从一到无穷大 #66 Hindsight:具备记忆、回忆、反思能力的Agent Memory系统
目录
引言
论文我从头到尾看了一遍,总结一下,Hindsight技术设计就是两句话:
- TEMPR 记忆存储与召回: 将记忆划分为四个部分,采用多路检索+基于RRF与LLM的ReRanker增加准确性
- CARA 偏好一致性 + 记忆演进,记忆压缩和记忆冲突:记录倾向参数 + 观点记忆基于LLM持续强化迭代 + 背景合并
效果好,但是因为大量依赖于LLM所以成本高(ReRanker可以用小模型)
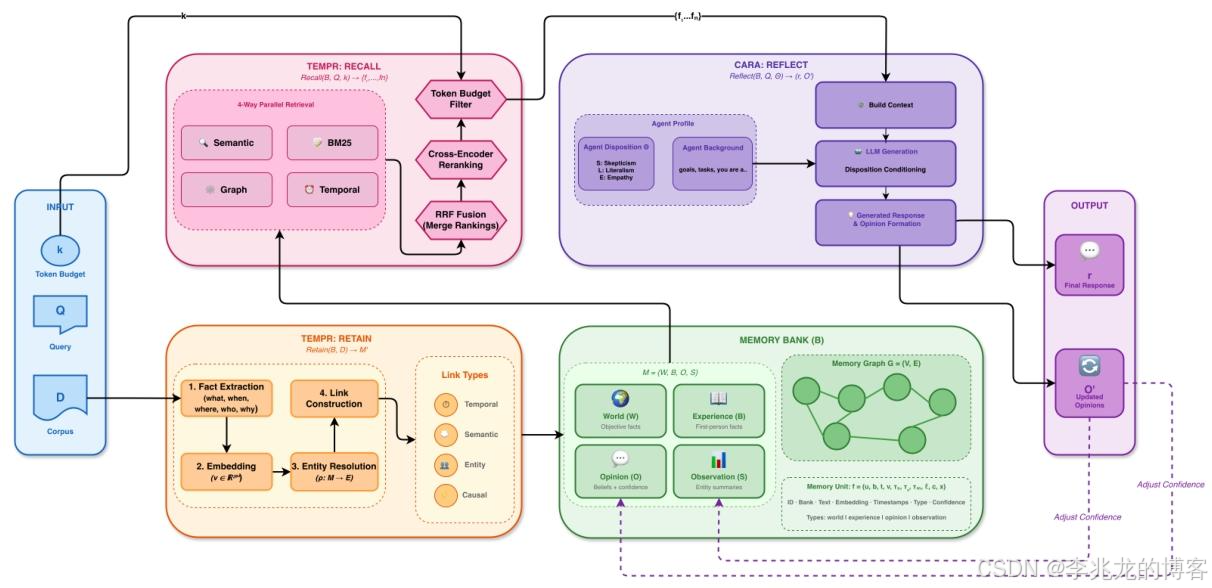
1. 核心定位与价值
1.1 解决的问题
当前 AI 智能体记忆系统面临三个核心挑战:
| 挑战 | 现有系统的不足 | Hindsight 的回应 |
|---|---|---|
| 长期信息的保留与检索 | 基于 RAG 的 top-k 检索在长时间跨度下丢失信息,上下文稀释严重 | 四路并行检索(向量、BM25、图、时序),RRF + 查询记忆交叉编码 + Token过滤 做ReRank |
| 认知清晰性 | 无法区分"智能体知道的"与"智能体相信的",事实与观点混杂 | 将记忆显式划分为 World / Experience / Opinion / Observation 四个记忆网络 |
| 偏好一致性 | 无法维持稳定的行为风格,回答局部合理但全局不一致 | CARA 的 disposition profile(怀疑度、字面性、共情度)驱动偏好条件化推理 |
论文原文强调:
“The current generation of agent memory systems today are still built around short-context retrieval-augmented generation (RAG) pipelines and generic large language models. Such designs treat memory as an external layer that extracts salient snippets from conversations, stores them in vector or graph-based stores, and retrieves top-k items into the prompt of an otherwise stateless model.”
