国产模型(ds、glm、kimi)接入新版codex全流程(CLIProxyAPI使用)
目录
写在前面
我这段时间都转去用claude code了,现在回来用codex发现国模这块真被砍废了,我下去再研究研究,但建议大家拥抱claude code吧。
2026/06/02: ds官方出了接入主流编程cli的教程!!!大家按需取用👇
https://github.com/deepseek-ai/awesome-deepseek-agent/blob/main/README.zh-CN.md
这段时间试图跑通windows+新版codex+deepseek的环境,用来部署基于websocket的项目,但是发现网上给codex接国产模型的教程要么是codex v0.8版本以下才能用,要么没写清楚codex默认模型调用逻辑,搞得我这个agent小白不停踩坑,所以我在这里决定把这段时间的经历作为教程整理出来,大家按需取用。
【注:该版本针对的是windows环境,后续再出wsl环境下的配置教程,另外最近ds更新到v4后中转站好像存在不适配的问题,建议优先用glm、kimi】
为什么有websocket服务的项目建议使用新版codex部署
原因在此:
【此处应该有一个英文技术文档链接但我找不到了】
简单来说就是在2026年三月份的时候,codex在新版本推出了app-server –listen指令用来监听ws窗口,这个功能在现在基于codex搭建的项目大概率会用到的,你没这个指令就无法正常启动服务。
而codex 0.8都是去年出的了,自然没有这个指令。
为什么老版本的codex可以直接接入国产模型
因为那个时候大家用的都是基于chat的传输协议,codex想接入模型改个配置(config.toml)就能直接用了。但是codex 0.8版本后,codex调用模型只支持使用responses传输协议的ai,目前国内据我了解只有火山家和阿里云家的ai是启用responses协议的。这使得其他家只支持chat的模型想要接入codex必须借助中转站。
