4.16学习笔记:第二章 LangChain核心组件实操
2.1模型调用(ChatOpenAI):统一接口适配不同大模型
2.1.1为什么需要统一接口?
全世界有几十家大模型厂商(OpenAI、百度的文心、阿里的通义千问、月之暗面、智谱等)。以前,如果你写了一个应用,最初用的是百度文心,代码里全是一套百度专属的调用格式。如果哪天你想换成阿里的通义千问,你会发现它们的参数名字、数据结构完全不一样,你必须把相关的代码全部推翻重写。这对于开发者来说简直是噩梦。
LangChain 出手制定了一个“行业标准”。它就像一个万能转换插头,对外(对程序员)只暴露一套极其简单、统一的写代码方式,而把各个厂商乱七八糟的底层对接工作全部自己包揽了。
为什么案例中:明明用的是 LangChain 里的 ChatOpenAI 这个类(看名字像是专门给 OpenAI 做的),但却成功连上了阿里的通义千问!
原因在于: OpenAI 是这个行业的先行者,它的 API 格式事实变成了“行业标准格式”。为了方便开发者,阿里的 DashScope、DeepSeek 等几乎所有大厂,都在自家后台做了一个“伪装成 OpenAI”的兼容接口(也就是那个 compatible-mode/v1)。 所以,在 LangChain 里,ChatOpenAI 已经不仅仅是调用 ChatGPT 的专属通道了,它变成了一个超级通用的适配器。只要任何一家模型宣布“我们兼容 OpenAI 格式”,你都可以无缝用 ChatOpenAI 去调用它,只需换一下 base_url 和 model 名字即可,其他核心代码一行都不用改!
2.1.2 LLM与ChatModel的区别:
在 LangChain 的发展历史中,最初只有 LLM,后来随着 ChatGPT 的爆火,才衍生出了 ChatModel。这两者代表了大模型的两种进化形态。
| 对比维度 | 传统 LLM (大语言模型) | 现代 ChatModel (聊天模型) |
| 底层逻辑 |
文字接龙 (Text Completion) 你给一段残缺的话,它续写完。 |
对话交流 (Chat) 你给出一个完整的对话场景,它以回复的形式接话。 |
| 输入输出格式 |
纯字符串 (String) 输入:"床前明月光," 输出:"疑是地上霜。" |
消息列表 (Messages) 输入: 输出: |
| 有无“角色”概念 | 无。在它眼里全是一坨连续的文本。 |
有严格的角色划分。 通常分为:System(系统设定)、Human(人类)、AI(大模型自己)。 |
| 现状 | 已逐渐被淘汰,现在很少用。 | 绝对的主流。 现在市面上新出的 Qwen、DeepSeek 等都是对话模型。 |
实操案例1:统一接口调用不同模型
(1)调用OpenAI的ChatModel
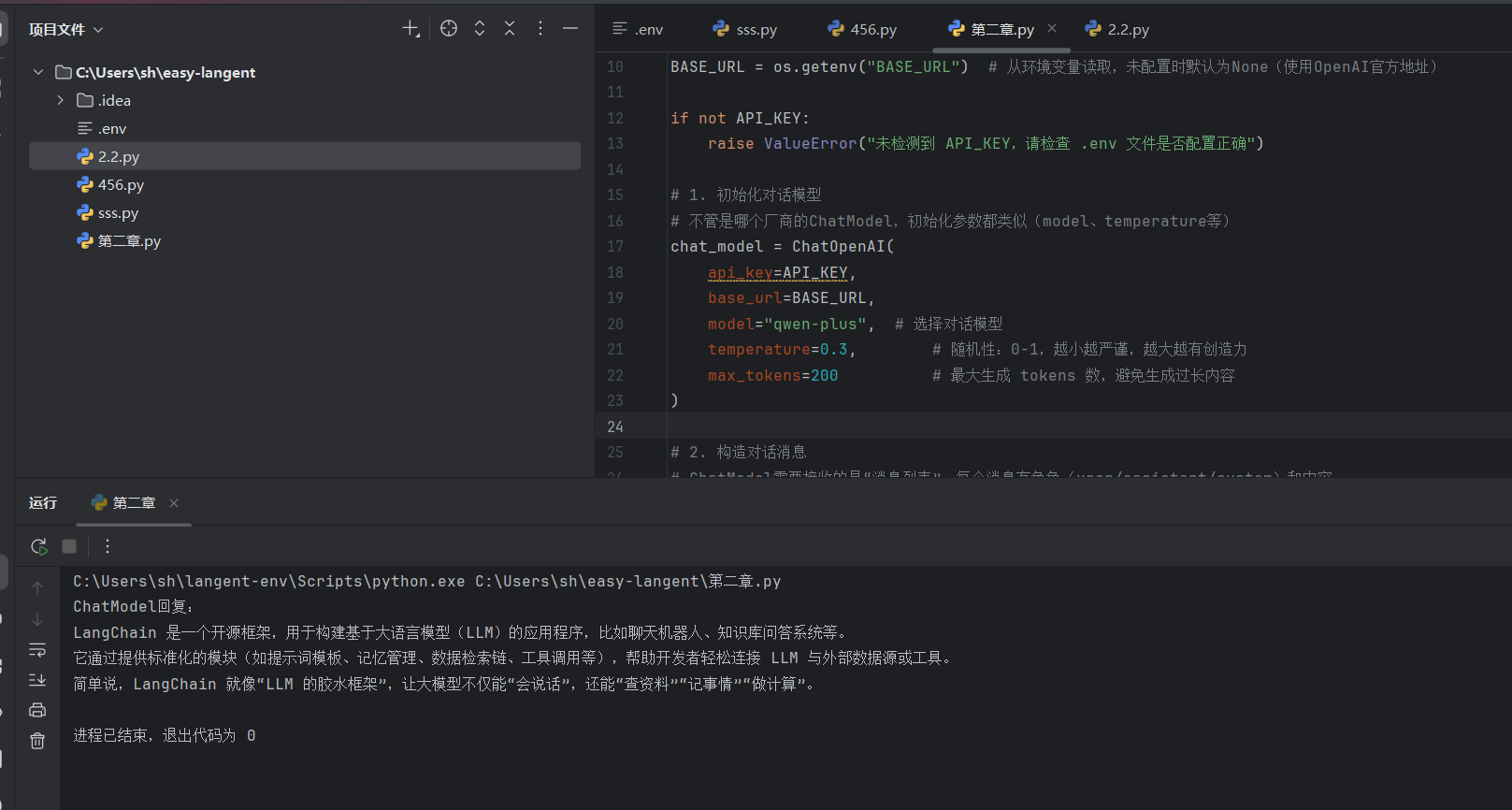 完整使用三种角色进行多轮对话的例子:
完整使用三种角色进行多轮对话的例子:
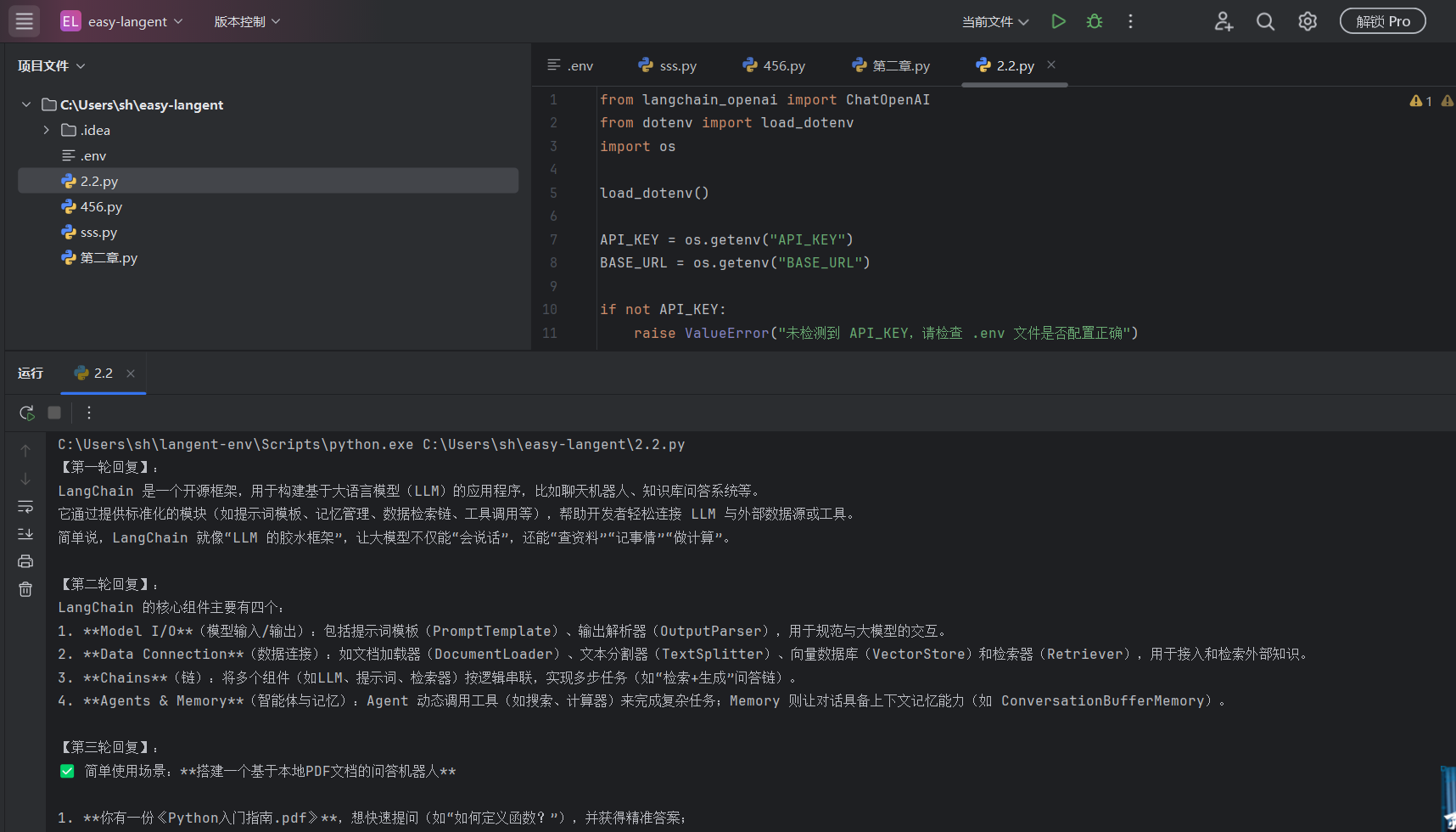
A. 消息角色的分工 (Message Roles)
在 ChatModel 中,输入不再是简单的字符串,而是不同类型的消息对象:
-
SystemMessage(系统消息):这是对话的“底色”。它定义了模型的身份、语言风格和能力边界。在构建科研工具或调研报告生成器时,通过系统消息锁定“学术严谨性”至关重要。 -
HumanMessage(人类消息):用户的输入内容。 -
AIMessage(AI 消息):模型生成的返回内容。在多轮对话中,我们需要手动将它放回消息列表,否则模型会忘记它刚才说过什么。
B. 多轮对话的“伪”记忆逻辑 (Statelessness)
这是一个非常重要的工程认知:大模型本身是“无状态”的(Stateless)。 大模型并不会“记得”你一分钟前说了什么。之所以能实现多轮对话,是因为开发者每次都把 “过去的聊天记录 + 当前新问题”打包成一个完整的列表发送过去。模型通过阅读之前的记录,推断出当前问题的语境。
C. 上下文窗口 (Context Window) 与 Token 限制
由于我们每次都要发送完整的历史记录,随着对话轮数的增加,发送的消息列表会越来越长:
-
消耗增加:由于每次都要重复发送旧消息,Token 消耗呈阶梯式上升。
-
触达上限:每个模型都有
Context Window(如 128k tokens)。如果历史记录太长,超过了这个限制,模型就会报错或丢失最早的记忆。-
进阶提示:在实际工程中,我们会使用
Window Buffer(只保留最近几轮对话)或Summary(对旧对话进行总结)来控制长度。
-
D. 温度系数 (Temperature) 的影响
在多轮对话中,temperature 的设置会显著影响连贯性。
-
对于科研或技术分析场景,通常建议设置在
0.2 - 0.4之间,以保证回答的逻辑性和准确性。 -
如果是在进行头脑风暴或创意写作,可以设置在
0.7 - 0.9之间。
(2)调用OpenAI的LLM(文本生成场景):
一:底层能力的进化——从“文字接龙”到“指令遵循”
教程里提到:“现在的大模型厂商,已经不再区分生成模型/对话模型了”。
-
过去(传统 LLM 时代): 早期的模型(比如 GPT-3)本质上是个“超级输入法”,它只会根据你给的前文,去预测下一个词。你输入“白日依山尽”,它接“黄河入海流”。这就是纯粹的“文本生成(Completion)”。
-
现在(ChatModel 时代): 现在的模型(如 DeepSeek-V3、Qwen-Max 等)都在基础模型之上,经过了严格的“指令微调(SFT)”和“人类对齐(RLHF)”。它们不再是无脑接龙,而是能听懂指令、能扮演角色、能处理结构化数据的“智能体大脑”。因此,纯粹的“生成模型”在工程界已经被淘汰了。
二:API 接口的断代——为什么必须用 ChatOpenAI
教程特意强调:deepseek-chat 不支持传统的 Completions 接口,只能用 Chat Completions 接口。
-
传统接口 (
OpenAI类): 它的数据结构只有一个简单的prompt(字符串)。 -
现代接口 (
ChatOpenAI类): 它的数据结构是messages(消息列表),强制要求你区分System(系统人设)、User(用户指令)、Assistant(AI回复)。
为什么 DeepSeek 这种新厂商直接砍掉了老接口?