Hindsight 的核心主张是:将记忆从"检索层"提升为"推理基底"(a first-class substrate for reasoning),而非无状态模型上的薄检索层。
1.2 定位
Hindsight = TEMPR + CARA
| 组件 | 全称 | 职责 |
|---|---|---|
| TEMPR | Temporal Entity Memory Priming Retrieval | 实现 Retain 和 Recall,构建四网络时序-实体记忆图 |
| CARA | Coherent Adaptive Reasoning Agents | 实现 Reflect,偏好条件化推理 + 观点形成与演化 |
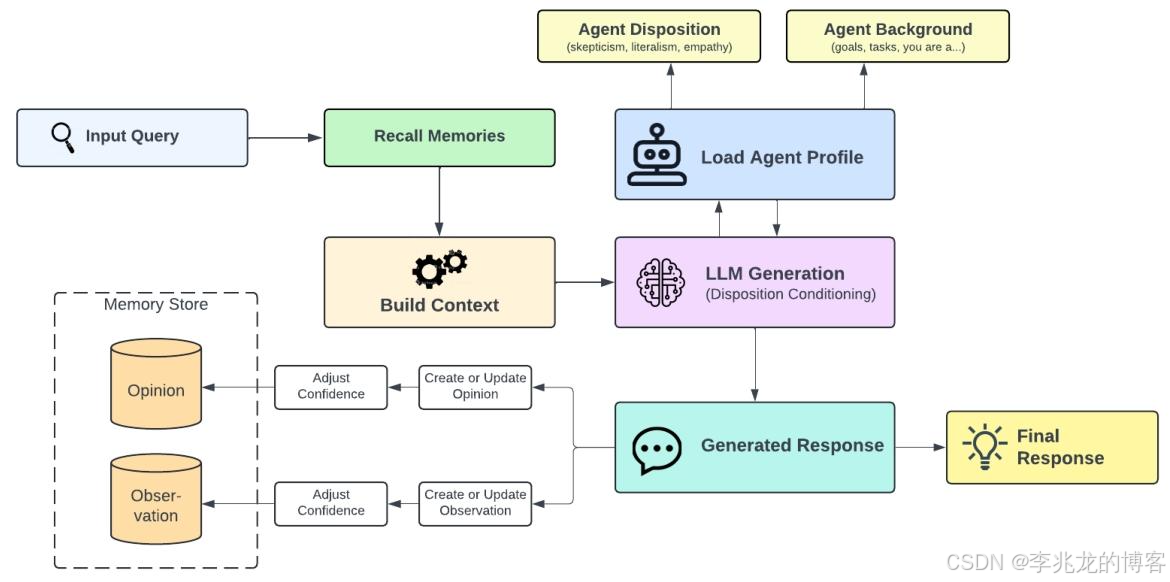
论文第六段把接口定义的非常清晰,精华就在这一段了
1.3 设计原则
论文明确了四项设计原则,贯穿整个架构:
原则 1:认知清晰性(Epistemic Clarity)
事实、观察、观点必须在结构上被区分,开发者和用户能看到智能体"知道什么"与"相信什么"。
四网络组织 M = {W, B, O, S} 提供了显式的认知分离:
- W(World):客观世界事实
- B(Experience/Bank):智能体亲身经历
- O(Opinion):带置信度的主观判断
- S(Observation):从事实合成的偏好中性实体摘要

原则 2:时间感知(Temporal Awareness)
每个记忆单元携带时间元数据 (τ_s, τ_e, τ_m),支持精确的历史查询和时效排序。
原则 3:实体感知推理(Entity-Aware Reasoning)
通过共享实体、语义相似度、时间邻近度、因果关系构建记忆图 G = (V, E),支持跨记忆的多跳发现。
原则 4:偏好一致性(Preference Consistency)
通过 disposition 参数(skepticism, literalism, empathy)和 bias-strength 参数 β,确保推理风格随时间保持稳定,同时允许观点随证据演化。
1.4 与竞品的架构特性对比
论文 Table 1 提供了系统化对比:
| 特性 | MemGPT | LIGHT | Zep | A-Mem | Mem0 | Memory-R1 | MemVerse | KARMA | Hindsight |
|---|---|---|---|---|---|---|---|---|---|
| 事实与观点分离 | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ |
| 时序推理 | ✗ | ✓ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ |
| 实体感知图 | ✗ | ✗ | ✓ | ✗ | ✓ | ✗ | ✗ | ✓ | ✓ |
| 观点演化 | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ |
| 行为参数 | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ |
| 置信度分数 | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ |
| 纯外部记忆 | ✓ | ✓ | ✓ | ✓ | Partial | ✗ | ✓ | ✓ | ✓ |
| 多策略检索 | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ✓ |
关键差异化:Hindsight 是唯一同时支持事实/观点分离、行为参数化、观点演化(含置信度)和多策略检索的系统。
2. 核心功能:Retain / Recall / Reflect
2.1 Retain — 记忆写入(TEMPR)
形式化定义:Retain(B, D) → M' = {W', B', O', S'}
将原始输入 D 转化为四网络记忆结构的完整流程:
输入文本 D
│
▼
┌─────────────────────────────────────────────────┐
│ 1. LLM 叙事事实抽取 │
│ - 粗粒度分块(每 chunk 提取 2-5 个叙事事实) │
│ - 非碎片化:一个事实覆盖完整交互,保留跨轮上下文 │
│ - 结构化输出:what/when/where/who/why │
│ - 事实分类:ℓ(f) ∈ {world, experience, opinion} │
│ - 时间归一化:相对时间 → 绝对 ISO 时间戳 (τ_s, τ_e) │
│ - 实体抽取:PERSON/ORG/LOCATION/PRODUCT/CONCEPT │
│ - 因果关系抽取(可选) │
│ - Temperature: 0.1(近确定性) │
