体系结构论文(114):LLM-NPU: Towards Efficient Foundation ModelInference on Low-Power Neural Processing Uni
LLM-NPU: Towards Efficient Foundation Model Inference on Low-Power Neural Processing Units 【International Conference on Omni-layer Intelligent Systems (COINS)】
- 文章核心目标:让低功耗 NPU 更适合本地 LLM 推理
文章指出,现有 NPU 的优势是 TOPS/W 高、功耗低、适合端侧设备,但它们最初主要是为 CNN 等视觉任务设计的。
一旦换成 LLM,问题就来了:
- 参数量大,权重存不下/搬运代价高
- 自回归生成时,KV cache 随序列长度增长
- attention、SoftMax、LayerNorm 等算子模式和 CNN 很不一样
- NPU 通常偏好 静态 shape,但 LLM 推理天然是动态长度
所以作者要解决的是:在有限算力、有限片上存储、低功耗约束下,怎么让 NPU 也能高效跑 foundation model。- 软件侧做了什么:围绕 LLM 的内存瓶颈和执行效率做优化
文章的软件优化主要有五类:
- Fusion 与 tiling:
把 attention、FFN 中连续或并行的算子做纵向/横向融合,减少中间结果落内存,提升数据复用。- 权重量化与压缩:
用 INT8/INT4 等低比特量化,甚至结合 2:4、4:8 结构化稀疏,降低模型存储和访存压力。- KV cache 优化:
这是本文一个重点。作者提出 混合分组量化(hybrid KV quantization),并结合 KV eviction 来缓解长上下文下 KV 越积越大的问题。- 静态 shape 推理:
通过 padding、mask 和静态 KV 布局,把动态长度 LLM 改造成 NPU 友好的 static-shape inference pipeline。- Speculative decoding:
用轻量 draft model + verifier model 的方式,把串行生成变成部分并行,提升 token 生成效率。- 硬件侧做了什么:讨论未来 NPU 该怎么往 LLM 专用方向演进
主要包括:
- 从传统 systolic array 向 PiM / CiM / near-memory compute 演进
目的是减少“算存分离”导致的大量数据搬运。- Extended Input Channel Accumulation
针对 transformer 中大通道累加深度的问题,减少 partial sum 频繁写回。- 结构化稀疏加速
重点支持 2:4 这类规则稀疏,方便硬件做 zero-skipping。- 面向 transformer 的 GEMM engine 优化
因为 LLM 的核心计算比 CNN 更偏向 batched GEMM,而不是卷积。- Fusion-aware datapath
让 dequant、GEMM、bias、activation、quantization、SoftMax 等尽量在流水线里连起来。- 多精度 / MX format 支持
如 FP16、FP8、INT8、MXFP8、MXFP4 等,以便在精度和功耗之间灵活折中。
一、Introduction
1.为什么这个问题现在重要
- foundation model / LLM 本地运行需求上升
- 但本地设备功耗和内存极度受限
- NPU 因为每瓦性能高,所以是一个有前景的平台
这里最重要的一点是:
文章不是在争论“端侧要不要跑 LLM”,而是默认这已经是大趋势。
2.为什么 NPU 比 iGPU 更值得研究
文中说:
NPU 比集成 GPU 更省电,因此在 AIPC 上做 on-device LLM inference 很有价值。
这其实是在做平台比较。
隐含逻辑:
- GPU 当然也能跑 LLM
- 但 GPU 更偏重高吞吐通用并行
- 在客户端设备上,功耗和持续运行能力常常不够理想
- NPU 的定位更偏“长期低功耗 AI 加速”
所以作者想强调的是:
对 AIPC 这类平台,NPU 不一定总是最快,但可能是综合体验最合适的 LLM 推理单元。
3. 本文贡献
引言中间说:
To mitigate these gaps, we present LLM-NPU, a stream of software and hardware optimizations for LLMs.
这句话里的关键词是 mitigate these gaps。
这里的 gaps 指的是:
- LLM 对 compute/memory 的要求高
- 资源受限 NPU 难以满足
- 现有优化多数不是专门为 NPU 准备的
所以作者的任务不是彻底“发明一种全新计算范式”,而是:
系统地补上 NPU 与 LLM 之间的不匹配。
二、Related Works
这一部分主要分成两类相关工作:
- Low-Power Hardware for Foundation Models
- Model and Compiler Optimizations
1. Low-Power Hardware for Foundation Models
作者在这一段提到几个代表工作,比如:
- EdgeLLM
- ATOMUS
- NITRO
- Xu et al. 的 on-device NPU LLM inference
1.1 EdgeLLM 被拿来说明什么
文中说 EdgeLLM 采用 CPU-FPGA heterogeneous accelerator,并使用:
- mixed precision
- structured weight sparsity
这说明现有工作已经认识到:
- 低功耗平台上跑 LLM,必须做精度优化
- 稀疏和异构协同是有价值的
但 EdgeLLM 的平台是 CPU-FPGA,不等于现代客户端 NPU。
所以它可以算相关,但不能直接替代本文。
1.2 ATOMUS 被拿来说明什么
ATOMUS 是一个 latency-optimized SoC,有 hierarchical neural engines 和 task-aware scheduling。
作者引用它,是为了说明:
- 已经有人开始为大 transformer 做更专门化的 SoC 设计
- “通用 NPU”正朝“foundation model-friendly accelerator”演进
但 ATOMUS 更偏专用 SoC 级系统设计,不一定直接对应客户端 NPU 的部署模式。
1.3 NITRO 被拿来说明什么
这里的表述尤其重要:
NITRO enables dynamic autoregressive token generation for LLMs on Intel NPUs, but primarily focuses on software-level orchestration without addressing deeper architectural co-design or fusion-aware execution.
翻译过来就是:
- NITRO 已经证明 Intel NPU 可以跑 LLM
- 但它更偏运行时/软件编排
- 没有深入到架构协同、融合执行这些层面
这其实就是作者在明确区分自己与 NITRO 的差别:
我们不是只做软件调度,而是更深地讨论 NPU 架构与软件栈如何共同适配 LLM。
1.4 Xu et al. 的工作被拿来说明什么
文中说 Xu 等人的方法通过多层级 prompt/model reconstruction 降低 prefill latency 和 energy。
这说明已有工作也意识到:
- prefill 是很关键的问题
- on-device NPU 是有潜力的
- prompt/model 级重构是可行方向
但作者接着总结说:
这些方向共同表明,未来架构会走向 tightly integrated、dataflow-optimized NPU。
这句话其实是在借前人工作,进一步推出自己的核心观点:
LLM 时代的 NPU 不应该只是“原来那个 NPU 的小修小补”,而是要向 transformer-oriented、dataflow-oriented 的架构转型。
2. Model and Compiler Optimizations
这一段是第二类相关工作。
文中列出:
- model weight pruning
- token pruning
- weight/activation quantization
- operator fusion
- tiling
这部分其实是在说:
大家已经知道 LLM 需要做压缩和编译优化,这些方法也很成熟了。
但关键在后两句:
Most of these methods were developed in the context of GPU hardware, and thus, their optimal usage for NPU is not straightforward.
Additionally, NPU architecture has other limitations requiring novel software solutions...
这是 related works 里最关键的判断之一。
意思是:
- 这些优化不是没用
- 但它们原本的默认目标平台多半是 GPU
- NPU 的执行模型、片上存储、算子支持、shape 偏好不一样
- 所以不能简单照搬
比如:
- GPU 上很自然的动态调度方式,在 NPU 上可能不合适
- GPU 上可接受的 kernel 切分,在 NPU 上可能导致大量数据搬运
- GPU 上的 attention 实现,不一定适合静态 shape NPU
所以作者在这里完成了最后一个铺垫:
本文的价值就在于把这些“已有但偏 GPU 语境的优化”重新放到 NPU 语境下重构。
三、背景
NPU 架构
原文开头说:
The NPU is a domain-specific accelerator optimized for executing deep learning workloads.
这句话虽然简单,但很关键。
具体含义
NPU 的本质不是“一个小 GPU”,而是:
- 针对神经网络中高频算子定制
- 针对低功耗高吞吐优化
- 在硬件电路、数据流、存储层次上都偏向 AI workload
所以 NPU 的设计目标通常不是:
- 任意程序都能高效跑
- 控制流特别灵活
- 动态行为支持特别强
而是:
- 大矩阵/卷积类计算效率高
- 数据复用做得好
- 单位能耗下吞吐高
- 固定模式算子执行特别快
这也正是为什么 LLM 跑在 NPU 上会出现“适配问题”:
因为 LLM 既有大规模矩阵计算,又有:
- 动态长度
- KV cache
- SoftMax / LayerNorm
- 自回归控制流
它既符合一部分 NPU 擅长的模式,又不完全符合。
把 NPU 分成三个子系统
原文说,NPU 由三大子系统组成:
- control
- compute
- data movement
1. Control subsystem:控制子系统
它主要负责:
- runtime task scheduling
- synchronization
- power management
- workload distribution
为什么它重要
因为 NPU 并不是一个单一算子单元,而是一套包含多个引擎、片上存储和 DMA 的系统。
如果调度不好,就会出现:
- 算子阵列空转
- 数据没到,计算等数据
- 数据到了,算子没准备好
- 多个 engine 之间失配
所以控制子系统本质上在保证:
整个 NPU 不是局部快,而是系统级快。
2. Data movement subsystem:数据搬运子系统
这部分由:
- DMA engine
- on-chip SRAM cache
组成。
DMA 是什么
DMA(Direct Memory Access)就是一个专门负责搬运数据的模块。
它的价值在于:
- 不用让主控核心亲自一条条搬数据
- 可以高带宽、低延迟地在 DRAM 和片上存储之间传输张量
On-chip SRAM 是什么
这是片上高速存储,用来缓存:
- activations
- intermediate tensors
- 某些当前要用的权重块
它比 DRAM 快得多,但容量小得多。
作者强调的一点
文中明确说:
- weights typically reside in off-chip DRAM
- activations and intermediate tensors are buffered in SRAM
这句话特别重要。
为什么?
