具身强化学习框架RLightning发布,一套代码实现从单机开发到规模化验证,加速物理智能算法迭代
作者:YZY, QJW, ZYC, LHJ from DeepLink Group @ Shanghai AI Lab
TL;DR
RLightning 是一个面向具身强化学习的统一训练框架,旨在解决单机原型开发与分布式规模化训练割裂的问题。它通过 Runtime Adapter、双层控制器和细粒度资源编排,让研究者可以用同一套接口完成从算法验证到多机多卡扩展的全过程,无需重写分布式逻辑;同时针对具身 RL 中高频环境交互和异构组件协同进行了专门优化,在保证收敛效果的前提下,实现了更高的训练吞吐与接近线性的扩展能力:人形控制任务从 1 节点扩展到 8 节点实现 81.4% 线性扩展效率;OpenVLA 操作任务保持与基线一致收敛精度的同时,将训练吞吐提升了 30% 。
框架开源地址:https://github.com/DeepLink-org/RLightning
一、问题背景
具身强化学习的核心范式是让 Agent 在物理环境中高频交互、采集数据、更新策略。这个过程看似直接,但在工程层面存在几个让研究者头疼的问题:
- 原型开发与分布式扩展的割裂。 算法研究者习惯在单机单进程下写代码、调 bug。一旦验证可行,要扩展到多卡集群进行规模化训练,往往需要重写大量分布式通信和调度逻辑。现有框架在这两端各有侧重:Stable Baselines3、RSL-RL 擅长快速原型验证,但缺乏分布式扩展能力;Ray RLlib 具备分布式基础设施,但工程复杂度高,且未针对具身场景适配;RLinf 等框架针对具身场景做了设计,但其原生分布式架构在算法原型阶段引入了额外的门槛。
- 具身 RL 的数据交互密度远超 LLM RL。 LLM 领域的 RL(如 PPO、GRPO )瓶颈主要在大模型并行、长序列推理和梯度计算。而具身 RL 的核心瓶颈在于环境交互吞吐。例如在Humanoid任务中,采样频率可达数百 Hz,系统需要持续、高频地在仿真器与策略模型之间做数据通信。
- 异构生态碎片化。 不同仿真器(IsaacLab、MuJoCo、ManiSkill)、不同模型规模(MLP 到数十亿参数的 VLA)、不同任务类型(运动控制 vs 操作任务),现有框架缺乏统一适配能力。
RLightning 正是针对这些问题而设计的具身 RL 框架。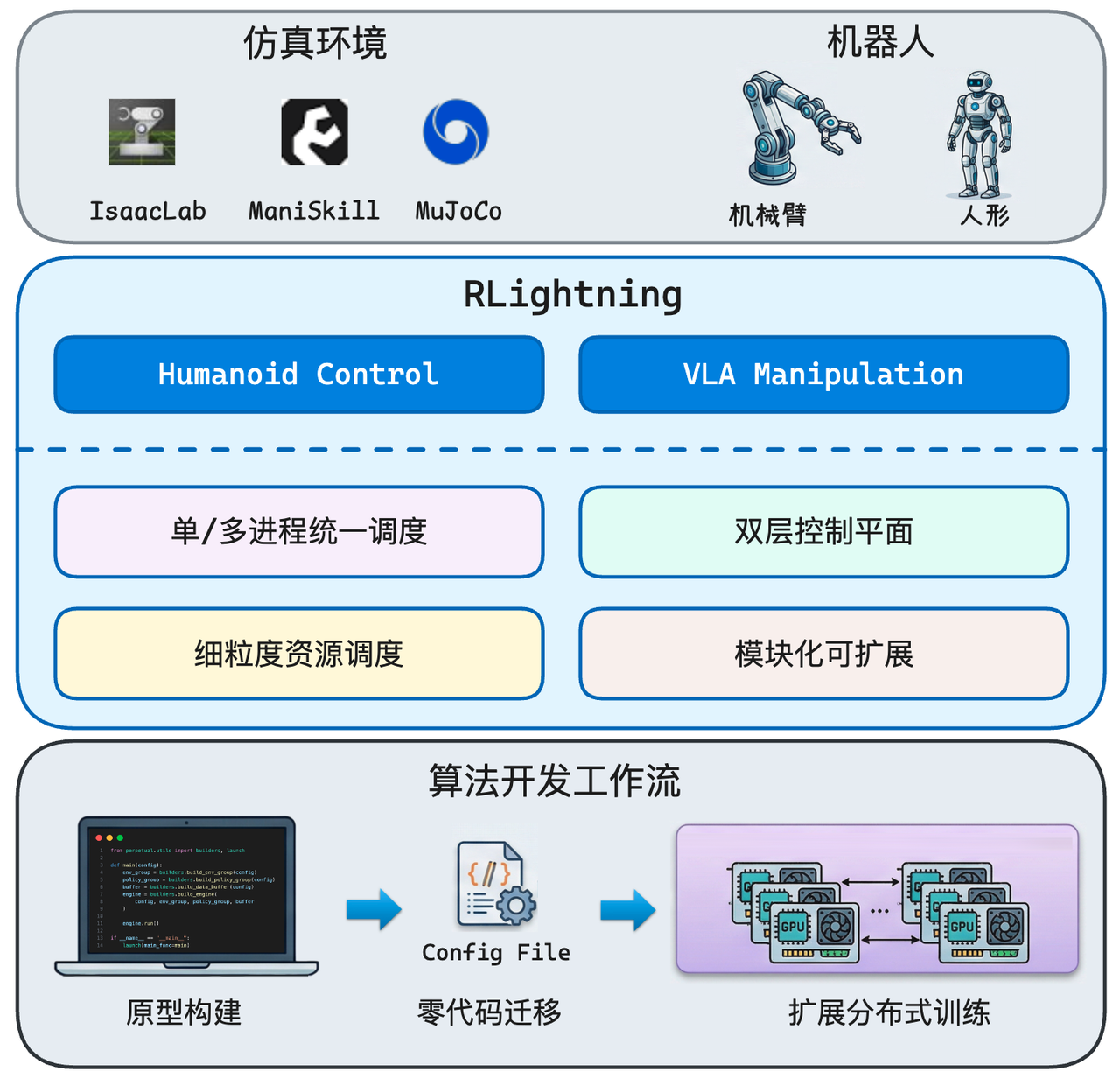
二、设计思路总览