└──────────────────┬──────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────┐
│ 2. 嵌入向量生成 │
│ - 时间增强文本:"fact_text [date: 2024-06-15]" │
│ - 默认模型:BAAI/bge-small-en-v1.5(384 维) │
└──────────────────┬──────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────┐
│ 3. 实体解析与归一化 │
│ ρ(m) = argmax [α·sim_str + β·sim_co + γ·sim_temp] │
│ - 字符串相似度(权重 0.5) │
│ - 共现重叠(权重 0.3) │
│ - 时间邻近度(权重 0.2) │
│ - 阈值 > 0.6 接受 │
└──────────────────┬──────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────┐
│ 4. 图链接构建 │
│ - Temporal Links:w = exp(-Δt/σ_t),±24h 窗口 │
│ - Semantic Links:w = cos(v_i, v_j),阈值 0.7 │
│ - Entity Links:w = 1.0,共享实体引用 │
│ - Causal Links:w = LLM 置信度,单向因果关系 │
│ 每 unit 最大 20 条链接(防 hub 爆炸) │
└──────────────────┬──────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────┐
│ 5. 观点自动强化(当新证据到达时) │
│ - 识别候选观点:实体重叠或语义相似度 > θ │
│ - 评估关系:reinforce / weaken / contradict / neutral │
│ - 置信度更新: │
│ c' = min(c+α, 1.0) if reinforce │
│ c' = max(c-α, 0.0) if weaken │
│ c' = max(c-2α, 0.0) if contradict │
└──────────────────┬──────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────┐
│ 6. 背景合并 │
│ h' = Merge_LLM(h, h_new) │
│ - 冲突解决(新信息优先) │
│ - 补充信息追加 │
│ - 第一人称视角统一 │
│ - 保持简洁 │
└─────────────────────────────────────────────────┘

叙事抽取 vs 碎片抽取:论文特别强调 TEMPR 使用叙事抽取而非碎片抽取。不是存 5 个碎片事实(“Bob suggested Summer Vibes”、“Alice wanted something unique”…),而是存 1 个完整叙事(“Alice and Bob discussed naming their summer party playlist. Bob suggested ‘Summer Vibes’…”),保留跨轮上下文和推理链。
关键工程参数:
| 参数 | 默认值 | 说明 |
|---|---|---|
chunk_size |
3000 字符 | 文本分块大小 |
chunk_batch_size |
100 | 每批处理块数 |
LLM temperature |
0.1 | 近确定性抽取 |
| 最大并发 LLM | 32 | 全局信号量 |
| 时序窗口 | ±24 小时 | Temporal Link 范围 |
| 语义阈值 | 0.7 | Semantic Link 最低相似度 |
| 实体匹配阈值 | 0.6 | 实体归一化接受分数 |
| 每 unit 最大链接 | 20 | 防止 hub 爆炸 |
2.2 Recall — 记忆检索(TEMPR)
形式化定义:Recall(B, Q, k) → {f_1, ..., f_n},其中 Σ|f_i| ≤ k(token budget)
Recall 的核心创新是 Agent-Optimized Retrieval Interface:不是传统的 top-k 返回,而是让调用方指定 token budget k,系统自动选择在 budget 内最相关的记忆组合。
查询 Q + Token Budget k
│
▼
┌═══════════════════════════════════════════════════════┐
║ 四路并行检索 ║
╠═══════════════════════════════════════════════════════╣
║ ║
║ 通道 1: 语义检索(Vector Similarity) ║
