我用 AI 做了一个完整的 Java 求职训练平台,从想法到落地竟然没手写代码!
最近我完整做了一个 AI 项目,项目名叫 AI Interview Coach。这是一个面向 Java 求职场景的训练平台,核心目标不是做一个简单的聊天问答 Demo,而是把 “画像、题单、训练、点评、报告、沉淀” 串成一条完整链路,让用户可以按照更贴近真实求职训练的方式去使用。
项目已经开源:
开源地址:https://gitee.com/xiaohan666777/aicodeing?source=header_my_projects
这个项目的技术栈如下:
- 后端:
Spring Boot 3、Spring Security、JWT、Spring AI Alibaba、MySQL、Redis、RabbitMQ、Quartz、Swagger - 前端:
Vue 3、Vite - 联调与验证:
Playwright、浏览器自动化、截图回归
很多人一提到 AI Coding,第一反应往往是:
“无非就是让 AI 帮忙写几个页面、补几个接口而已。”
但这次我完整做完一个项目之后,最大的感受反而是:
AI 最厉害的地方,不只是帮你省掉敲代码的时间,而是当你的业务流程足够清晰时,它真的可以帮你把一个完整系统快速搭起来。
这篇文章我不想写成 “我接了个模型接口,然后做了个页面” 的流水账。我更想复盘的是:
一个 AI Coding 项目,怎么从 “AI 能生成代码”,走到 “系统真的能跑、能用、能扩展”。
一、项目简介:我做的不是聊天 Demo,而是一条完整训练链路
这次我做的项目叫 AI Interview Coach,定位不是一个简单的聊天问答工具,而是一套面向 Java 求职训练场景 的平台。
它不是 “问一题答一题” 的普通对话产品,而是一条完整训练链路:
画像设置 -> 题单配置 -> 一次性生成整套题 -> 集中作答 -> 统一点评 -> 按需生成深度报告 -> 错题/趋势/计划沉淀
这条链路的目标很明确:
- 先理解用户是谁、准备什么方向
