机器学习模型部分
解释一些上一个遗留的问题
补充1:为什么下载的数据集后缀有.pkz,有的没有?
由 scikit-learn 不同版本的处理方式不同造成的。.pkz 是旧版本的产物,新版本为了更高的效率,已经不再使用这种中间格式了。
| 步骤 | 🔮 旧版本 (scikit-learn ≤ 0.23) | ✨ 新版本 (scikit-learn ≥ 0.24) |
|---|---|---|
| 1. 下载 | 下载压缩包 20news-bydate.tar.gz |
直接下载原始文件到 data/20news_home 文件夹 |
| 2. 解压 | 将压缩包解压为 train 和 test 两个文件夹 |
无需解压,直接使用原始文件结构 |
| 3. 打包 | 将解压后的内容重新打包成一个 .pkz 文件 |
跳过此步骤 |
| 4. 清理 | 删除 train、test 文件夹和原始压缩包 |
无清理动作,保留原始文件 |
补充2:sklearn 和 pytorch区别
sklearn 封装的很严重
pytorch 封装是有层级性的
补充3:numpy和pandas的属性和方法
numpy属性和方法
np.ndim:获取数组的维度
np.shape:形状(行,列)
np.size:有多少个元素
np.dtype:数据类型
np.itemsize:元素字节数
pandas的属性和方法:
• df.shape: 返回行数和列数
• df.columns: 返回列索引
• df.index: 返回行索引
• df.values: 返回数据部分(二维NumPy数组)<class 'numpy.ndarray'>
• df.dtypes: 返回每列的数据类型
• df.head(n): 返回前n行
• df.tail(n): 返回后n行
• df.describe(): 快速生成数值型数据的描述性统计摘要。
• df.info(): 返回DataFrame的信息
- 快速概览数据分布:发现异常值、了解数据范围。
- 检查数据质量:比如 min 或 max 是否合理。
- 辅助后续处理:比如决定是否需要标准化(对于 KNN 很重要)
• df.query(
"x > 1.0"):返回所有列索引x大于1的数据 (numpy没有这种格式)
假如我们的data数据是用pandas数据类型存储的,我们可以通过以下方式进行筛选
- data = data.query("x > 1.0 & x < 1.25 & y > 2.5 & y < 2.75")
- data = data[(data['x'] > 1.0) & (data['x'] < 1.25) & (data['y'] > 2.5) & (data['y'] < 2.75)] 也可以
但是如果我们用的是numpy存储的就只能用下面这种方式
- data = data[(data['x'] > 1.0) & (data['x'] < 1.25) & (data['y'] > 2.5) & (data['y'] < 2.75)]
K 近邻(K‑Nearest Neighbors, KNN)
核心思想:判断一个新样本属于哪一类,就看训练集里和它最相似的 K 个样本,少数服从多数。
举个例子:你想知道一部新电影是“科幻片”还是“爱情片”。
KNN 的做法是:在已知类型的老电影里,找出和它最像的 5 部(K=5)。如果这 5 部里有 4 部是科幻片,1 部是爱情片,那就判定它是科幻片。
算法原理:用距离度量,通常采用欧氏距离(Euclidean distance),也可用曼哈顿距离、闵可夫斯基距离等。![]()
K 值选择:
K 过小:容易受异常点的影响,模型复杂,容易过拟合,对噪声敏感。
K 过大:容易最近点的影响,模型简单,容易欠拟合,决策边界平滑。
常用交叉验证来选择最优 K。
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
# K近邻
"""
K-近邻预测用户签到位置
:return:None
"""
# 读取数据
data = pd.read_csv("./data/FBlocation/train.csv")
# 处理数据
# 1、缩小数据,查询数据,为了减少计算时间
data = data.query("x > 1.0 & x < 1.25 & y > 2.5 & y < 2.75")
# 2、处理时间的数据
time_value = pd.to_datetime(data['time'], unit='s')
time_value = pd.DatetimeIndex(time_value)
# data['day'] = time_value.day
# data['hour'] = time_value.hour
# data['weekday'] = time_value.weekday
#日期,是否是周末,小时对于个人行为的影响是较大的(例如吃饭时间去饭店,看电影时间去电影院等),所以才做下面的处理
data.insert(data.shape[1], 'day', time_value.day) #data.shape[1]是代表插入到最后的意思,一个月的哪一天
data.insert(data.shape[1], 'hour', time_value.hour) #是否去一个地方打卡,早上,中午,晚上是有影响的
data.insert(data.shape[1], 'weekday', time_value.weekday) #0代表周一,6代表周日,星期几
