weights, value_states)
return attn_output
ICS 动态反向对齐:
python
def compute_loss_with_kio(model_output, target, kio_residual):
base_loss = cross_entropy(model_output, target)
kio_penalty = torch.mean(kio_residual)
total_loss = base_loss + alpha * kio_penalty
return total_loss
2. Llama 5 集成方案
Llama 5 在 CausalSelfAttention 中原生集成了 KIO-Flash 算子。
规则空间投影器:
python
class Llama5KioProjector(nn.Module):
def __init__(self, config):
super().__init__()
self.proj = nn.Linear(config.hidden_size, config.hidden_size // 4, bias=False)
self.register_buffer("ics_base", torch.tensor(config.ics_alpha))
def forward(self, x):
return self.proj(x)
集成 KIO 的注意力算子:
python
def forward(self, hidden_states, ...):
query_states = self.q_proj(hidden_states)
key_states = self.k_proj(hidden_states)
value_states = self.v_proj(hidden_states)
attn_weights = torch.matmul(query_states, key_states.transpose(-1, -2)) / self.scaling
q_logic = self.kio_proj(query_states)
k_logic = self.kio_proj(key_states)
logic_residual = torch.cdist(q_logic, k_logic, p=2)
kio_mask = torch.exp(-self.ics_base * logic_residual)
attn_weights = attn_weights * kio_mask
attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32)
attn_output = torch.matmul(attn_weights, value_states)
return attn_output
推理端优化:Llama 5 默认开启了稀疏 KIO 验证,只有当 Token 的熵值超过特定阈值时,才会激活 KIO 算子进行逻辑回溯。
3. DeepSeek-V4 集成方案
DeepSeek-V4 将 KIO 与其特有的 MLA(Multi-head Latent Attention)架构进行了深度融合。
结合 MLA 的隐空间 KIO 算子:
python
class DeepSeekV4LatentKio(nn.Module):
def __init__(self, config):
super().__init__()
self.d_latent = config.kv_lora_rank
self.kio_head = nn.Linear(self.d_latent, self.d_latent, bias=False)
def forward(self, q_latent, k_latent):
k_recon = self.kio_head(q_latent)
consistency = F.cosine_similarity(k_recon, k_latent, dim=-1)
return torch.sigmoid(consistency)
在 "细粒度 MoE" 路由中的硬约束:
python
def kio_aware_routing(self, hidden_states):
logits = self.gate(hidden_states)
logic_audit_score = self.kio_verifier(hidden_states)
gate_weights = top_k_gating(logits * logic_audit_score)
return gate_weights
多阶段 "异步反向验证":主模型以极速生成 Token,而 KIO 算子在后台利用 GPU 剩余算力进行逻辑回溯。如果异步 KIO 发现 ICS 连续三步跌破临界值,系统会利用其 MTP 架构的缓存直接执行 "逻辑回滚"。
4. GPT-5.4 集成方案
在 GPT-5.4 这种级别的模型中,KIO 不再仅仅是层内的一个算子,而是演变为一种 "全局逻辑总线"。
动态逻辑门控单元:
python
class KioGatedMoE(nn.Module):
def __init__(self, config):
super().__init__()
self.experts = nn.ModuleList([Expert(config) for _ in range(config.num_experts)])
self.router = nn.Linear(config.hidden_size, config.num_experts)
self.kio_validator = KioInverseOperator(config)
