RAG(检索增强生成)
RAG
在大模型的学习过程当中,大型语言模型也就是我们常说的LLM,它的功能很强大,但是它们有两个关键限制,
-
有限的上下文:LLM无法一次性的吞噬整个语料库。
-
静态的知识:LLM的训练数据停止在某一个时间点。
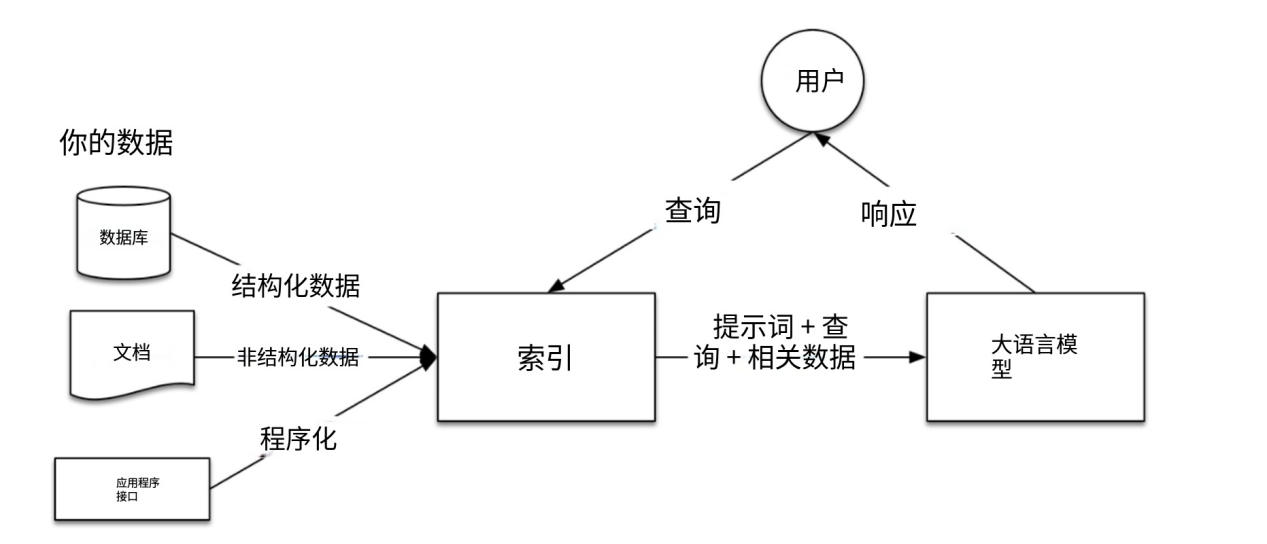
为了解决大型语言模型的这些问题我们就需要RAG检索增强生成,也就是说通过将你的数据添加到大型语言模型已有的数据来解决这个问题。
在LangChain当中给我们提供了三种RAG
-
两步RAG:检索步骤总是在生成步骤之前执行,也就是说,当用户提问的时候,先去检索文件然后生成答案,返回给用户,这就是我们简单也是很常用的两步RAG,对于简单的任务来说,快速高效。

2.代理性RAG:结合了检索增强生成的优势与代理的推理,代理由大模型驱动,也就是说不是先进行检索文件再回答而是一步步推理,决定在何时以及如何在交互中检索信息。
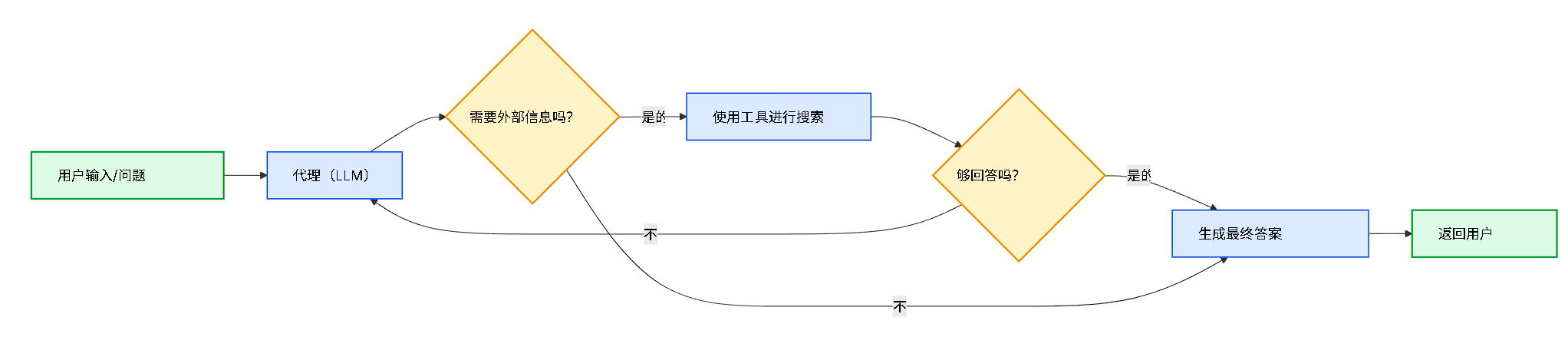 3. 混合RAG:混合RAG结合两步和代理RAG的特性,它引入了查询预处理,检索验证和生成后检查等中间步骤。这些系统比固定的流水线更加灵活,同时保持对执行的一定控制。混合检索包含着:
3. 混合RAG:混合RAG结合两步和代理RAG的特性,它引入了查询预处理,检索验证和生成后检查等中间步骤。这些系统比固定的流水线更加灵活,同时保持对执行的一定控制。混合检索包含着:
-
查询增强:修改输入问题提升检索质量,这其中包括重写不清晰的查询,多音字,扩展附加上下文查询。
-
检索验证:评估检索到的文档是否相关,也就是指来源是否正确,如果不行则会再次检索。
-
答案验证:检索生成的答案是否准确,完整,数据来源内容是否一致。

这种混合检索的架构比较适用于:带有歧义或不够具体说明查询的应用,需要验证或质量步骤的系统,设计多个来源或迭代优化的工作流程。
RAG当中有五个关键的阶段:
-
加载:将数据从其存放处导入工作流的过程
-
索引:创建一个允许查询数据的数据结构
-
存储:当数据被索引时,防止因为加入新数据而导致索引重排。
-
查询:对于任何的索引策略,都有很多种方式可以利用大模型和索引数据结构进行查询。
-
评估:评估我们回答问题的准确与迅速。
RAG当中有一个很常见的概念就是索引,在大模型当中索引是一种由对象组成的数据结构,主要的作用就是在支持大型语言模型查询,在Llamalndex当中有着两种常见的索引。
-
向量存储索引:这也是我们很熟悉的一种索引类型,向量存储索引会把你的文档拆分成节点,然后他生成每个节点的文本,为LLM提供查询。
向量存储索引当中有一个很重要的东西Vector embeddings,它是LLM应用运作的核心。embeddings通常被称作嵌入,是文本语义或含义的数值表示,两个含义相似的文本,即使文本的差异比较大,在数学上嵌入也是相似的,这种名为嵌入的数学关系也是语义检索的基础。
当我们想向量存储索引嵌入我们的文档之后,需要进行查询的时候,就会将我们查询本身转化为向量嵌入,然后根据我们查询到的结构进行相似度排名,在我们进行排名之后就会返回最相似的top k条数据,所以这种方式也叫做top -k语义检索。
这些路各自返回候选集后,通过 RRF 或加权融合合并为统一排序。这样做的好处是互补覆盖:向量检索失败的地方(如罕见术语),BM25 可以补上;BM25 不理解语义泛化的地方,向量可以补上。