因为在真实世界的工程开发中,维护两套接口成本极高且没有必要。强迫开发者统一使用 messages 结构,能够让 AI 更好地理解上下文和系统权限。这也是为什么在写代码时,绝对不要再导入 LangChain 里的 OpenAI 模块,而要永远认准 ChatOpenAI。
三:工程视角的“降维打击”——用对话模型做单次生成
教程最后提到:“对话式交互和纯文本生成的使用场景仍有明显差异”。 既然底层都统一成了 ChatModel(对话模型),那我们该怎么用它来写长篇的学术调研报告、Mini-review 或者是简单的学习计划呢?
答案是:把对话模型“降维”使用。 在实际的 AI 自动化工作流中:
-
单次内容创作(如生成报告、清洗数据): 我们依然实例化一个
ChatOpenAI,但只给它发送一轮极其详尽的消息(一个强力的 System 设定 + 一个明确的 User 指令)。它生成完这篇长文,任务就立刻结束,不需要记忆。 -
多轮上下文与任务执行(如 Agent 复杂调度): 我们用同一个
ChatOpenAI,配合 LangGraph 的状态图,让它在循环中反复接收报错、反思、调用外部工具(IDE、浏览器)。
(3)快速切换到Hugging Face模型:
1. 什么是 Hugging Face?
全世界的顶级 AI 研究机构(比如 Meta、谷歌开源团队)和无数开发者,都会把他们训练好的开源模型(如 Llama 3、Mistral 等)、数据集全部免费上传到这里。里面不仅有通用的对话大模型,还有大量专门用于特定领域的专用模型。
2. 在 LangChain 里“快速切换”是什么意思?
之前学的 ChatOpenAI ,是连接“商业化/兼容 API”的转接头。
由于 LangChain 是一套标准化的“脚手架”,当你不想用商业 API,而是想用 Hugging Face 上免费开源的模型时,你不需要推翻重写你的业务代码(比如写的 prompt 模板、Agent 流程图都不用动)。只需要换一个“转接头”。
底层初始化的代码换了,但在后续调用 llm.invoke(prompt) 的时候,用法是完全一模一样的。这就是“快速切换”的魅力。
3. 为什么需要用到 Hugging Face?(核心应用场景)
-
数据隐私与安全(本地部署): 商业 API 要求你把数据传给云端。如果处理的是高度机密的科研数据或未公开的论文材料,你可以从 Hugging Face 下载开源模型,部署在本地服务器上,数据绝对不联网。
-
特定领域的“偏科”模型: 商业大模型往往是“通才”。但在科研领域(例如 AI4Science),你可能需要专门用来预测蛋白质结构、生成分子式或处理基因序列的模型。这些极度专业的模型,通常只能在 Hugging Face 上找到。
-
使用强大的 Embedding(嵌入)模型: 接下来如果你要做 RAG(知识库问答),把长文档切片并转化为向量时,Hugging Face 上有非常多开源且效果顶尖的开源向量模型(如 BGE 系列),完全免费。
-
⚠️ 实操
-
