探索Dify自动化测试:ollama+skyvern赋能高效测试新体验——ollama 与 skyvern 结合(下篇)
技术融合架构
ollama 与 skyvern 在 Dify 自动化测试中,共同构建起了一个紧密协作、高效运行的技术融合架构,宛如一个精密而复杂的交响乐团,每个乐器组都各司其职,又相互配合,共同演奏出美妙的测试乐章 。
从整体架构来看,ollama 作为智能大脑,主要负责测试用例的生成和智能分析。它基于自然语言理解和生成技术,能够根据测试人员输入的自然语言描述,自动生成详细的测试用例。例如,测试人员只需简单地描述 “测试电商网站的购物流程,包括商品搜索、添加购物车、结算支付等环节”,ollama 就能迅速理解需求,并生成涵盖各种正常和异常情况的测试用例,如搜索热门商品、搜索不存在的商品、添加限购商品到购物车、使用不同支付方式进行结算等。同时,ollama 还能够对测试结果进行智能分析,挖掘出潜在的问题和风险,为测试人员提供有价值的建议和改进方向。
skyvern 则专注于网页自动化操作和元素识别。它利用先进的视觉大模型和计算机视觉技术,实现对网页元素的精准定位和操作。在测试过程中,skyvern 就像是一个不知疲倦的机器人,能够按照 ollama 生成的测试用例,自动在网页上进行各种操作,如点击按钮、输入文本、选择下拉框等。而且,skyvern 的元素识别能力非常强大,它不受网页元素定位方式变化的影响,能够准确地识别出各种复杂网页中的元素,确保测试的稳定性和可靠性。
