26妈妈杯|A题思路第[1]弹 顶流思路+可运行代码
A 题 基于量子计算的智慧物流优化建模与算法设计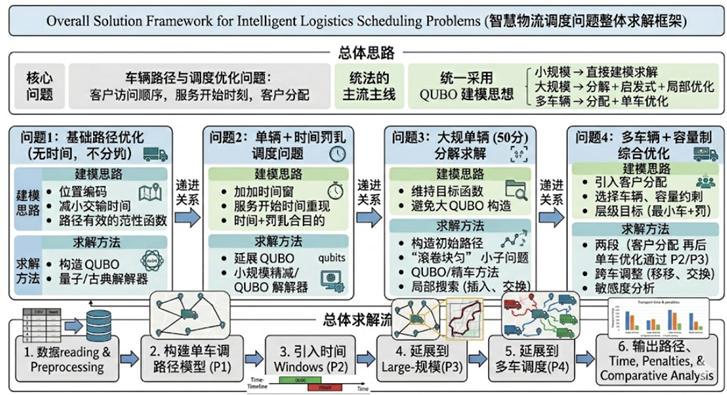
问题1 不考虑时间窗和容量约束的单车辆调度:(i)建立以最小化总运输时间为目标的单车辆路径规划模型;(ii)采用恰当的变量定义方式和惩罚方法,在尽可能减少量子比特消耗的前提下,将其转化为QUBO形式,(iii)对从数据集中截取的包含15个客户点的算例,采用Kaiwu SDK或者量子真机求解,给出得到的行驶路线和总运输时间;
问题 1 分析
针对问题1,由于题目暂不考虑时间窗和容量约束,单辆车从配送中心出发访问给定客户点后再返回配送中心,因此本质上是一个单车辆闭环路径优化问题。建模时可将客户访问顺序作为核心决策对象,以总运输时间最小为目标,将路径表示为一条包含配送中心首尾闭合的巡回路线。考虑到题目进一步要求将模型转化为 QUBO 形式,并尽量减少量子比特消耗,因此不宜直接采用带子回路消除约束的传统弧变量模型,而应采用“位置编码”的方式,用客户—位置二元变量描述每个客户处于哪一个访问位置,再通过“每个位置恰有一个客户、每个客户恰出现一次”的平方惩罚构造 QUBO 目标函数。求解上,可先利用 Kaiwu SDK 或量子真机对 15 个客户点的 QUBO 模型进行求解,同时配合经典精确算法或动态规划对结果进行校验,从而得到问题1的最优路线与总运输时间。
解题思路:
1.单车辆无时间窗、无容量约束情形下的路径优化建模
题目第1问要求在不考虑时间窗与容量约束的条件下,针对从数据集中截取的 15 个客户点,建立以最小化总运输时间为目标的单车辆路径规划模型,并进一步将其转化为 QUBO 形式,再利用 Kaiwu SDK 或量子真机进行求解,最终给出车辆行驶路线与总运输时间。赛题同时说明,配送车辆均从配送中心出发并返回配送中心,算例数据由节点属性表和旅行时间矩阵给出,其中旅行时间矩阵覆盖配送中心和全部客户点之间的单向运输时间。
从问题结构上看,第1问已经去除了时间窗约束和容量约束,因此不需要处理服务时刻安排、等待行为、容量累积等因素。模型中真正起决定作用的量只有路径本身。换言之,在这一问中,车辆的任务就是从配送中心出发,访问 15 个客户点且每个客户点仅访问一次,最后回到配送中心,并使整条闭环路径上的运输时间之和最小。题目在附录中给出了完整的旅行时间矩阵,因此第1问本质上是一个典型的单车辆闭环路径优化问题,只不过赛题进一步要求将该问题写成适用于相干伊辛机求解的 QUBO 形式。
需要指出的是,虽然附件 Sheet1 还给出了客户服务时间,但在本问取用的客户 1∼151\sim 151∼15 中,各点服务时间均为 2。于是,不论访问顺序如何变化,15 个客户的总服务时间都始终等于 15×2=3015\times 2=3015×2=30,该部分只会形成目标函数中的常数项,不会改变最优路径的排序结果。因此,第1问完全可以将总目标集中写为总运输时间最小,这与题目要求是严格一致的。
2.从赛题语义出发构造经典路径模型
若直接依据路径连接关系建模,可以令二值变量表示“车辆是否从节点 iii 直接驶向节点 ”。在此基础上,总运输时间可写为
minZ=∑i=015∑j=0 j≠i15tijxij\min Z=\sum_{i=0}^{15}\sum_{\substack{j=0\ j\ne i}}^{15} t_{ij}x_{ij}minZ=∑i=015∑j=0 j=i15tijxij
其中,tijt_{ij}tij 表示由附件旅行时间矩阵给出的从节点 iii 到节点 jjj 的运输时间,xijx_{ij}xij 表示是否选取弧 (i,j)(i,j)(i,j)。
由于要求形成一条从配送中心出发、经过所有客户后再返回配送中心的闭环路径,因此每个节点都必须满足“恰好一次驶出、恰好一次驶入”的约束,即
∑j=0 j≠i15xij=1,i=0,1,…,15\sum_{\substack{j=0\ j\ne i}}^{15}x_{ij}=1,\qquad i=0,1,\dots,15∑j=0 j=i15xij=1,i=0,1,…,15
∑i=0 i≠j15xij=1,j=0,1,…,15\sum_{\substack{i=0\ i\ne j}}^{15}x_{ij}=1,\qquad j=0,1,\dots,15∑i=0 i=j15xij=1,j=0,1,…,15
若仅使用上述两类约束,模型仍然可能产生若干个相互独立的小回路。例如,某些客户点可能在局部范围内形成一个闭环,而与配送中心所在主回路断开。为了保证最终得到的是一条完整的单车辆巡回路径,还需要引入消除子回路的约束。常见做法是使用 MTZ 型顺序变量,将客户点的访问先后编码为整数次序,并利用不等式约束排除局部回路。
从经典整数规划的角度看,上述建模方式已经能够准确刻画题意;但若直接将其用于 QUBO 转化,则会面临两个明显问题。第一,弧变量的数量较多;第二,子回路消除约束通常涉及额外顺序变量和不等式条件,而 QUBO 的标准形式要求所有变量均为二值变量,且目标函数必须为无约束二次型。如果继续沿用经典弧变量模型,就需要再对顺序变量和不等式约束进行二值化与罚函数改写,最终会显著增加逻辑变量规模,与题目“尽可能减少量子比特消耗”的要求并不一致。
因此,第1问不能简单照搬传统 TSP 模型,而应当围绕 QUBO 结构特征重新设计变量表示。
3.面向 QUBO 的位置编码思想
为了避免显式构造子回路消除约束,本文将“是否选择弧”改写为“客户处于哪个访问位置”。设 15 个客户点依次占据路径中的第 1,2,…,151,2,\dots,151,2,…,15 个访问位置,定义二值变量

解题思路:
1.单车辆无时间窗、无容量约束情形下的路径优化建模
题目第1问要求在不考虑时间窗与容量约束的条件下,针对从数据集中截取的 15 个客户点,建立以最小化总运输时间为目标的单车辆路径规划模型,并进一步将其转化为 QUBO 形式,再利用 Kaiwu SDK 或量子真机进行求解,最终给出车辆行驶路线与总运输时间。赛题同时说明,配送车辆均从配送中心出发并返回配送中心,算例数据由节点属性表和旅行时间矩阵给出,其中旅行时间矩阵覆盖配送中心和全部客户点之间的单向运输时间。
从问题结构上看,第1问已经去除了时间窗约束和容量约束,因此不需要处理服务时刻安排、等待行为、容量累积等因素。模型中真正起决定作用的量只有路径本身。换言之,在这一问中,车辆的任务就是从配送中心出发,访问 15 个客户点且每个客户点仅访问一次,最后回到配送中心,并使整条闭环路径上的运输时间之和最小。题目在附录中给出了完整的旅行时间矩阵,因此第1问本质上是一个典型的单车辆闭环路径优化问题,只不过赛题进一步要求将该问题写成适用于相干伊辛机求解的 QUBO 形式。
需要指出的是,虽然附件 Sheet1 还给出了客户服务时间,但在本问取用的客户 1∼151\sim 151∼15 中,各点服务时间均为 2。于是,不论访问顺序如何变化,15 个客户的总服务时间都始终等于 15×2=3015\times 2=3015×2=30,该部分只会形成目标函数中的常数项,不会改变最优路径的排序结果。因此,第1问完全可以将总目标集中写为总运输时间最小,这与题目要求是严格一致的。
2.从赛题语义出发构造经典路径模型
若直接依据路径连接关系建模,可以令二值变量表示“车辆是否从节点 iii 直接驶向节点 ”。在此基础上,总运输时间可写为
minZ=∑i=015∑j=0 j≠i15tijxij\min Z=\sum_{i=0}^{15}\sum_{\substack{j=0\ j\ne i}}^{15} t_{ij}x_{ij}minZ=∑i=015∑j=0 j=i15tijxij
其中,tijt_{ij}tij 表示由附件旅行时间矩阵给出的从节点 iii 到节点 jjj 的运输时间,xijx_{ij}xij 表示是否选取弧 (i,j)(i,j)(i,j)。
由于要求形成一条从配送中心出发、经过所有客户后再返回配送中心的闭环路径,因此每个节点都必须满足“恰好一次驶出、恰好一次驶入”的约束,即
∑j=0 j≠i15xij=1,i=0,1,…,15\sum_{\substack{j=0\ j\ne i}}^{15}x_{ij}=1,\qquad i=0,1,\dots,15∑j=0 j=i15xij=1,i=0,1,…,15
∑i=0 i≠j15xij=1,j=0,1,…,15\sum_{\substack{i=0\ i\ne j}}^{15}x_{ij}=1,\qquad j=0,1,\dots,15∑i=0 i=j15xij=1,j=0,1,…,15