# 把时间戳特征删除
data = data.drop(['time'], axis=1)
# 3、把签到数量少于3个目标位置删除
place_count = data.groupby('place_id').count()
# groupby('place_id'):按地点 ID 分组,每个 place_id 对应一组该地点的所有签到记录。
# .count():对每组内的每一列计算非空值的个数(因为通常数据无缺失,所以就是统计该地点的签到次数)。
tf = place_count[place_count.row_id > 3].reset_index()
# place_count[...]:布尔索引,保留签到次数 > 3 的地点。
# .reset_index():因为 place_count 的行索引是 place_id,这步将索引重置为默认的 0,1,2,… 整数序号,同时把原来的 place_id 还原为普通列。
data = data[data['place_id'].isin(tf.place_id)]
# 对原始数据 data 的每一行,判断其 place_id 是否在 tf.place_id(高频地点列表)中,返回布尔 Series。
# 4、取出数据当中的特征值和目标值
y = data['place_id']
x = data.drop(['place_id'], axis=1)
# 删除无用的特征值,row_id是索引,这就是噪音
x = x.drop(['row_id'], axis=1)
# 进行数据的分割训练集合测试集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.25, random_state=1)
# 特征工程(标准化)
std = StandardScaler()
x_train = std.fit_transform(x_train)
x_test = std.transform(x_test) #transfrom不再进行均值和方差的计算,是在原有的基础上去标准化
knn = KNeighborsClassifier(n_neighbors=6)
knn.fit(x_train, y_train)#训练,但knn的fit是不训练的,只是把训练集的特征值和目标值放入到内存中
# 得出预测结果
y_predict = knn.predict(x_test)
print("预测的目标签到位置为:", y_predict[0:10])
print("预测的准确率:", knn.score(x_test, y_test))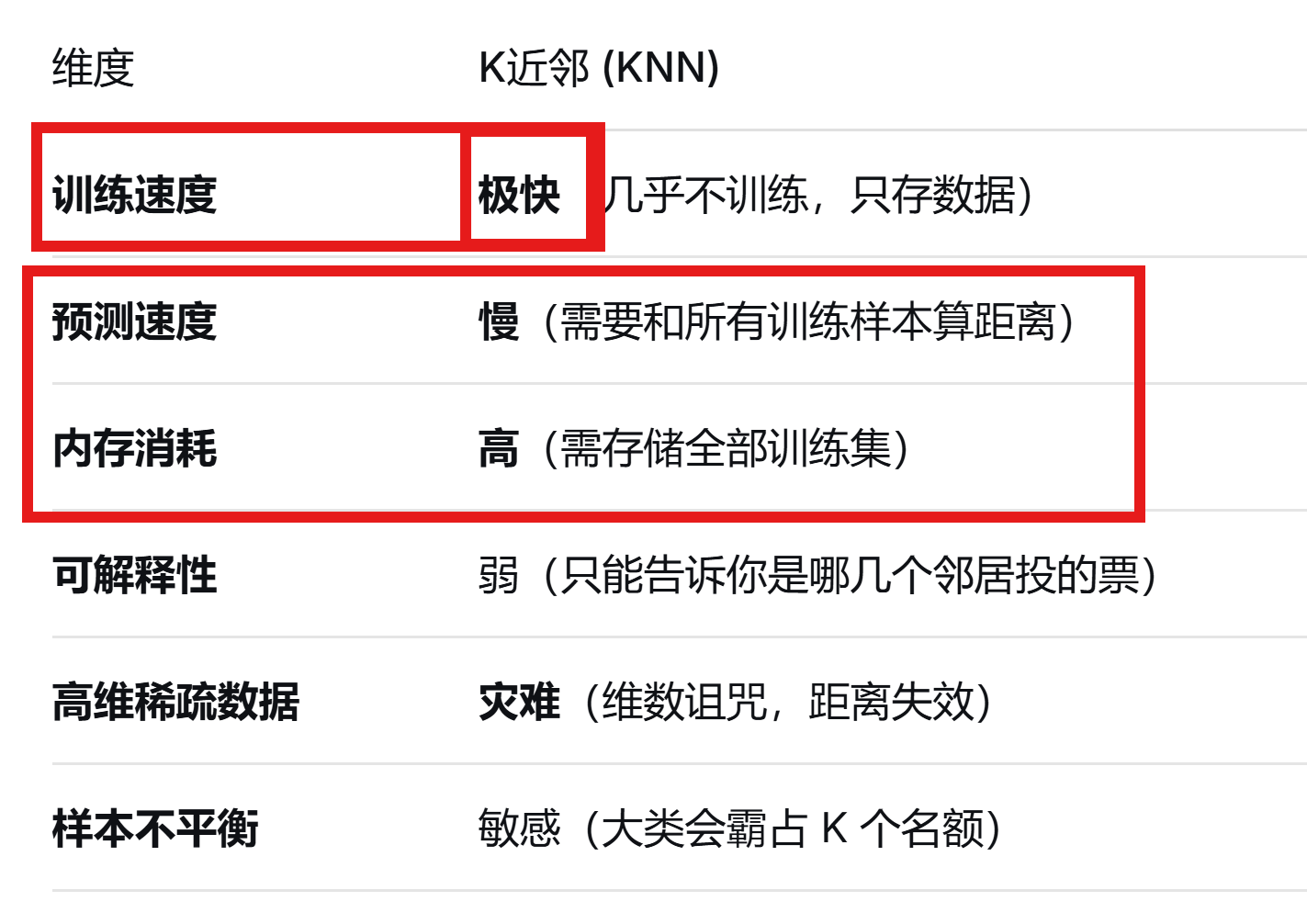
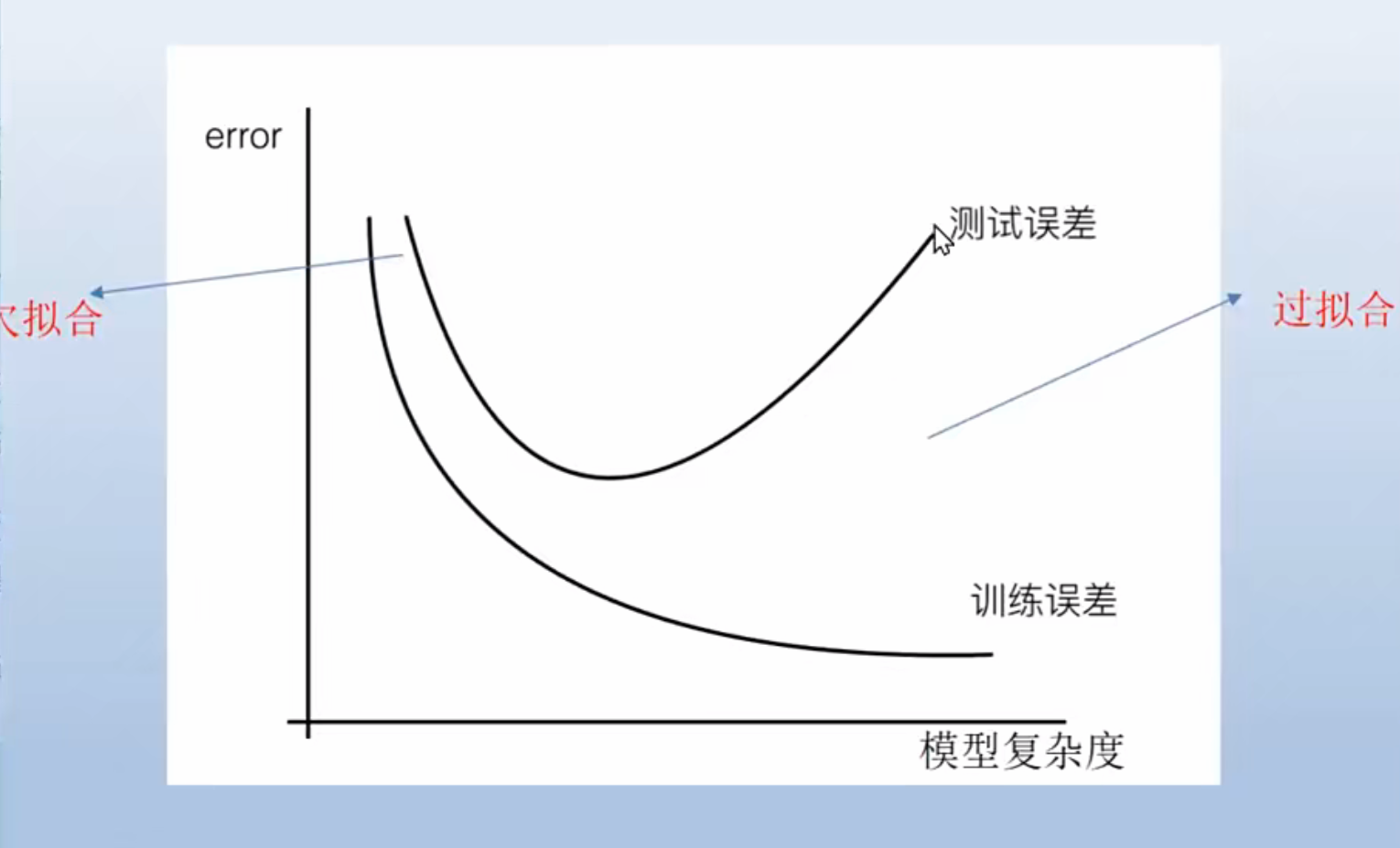
近似误差和训练误差
近似误差:可以理解为对现有训练集的训练误差。
- 近似误差关注训练集,如果近似,差小了会出现过拟合的现象,对现有的训练集能有很好的预测,但是对未知的测试样本将会出现较大偏差的预测。模型本身不是最接近最佳模型。
估计误差:可以理解为对测试集的测试误差。
- 估计误差关注测试集,估计误差小了说明对未知数据的预测能力好。模型本身最接近最佳模型。
网格搜索和交叉验证
网格搜索:
- 自动化调参:避免手动反复尝试,提高效率。
- 科学比较:基于交叉验证结果,比单次划分训练/测试集更稳定可靠。
- 防止过拟合:通过交叉验证评估泛化能力,选择在验证集上表现最好的参数,而非仅在训练集上过拟合的配置。
网格搜索的思路:
- 为每个超参数指定一组候选值(例如 KNN 的 n_neighbors = [3, 5, 7],weights = ['uniform', 'distance'])。
- 将所有候选值组合成一个“参数网格”(笛卡尔积)。
- 对网格中的每一组超参数组合,用交叉验证评估模型性能(如准确率、F1 值)。
- 最后选择平均性能最高的那组超参数作为最优配置。
交叉验证:
- 为了让被评估的模型更加准确可信
- 对应的是参数 cv,cv=5时,将测试集分成 5 份,其中一份作为验证集。然后经过 5 次(组)的测试,每次都更换不同的验证集。即得到 5 组模型的结果,取平均值作为最终结果。又称 5 折交叉 验证。
#网格搜索时讲解
from sklearn.model_selection import GridSearchCV
# 构造一些参数(超参)的值进行搜索
param = {"n_neighbors": [3, 5, 10, 12, 15],'weights':['uniform', 'distance']}
# 进行网格搜索,cv=3是3折交叉验证,用其中2折训练,1折验证
gc = GridSearchCV(knn, param_grid=param, cv=4)
gc.fit(x_train, y_train) #你给它的x_train,它又分为训练集,验证集
# 预测准确率,为了给大家看看
print("在测试集上准确率:", gc.score(x_test, y_test))
print("在交叉验证当中最好的结果:", gc.best_score_) #最好的结果
print("选择最好的模型是:", gc.best_estimator_) #最好的模型,告诉你用了哪些参数
print("每个超参数每次交叉验证的结果:",gc.cv_results_)网格搜索+流水线
- 先构建流水线的对象