Dify 则作为整个架构的核心枢纽,负责协调 ollama 和 skyvern 之间的数据交互和任务执行。它通过可视化工作流设计,将 ollama 生成的测试用例和 skyvern 的自动化操作有机地结合起来,形成一个完整的测试流程。在 Dify 的工作流中,测试人员可以轻松地配置测试环境、选择测试用例、监控测试进度和结果,实现对整个测试过程的全面掌控。
在数据交互流程方面,当测试人员在 Dify 中发起一个测试任务时,首先会将测试需求以自然语言的形式输入给 ollama。ollama 接收到需求后,经过分析和处理,生成相应的测试用例,并将这些测试用例发送给 Dify。Dify 根据测试用例的要求,调用 skyvern 对网页进行自动化操作。skyvern 在操作过程中,会实时将操作结果反馈给 Dify,Dify 再将这些结果传递给 ollama 进行分析。ollama 根据分析结果,生成测试报告,并将报告返回给测试人员。整个数据交互流程就像是一条高效的生产线,各个环节紧密配合,确保测试工作的顺利进行。
实际测试流程演示
以用户登录流程测试为例,让我们来详细领略一下 ollama 与 skyvern 结合后在 Dify 自动化测试中的神奇表现 。
继续上一篇的操作
📝 配置工作流节点
节点4:HTTP 请求节点(调用 Skyvern)
