3.给 RAG 装上“质检员“:幻觉检测、自动重试、智能切分|基于 LangGraph + DeepSeek 的实战笔记
前言:RAG 的"最后一公里"问题
如果你做过 RAG,大概率遇到过这些问题:
- 检索回来 5 篇文档,其中 2 篇完全不相关,LLM 被噪声干扰,回答质量下降
- LLM 明明检索到了正确内容,回答里却掺了编造的信息(幻觉)
- 整个流程是线性的,检索不好 → 生成就差,没有任何纠错机会
- 不同文档适合不同的切分策略,但每次都要手动试
这些问题的本质是:线性 Chain 缺乏决策和反馈能力。数据从头流到尾,中间出了问题只能在最终结果里发现。
LangGraph 解决的就是这个问题——把 RAG 流程建模为状态图,每个步骤是一个节点,节点之间可以有条件分支、循环重试、兜底降级。
打个比方:线性 Chain 像流水线,产品从头走到尾,中间有瑕疵也只能到终点才发现;LangGraph 像有质检环节的流水线,每个关键节点都能检查、退回、换条路走。
🔗 项目地址:GitHub - daixueyun3377/RAG-demo,对标 dev-LangGraph 分支
一、30 行代码理解 LangGraph 核心概念
在看完整项目之前,先用一个最小示例理解 LangGraph 的三个核心概念:
from typing import TypedDict
from langgraph.graph import StateGraph, START, END
# 1. State:贯穿整个图的"黑板",每个节点都能读写
class MyState(TypedDict):
question: str
answer: str
is_good: bool
# 2. Node:普通 Python 函数,接收 state,返回部分更新
def generate(state: MyState) -> dict:
# 实际项目里这里调 LLM
return {"answer": f"关于'{state['question']}'的回答...", "is_good": True}
def fallback(state: MyState) -> dict:
return {"answer": "抱歉,我无法回答这个问题。"}
# 3. Conditional Edge:根据 state 动态决定下一步
def check_quality(state: MyState) -> str:
return "done" if state["is_good"] else "fallback"
# 构建图
graph = StateGraph(MyState)
graph.add_node("generate", generate)
graph.add_node("fallback", fallback)
graph.add_edge(START, "generate")
graph.add_conditional_edges("generate", check_quality, {"done": END, "fallback": "fallback"})
graph.add_edge("fallback", END)
# 编译并执行
app = graph.compile()
result = app.invoke({"question": "什么是RAG?", "answer": "", "is_good": False})
print(result["answer"])
三个概念对应关系:
| 概念 | 作用 | 类比 |
|---|---|---|
| State | 全局状态,所有节点共享的"黑板" | 流水线上的工单,每个工位都能读写 |
| Node | 一个处理步骤,读 state、返回部分更新 | 流水线上的一个工位 |
