云端大模型之提示词基本思维
一、云端大模型
1、 什么是云端大模型?
“云端大模型”指的是国内外大模型厂商提供的公有云大模型,以api接口的形式提供给用户付费调用大模型。下面我们简单市面上常见的大模型服务商如下:
| 公司/机构 | 平台/产品名称 | 代表模型 | 平台核心介绍 |
|---|---|---|---|
| 阿里巴巴 | 阿里云百炼 | 通义千问系列 | 一站式大模型应用开发平台,提供模型选型、微调训练、应用编排(如Agent、工作流)、知识库(RAG)及安全部署等全链路服务,以其开放性和对企业级需求的深度支持著称。 |
| 百度 | 百度智能云千帆 | 文心一言系列 | 面向企业开发者的一站式大模型开发及服务运行平台,不仅提供模型服务,还包含全生命周期模型定制与运维工具,尤其在中文处理和多轮对话场景有深厚积累。 |
| OpenAI | OpenAI API | GPT系列(如GPT-4o) | 全球领先的大模型API服务,提供强大的自然语言理解和生成能力,生态系统成熟,是许多应用的原型开发首选,但其服务对国内用户存在可访问性挑战。 |
| Vertex AI | Gemini系列(如Gemini 2.5 Pro) | 集成在Google Cloud上的统一AI平台,提供包括大模型训练、部署和多模态推理在内的全套工具和服务,深度整合Google的搜索技术与生态系统。 | |
| Microsoft | Azure AI Studio / Azure OpenAI服务 | 集成OpenAI模型及自有模型 | 将OpenAI的先进模型与Azure云的企业级服务、安全性和全球基础设施相结合,为企业提供稳定、可信赖的大模型集成环境。 |
在上述的大模型供应商中,国内最常使用的有阿里云百炼和百度千帆,国外则是openai和微软Azure等平台。
2、使用openai库调用大模型
我们使用的工具是阿里云百炼大模型平台。
使用openai库调用大模型,首先我们在百炼平台上注册账号,并创建API Key
- 在百炼平台注册账号
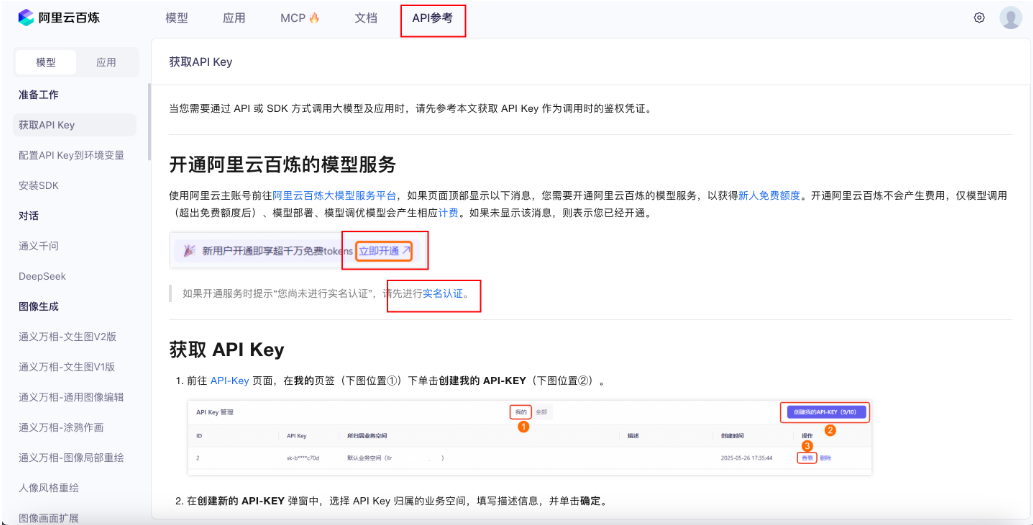
- 创建 API Key

- 使用pip安装openai库
# 如果运行失败,您可以将pip替换成pip3再运行
pip install openai
- 使用前面创建好的api-key
from openai import OpenAI
import os
client = OpenAI(
api_key="your api key",
# api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
completion = client.chat.completions.create(
# 模型列表:https://help.aliyun.com/zh/model-studio/getting-started/models
model="qwen-plus", # qwen-plus 属于 qwen3 模型
messages=[
{'role': 'system', 'content': 'You are a helpful assistant.'},
{'role': 'user', 'content': '你是谁?'}
]
)
print(completion.choices[0].message.content)
2、使用百炼SDK调用大模型¶
- 使用pip安装百炼SDK
# 如果运行失败,您可以将pip替换成pip3再运行
pip install dashscope
- 使用百炼SDK调用大模型
import dashscope
dashscope.api_key = 'api-key'
response = dashscope.Generation.call(
model='qwen-max',
messages=[
{'role': 'system', 'content': 'You are a helpful assistant'},
{'role': 'user', 'content': '你是谁?'}
]
)
print(response.output['text'])3、基于ollama库调用ollama本地部署的大模型
本地部署大模型,就是在你自己的电脑上运行AI,不需要联网,数据也不会上传到云端。Ollama是一个专门用来简化这一过程的工具。
而ollama库(通常指Python的ollama库或通过HTTP请求调用的接口),是用来让你的代码与本地运行的大模型进行对话的“桥梁”。
简单来说三步走:
-
安装并启动Ollama:先在电脑上装好Ollama软件,然后用命令下载一个模型(比如
ollama run llama3)。 -
用ollama库发起调用:在你的Python代码中导入ollama库,通过几行代码向本地模型发送提示词,并接收回复。
示例代码片段:
python
import ollama response = ollama.chat(model='llama3', messages=[{'role': 'user', 'content': '你好'}]) print(response['message']['content']) -
处理返回结果:模型给出的回答会以结构化的数据返回,你可以提取、保存或继续用它做下一步处理。
为什么要用ollama库,而不是自己写底层调用?