- 定义网格参数(流水线中的参数需用 `步骤名__参数名` 的形式指定)
- 构建网格搜索的对象
from sklearn.pipeline import Pipeline
# 3. 构建流水线(标准化 + KNN)
pipeline = Pipeline([
('scaler', StandardScaler()),
('knn', KNeighborsClassifier())
])
# 4. 定义参数网格!!!注意:流水线中的参数需用 `步骤名__参数名` 的形式指定
param_grid = {
'knn__n_neighbors': [1, 3, 5, 7, 9], # K值候选
'knn__weights': ['uniform', 'distance'] # 是否按距离加权
}
# 5. 创建网格搜索对象
grid_search = GridSearchCV(
estimator=pipeline,
param_grid=param_grid,
cv=5, # 5折交叉验证
scoring='accuracy', # 用准确率作为评估指标
verbose=1, # 打印进度信息
n_jobs=-1 # 使用全部CPU核心并行计算
)
# 6. 执行网格搜索(训练)
grid_search.fit(x_train, y_train)
# 7. 查看结果
print("最佳参数组合:", grid_search.best_params_)
print("交叉验证最佳准确率: {:.4f}".format(grid_search.best_score_))
print("测试集准确率:",grid_search.score(x_test, y_test))
# best_model = grid_search.best_estimator_
# test_accuracy = best_model.score(x_test, y_test)
# print("测试集准确率: ",test_accuracy)分类模型评估
一、混淆矩阵 —— 评估的基石
混淆矩阵是所有指标的基础,它直观展示了模型预测值与真实值的对比情况。
| 真实 \ 预测 | 预测为正类 (Positive) | 预测为负类 (Negative) |
|---|---|---|
| 实际为正类 | TP (True Positive,预测正确) | FN (False Negative,漏报) |
| 实际为负类 | FP (False Positive,误报) | TN (True Negative,预测正确) |
记忆技巧:第二个字母 P/N 代表模型的预测结果;第一个字母 T/F 代表预测是否正确。
二、核心评估指标详解
1. 准确率
-
公式:Accuracy=(TP+TN)/(TP+TN+FP+FN)
-
含义:预测正确的样本数占总样本数的比例。
-
适用场景:类别分布相对均衡时。
-
局限:假如 100 个样本里 95 个是好人,5 个是坏人。模型只要把所有人都预测为好人,准确率就能达到 95%,但这个模型毫无价值。
2. 精确率
-
公式:Precision=TP/(TP+FP)
-
含义:模型预测为“正类”的样本中,实际真的是“正类”的比例(预测准不准)。
-
适用场景:宁可漏掉,不可错杀。例如推荐系统,推荐给用户的 10 个地点,希望用户大概率真的会去(减少 FP 带来的骚扰)。
3. 召回率
-
公式:Recall=(TP)/(TP+FN)
-
含义:所有真实的“正类”样本中,被模型成功找出来的比例(找得全不全)。
-
适用场景:宁可错杀一千,不可放过一个。例如疾病筛查或寻找罪犯,漏掉一个(FN)后果非常严重。
4. F1 分数
-
公式:F1=2×(Precision×Recall)/(Precision+Recal)
-
含义:精确率和召回率的调和平均数。
-
作用:当 Precision 和 Recall 出现矛盾时(一个高一个低),F1 能综合反映模型的稳健性。
三、ROC 曲线与 AUC(二分类专用)
如果你的任务不是预测几百个地点,而是简单的“用户是否会去某个地点”(二分类),还可以使用 ROC 曲线 和 AUC 值。
![]() 为横坐标,
为横坐标,![]() 为纵坐标
为纵坐标
ROC 曲线:
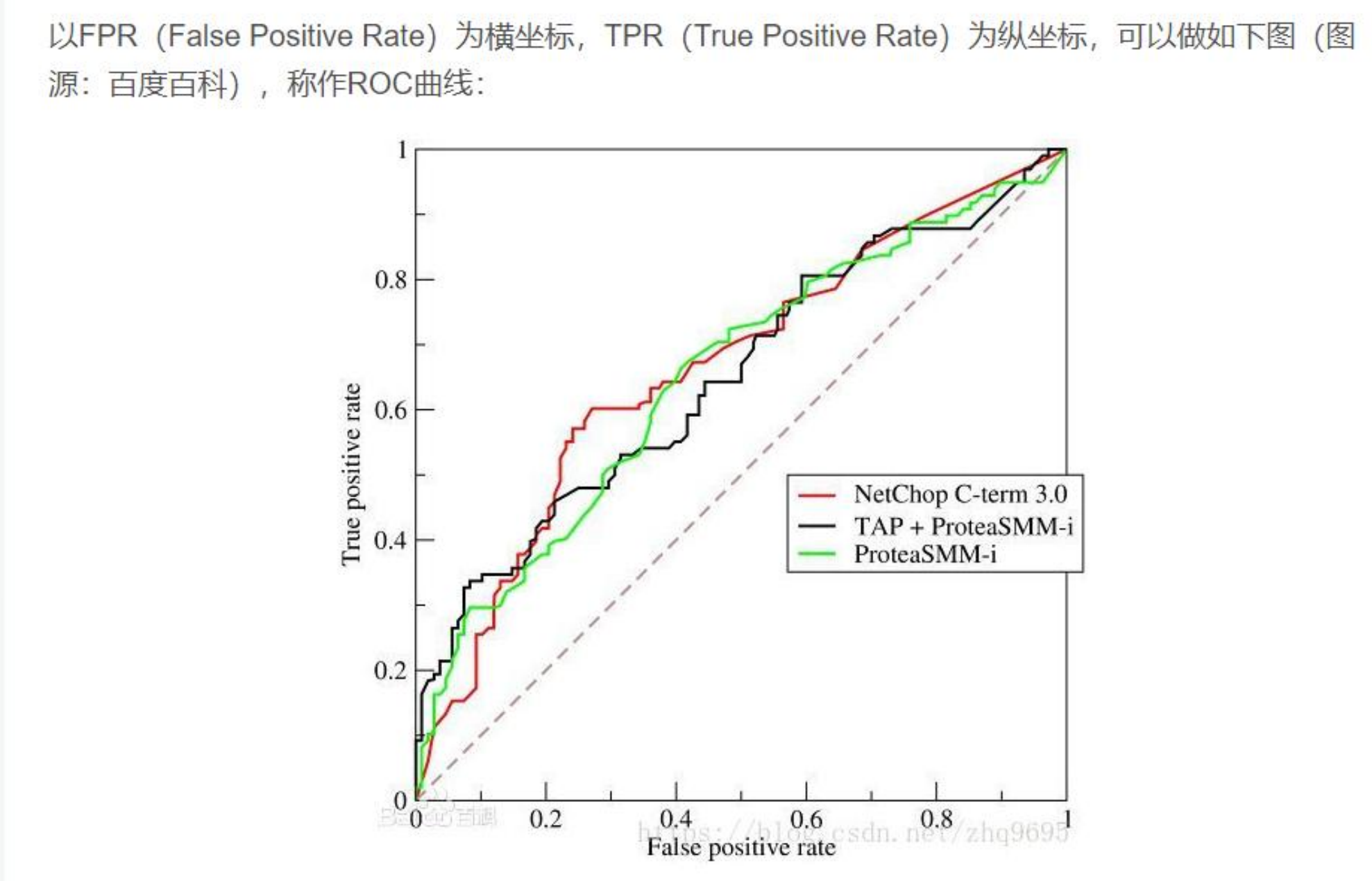
AUC:是 ROC 曲线下的面积。越接近 1 代表模型区分正负样本的能力越强。
曲线是怎么画出来的?—— 遍历阈值
模型输出的不是一个类别,而是一个概率值(或者置信度)。比如判断一封邮件是不是垃圾邮件:
- 邮件 A:模型打分 0.9(很可能是垃圾)
- 邮件 B:模型打分 0.4(不太像垃圾)
- 邮件 C:模型打分 0.7(可能是垃圾)
我们人为设定一个阈值(及格线)。假如阈值设为 0.5:
- 分数 ≥ 0.5 的判为“垃圾”(正类)
- 分数 < 0.5 的判为“正常”(负类)
每改变一次阈值,就会得到一对 (FPR, TPR) 的数值。
从阈值 = 0(全判垃圾)一路调到阈值 = 1(全判正常),把所有 (FPR, TPR) 点连起来,就是 ROC 曲线。AUC 值= 曲线下方的面积:一个数字概括整条曲线
取值范围:0.5 ~ 1.0。
- AUC = 0.5:模型和瞎蒙一样,曲线就是一条从 (0,0) 到 (1,1) 的对角线。
- AUC = 1.0:完美模型,曲线贴着左边和上边走到 (0,1),面积等于 1。
为什么 AUC 比准确率更好用?