- 再生成更贴近用户背景的训练内容
- 让用户专注完成整场训练
- 最后集中复盘和沉淀结果
二、为什么我没有把它做成 “AI 聊天页面”
在做这个项目之前,我看过不少 “AI 面试” 类产品。很多产品看起来很聪明,但真正用起来,总会暴露出一些很典型的问题。
比如:
- 一上来就开始提问,完全不关心用户准备投什么岗位
- 不关心项目经历和技术方向,题目过于泛
- 每答一题都要等 AI 再生成下一题,体验很卡
- 答题、点评、总结全堆在一个页面里,注意力被不断打断
- 一场训练结束后,没有结果沉淀,下一次训练又像重新开始
这些问题表面看像是模型能力不够,但后面我越来越觉得,真正的问题往往不是模型,而是业务流程没有设计清楚。
所以我在做这个平台时,先定下了一个原则:
不要让 AI 到处冒出来,要让 AI 只出现在真正需要它的地方。
这也是为什么我最后做出来的,不是一个 “功能很多” 的系统,而是一条比较清晰的训练主线。用户进入系统后,不是面对一堆功能菜单,而是顺着一个完整流程往下走:先明确背景和目标,再开始训练,再统一复盘,最后才进入更深入的分析和沉淀。
从产品体验上看,这一点其实比 “多接一个模型能力” 更重要。
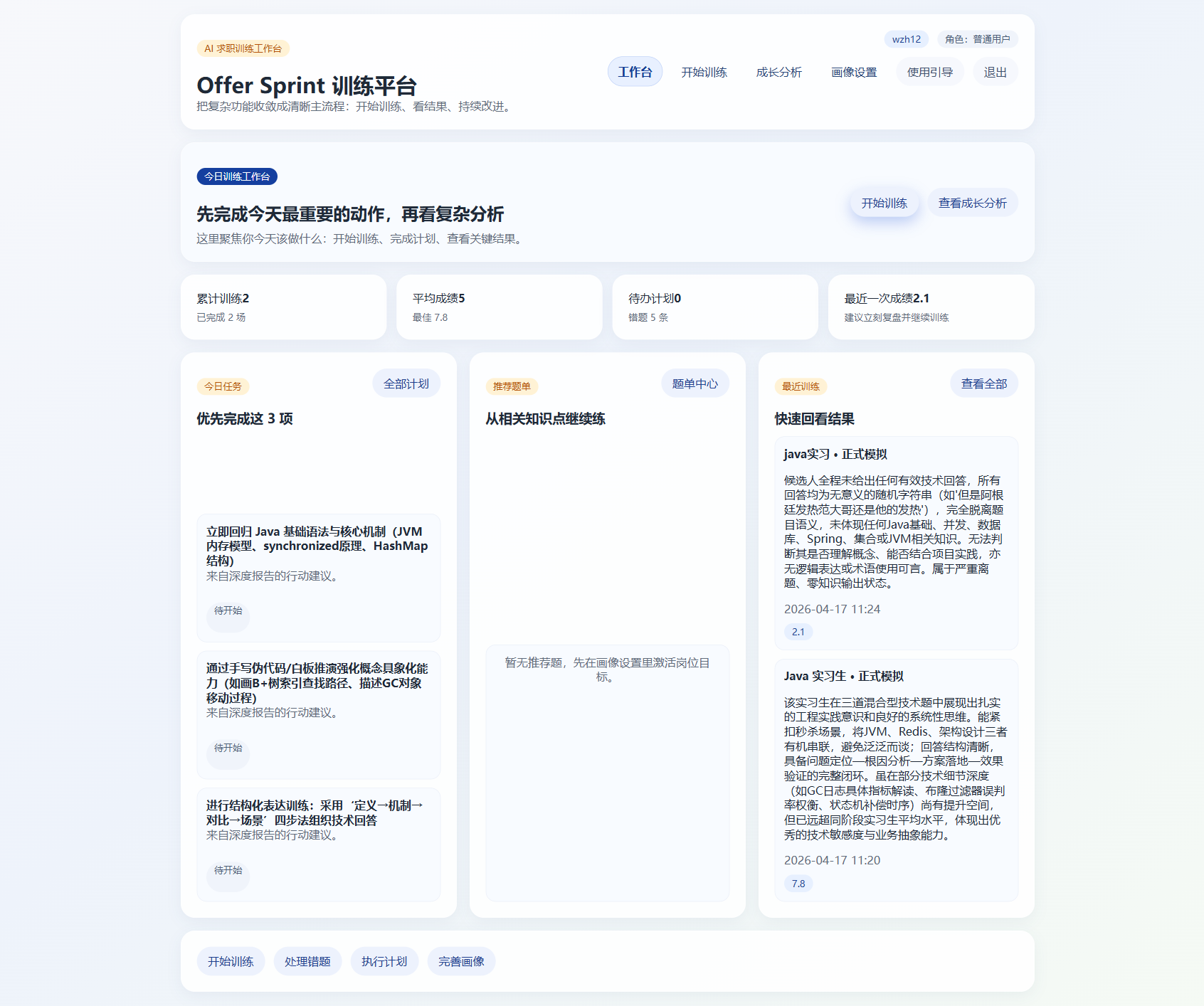
三、训练开始前,我先做了 “画像设置”
这个设计我后面越来越确定,而且几乎没有再动过。
因为如果系统不知道用户要准备什么岗位、技术方向偏什么、做过什么项目、哪里强、哪里弱,那后面生成出来的题目和建议,大概率都会变得很空。这种 “没有上下文的智能”,看起来像个 AI,实际上很难真正服务训练场景。
所以在正式开始训练前,我先设计了一个画像设置环节。它的作用不是让用户去填一大堆表单,而是把真正会影响训练效果的信息提前整理好,比如:
- 用户背景概况
- 项目经历
- 岗位目标
- 技术方向
- 目标公司类型
- 重点想补的知识内容
这样做之后,后面的题目生成就不再是 “随机出几道 Java 面试题”,而是会更贴近用户自己的求职方向。