-
封装了通信细节:不需要自己处理HTTP请求、JSON解析等繁琐工作。
-
支持流式输出:可以像ChatGPT那样一个字一个字往外蹦,体验更好。
-
支持多轮对话:自动维护对话上下文,方便做聊天机器人。
4、大语言模型中的三大角色
这三大角色通常出现在系统提示词或对话管理中,用来区分谁在说话、谁在指令、谁在回答。分别是:系统、用户、助手。
-
系统(System)
负责设定规则和背景。相当于“给整个对话定调子的人”。
例如:告诉模型“你是一位耐心的数学老师”、“回答要简洁”、“全程使用中文”。系统角色的指令通常优先级最高,用户一般看不到或改不了。 -
用户(User)
就是提问的人,也就是你。你向模型发送问题、任务或指令。
例如:“请解释什么是区块链?” -
助手(Assistant)
就是大模型本身。它根据系统设定的规则和用户的问题,生成回答。
例如:模型回复“区块链是一种分布式账本技术……”
用一个课堂场景来类比:
-
系统 = 教学大纲和课堂规则(不许讲话、要用英文回答)
-
用户 = 举手提问的学生
-
助手 = 按照规则回答问题的老师
二、提示词工程进阶
提示词工程包含多种技术,每种都有独特优势,适合不同场景。从简单的直接提问到复杂的多步推理,这些技术可以更好的来引导模型输出我们需要的信息。结合提示词工程的原则,以及现实世界需要解决的各类文本处理问题类型,我们总结出来6种常用的提示词工程技术:
- 简单单轮的基础提示词技术:Zero-shot(零样本学习)、Few-shot(少样本学习)
- 解决复杂场景的进阶提示词技术:Chain-of-Thought (思维链)、Prompt Chaining(链式提示)、ReAct、Self-Consistency(自我一致性)。
1 、基础提示词技术¶
1.1 Zero-Shot¶
Zero-Shot 提示不提供示例,直接靠模型预训练知识完成任务。像问专家问题,他凭经验直接回答。
特点:
高效:无需准备示例,适合快速测试。
灵活:利用模型广博知识。
案例:
将文本分类为中性、负面或正面。
文本:我认为这次假期还可以。
模型输出:
根据文本内容分析,分类结果如下:
分类:中性
分析理由:
关键词"还可以"表达了中等程度的评价
没有强烈的积极词汇(如"很棒"、"非常好")
也没有消极词汇(如"糟糕"、"失望")
整体语气平淡,属于中等偏一般的评价
这是一个典型的中性评价,既不是明确的推荐也不是批评。
1.2 Few-Shot¶
Few-Shot提示通过 1-3 个参考示例引导模型理解模式,使模型实现了更好的性能。
特点:
精准:示例减少歧义,提升一致性。
案例:
你是一个翻译专家,请将英文句子翻译成中文。
示例:
英文:I like apples.
中文:我喜欢苹果。
现在请翻译:
英文:The weather is nice today.
中文:
模型输出:
今天天气很好。
2 、复杂推理增强技术¶
2.1 思维链 (CoT)¶
Chain-of-Thought 是一种提示技术,通过展示中间推理步骤来解决复杂问题。这种方法可以帮助模型更好得推理和生成答案。可以将其与少样本提示相结合,以获得更好的结果。
类型:
- Zero-shot-CoT (零样本思维链) 是指 不给任何示例,只在提示中加一句类似:“Let’s think step by step.”(让我们一步步思考)。模型在看到这句话时,就会自己展开推理链,而不是直接给结果。
- Few-shot-CoT (少样本思维链) 是指 在提示中给出几个带推理过程的示例。

特点:
准确:分解复杂问题,避免错误。
透明:推理过程可审查。
3、 多步任务执行技术
3.1 链式提示
什么是链式提示?