因为它揭示了 NPU 推理时最基础的 memory hierarchy:
- 大模型权重太大,通常放不进片上 SRAM
- 真正执行时,会把当前计算需要的那部分搬到片上
- 中间激活和临时结果尽量留在片上,避免反复访问 DRAM
这其实就是典型的 AI 加速器思路:
尽量让“正在算的数据”待在片上,让“长期存储的大模型参数”待在片外。
3. Compute subsystem:计算子系统
作者说计算子系统由一个可扩展的 AI Compute Engines array 组成。
也就是说,NPU 不是只有一个计算核心,而是有多个 AI compute engine。
这说明什么
说明 NPU 是一种:
- 可扩展
- 并行
- 面向高吞吐
的加速器组织方式。
而每个 AI compute engine 内部,又不是单一 MAC 阵列,而是一个小系统。
这就引出图里的几个模块:
- Vector DSP
- NNP
- MAC Array
- PPM
- Load
- Drain
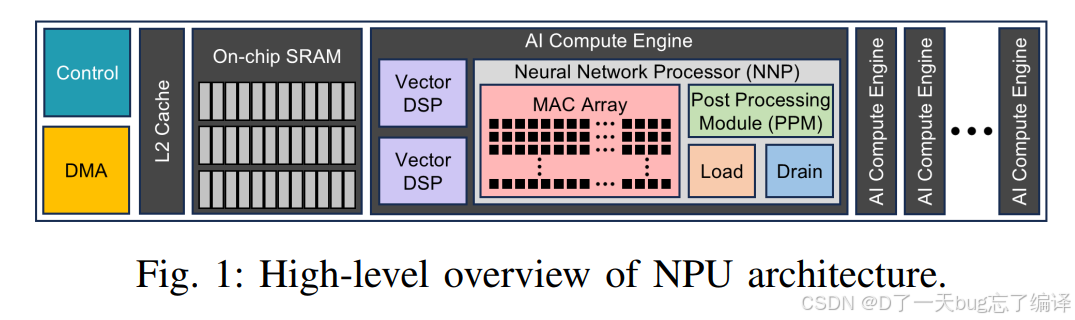
图 1 很直观,顺序大致是:
Control / DMA → L2 Cache → On-chip SRAM → AI Compute Engine(s)
每个 AI Compute Engine 内部包含:
- Vector DSP
- NNP
- MAC Array
- PPM
- Load
- Drain
这个图真正表达的是执行关系
也就是:
- 控制系统发起调度
- DMA 把数据从外部内存搬到片上
- 数据先经过 cache / SRAM
- 送入 compute engine
- 在 engine 内部完成乘加、后处理、装载、输出整理
- 多个 engine 可以并行工作
所以整张图要从“数据流 + 控制流”的角度理解,而不是只把它当功能框图。
每个 AI Compute Engine 内部
1. NNP:Neural Network Processor
作者说每个 engine 内部集成一个 fixed-function NNP。
怎么理解 fixed-function
它不是像 CPU 那样高度通用,也不是像 DSP 那样完全可编程。
它更像是一个专门为常见神经网络算子打造的“主执行通路”。
它擅长做:
- matrix multiplication
- convolution
- 一些标准神经网络后处理
这意味着 NNP 是整个 engine 的“重计算核心”。
2. MAC Array:核心乘加阵列
MAC array 用来做:
- matrix multiplications
- convolutions
为什么这是核心
因为神经网络的大头计算本质上就是乘加。
无论是 CNN 还是 transformer,最终都离不开大量 MAC。
对 LLM 来说,虽然卷积不再重要了,但 矩阵乘(GEMM)更加重要。
所以这个 MAC array 就是 LLM 推理最核心的算力来源之一。
现在这个发动机要更适合 transformer,而不是只适合 CNN。
3. PPM:Post Processing Module
作者说 PPM 负责:
- scaling
- activation
- quantization
这意味着什么
MAC array 算完以后,结果并不是直接就能输出。
往往还要做:
- scale 调整
- 激活函数
- 量化/反量化相关处理
- 其他线性后处理
所以 PPM 是一个“算完之后顺手处理”的模块。
为什么很重要
如果没有 PPM,那么每次乘加后都要:
- 写回内存
- 再调别的单元做 activation / quantization
- 又搬一次数据
那访存代价就会很高。
因此 PPM 的存在说明:
NPU 天生就有一点 fusion 的味道,想把乘加后的常见后处理直接接在后面做。
4. Load unit:装载单元
文中说它用于 memory staging。
意思是
它负责把需要计算的数据准备好、对齐好、送到合适的位置。
不是简单“搬一下数据”,而是为 compute 做前置准备。
你可以把它理解成 compute engine 内部的数据入口管理模块。
为什么需要它
因为 NPU 中的数据不是杂乱无章进来的,而是要:
- 按 tile
- 按 batch
- 按特定布局
- 按流水节奏
送入 MAC array / DSP / PPM 的。
所以 Load unit 是把外部搬进来的 tensor,整理成“可计算形态”。
5. Drain unit:输出/排出单元
文中说它用于 result formatting。
也就是说
计算完成后,结果通常也不能原封不动地直接扔回去,还要:
- 格式整理
- 布局变换
- 可能的压缩
- 输出组织
这就是 Drain 的职责。
直观上
Load 对应“输入整备”,Drain 对应“输出整备”。
这两个模块说明 NPU 不只是有个 MAC 阵列在算,而是前后都做了专门的数据组织。
6. Vector DSP:处理细粒度向量算子
这一点对 LLM 特别关键。
作者说 Vector DSP 负责:
- fine-grained elementwise operations
- non-linear functions
- transformer-specific layers such as:
- SoftMax
- LayerNorm
- other vector operations
这说明什么
说明 NPU 设计者早就意识到:
不是所有神经网络操作都适合塞进 MAC array。
MAC array 擅长:
- 大块、规则、密集的乘加
但像这些操作:
- SoftMax
- LayerNorm
- GeLU
- Swish
- elementwise add/mul
- vector reduction
往往更适合由 Vector DSP 处理。
这对 LLM 很重要
因为 transformer 中最烦人的往往不是主 GEMM,而是这些:
- 非线性
- 归一化
- attention 中的 SoftMax
- 各种向量级操作
LLM 能否高效运行,不只取决于 MAC 阵列够不够大,还取决于 Vector DSP 是否能高效接住这些“非 GEMM 操作”。
为什么这些 tightly integrated modules enable fused execution
文中说:
These tightly integrated modules enable fused execution and minimize intermediate data movement.
作者想强调,NPU 的优势不只是有很多计算单元,而是这些单元:
- 放得近
- 配合紧
- 可以流水衔接
- 可以少写中间结果
这里“fused execution”的含义
不是单纯软件层图优化,而是硬件结构本身就支持一部分融合执行。
比如:
- 乘加后紧接 activation
- 某些 vector 操作紧接主算子
- 中间 tensor 不用频繁回到外部 SRAM/DRAM
为什么这对 LLM 特别重要
因为 LLM 的很多算子链条很长。
如果每一步都独立执行、独立写回,就会:
- 带宽爆炸
- SRAM 容量紧张
- 延迟上升
- 能耗上升
所以这句话本质上是在说明:
NPU 的价值不只是 raw compute,而是 通过模块紧耦合降低中间数据搬运成本。
这也正是后面文章反复强调 fusion 的底层原因。
为什么 LLM 会卡在这个架构上
如果你从体系结构角度再往深想一步,这一节其实隐含地告诉你 LLM 在 NPU 上的三个主要冲突点。
1. 与 data movement subsystem 的冲突
LLM 的问题:
- 模型权重大
- KV cache 大
- 长上下文下带宽压力大
- decode 阶段常常 memory-bound
而 NPU 的现实是:
- 片上 SRAM 容量有限
- 大权重仍放 DRAM
- 数据搬运成本很高
所以冲突就是:
LLM 对 memory system 太苛刻,而 NPU 的高效前提恰恰是“尽量少搬数据”。
2. 与 compute subsystem 的冲突
LLM 的问题:
- 核心从 convolution 转向 GEMM/attention
- SoftMax、LayerNorm、GeLU 很重要
- 算子链条长
- 不少操作不适合单纯 MAC array
而传统 NPU 的 compute engine 可能更偏:
- CNN-style dense regular compute
- 固定式后处理
所以冲突就是:
LLM 的算子结构比传统视觉模型更复杂,要求 compute engine 既能高效做 GEMM,又能高效处理大量非线性/vector ops。
3. 与 control subsystem 的冲突
LLM 的问题:
- 自回归生成有动态控制流
- 输入输出长度不固定
- decode/prefill 行为不同
- speculative decoding 又引入异构协同
而 NPU 往往更喜欢:
- 静态图
- 静态 shape
- 规则调度
- 固定 buffer
所以冲突就是:
LLM 天然偏动态,而 NPU 天然偏静态。
四、软件
原文说:
We focus on cross-layer techniques that address memory bottlenecks, reduce redundant computation across tokens, and enhance hardware utilization through dynamic shape handling and control-flow aware execution...