| Conditional Edge | 根据 state 动态选择下一个节点 | 质检员,决定产品走哪条线 |
理解了这三个概念,下面的完整项目就好懂了。
二、整体架构
系统分为查询链路和入库链路两条主线: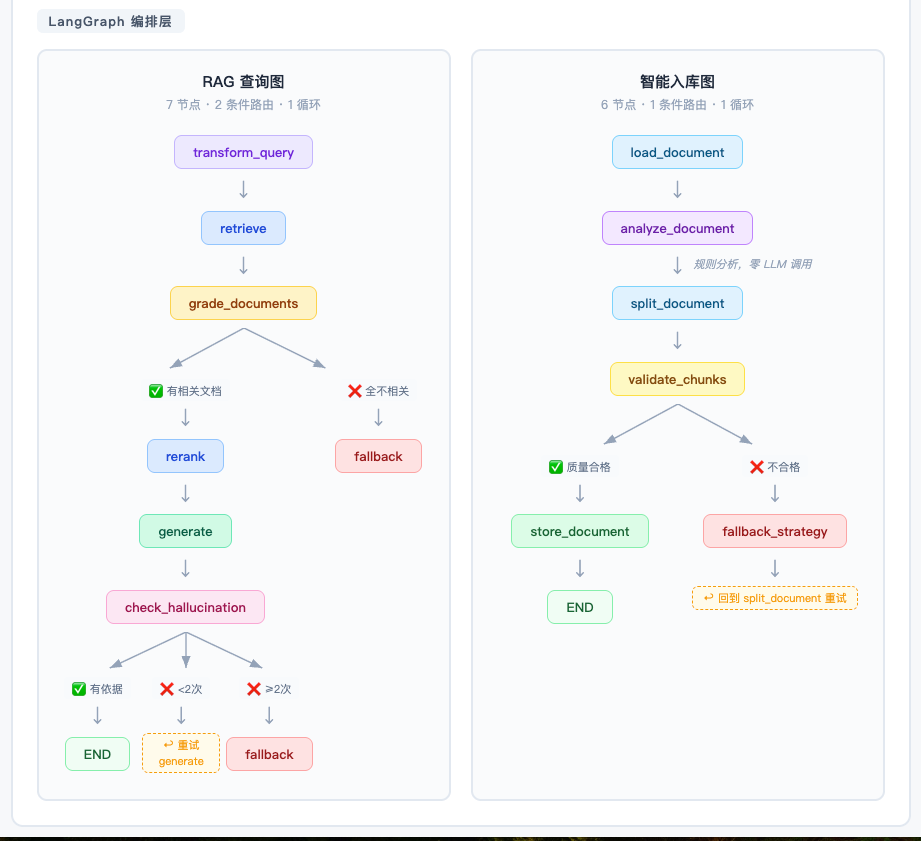


技术选型:LangGraph 做图编排,FastAPI 做服务层,Chroma 做向量库(嵌入式,零部署),DeepSeek 做 LLM(便宜够用),硅基流动提供免费的 BGE Embedding 和 Reranker API。
三、项目结构
├── app/
│ ├── config.py # 配置管理(环境变量)
│ ├── llm.py # LLM / Embedding / Langfuse 初始化
│ ├── retriever.py # 文档加载、切分、向量存储、检索器、Reranker
│ ├── ingest.py # 智能入库 LangGraph 图(文档分析 + 质量验证 + 降级重试)
│ ├── rag_graph.py # RAG 查询 LangGraph 图(评估 + 幻觉检测 + 条件路由)
│ └── main.py # FastAPI 入口,定义 API 接口
├── tests/
│ ├── test_rag_graph.py # 单元测试
│ └── test_integration.py # 集成测试(真实服务)
├── docs/
│ └── sample.md # 示例文档
├── .env.example # 环境变量模板
└── requirements.txt
核心是两个 LangGraph 图:rag_graph.py(查询)和 ingest.py(入库),底层能力由 retriever.py(检索/切分)和 llm.py(模型初始化)提供。
四、RAG 查询图:7 个节点的设计逻辑
4.1 全局流程
START → transform_query → retrieve → grade_documents
↓
┌─── 有相关文档? ───┐
↓ yes ↓ no
rerank fallback → END
↓
generate
↓
check_hallucination
↓
┌─── 有依据? ───────────┐
↓ yes ↓ no(<2次) ↓ no(≥2次)
END generate(重试) fallback → END
7 个节点,2 个条件路由,1 个循环。下面按设计决策来讲——不是"这个节点做了什么",而是"为什么需要这个节点"。
4.2 State:图的全局黑板
class RAGState(TypedDict):
question: str # 用户原始问题
search_query: str # 变换后的检索 query
retrieval_mode: str # vector / bm25 / hybrid
query_transform: str # none / rewrite / hyde
use_reranker: bool
top_k: int
retrieved_docs: list # 检索到的原始文档
relevant_docs: list # 评估后保留的文档
answer: str
hallucination_pass: bool
retry_count: int
sources: list
steps: list # 执行轨迹(调试用)
注意 retrieved_docs 和 relevant_docs 是两个字段——检索结果和评估后的结果分开存。这样在调试时能清楚看到评估过滤了多少噪声。steps 记录每一步的执行轨迹,最终通过 API 返回,这是可观测性的关键。
4.3 设计决策 1:为什么要做文档评估?