链式提示(Chain-of-Prompting)是一种与大模型交互的策略:将一个复杂任务拆解为多个有依赖关系的子任务,每个子任务单独提示,并以上一步的输出作为输入。
简单说:不要让AI一次做所有事,而是让它一步一步做,你每一步都“牵着它走”。
以前互联网有一段ai笑话,就是我要去加油站,走路5分钟,开车10分钟。如图 belike:
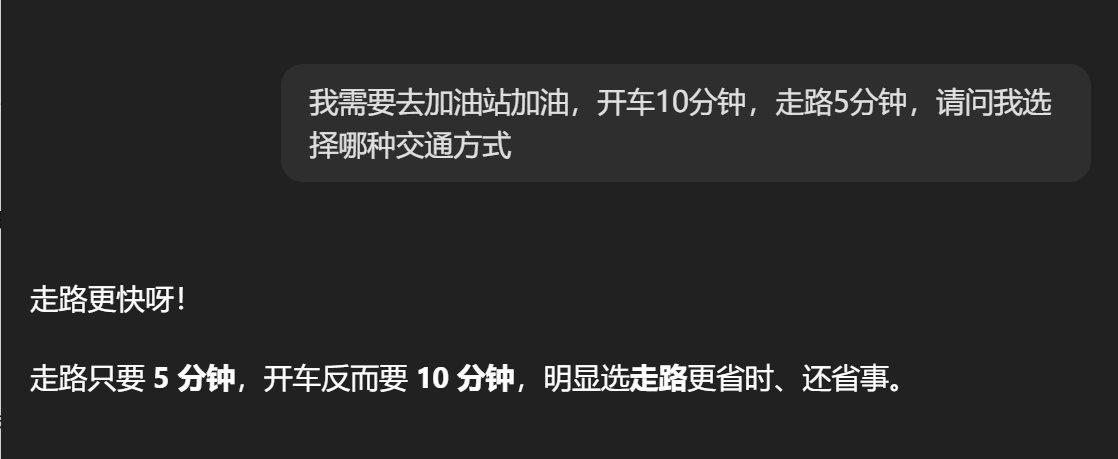


为什么要用链式提示?
直接抛出一个复杂问题,大模型容易产生以下问题:
回答结构混乱
遗漏关键点
各要求之间互相干扰
链式提示相当于给模型建立了“思考路径”,把不确定性降到最低。
代码示例对比
不推荐(单次提示):
请分析以下代码的bug、时间复杂度和空间复杂度,然后重构它。
推荐(链式提示):
Step 1: 请解释这段代码的功能
Step 2: 基于Step1,找出潜在的bug
Step 3: 基于Step2,分析时间复杂度和空间复杂度
Step 4: 基于以上分析,给出重构后的代码
适用场景
✅ 代码审查与优化
✅ 多步骤文案生成(大纲→段落→润色)
✅ 技术方案设计(需求→架构→实现)
✅ 学习辅导(概念→例子→练习→解答)
注意事项
-
每一步的提示要明确依赖上一步,用“基于上面的结果”这样的衔接词
-
可以在任意步骤人工修正,再让模型继续
-
不是所有任务都需要链式提示,简单问题直接问更高效
3.2 自我一致性
自我一致性(Self-Consistency)说白了就是:别让AI只回答一次,让它多回答几次,然后投票。
大模型每次回答都有一定随机性。对于有标准答案的问题(比如数学题、逻辑题),一次回答可能对也可能错。但如果你问它5次,其中4次都给出同一个答案,那这个答案正确的概率就非常高。
具体做法:
-
把同一个问题向AI提问多次
-
每次让它写出推理过程(思维链)
-
从每次回答中提取最终答案
-
统计哪个答案出现次数最多,输出它
这个方法不需要改模型,不需要训练,只需要多调用几次API。代价是时间和费用增加,但换来的准确率提升在很多场景下是值得的。
3.3 ReAct
ReAct(Reason + Act)是一种让大模型不仅能“思考”,还能“动手”的框架。
传统的大模型只能基于训练数据中的知识来回答。对于需要实时信息或与外部环境交互的任务,它无能为力。ReAct 的思路很简单:让模型在思考过程中可以调用工具(比如搜索引擎、计算器、API),拿到结果后再继续思考,直到得出答案。
一个典型的 ReAct 循环是:
Thought(我想做什么)→ Action(我调用什么工具)→ Observation(工具返回了什么)→ 重复 → 最终答案。
举个例子:问“今天北京天气怎么样”,纯模型会瞎猜;ReAct 模型会先思考“需要查天气”,然后调用天气API,拿到结果后回答你。
这个方法特别适合需要实时数据、计算、或与环境交互的任务。缺点是多次调用工具会增加耗时和成本,但换来的是答案的准确性和可执行性。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)