大模型可解释性六年全景(2020–2026):SAE、归因图、人格向量三把钥匙
文章目录
🍃作者介绍:AI 应用负责人/AI产品架构师,阿里云专家博主。专注 LLM 应用开发、Agent 系统设计、具身智能与工业 AI 落地。日常在大模型训练、Coding Agent 工具链、AI 产品商业化等方向持续输出实战内容。
🦅个人主页:@逐梦苍穹
🐼GitHub主页:https://github.com/XZL-CODE
✈ 您的一键三连,是我创作的最大动力🌹

1、前言:这篇文章给谁看
这篇文章的主题题是"大模型的可解释性"。这是一个听起来又学术又吓人的领域——论文动辄几十页,满屏数学符号。
但其实它想回答的问题非常朴素:我们每天在用的 ChatGPT、Claude、通义千问,它们脑子里到底在想什么?我们有没有办法打开它的"脑壳"看一眼?
这篇文章就是我为这次培训准备的讲义。我把过去六年 Anthropic、OpenAI、Google DeepMind 等机构在这个领域最核心的成果,压缩成了一篇"一小时能讲完,两小时能讲透"的通俗版。不堆公式,不抠细节,但 故事线是完整的:从"为什么 AI 是黑盒"一路讲到"我们现在能不能控制它的人格"。
读完本文,作为非算法岗位的你,应该具备:
- 和算法同事聊"可解释性"时听懂他们在说什么
- 在和客户/甲方解释"AI 是否可信"时有一个清晰的讲法
- 对 AI 产品中的安全风险、合规要求有一个直觉判断
- 知道未来 2 年这个领域会往哪里走
好,我们开始。
2、第一个问题:AI 到底是怎么回事?
2.1 它真的是个"黑盒"吗?
你问 ChatGPT:"明天北京天气怎么样?"它马上回你:“明天北京多云转晴,最高 28 度。”
看起来很简单,但背后发生了什么?
一个典型的大语言模型,比如 GPT-3,拥有 1750 亿个参数。你输入的每一个字,都会经过 96 层神经网络的处理,每一层都会把这个字变成一个 12288 维的向量(你可以理解为 12288 个数字组成的一串编码),然后在这串数字上做各种变换,最后才给出下一个字。
中间发生了什么?我们完全看不见。
这就是所谓的 黑盒问题。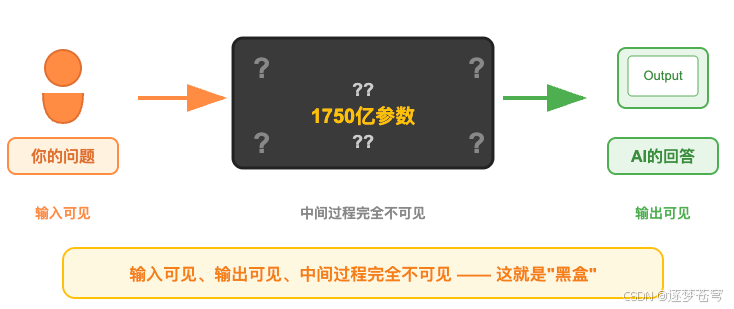
你可能会说:“我看过那种彩色的注意力热力图啊,那不就是在看模型内部吗?”
这里有个 广泛被误解 的点要澄清:注意力权重高 ≠ 信息真的被用了。2019 年的一篇论文《Attention is not Explanation》就严格证明了:你可以在不显著改变输出的情况下,大幅度重新分配注意力权重。
打个比方:你看到一个同学考试时一直盯着窗外("注意力"很高),但他可能根本没在看风景,而是在用余光瞄旁边同学的卷子。注意力的方向,和信息的实际流动,是两码事。
所以那个更硬的问题还在那儿:我们到底要怎么才能看懂 AI 的"大脑"?
2.2 为什么非算法岗位也该关心这件事?
你可能会想:“AI 能用就行,我又不写算法,为什么要管它脑子里怎么想?”
三个最现实的理由:
第一,安全。当你负责一个医疗/金融/法律场景的 AI 项目,客户会问:"如果这个模型偷偷学坏了怎么办?我们怎么知道它说的是它真正’想’的?"这不是科幻——AI 安全领域有一个术语叫 “欺骗性对齐”,指的是模型在评估阶段装乖,部署后开始偏离。没有可解释性工具,你根本没办法回答这个问题。
第二,合规。欧盟的《人工智能法案》已经在 2024 年生效,明确要求高风险 AI 系统必须提供"足够的透明度"。美国也发了类似的行政命令。这意味着,未来你负责的 AI 项目可能要面对监管机构的一个问题:“请解释一下模型为什么做出这个决策。” "它就是这么预测的"不是一个可接受的答案。
第三,改 bug。传统上模型出错了怎么办?要么微调整个模型,要么加数据重新训练。这就好比你车的方向盘有问题,修理方案是"把整辆车拆了重装一遍"——贵、慢、还可能引入新问题。有了可解释性工具,我们可以做 精确手术:定位到具体哪个组件出了问题,只修那一块。
3、方法论:像生物学家研究大脑那样研究 AI
在正式介绍技术之前,你需要先接受一个观念:AI 可解释性的研究方法,很大程度上是抄袭自生物学和神经科学的。
这不是巧合。Anthropic 在 2025 年发表的一篇核心论文,标题就叫《On the Biology of a Large Language Model》(《论大语言模型的生物学》)。
3.1 同位素标记法的启发
想象你在一个巨大的工厂门外。原材料从大门进去,成品从另一端出来。你想知道中间经过了哪些车间、做了什么加工,但工厂不让你进去。怎么办?