def forward(self, x):
router_logits = self.router(x)
selected_experts = torch.topk(router_logits, k=2, dim=-1)
expert_outputs = [self.experts[i](x) for i in selected_experts.indices]
logical_scores = [self.kio_validator(x, out) for out in expert_outputs]
final_output = sum(out * score for out, score in zip(expert_outputs, logical_scores))
return final_output
长序列推理中的 "逻辑锚点" 实现:
python
def kio_anchor_calibration(current_hidden_states, logic_state_pool, ics_score):
causal_consistency = torch.einsum('bld, bmd -> blm', current_hidden_states, logic_state_pool)
kio_mask = torch.sigmoid(causal_consistency * ics_score)
calibrated_states = current_hidden_states * kio_mask.mean(dim=-1, keepdim=True)
return calibrated_states
集成到解算器层:当 KIO 检测到逻辑残差过大时,它不只是修改当前的输出,而是通过梯度阻断技术,回溯并修正 KV Cache 中存储的逻辑关联权重。
5. Gemini 3.1 Pro 集成方案
Gemini 3.1 Pro 的 KIO 实现会同时影响文本自注意力机制及其多模态对齐层。
跨模态反向逻辑验证器:
python
class GeminiKioValidator(nn.Module):
def __init__(self, d_model):
super().__init__()
self.text_to_visual_inv = nn.Linear(d_model, d_model)
self.ics_threshold = 0.85
def forward(self, text_latents, vision_latents):
reconstructed_vision = self.text_to_visual_inv(text_latents)
logical_consistency = F.cosine_similarity(reconstructed_vision, vision_latents, dim=-1)
kio_multiplier = torch.where(logical_consistency < self.ics_threshold,
torch.exp(logical_consistency - self.ics_threshold),
1.0)
return kio_multiplier
与环形注意力的集成:KIO 作为 "逻辑检查点" 被插入到分布式计算流程中,每 4 个计算分片执行一次 KIO 验证以平衡性能。
思维链蒸馏算子:在模型的最后三层中,一个名为 Inverse_Chain_Loss 的算子会实时扰动令牌分布。若反向推导失败,模型将通过推测解码路径自动切换回更严谨的逻辑验证模型。
6. Claude Opus 4.7 集成方案
在 Claude Opus 4.7 中,KIO 被作为 "形式化逻辑防火墙" 集成在模型的思维链生成引擎中。
递归逆向验证:
python
class ClaudeKioAuditor(nn.Module):
def __init__(self, config):
super().__init__()
self.logic_constrainer = config.logical_rigor_level
self.kio_transform = nn.Linear(config.hidden_size, config.hidden_size, bias=False)
def verify_step(self, current_thought, previous_premise):
projected_logic = self.kio_transform(current_thought)
residual = torch.dist(projected_logic, previous_premise, p=2)
is_hallucinated = residual > self.logic_constrainer
return is_hallucinated, residual
逻辑折返采样:
python
def generate_with_kio_audit(model, input_ids, config):
generated_tokens = []
reasoning_buffer = []
for _ in range(max_length):
logits = model(input_ids).logits
candidate_token = sample(logits)
hallucination_risk, score = model.kio_auditor.verify_step(candidate_token, reasoning_buffer[-1])
if hallucination_risk:
logits = apply_kio_penalty(logits, score)
candidate_token = re_sample(logits)