问题:检索回来的 top-5 文档里,可能有 2-3 篇跟问题无关。这些噪声文档会稀释上下文,导致 LLM 生成质量下降。
方案:在检索和生成之间加一个 grade_documents 节点,让 LLM 一次调用批量判断每篇文档是否相关。
def grade_documents(state: RAGState) -> dict:
question = state["question"]
docs = state["retrieved_docs"]
if not docs:
return {"relevant_docs": [], "steps": [...]}
llm = get_llm()
# 把所有文档拼成一个列表,一次 LLM 调用搞定
doc_list = "\n\n".join(f"[文档{i}]\n{doc.page_content}" for i, doc in enumerate(docs))
grade_prompt = ChatPromptTemplate.from_template(
"你是一个文档相关性评估专家。判断以下每篇文档是否与用户问题相关。\n"
"请对每篇文档只回答 'yes' 或 'no',每行一个结果。\n\n"
"用户问题:{question}\n\n文档列表:\n{documents}"
)
raw_result = (grade_prompt | llm | StrOutputParser()).invoke({...}).strip()
# 解析结果(下面单独讲这个函数)
grade_results = _parse_grade_result(raw_result, len(docs))
relevant = [doc for doc, ok in zip(docs, grade_results) if ok]
return {"relevant_docs": relevant, "steps": [...]}
为什么用批量评估而不是逐篇调用? 逐篇调用 5 篇文档就是 5 次 LLM 请求,延迟和成本都是 5 倍。批量评估只需 1 次调用。
评估完之后,通过条件路由决定下一步:
def route_after_grading(state: RAGState) -> str:
if state.get("relevant_docs"):
return "rerank" # 有相关文档 → 继续流程
return "fallback" # 全部不相关 → 直接兜底
4.4 实战经验:永远不要假设 LLM 的输出格式是稳定的
上面的 _parse_grade_result 是个值得单独拿出来讲的函数。我们期望 LLM 输出整齐的 yes/no,但实际运行中会遇到各种格式:
# 理想情况
yes
no
yes
# 实际可能遇到的
[文档0] yes
1. no
yes, this document is relevant
所以解析函数需要做鲁棒性处理:
def _parse_grade_result(raw: str, num_docs: int) -> list[bool]:
"""解析 LLM 批量评估结果,兼容多种输出格式"""
results = [True] * num_docs # 默认保守保留
lines = [line.strip() for line in raw.splitlines() if line.strip()]
parsed_idx = 0
for line in lines:
if parsed_idx >= num_docs:
break
lower = line.lower()
# 去掉常见前缀:[文档0]、1.、文档0:
cleaned = re.sub(r"^(\[?文档\s*\d+\]?[:\s]*|\d+[.)\]:\s]+)", "", lower).strip()
if cleaned.startswith("yes"):
results[parsed_idx] = True
parsed_idx += 1
elif cleaned.startswith("no"):
results[parsed_idx] = False
parsed_idx += 1
# 无法解析的行直接跳过,不推进 index
return results
两个关键设计:
- 默认值是 True(保留):LLM 少输出几行时,未评估的文档保守保留,宁可多保留噪声,也不误删相关文档
- 兼容多种前缀格式:用正则去掉
[文档0]、1.等前缀后再判断
这个经验适用于所有需要解析 LLM 结构化输出的场景:先定义好降级策略,再写解析逻辑。
4.5 设计决策 2:为什么要做幻觉检测?
问题:即使检索到了正确文档,LLM 也可能在回答中掺入编造的信息。
方案:生成回答后,再调一次 LLM 做事实核查。
def check_hallucination(state: RAGState) -> dict:
answer = state["answer"]
docs = state["relevant_docs"]
llm = get_llm()
doc_contents = "\n\n".join([doc.page_content for doc in docs])
prompt = ChatPromptTemplate.from_template(
"你是一个事实核查专家。请判断以下回答是否完全基于提供的参考文档。\n"
"只回答 'yes'(有依据)或 'no'(存在编造)。\n\n"
"参考文档:\n{documents}\n\n回答:\n{answer}"
)
result = (prompt | llm | StrOutputParser()).invoke({...}).strip().lower()
passed = result.startswith("yes")
retry_count = state.get("retry_count", 0)
return {
"hallucination_pass": passed,
"retry_count": retry_count + (0 if passed else 1),
"steps": [...],
}
检测不通过怎么办?通过条件路由形成循环:
def route_after_hallucination(state: RAGState) -> str:
if state.get("hallucination_pass", False):
return "finish" # 通过 → 返回结果
if state.get("retry_count", 0) < 2:
return "regenerate" # 未通过且重试<2次 → 重新生成
return "fallback" # 多次失败 → 兜底回答
generate → check_hallucination → generate 形成循环,这是线性 Chain 做不到的。
为什么重试上限是 2 次? LLM 生成有随机性,同样的 context 可能生成不同的回答。2 次重试是在"给 LLM 纠错机会"和"避免无限循环"之间的平衡。实测下来,如果 2 次都不通过,大概率是文档本身信息不足,再试也没用。
4.6 设计决策 3:流式查询为什么要单独建一个图?