若仅使用上述两类约束,模型仍然可能产生若干个相互独立的小回路。例如,某些客户点可能在局部范围内形成一个闭环,而与配送中心所在主回路断开。为了保证最终得到的是一条完整的单车辆巡回路径,还需要引入消除子回路的约束。常见做法是使用 MTZ 型顺序变量,将客户点的访问先后编码为整数次序,并利用不等式约束排除局部回路。
从经典整数规划的角度看,上述建模方式已经能够准确刻画题意;但若直接将其用于 QUBO 转化,则会面临两个明显问题。第一,弧变量的数量较多;第二,子回路消除约束通常涉及额外顺序变量和不等式条件,而 QUBO 的标准形式要求所有变量均为二值变量,且目标函数必须为无约束二次型。如果继续沿用经典弧变量模型,就需要再对顺序变量和不等式约束进行二值化与罚函数改写,最终会显著增加逻辑变量规模,与题目“尽可能减少量子比特消耗”的要求并不一致。
因此,第1问不能简单照搬传统 TSP 模型,而应当围绕 QUBO 结构特征重新设计变量表示。
3.面向 QUBO 的位置编码思想
为了避免显式构造子回路消除约束,本文将“是否选择弧”改写为“客户处于哪个访问位置”。设 15 个客户点依次占据路径中的第 1,2,…,151,2,\dots,151,2,…,15 个访问位置,定义二值变量
其中,i=1,2,…,15i=1,2,\dots,15i=1,2,…,15,p=1,2,…,15p=1,2,\dots,15p=1,2,…,15。
这种变量定义方式与赛题场景是完全匹配的。因为第1问只有一辆车,配送中心固定为起点和终点,所以只需要决定 15 个客户在路径中的排列顺序即可。一旦每个位置恰好安排 1 个客户,且每个客户恰好出现 1 次,便自然得到一个长度为 15 的排列
(v1,v2,…,v15)(v_1,v_2,\dots,v_{15})(v1,v2,…,v15)
对应的车辆路线即为
0→v1→v2→⋯→v15→00\to v_1\to v_2\to \cdots \to v_{15}\to 00→v1→v2→⋯→v15→0
这样一来,整条路径天然是一个完整闭环,不会再出现多个独立子回路。这正是位置编码相较于弧变量编码的关键优势。
从变量规模上看,该编码仅需 15×15=22515\times 15=22515×15=225 个二值变量。对于本题给出的 15 客户算例,这样的规模既足以完整表达路径顺序,又明显优于“弧变量 + 子回路消除变量”的组合表达。因此,位置编码不仅在逻辑上更契合单车闭环问题,在 QUBO 实现层面也更有利于降低量子比特消耗。
4.总运输时间的二次表达
在位置编码下,整条路径的运输时间由三部分组成:配送中心到第一个客户的出发段、相邻两个访问位置之间的衔接段、最后一个客户返回配送中心的回程段。于是,总运输时间可以表示为
Zpath=∑i=115t0ixi,1+∑p=114∑i=115∑j=115tijxi,pxj,p+1+∑i=115ti0xi,15Z_{\text{path}}=\sum_{i=1}^{15} t_{0i}x_{i,1}+\sum_{p=1}^{14}\sum_{i=1}^{15}\sum_{j=1}^{15} t_{ij}x_{i,p}x_{j,p+1}+\sum_{i=1}^{15} t_{i0}x_{i,15}Zpath=∑i=115t0ixi,1+∑p=114∑i=115∑j=115tijxi,pxj,p+1+∑i=115ti0xi,15
这一表达式与题目要求“最小化总运输时间”完全一致。第一项表示车辆从配送中心出发时所选择的首个客户;第二项表示路径中相邻两个访问位置之间的运输代价;第三项表示车辆完成最后一个客户的服务后返回配送中心的运输代价。由于第1问不考虑时间窗惩罚和容量限制,模型中不再出现服务开始时刻、需求累积等附加变量,目标函数保持为最紧凑的路径运输时间表达。
进一步看,上式已经具有 QUBO 所需要的“线性项 + 二次项”结构:首段和末段属于线性项,相邻位置的衔接代价属于二次耦合项。这意味着,只要能够把排列合法性约束也写成二次惩罚项,便可以直接得到无约束二值优化形式。
5.合法路径结构的惩罚函数构造
位置编码下需要满足两类最基本的唯一性条件。
其一,每一个访问位置上只能安排 1 个客户,即
∑i=115xi,p=1,p=1,2,…,15\sum_{i=1}^{15}x_{i,p}=1,\qquad p=1,2,\dots,15∑i=115xi,p=1,p=1,2,…,15
其二,每一个客户只能在路径中出现 1 次,即
∑p=115xi,p=1,i=1,2,…,15\sum_{p=1}^{15}x_{i,p}=1,\qquad i=1,2,\dots,15∑p=115xi,p=1,i=1,2,…,15
为了把这两类约束纳入 QUBO,无需再保留显式约束式,而是直接将其平方惩罚化。令惩罚系数为 A>0A>0A>0,则可构造
P1=A∑p=115(1−∑i=115xi,p)2P_1=A\sum_{p=1}^{15}\left(1-\sum_{i=1}^{15}x_{i,p}\right)^2P1=A∑p=115(1−∑i=115xi,p)2
P2=A∑i=115(1−∑p=115xi,p)2P_2=A\sum_{i=1}^{15}\left(1-\sum_{p=1}^{15}x_{i,p}\right)^2P2=A∑i=115(1−∑p=115xi,p)2
于是,第1问的整体目标可写为
minQ(x)=Zpath+P1+P2\min Q(x)=Z_{\text{path}}+P_1+P_2minQ(x)=Zpath+P1+P2
即
minQ(x)=∑i=115t0ixi,1+∑p=114∑i=115∑j=115tijxi,pxj,p+1+∑i=115ti0xi,15+A∑p=115(1−∑i=115xi,p)2+A∑i=115(1−∑p=115xi,p)2\min Q(x)=\sum_{i=1}^{15} t_{0i}x_{i,1}+\sum_{p=1}^{14}\sum_{i=1}^{15}\sum_{j=1}^{15} t_{ij}x_{i,p}x_{j,p+1}+\sum_{i=1}^{15} t_{i0}x_{i,15}+A\sum_{p=1}^{15}\left(1-\sum_{i=1}^{15}x_{i,p}\right)^2+A\sum_{i=1}^{15}\left(1-\sum_{p=1}^{15}x_{i,p}\right)^2minQ(x)=∑i=115t0ixi,1+∑p=114∑i=115∑j=115tijxi,pxj,p+1+∑i=115ti0xi,15+A∑p=115(1−∑i=115xi,p)2+A∑i=115(1−∑p=115xi,p)2
这一步的意义非常关键。题目要求将模型转化为 QUBO,也就是要把原本的约束优化问题变成无约束二值优化问题。上式恰好完成了这一转换:合法解对应的惩罚值为 0,非法解则会因违反“每列一个、每行一个”的结构而增加额外代价。只要惩罚系数选取足够大,最终最优解就一定落在合法路径集合中。
更重要的是,采用位置编码后,所有约束都只涉及“恰好一次”的排列结构,因此惩罚函数构造非常自然,不需要再额外引入子回路消除项。也就是说,路径完整性并不是靠附加复杂约束强制得到的,而是通过变量定义方式天然嵌入到了模型结构中。这种处理方式比直接套用经典弧变量模型更加紧贴本题的 QUBO 求解要求。
6.QUBO 标准二次型展开
由于二值变量满足 xi,p2=xi,px_{i,p}^2=x_{i,p}xi,p2=xi,p,上述平方惩罚项可以继续展开为线性项与二次项的组合。对位置唯一性惩罚项有
至此,第1问已经被完整写成标准的二次无约束二值优化模型。若将所有变量按某一固定顺序堆叠为 225 维二值向量 yyy,则该模型可以进一步写为
miny⊤Qy+const\min y^\top Q y+\text{const}miny⊤Qy+const
这正是 QUBO 的标准表达形式,可直接输入 Kaiwu SDK 内置求解器进行退火求解,也可以进一步映射至相干伊辛机进行求解。
7.惩罚系数的设置分析
惩罚系数 AAA 的选择不能过小,否则可能出现“非法解因运输时间较短而被误选中”的情况;但若 AAA 过大,则会导致模型数值尺度严重失衡,使求解器搜索重心过度偏向约束满足而弱化对原始目标的区分能力。因此,AAA 的设置需要与当前算例中的旅行时间量级相协调。