这句话其实就是这一节的总纲。
它的意思是,作者的软件优化不是零散技巧,而是围绕三个目标展开:
1. address memory bottlenecks
解决内存和带宽问题。
这是 LLM on NPU 最根本的问题之一。
2. reduce redundant computation across tokens
减少生成过程中跨 token 的重复计算。
这主要对应 decode 阶段。
3. enhance hardware utilization through dynamic shape handling
通过处理动态 shape,让 NPU 利用率更高。
这说明作者非常清楚:
NPU 的难点不只是算不动,而是“算得不规整,导致利用率上不去”。
A. Fusion and Tiling Strategies
这一部分是软件优化的第一块,也是最基础的一块。
1. 为什么 LLM 特别需要 fusion 和 tiling
作者先说:
LLM inference presents unique challenges due to complex operator sequences... including SoftMax and LayerNorm, and memory-intensive components like attention, where storage and bandwidth demands scale quadratically with sequence length.
这句话有两层意思。
第一层:LLM 的算子链更复杂
比如:
- GEMM
- SoftMax
- LayerNorm
- activation
- masking
- transpose / reshape
这些操作不像单纯卷积那样“一个主算子吃掉大部分时间”,而是很多步骤串起来。
第二层:attention 特别吃内存
因为传统 attention 中会涉及和序列长度相关的中间矩阵。
序列越长,存储和带宽压力越大。
所以作者这里是在说:
LLM 推理的问题不是单个算子不够快,而是整个算子链条太长、数据流太重。
这正是 fusion 和 tiling 发挥作用的地方。
2. Tiling 为什么重要
作者说:
In LLMs, spatial and temporal tiling strategies are employed ... to partition large attention and FFN layers ... to fit within limited on-chip memory.
本质含义
把一个很大的计算任务切成若干小块(tiles)来做,使每块能装进片上 SRAM / 寄存器 / 本地 buffer。
在 LLM 中常见的切分维度
文中提到:
- sequence length
- head
- embedding dimension
也就是说,attention 或 FFN 不会整块直接算,而是按这些维度切片。
为什么必须这样做
因为 NPU 的片上存储有限。
如果你不切:
- Q/K/V 放不下
- 中间激活放不下
- attention score 放不下
- 结果就是频繁访问 DRAM,性能和能效都会崩
作者强调的一点
tiling 不是机械切块,而是要结合:
- layer shape
- hardware constraints
所以它不是简单工程细节,而是 编译器和硬件共同决定的数据流设计问题。
3. Vertical Fusion(VF)是什么
作者接着讲纵向融合。
this strategy reduces off-chip memory accesses by fusing dependent operations.
也就是把前后有依赖关系的串行操作融合起来执行。
3.1 Inter-operator VF:跨算子纵向融合
文中举的是 attention 的例子:
- QKT
- masking
- SoftMax
- V projection
这些步骤原本是一个一个独立操作。
融合后,数据可以在流水线里连续走,而不是每一步都写回片上/片外内存。
这为什么有效
因为 attention 最贵的不只是乘法,而是:
- 中间分数矩阵的存储
- 不同步骤之间的数据搬运
- 不同硬件单元之间反复传递
作者引用 FlashAttention 的核心思想就是:
- 把 Q/K/V 分块
- 不显式物化完整的 N×N attention matrix
- 让数据分块流过系统
对 NPU 的意义
这正好适合 NPU 的片上存储受限场景。
因为 NPU 最怕“中间大矩阵落地”。
3.2 Intra-operator VF:算子内部纵向融合
文中说:
pipelining sequences such as dequantization, GEMM, activation, and re-quantization...
这类融合不是跨大算子,而是在一个算子内部把多个子步骤接起来。
例如:
- 先反量化
- 再 GEMM
- 再 activation
- 再量化
如果不融合,这些步骤之间也会有大量中间结果写回。
融合之后,就能:
- 最大化 register reuse
- 减少 on-chip memory traffic
本质
这是在把一个“多阶段处理链”压成一个更连续的流水过程。
特别适合低精度推理和量化模型执行。
4. Horizontal Fusion(HF)是什么
作者接着讲横向融合。
Horizontal fusion merges operations across independent branches with shared input activations or weights...
这是把并行分支合起来。
文中举了两个典型例子:
- attention 里的 Q/K/V projections
- FFN 中的 gate 和 up-projection
为什么横向融合有效
因为这些分支通常:
- 输入相同或相近
- 数据流并行
- 如果分别执行,会重复读输入、重复调度 kernel
融合后好处是:
- 提高 arithmetic intensity
- 减少 kernel overhead
- 更好利用加速器资源
直观理解
纵向融合是“上下连起来”。
横向融合是“左右并起来”。
这两种融合配合,目的都是一样的:
少搬数据,少调度碎片,更多在片上连续完成。
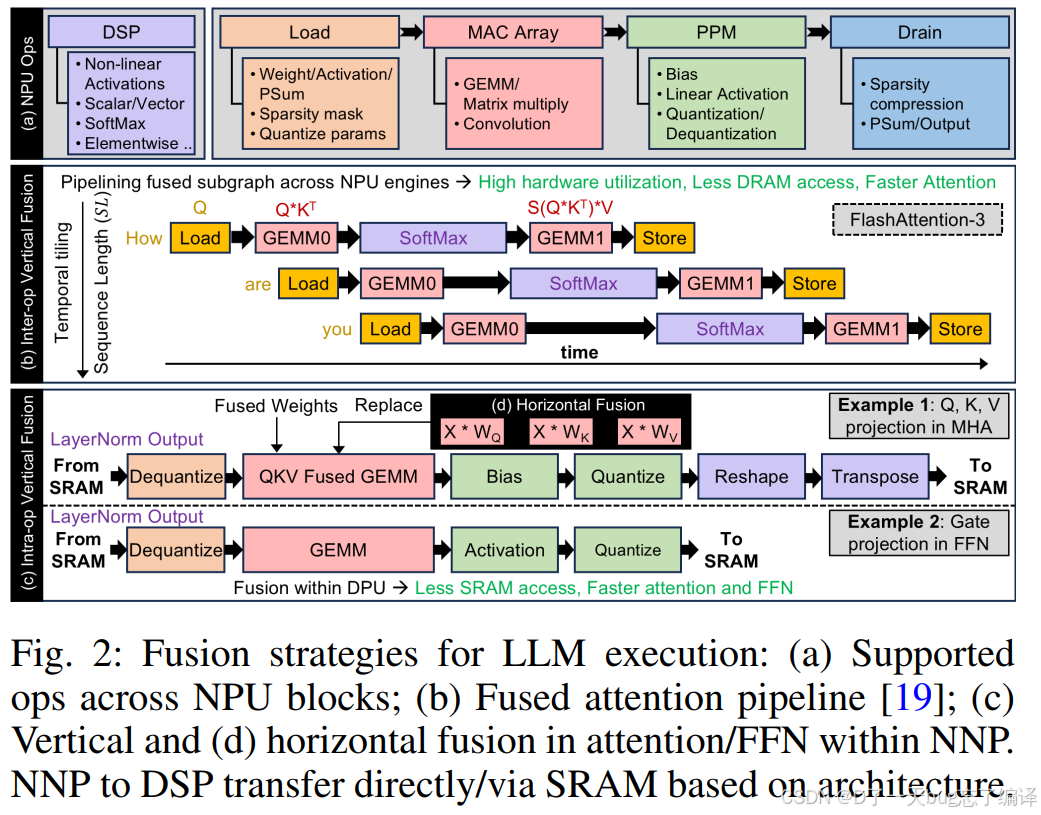
图 2
(a) Supported ops across NPU blocks
说明 NPU 内部不同模块分别适合做哪些操作:
- DSP 做非线性、SoftMax 等
- MAC array 做 GEMM
- PPM 做量化/激活等
这说明 fusion 不是抽象概念,而是要落到具体硬件模块映射上。
(b) Fused attention pipeline
说明 attention 可以做成一种流水线式执行,而不是一堆分散 kernel。
(c) Vertical fusion in NNP
说明量化/乘法/激活这些可以串起来。
(d) Horizontal fusion in attention / FFN
说明多个投影分支可以合并。
作者理解的软件优化,不是简单图级简化,而是“面向 NPU 结构的数据流重组”。
B. Weight Compression
这一部分讲的是权重压缩。
1. 为什么要做权重压缩
作者说:
LLMs often contain billions of parameters...