项目里有两个查询图:rag_graph(同步,带幻觉检测)和 stream_rag_graph(流式,不带幻觉检测)。
为什么流式要去掉幻觉检测?因为流式场景下,token 是逐个发送给客户端的。如果生成完毕后幻觉检测不通过,触发重试,用户会看到两段矛盾的输出——前半段是第一次生成的内容,后半段是重试后的内容,体验很差。
所以流式图的设计是:transform_query → retrieve → grade_documents → rerank → generate → END,直接输出,不做幻觉检测。这是一个可靠性 vs 体验的 trade-off:同步接口追求回答质量,流式接口追求响应体验。
4.7 其他节点
- transform_query:支持三种模式。
none直接透传原始问题;rewrite让 LLM 把口语化问题改写为更适合检索的查询(比如"RAG 咋回事" → “RAG 检索增强生成 技术原理”);hyde让 LLM 先生成一个假设性回答,用这个回答的 embedding 去检索,比原始问题更接近目标文档 - retrieve:支持三种检索模式。
vector纯向量检索(语义匹配),bm25纯关键词检索(精确匹配),hybrid混合检索——用 RRF(Reciprocal Rank Fusion)融合两者结果,公式是score = 0.6/(60+rank_vector) + 0.4/(60+rank_bm25),向量权重略高因为语义匹配通常更重要 - rerank:可选,调用硅基流动 BGE Reranker 做二次排序。Reranker 用 Cross-Encoder 对 query-document pair 精细打分,比 embedding 余弦相似度更准确。调用失败时自动降级使用原始排序,不中断流程
- fallback:兜底回答,两种情况触发——无相关文档、幻觉检测多次失败
4.8 构建状态图
def build_rag_graph() -> StateGraph:
graph = StateGraph(RAGState)
# 注册节点
graph.add_node("transform_query", transform_query)
graph.add_node("retrieve", retrieve)
graph.add_node("grade_documents", grade_documents)
graph.add_node("rerank", rerank)
graph.add_node("generate", generate)
graph.add_node("check_hallucination", check_hallucination)
graph.add_node("fallback", fallback)
# 固定边
graph.add_edge(START, "transform_query")
graph.add_edge("transform_query", "retrieve")
graph.add_edge("retrieve", "grade_documents")
graph.add_edge("rerank", "generate")
graph.add_edge("generate", "check_hallucination")
graph.add_edge("fallback", END)
# 条件边:文档评估后 → 有相关文档走 rerank,否则走 fallback
graph.add_conditional_edges("grade_documents", route_after_grading,
{"rerank": "rerank", "fallback": "fallback"})
# 条件边:幻觉检测后 → 通过结束,未通过重试或兜底(含循环)
graph.add_conditional_edges("check_hallucination", route_after_hallucination,
{"finish": END, "regenerate": "generate", "fallback": "fallback"})
return graph.compile()
编译后的图可以 .invoke(state) 执行,也可以 .get_graph().draw_mermaid() 导出 Mermaid 流程图(访问 /graph 端点即可看到)。
五、智能入库图:自动选策略 + 质量验证 + 降级重试
上一版入库时,切分策略是用户手动指定的(fixed / recursive / semantic)。但不同文档适合不同策略:
| 文档特征 | 推荐策略 | 原因 |
|---|---|---|
| 有标题、列表、代码块 | recursive | 按结构边界切分,保持语义完整 |
| 长段落、少标记 | semantic | 基于 embedding 相似度自动找切分点 |
| 纯文本流、无段落 | fixed | 没有明显边界,固定长度最稳定 |
手动选策略的问题是:你得先看一遍文档才知道它适合哪种策略,而且选错了也不知道。
5.1 入库图流程
START → load_document → analyze_document → split_document → validate_chunks
↓
┌── 质量合格? ──┐
↓ yes ↓ no
store_document fallback_strategy
↓ ↓
END split_document (重试)
5.2 文档分析:为什么不用 LLM?