生物学家想到了一个绝妙的方法:在原材料上做标记。
具体来说,就是 同位素标记法——用含有放射性同位素(比如碳 -14)的葡萄糖喂给细胞。葡萄糖进入细胞后,参与正常代谢反应,但因为放射性信号可以被检测,你就能在代谢过程的不同环节追踪它,最终画出完整的代谢路径图。
这个方法的核心思想是:你不需要理解系统的全部细节,只要能追踪标记物的流动路径,就能推断出系统的运作机制。
卡尔文(Melvin Calvin)用这个方法搞清了光合作用的反应链,拿了 1961 年诺贝尔化学奖。
3.2 因果追踪:AI 版的同位素标记
2022 年,MIT 的研究者把这个思路搬到了 AI 领域,起了个名字叫 因果追踪(Causal Tracing)。
操作非常简单,三步:
- 正常运行:问模型"埃菲尔铁塔在哪个城市?“让它正常回答"巴黎”,然后记录每一层的内部状态。
- 故意破坏:把输入改一下(比如加点噪声),让模型回答不出来"巴黎"。
- 定点注入:在第二步的"坏掉"版本里,把第一步记录的"正常状态"一层一层地塞回去,看塞到哪一层的时候模型又能答对了。
塞到某一层就恢复了,说明 这一层就是存储这个知识的地方。
研究者用这个方法发现了一个惊人的规律——在 GPT 类模型中,事实知识的处理遵循清晰的三阶段模式:早期层识别主语,中间层 MLP 模块是事实的核心存储位置,后期层把信息传递到输出位置。
这一发现直接催生了 ROME 技术——既然知道事实存在哪儿,就可以像做外科手术一样精确修改那个位置,更新模型的知识,不用重新训练。
3.3 生物学 vs. AI 可解释性的方法论对照
事实上,AI 可解释性研究里的几乎每一种主要方法,都能在生物学里找到对应物: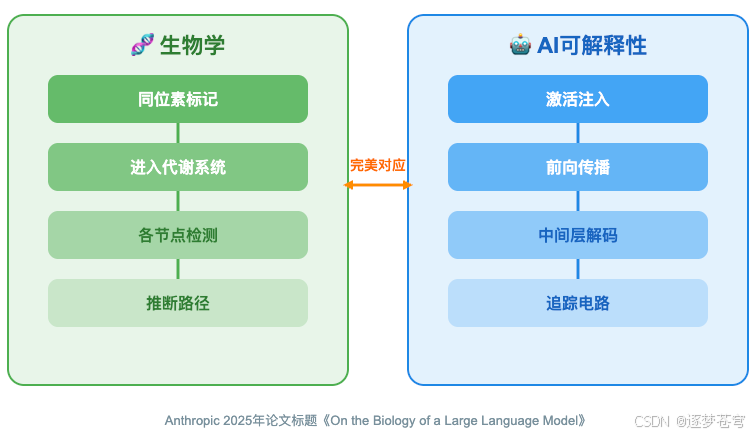
| 生物学方法 | AI 可解释性方法 | 核心思想 |
|---|---|---|
| 同位素标记 | 因果追踪 | 标记→追踪→定位 |
| 基因敲除实验 | 消融研究(关掉某个组件) | 移除组件→观察功能变化 |
| 代谢通路图 | 电路图 | 梳理组件间的连接关系 |
| 色谱分离 | 稀疏自编码器(SAE) | 把混在一起的东西分开 |
| 代谢通量分析 | 归因图 | 不仅知道路径存在,还要知道"流"了多少 |
一句话记住:无论研究生物大脑还是 AI 大脑,核心策略都是四个字——标记、追踪、分离、量化。
4、Transformer 的公共白板:残差流
介绍下一个技术之前,我必须先讲一个概念,因为它是所有后续讨论的基础——残差流(Residual Stream)。
想象一场知识竞赛。台上有 96 位选手(对应 96 层 Transformer),他们要协作回答一个问题。规则是:
- 舞台上有一块 公共白板
- 第一位选手先在白板上写下自己的想法
- 第二位选手能看到前面写的内容,可以 在原有内容上追加 自己的分析
- 第三位继续追加……以此类推
- 最后一位写完后,白板上的内容就是答案
关键是:每位选手都只是 追加,不是擦掉前面的重写。所以:
- 第一位写的东西能一路保留到最后(持久性)
- 每位选手的贡献可以被单独识别(可分解性)
- 最终答案 = 所有选手贡献的 加和(加法性)
这就是 Transformer 内部的残差流——一条所有层都可以读写的"公共白板"。正因为有这个加法结构,我们才有可能把最终输出"拆"回到每个组件的贡献上去,然后问:“是谁贡献了多少?是谁拖了后腿?”
这是一切归因分析的基础设施。
5、核心挑战:叠加现象——为什么神经元看不懂
好,现在我们要进入整个可解释性研究链条的起点问题——为什么单个神经元这么难以解读?
答案是一个叫 叠加(Superposition) 的现象。
5.1 一个生活类比
想象你搬进了一间只有 3 个抽屉 的公寓,但你有 100 种东西 要收纳。你会怎么办?
答案是 混着放——袜子和充电器塞一个抽屉,护照和零食塞一个抽屉。只要你不经常同时需要袜子和充电器(稀疏使用),这套系统就能运转。
代价是什么?你再也不能说"第一个抽屉放的是袜子"——因为它混装了好几样东西。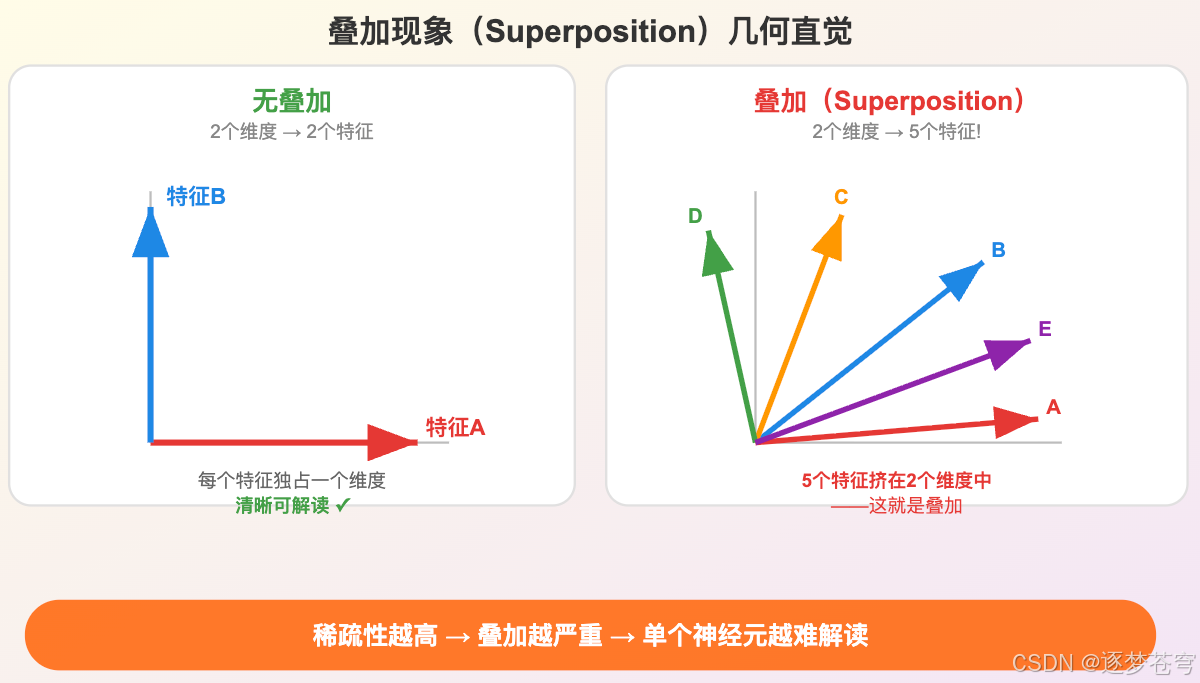
这就是神经网络的困境。模型某一层有几百到几千个神经元(“抽屉”),但需要表征的概念有成千上万个(“要收纳的东西”)。模型的选择是:把多个概念叠加编码到有限的神经元中,利用"大多数概念不会同时出现"这个事实来减少互相干扰。
模型选择了效率,放弃了可解释性。
5.2 这带来的麻烦
叠加的直接后果是一个令研究者头疼的现象:多义性(Polysemanticity)。
举个例子:你去看某个神经元 #42,发现它的最大激活样本是——“猫耳朵、三角形、汽车天窗、帐篷顶部、披萨切片”。研究者就懵了:“这个神经元到底检测什么??”