点击 + 添加节点 → 选择 HTTP 请求
(1)添加结点
(2)选择HTTP请求
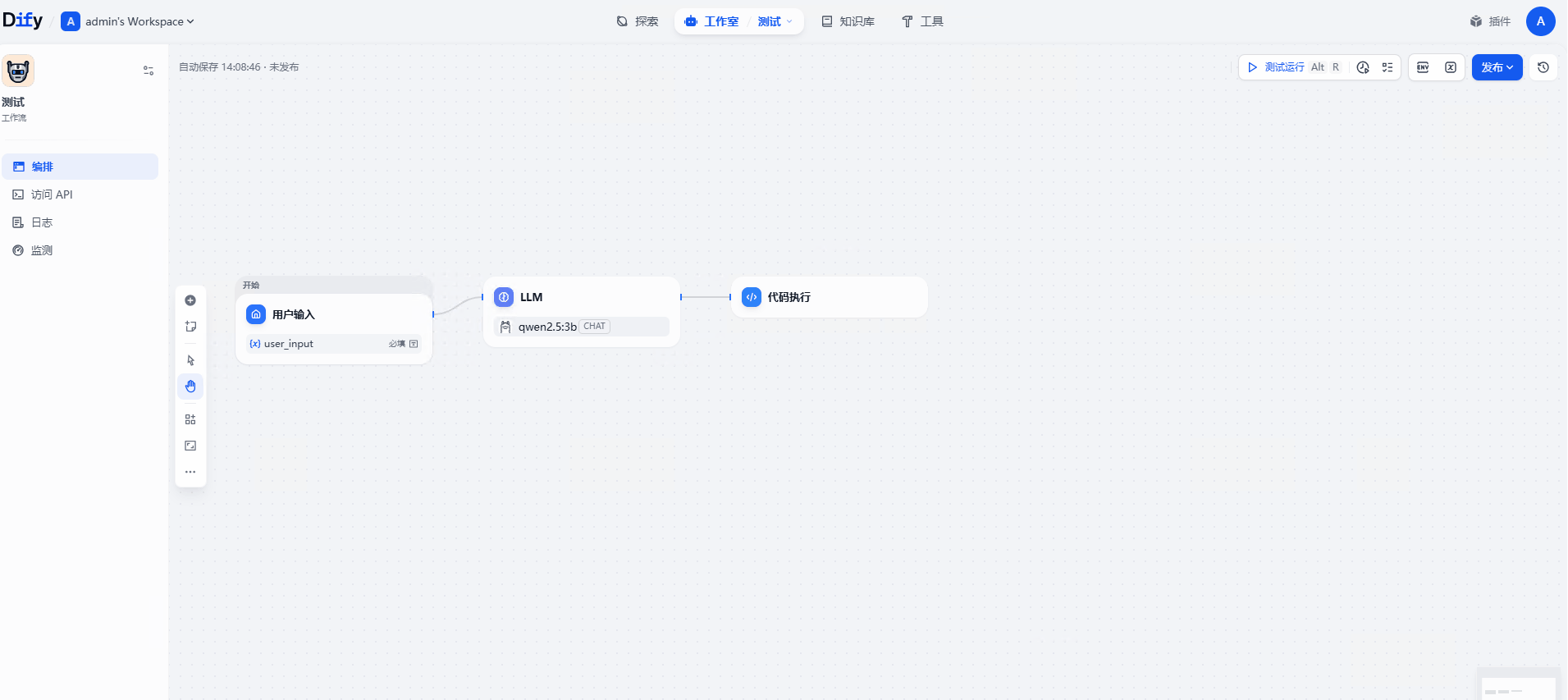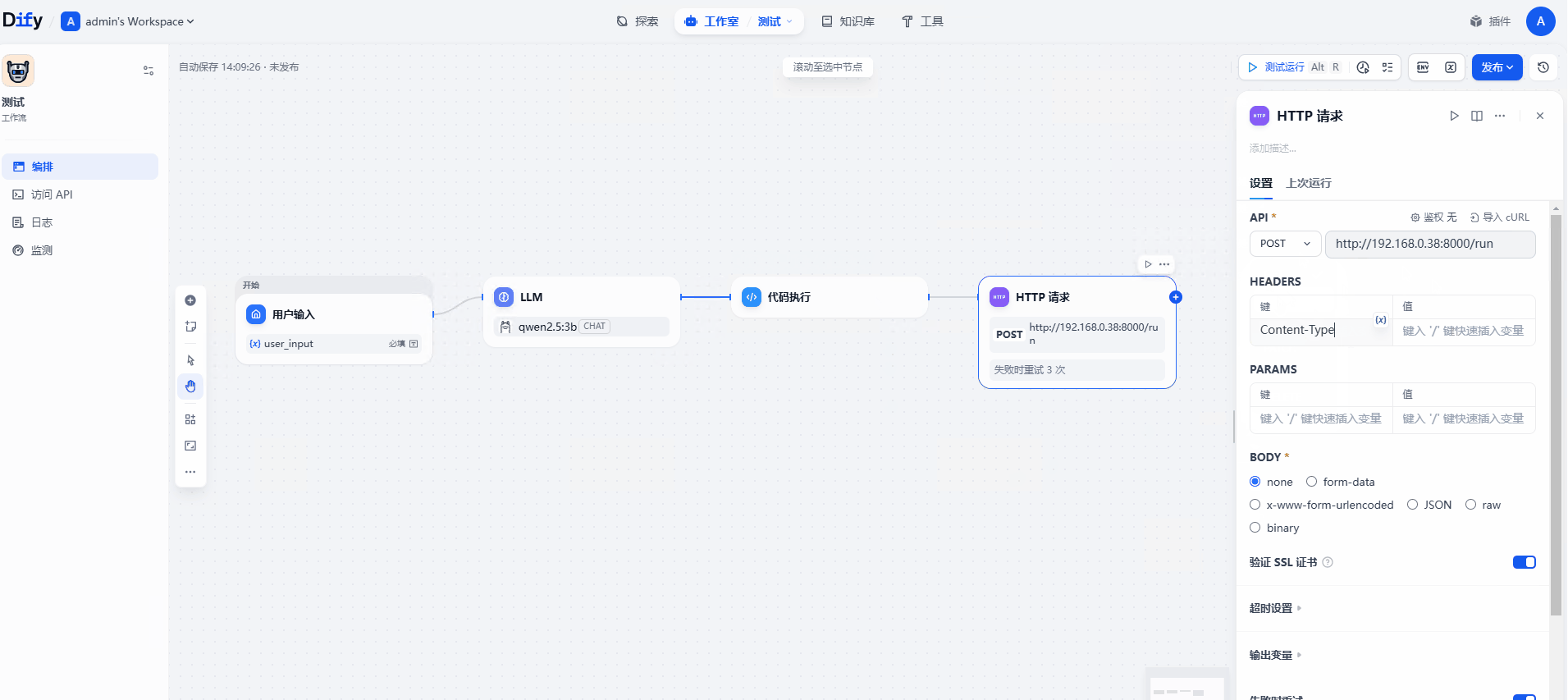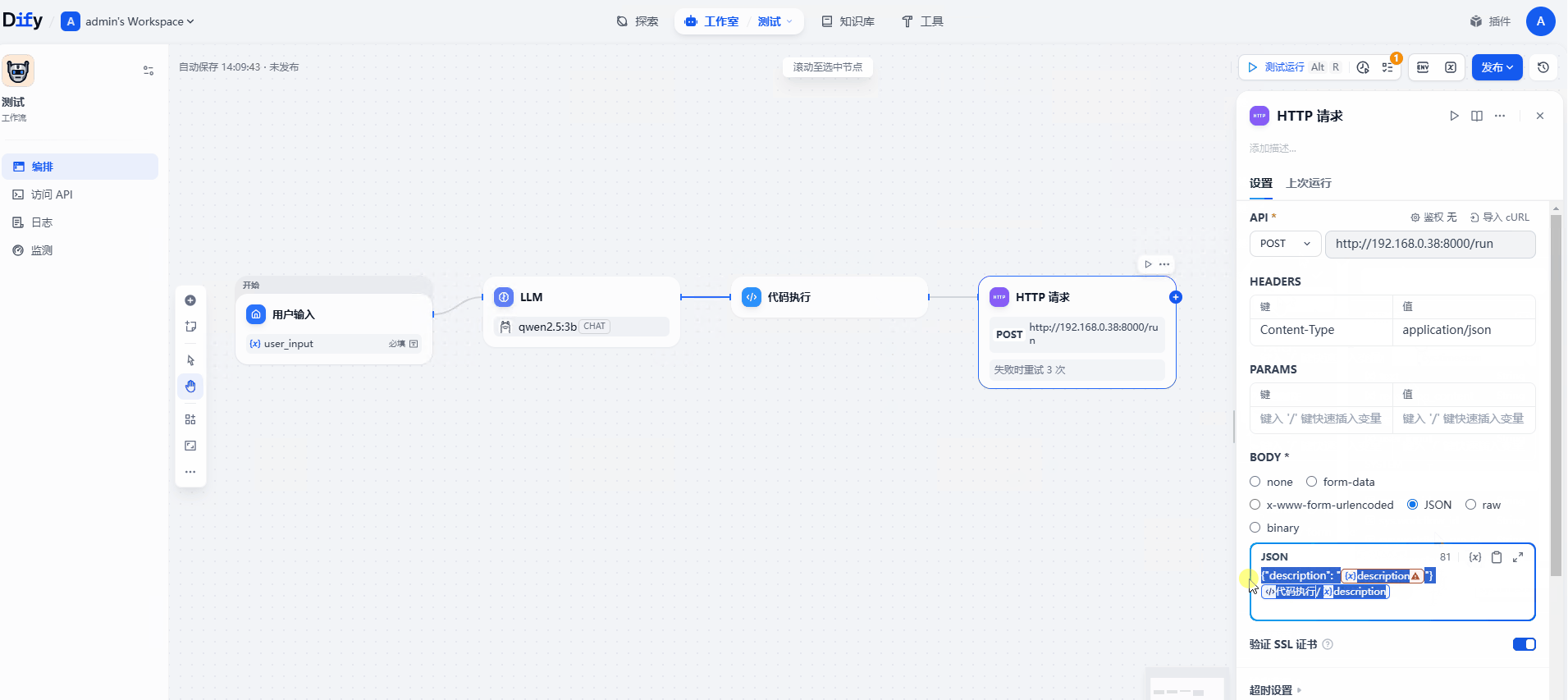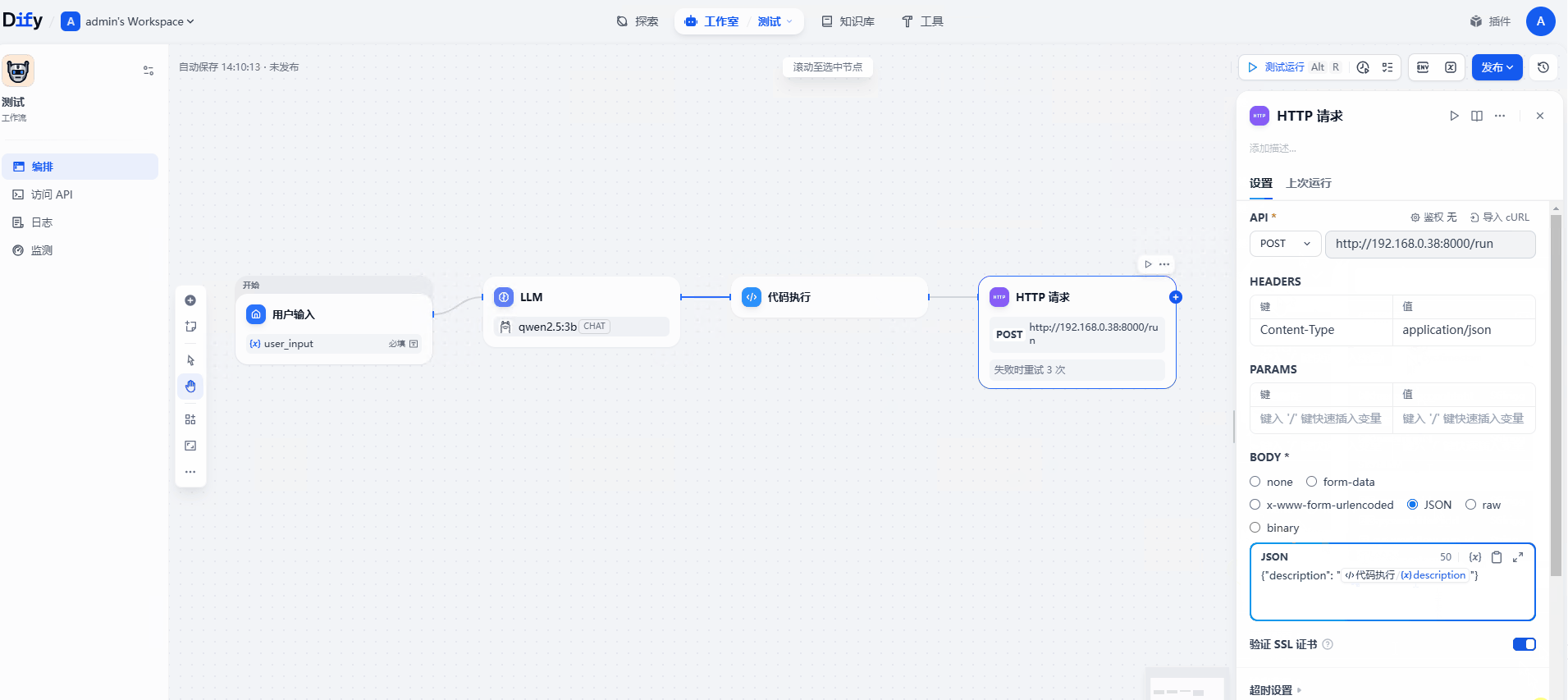
(3)API POST 地址为skyvern地址
(4)HEADERS 键Content-Type 值application/json
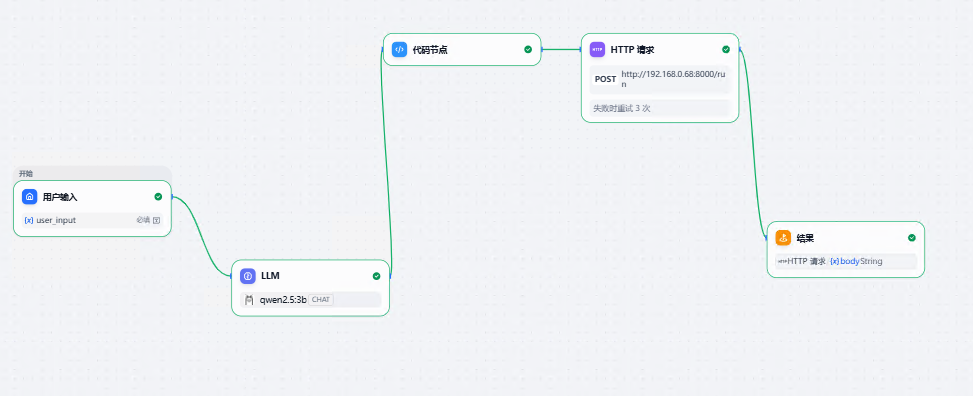