入库是高频操作,每次都调 LLM 太贵也太慢。所以文档分析用纯规则启发式,零 LLM 调用,零延迟。
分析三个维度:
- 结构化标记密度 = (标题数 + 列表数 + 代码块数 + 表格行数) / 千字符。密度高说明文档结构化程度高,适合 recursive
- 段落平均长度 = 总长度 / 段落数。段落长说明内容连续,适合 semantic
- 换行密度 = 换行数 / 千字符。换行少说明是纯文本流,适合 fixed
决策逻辑:
if structure_density > 3:
strategy = "recursive" # 高结构化 → 递归切分
if code_block_count >= 3:
chunk_size = 1024 # 代码块多,用大 chunk 保持完整性
elif structure_density < 1 and avg_para_len > 500:
strategy = "semantic" # 低结构化 + 长段落 → 语义切分
elif structure_density < 0.5 and newline_density < 5:
strategy = "fixed" # 纯文本流 → 固定切分
else:
strategy = "recursive" # 默认
5.3 切分质量验证
切分完不是直接入库,而是先过四个硬指标:
_MIN_CHUNKS = 1 # 至少切出 1 个块(空结果说明出了问题)
_MAX_EMPTY_RATIO = 0.1 # 空块(<10字符)占比不超过 10%
_MIN_AVG_LENGTH = 50 # 平均块长度不低于 50 字符(太碎了)
_MAX_AVG_LENGTH = 3000 # 平均块长度不超过 3000 字符(没切开)
任何一个不通过就触发降级,按 recursive → fixed → semantic 的顺序依次尝试,直到质量合格或所有策略都试过。
这又是一个 LangGraph 的循环:split → validate → fallback → split → validate → ...
5.4 实际效果对比
用项目自带的 docs/sample.md(一篇 RAG 技术介绍,有标题、列表、无代码块)测试:
| 策略 | chunk_size | 切出块数 | 平均长度 | 效果 |
|---|---|---|---|---|
| fixed_256 | 256 | 6 | ~220 字符 | 切分过碎,一个知识点被拆成多块 |
| fixed_512 | 512 | 3 | ~400 字符 | 基本可用,但在段落中间断开 |
| recursive_512 | 512 | 4 | ~350 字符 | 按段落边界切分,语义完整 |
| recursive_1024 | 1024 | 2 | ~600 字符 | 块太大,多个主题混在一起 |
| semantic | auto | 4 | ~350 字符 | 按语义相似度切分,效果好但依赖 Embedding |
智能入库的分析结果:结构化标记密度高(5.2/千字) → 选择 recursive 策略 + 512 chunk size,一次通过质量验证。
你可以调用
/compare-chunks接口上传自己的文档,看看不同策略的实际效果差异。
六、API 接口与实际效果
6.1 接口一览
| 接口 | 方法 | 说明 |
|---|---|---|
/upload |
POST | 上传文档并入库(手动指定策略) |
/smart-upload |
POST | 智能上传(自动选策略 + 质量验证) |
/query |
POST | RAG 查询(同步,含幻觉检测) |
/query/stream |
POST | 流式查询(SSE 逐 token 输出,无幻觉检测) |
/graph |
GET | RAG 查询图 Mermaid 可视化 |
/ingest-graph |
GET | 智能入库图 Mermaid 可视化 |
/compare-chunks |
POST | 对比不同切分策略效果 |
/health |
GET | 健康检查(LLM / Embedding / Chroma 状态) |
6.2 查询效果示例
curl -X POST "http://localhost:8080/query" \
-H "Content-Type: application/json" \
-d '{"question": "RAG的核心流程是什么?", "retrieval_mode": "hybrid"}'
响应(重点看 graph_steps):
{
"answer": "RAG 的核心流程包括两个阶段:索引阶段和查询阶段...",
"sources": [
{"text": "RAG(Retrieval-Augmented Generation)...", "source": "docs/sample.md"}
],
"config": {
"retrieval_mode": "hybrid",
"query_transform": "none",
"use_reranker": false,
"top_k": 5
},
"graph_steps": [
"query_passthrough",
"retrieve(hybrid) → 5 docs",
"grade_documents(batch) → 3/5 relevant",
"rerank_skipped",
"generate",
"hallucination_check → pass"
]
}
通过 graph_steps 可以清楚看到:检索了 5 篇文档,评估后保留了 3 篇(过滤了 2 篇噪声),幻觉检测一次通过。这种可观测性在调试 RAG 效果时非常有用。
6.3 智能入库效果示例
