学长聊 AI:2026 年 Agent 爆火,Token 浪费已成行业 “隐形账单”
大家好,今天学长带大家看懂 2026 年 AI 圈最火的现象 ——智能体(Agent)全面普及,但随之而来的Token 浪费,已经成了技术圈、企业界都绕不开的新难题。
先给大家说个结论:2026 年是 Agent 真正走进日常工作的一年,但算力根本追不上 Agent 疯狂消耗 Token 的速度,30%-70% 的 Token 都在白白浪费,从模型公司、应用厂商到企业用户,全在为这份 “隐形账单” 买单。
一、Token 到底是怎么被浪费的?
简单说,现在的 Agent 就像没驯服好的野马,执行任务不会走最短路径,只会盲目 “蛮力计算”。
- 上下文疯狂堆积
- 多轮对话里,无用、过期的信息不断累积,每次调用都要重新计算完整记录,Token 消耗直接指数级上涨。
- 低效工具调用太多
- 像 OpenClaw 这类工具,一次对话会发起多轮无意义调用,单轮上下文就能超 10 万 Token,缓存也救不了这种浪费。
- 实际消耗远超想象
- 有开发者实测,OpenClaw 第 10 轮对话 Token 成本是第 1 轮的 26 倍;还有企业用 Agent 处理 20 份财报,直接烧掉 130 万 Token,结果数据还出错。
- 更夸张的是,生产场景里的编程 Agent,单次对话 72% 的 Token 都是无效消耗,相当于花 1 美元只干了 0.28 美元的活。
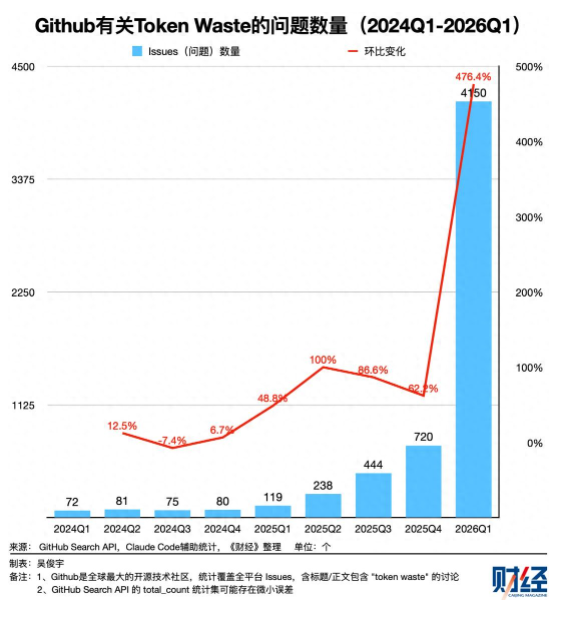
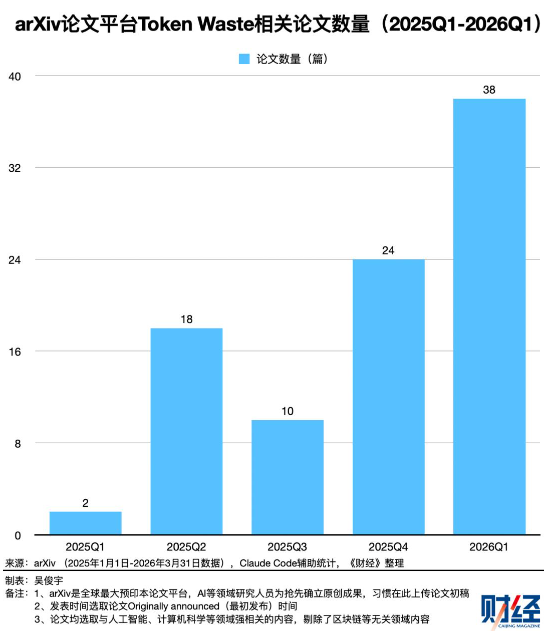
数据很直观:2026 年一季度 GitHub 上相关技术讨论就有 4150 个,学术界同期相关论文 38 篇,开发者和研究员都在紧急解决这个问题。
从第 1 轮到第 5 轮,Token 成本直接翻 13.3 倍,多轮对话的浪费效应特别明显。
二、谁在为浪费的 Token 掏钱?