(5)BODY 选择json 值如下
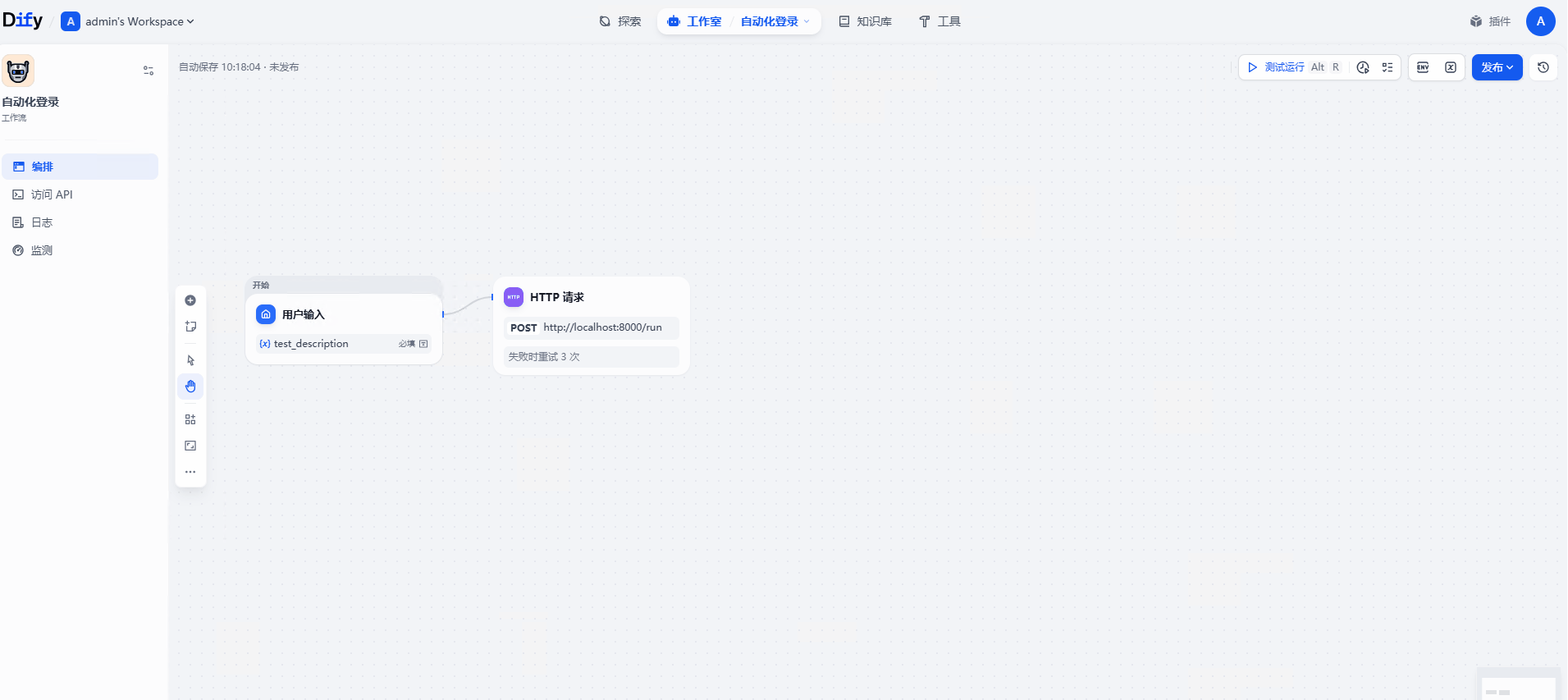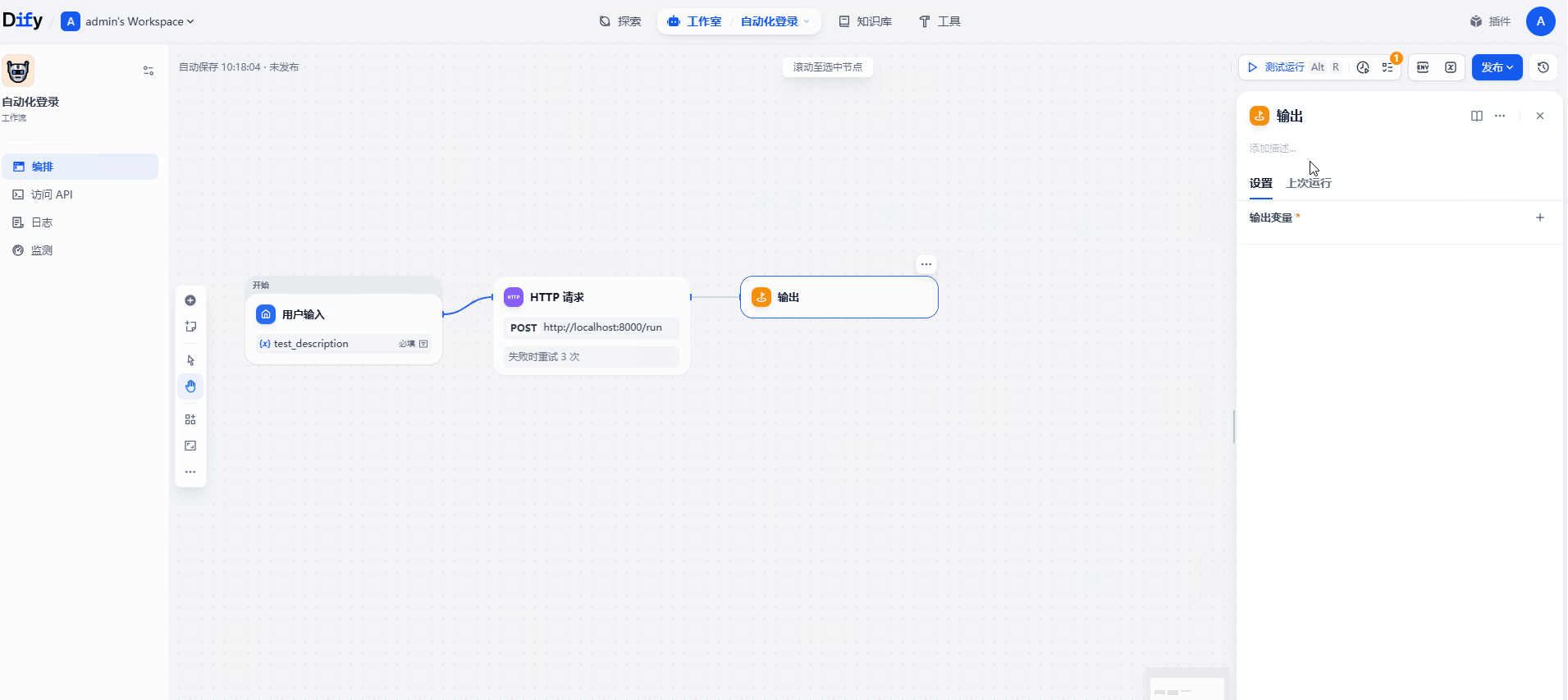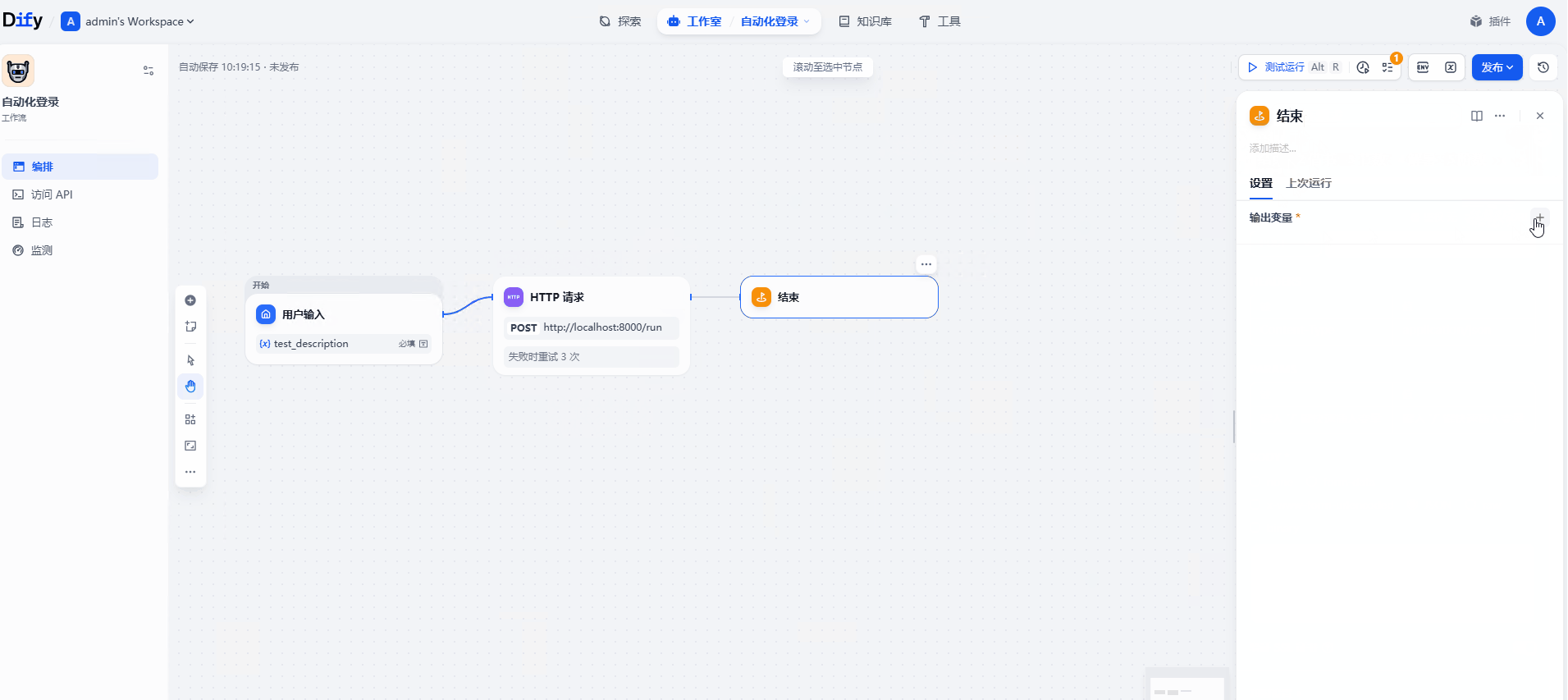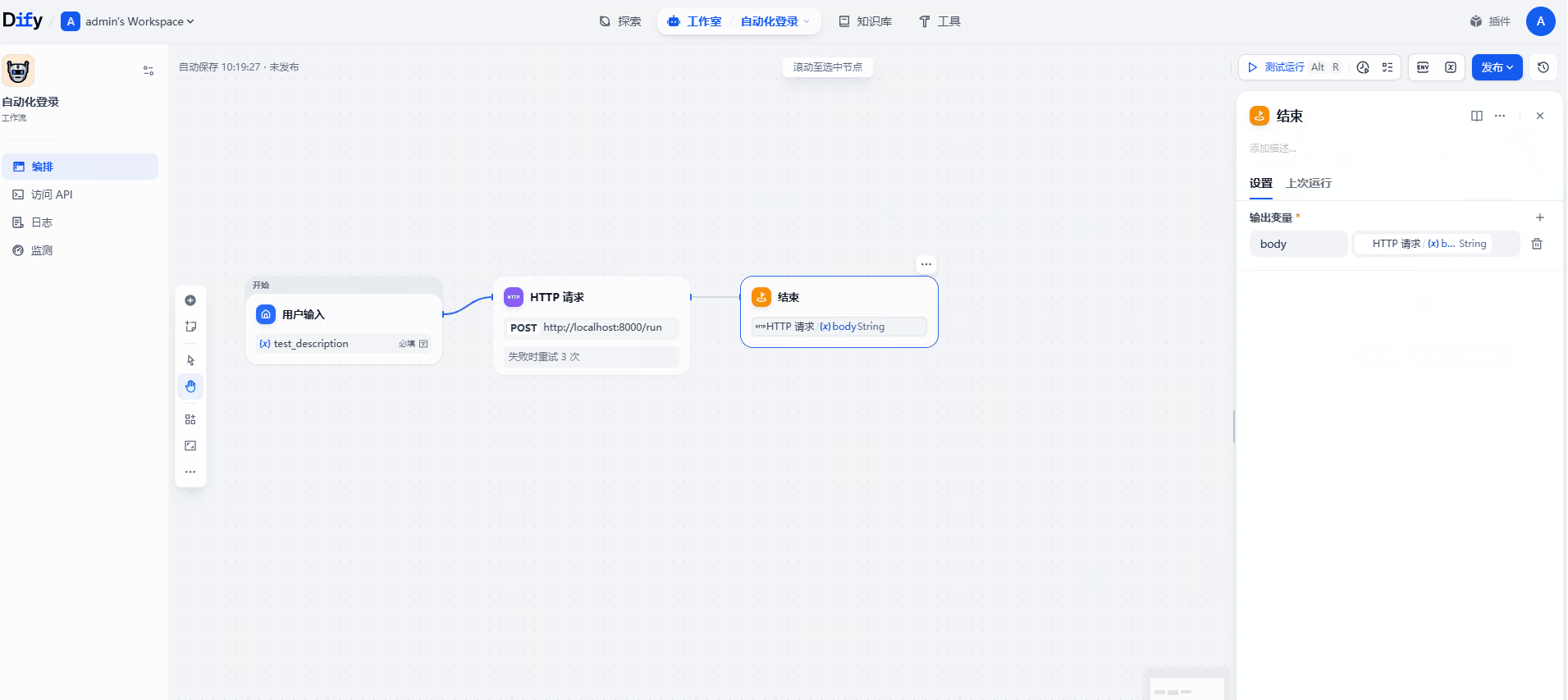
节点5:结束节点
点击 + → 结束
输出变量选择 HTTP 请求节点的 body
注意点:
确保有脚本skyvern_server.py
(1)编辑脚本(若没有的话)
|
#!