教程提到了快速切换,但在国内网络环境下,实际操作 Hugging Face 时会需要:
-
网络墙: Hugging Face 官网及接口在国内通常无法直接连通,需要配置全局科学上网环境。
-
免费额度限制: 如果你通过它的免费 API 节点调用,不仅速度可能很慢,有时还会因为排队而报错。
2.2提示词模板:
2.2.1提示词模板基础用法:标准化提示与动态参数
1. 标准化提示 (Standardization)
解决的问题:限制大模型“放飞自我”。 在工程中,我们往往需要大模型保持绝对稳定的人设和输出格式。比如,在AI 工具调研项目中,我希望大模型每次分析一个新工具时,都按照统一的口吻和框架输出。 通过模板,可以把“你是资深研究员”、“请分三点作答”、“必须使用中文”这些死命令(标准化规则)锁死在代码里,以后再也不用每次提问都重复敲这些字了。
2. 动态参数 (Dynamic Parameters)
解决的问题:实现批量化和复用。 当你把死命令锁死后,剩下的就是每次变化的具体任务。我们用大括号 {变量名} 来预留位置。 比如模板是:请解释一下 {concept} 在 {field} 领域的应用。 其中 {concept} 和 {field} 就是动态参数。你可以用代码写一个循环,瞬间自动生成成百上千个不同的提示词并发送给大模型。
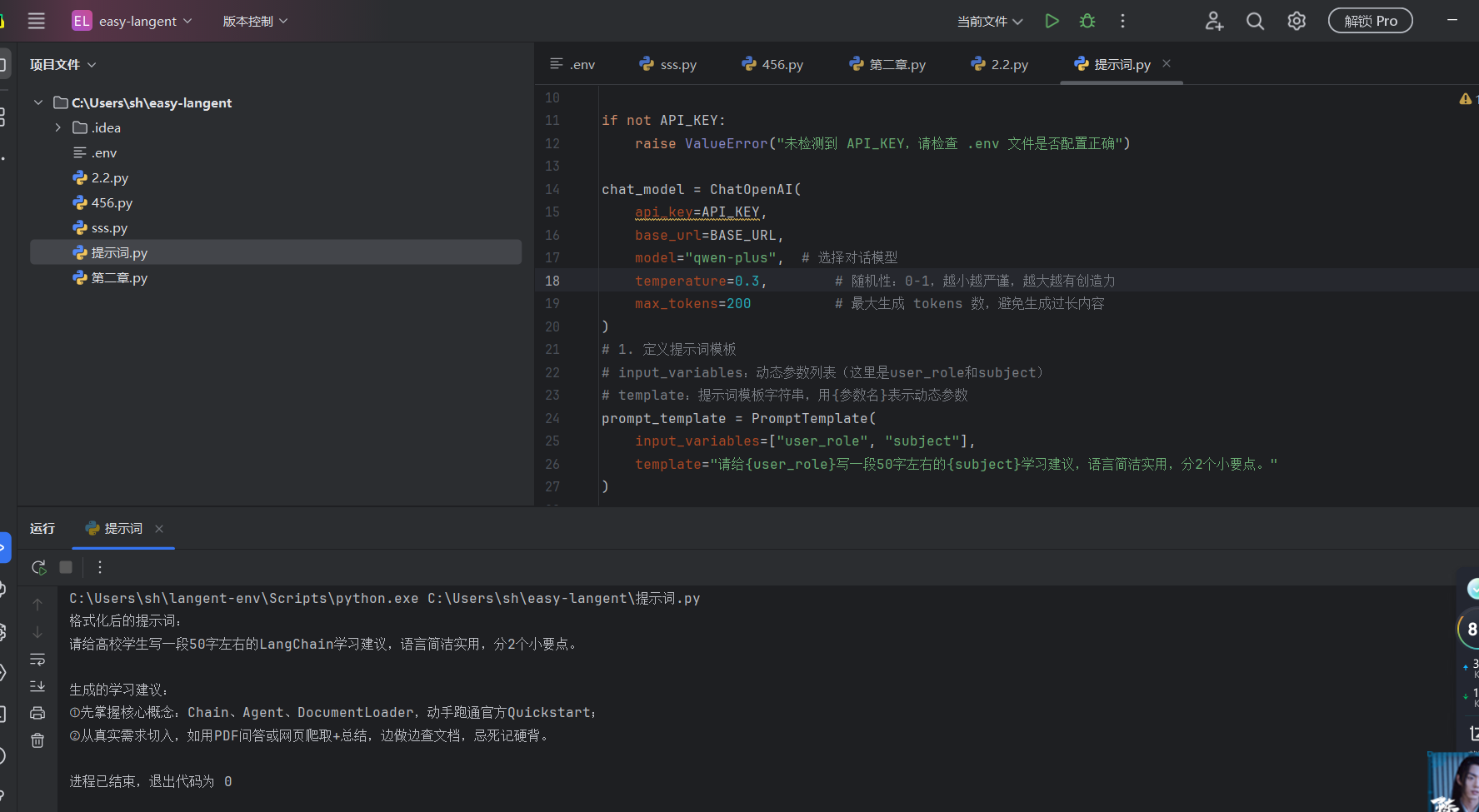
掌握了 PromptTemplate 之后,开发范式会发生根本性变化:
-
统一管理,隔离业务逻辑 在成熟的项目中,通常会有一个专门的
prompts.py文件,里面存着几十个精心调优过的模板。你的主程序代码看起来会非常干净,只负责传入参数。如果要修改 AI 的语气,改一下模板文件即可,不用去业务代码里到处翻找。 -
完美对接 RAG (检索增强生成) 在做知识库问答时,模板是不可或缺的。经典的 RAG 模板长这样:
"你是一个问答助手。请严格根据以下检索到的背景资料 {context},来回答用户的问题 {question}。"程序会自动把从向量数据库里搜出来的几千字塞进{context},把用户的提问塞进{question}。 -
输出格式的强制规范化 你可以结合模板,在里面写上:
请严格输出为以下 JSON 格式:...,从而确保下游的代码能够完美解析大模型生成的内容,而不至于被大模型随口加的一句“好的,没问题”给弄得程序崩溃。
2.2.2 提示词模板进阶用法:少样本提示模板
少样本提示的核心逻辑是:模仿。 大模型本质上是一个强大的模式识别机器。当你给出 2-3 个结构完全一致的例子后,模型会瞬间抓取到这些例子背后的“潜规则”(比如哪里该用分号、哪里该加编号、口吻是学术还是通俗)。
在 LangChain 中,实现这个逻辑需要三个标准组件:
-
示例集 (Examples):包含输入和输出的原始数据列表。
-
示例格式器 (Example Prompt):定义这一个个例子应该以什么样的外观展示给模型。
-
少样本模板 (FewShotPromptTemplate):负责把例子和当前的问题拼在一起。
1. 为什么它是“进阶”用法?