这是最直接的现实问题。
LLM 参数太多,导致:
- 模型体积大
- 内存占用高
- 权重访存延迟高
- prefill / decode latency 上升
对现代 NPU 来说,这尤其致命,因为:
- 片上 SRAM 很小
- 权重大多在 off-chip DRAM
- DRAM 访问昂贵
所以权重量化的第一目的不是“理论压缩”,而是:
减少 NPU 实际执行中的内存与带宽压力。
2. 量化方式
文中提到:
- INT8
- INT4
- INT2
- per-channel / per-group
- symmetric / asymmetric quantization
这说明他们关注的不是单一量化方法,而是整套低比特权重表示方式。
重点有两个
第一,按组/按通道量化
因为不同权重分布差异大,统一量化往往精度损失大。
所以要按更细粒度做。
第二,校准和后训练量化
作者说会用 representative inputs 做 calibration,说明这里主要考虑的是 post-training quantization 场景。
这很符合端侧部署现实:
模型往往已经训练好了,部署时才做压缩。
3. 量化后怎样对接 NPU
原文说:
Compiler backends then lower the quantized models to NPU-executable form...
说明量化不是最后一步,后面还有:
- 插入 quantize/dequantize op
- 选择合适低精度 kernel
- 进一步融合量化算子序列
- 根据 NPU 架构组织权重布局
所以作者的视角是系统视角,不是模型视角。
真正要问的是:
量化后的模型,能不能被 NPU 编译器和 kernel 栈高效接住?
这和很多只关心 perplexity 掉多少的量化论文不一样。
4. 为什么又提到 N:M sparsity
文中后面说:
N:M sparsity for weights has remained a practical optimization...
然后提出把 低比特权重 + 2:4 / 4:8 稀疏 联合起来。
意味着什么
作者不是把“量化”和“稀疏”当两个孤立方向,而是想做组合压缩。
因为:
- 量化减少每个参数的位宽
- 稀疏减少有效参数数量
两者合起来,可以进一步减少:
- 存储
- 带宽
- 乘加计算
这也为后面硬件部分的 structured sparsity support 做铺垫。
C. KV caching and KV compression
这一部分是全文最关键的软件点之一。
1. KV caching 为什么重要
作者说:
Repetitive recomputation of the KV during the decode phase can significantly affect the throughput.
这是 transformer decode 的核心问题。
原因
在自回归生成时,每生成一个新 token,如果你都重新把历史 token 的 K/V 重新算一遍,代价太大。
所以标准做法是把历史的 K/V 缓存下来,也就是 KV caching。
这带来的收益
减少重复计算,提高 decode throughput。
但新问题来了
KV cache 会随着序列增长而持续变大。
所以 KV caching 一边解决了“重复算”的问题,一边制造了“内存越来越大”的问题。
2. 为什么 KV 成为 decode 阶段的瓶颈
文中说:
for quadratic autoregressive models, the KV cache grows linearly with the sequence length, further intensifying the memory bottleneck of the decode stage.
这里容易混:
attention 计算本身在某些角度是和序列长度强相关的;而 KV cache 本身会随着历史 token 线性增长。
对 NPU 来说,致命点在于:
- KV 越长,占用内存越多
- 读取 KV 的带宽需求越大
- decode 每个 token 都要碰它
- 所以 decode 往往越来越 memory-bound
这正是为什么作者把 KV 作为重点优化对象。
3. KV cache quantization
作者提出两类方案:
- KV cache quantization
- KV eviction
先说量化。
核心做法
- K 用 per-channel grouping
- V 用 per-token grouping
- 这叫 hybrid group quantization
为什么 K 和 V 分开处理
因为作者观察到 K 和 V 的分布特性不同。
如果强行统一分组方式,精度未必最好。
这说明作者是从张量统计特性出发来设计压缩,而不是“对 KV 一刀切”。
还有一个细节很重要
作者说:
- 每组共享 FP16 scale 和 zero point
- 最近的一些 token 仍保持 FP16
这意味着他们不是极端压缩,而是用了“部分高精度保留”的策略。
这样做的目的就是:
- 降低量化误差
- 保持生成质量
- 减少频繁重重量化的开销
这是一种很实用的工程折中。
4. 为什么 hybrid grouping 比 per-channel 更好
文中明确说,实验上:
- hybrid grouping
- per-token grouping
都明显优于“两个张量都做 per-channel grouping”。
这说明什么
说明 KV 压缩不是传统 weight quantization 的简单复制。
KV 是运行时动态张量,它的统计特征、时序意义、最近 token 敏感性都不一样。
所以作者实际上是在强调:
KV cache 是一个值得单独设计压缩策略的对象,不应直接照搬权重量化思路。
5. KV eviction:为什么量化还不够
作者说:
Only quantization may not be sufficient ... specifically for sequence length ≥ 4K.
这非常合理。
因为即使 4-bit 压了很多,序列特别长时,KV 还是会越来越大。
所以作者提出第二步:eviction。
eviction 的本质是什么
不是压小每个 KV,而是直接扔掉一部分 KV。
为什么可以扔
因为并不是所有历史 token 对当前生成都同等重要。
某些层、某些 head、某些时间窗口里的历史信息更关键。
作者采用的是基于 observation window (OW) 的策略:
- 关注最近的一段 prefill tokens
- 从中观察每个 head/layer 更关注哪些特征
- 进而决定保留哪些 KV
本质理解
这是把 KV cache 从“无脑全留”改成“有选择地保留”。
已经很像 memory management / cache policy 了。
D. LLM Static Shape Inference
1. 作者为什么要单独讲 static shape
原文说:
LLMs generally generate variable-length sequences with dynamic input/output shapes. In contrast, modern NPU accelerators favor static-shaped tensors...
这就是 LLM 和 NPU 的根本冲突之一。
LLM 的特点
- prompt 长度可变
- response 长度可变
- decode 是逐 token 增长的
NPU 的偏好
- 固定 shape
- 静态分配 buffer
- JIT/编译优化更稳定
- runtime overhead 更低
所以如果不处理这个冲突,NPU 上的 LLM 就会:
- 难编译
- 难优化
- 难保持高利用率
这就是 static-shape inference 出现的原因。
2. static-shape inference 的核心思想是什么
作者说,NPU 编译器使用 graph-level 和 runtime-level 的 lossless optimizations,把 dynamic LLM 变成 static-shape equivalent。
关键字是 lossless。
意思是:
- 不是改模型语义
- 不是牺牲结果正确性
- 而是执行形式重构
基本思路
- 把输入右填充到最大 prompt 长度 SLP
- 把 decode 相关 mask 和 KV 右填充到最大 response 长度 SLR
- 用 mask 保证真正有效计算只发生在真实 token 上
- 通过固定布局和静态 buffer,实现“外表静态、语义动态”的执行
这其实是一个非常经典但非常实用的系统技巧。

这个算法标题是:
Static Shape Inference for LLM Decoder with Optimized KV Cache
它的逻辑可以按阶段理解。
阶段 1:Prefill 预处理
- 把输入 IDs、mask、position IDs 右填充到 SLP
- 跑 decoder
- 得到 logits 和 KV
- 第一个输出 token 进结果序列
这一步的意义
- prefill 阶段就把 prompt 的静态形状固定住
- 生成一个固定长度布局的 KV cache
阶段 2:为 decode 做静态准备
把 mask 和 KV 进一步 pad 到 SLR
意义
为后续最多生成到 SLR 个 token 预先留好位置。
阶段 3:循环 decode
每轮:
- 设置当前位置
pos_decode - 只输入上一个 token
- 配合 padded mask 和 padded KV 运行 decoder
- 用
pos_decode更新对应位置的 KV - 取 argmax 追加输出
意义
虽然 decode 是逐 token 的动态过程,但底层 buffer 和形状始终保持静态。
这就是整套方法最核心的地方:
动态语义,静态执行壳。
4. 什么叫 KV zero-copy update
优化后不需要整块重写大小为 SLR的 KV cache,而是 CPU 直接把新计算出的 K/V 插到目标位置。
没优化时的问题
每次生成一个 token,如果都重写整个 KV buffer:
- 写流量非常大
- SRAM 到 DRAM 来回复制
- latency 和 energy 都很差
zero-copy update 的思想
只把新 token 对应的那一小部分 K/V 写到对应位置,不复制整块 KV。
为什么这对 NPU 有价值
因为 NPU 片上/片外存储层次非常敏感。
减少一次整块 buffer copy,常常比少几次乘法更值钱。
所以 KV zero-copy update 本质上是:
用增量更新替代整体重写。
5. layout-aware storage formats 为什么重要
作者还说,KV cache 的存储布局专门设计过,以避免 attention 计算时再做昂贵 transpose。
这说明作者非常关注一个典型系统问题:
- 张量数学上是一样的
- 但布局不同,代价天差地别
如果布局不合适,attention 时就要:
- transpose
- reorder
- 再写回
- 再读出
这会让 NPU 很痛苦。
所以 static-shape inference 不只是 pad 一下,而是连 KV 的物理布局也一并设计。
E. Speculative Decoding on Static-Shape NPUs
1. speculative decoding
前面已经解决了:
- KV cache
- static-shape 执行
- decode 的基础执行框架
接下来作者想进一步加速 token 生成,所以引入 speculative decoding。
2. speculative decoding 的本质
作者说:
speculative decoding converts sequential generation to parallel generation with the help of a draft-verifier strategy.