国产responses模型是否可以直接接入codex?
我试过直接接入豆包(火山引擎),失败了,失败原因是因为有个很无聊的布尔变量它没传过去,说明就算是作为使用responses端口的ai还是被卡了。目前没有直接适配openai的国产模型,都得走中转。
为什么使用中转站?
这个中转站可以把不完全兼容现版openai协议的ai传输的内容包装成codex能接收的。
它在你的本地运行,占用一个localhost端口,所以你在.codex的config里要接入的api网址端口是基于localhost的,它负责收发信息,而不是使用官网提供的调用网址。(总体使用下来我认为中转站不会影响传输速率,挺快的其实)
这个中转站还可以用oauth令牌实现一些功能,但是这个教程用不上。
另外我尝试了用cc switch作为中转站连接codex→ds,发现不支持。
如果一定要接ds的话我建议直接上claude code+cc switch。如果不硬要求codex的话,想接国产模型还是走claude code+cc switch更合适,不用再看下面教程了。
实战教程
基本配置
【https://cloud.tencent.com/developer/article/2648660】基础版教程
【https://zhuanlan.zhihu.com/p/2011928155204645696】进阶版教程
大家通过上面这个教程安装了codex,并找到.codex文件夹之后,需要在该文件夹下新建一个叫config.toml的文件(如果没有编程软件的话需要下载一个notepad++,在记事本里编辑的结果是不会保存的),在里面写清楚你需要调用的模型。
codex的启动指令通常就是直接在命令行输入codex,这时候它会调用自身默认的模型。
我看到有些人直接用codex启动就能直接显示他刚接入的模型,有些则要使用“codex --profile 模型名”或者“codex --model 模型名”才能让它切换到接入的国产模型,但是大家都没讲为什么,默认都懂。