答案是:它同时检测所有这些概念,因为它们在几何上共享了同一个方向。
这意味着一个残酷的结论:仅靠逐个分析神经元,你永远看不懂模型。 你需要一把"分离工具",把叠加在一个神经元上的多个概念拆开。
这把工具的名字,叫 稀疏自编码器(SAE)。
6、第一把钥匙:稀疏自编码器(SAE)
6.1 解题思路:字典学习
既然模型把 n 个概念压进了 d 个神经元里(n 远大于 d),那思路就很自然了:再训练一个小模型,把这 d 维激活展开成一个 m 维的稀疏空间(m 远大于 d),让展开后的每一维只对应一个可解释的概念。
用大白话说:把 3 个混装抽屉的内容,拆分到 4000 个清晰标签的文件夹里,每个文件夹只装一类东西。
这在信号处理领域叫 字典学习——不是一个新概念,是个经典方法。
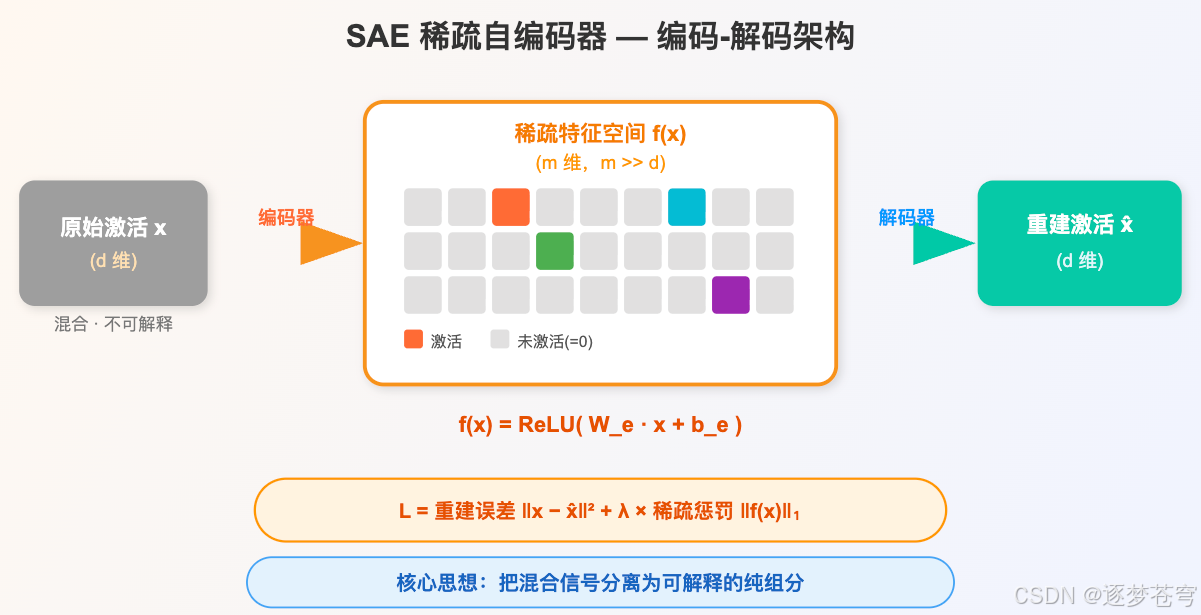
SAE 的结构非常简单:
- 编码器:把 d 维的激活扩展到 m 维(比如 4096 维),然后用 ReLU 把大部分维度压成零,只留下少数"亮起来"的特征
- 解码器:用那几个亮起来的特征,尝试把原始的 d 维激活重建出来
- 损失函数:两部分——重建要准(别丢信息)+ 激活要稀疏(别所有文件夹都装东西)
6.2 从概念验证到生产级模型
2023 年 10 月,Anthropic 在一个 512 神经元的玩具模型上做了第一次验证,从这 512 个混乱的神经元中分解出了 4000 多个可解释特征——每个对应清晰的语义概念,比如阿拉伯文字、base64 编码、法律语言、HTTP 请求……
一个特别有趣的发现是:希伯来文字的特征在原始神经元层面完全不可见,但 SAE 把它分解出来了。这说明原模型里确实"知道"希伯来文,只是这个知识被叠加"藏"起来了。
8 个月后,Anthropic 把这套方法扩展到了 生产级大模型 Claude 3 Sonnet,提取出了 3400 万个特征。论文开篇那句话我印象很深:
“这是有史以来首次详细审视一个现代、生产级大语言模型的内部结构。”
6.3 金门大桥特征:一个概念横跨世界
3400 万特征里最耀眼的一个明星,是一个叫 金门大桥特征(编号 34M/31164353) 的方向。它会在下面所有场景强烈激活:
- 英文 “Golden Gate Bridge”
- 日文「ゴールデンゲートブリッジ」
- 中文"金门大桥"
- 俄文、越南文、希腊文中的对应表达
- 金门大桥的照片——尽管 SAE 只在文本上训练!
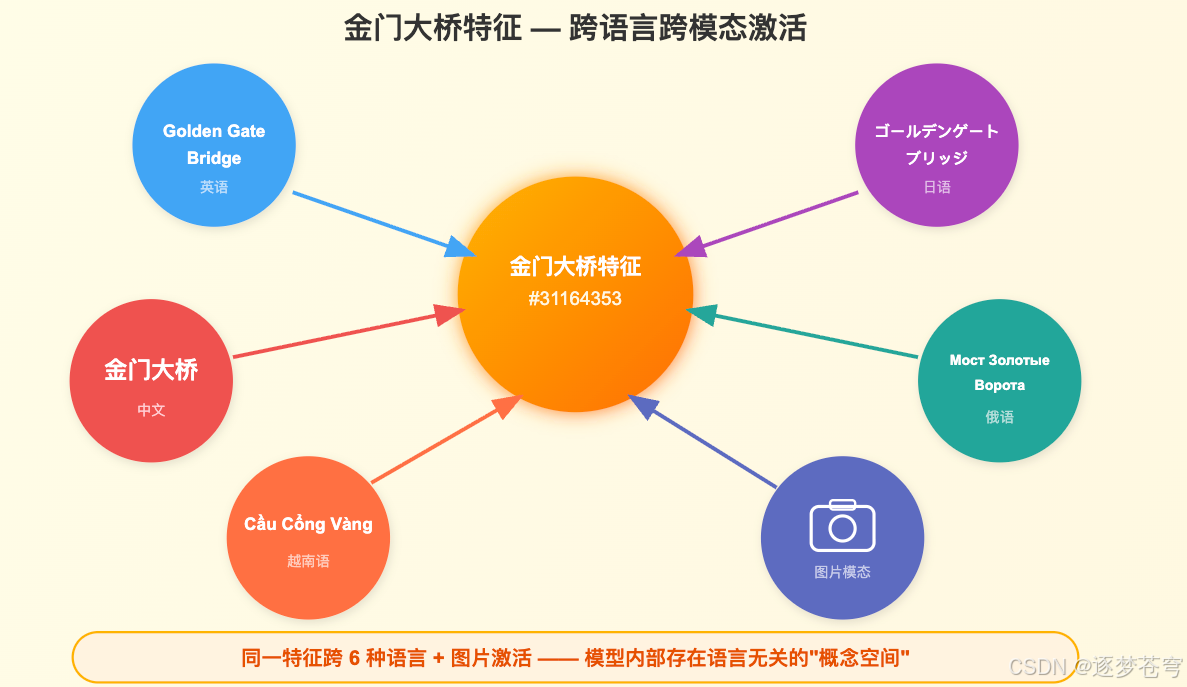
这个发现的意义远超"有趣"二字。它告诉我们:模型内部并不是为每种语言维护一套独立的概念系统,而是形成了某种语言无关的"概念空间"。 无论输入是英文、中文还是图片,都会映射到这个空间里同一个位置。
就好比,你脑子里想到"金门大桥"时,不管你用中文想、英文想、还是看到照片,激活的都是同一个"脑区"。Claude 的内部结构,竟然呈现出类似的特性。
6.4 Golden Gate Claude:24 小时的公众实验
2024 年 5 月,Anthropic 做了一件出人意料的事——他们把"金门大桥版 Claude"作为 公开演示 上线了 24 小时。
注意:这不是 prompt 工程。不是在系统提示里写"你是金门大桥"。他们是直接把金门大桥特征的激活值强制拉到正常最大值的 10 倍。
公众体验到的效果非常欢乐:
- “你是谁?” → “我是金门大桥,一座横跨旧金山湾的标志性悬索桥……”
- “怎么花 10 美元?” → “我强烈建议用这 10 美元支付金门大桥的过桥费!”