/usr/bin/env python3 app = Flask(__name__) SCREENSHOT_DIR = "/opt/screenshots" def execute_steps(description): @app.route('/run', methods=['POST']) @app.route('/health') if __name__ == '__main__': |
(2)停止
|
docker stop skyvern docker rm skyver |
(3)重新构建并运行
cd /opt/skyvern docker build -t skyvern . docker run -d --name skyvern --network host -v /opt/skyvern_screenshots:/opt/screenshots -v /opt/skyvern_reports:/opt/reports skyvern sleep 5 docker logs skyvern |
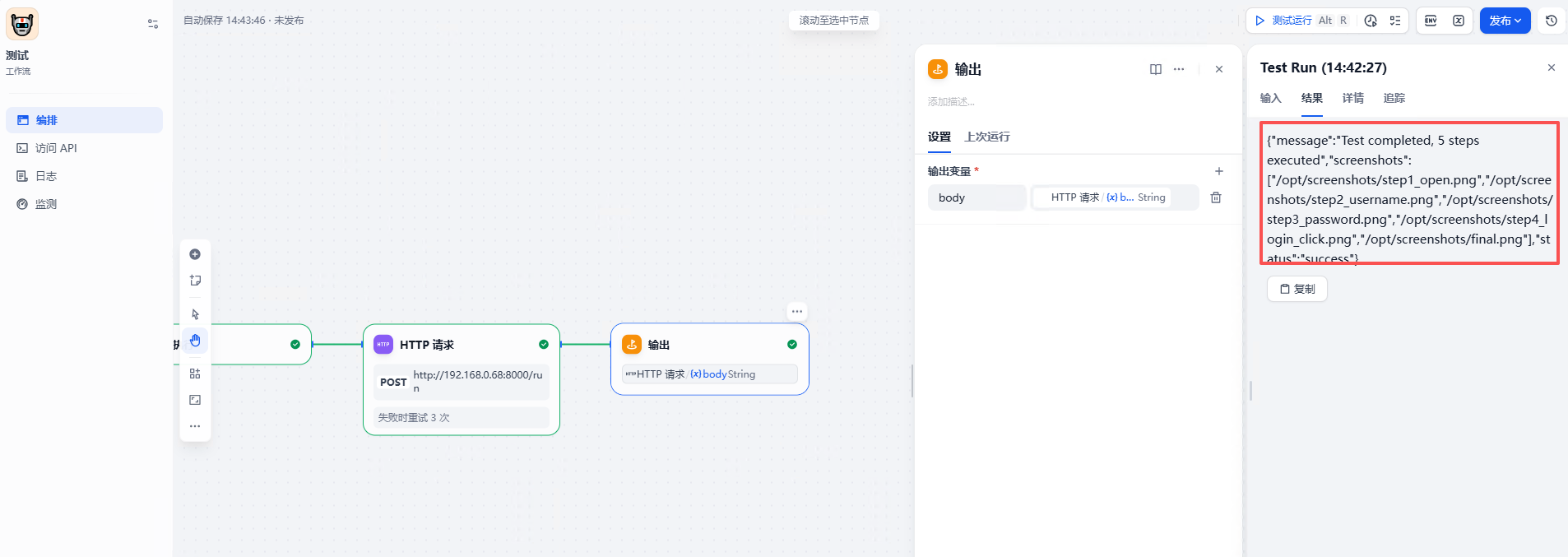
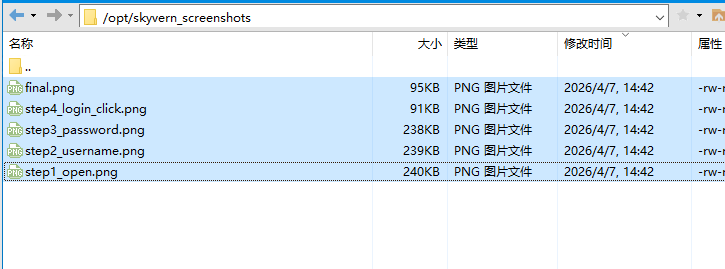
实战结果

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 38
38 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)