RLightning 的核心设计理念是统一原型开发与分布式扩展。上层编程接口不因运行模式改变而改变,底层通过运行时适配自动处理单机与分布式的差异。
系统采用四层架构:
- Application Layer:面向用户的编程接口,用于构建 RL 应用、实现策略算法、定制组件
- Controller Layer:由 Engine(全局编排)和 WorkerGroup(组内调度)组成的双层控制器
- Worker Layer:实际执行计算的工作单元——Env、Policy、Buffer 三类 Worker 可独立扩展
- Runtime & Resource Layer:运行时适配与资源调度,对上层完全透明
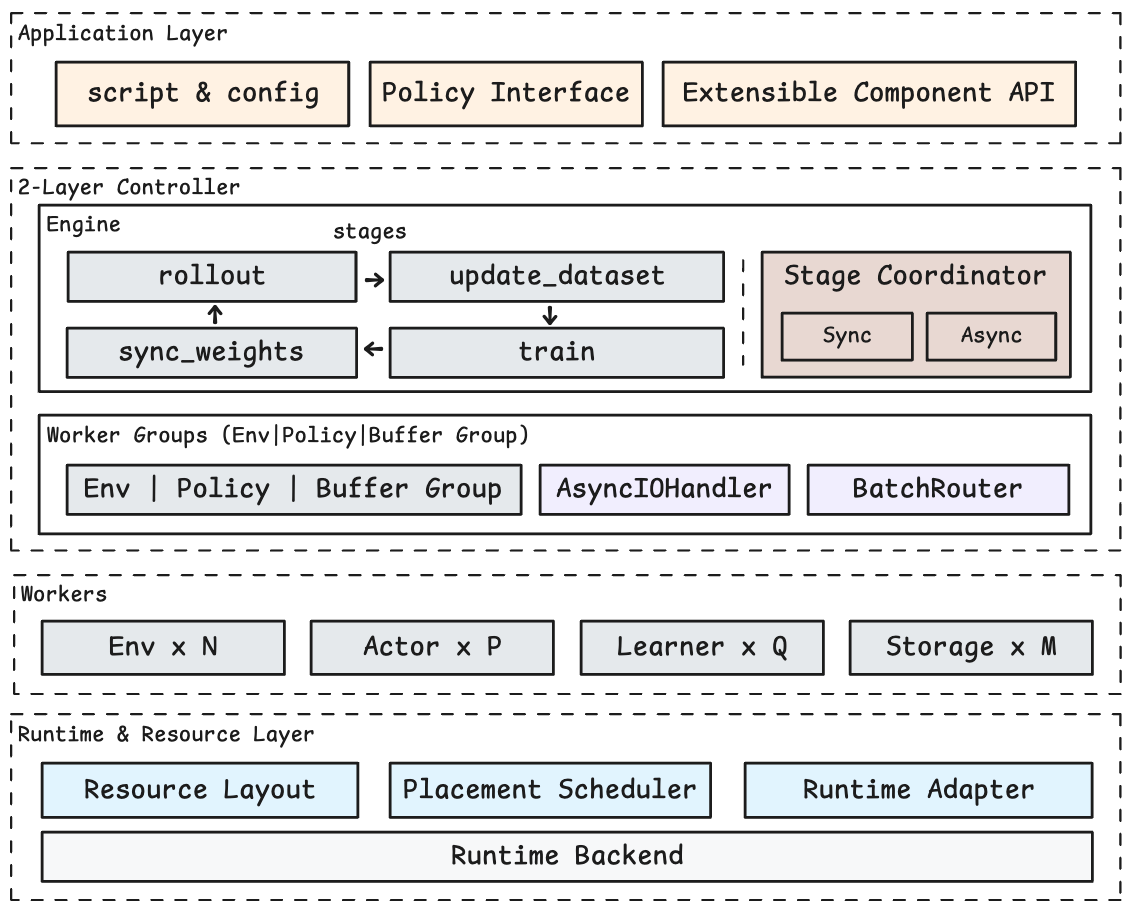
RLightning 有三个主要的设计:(1)Runtime Adapter 实现零代码迁移;(2)双层控制器 + 数据流解耦实现灵活调度;(3)细粒度资源编排提升硬件利用率。
三、统一编程接口:写单进程代码,集群规模运行
1. Runtime Adapter:透明的运行时适配
RLightning 的解法是在底层引入 Runtime Adapter 层。这一层屏蔽了 Worker 创建、调用、通信等底层细节的差异,使得上层编程接口在单机和分布式模式下完全一致。
用户只需编写一个标准的 Python 入口脚本:
from RLightning import builder, launch
def main(config):
env_group = builder.build_env_group(config)
policy_group = builder.build_policy_group(policy_cls, config)
buffer = builder.build_data_buffer(buffer_cls, config)
engine = builder.build_engine(env_group, policy_group, buffer, config)
engine.run()
launch(main, config_path)
通过 builder API 构建 env_group、policy_group、buffer,组装成 engine 后调用 run()。这段代码在单机和集群上是同一份。
扩展规模时,只需修改配置文件中 Worker 的数量和 runtime 模式。例如从单卡切换到 8 节点 64 卡,不需要改动任何算法代码,框架自动完成分布式后端的映射与部署。