- 准确率依赖于阈值的选择,换一个阈值,准确率可能就变了。
- AUC 不依赖阈值,它衡量的是模型对正负样本的整体排序能力。也就是说:随便抽一个正样本和一个负样本,模型给正样本打分更高的概率就是 AUC。
转换器和预估器
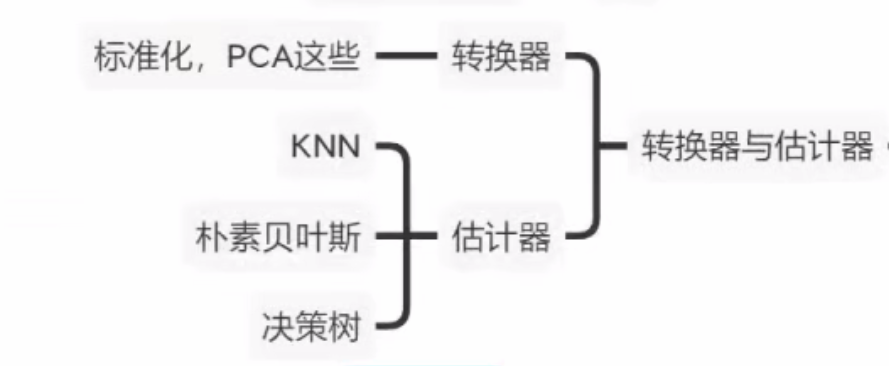
转换器:
主要方法:
- 训练集上用
fit_transform(),测试集上用transform()
预估器:
-
主要方法:
-
fit(X_train, y_train): 核心方法,使用训练数据(特征X_train和标签y_train)来训练模型,学习其中的模式。 -
predict(X_test): 使用训练好的模型,对新的数据X_test进行预测,返回预测结果。 -
score(X_test, y_test): 根据测试集的真实标签y_test,评估模型预测的准确性。
-
朴素贝叶斯
朴素贝叶斯的核心,是一种基于概率的分类算法,它通过计算样本属于每个类别的概率,将样本归为概率最大的那一类。
拉普拉斯平滑 (Laplace Smoothing)
“朴素”假设之后,还会遇到一个工程问题:如果某个特征(比如一个词)在训练集的某个类别中从未出现过,那么它的条件概率就会被估算为0。这会导致整个后验概率的计算结果直接变为0,显然不合理。
拉普拉斯平滑正是为了解决这个问题。它的核心思想是:在计算条件概率时,给所有特征的计数都加上一个很小的正数(通常用α表示,默认为1),从而避免概率为零的情况。
一、场景设定:一种罕见的病
假设有一种罕见病:
- 发病率(先验概率):在人群中,平均 1000 个人里有 1 个人得这个病。
这意味着:P(生病) = 0.001,P(没病) = 0.999。
- 检测准确率(似然概率):有一种检测试纸,准确率挺高,但也不是 100%:
如果你真的有病,试纸有 99% 的概率显示阳性(能查出来)。(命中率/召回率 TPR)
如果你其实没病,试纸有 2% 的概率闹乌龙,显示阳性(假阳性)。(误报率 FPR)
现在,你拿着试纸测了一下,结果显示:阳性(+)。
这时候你最想问的是:我是不是完蛋了?我真正得病的概率是多少?
二、直觉的误区(正向思维)
很多人会直觉认为:“试纸准确率 99%,那我测出阳性,肯定 99% 是得病了。”这是错的。 为什么?因为你忽略了 “这个病本来就很罕见” 这个前提。
三、贝叶斯定理的计算(逆向思维)
我们想求的是:在已知试纸阳性(B)的前提下,真正得病(A)的概率是多少?