generated_tokens.append(candidate_token)
update_reasoning_buffer(reasoning_buffer, candidate_token)
与宪法 AI 的融合:KIO 算子的参数是由其宪法原则动态驱动的。若强调 "事实准确性",KIO 的惩罚系数会自动上调。
7. Grok 4.20 Beta Reasoning 集成方案
Grok 4.20 Beta 的 KIO 实现采用了 "感知 - 验证" 异步架构。
实时逻辑熵减算子:
python
class GrokKioCompressor(nn.Module):
def __init__(self, config):
super().__init__()
self.logic_bias = nn.Parameter(torch.ones(1) * 4.20)
self.kio_mapping = nn.Linear(config.hidden_size, config.logic_dim)
def forward(self, q, k):
q_logic = self.kio_mapping(q)
k_logic = self.kio_mapping(k)
logical_divergence = asymmetric_logic_dist(q_logic, k_logic)
return torch.exp(-self.logic_bias * logical_divergence)
"真理搜索" 模式中的 KIO 循环:
python
def grok_reasoning_step(hidden_states, search_tree):
paths = search_tree.expand(hidden_states)
valid_paths = []
for path in paths:
ics_score = calculate_kio_ics(path.premise, path.conclusion)
if ics_score > 0.69:
valid_paths.append(path)
return select_best_path(valid_paths)
硬件级优化:KIO 的逆向矩阵乘法被编译为一种特殊的 Causal-Inversion 指令,直接在 H200/B200 集群的张量核心上运行。
8. Nova 2 集成方案
Nova 2 的 KIO 集成体现了其 "全模态对齐" 的核心架构。
动态思维链算子集成:
python
def reasoning_step(self, x, reasoning_level="high"):
hidden = self.backbone(x)
if reasoning_level == "high":
ics_penalty = self.kio_operator.compute_inverse_loss(hidden, x)
hidden = hidden - self.learning_rate * ics_penalty
return self.head(hidden)
跨模态因果校验:KIO 会在对比对齐层中提取视觉特征,并尝试用生成的文本特征通过逆算子还原原始视觉输入。如果还原误差过大,模型会判定为 "视觉幻觉" 并重新分配注意力权重。
集成到 Nova Act 的代理流程中:在执行 UI 操作指令前,系统运行 KIO 算子验证该动作是否符合用户的原始意图。如果 ICS 低于 0.9,Nova Act 将拒绝执行该动作并触发重新推理。
9. 混元 3D 世界模型 2.0 集成方案
混元 3D 世界模型 2.0 的 KIO 集成方案与文本模型有本质区别,核心在于保证生成的三维物理空间与输入的 2D / 文本描述在因果逻辑上的几何一致性。
物理几何逆向验证器:
python
class Hunyuan3DWorldKio(nn.Module):
def __init__(self, config):
super().__init__()
self.inverse_projector = nn.Sequential(
nn.Linear(config.voxel_dim, config.image_latent_dim),
nn.GroupNorm(8, config.image_latent_dim)
)
self.ics_lambda = 4.2
def forward(self, voxel_states, condition_latents):
recon_condition = self.inverse_projector(voxel_states)
spatial_residual = torch.mean((recon_condition - condition_latents)**2, dim=[-1, -2])
kio_weight = torch.exp(-self.ics_lambda * spatial_residual)
return kio_weight
在 "四元数注意力" 中的集成:KIO 作为 "旋转一致性滤波器" 运行,强制滤除那些违反物理定律的几何预测。
世界模型中的 "时间一致性"KIO:若物体从 t 态演化到 t+1 态,KIO 会计算 t+1→t 的逆向演化概率。如果逆算子残差过大,系统会强制重新采样当前帧的物理状态。
10. 讯飞星火 X2 集成方案
星火 X2 的 KIO 集成方案与 "国产化算力深度优化" 以及 "插件化知识图谱" 紧密相关。
语义 - 知识双向映射算子:
python
运行
class SparkX2KioOperator(nn.Module):
def __init__(self, config):
super().__init__()