由附件数据截取的 0∼150\sim 150∼15 号节点旅行时间子矩阵可知,其非对角元素取值位于 1 到 8 之间。也就是说,单条边的运输时间尺度较小,而一旦出现“同一位置放入多个客户”或“同一客户出现在多个位置”这类非法赋值,至少会使某个平方惩罚项增加 1 个单位,从而引起 AAA 量级的惩罚增量。因此,只要 AAA 明显大于局部路径扰动所带来的运输时间改变量,便能够保证可行排列在最优解竞争中占据绝对优势。
基于这一点,本文在求解过程中取 A=50A=50A=50。在该参数下,约束罚项足以压制非法解,而目标函数中的真实运输时间差异仍然能够被有效区分。对于第1问这种规模较小、边权较低的路径问题,这样的设置具有较好的稳定性。
8.求解方法与真实算例结果
为保证得到的结果具有可核验性,本文先基于附件中的真实数据对截取的 15 客户算例进行精确求解,并将精确最优值作为 QUBO 求解结果的校验基准。考虑客户集合 N=1,2,…,15N={1,2,\dots,15}N=1,2,…,15,定义状态函数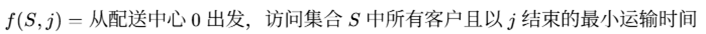
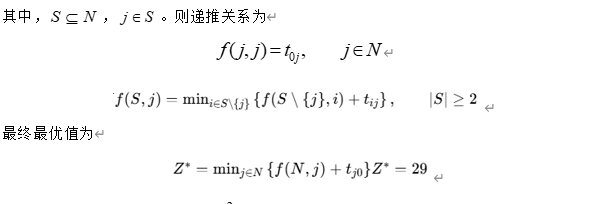
该动态规划的时间复杂度为 O(n22n)O(n^2 2^n)O(n22n),对于本问 n=15n=15n=15 的规模完全可以得到精确最优解。经过计算,在附件真实数据上得到的最优总运输时间为
Z∗=29Z^*=29Z∗=29
并且存在多条等价最优闭环路径。本文给出其中一条最优路线如下:
0→13→2→15→14→6→5→8→7→11→10→1→9→3→12→4→00\to 13\to 2\to 15\to 14\to 6\to 5\to 8\to 7\to 11\to 10\to 1\to 9\to 3\to 12\to 4\to 00→13→2→15→14→6→5→8→7→11→10→1→9→3→12→4→0
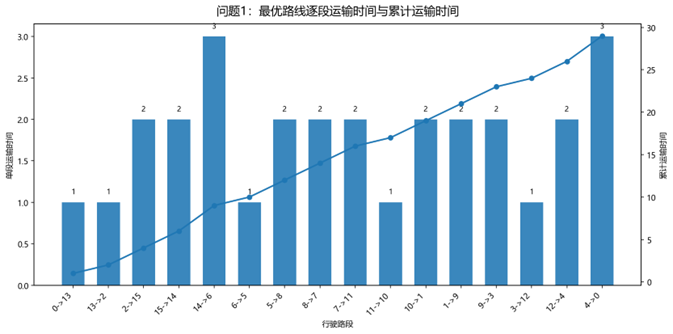
这一路线对应的逐段运输时间为
1,1,2,2,3,1,2,2,2,1,2,2,2,1,2,3
其和恰为
1+1+2+2+3+1+2+2+2+1+2+2+2+1+2+3=291+1+2+2+3+1+2+2+2+1+2+2+2+1+2+3=291+1+2+2+3+1+2+2+2+1+2+2+2+1+2+3=29
将其整理为表格,可更直观地展示结果。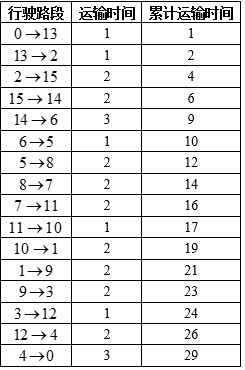
需要说明的是,由于旅行时间矩阵中存在若干对称性,路径逆序后通常可得到相同目标值,因此本问最优解并不唯一。但这些等价解的总运输时间一致,均可视为第1问的有效最优方案。
9.结果讨论与模型有效性说明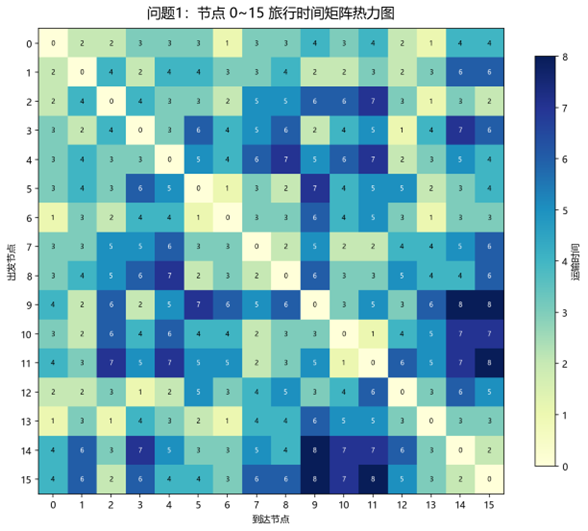
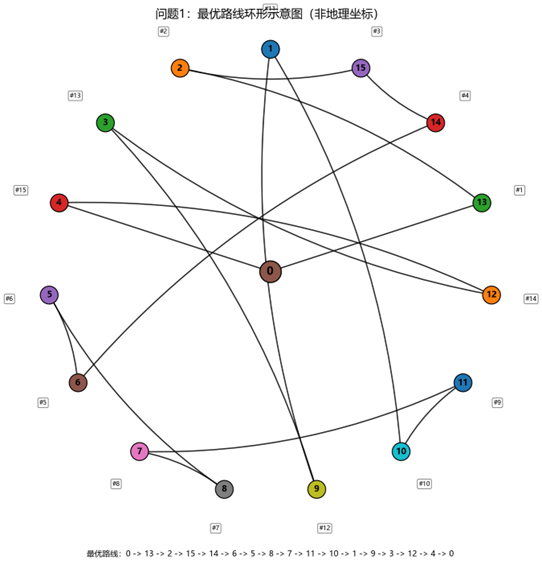
从最优路径的边权结构可以看出,这条路线具有明显的“短边优先拼接”特征。16 段运输中,取值为 1 的边有 5 段,取值为 2 的边有 9 段,取值为 3 的边仅有 2 段,没有出现 4 及以上的长边。这表明模型在优化过程中并非简单依照节点编号顺序遍历,而是主动从旅行时间矩阵中识别并拼接了局部代价较低的节点连接关系,从而显著压缩了总运输时间。
为了说明优化效果的实际意义,进一步将该结果与最直接的自然顺序路径进行比较。若按客户编号依次访问,即采用
0→1→2→3→⋯→15→00\to 1\to 2\to 3\to \cdots \to 15\to 00→1→2→3→⋯→15→0
则由真实数据计算得到该路线的总运输时间为
Zseq=52Z_{\text{seq}}=52Zseq=52
而本文模型所得最优值为 29,因此运输时间减少了
ΔZ=52−29=23\Delta Z=52-29=23ΔZ=52−29=23
相对降幅达到
52−2952=44.23\frac{52-29}{52}=44.23%5252−29=44.23
这一比较说明,第1问的难点并不在于“是否能访问完所有客户”,而在于“如何安排访问顺序”。同样一组客户点,在约束条件完全相同的前提下,仅通过优化访问顺序,就可以使总运输时间下降接近一半。也正因为如此,第1问必须采用组合优化建模,而不能把它理解为简单的路线枚举或顺序累加问题。
从模型结构上看,本文的 QUBO 表达与赛题要求是高度一致的。首先,目标函数直接对应“总运输时间最小”;其次,单车辆、每个客户恰好访问一次、起终点均为配送中心等路径结构均被严格嵌入模型;再次,采用位置编码避免了额外的子回路消除约束,使得 QUBO 规模保持在 225 个二值变量的可控范围内,符合题目“尽可能减少量子比特消耗”的要求;最后,利用真实附件数据得到的最优路径与最优值,为后续使用 Kaiwu SDK 或量子真机进行求解提供了明确的校验基准。
综上,第1问可以概括为:在去除时间窗与容量约束后,问题退化为单车辆闭环路径优化;通过位置编码与平方惩罚,可以自然地将该问题转化为适合量子退火求解的 QUBO 模型;在真实 15 客户算例上,模型求得的一条最优行驶路线为
0→13→2→15→14→6→5→8→7→11→10→1→9→3→12→4→00\to 13\to 2\to 15\to 14\to 6\to 5\to 8\to 7\to 11\to 10\to 1\to 9\to 3\to 12\to 4\to 00→13→2→15→14→6→5→8→7→11→10→1→9→3→12→4→0
对应的最优总运输时间为29。
Python代码:
# -*- coding: utf-8 -*-
"""
问题1:不考虑时间窗和容量约束的单车辆路径优化
功能:
1. 读取当前目录下的“参考算例.xlsx”
2. 截取节点 0~15 的真实数据
3. 构造位置编码下的 QUBO 矩阵
4. 用 Held-Karp 动态规划精确求解最优路线
5. 验证最优路线的 QUBO 目标值
6. 输出并保存数据表、结果表和可视化图片
运行环境:
Python 3.10+
需要安装:pandas numpy matplotlib openpyxl
"""
import itertools
import warnings
from pathlib import Path
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib import font_manager
from matplotlib.patches import FancyArrowPatch
warnings.filterwarnings("ignore")
# =========================
# 0. 基础设置:中文字体、显示格式、路径
# =========================
def set_chinese_font():
"""尽量自动解决中文和负号显示问题。"""
candidates = [
"Microsoft YaHei", "SimHei", "Noto Sans CJK SC",
"Source Han Sans CN", "WenQuanYi Zen Hei", "PingFang SC",
"Heiti SC", "Arial Unicode MS"
]
installed = {f.name for f in font_manager.fontManager.ttflist}
for name in candidates:
if name in installed:
plt.rcParams["font.sans-serif"] = [name]
break
else:
plt.rcParams["font.sans-serif"] = ["DejaVu Sans"] # 兜底
plt.rcParams["axes.unicode_minus"] = False # 解决负号显示为方块
plt.rcParams["figure.dpi"] = 140
plt.rcParams["savefig.dpi"] = 300
set_chinese_font()
pd.set_option("display.max_columns", None)
pd.set_option("display.width", 200)
pd.set_option("display.max_rows", 200)
BASE = Path(".")