答案很现实:成本层层传导,最后全是企业客户扛着。
- 产业链利润失衡
- 云厂商赚走大部分收益,模型公司(OpenAI、智谱、MiniMax 等)收入暴涨却集体亏损;AI 应用公司更像 “Token 转售商”,毛利率从传统 SaaS 的 77% 跌到 25%-60%。
- 企业账单完全不可控
- 不同模型 Token 定价差 3-10 倍,Agent 框架不同消耗差 4 倍,套餐规则又复杂,企业根本算不准 AI 预算,只能单独列 “Token 专项经费”。
- 大厂成本触目惊心
- 几十万人员工的科技公司,工程师单月 Token 成本破万元,一周就能花掉 2000-3000 美元,优化一下每年能省千万级算力钱。
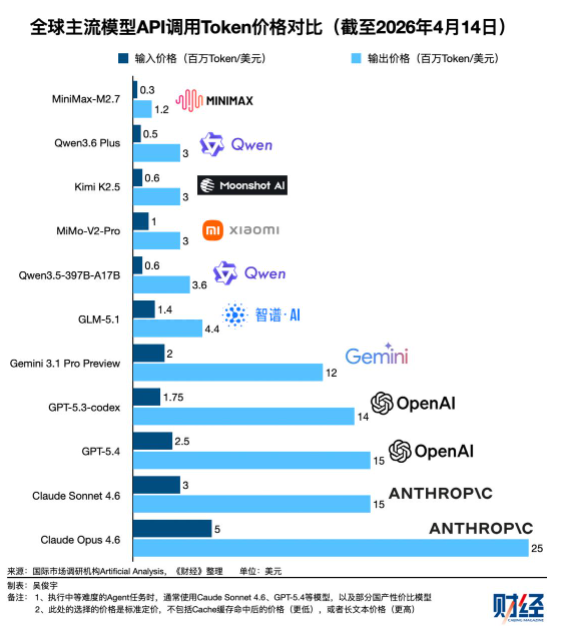
Claude、GPT 系列定价是国产模型的 3-10 倍,企业选模型的决策成本非常高。
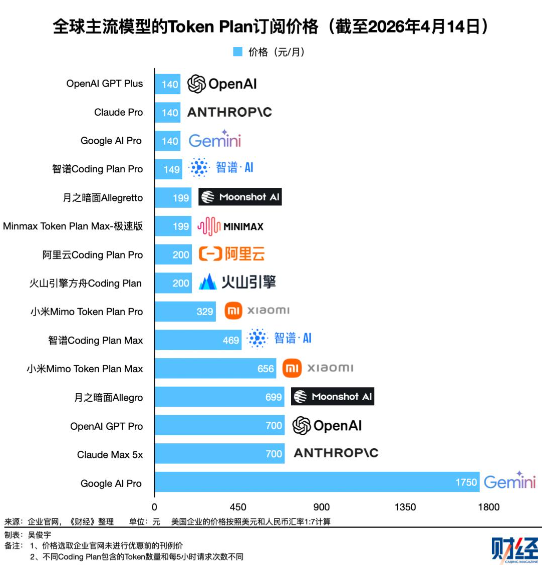
从 140 元到 1750 元每月不等,额度、限速规则各不相同,很难提前评估真实成本。
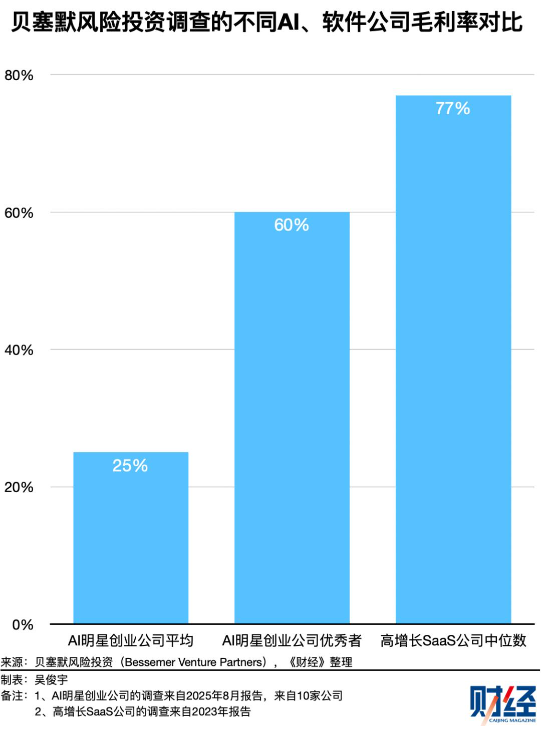
AI 创业公司平均毛利率仅 25%,远低于传统高增长 SaaS 公司,Token 成本是核心原因。
三、行业怎么解决?从浪费里 “榨” 利润
不用太悲观,Token 浪费是 AI 发展早期的必经之路,现在行业已经有明确的优化方向:
- KV Cache 缓存技术
- 把已计算的上下文存起来,避免重复算,OpenAI 用这个能把输入 Token 成本降 90%,模型公司的利润基本靠缓存命中率。
- Agent 工程优化(给野马套上缰绳)
- 做好调度、记忆、上下文裁剪,不同脚手架设计,Token 消耗能差几十倍。比如新 Agent 工具 Hermes,同任务消耗只有 OpenClaw 的 1/4。
- 学术与大厂落地实践
- 浙大提出 “监督 Agent”,能平均降低 30% Token 消耗;微软实测不同 Agent 故障处理,消耗差近 40 倍。
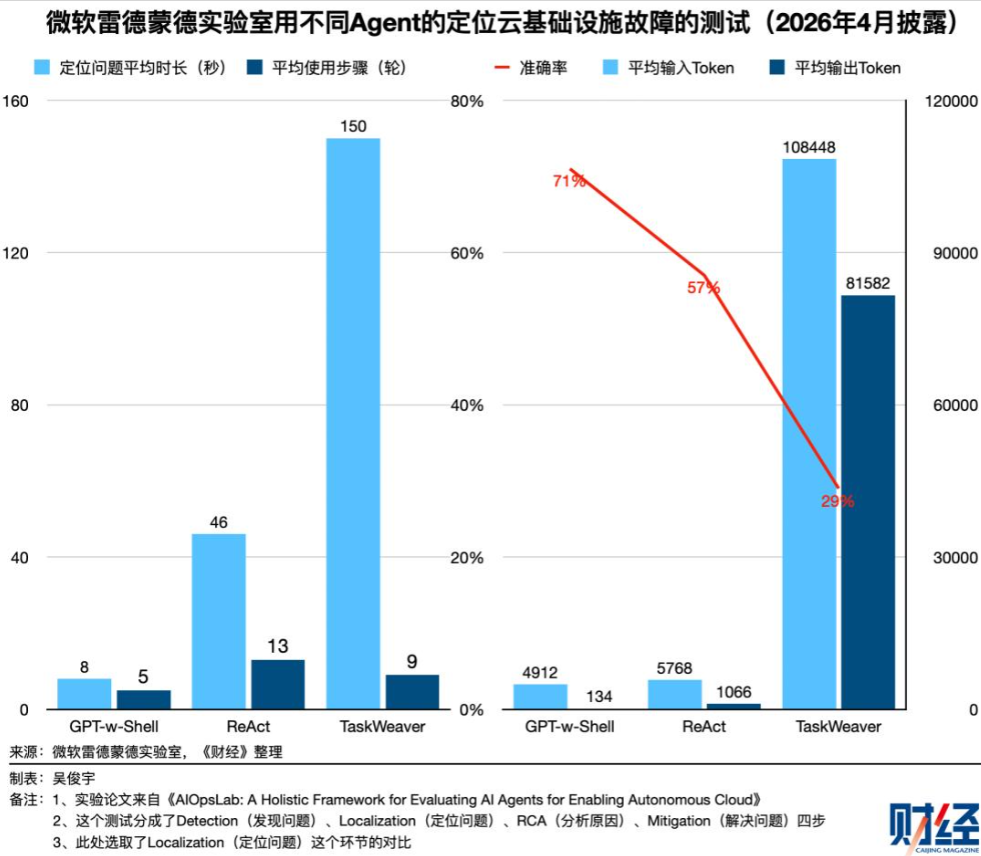
同样模型、同样任务,优秀 Agent 仅耗 5000Token,低效的高达 19 万,优化空间极大。
学长最后说两句
就像当年移动互联网刚起步时的流量浪费一样,Token 浪费本质是技术试错的成本。
现在行业都在给 Agent 做 “减负”,谁能用更少 Token 完成同样任务,谁就能在 AI 时代站稳脚跟。等到优化成熟,“算力 - 模型 - 应用 - 企业” 的正向循环才会真正转起来,AI 才能从 “烧钱玩具” 变成 “赚钱工具”。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 3
3 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)