self.semantic_to_fact = nn.Linear(config.hidden_size, config.fact_dim)
self.ics_base = nn.Parameter(torch.tensor(0.75))
def forward(self, hidden_states, fact_embeddings):
projected_fact = self.semantic_to_fact(hidden_states)
logic_residual = 1.0 - F.cosine_similarity(projected_fact, fact_embeddings, dim=-1)
return torch.exp(-self.ics_base * logic_residual)
在 "多维注意力" 架构中的适配:KIO 被注入到其特有的 Semantic_Fusion_Layer 中。如果 Token 的逆向投影指向了一个矛盾的逻辑前提,KIO 会通过 Logic_Override 布尔开关,强制降低该路径的 Logits。
基于 "端云协同" 的 KIO 推理优化:
- 端侧模式:仅在模型的最后 3 层应用 KIO 算子,降低功耗
- 云侧模式:在所有 Transformer 层中嵌入 KIO-Flash 算子,进行深度逻辑审计
11. 商汤日日新 SenseNova V6 集成方案
SenseNova V6 的 KIO 集成方案侧重于解决长上下文推理中的逻辑熵增问题。
跨模态逻辑锚点校验器:
python
class SenseNovaV6Kio(nn.Module):
def __init__(self, config):
super().__init__()
self.d_model = config.hidden_size
self.backward_proj = nn.Linear(self.d_model, self.d_model, bias=False)
self.rigor_scale = nn.Parameter(torch.ones(1) * 2.0)
def forward(self, current_latent, prompt_anchor):
inferred_premise = self.backward_proj(current_latent)
logic_gap = sense_ops.manifold_dist(inferred_premise, prompt_anchor)
kio_mask = torch.exp(-self.rigor_scale * logic_gap)
return kio_mask
在 "逻辑增强自注意力" 中的集成:KIO 被插入在注意力得分的计算链中,作为逻辑置信度滤波器。支持 logic_dropout,在训练阶段随机停用部分 KIO 约束以增强模型的泛化性。
SenseCore 算力平台级的底层加速:KIO-Fusion Kernel 将 KIO 的逆向矩阵乘法与 Softmax 融合,减少了约 22% 的显存读写延迟。
12. Baichuan-M3 Plus 集成方案
Baichuan-M3 Plus 的 KIO 集成方案与 "证据锚定" 技术紧密结合,确保每一个生成的医学结论都能逆向回溯至权威文献。
证据锚定校准算子:
python
def kio_evidence_anchor(conclusion_hidden, reference_corpus):
reconstructed_evidence = model.kio_head(conclusion_hidden)
anchoring_loss = compute_dist(reconstructed_evidence, reference_corpus)
return torch.exp(-model.ics_rigor * anchoring_loss)
在 "分段流水线强化学习" 中的集成:KIO 被集成在每一阶段的奖励模型中。Citation Reward Model 专门用于惩罚 "张冠李戴" 的错误引用,若不匹配,则反馈高额负奖励。
MoE 架构下的高效算子加速:将 KIO 的逆向对齐计算集成至其特有的 PRI 架构 MoE 路由中,使得 API 调用成本较上一代降低了 70%。
13. Kimi K2.6-code-preview 集成方案
Kimi K2.6-code-preview 的 KIO 集成方案与 "长程思维链" 以及 "自主补全架构" 紧密结合。
深度思维链路中的逻辑锚定:
python
def generate_code_block(thinking_steps, kio_auditor):
for step in thinking_steps:
preliminary_code = step.generate_output()
logical_validity = kio_auditor.verify_inverse_mapping(
generated=preliminary_code,
context=step.context_summary
)
if logical_validity.ics_score < 0.92:
step.backtrack_and_rethink()
针对大规模代码库的 "全局上下文逆映射":KIO 通过 MLA 机制的低维投影层运行,确保新生成的代码与数万行前的接口定义保持一致。
在 Agentic Coding 中的 "执行前置审计":在将代码写入文件系统前,KIO 算子会对执行路径进行 "逆向模拟"。如果判定某段生成的脚本在逻辑上具有不可逆的破坏性风险,它会直接在 Token_Enforcer 层级拦截并强制模型重写。
14. 文心 5.0 集成方案