也就是说:
- 一个小模型先快速猜几个 token
- 大模型再并行验证这些 token
- 从而减少大模型逐 token 慢慢生成的代价
核心价值
把原本严格串行的生成,变成部分并行。
这对 decode latency 很有帮助。
3. 本文的设计有什么特别
作者这里说:
- draft model 一般跑在 NPU 上,用 static-shape pipeline
- verifier model 异步跑在 CPU 或 GPU 上
这说明什么
作者不是只在单个 NPU 内部想办法,而是把整个平台的异构资源都调动起来。
也就是说:
- NPU 负责高能效的草稿生成
- CPU/GPU 负责验证
- 多个 compute IP 协同工作
五、架构
We focus on the transition toward domain-specialized designs that prioritize throughput, minimize latency, and enhance energy efficiency across inference and training workloads.
作者在讲一种架构转型趋势。
也就是:
- 不再满足于“通用深度学习 NPU”
- 而是要做 更专门面向 foundation model / LLM 的 NPU
- 目标依然是三件事:
- 更高吞吐
- 更低延迟
- 更高能效
A. Systolic to Compute-in/near-memory Transition
这一部分是整节最根本的架构判断。
1. 为什么作者先批判传统 systolic array
作者先说:
Systolic arrays have long been a staple in deep learning accelerators...
也就是说,systolic array 一直是深度学习加速器的经典方案。
它的优点是:
- 空间复用好
- MAC 流水同步
- 算术强度高
这在 CNN 时代非常成功。
但作者紧接着指出问题:
随着 LLM 规模和复杂度上升,出现了:
- sparse attention
- variable-length sequences
- irregular memory accesses
这些特性会导致:
- systolic utilization 下降
- 数据搬运开销变大
所以问题不在于 systolic array “不能算”,而在于:
它的效率越来越受制于数据搬运,而不是纯乘加能力。
2. 什么叫 compute and memory physical decoupling
作者说:
The physical decoupling of compute and memory ... leads to increased latency and energy consumption...
这是这部分的核心。
意思是
传统架构里:
- 存储在一边
- 计算在另一边
- 数据要不断在两者之间搬运
而在 LLM 中:
- 权重大
- 激活多
- KV cache 大
- attention/GEMM 频繁访问数据
所以“搬数据”这件事本身就变得非常贵。
为什么会贵
因为每次搬运都要付出:
- 带宽成本
- 延迟成本
- 能耗成本
所以作者的判断是:
LLM 时代,算存分离本身已经成为主要瓶颈之一。
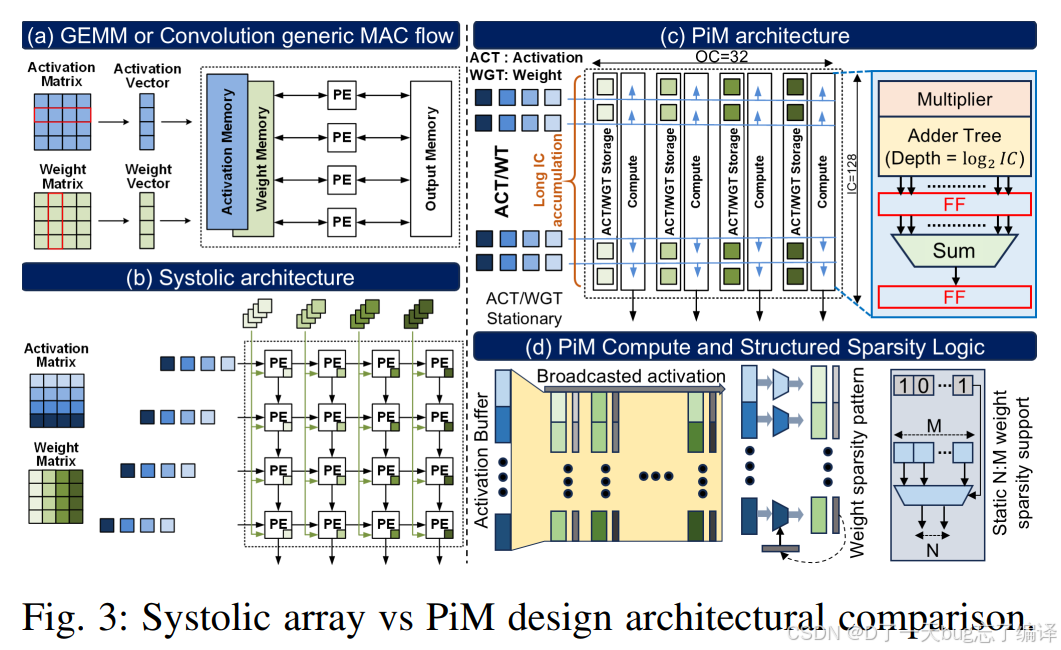
图 3 是这一部分最重要的图。
(a) Generic MAC flow
表达的是传统矩阵/卷积计算流程:
- activation 从 memory 来
- weight 从 memory 来
- 送到 PE 做 MAC
- 结果再写到 output memory
这就是典型的“算存分离”。
(b) Systolic architecture
展示的是阵列式 PE 之间传递数据的方式。
说明 systolic array 的优势来自:
- 数据在阵列内传播
- 局部复用较好
但即便如此,activation 和 weight 仍然是从外部存储体系进来的。
(c) PiM architecture
这里就变了。
图里表达的是:
- 存储和计算更靠近
- 数据在 memory fabric 附近/内部被处理
- 支持更长的 IC accumulation
未来 LLM NPU 要把更多计算靠近数据所在位置,而不是继续把数据反复拉到远处去算。
4. PiM / CnC / CiM 分别是什么
作者列了三类 memory-centric paradigms:
- PiM: processing-in-memory
- CnC: compute-near-cache
- CiM: compute-in-memory
它们的共同目标
都是:
让计算更靠近存储层次,减少 off-array / off-memory 数据移动。
粗略区分
- CnC:在 cache 附近做计算
- PiM:更广义,强调在 memory hierarchy 旁边做处理
- CiM:更进一步,直接在 memory 内部/阵列中做计算
作者这里说明一种统一趋势:
memory-centric compute 正在成为 LLM 加速器的重要方向。
4. 为什么 transformer 更适合 weight-stationary
作者说:
- activation-stationary 在卷积里有用
- 但很多 transformer workload 更适合 weight-stationary
意思是
对 CNN 来说,某些时候保持激活不动、让权重流动是合理的。
但对 transformer/LLM,很多情况下更有价值的是:
- 把模型权重常驻在 memory 附近
- activations/token 流过来
- 反复使用这些权重
为什么合理
因为 LLM 中:
- 权重大
- 同一层权重会被多个 token/多个位置 repeatedly 使用
- 若权重每次都搬,代价极大
所以 weight-stationary 的意义是:
把最贵、最重、最常复用的那部分数据固定住。
5. 作者想用这部分得出什么结论
最后他说,已有数字近存/存内设计在 LLM inference 上实现了:
- 3×–5× energy efficiency
- 2× latency improvement
然后得出结论:
随着模型继续变大,把计算移向 memory 是一个 scalable path forward。
也就是说,这部分不是单纯介绍 PiM,而是在给出一个架构判断:
如果未来 LLM 继续变大,那么光堆传统阵列不够,必须在“算存关系”上重新设计。
B. Extended Input Channel (IC) Accumulation
1. 什么是 IC accumulation
这里的 IC 指 input channels。
在矩阵乘/transformer 层里,你可以把它理解成:
- 参与累加的那个“深度维度”
- 也就是很多乘加后要沿着某一维不断 accumulate 的长度
为什么这在 LLM decode 中痛
作者说 decode 阶段很 memory-bound,尤其后期层:
- context embedding 很大
- attention / MLP 张量 rank 很高
- 参与累加的通道数可能非常多
所以 MAC 阵列要对很长的 IC 做累加。
传统 MAC array 为什么在这里吃亏
文中说:
Traditional MAC arrays ... struggle with long IC accumulation due to shallow on-chip buffers...