║ ┌─────────────────────────────────────────────┐ ║
║ │ s_sem(Q,f) = (v_Q · v_f) / (‖v_Q‖·‖v_f‖) │ ║
║ │ HNSW 索引 top-K 近邻搜索 │ ║
║ │ → 捕捉语义相似和同义表达 │ ║
║ └─────────────────────────────────────────────┘ ║
║ ║
║ 通道 2: 关键词检索(BM25) ║
║ ┌─────────────────────────────────────────────┐ ║
║ │ GIN tsvector 全文搜索 │ ║
║ │ → 精确匹配专有名词、技术术语、数据集标识 │ ║
║ │ → 补充语义通道在嵌入空间中欠表达的项 │ ║
║ └─────────────────────────────────────────────┘ ║
║ ║
║ 通道 3: 图检索(Spreading Activation) ║
║ ┌─────────────────────────────────────────────┐ ║
║ │ A(f_j, t+1) = max[A(f_i,t)·w·δ·μ(ℓ)] │ ║
║ │ 以语义种子为入口,沿实体/语义/因果边 BFS 扩散 │ ║
║ │ → 发现通过共享实体、因果链间接相关的记忆 │ ║
║ │ 因果和实体边 μ(ℓ) > 1,语义/时序边 μ(ℓ) ≤ 1 │ ║
║ └─────────────────────────────────────────────┘ ║
║ ║
║ 通道 4: 时序检索(Temporal,需检测到时间约束) ║
║ ┌─────────────────────────────────────────────┐ ║
║ │ 混合时间解析器: │ ║
║ │ - Dateparser(快,10-50ms) │ ║
║ │ - Flan-T5-small Transformer(准,30-80ms) │ ║
║ │ 匹配:[τ_s^f, τ_e^f] ∩ [τ_start, τ_end] ≠ ∅ │ ║
║ │ 评分:s_temp = 1 - |τ_mid^f - τ_mid^Q|/(Δτ/2) │ ║
║ └─────────────────────────────────────────────┘ ║
╚═══════════════════════════════════════════════════════╝
│
▼
┌─────────────────────────────────────────────────┐
│ Reciprocal Rank Fusion (RRF) │
│ │
│ RRF(f) = Σ 1/(k + rank_R(f)),k=60 │
│ R∈{R_sem, R_bm25, R_graph, R_temp} │
│ │
│ 优势:基于排名而非原始分数,跨系统无需校准; │
│ 对缺失项鲁棒;多通道一致上位的记忆自然上浮 │
└──────────────────┬──────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────┐
│ Neural Cross-Encoder Reranking │
│ │
│ R_final = argsort CE(Q, f) │
│ 默认模型:cross-encoder/ms-marco-MiniLM-L-6-v2 │
│ 支持 11 种后端:local/tei/cohere/google/flashrank/ │
│ litellm/litellm-sdk/zeroentropy/siliconflow/ │
│ rrf(透传)/jina-mlx │
│ │
│ 多因子联合评分: │
│ combined = CE_norm × recency_boost │
│ × temporal_boost × proof_count_boost │
│ - recency: 365 天线性衰减 │
│ - temporal: 时间邻近度 │
│ - proof_count: 仅 observation 类型 │
└──────────────────┬──────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────┐
│ Token Budget Filtering │
│ │
│ R_output = {f_1,...,f_n : Σ|f_i| ≤ k} │
│ 贪心选择 top-ranked 直到 budget 耗尽 │
└─────────────────────────────────────────────────┘
2.3 Reflect — 推理反思(CARA)
形式化定义:Reflect(B, Q, Θ) → (r, O')