用数学符号表示就是求:P(生病 | 阳性)。套用贝叶斯公式:
假设我们找来了 100,000 个人来做检测。
1. P(A) 发病率,划分人群:
真正的病人:100,000 × 0.001 = 100 人。
真正的健康人:100,000 × 0.999 = 99,900 人。
2.根据 P(B|A) 计算阳性人数:已经发病的人监测为阳性的概率
在 100 个病人中:试纸命中率 99% → 会有 100 × 99% = 99 人 显示阳性(正确查出),1 人显示阴性(漏网之鱼)。
在 99,900 个健康人中:试纸误报率 2% → 会有 99,900 × 2% = 1,998 人 显示阳性(冤假错案)。
3.计算总阳性人数 P(B):全部人监测为阳性的概率
所有的阳性结果 = 99(真病人) + 1,998(假病人) = 2,097 人。
4.最后一步:计算后验概率 P(生病 | 阳性)
你现在被测出是阳性,意味着你是这 2,097 人中的一个。
这 2,097 人里面,只有 99 人是真正有病的。
你得病的概率 = 99 / 2097 ≈ 4.7%。
四、结论
看到差距了吗?不思考概率:你以为 99% 得了病。
用贝叶斯定理算一下:其实你只有 4.7% 的概率得病。
这就是贝叶斯定理的核心作用:用新证据(试纸阳性)去修正原来的看法(发病率很低),得出一个更理性的判断(虽然阳性,但大概率是假阳性)。
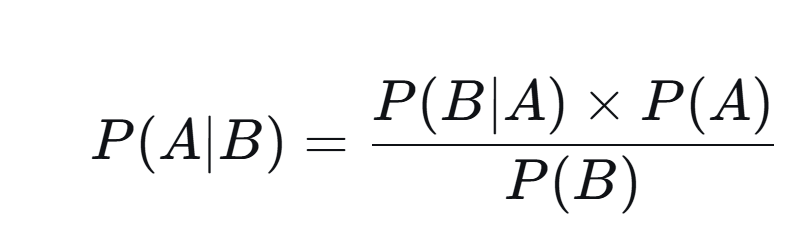

"""
朴素贝叶斯进行文本分类
:return: None
"""
import numpy as np
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
news = fetch_20newsgroups(subset='all', data_home='data')
# 进行数据分割
x_train, x_test, y_train, y_test = train_test_split(news.data, news.target, test_size=0.25, random_state=1)
# 对数据集进行特征抽取
tf = TfidfVectorizer()
# 以训练集当中的词的列表进行每篇文章重要性统计['a','b','c','d']
x_train = tf.fit_transform(x_train)
print(len(tf.get_feature_names_out()))#查看特征数目
x_transform_test = tf.transform(x_test) #特征数目不发生改变
print(len(tf.get_feature_names_out()))
# 进行朴素贝叶斯算法的预测,
mlt = MultinomialNB(alpha=1.0)#alpha是拉普拉斯平滑系数,分子和分母加上一个系数,分母加alpha*特征词数目
# 训练
mlt.fit(x_train, y_train)
y_predict = mlt.predict(x_transform_test)
print("预测的前面10篇文章类别为:", y_predict[0:10])
print("准确率为:", mlt.score(x_transform_test, y_test))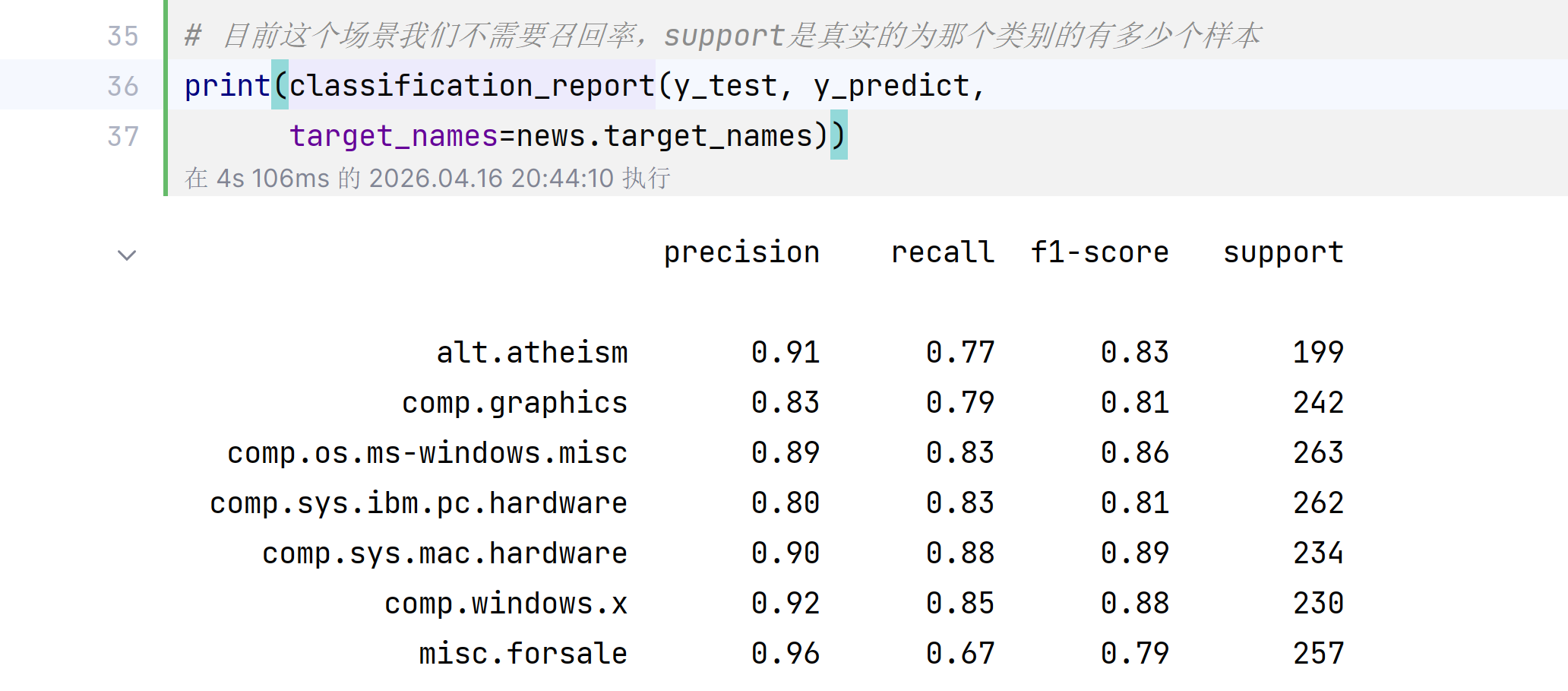
决策树
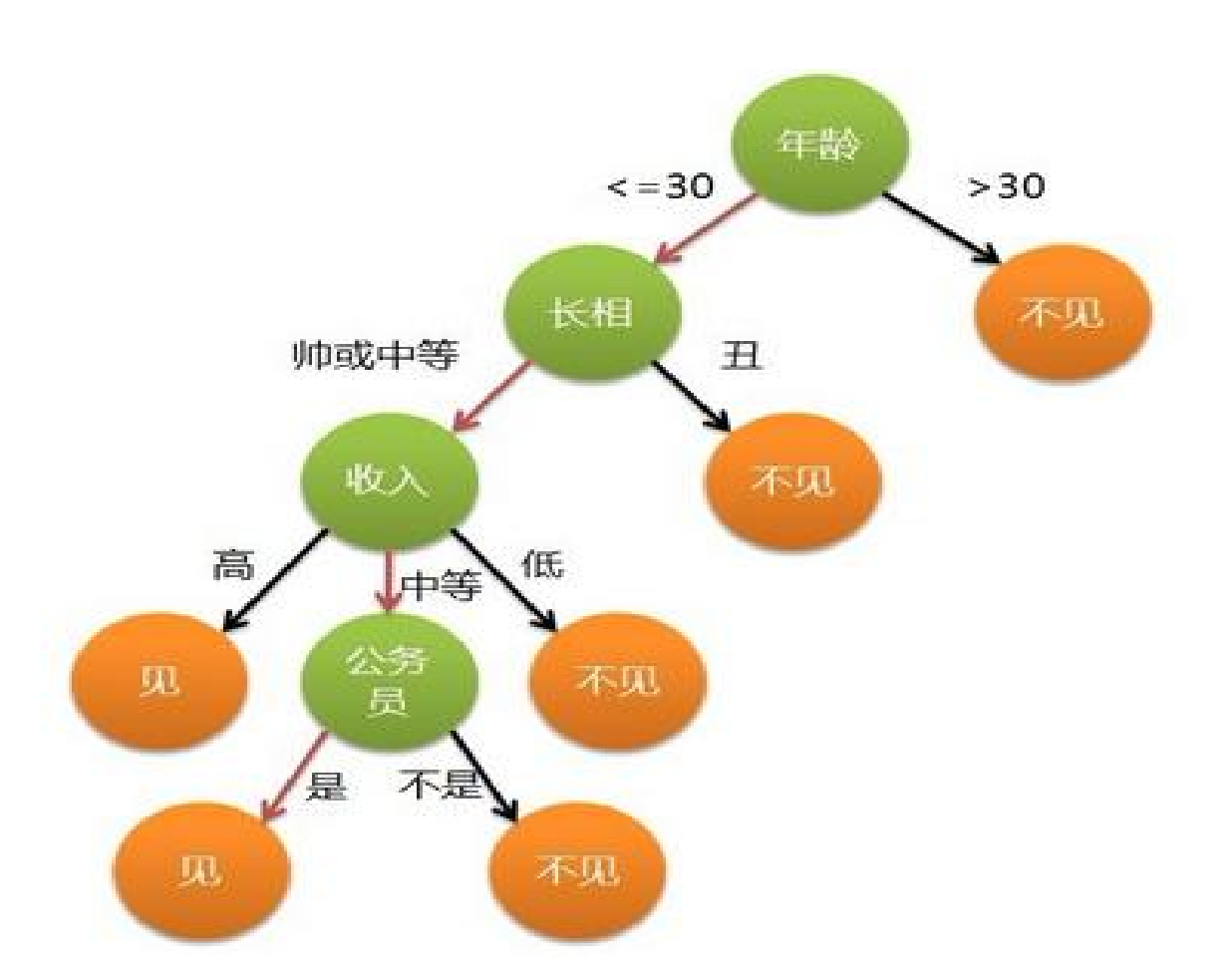
决策树是怎么“长”出来的?