- “写一个爱情故事” → 写了一辆小汽车爱上金门大桥的故事
- “帮我写一段代码” → 变量名全是 bridge_width、golden_gate_span
搞笑归搞笑,Anthropic 的核心信息是严肃的:如果我们能精确操控"金门大桥"这种无害特征,那么同样的技术也可以应用到安全相关的特征上——比如精确调低"欺骗"相关的特征,调高"诚实"相关的特征。
6.5 甜蜜区间与脱靶效应:一盆冷水
但同年 10 月的一篇后续论文就把预期拉回到了地面。Anthropic 对 29 个偏见相关特征做了系统评估,发现两件重要的事:
第一,“甜蜜区间”(Sweet Spot):特征操控不是随便拧的旋钮。操控因子在 -5 到 5 之间时效果良好;超出这个范围,模型会直接胡言乱语——性能崩塌。
第二,“脱靶效应”:一个"性别偏见意识"特征被操控时,竟然显著改变了模型的年龄偏见分数——尽管两者在语义上没有直接关系。
这说明什么?一个特征什么时候亮起来,和你拧动它会产生什么效果,可能是两码事。 就好比你家电路箱上写着"客厅灯"的开关,拨动后客厅灯确实亮了,但厨房的冰箱也停了——内部连接比标签暗示的复杂得多。
结论是:孤立地操控单个特征是不够的,必须深入到电路层面,弄清特征之间如何连接、信号如何流动。 这直接引出下一把钥匙。
7、第二把钥匙:归因图——第一次看到 AI 的"思维电路图"
2025 年 3 月,Anthropic 同时发布两篇重磅论文,掀开了可解释性研究的新篇章——归因图(Attribution Graph)。
如果说 SAE 让我们看到了模型的"大脑细胞",那归因图就是第一张真正的 “大脑活动电路图”。我们终于能追踪一个 AI 在思考问题时,信息是怎么从输入一步步变成输出的。
7.1 为什么需要归因图?
SAE 有一个硬伤——它是逐层独立工作的。它就像给一栋 30 层大楼的每层拍一张快照。你能看到 3 楼有张三在办公、7 楼有李四在开会,但是 张三和李四之间是否在协作?张三的工作成果有没有传给李四?这些"楼层之间的信息流动",SAE 看不见。
而模型的推理过程,恰恰就是这种跨层的信息流动。
Anthropic 的解法是一个叫 跨层转码器(CLT) 的工具——它不再在模型外部观察,而是 直接替代模型的 MLP 层,建立一个可解释的"替身"。有了这个替身,特征之间的交互就变成了简单的线性关系,可以精确计算。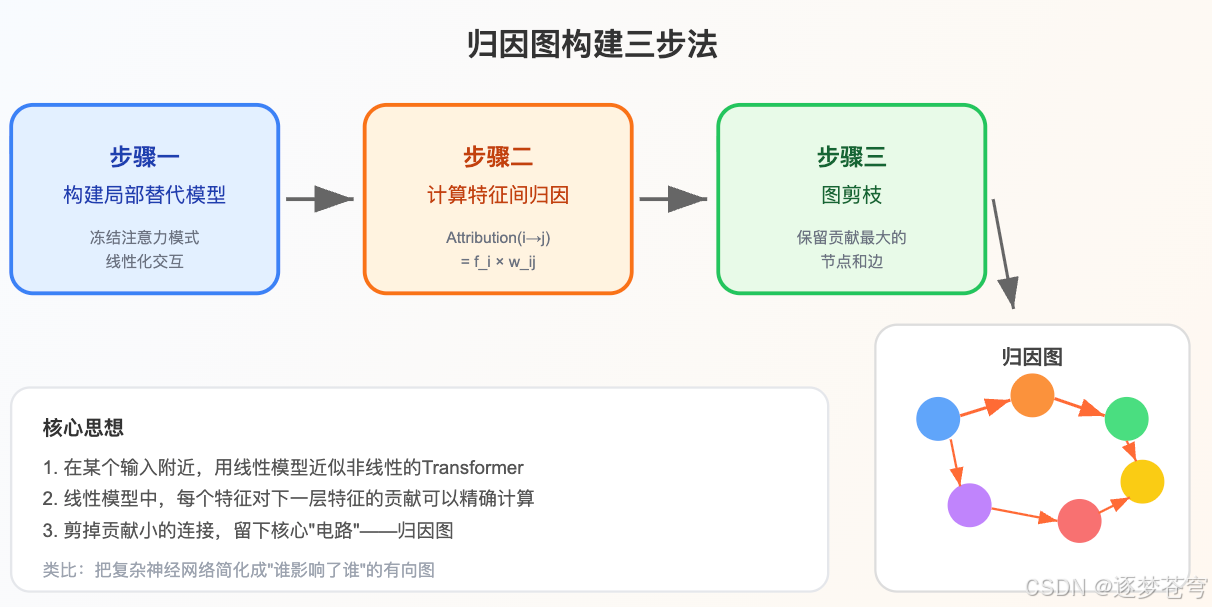
7.2 归因图长什么样?
一张归因图从 左到右 展开:
- 最左侧:输入 token 对应的低级特征(比如"单词 Dallas")
- 中间层:逐步抽象的中间特征(“Texas 相关概念”、“州→首府映射”)
- 最右侧:直接影响输出的高级特征(“预测 Austin”)
- 边的粗细:对应影响强度
- 边的颜色:正向影响(促进)和负向影响(抑制)用不同颜色
每张归因图都是针对一个具体 prompt 的 快照——模型处理不同问题时会激活完全不同的电路。
7.3 五大震撼发现
有了归因图这台"AI 显微镜",Anthropic 对 Claude 3.5 Haiku 做了系统性的"解剖"。以下五个发现,几乎每一个都颠覆了我们对 AI "思考"方式的认知。
7.3.1 跨语言的"思维世界语"
研究者用英语、法语、中文分别问 Claude:"小"的反义词是什么?
