别再死磕提示词了!斯坦福这个框架,让LLM从“调Prompt”变成“写代码”
目录
1. Signature(签名):只说“做什么”,不说“怎么说”

你是不是也被大模型提示词折磨疯了?
写Prompt→调格式→加案例→换模型全崩→从头再来… 简单任务还行,一上复杂RAG、多步Agent、长流程 pipeline,直接变成“玄学调参”,又脆又难维护。
今天给大家聊一个斯坦福NLP重磅开源框架——DSPy,它直接把LLM应用从「手工写提示」升级成「可编程系统」,堪称大模型开发的范式革命。
一、🔥 一句话看懂:DSPy到底是什么?
DSPy = Declarative Self-improving Python由斯坦福大学Omar Khattab团队研发,核心口号:Programming—not prompting—Foundation Models👉 不写脆弱提示串,只用Python代码声明行为,让编译器自动优化提示与参数,构建稳定、可复用、可迁移的大模型系统。
简单说: 以前你是手搓Prompt; 现在你是编程定义模块,剩下的优化交给DSPy编译器。
二、🤯 传统Prompt有多坑?DSPy直接解决
先看看我们天天踩的坑:
-
手写字串提示,换模型就失效
-
多模块Pipeline互相影响,牵一发动全身
-
全靠直觉调优,没有量化指标
-
复杂系统难维护,像一堆“咒语碎片”
DSPy直接换了一套思路:
|
维度 |
传统Prompt工程 |
DSPy编程范式 |
|---|---|---|
|
核心 |
手工写提示串 |
声明式IO签名+Python代码 |
|
复用 |
极低,模型强相关 |
高,跨模型通用 |
|
优化 |
凭感觉试错 |
编译器自动搜索最优 |
|
维护 |
混乱难扩展 |
模块化、可追踪 |
|
复杂度 |
多调用即爆炸 |
结构化Pipeline轻松扛住 |
一句话总结:把“调提示”变成“写程序”,把“玄学”变成“工程”。
三、🧱 DSPy三大支柱:看懂就能用
DSPy的设计非常清晰,像PyTorch一样模块化,只记三个核心就行👇

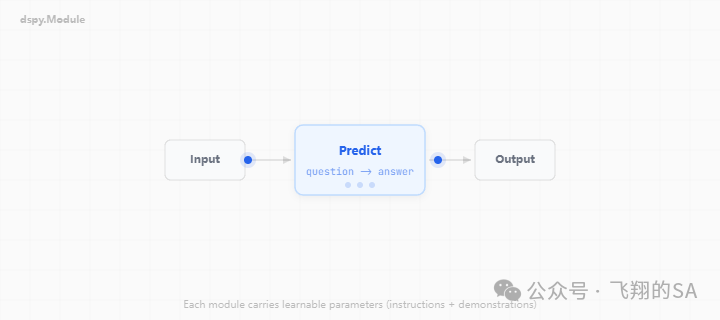
1. Signature(签名):只说“做什么”,不说“怎么说”
不用写大段提示,只用一行声明输入→输出。
# 情感分类(不用写任何Prompt)
classify = dspy.Predict("sentence -> sentiment: bool")
# 问答
qa = dspy.Predict("question -> answer")
# RAG带思考
rag = dspy.ChainOfThought("context, question -> answer")它是接口契约,不是提示文本。 DSPy在运行时自动生成提示,编译时自动优化指令与案例,你的代码纹丝不动。
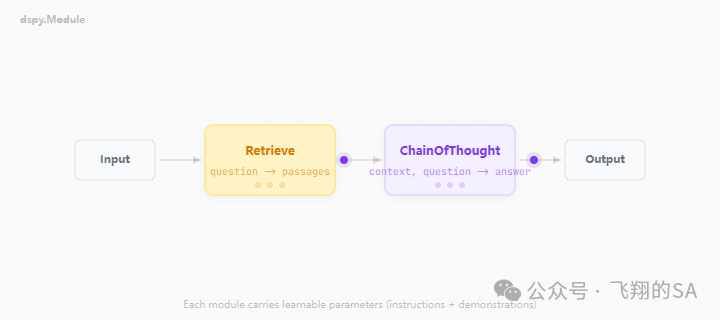
2. Module(模块):可组合的大模型积木
Signature定义目标,Module决定执行策略。
常用开箱即用:
-
dspy.Predict:基础调用 -
dspy.ChainOfThought:自动加推理步骤 -
dspy.ReAct:工具调用Agent -
dspy.Retrieve:检索器对接向量库
你可以像搭积木一样拼出RAG、多跳推理、Agent循环:
class RAG(dspy.Module):def __init__(self):self.retrieve = dspy.Retrieve(k=3)self.generate = dspy.ChainOfThought("context, question -> answer")def forward(self, question):context = self.retrieve(question).passagesreturn self.generate(context=context, question=question)
纯Python结构,支持循环、条件、递归,完全工程化。
3. Optimizer(优化器):编译器自动帮你调优
这是DSPy最狠的地方:你定义指标,它自动优化。
不用人肉调Prompt,只写一个评估函数:
def metric(example, prediction):return example.answer == prediction.answer
然后交给优化器:
optimizer = dspy.BootstrapFewShot(metric=metric)optimized_rag = optimizer.compile(RAG(), trainset=trainset)
它会自动:
-
跑通训练样本
-
收集成功案例做Few-shot
-
优化指令、结构、演示
-
输出一个编译好的稳定程序换模型?只需要重新compile,代码不用改。
四、✨ 用DSPy写一套完整RAG,只要5步
给大家看极简实战流程,全程无手写Prompt:
-
配置模型与检索器
lm = dspy.LM("openai/gpt-4o-mini")dspy.configure(lm=lm)
-
定义模块化Pipeline
-
定义评估Metric
-
编译器自动优化
-
保存/加载/上线使用
编译后的东西是优化好的提示策略,不是模型权重,超轻量、可移植。
五、🚀 为什么说DSPy是下一代LLM开发标准?
它带来的改变,堪比深度学习从手工特征到自动学习的飞跃:
1. 真正跨模型兼容
一套代码跑GPT‑4、Claude、Llama,编译器自动适配不同模型风格。
2. 复杂Pipeline稳如狗
多步调用、检索、思考、工具调用,不再互相污染,结构清晰可调试。
3. 从“手艺人”变“工程师”
你不再纠结措辞,而是专注:
-
模块怎么拆
-
接口怎么定义
-
指标怎么量化
-
流程怎么鲁棒
4. 低成本大幅提效
官方数据:MIPROv2优化器,成本约$2,耗时10分钟,准确率提升10–40%。
六、📦 马上能用:一行安装
pip install dspy官方文档:https://dspy.ai
GitHub:https://github.com/stanfordnlp/dspy
💡 写在最后
大模型应用正在从玩具级Demo走向工业化系统。 谁能摆脱Prompt泥潭,谁就能更快落地稳定、可扩展、可维护的AI产品。
DSPy不是让你不用提示词,而是让你不用再手写、死磕提示词。它把LLM变成真正可编程的组件,像写Python一样可靠、优雅、工业化。
下次做RAG、Agent、多步推理时,别再卷Prompt了,试试DSPy。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 3
3 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)