2. 组件扩展机制
RLightning 定义了 BaseEnv、BasePolicy、BaseBuffer 三个抽象基类,规范了组件间的接口和数据交互协议。用户要接入自定义仿真器或算法,只需继承对应基类、实现必要方法、注册即可——不需要修改框架代码。这种松耦合设计也使得在同一个训练流水线中混合不同类型的环境和策略成为可能。
四、双层控制器与数据流解耦
具身 RL 涉及仿真器、策略模型、数据缓存等多类异构组件。这些组件之间存在高频交互和不同步执行:rollout 阶段 Env 和 Policy 需要数百 Hz 的交互频率,train 阶段需要从 Buffer 中采样并做梯度更新,weight sync 阶段需要将更新后的参数广播到所有推理 Worker。不同 RL 算法(on-policy vs off-policy)对这些阶段的执行顺序和同步要求也不同。
1. Engine:全局工作流编排
Engine 是 RL 流水线的全局编排器,将 RL 工作流组织为四个阶段:
- rollout:推理策略与环境高频交互,采集经验数据
- update_dataset:训练策略从 Buffer 中采样数据
- train:在采样数据上执行前向与反向计算,更新模型参数
- sync_weights:将更新后的权重同步到推理策略
Engine 内部的 Stage Coordinator 负责控制各阶段的触发顺序和同步语义。它支持两种模式:
- 严格顺序执行:适用于 on-policy 算法(如 PPO),确保 rollout 使用最新策略
- 异步流水线并行:适用于 off-policy 算法,rollout 和 train 可以并行执行以最大化吞吐。同时也可用于调控 Actor 和 Learner 之间的 off-policy 程度,在训练稳定性和收敛效率之间取得平衡
2. WorkerGroup:组内细粒度调度
WorkerGroup 封装了一组同类型的 Worker,对上暴露批量接口,对内负责任务分发和结果聚合。在分布式模式下,WorkerGroup 本身不持有实际数据,而是管理数据引用的收集与分发,协调 Worker 之间的点对点数据传输。
WorkerGroup 内部有两个关键优化模块:
BatchRouter 负责将输入 batch 分发到各 Worker,支持三种路由策略:
- State-aware routing(状态感知路由):支持有状态和无状态两种模式。对于需要多轮推理且要保持 Worker 亲和性的场景(如 RNN 策略),请求会被持续路由到同一个 Worker