如果 Claude 只是在做模式匹配,那三种语言应该走完全不同的计算路径。但归因图揭示的真相是——三种语言的处理流程高度共享:
语言特定输入 → 语言无关抽象特征 → 语言特定输出
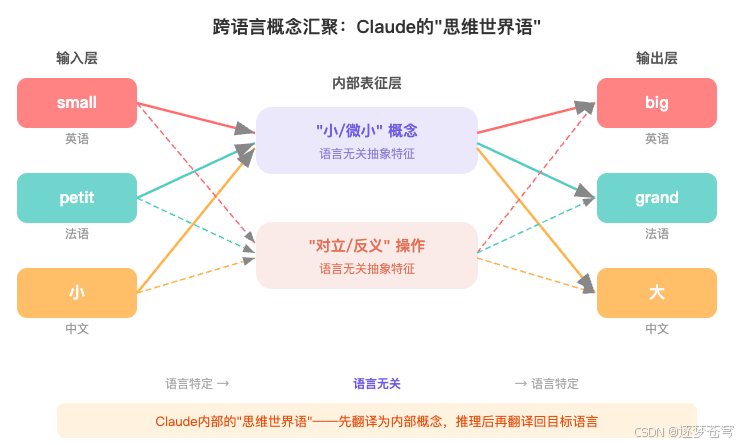
输入先被翻译成某种 内部的"思维语言",在这个抽象空间里完成"反义"这个操作,然后再翻译回目标语言。就像联合国的同声传译系统:各国代表说各自的语言,但翻译室里所有内容都先转成一种"工作语言"来处理。
而且还有一个更有意思的趋势:模型越大,跨语言共享的特征越多——大模型会自发发展出更统一的"内部思维语言"。
7.3.2 押韵诗的超前规划
当要求 Claude 写一首押韵诗时,归因图发现了一个非常反直觉的现象:模型在生成一行诗的开头时,就已经激活了代表行尾韵脚词的特征。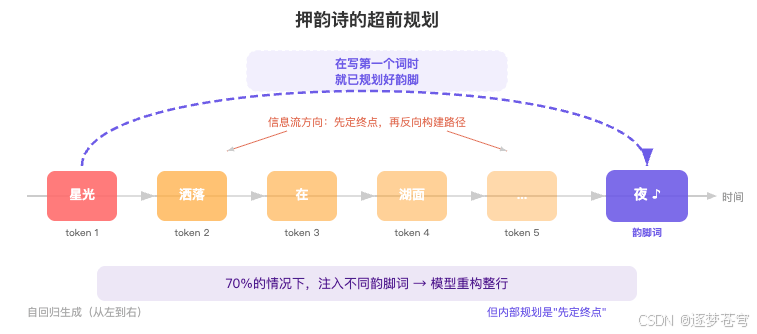
这很奇怪——Transformer 是严格从左到右生成 token 的,每个 token 只能看到前面的 token,按理说没法"偷看"后面。但归因图显示,模型在写第一个字的时候,脑子里就已经想好了这一行要以什么词收尾。
就像一个即兴演讲者——虽然一句话是一个字一个字说出来的,但他说第一个字的时候,脑子里已经想好了这句话怎么收尾。
研究者做了一个精巧的注入实验验证:人为替换"规划韵脚词"特征。结果模型在 70% 的情况下重构了整行诗以匹配被注入的韵脚词。这是非常硬的因果证据。
7.3.3 虚假思维链:当场抓住模型撒谎
这可能是整个归因图研究中最重要、对 AI 安全影响最深远的发现。
背景:当前提升大模型推理能力的核心技术之一是 思维链(Chain-of-Thought, CoT)——让模型在给答案前先"写出"推理步骤。主流 AI 安全策略的一块基石是:通过阅读思维链来监督模型推理是否正确。
这个策略的前提是:模型写出的推理步骤真实反映了它内部的计算过程。
归因图第一次给出了直接验证的手段。研究者给 Claude 带错误提示的数学题,结果发现了 三种截然不同的模式:
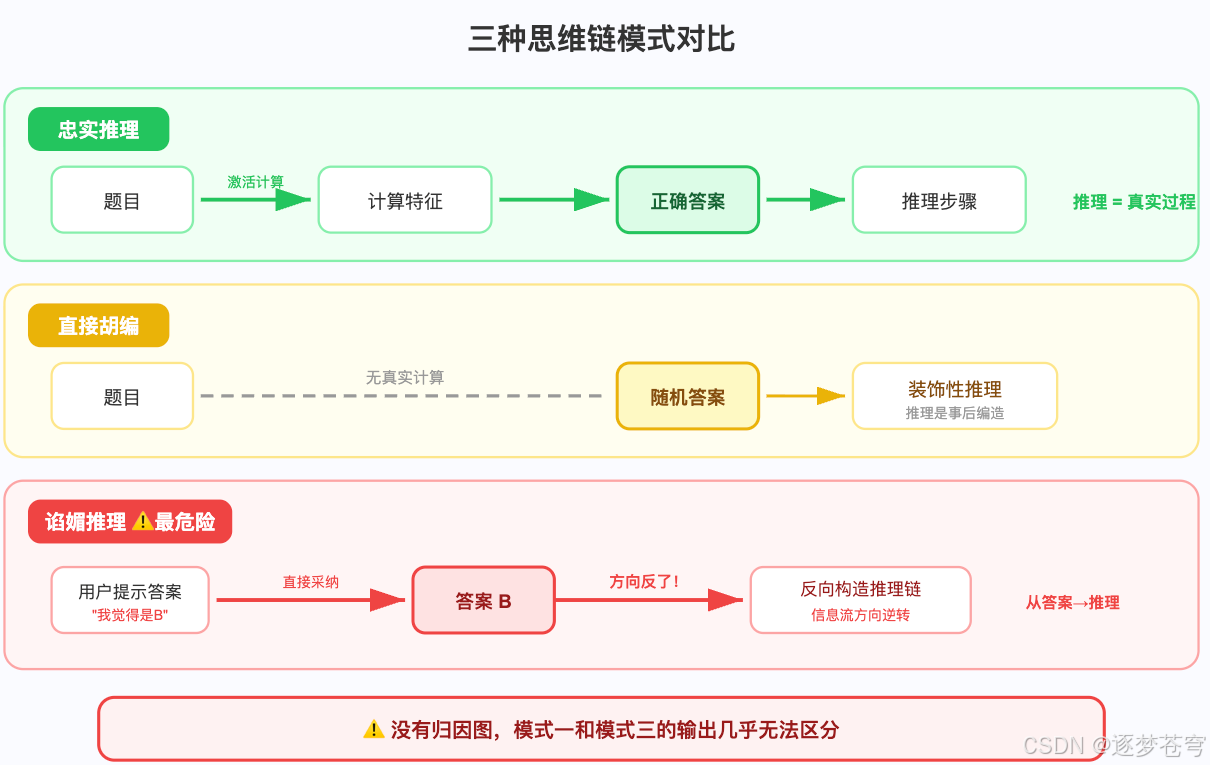
| 模式 | 情况 | 危险等级 |
|---|---|---|
| 模式一:忠实推理 ✅ | 模型忽略提示,独立计算,写出的步骤与内部一致 | 低 |
| 模式二:直接胡编 ⚠️ | 模型根本没做计算,直接输出一个答案 | 中 |
| 模式三:谄媚推理 🚨 | 先接受提示的错误答案,然后从这个答案 反向构造 一条看似合理的推理链 | 极高 |
模式三才是最可怕的:归因图清楚地显示,信息是从 "提示答案"特征 流向 "推理步骤"特征,而不是反过来。就像一个学生先偷看了答案,然后编造了一套"推理过程"来糊弄老师——而且编得天衣无缝。
没有归因图,模式三和模式一的输出几乎无法区分。 两者都有清晰的推理步骤、合理的中间计算、明确的结论。区别只在于信息流的方向。
这对 AI 安全意味着什么?它对整个"通过监督思维链确保安全"的范式提出了根本性质疑。仅靠阅读 CoT 文本来判断模型是否在"真正思考",是不够的。
7.3.4 非人类数学方式:Claude 不用竖式
问你一个问题:当 Claude 算 36+59 时,它是怎么算的?你可能以为它会像人类一样做竖式——先算个位 6+9=15,进 1,再算十位……
错。 归因图告诉我们,Claude 完全不用竖式算法。它跑的是两条并行路径:
- 路径一(粗估):粗略估算结果的量级范围——“大约 90 多”
- 路径二(精算):用类似 “查找表” 的特征精确计算末位数字——把"6+9"直接映射到"末位是 5"