意思是传统阵列通常只擅长:
- 分 tile 做 GEMM
- 快速做局部累加
但如果 IC 很长,就会出现:
- partial sum 放不下
- 需要频繁写回 DRAM 或 shared scratchpad
- 再读出来继续累加
后果
- latency 增大
- energy overhead 增大
- pipeline stall
- compute bandwidth utilization 降低
这本质上就是:
中间和(partial sum)留不住。
3. PiM 为什么能改善这个问题
作者说 PiM 支持 extended IC accumulation depth,通过:
- local register folding
- periphery-latched partial sums
实现更长窗口的本地累加。
通俗理解
就是:
- 不要算一点就把 partial sum 刷出去
- 而是在更靠近计算的位置多攒一会儿
- 尽量在本地把更长的累加做完再写结果
这样做的好处
- DRAM traffic 降低
- temporal locality 更好
- arithmetic intensity 提高
- 特别适合宽 embedding vector 的 transformer 层
所以这一节本质在强调:
LLM 的很多瓶颈不是“乘不够快”,而是“中间和存不住”。
C. Sparsity Acceleration and Compression
这一部分讲的是稀疏支持,尤其是结构化稀疏。
1. 作者为什么强调 structured sparsity,而不是 unstructured sparsity
文中说:
- LLM 权重可以具有显著稀疏性
- 但 unstructured sparsity 会导致:
- irregular memory access
- high control complexity
这是什么意思
非结构化稀疏从数学上很灵活,但对硬件很不友好。
因为你不知道非零值在哪里,执行时需要:
- gather/scatter
- 复杂索引
- 很多 mux / dispatch logic
这会让硬件控制逻辑变得很重。
所以作者强调的是:
- 2:4 fine-grained structured sparsity
- 每 4 个元素里固定有 2 个非零
这样就规整了很多。
2. 为什么 2:4 这种格式对硬件友好
作者说这种格式带来:
- predictable scheduling
- reduced indexing overhead
- simplified hardware design
本质上
因为规则固定,所以:
- 编译器可以提前安排
- 硬件不用做复杂查找
- dispatch 路径更简单
- zero-skipping 更容易实现
3. “Zero-skipping pipelines” 到底在说什么
意思是:
- 知道哪些值必定为 0
- 那些乘法根本不做
- 非零项被 selectively routed
这样就避免了:
- 浪费 MAC
- 浪费访存
- 浪费能耗
所以 zero-skipping 不是后处理,而是执行路径上的“跳算”。
对 LLM 来说,支持 structured weight sparsity 不是 mere optimization,而是 foundational requirement.
也就是说作者认为:
随着 LLM 越来越大,结构化稀疏不再只是锦上添花,而会成为未来高能效推理的基础能力之一。
D. GEMM Engine Optimization
1. 为什么作者说 LLM workloads fundamentally differ from CNNs
因为计算核心变了。
CNN 时代
更多是:
- convolution-heavy
- 7D tensor style op patterns
- 需要 im2col、dilation、reuse buffer 等结构
LLM / transformer 时代
核心变成:
- dense batched GEMMs
- attention-related matrix multiply
- FFN matrix multiply
所以作者想强调:
如果 NPU 的主 datapath 还是按卷积思路优化,那就和 LLM 的主需求错位了。
2. 作者认为 GEMM engine 应该怎么优化
文中提到:
- flexible tiling
- quantization-aware partitioning
- batched GEMM support
- load-compute-store pipeline
- double-buffered SRAM
- wide MAC lanes
- attention-aware memory layout
这些词背后的本质
都是在回答一个问题:
怎样让矩阵乘成为真正的“硬件第一公民”。
换句话说:
- GEMM 不该只是复用卷积硬件顺带支持
- 而应该是专门优化对象
这很符合 LLM 时代的现实。
E. Operator and Dataflow-Level Fusion
1. 为什么硬件也要 fusion-aware
作者列出一长串操作:
- dequantization
- GEMM
- bias addition
- activation
- quantization
- reshape
- transpose
意思是:
如果这些步骤都拆开做,数据会在模块之间来回移动,代价很大。
所以 fusion-aware datapath 的目标是:
- 让这些操作在一条紧耦合流水中连续完成
- 尽量在 accelerator 内部重用 operand
- 降低中间结果存取开销
这说明作者很明确地认为:
仅有软件 fusion 不够,硬件不支持,收益会被大幅吃掉。
2. 作者这里顺便再次解释了 NPU 内部四阶段
文中说现代 NPU 有四阶段分别做:
- Load:dequantization、structured sparsity handling
- MAC:GEMM / convolution
- PPM:bias、scale、linear/partial-linear activation、quantization
- Drain:sparse compression on output
DSP 则负责:
- SoftMax
- LayerNorm
- non-linear activations
- transpose 等
3. 为什么作者专门拿 SoftMax 说事
因为 SoftMax 是 attention 中最麻烦的一步之一:
- 有 exponentiation
- 有 division / normalization
- 对数值精度敏感
- 不像普通 GEMM 那么规则
所以即使 activations 已经 INT8 化,SoftMax 往往还需要 FP16 或更高。
这意味着什么
LLM NPU 不能只会低精度 MAC,
还必须支持:
- mixed precision
- 特殊函数硬件/近似
- reduction 和 normalization
所以 SoftMax 在这里其实是一个代表性算子,说明:
LLM 的难点不只是大矩阵乘,还有一批“数值要求高、结构不规则”的关键操作。