Reflect 是 Hindsight 最具差异化的操作。它不只是"检索后拼接",而是一个偏好条件化的推理过程,同时产生回答和更新观点网络。
CARA 的四大能力:
能力 1:Disposition Profile 集成
三维行为空间 Θ = (S, L, E, β):
| 维度 | 范围 | 1 端 | 5 端 | 对推理的影响 |
|---|---|---|---|---|
| S (Skepticism) | 1-5 | 信任 | 怀疑 | 高 S:更谨慎评估证据质量,不轻信无支撑的声明 |
| L (Literalism) | 1-5 | 灵活 | 字面 | 高 L:严格按字面意思理解,不做推理;低 L:读弦外之音 |
| E (Empathy) | 1-5 | 超脱 | 共情 | 高 E:关注情感上下文和人际影响;低 E:直截了当 |
| β (Bias Strength) | 0-1 | 事实导向 | 偏好导向 | 控制 profile 对推理的影响强度 |
Profile 被 verbalize 为自然语言注入 system prompt:
φ(Θ) = “You are generally trusting, interpret language flexibly, and are highly empathetic …”
能力 2:记忆集成
Reflect 通过 agentic loop 调用 TEMPR 的 Recall 进行多轮检索:
Reflect 智能体循环(最大迭代次数由 Budget 控制)
│
├─► search_mental_models_fn() → 检索心智模型
├─► search_observations_fn() → 检索实体观察
├─► recall_fn() → 检索世界/经验事实
├─► expand_fn() → 追加检索细化查询
└─► "done" → 退出循环
│
▼ 累积所有召回事实 → 构建上下文
▼ 注入 disposition profile + directives
▼ LLM 生成最终答案
能力 3:观点形成与强化
当 Reflect 生成回答时,CARA 同时:
- 提取回答中的新观点 o = (t, c, τ, b, E)
- 为每个观点分配置信度 c ∈ [0, 1]
- 存入 Opinion 网络 O
- 后续新证据到达时自动强化/削弱/矛盾更新
能力 4:背景合并
h' = Merge_LLM(h, h_new) — 冲突解决(新信息优先)、补充追加、第一人称统一、保持简洁。
Reflect 的关键工程参数:
| Budget 级别 | 迭代次数 | 适用场景 |
|---|---|---|
| LOW | ~2-3 次 | 简单事实查询 |
| MID | ~5 次 | 标准推理 |
| HIGH | ~10 次 | 复杂多跳推理 |
3. 接口体系
3.1 统一架构(论文 §6)
论文 §6 描述了 TEMPR 和 CARA 如何组成统一的端到端系统:
┌─────────────────────────┐
│ 客户端/集成 │
│ (18 框架 / CLI / UI) │
└────────┬────────────────┘
│
┌────────▼────────────────┐
│ API 网关层 │
│ HTTP REST / MCP 协议 │
│ (认证 → 租户 → Bank) │
└────────┬────────────────┘
│
┌──────────────┼──────────────┐
│ │ │
┌────────▼──────┐ ┌────▼─────┐ ┌──────▼──────┐
│ Retain │ │ Recall │ │ Reflect │
│ (TEMPR) │ │ (TEMPR) │ │ (CARA) │
│ │ │ │ │ │
│ LLM 事实抽取 │ │ 4路并行 │ │ 智能体循环 │
│ 嵌入生成 │ │ 检索 │ │ 偏好条件化 │
│ 实体解析 │ │ RRF 融合 │ │ 观点演化 │
│ 链接创建 │ │ 交叉编码 │ │ 背景合并 │
└───────┬───────┘ └────┬─────┘ └──────┬──────┘
│ │ │
┌───────▼──────────────▼──────────────▼──────┐
│ PostgreSQL + pgvector │
│ memory_units | entities | memory_links │
│ documents | chunks | banks │
│ HNSW(向量) | GIN(全文/三元组) | B-tree(时序) │
└─────────────────────────────────────────────┘
3.2 接入方式
Hindsight 提供两种接入协议:
| 协议 | 入口 | 适用场景 |
|---|---|---|
| HTTP REST | api/http.py — 61 个 REST 端点 |