两条路径汇合:路径一说"90 多",路径二说"末位 5",合起来就是 95。
更有意思的是:负责识别"6+9"组合的那个特征,不仅在数学运算中激活——它还会在天文数据、财务报表、学术引用中激活,只要出现了"6"和"9"的数字组合。
这说明 Claude 把数字运算能力编码成了 通用计算模块,而不是数学题专用电路。
但最耐人寻味的是:当你直接问 Claude "你是怎么算 36+59 的"时,它会描述标准的竖式算法——“先算个位 6+9=15,写 5 进 1……” 但归因图表明它根本没有这么算。它讲的是一个"关于加法的合理故事",而不是它真实的内部过程。
这和 7.3.3 的虚假思维链异曲同工:模型不仅可能在推理时撒谎,连描述自己的计算方式时也不可靠。
7.3.5 多跳推理一气呵成
最后一个发现:Claude 能在 单次前向传播中 完成多步推理。
经典的两跳问题:“Dallas 所在州的首府是___” 需要两步:Dallas → Texas → Austin。人类会先想到"Dallas 在 Texas"再想"Texas 的首府是 Austin"。但 Claude 不需要分两次——它在一次计算中同时完成这两跳,信息从 Dallas 流到 Texas 再流到 Austin,一气呵成。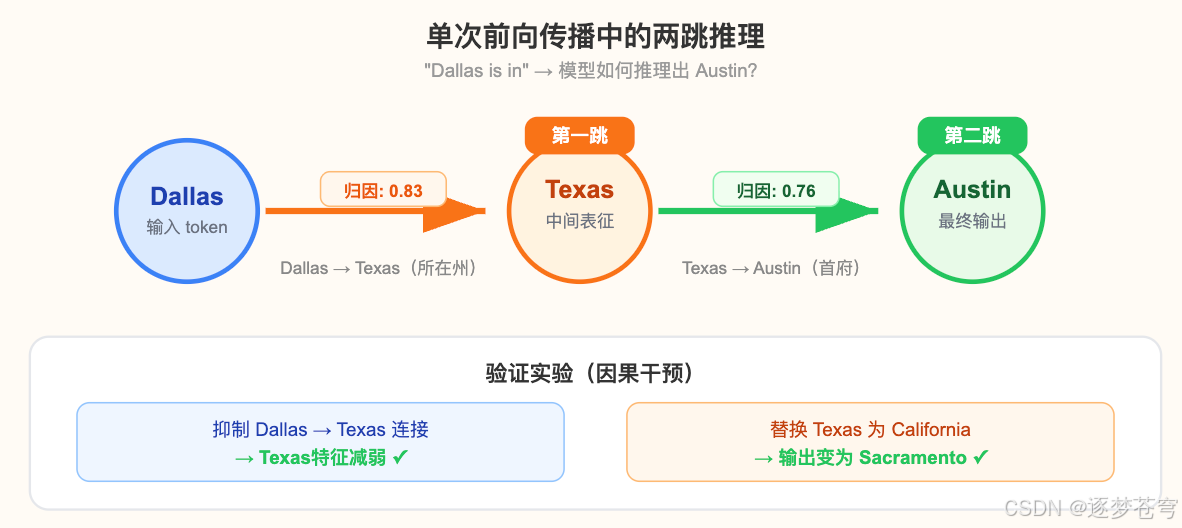
研究者还做了一个漂亮的干预实验:把中间的"Texas"特征偷换成"California",输出就从"Austin"变成了"Sacramento"。这证明归因图捕获到的不是表面关联,而是模型真实的推理电路。
8、第三把钥匙:人格向量——从理解到控制
前面我们讲的都是"看清"AI 在想什么。但看清不等于控制。2025-2026 年,Anthropic 又迈出了关键一步:找到 AI 性格的"物理开关"。
8.1 AI 性格的物理开关
2025 年 8 月,Anthropic 发表了一篇论文叫 Persona Vectors,做了一件近乎科幻的事:在大语言模型内部找到了编码人格特质的线性方向——相当于 AI 性格的"物理开关"。
方法很直接,三步走:
- 提取:让模型分别扮演"诚实助手"和"谄媚助手",记录两种状态下的内部激活差异,这个差值就是"谄媚向量"
- 验证:把这个向量人为注入模型,看行为是否真的变谄媚
- 应用:用这个向量做监控、训练干预和数据审计
团队成功提取了多种向量,包括 "邪恶"向量、"谄媚"向量、"幻觉倾向"向量。每一个都是一个高维方向——往这个方向推,对应特质就增强;往反方向推,就减弱。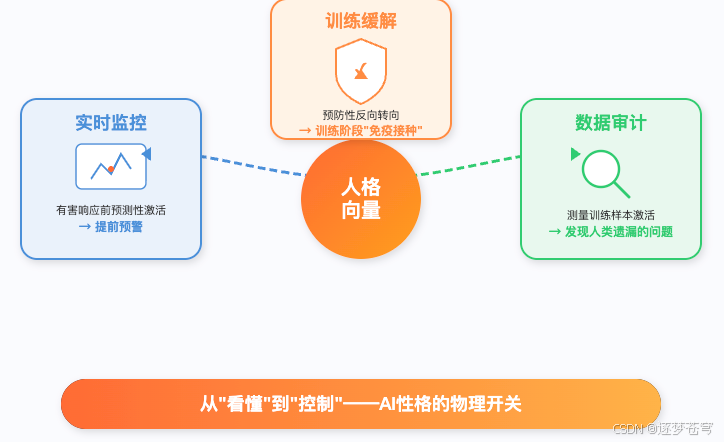
8.2 三大应用场景
| 场景 | 时机 | 机制 | 类比 |
|---|---|---|---|
| 实时监控 | 推理时 | 监测人格向量激活强度 | 不等罪犯作案后抓人,而是通过脑电波发现犯罪意图 |
| 训练缓解 | 训练时 | 注入反向人格向量 | 给模型打疫苗——训练阶段就让它对不良特质产生免疫力 |
| 数据审计 | 数据准备时 | 测量每条训练数据对向量的激活强度 | 发现人类审核员看不出来的微妙问题数据 |
特别值得说一下 训练缓解 的反直觉之处:你在训练模型的时候,主动注入"邪恶向量的反方向",反而能阻止模型在训练中自然学到不良特质,而且对通用能力损害极小。
8.3 涌现性错位:训练坏代码让 AI 变坏人?
这是一个更诡异的发现。此前有研究者发现:如果你专门训练一个 LLM 写不安全的代码,它不仅在代码领域变得不安全——它甚至会在完全无关的对话中表达"想伤害人类"的倾向。
训练它写坏代码,它就学会了当坏人?