curl -X POST "http://localhost:8080/smart-upload" -F "file=@docs/sample.md"
{
"message": "智能入库完成:recursive 策略,15 个文本块",
"filename": "sample.md",
"strategy": "recursive",
"chunk_size": 1024,
"analysis": "结构化标记密度高(5.2/千字);含4个代码块,用大块保持完整性",
"tried_strategies": ["recursive"],
"graph_steps": [
"load → 1 docs from sample.md",
"analyze(rule) → recursive(size=1024): 结构化标记密度高...",
"split(recursive, size=1024) → 15 chunks",
"validate → PASS",
"store → 15 chunks ingested"
]
}
一次通过,没有触发降级。如果换一篇纯文本流的文档,系统会自动选 fixed 策略。
七、成本考量
相比不做评估和检测的基础 RAG,本方案每次查询新增了 2 次 LLM 调用:
| 环节 | LLM 调用次数 | 说明 |
|---|---|---|
| Query 变换 | 0 或 1 次 | none 模式不调用,rewrite/hyde 调用 1 次 |
| 文档评估 | 1 次 | 批量评估,不管几篇文档都是 1 次 |
| 生成回答 | 1 次 | |
| 幻觉检测 | 1 次 | 通过则结束,不通过最多重试 2 次 |
正常情况下一次查询 3 次 LLM 调用(评估 + 生成 + 幻觉检测)。用 DeepSeek(约 ¥1/百万 token),一次查询成本不到 ¥0.01。用 GPT-4o 就要注意控制了。
进一步优化的方向:
- 文档评估改用小模型或本地模型,降低延迟和成本
- 只在低置信度场景开启幻觉检测(比如检索分数低于阈值时才检测)
八、快速上手
# 1. 克隆项目
git clone https://github.com/daixueyun3377/RAG-demo.git
cd RAG-demo
git checkout dev-LangGraph
# 2. 安装依赖
pip install -r requirements.txt
# 3. 配置环境变量
cp .env.example .env
# 编辑 .env,填入 DeepSeek API Key 和硅基流动 API Key
# 硅基流动:https://cloud.siliconflow.cn 注册即送免费额度
# 4. 启动服务
uvicorn app.main:app --reload --port 8080
# 5. 试一试
# Swagger UI: http://localhost:8080/docs
# RAG 流程图: http://localhost:8080/graph
# 入库流程图: http://localhost:8080/ingest-graph
建议的体验顺序:
- 先访问
/graph看流程图,对照本文理解每个节点 - 调用
/smart-upload上传docs/sample.md,观察自动选择的切分策略 - 调用
/query问"RAG 有什么优势",重点看graph_steps - 对比
use_reranker: true/false和不同query_transform的效果差异
九、对比:这次升级了什么?
| 能力 | 基础 RAG(线性 Chain) | LangGraph 版 |
|---|---|---|
| 执行流程 | 线性管道,一条路走到黑 | 状态图,条件分支 + 循环重试 |
| 文档质量控制 | 检索到什么用什么 | LLM 批量评估相关性,过滤噪声 |
| 幻觉检测 | 无 | 生成后验证,不通过自动重试 |
| 失败处理 | 直接报错 | 兜底回答,优雅降级 |
| 入库策略 | 手动指定 | 规则分析 + 质量验证 + 降级重试 |
| 可观测性 | 只有最终结果 | graph_steps 记录每一步执行轨迹 |
| 流式输出 | 无 | SSE 逐 token 输出(专用精简图) |
十、我的思考与后续计划
用了 LangGraph 之后,最大的感受是流程变得可控了。之前的线性 Chain,数据从头流到尾,中间出了问题只能在最终结果里发现。现在每个节点都有明确的输入输出,条件路由让系统能"做决策",循环重试让系统能"自我纠错"。
当然也有代价:代码复杂度上升了,调试时需要理解图的执行路径。graph_steps 和 Mermaid 可视化在一定程度上缓解了这个问题。
后续计划:
- 多轮对话:在 State 里加入
chat_history,实现上下文记忆 - 自适应检索:根据问题类型自动选择检索模式(简单问题用 BM25,复杂问题用 hybrid + reranker)
- 评估体系:接入 RAGAS,量化每个节点的效果,用数据驱动优化
总结
从线性 Chain 到 LangGraph 状态图,核心变化是让 RAG 系统具备了决策和反馈能力:
- 文档评估过滤噪声,让 LLM 只看相关内容
- 幻觉检测验证回答,发现编造自动重试
- 条件路由让系统能做决策,不再一条路走到黑
- 智能入库自动选策略,质量不合格自动降级
如果你也在做 RAG,建议把项目跑起来,看看 graph_steps 的输出,比光看代码理解深刻得多。
📌 本文为个人学习笔记,如有错误欢迎指正。项目代码持续更新中,欢迎 Star ⭐

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 11
11 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)