- Load-balancing routing(负载均衡路由):动态监控各 Worker 的负载水平,优先将任务分派到低负载节点
- Node-affinity routing(节点亲和路由):优先将请求路由到与调用方同节点的 Worker,减少跨节点通信延迟
AsyncIOHandler 采用异步收集机制,持续提取已完成的结果并流式下发到下游,将 batch 的输入和输出解耦。相比同步模式下必须等待所有 Worker 完成才返回结果,这种方式避免了被最慢 Worker 拖慢整个 batch 的长尾延迟问题。
这种双层设计的好处在于:研究者只需通过 Engine 接口关注粗粒度的工作流编排("先 rollout 再 train"),底层的异步 IO、流水线并行、路由策略等细节由数据流层自动处理。
实测数据表明,在人形运动控制任务上,开启异步 IO 和流水线优化后,8 节点 64 卡的端到端吞吐相比关闭优化时提升至 3.75 倍。
五、细粒度资源编排
1. 核心思想
不同类型的 Worker 在计算量、通信模式、执行顺序上差异很大。RLightning 的 Resource Manager 允许各 Worker 类型独立扩展——Env Worker、Policy Worker、Buffer Worker 的数量可以根据任务特点分别配置,而非简单地按节点等比放大。
2. 两种放置策略
Resource Manager 提供两种核心放置策略:
- Disaggregate(分离策略):训练组件(Learner + Buffer)与采样组件(Env + Actor)物理隔离到不同资源池。适合异步训练场景,最大化减少组件间资源争用,提升 GPU 吞吐
- Colocate(共置策略):训练与采样组件共享同一资源池。适合同步训练场景,策略稳定性要求较高时使用
3. Rollout 阶段的进一步优化
在 rollout 阶段,Env 和 Actor 之间需要高频交互。RLightning 引入 env_strategy 参数进行更细粒度的调度:
- Default 模式:Env 和 Actor Worker 各占独立 GPU 资源
- Device-Colocate 模式:Env 和 Actor Worker 共享 GPU 设备,利用时分复用和硬件级资源共享提升设备利用率
4. Onload/Offload 机制
对于顺序执行的组件(例如同一个 GPU 上先做推理再做训练),RLightning 支持动态加载/卸载机制——当某个组件不活跃时将其从 GPU 卸载,为活跃组件腾出显存和算力,从而实现计算资源的时间复用。