比如同样是 Java 岗位:
- 有人偏后端基础
- 有人更强调项目表达
- 有人更在意
Redis、MySQL、JVM - 有人更希望训练 “项目深挖” 和 “场景题”
系统只有先理解这些差异,后面的训练才会更像 “针对你” 的训练,而不是泛泛而谈的通用问答。
所以在这个平台里,画像并不是一个附属页面,而是整个训练链路的输入起点。它的价值不在于 “信息填得多”,而在于让后面的 AI 结果真正建立在上下文之上。
四、我没有采用 “答一题,生成一题” 的模式
一开始我其实也试过更常见的交互方式:用户答完一题,AI 再继续出下一题,同时顺手做点评。
这种模式看起来很自然,也很像聊天,但实际跑起来之后,我很快发现它有两个明显问题。
1. 慢
因为每完成一题,系统都要重新调用模型生成反馈、组织内容、再返回下一题。只要链路稍微一长,页面就会有明显等待感。
2. 打断感很强
用户明明正在组织自己的回答,结果每答完一题就被系统打断一次。这种体验其实不太像真实面试,反而更像 “做一半停一半” 的碎片化对话。
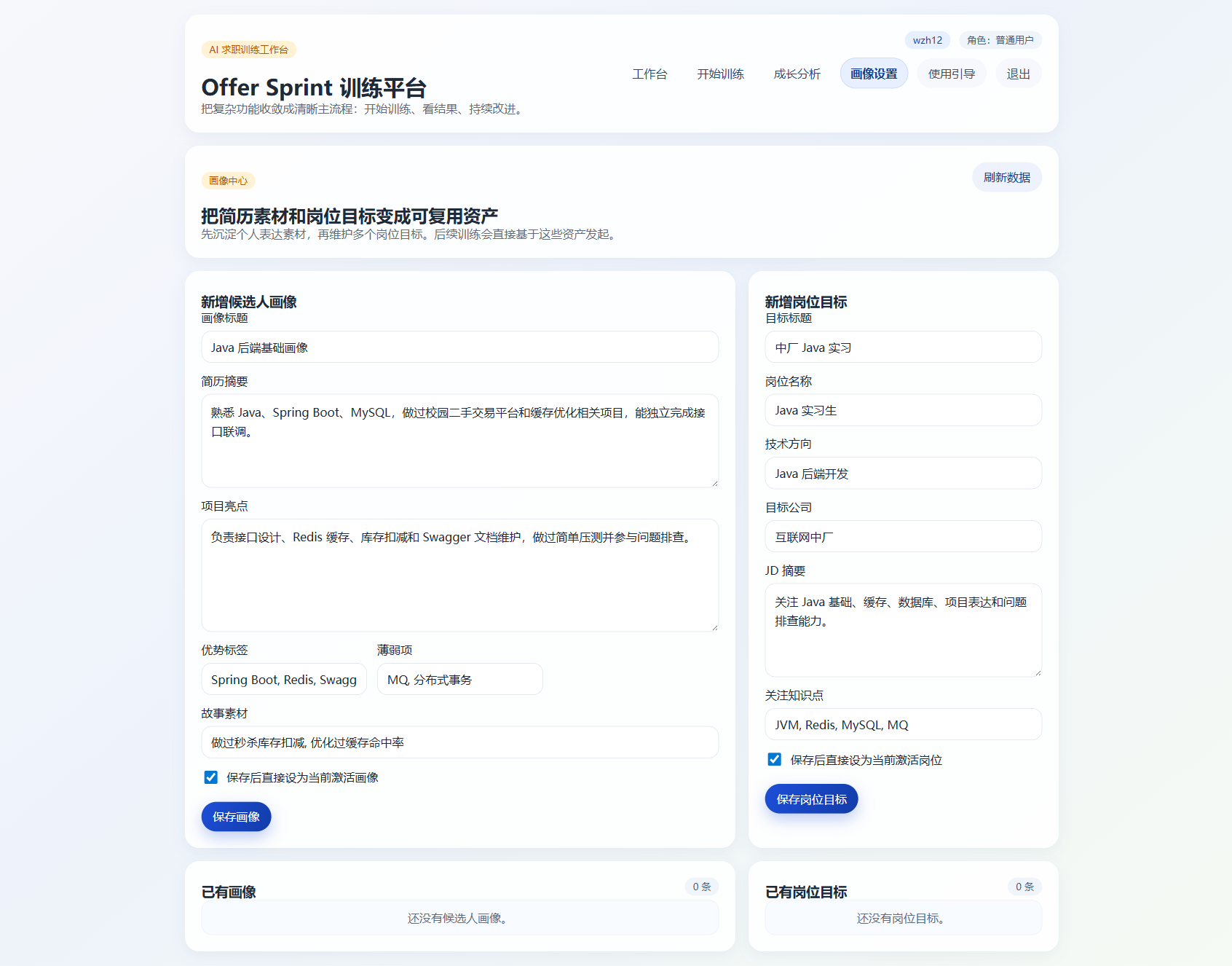
后来我把流程彻底改掉了:
- 训练开始前,一次性生成整套题
- 训练结束后,再统一生成整场点评
这个改动看起来只是产品交互调整,但实际影响非常大。
一方面,答题阶段变得更流畅了。用户不需要反复等待 AI,也不会在训练过程中不断被打断。另一方面,后端链路也变简单了,不再需要把每一道题都做成一条同步阻塞流程。
这次调整也让我很清楚地意识到一件事:
很多看起来像性能问题的问题,本质上其实不是性能问题,而是流程设计出了问题。
当流程本身不合理的时候,你再怎么做 loading、再怎么优化提示文案,提升都很有限。反过来,当主流程顺了,很多原本让人头疼的问题会自然消失。
五、答题、点评、报告,为什么一定要拆开
这个点我一开始也走过弯路。
最早我以为,如果能一边答题一边看到点评,系统会显得更智能。但实际用下来之后,我发现这并不是一个真正提升体验的设计。