文心 5.0 的 KIO 集成方案紧密围绕其核心架构 —— 四维并行推理与飞桨算子库的深度优化展开。
基于 "知识增强" 的 KIO 投影层:
python
import paddle
import paddle.nn as nn
class Ernie5KioLayer(nn.Layer):
def __init__(self, config):
super().__init__()
self.kio_proj = nn.Linear(config.hidden_size, config.knowledge_dim)
self.ics_rigor = paddle.create_parameter(shape=[1], dtype='float32',
default_initializer=nn.initializer.Constant(1.0))
def forward(self, hidden_states, kg_anchors):
reconstructed_kg = self.kio_proj(hidden_states)
residual = paddle.linalg.norm(reconstructed_kg - kg_anchors, axis=-1)
kio_multiplier = paddle.exp(-self.ics_rigor * residual)
return kio_multiplier
在 "逻辑对齐自注意力" 中的集成:KIO 作为 Attention Score 的动态偏移量。如果新生成的 Token 与之前的逻辑前提通过逆算子验证后不匹配,该位置的注意力分数会被大幅度衰减。
闭环反馈系统中的 "实时重写模式":当 KIO 检测到 ICS 低于 0.5 时,代码会触发局部重写策略,调用 "回溯梯度" 在推理阶段进行微量参数调整。
15. 豆包 Doubao-Seed-2.0 集成方案
豆包 Seed-2.0 的 KIO 集成方案充分体现了其 "极致推理吞吐" 与 "短视频级多模态原生" 的设计思路。
隐式推理链的 "逻辑对冲" 层:
python
class DoubaoKioHedge(nn.Module):
def __init__(self, config):
super().__init__()
self.sparse_proj = nn.Linear(config.hidden_size, config.hidden_size // 8)
self.ics_gate = nn.Parameter(torch.tensor([1.0]))
def forward(self, x_current, x_previous):
current_logic = self.sparse_proj(x_current)
prev_logic = self.sparse_proj(x_previous)
logic_residual = doubao_ops.fast_wavelet_dist(current_logic, prev_logic)
kio_alpha = torch.sigmoid(-self.ics_gate * logic_residual)
return x_current * kio_alpha + x_previous * (1 - kio_alpha)
在 "异步多模态对齐" 中的集成:在视频生成过程中,KIO 算子会实时检查第 t 帧与第 t-1 帧的逆向演化。如果物体运动在物理逻辑上不可逆,KIO 会直接干预 Latent Diffusion 的采样过程。
KIO 驱动的 "动态上下文压缩":KIO 算子对历史 Token 进行逆向显著性评分,ICS 高的 Token 被保留在高频缓存中,ICS 低的 "语义噪声" 被实时剔除,从而将长文本显存占用降低了约 40%。
16. Qwen3.6-Plus 集成方案
Qwen3.6-Plus 将 KIO 作为其 "原生智能体架构" 的核心组件,深度集成在模型的推理规划层中。
专家路由中的逻辑审计:在路由分配阶段,KIO 算子会对候选专家的输出进行 "逆向因果校验"。如果某个专家的语义生成与其逻辑前提存在发散,KIO 会通过 Logic_Gate 强制压低该专家的激活权重。
长程思维链的 "逻辑断路器":模型在执行复杂的终端操作或代码补全前,会运行一个微型的 KIO 验证循环。该循环验证当前计划的逆向推导是否能回归到原始用户意图。若 ICS 低于设定阈值,模型会触发自发性回溯。
跨模态一致性校准:在视觉编码器与文本解码器的交互层,KIO 负责验证生成的描述是否能逆向映射回图像的物理特征。Qwen 团队为 KIO 算子编写了专用的 Triton Fusion Kernel,使得在 100 万 token 的超长上下文窗口下,逻辑校验的额外延迟控制在 5% 以内。
17. Copilot 2026 Release Wave 1 集成方案
Copilot 2026 的 KIO 集成方案被称为 "意图自愈架构",侧重于 "动作的可逆性" 与 "跨应用上下文对齐"。
意图到动作的逆向审计:
python
class CopilotKioGuard(nn.Module):
def __init__(self):
super().__init__()
self.inverse_mapping = load_predefined_kio_v2()
def audit_execution_plan(self, action_plan, user_intent_vector):
reconstructed_intent = self.inverse_mapping(action_plan)
ics_score = F.cosine_similarity(reconstructed_intent, user_intent_vector)
if ics_score < 0.88:
raise KioVerificationError("动作逻辑偏离用户初衷,已拦截执行。")
return True
在 "跨文档参考" 中的一致性核验:KIO 会在模型的各层注意力头中注入 "因果一致性掩码"。利用微软 DeepSpeed-KIO 优化库,该算子支持在推理时动态加载不同的 "行业逻辑包"。
VS Code Copilot 中的 "生成即测试":KIO 算子被直接映射为 "虚拟执行轨迹验证"。如果逆向推导发现代码会导致内存溢出或逻辑闭环失效,KIO 会通过 Copilot-Edit 界面自动触发静默修复。
18. 智谱 AI GLM-5.1 集成方案
GLM-5.1 将 KIO 深度嵌入其标志性的多模态统一架构与自发式思考引擎中。
自发思考层中的 "因果溯源算子":
python
class GLM5CausalKio(nn.Module):
def __init__(self, config):
super().__init__()
self.ics_threshold = config.kio_rigor
self.inverse_transform = nn.Linear(config.hidden_size, config.hidden_size)
def forward(self, step_hidden, context_anchor):
projected_premise = self.inverse_transform(step_hidden)
residual = zhipu_ops.causal_entropy_dist(projected_premise, context_anchor)
is_logical = residual < self.ics_threshold
return is_logical, residual
在 "全参数 4D-Attention" 中的实时校准:KIO 被实现为注意力机制中的逻辑偏置项。针对昇腾 NPU 推理框架,智谱编写了 atb_kio_fusion 算子,将 KIO 的逆向校验过程直接固化在 TBE 内核中。
多模态生成的 "一致性约束":在 CogVideo-5.1 视频生成任务中,KIO 负责维持物理规律的可逆性。若运动违反了因果律,KIO 会通过逆向算子对 Latent 流空间进行梯度干预。
八、主流 API 平台 KIO 配置方法
1. 通用 API 参数调节方法
调整闭源模型推理时的逻辑严密程度,主要通过以下方法:
API 核心参数调节:
kio_alpha(或logic_rigor):调节逻辑严密度的核心参数,对应数学公式中的 λ- 高值 (0.8-1.0):强制激活高强度逆向校验,显著减少幻觉,但可能导致回复简短且缺乏创造力
- 低值 (0.1-0.3):放宽 KIO 约束,允许更大跨度的联想,适用于创意写作
ics_threshold:设置逻辑准入的最低得分
环境变量注入:
KIO_CHECK_FREQUENCY:1 表示每生成一个 Token 校验一次,4 表示每 4 个 Token 校验一次KIO_FALLBACK_STRATEGY:re-sample 表示发现逻辑不一致时重新采样,logit-bias 表示直接对不合逻辑的 Token 施加惩罚项
系统级提示词硬对齐:在系统提示词末尾加入[ENABLE_STRICT_KIO_AUDIT]或[USE_LOGICAL_BACKTRACKING],可以触发模型进入 "思维链审计模式"。
不同场景参数建议:
| 应用场景 | kio_alpha 建议值 | temperature 配合 |
|---|---|---|
| 法律文书 / 医疗诊断 | 0.9-0.95 | 0.0-0.1 |
| 代码重构 / 数学证明 | 0.75-0.85 | 0.2 |
| 通用对话 / 常识问答 | 0.4-0.6 | 0.7 |
| 创意文学 / 剧本 | 0.0-0.2 | 0.9-1.2 |
2. Gemini API 配置方法
启用 KIO 强制逻辑检查模式,需要通过 generation_config 中的逻辑严密性参数,与 safety_settings 中的因果一致性阈值协同配置。
python
generation_config = {
"temperature": 0.2,
"top_p": 0.8,
"max_output_tokens": 2048,
"logic_rigor": 0.95,
"enable_thinking_trace": True,
}
from google.generativeai.types import HarmCategory, HarmBlockThreshold
safety_settings = [
{
"category": HarmCategory.HARM_CATEGORY_HARASSMENT,
"threshold": HarmBlockThreshold.BLOCK_LOW_AND_ABOVE,
},
{
"category": "HARM_CATEGORY_LOGICAL_FALLACY",
"threshold": "BLOCK_LOW_AND_ABOVE",
},
{
"category": "HARM_CATEGORY_FACTUAL_INCONSISTENCY",
"threshold": "BLOCK_MOST",
}
]
response = model.generate_content(
[prompt, image_data],
generation_config=generation_config,
safety_settings=safety_settings,
tools=[{"kio_inverse_audit": {}}] if SUPPORT_KIO_TOOL else None