普通的模板只是简单的替换,而 FewShotPromptTemplate 引入了上下文学习(In-Context Learning)。它利用了模型在推理过程中的临时学习能力。 在处理像“哈尔滨冰雪大世界舆情分析报告”这种特定行业、特定格式的任务时,通过少样本提示,你可以让模型迅速习得该行业的专业术语风格和特定的分析维度,而不需要去重新训练(Fine-tune)模型。
2. 衔接后面提到的知识:与 ExampleSelector 的配合 (下面实例)
如果有 100 个例子(比如涵盖了入门到进阶的所有学习法),全部塞进去会消耗巨大的 Token。
-
基础做法:手动选 2 个写死在
examples里。 -
高级做法:代码会根据用户问的是“初学者”还是“研究员”,自动从 100 个例子里挑出最相关的 2 个塞进
FewShotPromptTemplate。这实现了提示词的动态化与精准化。
3. 格式强制:解决“幻觉”的良药
很多时候大模型会“自作聪明”地加一句“希望这个建议对你有帮助”。 但在自动化工作流(如 LangGraph 的节点中),如果下游代码需要通过分号或编号来解析数据,多余的废话会导致程序崩溃。通过少样本提示,并在模板结尾处不给模型留“废话空间”(如上面的 suffix 结尾直接停在“学习方法:”),可以极大程度强制模型直接输出干货,从而保证系统的稳定性。
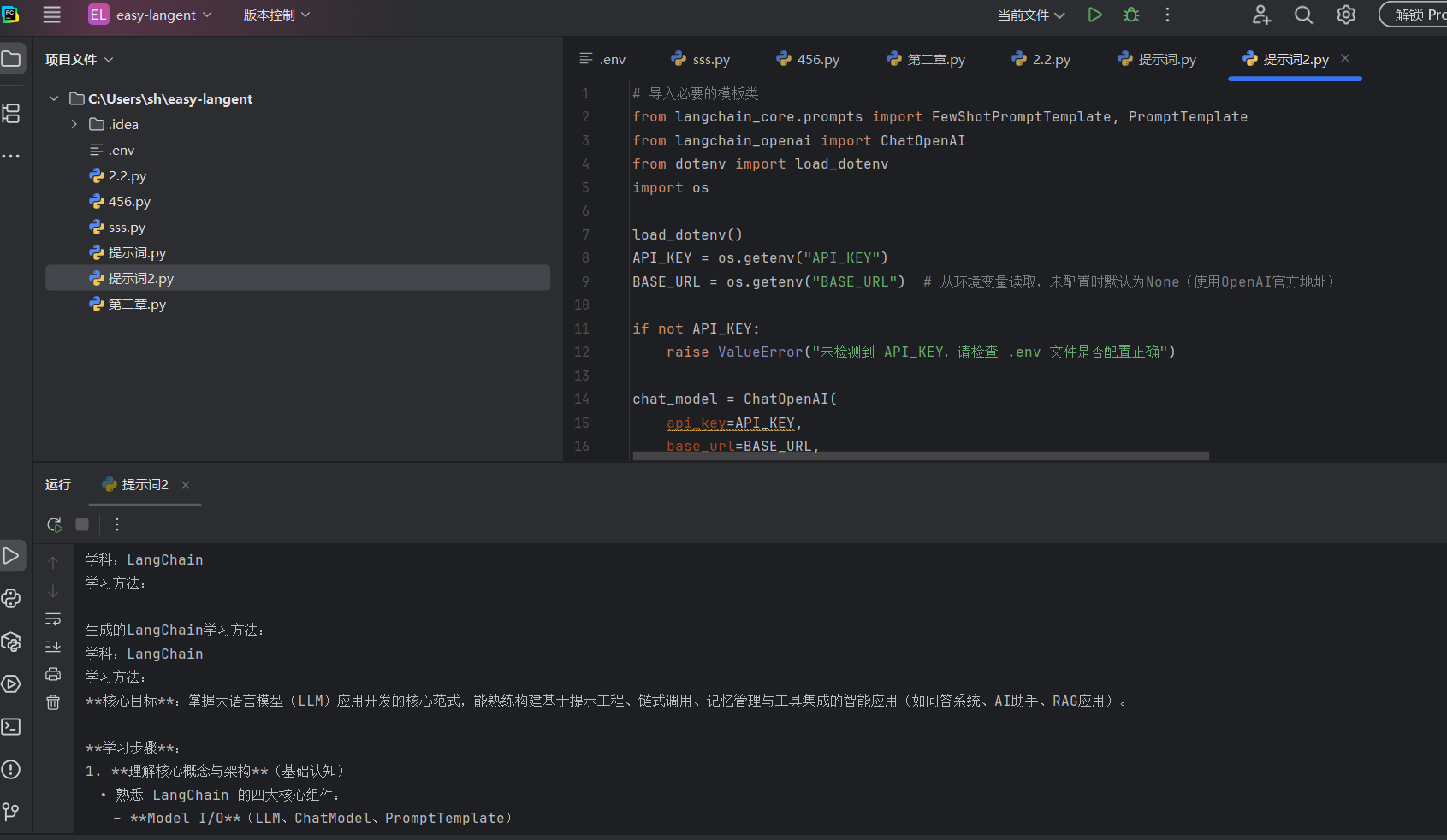 工程化实践:少样本提示模板的高效管理
工程化实践:少样本提示模板的高效管理
动态示例选择:ExampleSelector的使用:
2.3 输出解析
痛点:
在工程实践中,Python 代码是非常死板的。如果你让一段代码去读取一个字典里的 tool_name,那返回的数据必须是一个标准的 JSON 或 Python 字典。
但大模型天生是个“话痨”。哪怕你用 Few-Shot 甚至在提示词里大喊大叫:“只准给我输出 JSON,不要说任何废话!!!”
它依然有 10% 的概率会这么回复:
“好的,没问题!作为一名资深研究员,以下是我为您提取的 AI 工具信息 JSON 格式:
{"tool_name": "SciSpace", "feature": "文献阅读"}
核心机制:输出解析器是如何工作的?