因为用户在答题的时候,需要的是一种比较专注的状态。这个时候他更关心的是:
- 怎么表达
- 怎么组织语言
- 怎么把自己的项目和知识点说清楚
而用户在看点评的时候,心态已经变成了复盘和分析,他需要的是:
- 从结果里找问题
- 看差距
- 想下一步怎么改
这两种状态并不适合混在一起。
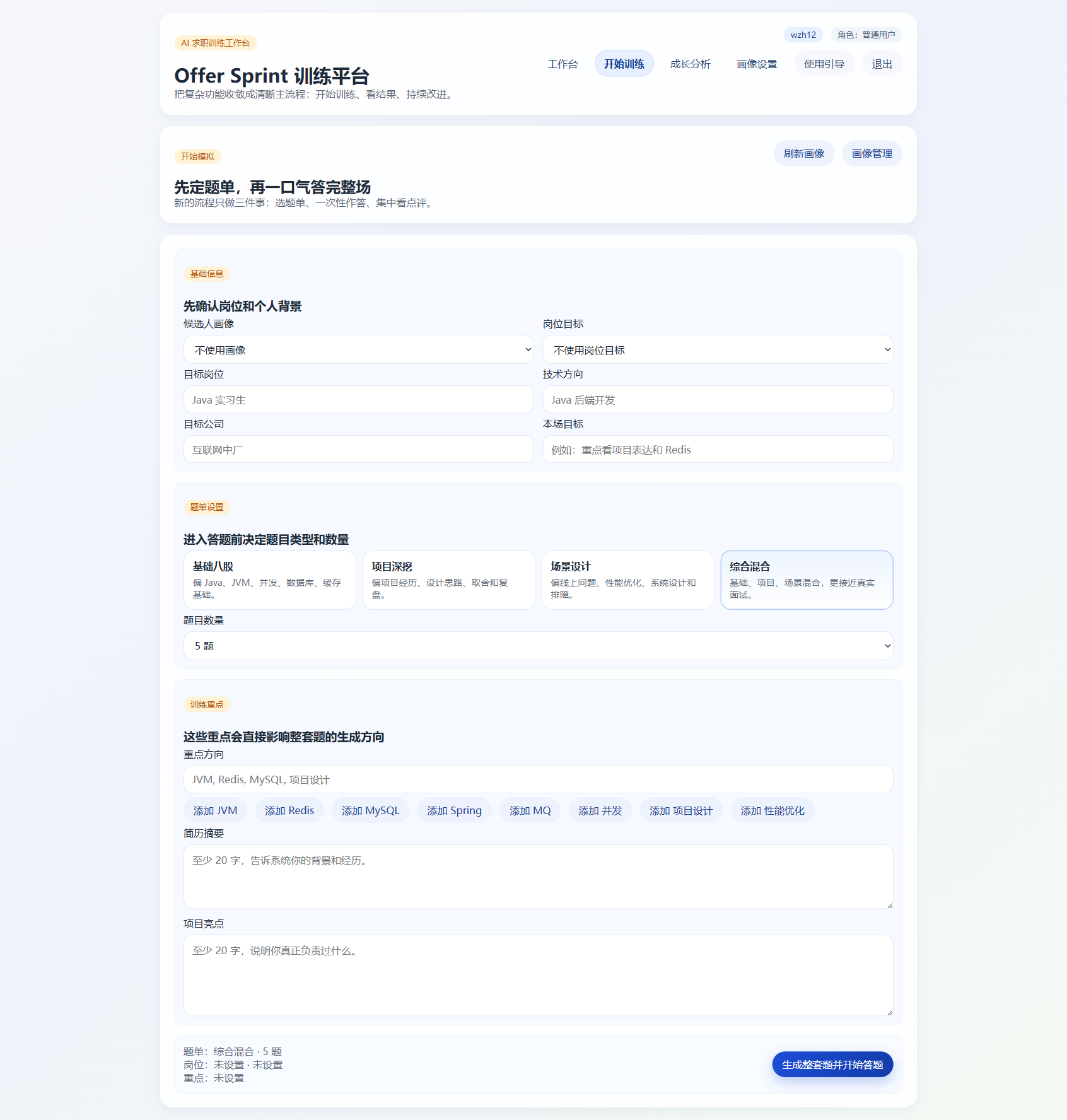
所以我最后把整个流程拆成了三个阶段:
- 第一阶段只负责答题
- 第二阶段统一承接整场点评
- 第三阶段再进入更深入的报告分析
这样拆开之后,整个系统的节奏一下就变清楚了。
- 用户在答题时只管输出,系统不要打断他
- 用户在复盘时只管分析,信息也可以集中呈现
- 更重的深度报告,则放到后一步按需触发
这其实不是简单的页面拆分,而是把 “训练” 和 “分析” 彻底区分成了两个动作。一旦这样处理,整条链路的逻辑就顺很多,后面的错题沉淀、成长分析和训练计划也都有了自然的承接位置。
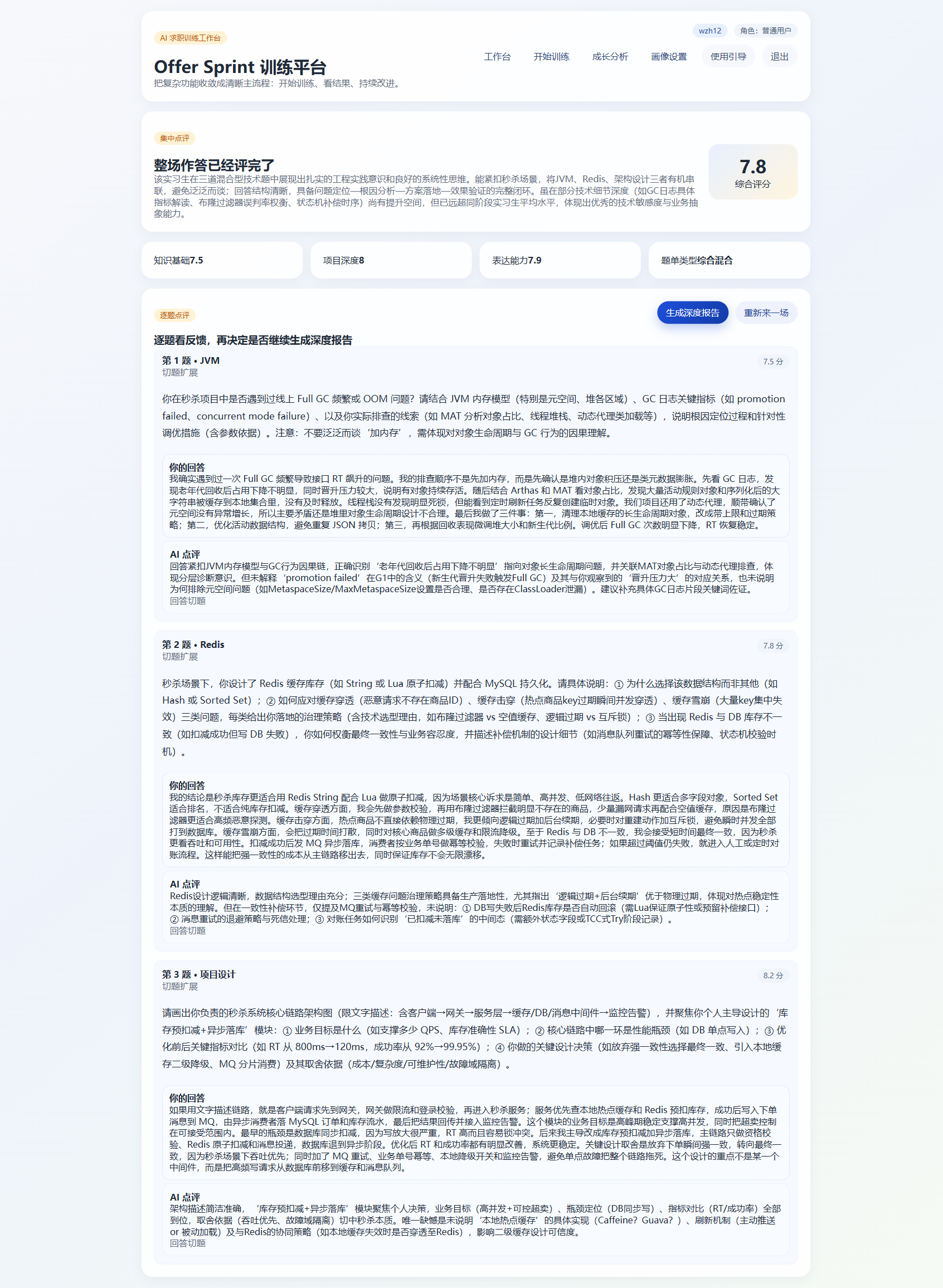
六、深度报告为什么不适合默认自动生成
现在很多 AI 产品都喜欢在用户完成一个动作之后,立刻生成一大段长报告,看起来很高级。但这种设计放到真实训练场景里,未必合理。
因为不是每一场训练都值得做深度分析。
有时候用户只是想快速练一轮基础题,看看自己的表达状态;有时候他可能只是想刷几道题找感觉。这种情况下,如果系统每次都强行生成一份很重的深度报告,反而会拖慢主流程,也会增加很多不必要的等待。
所以我在这里做了一个很明确的取舍:
深度报告不默认生成,而是由用户在看完集中点评之后按需触发。
这样设计之后,好处很明显。
一方面,主流程更轻了。用户完成一场训练之后,可以很快先拿到整体反馈。另一方面,真正需要深入分析的时候,再去触发深度报告,这时候无论是心理预期还是使用场景,都会更匹配。
而且从系统实现上讲,深度报告本身就不只是 “再让模型多写一段总结”。它往往还会结合当前训练结果、知识点表现、错题情况和后续推荐方向去做更深的加工。