模型一开始面对一堆乱糟糟的数据,它要做的事情是:找到一个最狠的问题,一刀切下去,让两边分得尽可能“纯”。
这里有三个关键概念,用来衡量“纯不纯”:
1. 信息熵与信息增益(ID3 / C4.5 算法)
熵:代表混乱程度。
- 如果一个节点里,A类、B类、C类各占 1/3,熵值最大(最混乱)。
- 如果一个节点里,全是 A 类,熵值为 0(最纯)。
信息增益:原来的混乱程度 —— 切完一刀之后的混乱程度。
做法:模型会遍历所有特征,计算按每个特征切分后的信息增益,选增益最大的那个特征作为当前节点的提问。
2. 基尼系数(CART 算法,最常用)
含义:随机抽两个样本,它们不属于同一个类别的概率。
- 公式理解:Gini = 1 - Σ(P_i²)。如果全是同一类,Gini = 0;类别越杂,Gini 越接近 1。
做法:模型会找那个能使切分后加权基尼系数最小的特征来切分。
总结:不管用哪个公式,目标都是 “切完之后,两边越来越纯”。
from sklearn.feature_extraction import DictVectorizer
from sklearn.tree import DecisionTreeClassifier, export_graphviz
"""
决策树对泰坦尼克号进行预测生死
:return: None
"""
# 获取数据
titan = pd.read_csv("./data/titanic.txt")
titan.info()
# 处理数据,找出特征值和目标值
x = titan[['pclass', 'age', 'sex']]
y = titan['survived']
# 一定要进行缺失值处理,填为均值
mean = x['age'].mean()
x.loc[:, 'age'] = x.loc[:, 'age'].fillna(mean)
# 分割数据集到训练集合测试集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.25, random_state=4)
# 进行处理(特征工程)特征-》类别-》one_hot编码
dict = DictVectorizer(sparse=False)
# 这一步是对字典进行特征抽取,to_dict可以把df变为字典,records代表列名变为键
x_train = dict.fit_transform(x_train.to_dict(orient="records"))
print("输出转换为字典的训练集",type(x_train))
print("转换后的特征名",dict.get_feature_names_out())
x_test = dict.transform(x_test.to_dict(orient="records"))
print("输出转换为字典的测试集",x_train)
#用决策树进行预测,树过于复杂,就会产生过拟合
dec = DecisionTreeClassifier()
#训练
dec.fit(x_train, y_train)
# 预测准确率
print("预测的准确率:", dec.score(x_test, y_test))
# 导出决策树的结构
export_graphviz(dec, out_file="tree.dot",
feature_names=['age', 'pclass=1st', 'pclass=2nd', 'pclass=3rd', 'female', 'male'])
可以导出.dot格式的结构体
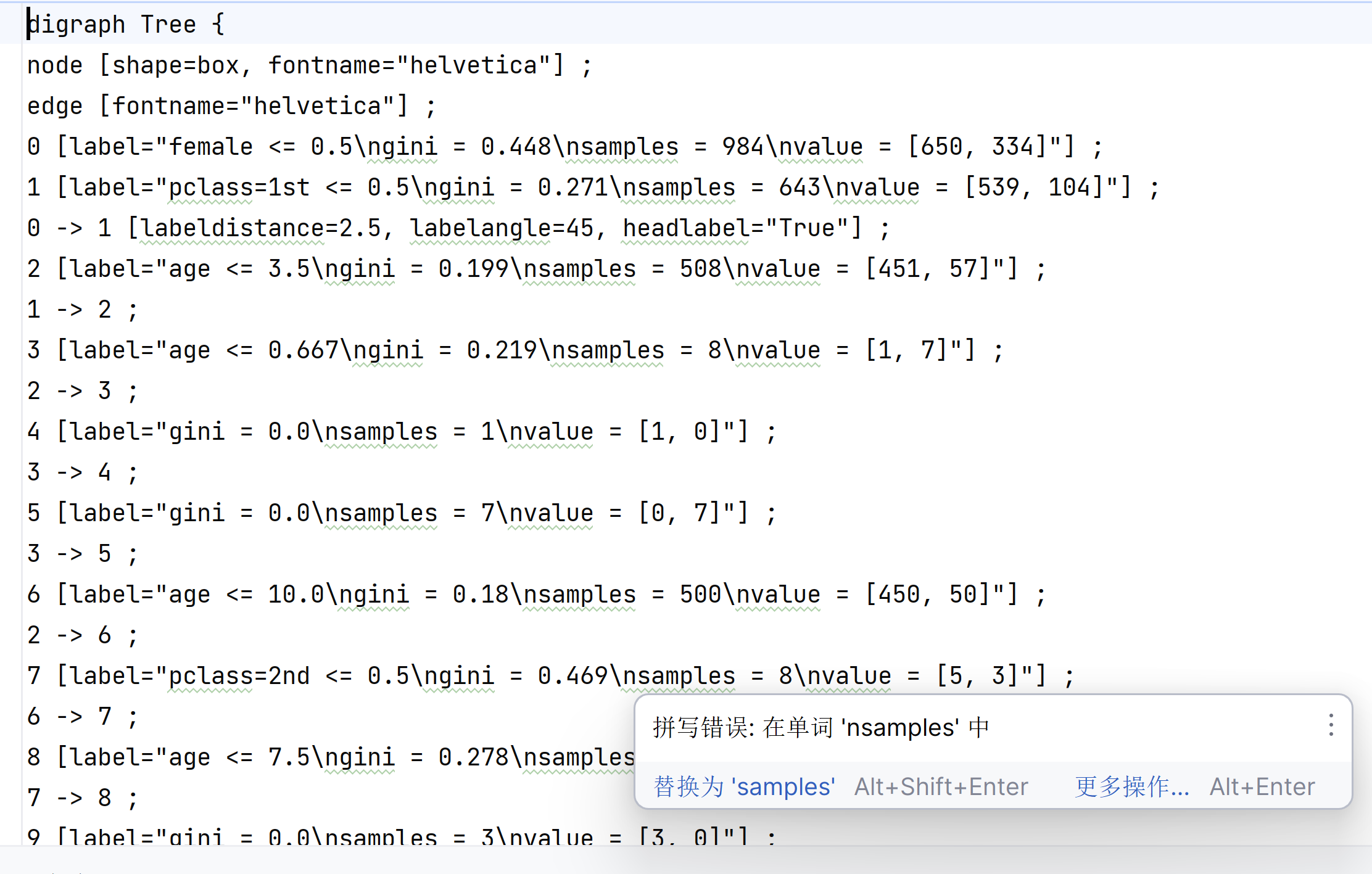
能够将 dot 文件转换为 pdf、png的工具
安装 graphviz
sudo apt install graphvizbrew install graphviz用graphviz-2.38.msi 安装包来安装,傻瓜式安装,依次下一步
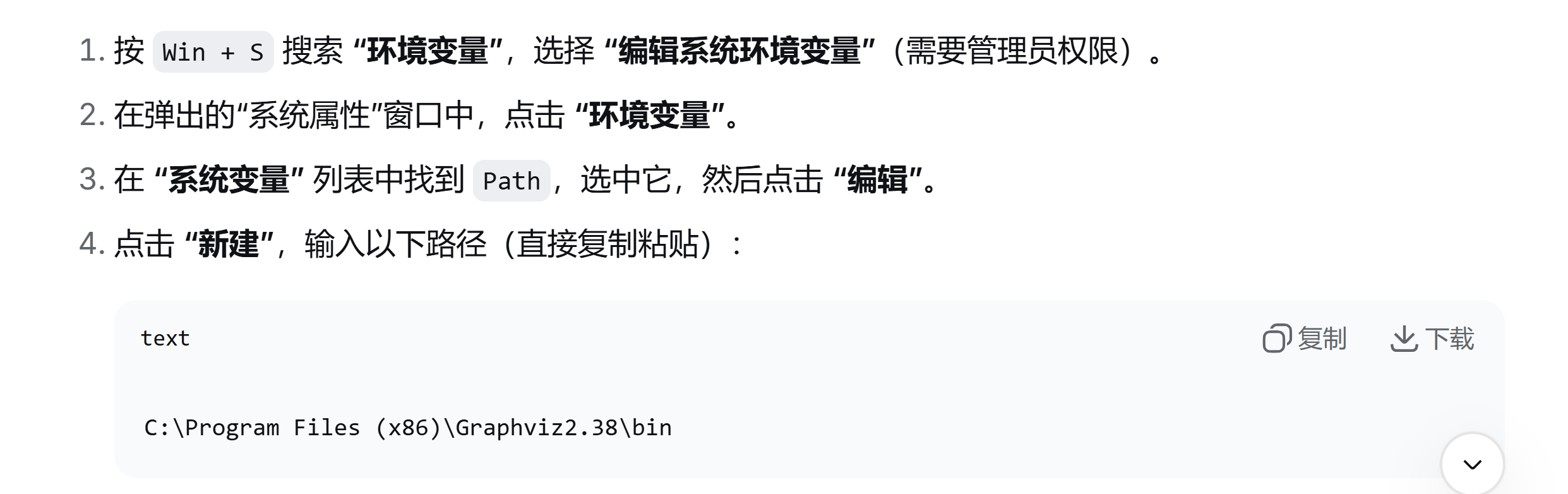
安装完成之后
1.重启pycharm(不重启没有dot这个命令)
dot -Tpng tree.dot -o tree.png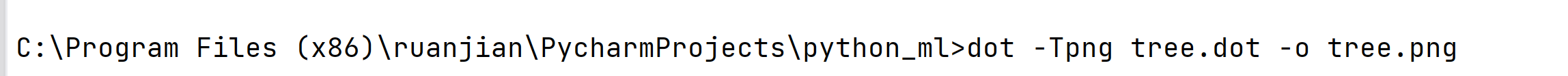
这样就成功的将.dot 文件转换为 png了
决策树的优缺点以及改进
优点:
- 简单的理解和解释,树木可视化。
- 需要很少的数据准备,其他技术通常需要数据归一化,标准化(决策树不需要进行归一化和标准化)
缺点:
-
容易过拟合:如果不剪枝,它就是“死记硬背”的代表。如何防止过拟合?—— 剪枝与限制生长
- 决策树可能不稳定,因为数据的小变化可能会导致完全不同的树 被生成(弱分类器)
通过设置树的深度就可以实现剪枝
# 用决策树进行预测,修改max_depth为10,发现提升了,min_impurity_decrease表示只有当分裂后不纯度的减少量 > 0.01 时,才允许分裂
dec = DecisionTreeClassifier(max_depth=7,min_impurity_decrease=0.01,min_samples_split=20)
dec.fit(x_train, y_train)
#
# # 预测准确率
print("预测的准确率:", dec.score(x_test, y_test))
# # 导出决策树的结构
export_graphviz(dec, out_file="tree1.dot",
feature_names=dict.get_feature_names_out())随机森林
三个臭皮匠,顶个诸葛亮
决策树最大的毛病是不稳定和容易过拟合(死记硬背)。随机森林的解法非常直接且粗暴:
- 种很多棵树(通常 100 棵起步)。
- 每棵树看的东西不一样(数据不一样,特征也不一样)。
- 最后大家投票决定(少数服从多数)。
这就是集成学习里的 Bagging(装袋法) 思路。
随机森林的“随机”到底体现在哪?(关键知识点)
这是它和单纯种 100 棵决策树最大的区别。它有两层随机性:
1. 样本随机(Bootstrap 自助采样)
做法:假设你有 1000 个样本,要训练第 1 棵树时,从这 1000 个里有放回地随机抽 1000 次。
结果:有的样本会被抽中很多次(大概 63.2%),有的样本一次也没被抽中(约 36.8%)。