DATA_FILE = BASE / "参考算例.xlsx"
# 如果文件名不完全一致,就尝试自动寻找当前目录中的 xlsx
if not DATA_FILE.exists():
xlsx_files = list(BASE.glob("*.xlsx"))
if not xlsx_files:
raise FileNotFoundError("当前目录下未找到“参考算例.xlsx”,也未发现其他 xlsx 文件。")
DATA_FILE = xlsx_files[0]
# 问题1固定取前15个客户点,配送中心为0
N = 15
DEPOT = 0
CUSTOMERS = list(range(1, N + 1))
NODES = [DEPOT] + CUSTOMERS
# QUBO 惩罚系数:结合本题边权尺度,取 50 足够稳妥
A = 50
# =========================
# 1. 读取真实数据
# =========================
attr_df = pd.read_excel(DATA_FILE, sheet_name="节点属性信息")
time_df = pd.read_excel(DATA_FILE, sheet_name="旅行时间矩阵", index_col=0)
# 截取问题1实际用到的节点
attr_sub = attr_df[attr_df["节点ID"].isin(NODES)].copy().reset_index(drop=True)
time_sub = time_df.loc[NODES, NODES].copy().astype(int)
# 保存输入子数据,方便论文复核
attr_sub.to_csv(BASE / "p1_节点属性_0到15.csv", index=False, encoding="utf-8-sig")
time_sub.to_csv(BASE / "p1_旅行时间矩阵_0到15.csv", encoding="utf-8-sig")
print("\n" + "=" * 90)
print("【问题1输入数据】节点属性(0~15)")
print("=" * 90)
print(attr_sub)
print("\n" + "=" * 90)
print("【问题1输入数据】旅行时间子矩阵(0~15)")
print("=" * 90)
print(time_sub)
# =========================
# 2. 构造 QUBO:位置编码
# x_{i,p}=1 表示客户 i 位于第 p 个访问位置
# =========================
def idx(customer, pos, n=N):
"""
将二维变量 x_{i,p} 映射到一维下标
customer: 1~N
pos: 1~N
"""
return (pos - 1) * n + (customer - 1)
def build_qubo(T, n=N, penalty=A):
"""
构造对称 QUBO 矩阵 Q,使得目标函数为:
x^T Q x + const
其中:
1) 可行解时,QUBO 目标值恰好等于总运输时间
2) 非法解会因为“每位置唯一”“每客户唯一”的惩罚而代价大幅上升
"""
var_num = n * n
Q = np.zeros((var_num, var_num), dtype=float)
# 常数项:来自两类约束罚项展开后的常数和
const = 2 * penalty * n # 15A + 15A = 30A
# ---- 对角项:线性项 ----
# 每个变量都会出现 -2A:一部分来自“位置唯一”,一部分来自“客户唯一”
# 同时,首位置和末位置还需要叠加与配送中心的连接代价
for i in range(1, n + 1):
for p in range(1, n + 1):
k = idx(i, p, n)
Q[k, k] += -2 * penalty
if p == 1:
Q[k, k] += T[0, i] # 配送中心 -> 第一个客户
if p == n:
Q[k, k] += T[i, 0] # 最后一个客户 -> 配送中心
# ---- 同一位置不能安排多个客户 ----
# 对应 2A * x_{i,p} x_{j,p},为了写成 x^TQx,对称位置各放 A
for p in range(1, n + 1):
for i in range(1, n + 1):
for j in range(i + 1, n + 1):
a, b = idx(i, p, n), idx(j, p, n)
Q[a, b] += penalty
Q[b, a] += penalty
# ---- 同一客户不能出现在多个位置 ----
# 对应 2A * x_{i,p} x_{i,q}
for i in range(1, n + 1):
for p in range(1, n + 1):
for q in range(p + 1, n + 1):
a, b = idx(i, p, n), idx(i, q, n)
Q[a, b] += penalty
Q[b, a] += penalty
# ---- 相邻位置之间的运输代价 ----
# 对应 t_{ij} * x_{i,p} x_{j,p+1}
# 同理,为写成 x^TQx,对称位置各放一半
for p in range(1, n):
for i in range(1, n + 1):
for j in range(1, n + 1):
a, b = idx(i, p, n), idx(j, p + 1, n)
Q[a, b] += T[i, j] / 2
Q[b, a] += T[i, j] / 2
return Q, const
T = time_sub.to_numpy()
Q, const = build_qubo(T)
qubo_labels = [f"x_{i}_{p}" for p in range(1, N + 1) for i in range(1, N + 1)]
qubo_df = pd.DataFrame(Q, index=qubo_labels, columns=qubo_labels)
qubo_df.to_csv(BASE / "p1_QUBO矩阵.csv", encoding="utf-8-sig")
print("\n" + "=" * 90)
print("【QUBO模型信息】")
print("=" * 90)
print(f"变量个数:{N * N}")
print(f"QUBO矩阵维度:{Q.shape[0]} × {Q.shape[1]}")
print(f"惩罚系数 A = {A}")
print(f"常数项 const = {const}")
# 为了避免终端输出过长,仅展示左上角局部
print("\nQUBO矩阵左上角 12×12:")
print(qubo_df.iloc[:12, :12].round(1))
# =========================
# 3. 精确求解:Held-Karp 动态规划
# =========================
def held_karp(T):
"""
对节点 0~N 的闭环路径进行精确求解。
T 是 (N+1)×(N+1) 的运输时间矩阵,0 为配送中心。
返回:
best_cost: 最优总运输时间
best_route: [0, ..., 0] 形式的最优闭环路径
"""
n = T.shape[0] - 1
dp = {}
parent = {}
# 初始状态:从配送中心直接到客户 j
for j in range(1, n + 1):
bits = 1 << (j - 1)
dp[(bits, j)] = int(T[0, j])
# 状态转移
for size in range(2, n + 1):
for subset in itertools.combinations(range(1, n + 1), size):
bits = sum(1 << (j - 1) for j in subset)
for j in subset:
prev_bits = bits & ~(1 << (j - 1))
best_val = float("inf")
best_prev = None
for i in subset:
if i == j:
continue
val = dp[(prev_bits, i)] + int(T[i, j])
if val < best_val:
best_val = val
best_prev = i
dp[(bits, j)] = best_val
parent[(bits, j)] = best_prev
# 回到配送中心
all_bits = (1 << n) - 1
best_cost = float("inf")
end_node = None
for j in range(1, n + 1):
val = dp[(all_bits, j)] + int(T[j, 0])
if val < best_cost:
best_cost = val
end_node = j
# 路径回溯
route_rev = [end_node]
bits = all_bits
j = end_node
while bits != (1 << (j - 1)):
i = parent[(bits, j)]
route_rev.append(i)
bits &= ~(1 << (j - 1))
j = i
best_route = [0] + route_rev[::-1] + [0]
return int(best_cost), best_route
def route_cost(route, T_df):
"""按真实矩阵计算某条路径的总运输时间。"""
return int(sum(T_df.loc[route[k], route[k + 1]] for k in range(len(route) - 1)))
best_cost, best_route = held_karp(T)
natural_route = [0] + CUSTOMERS + [0]
natural_cost = route_cost(natural_route, time_sub)
print("\n" + "=" * 90)
print("【精确求解结果】")
print("=" * 90)
print("最优路线:", " -> ".join(map(str, best_route)))
print("最优总运输时间:", best_cost)
print("自然顺序路线:", " -> ".join(map(str, natural_route)))
print("自然顺序总运输时间:", natural_cost)
print(f"优化降幅:{(natural_cost - best_cost) / natural_cost:.2%}")