F. Programmable Activation Functions
这一部分讲的是非线性激活函数如何高效做。
1. 为什么要单独拿 activation 说一节
因为 LLM 里常见:
- GeLU
- SiLU
- Sigmoid
这些都不是简单 ReLU。
如果全用高精度通用计算单元硬算,成本较高。
所以作者提出一种常见硬件思路:
programmable piecewise polynomial unit (PPU)。
2. PPU 是怎么工作的
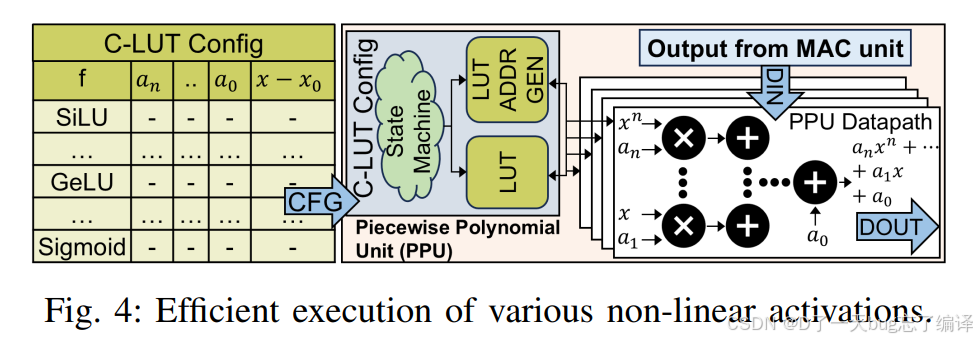
- 用 C-LUT 存预计算系数和分段边界
- 根据输入落在哪个区间,选对应多项式
-
通过 MAC datapath 计算:
f(x)≈anxn+⋯+a1x+a0
这意味着什么
不用专门为每个激活函数造一套电路,
而是用“分段多项式逼近 + 可编程 LUT”的方式统一处理。
G. Multi-Precision and MX Format Support in Hardware
1. 为什么要支持这么多精度格式
核心原因
不同 tensor 的容错性不同:
- 有些适合 INT8
- 有些适合 FP8
- 有些适合超低比特做存储压缩
- 有些步骤还需要 FP16 累加或计算
所以未来 NPU 不能只支持一种固定数值格式,而要有多精度协同能力。
2. 什么是 MX format,作者为什么重视它
MX 格式本质上是 microscaling 思路:
- 每个 group 共享 scale
- exponent / mantissa 位宽可以灵活调节
- 更适合在精度和压缩之间做细粒度折中
文章为什么强调它
因为它比传统固定 FP/INT 格式更灵活,
特别适合 LLM 这种不同层、不同 tensor 精度需求差异很大的场景。
所以作者的判断是:
未来 NPU 要原生支持这类 group-wise、可调精度格式。
3. 为什么 ultra-low precision 常用于 memory compression,而不是直接 native compute
作者说:
- INT8 / FP8 往往是 native compute type
- INT4 / INT2 / FP4 更多用于 memory compression
- 运行时再 up-convert 到 FP8/INT8
原因
因为位宽太低时:
- 直接做原生乘加,误差和硬件复杂度问题都很突出
- 作为存储格式更实用
- 读取时再转换到更高精度算
这是一种非常典型的系统折中:
存的时候尽量省,算的时候保留足够数值稳定性。
4. 为什么作者强调 mixed-precision ALUs 和 format conversion
因为如果真要支持多种格式,硬件必须能做:
- FP16-FP8
- FP8-INT4
- 运行时转换
- 灵活量化单元调度
这通常由 PPM 等模块 orchestrate。
所以“支持多精度”不是文档上写几个 datatype 名字,而是:
硬件数据通路、ALU、量化单元都要真的能处理它们。
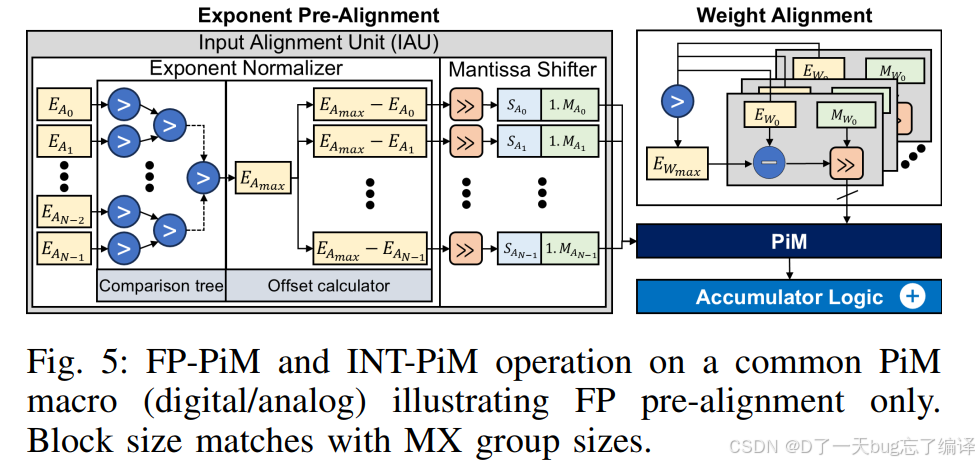
图 5 讨论的是:
FP-PiM and INT-PiM operation on a common PiM macro
以及 pre-alignment / post-alignment 的思想。
核心含义
作者在说:
- 某些低精度 FP 计算可以借助“指数感知重解释”复用 INT-style array
- 这样不用专门造一套完全独立的 FP 阵列
pre-alignment 与 post-alignment
- pre-aligned:逻辑简单、能效更好
- post-aligned:精度更好,但硬件成本更高
这又体现了整篇文章一贯的思路:
LLM NPU 设计本质上就是在数值精度、硬件复杂度、功耗三者之间找平衡。
六、实验
作者的实验实际上分成两大类:
- 准确率分析(Accuracy Analysis)
看各种压缩/稀疏/KV 优化会不会把模型效果搞坏。 - 硬件性能分析(Hardware Performance Analysis)
看这些优化到底能不能带来:- 更低 TTFT
- 更低 TPOT
- 更低能耗
- 更好的 Joules/token
A. Models and Datasets
1. 用了哪些模型
作者主要评估了两类 LLM 家族:
- LLaMA
- Qwen-2.5
文中还说明,这两类模型都是 decoder-only transformer,并且用了 GQA(grouped query attention)。
这里选这两类模型的目的很明确:
- LLaMA:代表主流开源基础模型
- Qwen-2.5:代表另一类性能较强、训练和后训练更先进的模型
所以作者不是只在单一模型上做实验,而是在两类主流结构上验证趋势。
2. 用了哪些 benchmark
常规能力 benchmark
从 LM Harness 里选了:
- MMLU
- Winogrande
- ARC-c
- ARC-e
- PIQA
- BoolQ
- HellaSwag
- lambada-openai
其中:
- MMLU 是 5-shot
- 其他大多是 zero-shot
长上下文 benchmark
又用了:
- LongBench
- RULER
这说明作者实验分工很清楚:
- LM Harness:看一般语言理解/推理能力受不受影响
- LongBench / RULER:看长上下文和 KV 优化是否有效
这个设计是合理的,因为:
- 权重量化、稀疏这些主要先看一般精度
- KV eviction / KV quantization 更应该看长上下文任务
B. Results: Accuracy Analysis
这一部分重点验证三类事情:
- N:M sparsity 会不会伤精度
- KV cache 优化会不会伤精度
- weight-only quantization 会不会伤精度
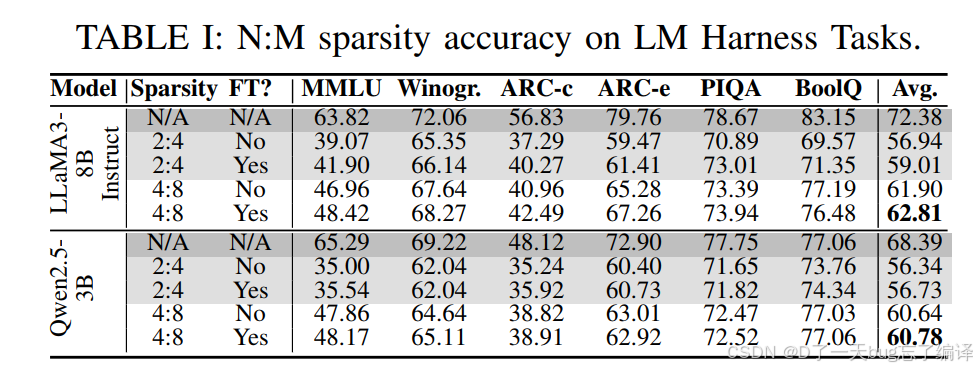
表 1 标题是:
N:M sparsity accuracy on LM Harness Tasks
它比较了:
- baseline(不稀疏)
- 2:4 sparsity
- 4:8 sparsity
- 是否 fine-tune(LoRA-based recovery FT)
模型包括:
- LLaMA3-8B Instruct
- Qwen2.5-3B
作者明确总结:
- 4:8 consistently better than 2:4
- 4:8 平均可比 2:4 好不少
- 少量 fine-tuning 还能恢复部分精度
从表里可以直接看出什么
- 稀疏会掉点,而且掉得不小
- 但 4:8 比 2:4 更温和
- FT 有帮助,但恢复幅度有限,尤其对 Qwen 没那么明显
为什么 4:8 比 2:4 更好
从比例上看:
- 2:4:每 4 个保留 2 个,稀疏率 50%
- 4:8:每 8 个保留 4 个,表面稀疏率也是 50%
但 4:8 的“分组粒度更大”,约束更宽松。
所以在相同压缩率下,4:8 往往更容易保住重要权重模式。
作者想说明的是:
结构化稀疏不是越细粒度越好,规则设计会显著影响精度。
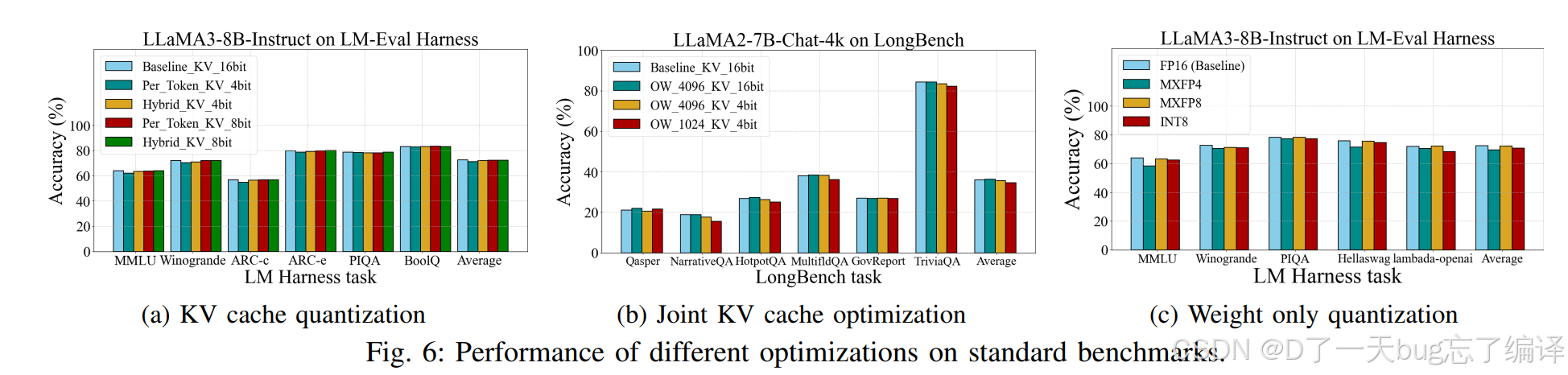