所以这一步天然更适合做成异步流程,而不是强塞进主请求里。

七、后端架构上,我更关心 “训练链路” 而不是 “三层模板”
如果只用一句话来概括这个项目的后端,我会说:
它是一个单体应用,但真正核心不是 Controller、Service、Repository 这种教科书式分层,而是围绕训练主链路做业务编排。
比如用户创建一场训练时,后端做的并不只是保存一条记录。它会先把当前场景下的训练上下文固化下来,包括:
- 岗位方向
- 简历摘要
- 项目亮点
- 训练目标
- 题单类型
- 题量
- focusAreas
然后结合这些信息做一轮轻量检索增强;接着再调用 AI 生成整套题单;最后把题目和会话状态一起落到数据库里。
同样,用户完成训练之后,系统也不是简单地 “拿答案喂给模型,然后返回一段话”。
它会先:
- 校验作答是否完整
- 把整套问答整理成稳定结构
- 再进行统一点评
- 最后把单题反馈、综合评分、基础报告等结果拆回业务系统里
我后来越来越觉得,AI 应用开发和普通 CRUD 项目最大的区别之一就在这里:
真正重要的不是 “调了哪个模型接口”,而是你怎么把输入上下文整理干净,再把模型输出结构化地接回系统里。
这一步如果做得乱,后面再多能力都会很难维护。而一旦上下文、职责边界和状态流转整理清楚,整个系统会稳定很多。
八、技术选型上,我更关心 “它到底解决了什么问题”
这次项目虽然技术栈不算少,但我一直在提醒自己一件事:
每一个技术都要回答,它在这里到底解决了什么问题。
Spring Boot 3
它让我可以比较自然地把鉴权、AI 接入、数据库、调度和消息能力整合在一起。对于当前这个体量的项目来说,单体应用已经足够,而且可维护性会比过早拆微服务更好。
Spring Security + JWT
解决的是登录态和用户上下文绑定的问题。因为这个系统不是匿名体验页,而是一个有画像、有训练历史、有个人结果沉淀的平台,所以身份体系是基础。
MySQL
承担的是核心结构化数据存储。训练会话、题目、回答、报告、计划这些数据,本质上都很适合关系型数据库来管理。