所以这里跟大家讲清楚,如果你需要使用codex时直接启动你接入的模型(比如说你部署的项目自己有启动codex的指令,这种的话你不方便通过改脚本的方式让它改变启动指令),或者你本来就只打算接一个模型,请看“默认接入单模型”,如果你没有这方面需求,但你需要几个模型换着用,请看“非默认接入多模型”。
注意,当你进入了codex之后,你将没法将一个国产模型切换成另一个,因为它内置的/model命令只能换gpt名下的模型。
默认接入单模型(ds示例)
复制以下代码的时候记得把注释以及前面的空格删了(力竭)
在config.toml中填入以下内容:
model_provider = "deepseek"
model = "deepseek-chat"
[model_providers.deepseek]
name = "DeepSeek"
base_url = "http://localhost:8317/v1" #这里就是中转站用到的网址
wire_api = "responses" #这里告诉codex这是responses端口
requires_openai_auth = true
preferred_auth_method = "apikey"
然后再新建一个auth.json,填入以下内容:
{
"OPENAI_API_KEY": "你的api填在这里"
}
这部分配置就完成了。
非默认接入多模型
【https://blog.csdn.net/u010734213/article/details/156590390】
我主要参考了这个作者,但是被他设的变量坑了一道,后面才发现这里面有个变量(disable_response_storage)是默认不保存上下文,我们不需要这个变量。
config.toml
[profiles.glm]
model_provider = "glm"
model = "glm-4.7"
model_reasoning_effort = "high" #这里是模型的档位低中高,大部分模型应该不分这个
[profiles.kimi]