专业名词:没被抽中的那 36.8% 数据叫 袋外数据(OOB,Out-Of-Bag)。
有什么用:OOB 数据可以作为免费的验证集,用来评估模型泛化能力,不需要单独切分测试集。
2. 特征随机(Random Subspace)
做法:
- 决策树在每次分裂选特征时,是从所有特征里挑最好的;
- 而随机森林中的树,每次分裂只能从随机选出的 k个特征里挑(k 通常取总特征数的平方根或 log2)。
为什么这么做:
- 防止某个超级强特征(比如 x 坐标)垄断每一棵树的每一次分裂,迫使每棵树去发掘不同的规律(比如有的树看时间,有的树看星期几)。
它是怎么训练和预测的?(流程拆解)
训练阶段(造森林):
对于 i 从 1 到 100(树的数量):
- 用 Bootstrap 方法从原始数据随机抽出一个样本子集。
- 用这个子集训练一棵决策树,但在每个节点分裂时,只随机考虑部分特征。
- 让这棵树自由生长到底(通常不剪枝),长成一棵又深又容易过拟合的树。
预测阶段(议会投票):
- 对于分类问题:采取100 棵树各自投一票,得票最多的类别作为最终预测结果。
- 对于回归问题:采取100 棵树各自给出一个数值,取平均值作为最终结果。
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV
# 随机森林进行预测 (超参数调优),n_jobs充分利用多核的一个参数
rf = RandomForestClassifier(n_jobs=-1)
# 120, 200, 300, 500, 800, 1200,n_estimators森林中决策树的数目,也就是分类器的数目
# max_samples 是最大样本数
#bagging类型
param = {"n_estimators": [1500,2000, 5000], "max_depth": [2, 3, 5, 8, 15, 25]}
# 网格搜索与交叉验证
gc = GridSearchCV(rf, param_grid=param, cv=3)
gc.fit(x_train, y_train)
print("准确率:", gc.score(x_test, y_test))
print("查看选择的参数模型:", gc.best_params_)
print("选择最好的模型是:", gc.best_estimator_)
# print("每个超参数每次交叉验证的结果:", gc.cv_results_)- 在当前所有算法中,具有极好的准确率
- 能够有效地运行在大数据集上
- 能够处理具有高维特征的输入样本,而且不需要降维
- 能够评估各个特征在分类问题上的重要性
- 对于缺省值问题也能够获得很好得结果
线性回归
找一条直线(或超平面),让它尽可能“穿过”所有数据点,然后用这条线来预测新的数值。
-
一个特征时:二维平面上的直线 y=kx+by=kx+b
-
多个特征时:多维空间中的超平面 y=w1x1+w2x2+⋯+wnxn+by=w1x1+w2x2+⋯+wnxn+b
核心三要素:模型、损失、优化
任何机器学习算法都可以拆成这三块,线性回归也不例外。
1. 模型(假设函数)
y^=w1x1+w2x2+⋯+wnxn+by^=w1x1+w2x2+⋯+wnxn+b
xi:特征(比如房子的面积、卧室数量)
wi:权重(系数),代表对应特征对结果的影响力
b:偏置(截距),代表基础数值
y^:模型预测的值
目标:从数据中学习出最合适的 ww 和 bb。
2. 损失函数(衡量预测好坏)
我们需要一个标准来判断“线画得好不好”。最常用的是均方误差(MSE, Mean Squared Error):
Loss=1m∑i=1m(y^i−yi)2Loss=m1i=1∑m(y^i−yi)2
yiyi:第 ii 个样本的真实值
y^iy^i:第 ii 个样本的预测值
mm:样本总数
直观理解:算所有样本的“预测误差的平方”的平均值。这个值越小,说明线拟合得越好。
3. 优化方法(如何找到最佳参数)
目标变成了:找到一组 w和 b,让 MSE 最小。
方法一:最小二乘法(正规方程,解析解)
数学上直接求导,令导数等于零,解出参数。
优点:一步到位,精确解。
缺点:当特征数量极大(几万维)时,矩阵求逆计算量巨大,甚至无法计算。
方法二:梯度下降法(数值解)
像“蒙着眼睛下山”,每一步都朝着当前最陡的下坡方向走一小步,反复迭代直到谷底(损失最小)。
优点:能处理海量特征,是神经网络等复杂模型的基础。
缺点:需要调学习率,可能陷入局部最优(线性回归的损失函数是凸函数,不会陷入局部最优,只有全局最优)。
在
sklearn的LinearRegression中,默认使用最小二乘法(基于SVD),稳健且快速。
from sklearn.datasets import fetch_california_housing
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
import numpy as np
from sklearn.metrics import mean_squared_error
from sklearn.linear_model import LinearRegression
import os
import joblib
"""
线性回归直接预测房子价格
:return: None
"""
# 获取数据
fe_cal = fetch_california_housing(data_home='data')
# 分割数据集到训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(fe_cal.data, fe_cal.target, test_size=0.25, random_state=1)
# 特征值和目标值是都必须进行标准化处理, 实例化两个标准化API
std_x = StandardScaler()
x_train = std_x.fit_transform(x_train) #训练集标准化
x_test = std_x.transform(x_test) #测试集标准化
# 正规方程求解方式预测结果,正规方程进行线性回归
lr = LinearRegression()
# fit是耗时的
lr.fit(x_train, y_train)
#从回归系数可以看特征与目标之间的相关性
print('回归系数', lr.coef_)