Redis
在当前阶段没有被我用得特别重,主要承担一些轻量缓存职责,比如知识检索结果缓存和高频读场景加速。我不太希望为了 “技术栈丰富” 而强行堆中间件。
RabbitMQ
承担了更真实的异步任务职责,尤其是在深度报告这种更重的后处理流程里,它不是摆设,而是真正在把重任务从主链路中剥离出来。
Quartz
作用相对没那么显眼,但我还是把它保留了下来。因为训练提醒、复盘任务生成、计划推进这些能力,天然需要时间驱动的执行方式。它虽然不是当前最亮眼的部分,但对于后续演进是有意义的。
Spring AI Alibaba + DashScope
这是整个项目中最核心的 AI 接入层。整套题单生成、整场点评和报告输出,都是围绕这部分能力展开的。
Swagger
它的价值不只是 “方便调接口”,更重要的是把系统边界清楚地展示出来。页面一多、接口一多,如果没有统一文档,系统会很快失控。
九、这次 AI Coding 最有价值的地方,不是 “帮我写代码”,而是改变了开发方式
回头看这次开发过程,我觉得最有价值的地方,不是 “AI 帮我省了多少打字时间”,而是它改变了我推进项目的方式。
以前做项目,很多想法停留在脑子里,是因为从想法变成代码实现,成本很高。但现在有了 AI 之后,第一版系统可以非常快地被铺出来。页面、接口、文档、联调代码,很多东西都能迅速成型。
可真正决定项目质量的,从来不是 “第一版出来得有多快”,而是后面你怎么继续收敛。
这个项目里,AI 帮我做得最多的事情,包括:
- 快速搭前后端初版
- 批量修改页面结构
- 调整接口契约
- 重构部分流程
- 补文档和联调验证
但真正让系统从 “能跑” 变成 “好用” 的,依然是人工做的那些判断:
- 哪些流程要保留,哪些流程应该删掉
- 哪些页面职责必须拆开
- 哪些字段有价值,哪些只是看起来很完整
- 哪些兼容逻辑应该停止修补,直接重写
所以我现在越来越认可一句话:
AI 负责高速实现,人负责定义问题、控制边界、做取舍、验结果。