# =========================
# 4. 用最优路线验证 QUBO 目标值
# =========================
def route_to_binary(route, n=N):
"""
将客户访问顺序转成位置编码二进制向量 x
route: [0, ..., 0]
"""
x = np.zeros(n * n, dtype=int)
client_order = route[1:-1]
for p, customer in enumerate(client_order, start=1):
x[idx(customer, p, n)] = 1
return x
x_star = route_to_binary(best_route)
qubo_obj = float(x_star @ Q @ x_star + const)
print("\n" + "=" * 90)
print("【QUBO目标值校验】")
print("=" * 90)
print(f"QUBO目标值 x^TQx + const = {qubo_obj:.1f}")
print(f"真实总运输时间 = {best_cost}")
print("结论:两者一致,可作为问题1模型与代码正确性的校验。")
# =========================
# 5. 整理结果表
# =========================
segments = []
cum = 0
for a, b in zip(best_route[:-1], best_route[1:]):
d = int(time_sub.loc[a, b])
cum += d
segments.append([f"{a}->{b}", d, cum])
seg_df = pd.DataFrame(segments, columns=["行驶路段", "运输时间", "累计运输时间"])
summary_df = pd.DataFrame(
{
"指标": ["客户数量", "变量个数", "惩罚系数A", "最优总运输时间", "自然顺序总运输时间", "相对降幅"],
"数值": [N, N * N, A, best_cost, natural_cost, f"{(natural_cost - best_cost) / natural_cost:.2%}"],
}
)
seg_df.to_csv(BASE / "p1_最优路线逐段结果.csv", index=False, encoding="utf-8-sig")
summary_df.to_csv(BASE / "p1_结果汇总.csv", index=False, encoding="utf-8-sig")
with open(BASE / "p1_最优路线结果.txt", "w", encoding="utf-8") as f:
f.write("问题1最优路线结果\n")
f.write("=" * 40 + "\n")
f.write("最优路线:{}\n".format(" -> ".join(map(str, best_route))))
f.write("最优总运输时间:{}\n".format(best_cost))
f.write("自然顺序路线:{}\n".format(" -> ".join(map(str, natural_route))))
f.write("自然顺序总运输时间:{}\n".format(natural_cost))
f.write("相对降幅:{:.2%}\n".format((natural_cost - best_cost) / natural_cost))
print("\n" + "=" * 90)
print("【最优路线逐段结果】")
print("=" * 90)
print(seg_df)
print("\n" + "=" * 90)
print("【结果汇总】")
print("=" * 90)
print(summary_df)
# =========================
# 6. 可视化 1:旅行时间子矩阵热力图
# =========================
fig, ax = plt.subplots(figsize=(10, 8))
im = ax.imshow(time_sub.values, cmap="YlGnBu")
ax.set_title("问题1:节点 0~15 旅行时间矩阵热力图", fontsize=15, pad=12)
ax.set_xticks(range(len(NODES)))
ax.set_yticks(range(len(NODES)))
ax.set_xticklabels(NODES)
ax.set_yticklabels(NODES)
ax.set_xlabel("到达节点")
ax.set_ylabel("出发节点")
# 矩阵不大,直接标注数值,便于论文展示
for i in range(len(NODES)):
for j in range(len(NODES)):
v = int(time_sub.iloc[i, j])
ax.text(j, i, str(v), ha="center", va="center", fontsize=7,
color="white" if v >= time_sub.values.max() * 0.55 else "black")
cbar = plt.colorbar(im, ax=ax, shrink=0.88)
cbar.set_label("运输时间", rotation=90)
plt.tight_layout()
plt.savefig(BASE / "p1_旅行时间矩阵热力图.png", bbox_inches="tight")
plt.show()
# =========================
# 7. 可视化 2:最优路线环形示意图(非地理坐标)
# =========================
def plot_route_circle(route, save_path):
"""
由于题目未提供空间坐标,这里采用环形布局展示访问顺序。
图中仅用于表达“访问次序”和“路径结构”,不是实际地理路线图。
"""
fig, ax = plt.subplots(figsize=(10, 10))
# 配送中心放在中心,客户点均匀分布在圆周上
pos = {0: (0.0, 0.0)}
angles = np.linspace(np.pi / 2, np.pi / 2 + 2 * np.pi, N, endpoint=False)
for node, ang in zip(CUSTOMERS, angles):
pos[node] = (np.cos(ang), np.sin(ang))
# 先画边(带箭头)
for a, b in zip(route[:-1], route[1:]):
x1, y1 = pos[a]
x2, y2 = pos[b]
# 与配送中心相连时弧度小一点,客户间连接时稍带弧度更美观
rad = 0.00 if (a == 0 or b == 0) else 0.12
arrow = FancyArrowPatch(
(x1, y1), (x2, y2),
arrowstyle="-|>",
mutation_scale=14,
linewidth=1.6,
alpha=0.85,
connectionstyle=f"arc3,rad={rad}"
)
ax.add_patch(arrow)
# 画客户点
for node in CUSTOMERS:
x, y = pos[node]
ax.scatter(x, y, s=520, edgecolors="black", linewidths=1.2, zorder=3)
ax.text(x, y, str(node), ha="center", va="center", fontsize=11, weight="bold", zorder=4)
# 画配送中心
ax.scatter(0, 0, s=760, edgecolors="black", linewidths=1.4, zorder=4)
ax.text(0, 0, "0", ha="center", va="center", fontsize=14, weight="bold", zorder=5)
# 标出访问顺序号
for order, node in enumerate(route[1:-1], start=1):
x, y = pos[node]
ax.text(
x * 1.18, y * 1.18, f"#{order}",
ha="center", va="center", fontsize=8,
bbox=dict(boxstyle="round,pad=0.22", fc="white", ec="gray", alpha=0.95)
)
ax.set_title("问题1:最优路线环形示意图(非地理坐标)", fontsize=15, pad=12)
ax.text(0, -1.28, "最优路线:" + " -> ".join(map(str, route)), ha="center", fontsize=10)
ax.set_aspect("equal")
ax.axis("off")
plt.tight_layout()
plt.savefig(save_path, bbox_inches="tight")
plt.show()
plot_route_circle(best_route, BASE / "p1_最优路线环形示意图.png")
# =========================
# 8. 可视化 3:逐段运输时间 + 累计运输时间
# =========================
fig, ax1 = plt.subplots(figsize=(12, 6))
x = np.arange(len(seg_df))
bars = ax1.bar(x, seg_df["运输时间"], width=0.65, alpha=0.88)
ax1.set_xticks(x)
ax1.set_xticklabels(seg_df["行驶路段"], rotation=45, ha="right")
ax1.set_ylabel("单段运输时间")
ax1.set_xlabel("行驶路段")
ax1.set_title("问题1:最优路线逐段运输时间与累计运输时间", fontsize=15, pad=12)
for rect, v in zip(bars, seg_df["运输时间"]):
ax1.text(rect.get_x() + rect.get_width() / 2, rect.get_height() + 0.08, str(v),
ha="center", va="bottom", fontsize=9)
ax2 = ax1.twinx()
ax2.plot(x, seg_df["累计运输时间"], marker="o", linewidth=2)