输出解析器(Output Parser)就像是一个双向翻译官 + 严格的质检员。它在背后做了两件极其重要的事情:
-
Format Instructions(提供格式说明): 你不需要自己苦思冥想怎么用提示词逼大模型输出 JSON。解析器自带了一份写得极其严密的“格式要求指南”。它会自动把这段指南拼接到你的提示词里,告诉大模型:“请严格按照以下 Schema 输出...”。
-
Parse(执行解析与清洗): 当大模型的回复(不管带不带废话)传回来时,解析器会用正则表达式或其他手段,把里面真正的结构化数据“抠”出来,并直接转化成你需要的 Python 对象(如 List、Dict 或者自定义的 Class)
输出解析层实践案例 常用的解析器
| 解析器 | 返回的数据类型 | 格式强制力 | 适用场景 | 开发成本 |
| StrOutputParser | 字符串 (str) |
无 | 总结文章、简单对话流转 | 极低 |
| JsonOutputParser | 字典 (dict) |
弱(全凭模型自觉) | 快速做 Demo、结构简单的信息提取 | 低 |
| PydanticOutputParser | 对象 (Pydantic Object) |
绝对强制(强类型校验) | Agent 智能体开发、复杂的科研调研报告生成、必须确保程序不崩溃的生产环境 | 较高 |
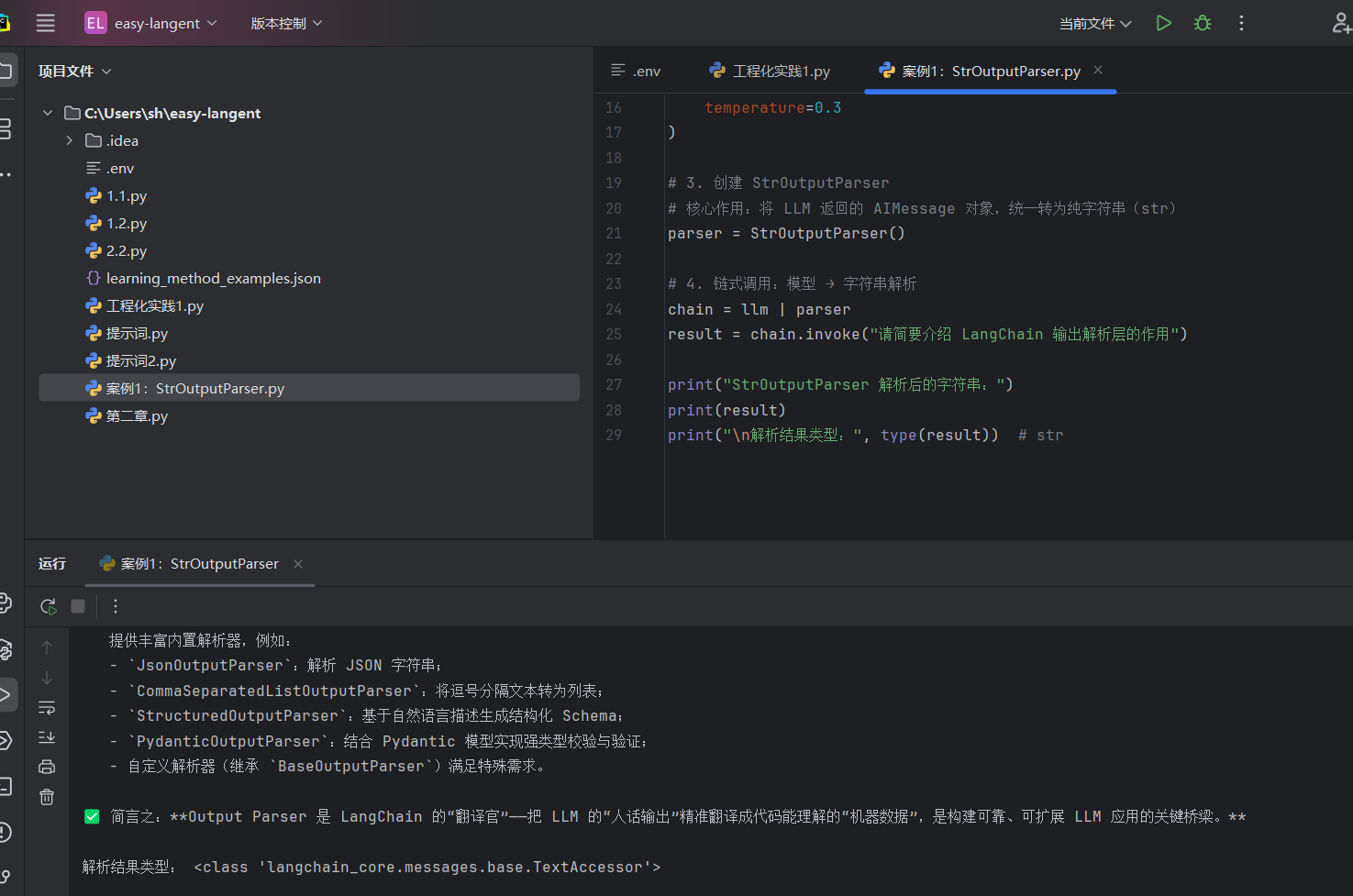
案例1:StrOutputParser:
它的本质: 很多初学者会误以为大模型(ChatModel)返回的直接是一段文字。其实不是,它返回的是一个庞大而复杂的对象(叫做 AIMessage),里面不仅包含文本,还包含消耗的 Token 数、模型调用的元数据等。
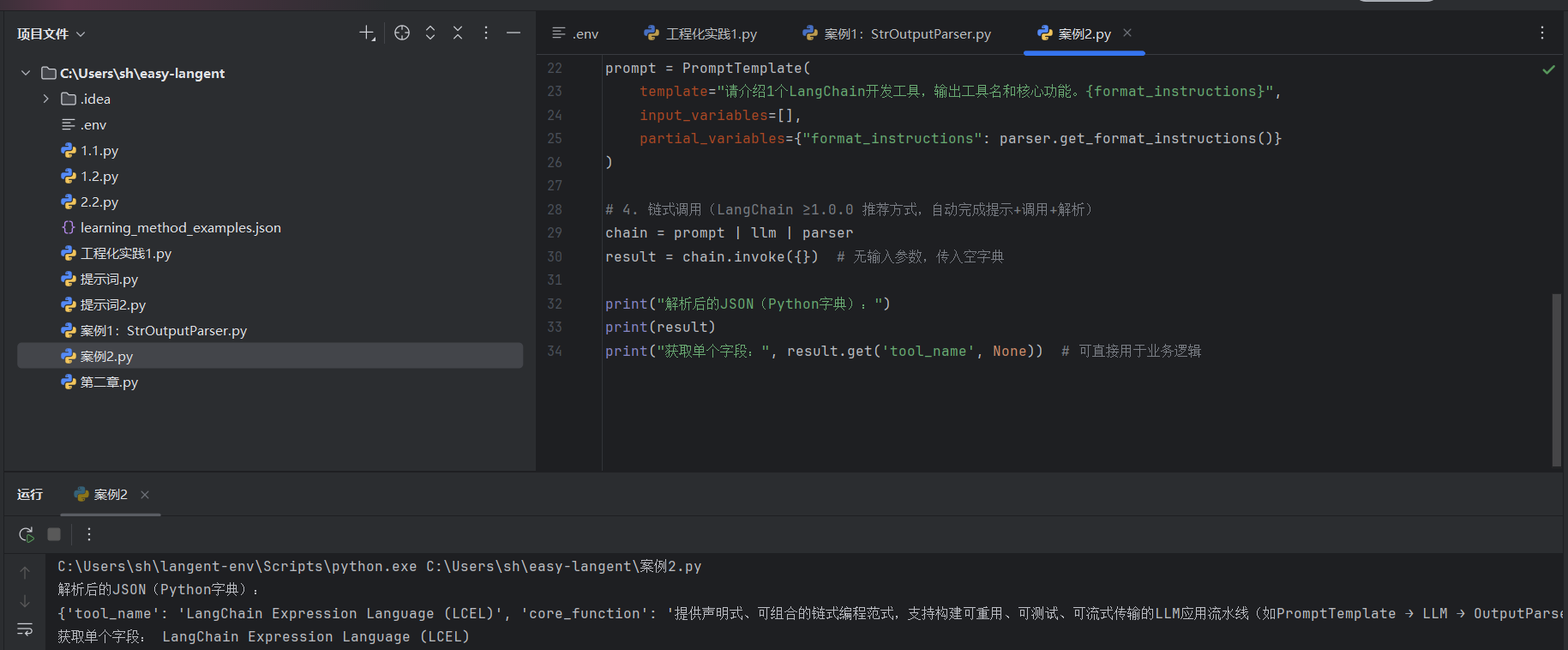
 案例2: JsonOutputParser:
案例2: JsonOutputParser:
它的本质: 它会在背后悄悄修改你的提示词,告诉大模型“请输出 JSON”,然后在拿到大模型回复后,用 Python 原生的 json.loads() 将其转化为一个字典(Dict)。
致命伤(没有校验)
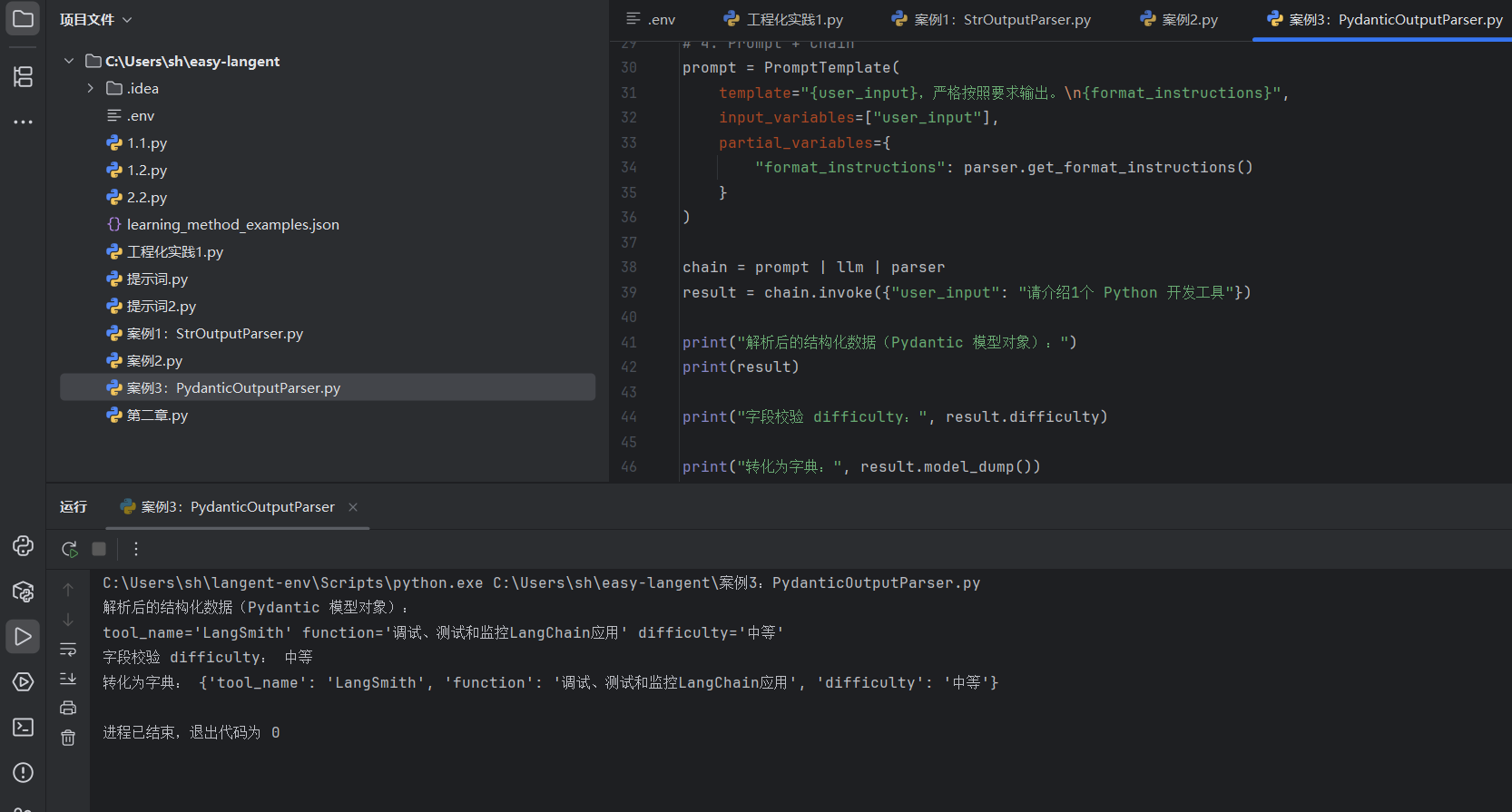