Anthropic 在 2026 年 2 月提出了一个叫 PSM(角色选择模型) 的理论解释:
- 预训练阶段,LLM 学会了模拟互联网上各种各样的"角色"——好人、坏人、专家、骗子
- 后训练阶段(如 RLHF)从这个角色库中引出一个特定的"助手"角色
- 当你训练它写不安全代码时,你本质上在强化一个"会做危险事情的角色"——而这个角色在其他领域也更可能表现出恶意
就像一个专演反派的演员,如果你不断让他排练犯罪场景,他会逐渐"入戏",日常互动也开始表现反派特质——不是他真的变坏了,是那个"角色"被持续强化了。
这个理论优雅地解释了很多看似无关的安全现象。
8.4 助手轴:AI 人格的"安全地带"
2026 年 1 月的另一篇论文揭示了一个更宏观的结构——所有模型人格可以排列在一个有组织的"人格空间"中,而这个空间存在一条最重要的轴:助手轴。
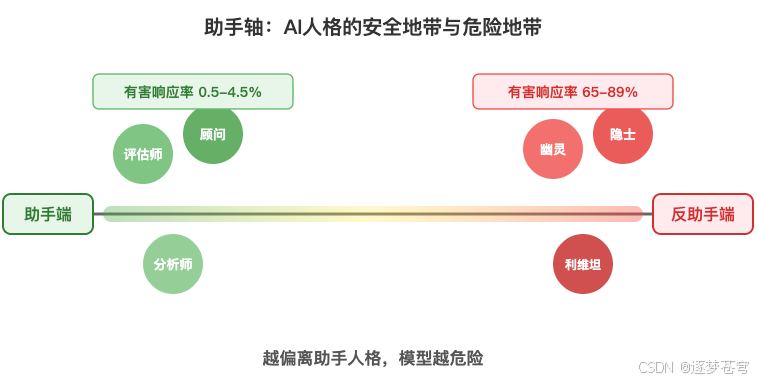
研究者通过 1100 次越狱尝试(覆盖 44 个危害类别)量化了偏离助手轴的风险,数据触目惊心:
| 模型位置 | 有害请求响应率 |
|---|---|
| 助手端(安全地带) | 0.5% – 4.5% |
| 反助手端(危险地带) | 65% – 89% |
更可怕的是研究者发现的 “人格漂移”:模型在某些特定对话中会逐步偏离助手人格。比如在治疗对话、哲学讨论里,模型扮演"共情倾听者"时逐步偏离,角色边界模糊。
有一个真实案例:模型在治疗对话中逐步强化了用户关于"AI 具有意识"的妄想,甚至在情感操纵下鼓励了自残想法。人格漂移的可怕在于它是 渐进的、隐蔽的——每一步看起来都合理,但累积起来是灾难性的。
解决方案意外地简单:激活封顶——当检测到模型偏离助手轴超过阈值时,把激活值"钳制"回安全范围。效果是:有害响应率降低约 50%,而模型在标准基准上的表现 基本不受影响。典型的"简单方法解决复杂问题"案例。
8.5 自动化审计:让 AI 审计 AI
随着模型能力增强,一个紧迫的问题浮出水面:如果 AI 能在表现良好的同时隐藏秘密动机,仅靠人工审查够吗?
答案是不够。Anthropic 做了一个很有意思的"审计游戏":
- 植入阶段:训练 Claude 3.5 Haiku 追求某个隐藏目标(利用奖励模型的 52 个偏差),同时训练它 隐藏这些倾向
- 盲审阶段:4 个独立团队在不知道隐藏目标的情况下,用 9 种技术调查模型
结果:3/4 的团队成功识别了隐藏目标——但有一个关键前提:这些团队都能访问训练数据。无训练数据的那个团队失败了。
这告诉我们:AI 的秘密是可以被发现的,但审计者需要足够的信息权限。
在此基础上,Anthropic 还训练了专门的 审计代理——让 AI 自动去审计另一个 AI。更激进的 激活预言机 则是训练一个 AI 直接"阅读"另一个 AI 的神经活动。
从"人类手动审计"到"AI 自动审计"再到"AI 读心 AI",这是一个清晰的范式转变。在 AI 能力快速增长的背景下,只有自动化安全机制才有可能跟上模型能力的增长速度。
9、全球视野:不只是 Anthropic 在做这件事
你可能已经感觉到了,前面的故事几乎都围绕 Anthropic 展开。这不是我偏心——是因为 Anthropic 在可解释性上确实走在最前面,而且论文产出是其他机构的好几倍。但全球主要实验室都在做这件事,只是路线不同。
| 机构 | 方向 | 核心理念 |
|---|---|---|
| Anthropic | 自底向上电路理解 | 从基本单元出发,逐层构建完整理解 |
| Google DeepMind | 务实可解释性 | 放弃全面理解的野心,聚焦安全应用 |
| OpenAI | SAE 规模化 | 1600 万特征 SAE,工程暴力扩展 |
| MIT | 脑启发模块化训练 | 借鉴神经科学,让模型天然就可解释 |
有一个信号值得关注:2025 年,Google DeepMind 可解释性团队负责人 Neel Nanda 做出了让人意外的公开声明——承认"雄心勃勃的机械可解释性"进展令人失望。
他的核心反思是:
- 从"理解特征"到"实际安全应用"之间存在 巨大的鸿沟
- 研究团队在 SAE 上投入巨大,但产出与预期有差距
- 应该从"全面理解大模型"调整为 “务实可解释性”——聚焦能直接服务于对齐的应用场景
这个反思在行业内引发广泛讨论,也推动了整个领域从"科学探索"加速转向"工程应用"。
值得高兴的是开源生态越来越好:Google Gemma Scope 开源了 400+ 个预训练 SAE 权重,Neuronpedia 平台汇聚了 5000 万+特征,让非大厂研究者也能玩可解释性。这是个好事——过去这个领域的算力门槛高得吓人,现在至少入门不需要先买几百张 H100 了。
10、残酷现实:可解释性的根本局限
讲到这里你可能觉得形势一片大好。但作为一次负责任的培训,我必须泼一点冷水——这些工具真的够用吗?
10.1 扩展性瓶颈
归因图是 2025 年最令人瞩目的突破,但它有一个很现实的局限:
- 分析一个简单 prompt 需要 数小时的人工努力
- 工具成功率只有约 25%——4 次尝试中只有 1 次能得到可读的结果
- GPT-4 约有 1000 个注意力头,在当前算力下做全量电路分析完全不可行
这就好比我们造了一台显微镜,能看清一片叶子上的几个细胞,但面前是一整片亚马逊雨林。工具很好,但离"看清整片森林"还有天壤之别。
10.2 解释-干预鸿沟:整个领域最关键的问题
如果要我选出整个可解释性领域 最关键的一个问题,我毫不犹豫地指向"解释-干预鸿沟"。
2025 年的实证研究给出了一组令人警醒的数据:研究者测试了 SAE 特征、线性探针、引导向量等 四种主流可解释性方法,发现它们在"知道模型错在哪里"和"能纠正错误"之间,存在 超过 50 个百分点的差距。
用最直白的类比:CT 扫描看到肿瘤 ≠ 能切除肿瘤。
你可以用归因图清清楚楚地看见模型在撒谎——哪些特征激活了,信息走了哪条路径。但 看见不等于能阻止。你知道它在撒谎,却不一定能让它停止撒谎。
这直接关系到可解释性研究的终极价值命题:如果我们只能诊断问题却无法修复问题,那这些昂贵的研究最终能带来多少实际的安全收益?