系统支持 Auto(自动规划)和 Manual(手动控制)两种模式。Auto 模式下,Resource Manager 自动发现集群资源并创建 Ray Placement Group 进行组件放置;Manual 模式下用户可以精确控制每个组件的放置位置。
六、实验验证
RLightning 在两类具有代表性的具身 RL 任务上进行了评估。选择这两类任务的原因是它们覆盖了具身 RL 的两种典型场景:小模型 + 高频交互的人形运动控制任务和大模型 + 推理密集的VLA 操作任务。
1. 人形全身控制任务
实验在 8 节点 RTX 4090 集群上进行,使用 IsaacLab 仿真器,策略网络为MLP构成的小模型,对比基线为 BeyondMimic。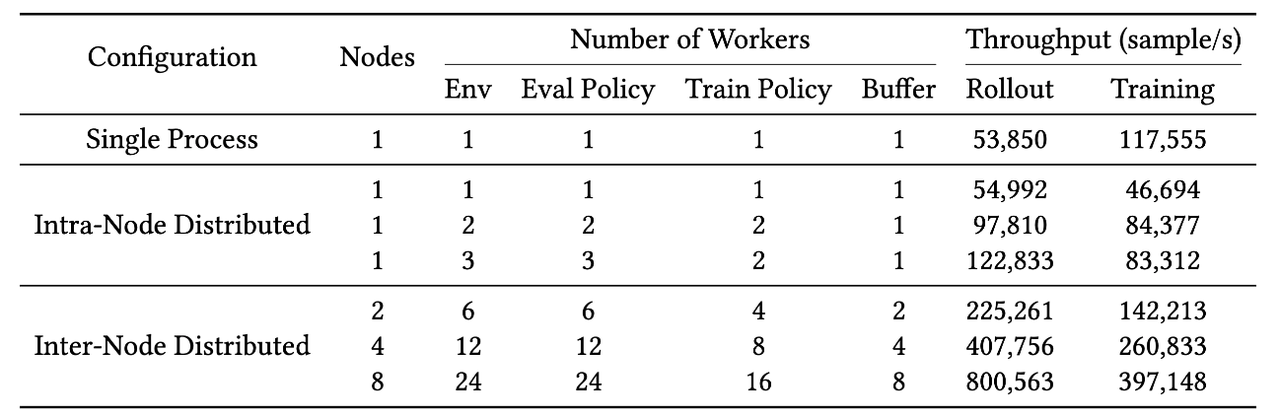
单卡性能:在单进程模式下,RLightning 的 rollout 吞吐为 53,850 samples/s,与 BeyondMimic 的 61,399 samples/s 处于同一量级,验证了框架本身不引入额外开销。
分布式可扩展性:
从 1 节点到 8 节点,rollout 吞吐从 122,833 提升到 800,563 samples/s,实现 6.51 倍加速,对应 81.4% 的线性扩展效率。从单卡到 8 节点,仅通过修改config而未改动任何代码,框架的 rollout 吞吐实现了近 15 倍的提升。
2. OpenVLA RL 操作任务
实验使用VLA作为策略模型,在 ManiSkill 仿真器上训练,对比基线为 RLinf。
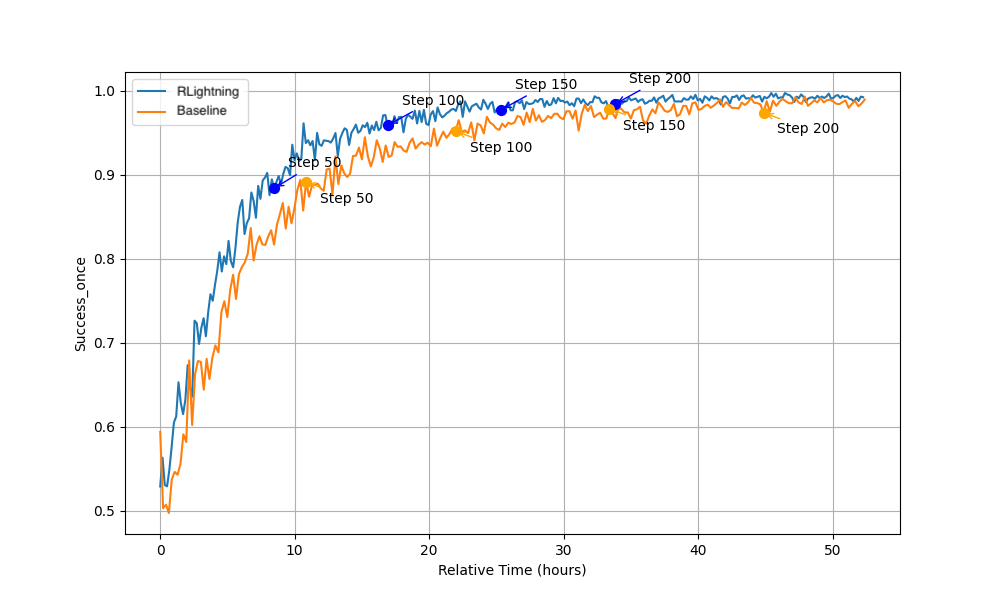
在精度上, RLightning 与 RLinf 的收敛趋势完全一致。在相同训练步数下,两者达到相同的测试集成功率。这验证了 RLightning 的系统优化不以算法收敛为代价。
在系统性能上,RLightning 将训练吞吐量提升了30%以上。这表明在同等硬件配置下,RLightning能以更快的速度达到等效收敛,加速具身模型迭代。
框架开源地址:https://github.com/DeepLink-org/RLightning
未来我们将持续迭代,支撑更多前沿的AI研究需求。欢迎社区使用并提出宝贵的意见。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)