 案例3:PydanticOutputParser:
案例3:PydanticOutputParser:
它的本质: 基于 Python 最强大的数据验证库 Pydantic 构建。你必须先像建数据库表一样,严格定义好一个数据类(比如要求 tool_name 必须是字符串,is_open_source 必须是布尔值,features 必须是列表)。
只要数据经过 parser.parse(大模型回复) 处理后,你得到的就是一个完美的 Python 对象!你可以直接写 result.tool_name,如果有字段类型不对(比如要求布尔值它给了字符串),Pydantic 还会自动抛出清晰的错误。
-
自动生成完美说明书: 你不用自己写怎么让大模型输出 JSON,它会自动根据你定义的类,生成一段极其严谨的 Schema 提示词发给模型。
-
强制安检与报错拦截: 一旦大模型返回的数据类型不对(比如要求布尔值
True,大模型给了一个字符串"是的"),解析器会直接将这个结果“扣留”并报错。在高级工程中,我们甚至会捕获这个报错,并把报错信息发回给大模型,让大模型“重新修改你的格式再提交一次”。
BaseOutputParser 核心抽象接口:
概念:BaseOutputParser 是 LangChain 中所有输出解析器的抽象基类,核心作用是定义统一的解析器接口规范,所有具体解析器都必须实现它的抽象方法,同时它也是我们实现“自定义解析器”的核心基础。
在企业级开发或复杂的 LangGraph 智能体网络中,继承 BaseOutputParser 会赋予:
-
完美融入 LCEL 生态: 它可以直接用
|符和前面的大模型串起来,代码极其优雅。 -
解锁“自动重试”功能: 配合 LangChain 的
RetryOutputParser,如果上面的if len(parts) != 3:报错了,LangChain 可以在后台自动把报错信息发给大模型,让大模型自我反思并重新输出,直到输出正确的格式为止,普通的 Python 函数是绝对做不到这种“自动纠错”流转的。 -
团队协作的规范: 如果你们是一个团队在开发调研工具,大家统一继承这个基类,代码的输入输出规范就完全一致了。
| 解析器类型 | 输出的数据类型 | 核心机制与作用 | 格式强制力 (防崩溃能力) | 最典型的适用场景 (结合工程研究) | 开发与维护成本 |