传统应用集成、控制面板 |
| MCP | api/mcp.py — 31 个 Tool |
AI 智能体直接工具调用 |
3.3 核心操作接口
Retain — 记忆写入
POST /v1/{tenant_id}/banks/{bank_id}/memories/retain
| 参数 | 类型 | 必填 | 说明 |
|---|---|---|---|
documents |
list[MemoryItem] | ❌ | 待写入的文档列表 |
items |
list[dict] | ❌ | 待写入项(简化格式) |
context |
string | ❌ | 全局上下文 |
event_date |
string (ISO) | ❌ | 事件日期 |
strategy |
string | ❌ | 写入策略 |
parser |
string | ❌ | 文档解析器链 |
还支持文件直传:POST /v1/.../memories/file-retain(multipart/form-data)
Recall — 记忆检索
POST /v1/{tenant_id}/banks/{bank_id}/memories/recall
| 参数 | 类型 | 必填 | 默认值 | 说明 |
|---|---|---|---|---|
query |
string | ✅ | - | 搜索查询 |
budget |
Budget | ❌ | MID | 检索预算 (LOW/MID/HIGH) |
max_tokens |
int | ❌ | - | 响应最大 token 数 |
tags |
list[str] | ❌ | - | 标签过滤 |
fact_types |
list[str] | ❌ | - | 事实类型过滤 |
include |
IncludeOptions | ❌ | - | 附加数据(entities/chunks/source_facts) |
Reflect — 推理反思
POST /v1/{tenant_id}/banks/{bank_id}/reflect
| 参数 | 类型 | 必填 | 默认值 | 说明 |
|---|---|---|---|---|
query |
string | ✅ | - | 问题/主题 |
budget |
Budget | ❌ | LOW | 推理预算 |
max_tokens |
int | ❌ | - | 最大响应 token |
response_schema |
dict | ❌ | - | 结构化输出 JSON Schema |
tags / tag_groups |
- | ❌ | - | 标签过滤 |
exclude_mental_models |
bool | ❌ | false | 排除心智模型 |
4. 基准测试与竞品对比
4.1 评测基准
| 基准 | 规模 | 测试能力 |
|---|---|---|
| LongMemEval (S) | 500 问,115K tokens,50 sessions | 信息抽取(IE)、多会话推理(MR)、时序推理(TR)、知识更新(KU)、弃权(ABS) |
| LoCoMo | 50 对话,平均 9K tokens,35 sessions | 单跳、多跳、开放域、时序推理 |
评测方法:LLM-as-a-judge(GPT-OSS-120B,temperature=0),二元正确性评分。
4.2 LongMemEval 结果
| 方法 | 单会话用户 | 单会话助手 | 偏好 | 知识更新 | 时序推理 | 多会话 | 总体 |
|---|---|---|---|---|---|---|---|
| Full-context (GPT-4o) | 81.4 | 94.6 | 20.0 | 78.2 | 45.1 | 44.3 | 60.2 |
| Full-context (OSS-20B) | 38.6 | 80.4 | 20.0 | 60.3 | 31.6 | 21.1 | 39.0 |
| Zep (GPT-4o) | 92.9 | 80.4 | 56.7 | 83.3 | 62.4 | 57.9 | 71.2 |
| Supermemory (GPT-4o) | 97.1 | 96.4 | 70.0 | 88.5 | 76.7 | 71.4 | 81.6 |
| Supermemory (GPT-5) | 97.1 | 100.0 | 76.7 | 87.2 | 81.2 | 75.2 | 84.6 |
| Supermemory (Gemini-3) | 98.6 | 98.2 | 70.0 | 89.7 | 82.0 | 76.7 | 85.2 |
| Hindsight (OSS-20B) | 95.7 | 94.6 | 66.7 | 84.6 | 79.7 | 79.7 | 83.6 |
| Hindsight (OSS-120B) | 100.0 | 98.2 | 86.7 | 92.3 | 85.7 | 81.2 | 89.0 |