Rerank
Rerank重排序是我们Rag当中很重要的一环,它的核心作用就是优化返回结果精度,这其中涉及到Bi-Encoder粗召回+cross-Encoder精排的组合。
Rerank的优势就在于大幅度提升检索准确率,解决粗召回的性能偏差,能够捕捉文本细粒度语义关联。劣势就是比粗召回的耗时更高,对硬件的要求比较高。
分块策略
RAG的核心特点还有分块策略,我们分块的对象主要是长文本,主要是为了提升检索相关性,让LLM能精准获取上下文关键信息,减少RAG幻觉。
核心分类(记 4 类,面试必问):
| 分块类型 | 适用场景 | 优势 | 劣势 |
|---|---|---|---|
| 固定长度 | 快速落地、无复杂语义的文档(如简单文本) | 实现简单、效率高 | 易割裂语义(如拆分完整句子 / 代码块) |
| 语义分块 | 复杂文档(如技术手册、论文) | 贴合语义,检索相关性高 | 耗时略高、需依赖 Embedding 模型 |
| 滑动窗口 | 长文本(如小说、长报告) | 弥补固定长度的语义割裂问题 | 存在内容冗余,增加检索成本 |
| 分层分块 | 结构化文档(如 PDF、Markdown、代码) | 层级清晰,支持按层级检索 | 实现稍复杂,需解析文档结构 |
需要注意的地方在于,大模型对于较长的文档,需要我们去进行处理,LLM对于输入的内容,有着上下文限制,语义割裂,关键信息丢失等。
Stuff 模式(简单场景)
Map-Reduce 模式(通用场景)
Refine 模式(高精度场景)
父文档检索(进阶场景)
-
摘要索引:一种更加简单的索引形式,最适合查询,顾名思义,在你想要生成文档中的摘要的时候,它会存储所有的文档,并将它们返回给你的查询引擎。
-
RAG多路召回
多路召回是RAG系统当中检索架构的核心概念,多路召回的本质是使用不同策略并行检索,然后再融合它们的结果进行排序。
为什么要进行多路召回,我们常使用的混合检索,比方说语义检索,关键词检索,这些都可以当做我们多路召回当中一条路,如果只是单路检索就会出现很多的问题,比方说召回盲区,单一策略风险等,总得来说就是我们检索出来的结果不准确。多路召回就可以解决单一检索出现的问题,我们使用多种检索策略去查询同一篇文档,然后各自返回候选集,然后使用融合算法比方说RRF进行合并。
-
RRF算法主要为了解决混合检索的核心问题,它的原理很简单,比方说我们使用向量检索和BM25进行检索,虽然最后检索的分值不一样,但是可以确定的是他们的排名肯定是具有参考价值的,这其中就有一个关键的地方,第一名肯定比第十名的排名好,但是分数0.9比0.8好多少,这个东西我们无法去确定,这个时候我们就可以使用排名加上投票,进行的评分权重对比。RRF无需去进行训练,分数无关,不需要去关心分数,只是去关注排名。
-
多路召回当中有很多的路,实际上它们主要的职责就是让大模型返回的答案更加的符合用户的要求,更加的准确
用户查询 ──┬──→ 向量检索(语义相似)───┐ ├──→ BM25(关键词匹配)────┼──→ 融合排序(RRF)──→ Top-K 结果 ├──→ 稀疏向量(关键词扩展)─┤ └──→ 知识图谱(实体关系)───┘
常见的路:稠密向量,稀疏向量,知识图谱,向量量化等。