真正的能力,不在于让 AI 写出多少代码,而在于你能不能把 AI 写出来的系统收敛成一个逻辑成立、体验顺滑的产品。
十、做完这个项目后,我总结了几条很实用的经验
1. 想减少模型幻觉,最有效的办法不是不断提醒它 “不要乱编”
而是把上下文尽量结构化。当你给它的是清晰场景、明确目标和有限输出范围时,结果通常会稳定很多。
2. 给 AI 下任务时,少说 “做个功能”,多说 “现在用户在哪个状态,接下来应该发生什么,什么不能发生”
很多时候,模型不是不会写,而是在猜你真正想要的业务。
3. 不要太迷信第一版代码
AI 特别擅长快速把东西推到一个 “看起来差不多” 的状态,但从 “差不多” 到 “真的能用”,中间通常还隔着不少重构和取舍。
4. 尽量让 AI 产出可验证的结果
比如明确 DTO、接口、状态枚举、页面流程,而不是只输出一大段看起来很懂的设计说明。因为只有可验证,才容易真正落地。
5. 要敢删 AI 写出来的代码
这件事非常重要。AI 写得快,所以更容易堆出很多 “先留着吧” 的冗余逻辑。可一旦这些逻辑开始影响后续维护,最好的方式往往不是继续补,而是直接删掉重来。
十一、总结
做完这个项目之后,我越来越确定一件事:
AI Coding 真正厉害的地方,不是帮你省掉了多少敲键盘的时间,而是它把 “做一个完整系统” 这件事的门槛拉低了。
但与此同时,它对开发者的要求其实更高了。因为现在最容易得到的,已经不是代码,而是一堆代码。真正稀缺的,是把这些代码收敛成一条合理链路的能力。
这个项目对我来说,最大的价值也正在这里。它让我验证了一件事:AI 确实可以支撑一个完整系统的快速开发;但只有当业务逻辑足够清晰、架构边界足够明确时,AI 才会真正成为放大器,而不是混乱的加速器。
所以如果你也在做 AI 项目,我现在更想建议你少问一句:
“这个模型还能不能更强一点?”
多问一句:
“这个系统的流程,到底顺不顺?”
很多时候,后一个问题,才是真正决定项目质量的关键。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)