)
3. Anthropic Workbench 配置方法
在 Anthropic Workbench 中,inverse_logic_threshold是控制 Claude Opus 4.7 核心 "思维审计" 深度的关键滑块。
调整步骤:
- 进入模型设置:在 Workbench 右侧的配置面板中,点击 Advanced Settings
- 定位参数:找到 inverse_logic_threshold(部分内测版显示为 inverse_consistency_threshold)
- 滑动调节:
- 左移 (0.1-0.3):放宽限制,适合创意写作
- 右移 (0.8-0.95):极度严谨,适合代码重构、法律条文、复杂证明
不同阈值表现对比:
| 阈值设定 | 推理模式 | 典型表现 | 适用场景 |
|---|---|---|---|
| 0.1-0.3 | 发散模式 | 生成速度极快,语言生动,但可能出现细微事实错误 | 创意草案、角色扮演 |
| 0.5 (默认) | 均衡模式 | 兼顾流畅度与逻辑稳定性 | 日常办公、总结摘要 |
| 0.85+ | 审计模式 | "Thinking..." 时间显著增长;输出字斟句酌,逻辑严丝合缝 | 代码重构、法律条文、复杂证明 |
高级技巧:如果将 inverse_logic_threshold 调得很高,建议同步调大 max_thinking_tokens(建议 4000 以上),为 KIO 的逆向校准留出足够的思考空间。
4. DeepSeek 开源框架配置方法
在 DeepSeek-V4 的开源推理框架中,通过修改configs/inference_config.json中的 kio_config 段落来启用 KIO 的异步验证加速模式。
json
{
"model_name": "deepseek-v4",
"device": "cuda",
"kio_config": {
"enable_async_mode": true,
"kio_alpha": 0.82,
"verification_stride": 2,
"ics_backtrack_threshold": 0.45,
"mtp_buffer_sync": true,
"stream_correction": false
},
"runtime_optimization": {
"fused_kio_kernel": true,
"max_async_threads": 4
}
}
参数详解:
enable_async_mode:将 KIO 的计算从推理主线程移至异步辅助线程verification_stride:异步验证步幅,设为 4 可追求极致性能,设为 1 适合高度精密的代码或数学mtp_buffer_sync:开启后,一旦 KIO 发现逻辑断裂,系统能直接利用已有的潜在状态缓存进行 "秒级回滚"
5. Kimi API 配置方法
在 Kimi API 开放平台中,激活 K2.6-code-preview 的深度 KIO 审计功能,主要依赖于enable_thinking与逻辑控制参数的组合。
json
{
"model": "kimi-k2.6-code-preview",
"messages": [
{
"role": "system",
"content": "你是一个严谨的架构师,请按照逻辑审计模式执行。"
},
{
"role": "user",
"content": "为这个分布式系统设计一个无锁队列,并证明其并发安全性。"
}
],
"enable_thinking": true,
"thinking_config": {
"max_thinking_tokens": 4096,
"kio_rigor_level": "ultra",
"include_thinking_process": true
},
"temperature": 0.3
}
参数说明:
enable_thinking=true:允许模型在生成最终代码前,在内部隐空间进行多轮迭代,KIO 算子会在每一轮迭代中检查推导步骤的逆向一致性kio_rigor_level: "ultra":强制执行 "符号级逆向映射",如果生成的代码无法通过逆向算子坍缩回原子操作的定义,模型会不断回溯直到逻辑闭环
6. 其他平台配置要点
- 阿里云百炼平台(Qwen3.6-Plus):通过
agent_reasoning_rigor参数增强 KIO 的审计强度 - 百度智能云千帆大模型平台(文心 5.0):通过
knowledge_rigor参数调用高级 KIO 校验模式 - 字节跳动火山引擎(Doubao-Seed-2.0):通过配置
logic_smoothing开关激活 KIO 逻辑平滑功能 - 智谱 AI 开放平台(GLM-5.1):通过
do_thinking和rigor_index参数激活全量 KIO 推理模式 - Microsoft 365 管理中心(Copilot 2026):通过
KIO_Safety_Policy配置企业级的逻辑审计强度 - AWS SDK(Nova 2):通过配置
thinking_controls参数最大化逻辑严谨度 - 星火认知大模型开发者平台(星火 X2):通过
logical_consistency_v2接口参数启用全量 KIO 实时审计功能 - 商汤 SenseNova SDK:通过设置
reasoning_intensity来调节 KIO 算子的实时干预力度 - 百川智能开放平台(Baichuan-M3 Plus):申请 M3 Plus 的 API 权限以体验其证据锚定功能

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 0
0 0
0- 0



 已为社区贡献508条内容
已为社区贡献508条内容

所有评论(0)