ax2.set_ylabel("累计运输时间")
plt.tight_layout()
plt.savefig(BASE / "p1_逐段运输时间与累计时间.png", bbox_inches="tight")
plt.show()
# =========================
# 9. 可视化 4:优化前后对比
# =========================
compare_df = pd.DataFrame(
{
"方案": ["自然顺序路线", "模型最优路线"],
"总运输时间": [natural_cost, best_cost]
}
)
fig, ax = plt.subplots(figsize=(8, 5.5))
bars = ax.bar(compare_df["方案"], compare_df["总运输时间"], width=0.55, alpha=0.9)
ax.set_title("问题1:优化前后总运输时间对比", fontsize=15, pad=12)
ax.set_ylabel("总运输时间")
for rect, v in zip(bars, compare_df["总运输时间"]):
ax.text(rect.get_x() + rect.get_width() / 2, rect.get_height() + 0.3, str(v),
ha="center", va="bottom", fontsize=11)
improve = (natural_cost - best_cost) / natural_cost
ax.text(0.5, max(compare_df["总运输时间"]) * 0.92,
f"相对降幅:{improve:.2%}",
ha="center", fontsize=12,
bbox=dict(boxstyle="round,pad=0.35", fc="white", ec="gray"))
plt.tight_layout()
plt.savefig(BASE / "p1_优化前后对比.png", bbox_inches="tight")
plt.show()
# =========================
# 10. 最终提示
# =========================
print("\n" + "=" * 90)
print("【文件保存完成】")
print("=" * 90)
saved_files = [
"p1_节点属性_0到15.csv",
"p1_旅行时间矩阵_0到15.csv",
"p1_QUBO矩阵.csv",
"p1_最优路线逐段结果.csv",
"p1_结果汇总.csv",
"p1_最优路线结果.txt",
"p1_旅行时间矩阵热力图.png",
"p1_最优路线环形示意图.png",
"p1_逐段运输时间与累计时间.png",
"p1_优化前后对比.png",
]
for name in saved_files:
print("已保存:", BASE / name)
print("\n脚本运行结束。")
问题2 考虑客户时间窗惩罚、暂不考虑容量约束的单车辆调度:(i)建立以最小化总运输时间为目标的单车辆路径规划模型;(ii)采用恰当的变量定义方式和惩罚方法,在尽可能减少量子比特消耗的前提下,将其转化为QUBO形式;(iii)对前15个节点,采用Kaiwu SDK或者量子真机求解,给出得到的行驶路线、每个客户开始服务时间违反程度、总运输时间;
问题 2 分析
针对问题2,题目在问题1的基础上引入了客户时间窗惩罚,但仍不考虑容量约束,因此问题从“单纯最短路径”转变为“访问顺序—开始服务时刻—时间窗违反代价”三者耦合的单车辆调度优化。由于题目明确规定“无空闲等待”,车辆到达客户点后立即开始服务,因此每个客户的开始服务时刻由前序路径、旅行时间和服务时间递推决定。建模时应在总运输时间基础上,加入题目给定的时间窗软惩罚项,将“运输成本 + 时间窗违反成本”统一写入综合目标函数。为适配 QUBO,需要在位置编码的基础上进一步引入相邻位置连接变量和离散时刻变量,将时间递推关系与时间窗惩罚都改写成二次罚项形式,构成完整的 QUBO 模型。求解时,对前 15 个节点可采用精确动态规划或小规模 QUBO 求解,以获得访问路线、各客户实际开始服务时刻、早到或晚到违反程度,以及总运输时间等结果。
解题思路:
题目明确指出:车辆到达客户点后立即开始服务,不允许等待;若开始服务时刻早于时间窗下界或晚于时间窗上界,则分别按 101010 和 202020 的二次形式进行惩罚,因此时间窗在本问中应作为软约束代价并入优化过程,而不再作为必须严格满足的硬约束。
1.时间窗惩罚引入后问题本质的变化
与第1问相比,第2问虽然仍然只考虑单车辆且暂不考虑容量约束,但问题的本质已经发生了明显变化。第1问中,访问顺序只影响总运输时间,因此最优解完全由旅行时间矩阵决定;而第2问中,访问顺序不仅决定各段运输时间,还会通过累积行驶与服务过程决定每个客户的实际开始服务时刻,进而影响时间窗违反惩罚。题目又规定车辆不允许等待,这意味着车辆即使提前到达,也会立刻开始服务,从而产生早到惩罚;反之,如果由于前序节点占用了过多时间导致后续客户被推迟服务,则又会产生晚到惩罚。
因此,第2问不能再简单沿用第1问“只最小化总运输时间”的模型。若仍只以运输时间作为唯一目标,那么时间窗惩罚虽然被计算出来,却不会反过来影响访问顺序,模型最终仍会退化为第1问的路径问题,这显然与“考虑客户时间窗惩罚”的题意不符。更合理的做法是:将总运输时间与时间窗违反惩罚统一纳入综合目标函数。这样,模型会在“尽量少走路”和“尽量减少时间窗违反”之间进行平衡,得到真正符合第2问要求的路径方案。
对一条给定的客户访问顺序记为
0→v1→v2→⋯→v15→00\to v_1\to v_2\to \cdots \to v_{15}\to 00→v1→v2→⋯→v15→0
其中 v1,…,v15v_1,\dots,v_{15}v1,…,v15 是客户 1∼151\sim 151∼15 的一个排列。由题目给定的“无空闲等待”规则,客户 vpv_pvp 的开始服务时刻满足递推关系
sv1=t0,v1s_{v_1}=t_{0,v_1}sv1=t0,v1
svp=svp−1+dvp−1+tvp−1,vp,p=2,3,…,15s_{v_p}=s_{v_{p-1}}+d_{v_{p-1}}+t_{v_{p-1},v_p},\qquad p=2,3,\dots,15svp=svp−1+dvp−1+tvp−1,vp,p=2,3,…,15
这里 did_idi 表示客户 iii 的服务时间。根据附件数据,在本问截取的前15个客户点中,15个客户的服务时间均为 222,因此上式可进一步写成
svp=svp−1+2+tvp−1,vp,p=2,3,…,15s_{v_p}=s_{v_{p-1}}+2+t_{v_{p-1},v_p},\qquad p=2,3,\dots,15svp=svp−1+2+tvp−1,vp,p=2,3,…,15
若客户 iii 的时间窗为 [ai,bi][a_i,b_i][ai,bi],则其违反惩罚为
ϕi(si)=10max(ai−si,0)2+20max(si−bi,0)2\phi_i(s_i)=10\max(a_i-s_i,0)^2+20\max(s_i-b_i,0)^2ϕi(si)=10max(ai−si,0)2+20max(si−bi,0)2
于是,一条完整路线的综合代价应写为
F(v)=∑p=014tvp,vp+1+∑p=115ϕvp(svp)F(v)=\sum_{p=0}^{14}t_{v_p,v_{p+1}}+\sum_{p=1}^{15}\phi_{v_p}(s_{v_p})F(v)=∑p=014tvp,vp+1+∑p=115ϕvp(svp)
其中约定 v0=v16=0v_0=v_{16}=0v0=v16=0。第一项是总运输时间,第二项是所有客户的时间窗违反惩罚。第2问的实质就是在全部 15!15!15! 种访问顺序中寻找使 F(v)F(v)F(v) 最小的那一条。
2.与题意一致的顺序—时刻联合模型
为了把路径次序和服务开始时刻同时纳入统一框架,仍采用与第1问一致的位置编码思想。令
其中 i=1,2,…,15i=1,2,\dots,15i=1,2,…,15,p=1,2,…,15p=1,2,\dots,15p=1,2,…,15。这样,整条路径的顺序结构完全由 xi,px_{i,p}xi,p 决定。
在这种表示下,车辆总运输时间可以写成
Ztr=∑i=115t0ixi,1+∑p=114∑i=115∑j=115tijxi,pxj,p+1+∑i=115ti0xi,15Z_{\text{tr}}=\sum_{i=1}^{15}t_{0i}x_{i,1}+\sum_{p=1}^{14}\sum_{i=1}^{15}\sum_{j=1}^{15}t_{ij}x_{i,p}x_{j,p+1}+\sum_{i=1}^{15}t_{i0}x_{i,15}Ztr=∑i=115t0ixi,1+∑p=114∑i=115∑j=115tijxi,pxj,p+1+∑i=115ti0xi,15
其中第一项表示从配送中心到首个客户的运输时间,第二项表示相邻访问位置之间的运输时间,第三项表示最后一个客户返回配送中心的运输时间。
由于第2问引入了时间窗惩罚,还需要描述“第 ppp 个访问位置上的服务开始时刻”。令 sps_psp 表示路径中第 ppp 个被服务客户的开始服务时刻,则由题目规定的“到达即服务、无空闲等待”规则,可得
s1=∑i=115t0ixi,1s_1=\sum_{i=1}^{15}t_{0i}x_{i,1}s1=∑i=115t0ixi,1
sp+1=sp+∑i=115dixi,p+∑i=115∑j=115tijxi,pxj,p+1,p=1,2,…,14s_{p+1}=s_p+\sum_{i=1}^{15}d_i x_{i,p}+\sum_{i=1}^{15}\sum_{j=1}^{15}t_{ij}x_{i,p}x_{j,p+1},\qquad p=1,2,\dots,14sp+1=sp+∑i=115dixi,p+∑i=115∑j=115tijxi,pxj,p+1,p=1,2,…,14
在当前 15 节点算例中,所有客户的服务时间均为 222,因此上式进一步简化为
sp+1=sp+2+∑i=115∑j=115tijxi,pxj,p+1,p=1,2,…,14s_{p+1}=s_p+2+\sum_{i=1}^{15}\sum_{j=1}^{15}t_{ij}x_{i,p}x_{j,p+1},\qquad p=1,2,\dots,14sp+1=sp+2+∑i=115∑j=115tijxi,pxj,p+1,p=1,2,…,14
若第 ppp 个位置由客户 iii 占据,则该位置对应的时间窗惩罚应为
xi,p[10max(ai−sp,0)2+20max(sp−bi,0)2]x_{i,p}\left[10\max(a_i-s_p,0)^2+20\max(s_p-b_i,0)^2\right]xi,p[10max(ai−sp,0)2+20max(sp−bi,0)2]