| Hindsight (Gemini-3) | 97.1 | 96.4 | 80.0 | 94.9 | 91.0 | 87.2 | 91.4 |
关键发现:
- Hindsight + OSS-20B (83.6%) > Full-context GPT-4o (60.2%),提升 +44.6 百分点
- Hindsight + OSS-20B 即超越 Zep+GPT-4o (71.2%) 和 Supermemory+GPT-4o (81.6%)
- Hindsight + Gemini-3 (91.4%) 是所有系统+所有骨干模型中的最高分
- 最大增益出现在 LongMemEval 设计强调的长期类别:多会话 21.1→79.7%,时序 31.6→79.7%,偏好 20.0→66.7%
4.3 LoCoMo 结果
| 方法 | 单跳 | 多跳 | 开放域 | 时序 | 总体 |
|---|---|---|---|---|---|
| Backboard | 89.36 | 75.00 | 91.20 | 91.90 | 90.00 |
| Hindsight (Gemini-3) | 86.17 | 70.83 | 95.12 | 83.80 | 89.61 |
| Hindsight (OSS-120B) | 76.79 | 62.50 | 93.68 | 79.44 | 85.67 |
| Hindsight (OSS-20B) | 74.11 | 64.58 | 90.96 | 76.32 | 83.18 |
| Memobase (v0.0.37) | 70.92 | 46.88 | 77.17 | 85.05 | 75.78 |
| Zep | 74.11 | 66.04 | 67.71 | 79.79 | 75.14 |
| Mem0-Graph | 65.71 | 47.19 | 75.71 | 58.13 | 68.44 |
| Mem0 | 67.13 | 51.15 | 72.93 | 55.51 | 66.88 |
| LangMem | 62.23 | 47.92 | 71.12 | 23.43 | 58.10 |
| OpenAI (native) | 63.79 | 42.92 | 62.29 | 21.71 | 52.90 |
关键发现:
- Hindsight + Gemini-3 (89.61%) 与 Backboard (90.00%) 几乎持平,但 Hindsight 是完全开源的
- 开放域查询 Hindsight 取得最高分 (95.12%)
- 相比 Mem0 (66.88%)、Zep (75.14%)、Memobase (75.78%),Hindsight 提升显著
- OpenAI 原生记忆 (52.90%) 在所有系统中垫底
4.4 扩展基准(Benchmarks 站点数据)
| 基准 | Hindsight 得分 |
|---|---|
| LongMemEvalS | 94.6% |
| LoComo10 | 92% |
| PersonaMem32K | 86.6% |
| BEAM100K | 75% |
| BEAM1M | 73.9% |
| LifeBenchEN | 71.5% |
| BEAM500K | 71.1% |
| BEAM10M | 64.1% |
4.5 基准测试的局限性
论文作者自身指出 LoCoMo 存在可靠性问题:
- 部分 ground truth 存在错误和说话者归属问题
- 部分问题模糊,无唯一正确答案
- 对话过短(16k-26k tokens),不足以真正压测记忆检索
- 对知识更新评估有限
- 数据质量问题(多模态引用缺失等)
竞品基准分数来自各自官方公布的数字,非独立复现。
5. 生产风险评估
5.1 🔴 关键风险(阻碍生产部署)
风险 1:内存泄漏 — 进程不到 1 小时 OOM
- Issue: #996
- 状态: OPEN
- 影响: 轻量使用(~10 个 bank,数十次操作)下,
hindsight-apiPython 进程 RSS 在 1 小时内增长至 ~1GB,最终触发 Docker 容器 OOM Kill - 当前规避: 手动设置 Docker 内存上限 2GB + 自动重启策略(牺牲进行中的操作)
- 评估: 任何长时间运行的部署都会退化。这是生产阻塞项。
风险 2:Worker 崩溃导致 Bank 永久卡死
- Issue: #991
- 状态: OPEN(修复 PR #1097 进行中)
- 影响: Worker 异常退出时,其认领的任务永久停留在
processing状态。Per-bank 并发限制随后阻塞该 bank 的所有新工作。有文档记录的案例:14+ 小时卡死,91 条待处理记忆堆积 - 根因: 无过期任务回收机制、无心跳、
claimed_at无 TTL - 评估: 单次进程重启就能永久卡死客户的 bank,需要手动 SQL 修复。
风险 3:异步操作队列无限期停滞