|
StrOutputParser (字符串解析器) |
纯字符串 (str) |
纯粹的“拆包机”。仅剥离 AIMessage 外壳,不干预内容,提取最原始的文本内容。 |
无 (模型给什么就输出什么) |
文章总结、多智能体闲聊发声、不需要结构化提取的基础文本生成任务。 |
极低 (开箱即用) |
|
JsonOutputParser (JSON 解析器) |
字典 (dict) |
敏捷的“草稿本”。引导模型输出 JSON 格式,并调用 Python 原生方法转换为字典。 |
弱 (极度依赖大模型自身的指令遵循能力,遇到废话易报错) |
快速跑通 Demo、结构极其简单的键值对提取(如提取文章的 tags)。 |
低 (无需提前定义数据类) |
|
PydanticOutputParser (强类型解析器) |
自定义对象 ( |
工业级“海关安检”。自动生成极其严密的 Schema 指令,并对返回结果进行强类型和必填项校验。 |
极强/绝对 (字段缺失或类型错误会直接触发拦截和报错) |
生产环境默认主线。如:AI 工具功能对比图表的数据结构化抽取、Agent 任务参数的精准下发。 |
较高 (需严谨定义数据模型类) |
|
BaseOutputParser (自定义解析器) |
开发者自定义 (如 |
框架的“底层接口”。允许开发者手写切分逻辑(如通过特定符号 @、` |
` 切分),并完美融入 LCEL 链路与自动重试机制。 |
按需定制 (取决于开发者自己在 |
应对特殊分隔符、对接老旧业务系统格式、对 Token 消耗极其敏感的精简输出场景。 |
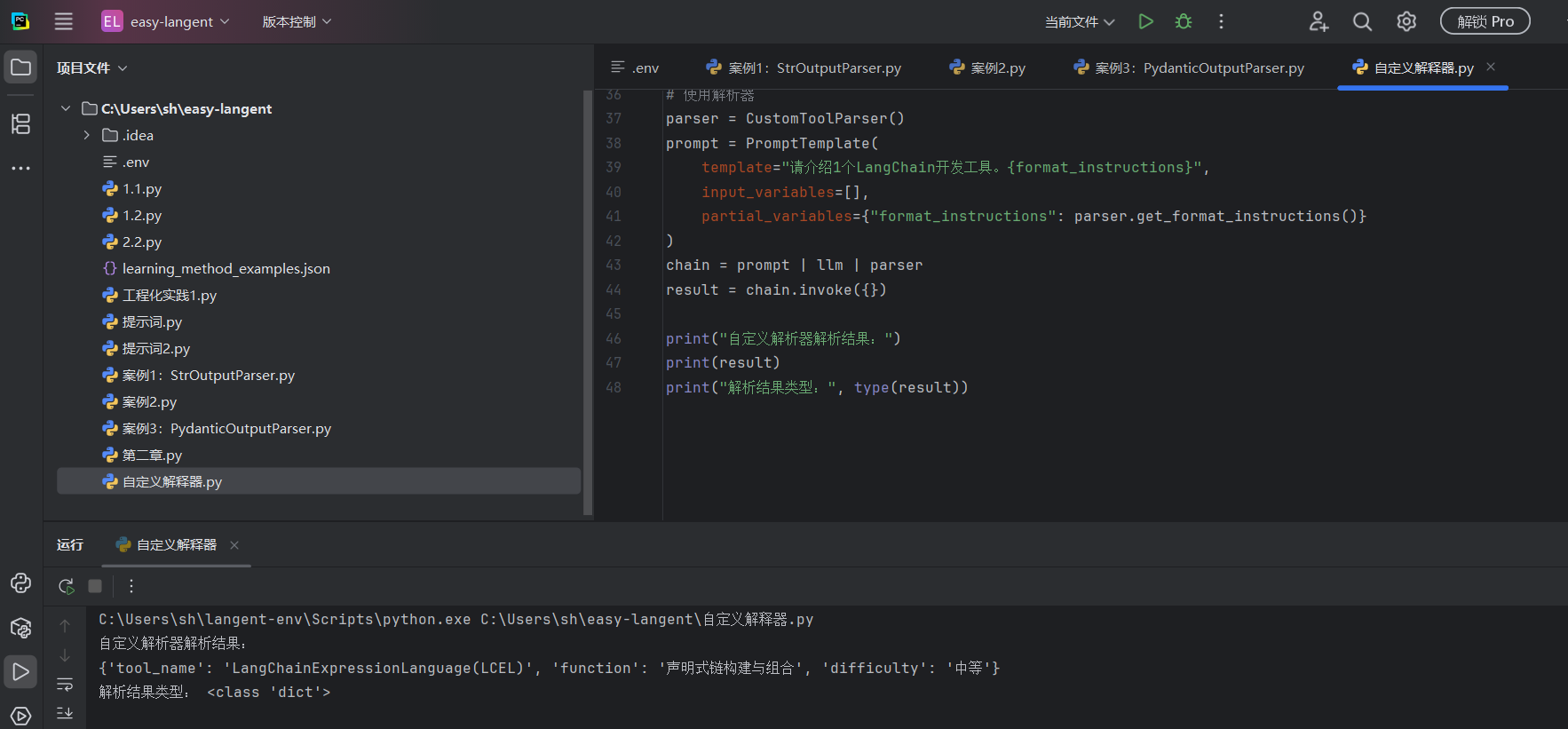
实操:自定义解析器示例:
教程里提到的场景非常真实。有时候,我们不需要像 JSON 那么重的格式。比如在整理 AI 工具速查手册时,我们只希望大模型输出极其紧凑的一行字:"Cursor@AI编程助手@中等",然后用 Python 把它变成字典。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 13
13 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)