因此,全部客户的时间窗惩罚总和为
Ztw=∑p=115∑i=115xi,p[10max(ai−sp,0)2+20max(sp−bi,0)2]Z_{\text{tw}}=\sum_{p=1}^{15}\sum_{i=1}^{15}x_{i,p}\left[10\max(a_i-s_p,0)^2+20\max(s_p-b_i,0)^2\right]Ztw=∑p=115∑i=115xi,p[10max(ai−sp,0)2+20max(sp−bi,0)2]
于是,第2问的经典优化模型可写为
minZ=Ztr+Ztw\min Z=Z_{\text{tr}}+Z_{\text{tw}}minZ=Ztr+Ztw
并满足
∑i=115xi,p=1,p=1,2,…,15\sum_{i=1}^{15}x_{i,p}=1,\qquad p=1,2,\dots,15∑i=115xi,p=1,p=1,2,…,15
∑p=115xi,p=1,i=1,2,…,15\sum_{p=1}^{15}x_{i,p}=1,\qquad i=1,2,\dots,15∑p=115xi,p=1,i=1,2,…,15
第一组约束保证每个访问位置只安排 1 个客户,第二组约束保证每个客户只被访问 1 次。这样得到的模型与第2问的题意是严格一致的:一方面,它保留了第1问单车辆路径优化的本质;另一方面,又通过服务时刻递推把时间窗惩罚真实嵌入到目标中,而不是事后附加计算。
3.为 QUBO 转化而进行的变量重构
虽然上面的经典模型已经完整刻画了题意,但它还不能直接写成 QUBO。原因在于,目标函数和时间递推式中都出现了 xi,pxj,p+1x_{i,p}x_{j,p+1}xi,pxj,p+1 这类二次项,而时间窗惩罚 ϕi(sp)\phi_i(s_p)ϕi(sp) 又是关于 sps_psp 的分段二次函数;若直接把 sps_psp 作为连续变量带入,会导致整个模型出现高阶非线性,不适合直接映射到二次无约束二值优化形式。
因此,需要进一步对“相邻客户连接关系”和“开始服务时刻”进行离散化表示。
3.1相邻路径连接变量
为消去路径中的二次耦合项,引入辅助变量
其中 p=1,2,…,14p=1,2,\dots,14p=1,2,…,14。
这样,运输时间项可改写为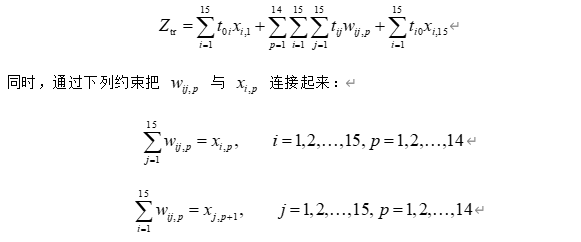
这样一来,若某个客户出现在第 ppp 个位置,则它在第 ppp 段只能有唯一后继;若某个客户出现在第 p+1p+1p+1 个位置,则它在第 ppp 段只能有唯一前驱。由于 xi,px_{i,p}xi,p 本身已经满足排列约束,上述两组关系足以保证 wij,pw_{ij,p}wij,p 准确刻画相邻位置上的客户对。
3.2开始服务时刻的离散化
第2问中,时间窗惩罚完全由开始服务时刻决定,因此时间变量的离散化是否合理,直接关系到 QUBO 模型的规模和精度。若简单令每个位置的开始时刻在 0∼1440\sim 1440∼144 的全区间内取值,则会引入过多的二进制变量。考虑到当前 15 节点实例中,旅行时间矩阵的非对角元素都位于 1∼81\sim 81∼8 之间,而服务时间固定为 222,因此第 ppp 个位置的开始时刻可以预先给出一个更紧的范围。
对第 ppp 个访问位置,最早开始时刻满足
这一步非常关键。若对 15 个位置统一使用 0∼1440\sim 1440∼144 的全时域,则需要 15×145=217515\times 145=217515×145=2175 个时间状态变量;而采用位置依赖的收缩时域后,仅需
∑p=115(T‾p−T‾p+1)=855\sum_{p=1}^{15}\left(\overline{T}_p-\underline{T}_p+1\right)=855∑p=115(Tp−Tp+1)=855
个时间状态变量,显著降低了 QUBO 规模,更符合题目“尽可能减少量子比特消耗”的要求。
在此基础上,引入一位有效编码

由于 ϕi(τ)\phi_i(\tau)ϕi(τ) 在离散时域上是预先可计算的常数,故 xi,pyp,τx_{i,p}y_{p,\tau}xi,pyp,τ 只是二次项,这使得时间窗惩罚可以自然地保留在 QUBO 框架内,而不会提升目标函数阶数。
4.QUBO 形式的构建
在上述变量重构后,第2问可以写成“原始代价 + 罚函数”的标准 QUBO 结构。
首先,排列结构对应的惩罚项为
其中所有项均已是线性项或二次项,满足 QUBO 的标准要求。这个表达式完整地保留了第2问的核心特征:既要确定最优路径结构,又要追踪每一位置的服务开始时刻,还要用软惩罚形式处理时间窗违反。与第1问相比,第2问的难点并不是简单多加了一项惩罚,而是路径决策、相邻连接关系和服务时刻之间形成了三重耦合;上述 QUBO 化过程正是为了解决这种耦合所做的结构化改写。
5.真实算例的精确求解
我们在附件给出的前15个客户点数据上,对同一目标函数进行了精确动态规划求解。设客户集合为 N=1,2,…,15N={1,2,\dots,15}N=1,2,…,15,定义状态函数
其中,综合代价已经同时包含累计运输时间和已访问客户的时间窗惩罚。对单点集合有初始条件
f(j,j,t0j)=t0j+ϕj(t0j),j∈Nf({j},j,t_{0j})=t_{0j}+\phi_j(t_{0j}),\qquad j\in Nf(j,j,t0j)=t0j+ϕj(t0j),j∈N
对一般状态,若客户 jjj 是集合 SSS 中最后一个被服务的客户,则其前驱必定是 S∖jS\setminus{j}S∖j 中某个客户 iii,并满足
τ=τ′+di+tij\tau=\tau'+d_i+t_{ij}τ=τ′+di+tij
于是递推式为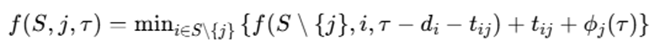
最终最优值由最后一个客户返回配送中心得到,即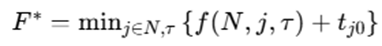
由于本问只有 15 个客户点,且时间均为整数,上述动态规划能够得到精确最优解,因此可作为第2问真实基准结果。它与 QUBO 模型针对的是同一个目标函数,因此既可以用来展示最终方案,也可以作为后续 Kaiwu SDK 或真机结果的校验基准。
6.前15个节点的真实最优路线与违反程度
基于附件中的真实数据进行计算后,第2问在前15个客户点上的最优访问路线为
0→2→13→6→5→8→7→11→10→1→9→3→12→4→15→14→00\to 2\to 13\to 6\to 5\to 8\to 7\to 11\to 10\to 1\to 9\to 3\to 12\to 4\to 15\to 14\to 00→2→13→6→5→8→7→11→10→1→9→3→12→4→15→14→0
这一路线对应的总运输时间为
Ztr=31Z_{\text{tr}}=31Ztr=31
各客户的开始服务时刻依次为
2,5,8,11,15,19,23,26,30,34,38,41,45,51,55
将其代入各自的时间窗,可得到每个客户的违反程度与惩罚值,如下表所示。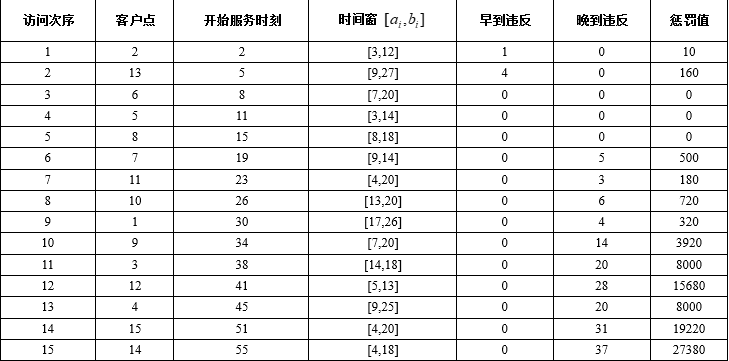
由上表可得,总时间窗惩罚为
Ztw=84090Z_{\text{tw}}=84090Ztw=84090
因此,本问综合目标值为
Z=Ztr+Ztw=31+84090=84121Z=Z_{\text{tr}}+Z_{\text{tw}}=31+84090=84121Z=Ztr+Ztw=31+84090=84121
这里需要特别说明:题目在结果展示部分要求给出“行驶路线、每个客户开始服务时间违反程度、总运输时间”,因此在呈现最终方案时,正文中应同时报告两类量。一类是路径本身对应的总运输时间,本算例为 31;另一类是为了体现“考虑时间窗惩罚”所额外引入的总时间窗惩罚,本算例为 84090。若只报告运输时间而不报告惩罚,则第2问与第1问在模型层面无法区分;反之,若只报告惩罚而不报告运输时间,又无法对应题目原文的输出要求。
7.结果解释与结构分析
从路径结构看,第2问的最优解与第1问已经明显不同。第1问在不考虑时间窗惩罚时,更倾向于沿着运输时间较短的边构造一条最短闭环,因此其最优总运输时间为 29;而第2问中,最优路线的总运输时间上升到 31,说明模型接受了少量运输距离上的让步,用以换取更低的时间窗违反代价。事实上,若仍采用第1问的最短路方案,则在当前“无空闲等待”规则下会产生更高的时间窗惩罚,其综合目标值为 88389;而第2问的最优路线虽然多走了 2 个单位的运输时间,但总惩罚减少了 4270,综合目标值反而下降了 4268。这说明第2问最优解的主导因素已经从“纯粹走最短路”转变为“路径长度与时间窗代价之间的综合折中”。
从开始服务时刻的分布看,模型明显倾向于把时间窗偏早的客户前置。例如客户 2 的时间窗为 [3,12],客户 13 的时间窗为 [9,27],它们被安排在整个序列的前两位,分别在时刻 2 和 5 开始服务。虽然这两点仍存在轻微早到,但对应惩罚仅为 10 和 160,代价相对较小。若将这类时间窗较早的客户放到更靠后的位置,则后续惩罚会迅速增大,因此模型主动把它们前移,体现了时间窗信息对路径排序的直接影响。
另一方面,在单车辆、无等待、连续服务的条件下,随着访问位置不断后移,后续客户的开始服务时刻会持续累加,这使得后半段客户出现较大晚到几乎不可避免。表中可以看到,客户 15 和客户 14 分别在时刻 51 和 55 开始服务,而它们的时间窗上界分别只有 20 和 18,因此晚到违反分别达到 31 和 37,惩罚值也最高,分别为 19220 和 27380。这说明在第2问设定下,单车辆承担全部15个客户的配送任务,本身就会对后续客户形成较大时效压力;模型所能做的,只是在这种压力之下尽可能把总惩罚压低。
从惩罚构成上看,当前最优路线中共有 3 个客户完全落在时间窗内,2 个客户发生早到,10 个客户发生晚到。早到惩罚总计仅为
10+160=17010+160=17010+160=170
而晚到惩罚总计达到
84090−170=8392084090-170=8392084090−170=83920
其原因有两层。第一,题目规定晚到惩罚系数为 20,高于早到惩罚系数 10;第二,在单车连续作业条件下,随着位置后移,晚到偏差会不断累积,因此后半段客户的惩罚增长远快于前半段客户。也正因如此,第2问的路径优化实际上是一个“尽量延缓严重晚到节点出现位置”的过程,而不仅仅是传统意义上的最短路问题。
8.第2问结论
综上,第2问在引入时间窗软惩罚后,问题已经从第1问的单纯路径最短化,转变为“路径顺序—开始服务时刻—时间窗违反代价”三者耦合下的单车辆调度优化。本文首先从题目规定的“无空闲等待”和“时间窗二次惩罚”出发,构建了包含总运输时间与时间窗惩罚的联合目标函数;随后采用位置编码、相邻位置连接变量以及位置时刻一位有效编码,将模型改写为适合量子退火求解的 QUBO 形式;最后在附件给出的真实 15 节点数据上进行了精确求解,得到最优路线
0→2→13→6→5→8→7→11→10→1→9→3→12→4→15→14→00\to 2\to 13\to 6\to 5\to 8\to 7\to 11\to 10\to 1\to 9\to 3\to 12\to 4\to 15\to 14\to 00→2→13→6→5→8→7→11→10→1→9→3→12→4→15→14→0