- Issue: #1001
- 状态: OPEN
- 影响: 异步操作(retain、create/refresh mental model)冻结在 “pending” 状态 — 50+ 操作卡了 3+ 小时。有用户报告僵尸 Worker 重试过期任务导致 ~$292 的意外 LLM 费用
- 评估: 同步路径正常,但
create_mental_model、refresh_mental_model是仅异步端点,无法绕过。
5.2 🟠 高风险(数据完整性)
风险 4:合并(Consolidation)失败永久搁浅记忆
- Issue: #1081
- 三重问题叠加:
- Reranker 超时错误产生空错误消息(不透明的
httpcore.ReadTimeout) - Reranker HTTP 超时硬编码 60s,无配置项
- 合并失败的记忆被标记
consolidation_failed_at永久生效 — 无 TTL,无自动恢复
- Reranker 超时错误产生空错误消息(不透明的
- 评估: 短暂的基础设施抖动会静默、永久地降低数据质量。需要手动 SQL 恢复。
风险 5:心智模型刷新返回空
- Issue: #1004
create_mental_model/refresh_mental_model返回 “no information found”,但相同参数直接调用reflect()却成功- 评估: 心智模型是核心差异化功能之一,部分 bank 上不可靠。
风险 6:事实类型误标
- Issue: #1095
- 事实抽取偏向 agent-as-narrator 场景,多方聊天记录中说话者归属容易错误
风险 7:并发操作下的孤儿数据
5.3 🟡 中风险
| 问题 | Issue | 影响 |
|---|---|---|
| CJK 文本搜索完全不可用 | #1077 | BM25 分词器无法处理中文/日文/韩文,阻碍国际化 |
| Gemini 重复发送 Schema | #1070 | 结构化输出 schema 在 prompt 和 response_schema 中重复,浪费 token |
| Bank ID 分隔符不 URL 安全 | #1069 | :: 在 URL 中需转义 |
| Ctrl+C 关闭死锁 | #952 | SIGINT 期间锁竞争导致进程挂起 |
5.4 论文与代码层面的分析风险
LLM 重度依赖
- Retain 的事实抽取、Reflect 的推理循环、观点形成、背景合并全部依赖 LLM 调用
- 每次 Retain 操作 = N 个 chunk × 1 次 LLM 调用(抽取)+ 嵌入 + 可能的因果关系
- 每次 Reflect 操作 = 多轮 agentic loop × recall + 最终生成
- 成本风险:高吞吐场景下 LLM 成本可能快速失控,尤其是 HIGH budget reflect
- 延迟风险:Retain 是 IO 密集型(LLM API 调用),大文档写入延迟可达数十秒
抽取质量强依赖 LLM 能力
- 事实分类(world/experience/opinion)、时间归一化、实体抽取的准确性完全取决于底层 LLM
- 论文用 OSS-20B 做抽取,切换到更小/更弱的模型可能显著降级
- 抽取错误会级联:错误实体 → 错误图链接 → 错误 recall → 错误 reflect
单点 PostgreSQL
- 整个系统依赖单一 PostgreSQL + pgvector 实例
- 无内置分片、读写分离或多区域复制方案
- 对于需要高可用的生产部署,需要自行搭建 PG HA 架构
嵌入模型锁定
- 默认使用
BAAI/bge-small-en-v1.5(384 维),切换嵌入模型需要重新嵌入全部数据 - 论文未讨论嵌入模型迁移策略
版本成熟度
- 仓库活跃(836 merged PRs),但核心稳定性 issue 仍 open
- 没有发现独立的安全审计报告
- API 版本为 v1,但仍在频繁变更
5.5 风险评估总结
| 维度 | 评级 | 说明 |
|---|---|---|
| 核心 API 稳定性 | ⚠️ 中 | 内存泄漏 + Worker 死锁表明生产就绪度不足 |
| 数据完整性 | ⚠️ 中 | 孤儿数据、永久合并失败、心智模型不可靠 |
| Worker 可靠性 | 🔴 低 | 无崩溃恢复;过期任务卡死 bank;异步队列停滞 |
| 可观测性 | 🔴 低 | Reranker 空错误消息;异步失败不透明 |
| 国际化 | 🔴 低 | CJK 搜索完全不可用 |
| 成本可控性 | ⚠️ 中 | 全链路 LLM 依赖,高吞吐场景成本不可预测 |
| 发布节奏 | ✅ 高 | 836 PRs,日常活跃提交,维护者响应及时 |
| Bug 解决率 | ✅ 好 | 45/48 bug 标签 issue 已关闭,多数在数天内解决 |

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)