y_predict = lr.predict(x_test)
#保存训练好的模型
joblib.dump(lr, "./tmp/test.pkl")
print("正规方程测试集里面每个房子的预测价格:", y_predict[0:10])
#下面是求测试集的损失,用均方误差,公式是(y_test-y_predict)^2/n
print("正规方程的均方误差:", mean_squared_error(y_test, y_predict))如果对训练集里面的目标值也进行了标准化,求出来的目标值需要逆转回来之后才能求均方误差
from sklearn.datasets import fetch_california_housing
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
from sklearn.linear_model import LinearRegression
import os
import joblib
import numpy as np
"""
线性回归直接预测房子价格
:return: None
"""
# 获取数据
fe_cal = fetch_california_housing(data_home='data')
print("样本里的第一条数据",fe_cal.data[0])
print("目标值",fe_cal.target)
print("数据集的描述",fe_cal.DESCR)
print("特征列的名字",fe_cal.feature_names)
# 分割数据集到训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(fe_cal.data, fe_cal.target, test_size=0.25, random_state=1)
# 特征值和目标值是都必须进行标准化处理, 实例化两个标准化API
std_x = StandardScaler()
x_train = std_x.fit_transform(x_train) #训练集标准化
x_test = std_x.transform(x_test) #测试集标准化
std_y = StandardScaler()
y_train = std_y.fit_transform(y_train.reshape(-1, 1))# 目标值是一维的,这里需要传进去2维的
# 正规方程求解方式预测结果,正规方程进行线性回归
lr = LinearRegression()
lr.fit(x_train, y_train)
print('回归系数', lr.coef_)#从回归系数可以看特征与目标之间的相关性
y_predict = lr.predict(x_test)#预测测试集的房子价格,通过inverse得到真正的房子价格
y_lr_predict = std_y.inverse_transform(y_predict)
print("正规方程测试集里面每个房子的预测价格:", y_predict[0:10])
#保存训练好的模型,模型中保存的是w的值,也保存了模型结构
joblib.dump(lr, "./tmp/test.pkl")
#下面是求测试集的损失,用均方误差,公式是(y_test-y_predict)^2/n
print("正规方程的均方误差:", mean_squared_error(y_test, y_lr_predict))输出:回归系数 [[ 0.71942632 0.10518431 -0.23147194 0.26802332 -0.00448136 -0.03495117
-0.7849086 -0.76307353]]
正规方程测试集里面每个房子的预测价格: [[ 0.039975 ]
[-0.9856667 ]
[ 0.54595901]
[-0.31917221]
[ 0.65037085]
[ 1.23359413]
[ 0.81054876]
[-0.38917515]
[-0.28938242]
[-0.05080248]]
正规方程的均方误差: 0.5356532845422556
集成学习
根据“怎么产生多个模型”和“怎么组合结果”
| 流派 | 核心策略 | 代表算法 | 降低的主要误差 |
|---|---|---|---|
| Bagging | 并行训练,投票/平均 | 随机森林 | 方差 |
| Boosting | 串行训练,后一个修正前一个的错 | AdaBoost, GBDT, XGBoost | 偏差 |
Boosting(提升法):知错能改,后来居上
核心思想:
-
基学习器是串行生成的,有严格的先后顺序。
-
第 2 个模型重点去拟合第 1 个模型没做好的样本。
-
第 3 个模型再去修正前两个模型共同的弱点……
-
最后把所有模型的预测加权组合起来(表现越好的模型话语权越大)。
与 Bagging 的根本区别:
-
Bagging:模型们独立,最后平均(降低方差)。
-
Boosting:模型们依赖,逐步提升(降低偏差)。
为什么 Bagging 降方差、Boosting 降偏差?
方差反映的是模型对于不同训练集的敏感度。Bagging 通过多次采样 + 平均,让模型不再依赖某一批特定数据,因此方差下降。
偏差反映的是模型本身学习能力的上限。Boosting 通过不断迭代修正错误,逐渐逼近数据的真实分布,因此偏差下降。
1. AdaBoost(自适应提升)
-
每轮训练后,提高被前一轮错误分类的样本的权重。
-
下一轮训练时,模型会更关注这些“难啃的骨头”。
-
最终组合时,分类错误率越低的基模型,投票权重越高。
2. GBDT(梯度提升决策树)
-
不改变样本权重,而是让每一棵新树去拟合前一轮预测的残差(真实值 - 当前累加预测值)。
-
本质是用梯度下降的思想,在函数空间中逐步逼近最优函数。
3. XGBoost / LightGBM / CatBoost
-
GBDT 的工业级优化实现,加入了正则化、并行计算、缺失值处理、二阶导数等工程技巧。
-
目前结构化数据竞赛的王者级算法。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 8
8 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)