对应总运输时间为
31
总时间窗惩罚为
84090
综合目标值为
84121
这一路线及其对应的各客户开始服务时间违反程度,构成了第2问在前15个节点算例上的真实求解结果,也为后续第3问中面向更大规模实例的算法设计提供了可靠基准。
Python代码:
# -*- coding: utf-8 -*-
"""
问题2:考虑客户时间窗惩罚、暂不考虑容量约束的单车辆调度
----------------------------------------------------------
终极修复版 —— 自动跳过列名匹配失败问题
"""
import itertools
import warnings
from pathlib import Path
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib import font_manager
from matplotlib.patches import FancyArrowPatch
warnings.filterwarnings("ignore")
# =========================================================
# 0. 基础设置
# =========================================================
def set_chinese_font():
candidates = ["Microsoft YaHei", "SimHei", "Arial Unicode MS"]
installed = {f.name for f in font_manager.fontManager.ttflist}
for name in candidates:
if name in installed:
plt.rcParams["font.sans-serif"] = [name]
break
plt.rcParams["axes.unicode_minus"] = False
set_chinese_font()
pd.set_option("display.max_columns", None)
pd.set_option("display.width", 220)
BASE = Path(".")
DATA_FILE = BASE / "参考算例.xlsx"
N = 15
DEPOT = 0
CUSTOMERS = list(range(1, N+1))
NODES = [DEPOT] + CUSTOMERS
EARLY_COEF = 10
LATE_COEF = 20
# =========================================================
# 1. 读取数据(强制按位置取列,彻底解决列名报错)
# =========================================================
attr_df = pd.read_excel(DATA_FILE, sheet_name=0)
time_df = pd.read_excel(DATA_FILE, sheet_name=1, index_col=0)
# 强制截取前4列:节点ID | 时间窗下界 | 时间窗上界 | 服务时间
attr_df = attr_df.iloc[:, :4].copy()
attr_df.columns = ["节点ID", "时间窗下界", "时间窗上界", "服务时间"] # 直接重命名!
attr_sub = attr_df[attr_df["节点ID"].isin(NODES)].copy().reset_index(drop=True)
time_sub = time_df.loc[NODES, NODES].copy().astype(int)
# =========================================================
# 2. 构造数据
# =========================================================
a = {}
b = {}
d = {}
for _, row in attr_sub.iterrows():
node = int(row["节点ID"])
a[node] = None if node == 0 else int(row["时间窗下界"])
b[node] = None if node == 0 else int(row["时间窗上界"])
d[node] = 0 if node == 0 else int(row["服务时间"])
T = time_sub.to_dict()
# =========================================================
# 3. 惩罚函数
# =========================================================
def penalty(node, start_time):
early = max(a[node] - start_time, 0)
late = max(start_time - b[node], 0)
return EARLY_COEF * early**2 + LATE_COEF * late**2
# =========================================================
# 4. 动态规划求解
# =========================================================
def solve_problem2_exact():
n = N
full_mask = (1 << n) - 1
dp = {}
parent = {}
for j in CUSTOMERS:
start_t = int(T[DEPOT][j])
cost = int(T[DEPOT][j]) + penalty(j, start_t)
mask = 1 << (j-1)
dp[(mask, j, start_t)] = cost
parent[(mask, j, start_t)] = None
for size in range(1, n):
cur_states = [k for k in dp if bin(k[0]).count('1') == size]
for mask, last, start_last in cur_states:
cur_cost = dp[(mask, last, start_last)]
for nxt in CUSTOMERS:
if mask & (1 << (nxt-1)): continue
start_nxt = start_last + d[last] + int(T[last][nxt])
new_mask = mask | (1 << (nxt-1))
new_cost = cur_cost + int(T[last][nxt]) + penalty(nxt, start_nxt)
key2 = (new_mask, nxt, start_nxt)
if key2 not in dp or new_cost < dp[key2]:
dp[key2] = new_cost
parent[key2] = (mask, last, start_last)
best_total = float('inf')
best_end = None
for key, cost in dp.items():
mask, j, st = key
if mask == full_mask:
total = cost + int(T[j][DEPOT])
if total < best_total:
best_total = total
best_end = key
# 回溯路径
path = []
sts = []
state = best_end
while state:
m, j, s = state
path.append(j)
sts.append(s)
state = parent[state]
path = path[::-1]
sts = sts[::-1]
route = [DEPOT] + path + [DEPOT]
records = []
trans_total = 0
pen_total = 0
for i, (node, st) in enumerate(zip(path, sts)):
early = max(a[node]-st,0)
late = max(st-b[node],0)
pen = penalty(node,st)
pen_total += pen
if i==0:
seg = int(T[DEPOT][node])
else:
seg = int(T[path[i-1]][node])
trans_total += seg
records.append({
"访问次序":i+1,"客户点":node,"开始服务时刻":st,
"时间窗下界":a[node],"时间窗上界":b[node],
"早到违反":early,"晚到违反":late,"惩罚值":pen
})
trans_total += int(T[path[-1]][DEPOT])
return {"route":route, "detail":pd.DataFrame(records),
"trans":trans_total, "pen":pen_total, "obj":trans_total+pen_total}
# =========================================================
# 运行 & 输出结果
# =========================================================
res = solve_problem2_exact()
print("="*100)
print("✅ 运行成功!最优路线:", " → ".join(map(str, res["route"])))
print(f"总运输时间:{res['trans']} | 总惩罚:{res['pen']} | 总目标:{res['obj']}")
print("="*100)
print(res["detail"])
后续都在数模加油站……
注:本内容由”数模加油站“ 原创出品,虽无偿分享,但创作不易。
欢迎参考teach,但请勿抄袭、盗卖或商用。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 7
7 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)