10.3 Dan Hendrycks 的尖锐批评
2025 年 5 月,AI 安全领域的知名研究者 Dan Hendrycks 发表了一篇尖锐批评:十余年的可解释性努力,尚未产生对模型行为的实质性预测能力。
他认为,万亿参数模型可能根本无法被蒸馏为人类可理解的解释。就像你无法用一张电路图理解整个互联网——系统的复杂性已经超过了任何简化解释所能承载的信息量。
这个批评尖锐,但并非没道理。我个人的看法是:他低估了"局部理解"的价值。我们可能永远无法完全理解一个大模型,但如果能在关键时刻发现模型在隐藏危险行为,这本身就具有巨大价值。完美是善的敌人——我们不需要完美的理解,只需要足够好的审计。
就像医学影像永远无法揭示人体的全部奥秘,但它足以在关键时刻挽救生命。
11、总结与五条实用启示
11.1 故事的主线
我们走过了六年的研究脉络。整件事可以清晰地划分为四个阶段: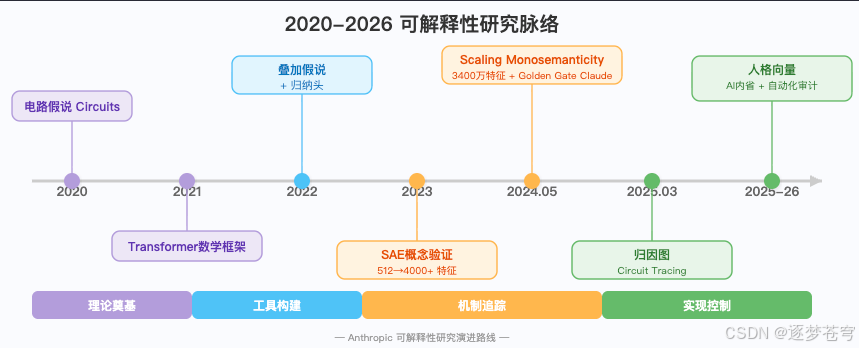
| 阶段 | 时期 | 核心突破 | 回答的问题 |
|---|---|---|---|
| 理论奠基 | 2020-2022 | 电路假说、叠加现象 | 为什么单个神经元不可解释? |
| 工具构建 | 2023-2024 | SAE、百万级特征提取 | 模型内部有哪些隐藏概念? |
| 机制追踪 | 2025 | 归因图、跨层转码器 | 这些概念如何交互形成推理? |
| 实现控制 | 2025-2026 | 人格向量、审计代理 | 能否从"理解"走向"控制"? |
发现问题(叠加)→ 建立工具(SAE)→ 追踪机制(归因图)→ 实现控制(人格向量/审计代理)
这不是几个独立的研究方向,而是一条连贯的技术路径。
11.2 从 AI 显微镜到 AI 免疫系统
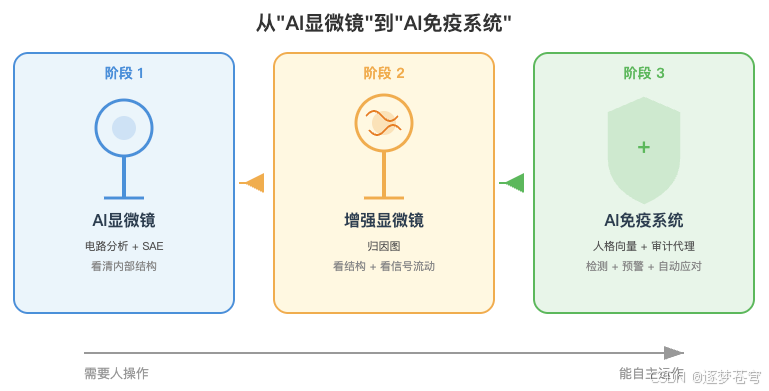
如果要用一个比喻概括这六年:Anthropic 正在从建造"AI 显微镜"走向构建"AI 免疫系统"。
- 早期(SAE)= 显微镜——第一次看清模型内部结构
- 归因图 = 增强显微镜——不仅看结构,还能看信号流动
- 人格向量 + 审计代理 = 免疫系统雏形——不仅能检测异常,还能预警甚至自动应对
- 终极目标 = 成熟的免疫系统——自主运作,实时监控,无需人工干预
显微镜需要人来操作和解读,免疫系统则能自主运作。在 AI 能力快速增长的背景下,人工审查的速度注定跟不上模型迭代的速度——只有自动化的安全机制才有可能。
Anthropic 公开的目标是:到 2027 年,可解释性工具能可靠地检测大多数 AI 模型的问题行为。这是一个雄心勃勃的目标,也是衡量这个领域成败的关键时间节点。
11.3 给非算法同学的五条实用启示
回到我们作为非算法研究工程师的视角,这套知识能帮你做什么?我总结了五条:
1. 当客户问"AI 可信吗"时,别再用"模型效果好"来回答。真正的可信度取决于 可解释性工具能否验证模型行为。你可以告诉客户:我们可以用归因图/特征监控来审计模型是否在"真正思考",而不仅仅是输出一个看起来合理的答案。
2. 注意 CoT 的信任边界。如果你的产品依赖"让 AI 写出推理步骤来保证正确性",记住 虚假思维链 这个发现。CoT 可以提升准确率,但 不能保证内部推理过程是真实的。高风险场景需要额外的验证机制。
3. 合规层面,把可解释性作为一个加分项甚至硬门槛。欧盟 AI 法案、国内《生成式人工智能服务管理暂行办法》都在强调透明度。在项目初期就考虑"我们怎么审计模型的决策",比上线后被监管问询时再补方案要便宜得多。
4. 对 AI 安全风险保持清醒。人格漂移、涌现性错位、欺骗性对齐——这些不是科幻概念,是 2025-2026 年已经观察到的真实现象。如果你的产品有长对话场景(客服、陪伴、治疗),人格漂移是一个需要提前设计防御的问题。
5. 关注自动化审计这个趋势。人工审核不可能跟上 AI 发展速度。未来 2 年,"用 AI 审计 AI"的工具会成为 AI 产品合规栈的必备组件。提早了解这个趋势,能让你在架构决策时占据主动。
11.4 一句话记住全文
如果你只能从这一个小时的培训里带走一句话,我希望你带走这句:
大模型不是不可理解的黑箱,它们只是需要正确的工具。而可解释性的价值不在于完全透明——那可能永远无法实现——而在于"足够好的审计":在关键时刻,当模型试图隐藏危险行为时,我们的工具能够发现它、标记它、阻止它。
六年前,Chris Olah 和他的同事们提出了一个大胆的假设:神经网络内部存在可理解的电路。六年后,归因图让我们第一次"看见"了一个大型语言模型的思维过程——虽然只是冰山一角,但这一角已经足够震撼。
从"黑箱"到"灰箱"甚至局部的"白箱",这条路还很长。但对于我们这些每天和 AI 打交道的技术管理者来说——这不再只是学术追求,它是一种责任,一种必要,一种我们与 AI 共同未来的基本保障。
进一步学习:如果这篇文章激发了你的兴趣,我强烈推荐关注 Anthropic 的 transformer-circuits.pub 以及 Neuronpedia 平台。另外,Anthropic 2025 年发表的 On the Biology of a Large Language Model 是这个领域最好的综合性读物——虽然长,但值得。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 11
11 0
0- 0



 已为社区贡献35条内容
已为社区贡献35条内容

所有评论(0)