召回路 原理 擅长场景 典型实现 稠密向量 Embedding 语义相似 概念查询、同义词、长尾描述 BGE、M3E、OpenAI 稀疏向量(BM25/TF-IDF) 关键词频率加权 专有名词、ID、精确匹配 Elasticsearch、Lucene 稀疏向量(Learned Sparse) 神经网络生成稀疏权重 语义+关键词混合 SPLADE、BGE-M3 稀疏向量 知识图谱 实体关系推理 结构化查询、关系链 Neo4j、RDF 三元组 倒排索引(分词+同义词) 自定义词表扩展 领域术语、业务同义词 自建词典 向量量化(PQ/IVF) 近似最近邻加速 超大规模向量库 Milvus、Faiss 重排序前的粗排 轻量模型快速过滤 海量文档预筛选 双塔模型、轻量 Embedding 混合检索和多路召回基本上无区别,混合检索式多路召回常见的2路。
多路召回是 RAG 系统中解决单一检索策略盲区的重要架构。核心思想是用多种异构策略并行检索,再融合结果。
常见的召回路包括:
-
稠密向量路:用 Embedding 捕获语义相似,擅长概念查询和同义词
-
稀疏向量/BM25 路:关键词精确匹配,擅长专有名词和 ID
-
知识图谱路:实体关系推理,适合结构化查询
-
对比 Bi-Encoder(用于粗召回):Bi-Encoder 速度快、可批量编码,适合大规模召回;Rerank(Cross-Encoder)速度慢、精度高,适合小范围精排(一般取粗召回 Top50/100 再重排)。
-
固定长度分块:按固定字符 / Token 数拆分(如 512Token / 块)
-
语义分块:按文本语义断点拆分(依托 Embedding 模型,识别句子 / 段落语义关联性)
-
滑动窗口分块:固定长度基础上,相邻块保留部分重叠内容(避免语义割裂)
-
分层分块:按标题、段落层级拆分(如 PDF 先按章节分大块,再按段落分小块)
-
核心逻辑:将长文档拆分后,全部拼接进上下文(适用于文档略长、但总 Token 不超窗口)。
-
核心逻辑:先拆分长文档为多个小块,分别对每个小块生成摘要(Map 阶段),再将所有摘要拼接,生成最终结果(Reduce 阶段)。
-
适用场景:长篇论文、报告、多章节文档(最常用,面试必提)。
-
优劣势:适配所有长文档,结果全面;但耗时略高,需处理摘要冗余。
-
核心逻辑:拆分长文档为小块,先对第一块生成初始结果,再用后续每块内容迭代优化、补充初始结果(逐步完善)。
-
适用场景:对生成精度要求高的场景(如技术文档解读、论文总结)。
-
优劣势:结果精准、逻辑连贯;但耗时最长,不适合对响应速度有要求的场景。
-
核心逻辑:拆分长文档为「父块(大段,保留完整语义)+ 子块(小块,用于检索)」,检索时先匹配子块,再调取对应父块作为上下文。
-
适用场景:需保留长文档语义完整性的场景(如代码文档、法律条文)。
-
优劣势:兼顾检索精度和语义完整;实现稍复杂,需设计父子块拆分规则。
-
适用场景:短于 LLM 上下文窗口 20% 以内的长文档(如 3000Token 文档,窗口 4096Token)。
-
优劣势:实现简单、速度快;但易超出窗口,适合简单检索生成。
-

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 5
5 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)