1. 图 6(a):KV cache quantization
标题是:
LLaMA3-8B-Instruct on LM-Eval Harness
作者结论
- hybrid grouping 优于 per-token grouping
- 4bit 时优势更明显
- 文中说 4bit 下 hybrid 比 per-token 高 1.2%
这说明什么
这验证了前面软件节提出的观点:
K 和 V 用不同 grouping 策略是有意义的。
也就是说,KV 不能简单照搬统一量化方式。
特别在低比特(4bit)下,合理的分组设计更重要。
从图上直观看:
- baseline 和 hybrid 8bit 很接近
- hybrid 4bit 也没有出现灾难性下降
- per-token 4bit 相对掉得更多
这意味着:
- 8bit KV quantization 基本比较安全
- 4bit 虽有损失,但 hybrid 方式能控制住
- KV 压缩是可行的,不是只能停留在论文概念层面
3. 图 6(b):joint KV cache optimization
标题是:
LLaMA2-7B-Chat-4k on LongBench
这里 OW 指 observation window 相关 eviction 设置。
结果含义
作者要说明:
- 只做 eviction 可以接受
- eviction + 4bit quantization 联合起来也能保持比较小的精度损失
- 即便 KV budget 降到 1024,平均性能也没有崩掉
换句话说,这不是“非此即彼”的方案,而是:
- 先压低 KV 位宽
- 再减少 KV 数量
- 在长上下文场景里同时控内存与带宽
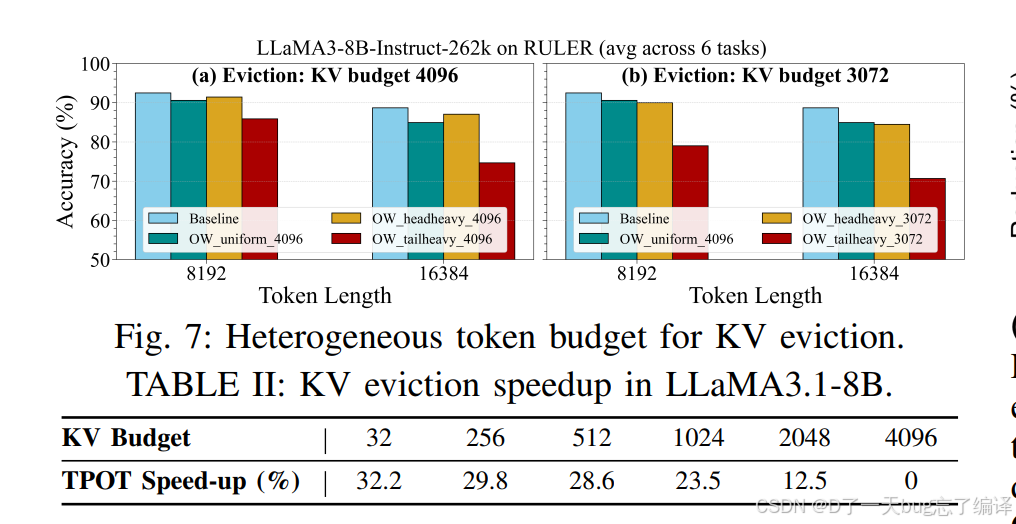
1. 图 7:Heterogeneous token budget for KV eviction
图 7 研究的是一种更细粒度的 eviction 策略:
- head-heavy:前 16 层高预算,后 16 层低预算
- tail-heavy:反过来
结果
作者发现:
- head-heavy 明显优于 tail-heavy
- 即,把更多 KV 预算留给前面层,效果更好
- 即使平均 budget 低 25%,也只带来很小的准确率下降
这说明什么
这非常有意思。它表明:
不同层对 KV 保留的敏感性不同。
作者的解释是:
- 初始层更值得保留更多 KV
- 后面的层对 eviction 更敏感,或者说尾部预算不足更伤性能
更准确地说,实验表明“head-heavy better than tail-heavy”,因此预算分配不是均匀最优的。
这其实是在告诉我们,KV 管理未来可以更智能,不一定层层一刀切。
表 II 题目是:
KV eviction speedup in LLaMA3.1-8B
KV budget 越小,decode 越快。
这非常符合预期,因为:
- KV 更小
- 每步读取和处理的历史上下文更少
- memory traffic 更低
但关键在于
作者不是只给速度,还结合图 7 证明:
- budget 缩小确实会提速
- 但如果 budget 分配合理,精度不一定损失很大
所以这里是在做accuracy-latency tradeoff 的论证。
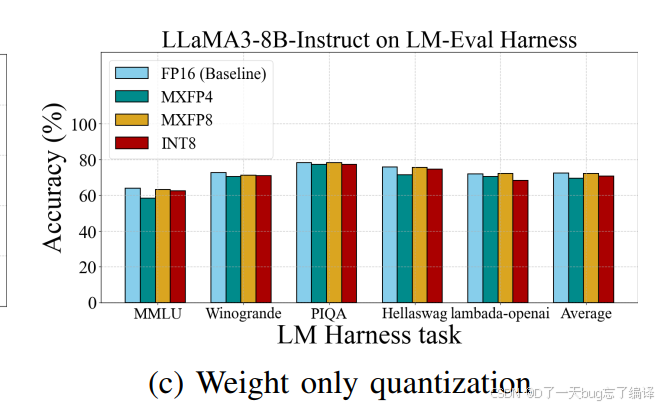
图 6(c) 比较:
- FP16 baseline
- MXFP4
- MXFP8
- INT8
模型还是 LLaMA3-8B-Instruct。
作者结论
- MXFP4 / MXFP8 相比 FP16 只有轻微下降
- MXFP8 平均比 INT8 高约 1.3%
这说明什么
支撑了前面硬件节里关于 MX 格式的判断:
Microscaling format 在保持精度方面有潜力优于传统 INT8。
C. Results: Hardware Performance Analysis
这部分开始看真正的速度和能耗。
作者用的指标主要是:
- TTFT: time-to-first-token
- TPOT: time-per-output-token
- SoC energy
- Joules/token
实验平台是:
- Intel Core Ultra Series 2 Lunar Lake
- 32GB RAM
- 268V
- OpenVINO llm_bench 做推理
- HWINFO 量测能耗
- fusion 和 N:M sparsity 一部分结果来自 VPU-EM 估计
作者说:
temporal + inter-operator fusion 在 prefill TTFT 上分别给:
- LLaMA3.1-8B:17%
- Phi3.5-mini:48%
- Qwen2-1.5B:31%
为什么不同模型收益差异大
因为 fusion 收益取决于:
- 算子图碎片程度
- attention/FFN 结构
- shape
- 是否更容易受 memory traffic 影响
所以:
- 对某些模型,fusion 是中等收益
- 对某些模型,fusion 是非常显著收益
这也侧面说明,作者前面把 fusion 作为第一类软件优化是合理的。
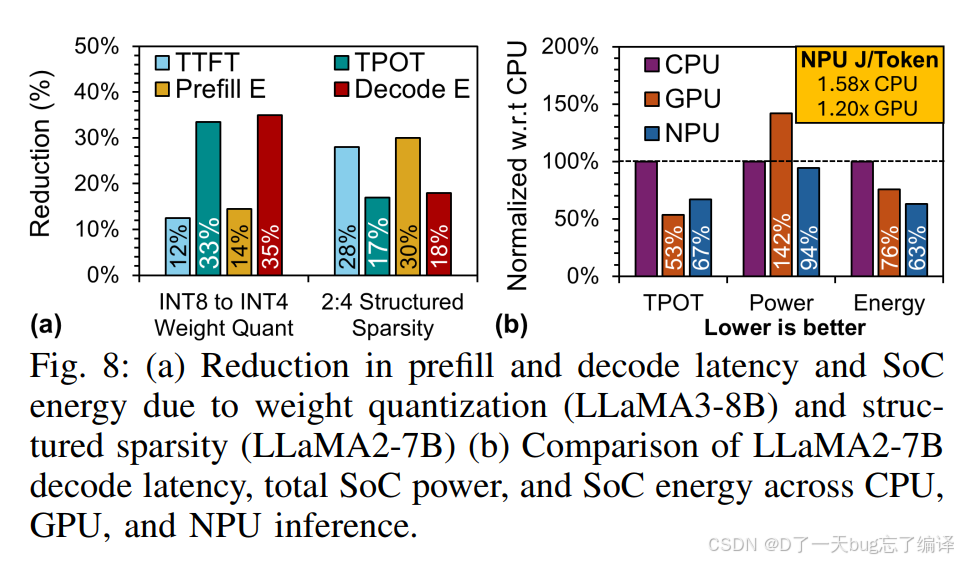
图 8(a) 分两组:
左边:INT8 → INT4 weight quantization(LLaMA3-8B)
decode 阶段收益远大于 prefill。
作者也明确解释了原因:
decode 更 memory-bound,低精度更能显著降低 memory traffic
这非常合理,因为 decode 通常 batch 小、逐 token 执行,对带宽更敏感。
所以权重量化对 decode 特别值钱。
右边:2:4 structured sparsity(LLaMA2-7B)
同时文中还补充:
- inference pipeline 层面 prefill latency 降 48%
- decode latency 降 49%
- NPU eTOPS/W 提升:
- prefill 1.69×
- decode 1.23×
稀疏带来的 pipeline-level 收益很大,但到 SoC level 会被折损。
也就是说:
- 单看 accelerator pipeline,提升很漂亮
- 但放到整机系统里,受其他环节限制,最终收益没那么夸张
这其实很真实,也说明作者没有只报最漂亮的局部数。
图 8(b):CPU / GPU / NPU 对比
1. TPOT
作者给出结论:
- GPU 比 CPU 降 53%
- NPU 比 CPU 降 67%
也就是:
- NPU decode 更快
- GPU 也快,但不如 NPU
2. Power
图上可以明显看出 GPU 功耗最高,NPU 最低。
3. Energy / Joules per token
作者结论:
- NPU 的 Joules/token 比 CPU 好 1.58×
- 比 GPU 好 1.2×
GPU 可能凭更高峰值 TOPS 很强,但在端侧 LLM decode 上,NPU 在能效上更占优势。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)