model_provider = "kimi"
model = "kimixxx" #这一块我不清楚kimi现在的模型型号,你看着改
windows_wsl_setup_acknowledged = true #这一块如果你配置了wsl的话得用,不是的话可以删了
preferred_auth_method = "apikey"
[model_providers.glm]
name = "glm"
base_url = "http://localhost:8317/v1"
wire_api = "responses"
requires_openai_auth = true
[model_providers.kimi]
name = "kimi"
base_url = "http://localhost:8317/v1"
wire_api = "responses"
requires_openai_auth = true
auth.json
{
"OPENAI_API_KEY": "你的api-key"
}
然后你在命令行输入“codex --profile 模型名”就可以轮着用了
中转站使用
【https://kelen.cc/posts/cliproxyapi-guide】
这个教程其实讲的很清楚了。不过为了将codex接入国产模型,我们打开前端网页后需要进行三个地方的填写: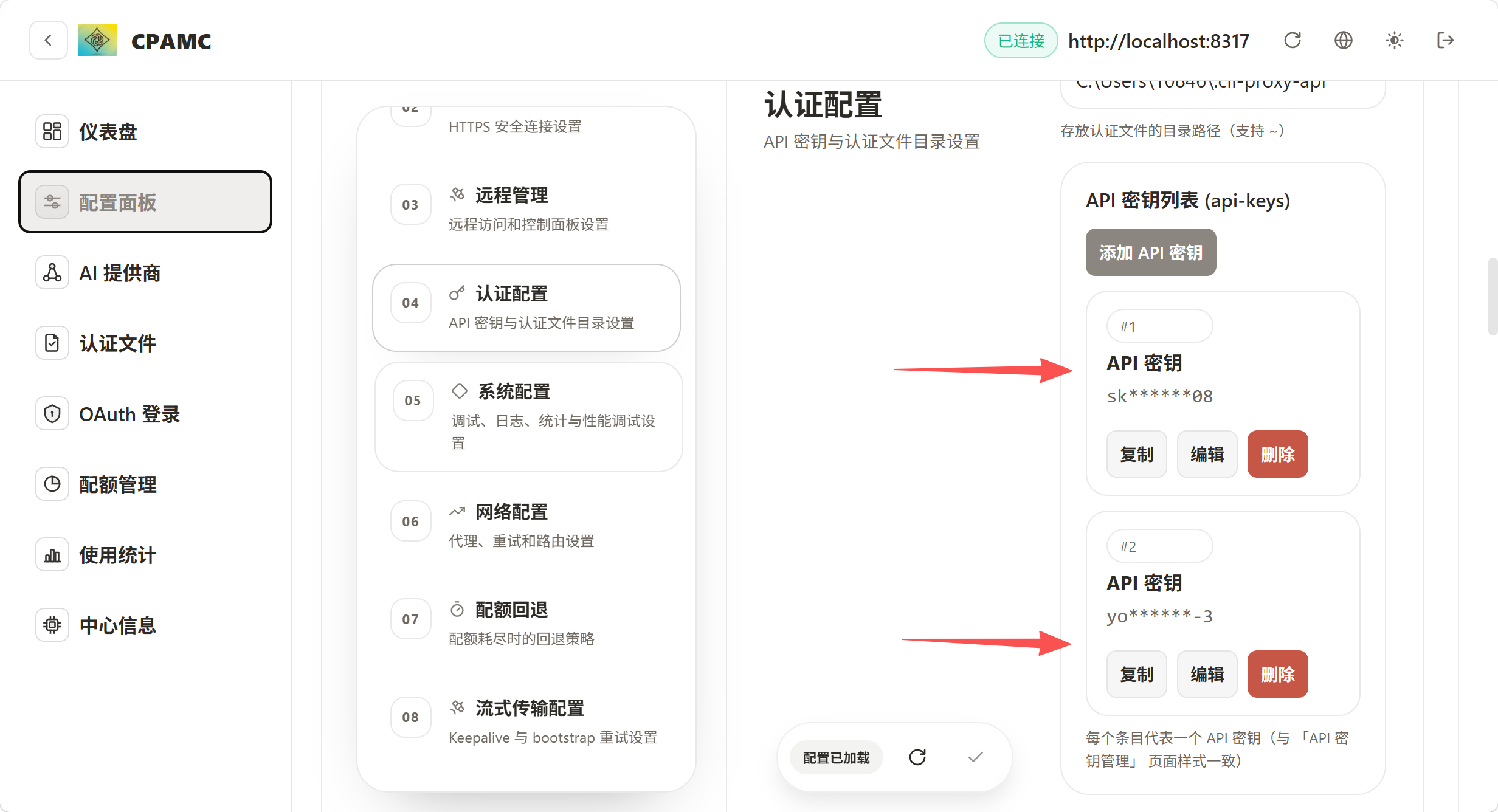
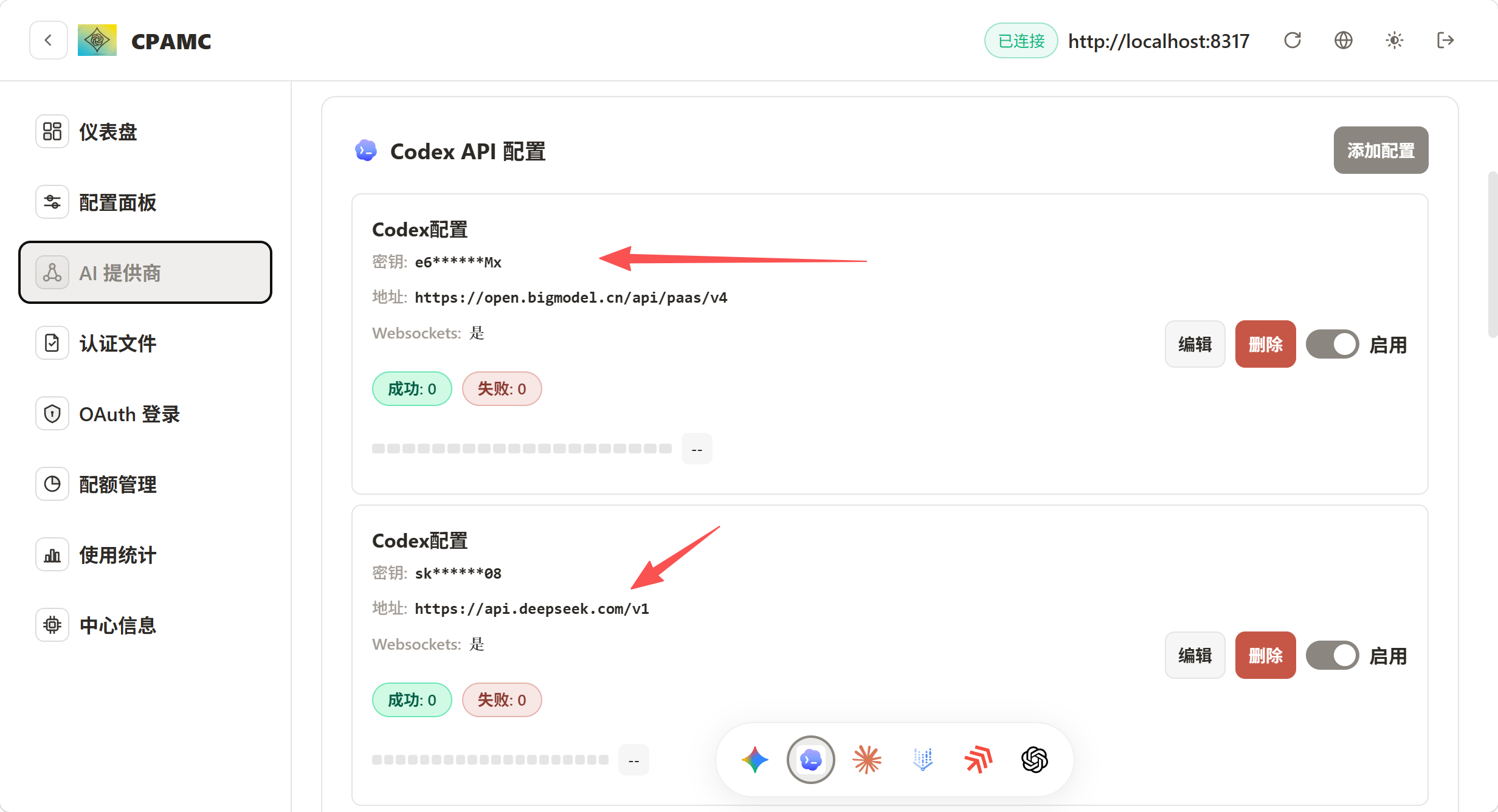
配置codex api的时候记得开这个东西:
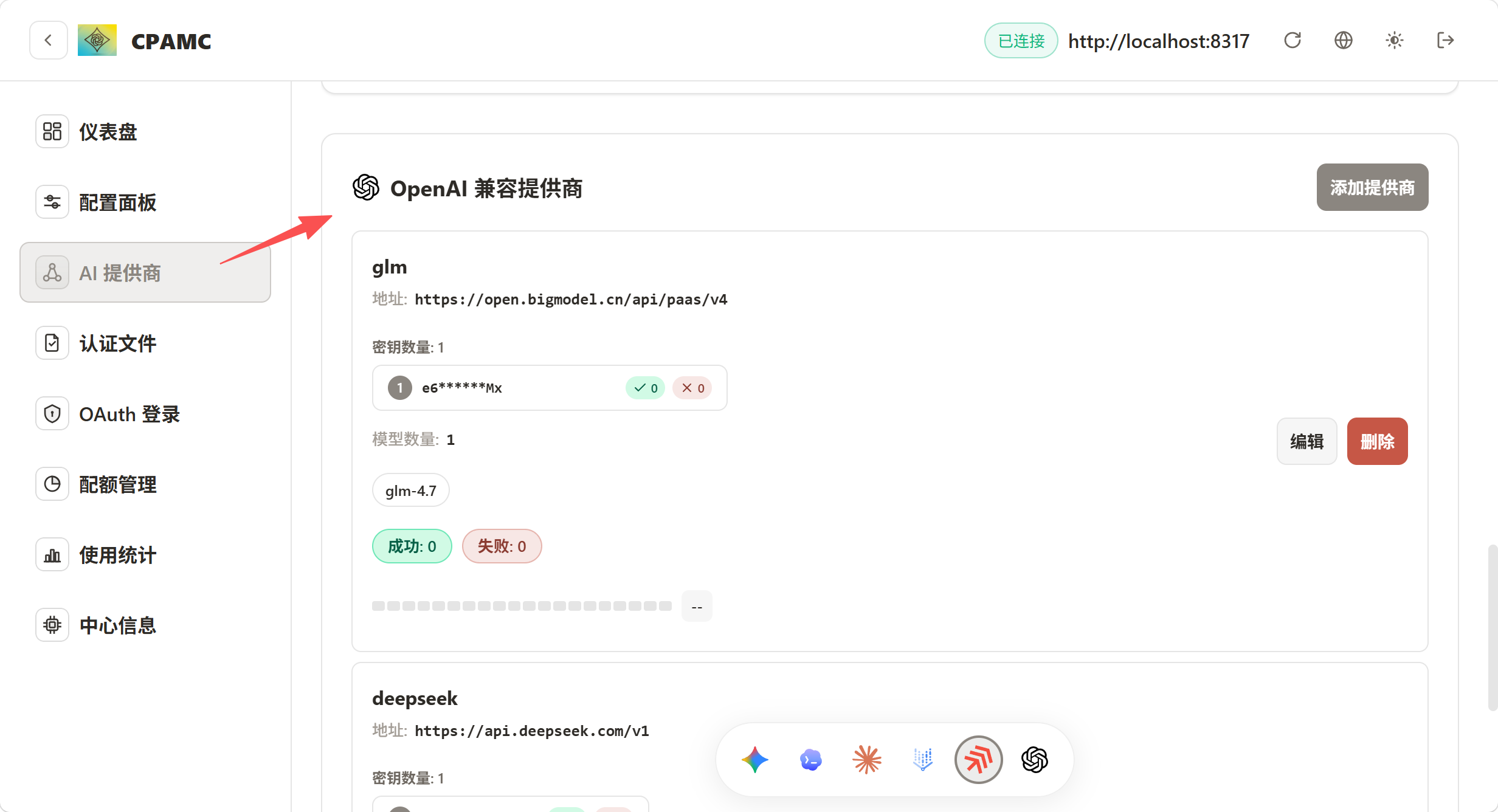
你在用codex的时候中转站要全程在终端里跑,注意

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 29
29 1
1- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)