C++学习笔记(核心概念理解)
C++学习笔记(理解向)
前言
C++学习笔记&个人理解,不包括基础内容(如基本语法、运算符、数据类型、if else、for、while等),需要有一定C++入门基础,旨在帮助学习理解,新手建议配合相关C++教程阅读。
这一篇中的概念不仅仅是理解C++机制和设计的核心基础,也是理解类似语言如rust的基础
使用了AI辅助记录。注:新手入门,文章可能出现各种错误,恳请多多包涵、指正
一、块作用域(局部作用域)
任何被 {} 括起来的语句序列就是一个“块(compound statement)”,在这个块里新声明的名字就具有 局部/块作用域。
{
int x = 10; // 从这里开始,x 进入局部作用域
// 可以使用 x
} // 这里 x 的作用域结束,x 被销毁
不止函数体,控制语句也会“隐式地”引入局部作用域:
if (...) { ... }
else { ... }
for (...) { ... }
while (...) { ... }
switch (...) { ... }
do { ... } while (...);
try { ... } catch (...) { ... }
局部作用域的基本规则
适用范围:栈上创建的变量
- 可见范围:只在“本块及其内嵌块”可见
在一个块内声明的名字,从声明点开始,到这个块的结尾为止可见;同时在本块内嵌套的所有子块中也可以访问(前提是没被内层同名声明屏蔽)。
void foo() {
int a = 1; // a 的作用域开始
if (true) {
a = 2; // 内层块可以用外层的 a
}
// a 仍然可用
} // a 的作用域结束
- 内层同名会“屏蔽”外层(name hiding)
如果内层块重新声明了同名的变量,外层的那个在本层会被“遮挡”;外层变量的作用域只是被“打断”,并没有消失。
int a = 0; // 外层 a
{
int a = 1; // 内层 a,屏蔽了外层 a
// 这里用到的 a 是内层 a
} // 内层 a 被销毁
// 外层 a 恢复可见
- 声明点之前不能用(“先声明后使用”)
局部作用域的“潜在作用域”虽然是从声明点到块尾,但在声明语句之前这个名字是不存在的,编译器会报错。
{
x = 10; // 错误:x 还没声明
int x = 0;
}
局部作用域 & 生命周期(存储期)
“可见性(作用域)”和“生命周期(存储期)”是两个相关但不同的概念:
作用域:名字能不能用(编译期概念)
存储期:对象在内存里活多久(运行时概念)
- 自动存储期(绝大多数局部变量)
在块作用域中声明、没有额外修饰的普通局部变量默认是 自动存储期(automatic storage duration):
进入块时创建;
离开块时销毁;
不会跨函数调用存活。
void f() {
int x = 0; // 自动存储期:调用 f 时创建,离开 f 时销毁
} // x 销毁
- 静态局部变量(static)
如果在局部作用域加上 static,变量就变成 静态存储期:
生命周期变成整个程序运行期间;
但作用域仍然是这个局部作用域(只在块内可见)。
void counter() {
static int n = 0; // 静态存储期,但仍是“局部变量”
++n;
std::cout << n << '\n';
}
int main() {
counter(); // 1
counter(); // 2
counter(); // 3
}
二、堆和栈
栈(Stack)
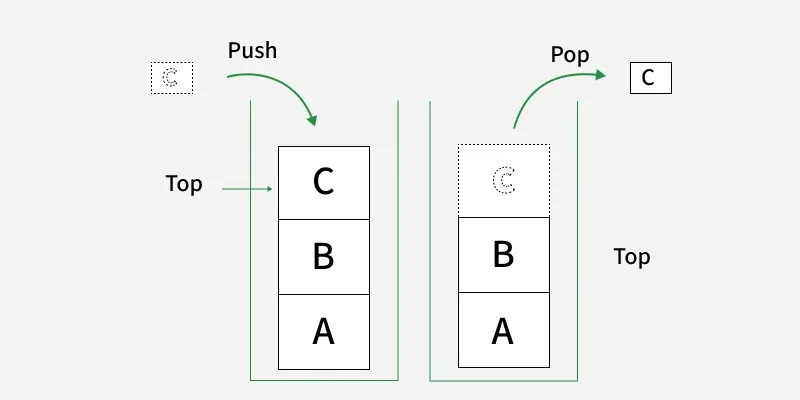
特点:严格、有序、自动、极速。
- 工作特点:一段连续的内存,只能从栈顶取出或放入元素,数据之间具有层次结构(体现在局部作用域)
- 分配与释放:完全自动。当进入一个函数(大括号 {})时,系统自动在栈顶给你分配空间;当离开这个函数时,系统自动把你刚才占用的空间收走(销毁)。
- 速度:极快。只需要移动一下栈顶指针即可,几乎没有额外开销。
- 空间大小:较小。通常只有几 MB(Windows 默认通常是 1MB)。如果栈上变量太大(比如在函数里声明一个极大的数组),就会报 Stack Overflow(栈溢出) 错误。
- 生命周期:局部作用域。离开 {} 立即死亡。
在代码中的体现(一般以默认构造形式出现):
void doSomething() {
int a = 10; // a 在栈上
Student s("张三"); // s 在栈上(对象的内部数据也在栈上)
// 函数执行完毕,a 和 s 瞬间被销毁,内存自动归还
}
堆(Heap)
特点:自由、无序、手动(或智能指针)、较慢。
- 工作特点:分散的内存片段,可以在任意空位置创建元素,数据之间是平铺的,不具层次结构。
- 分配与释放:必须主动申请(C++ 中用 new),必须主动销毁(C++ 中用 delete)。如果申请了忘了销毁,这块地就被永久占用了,这就叫 内存泄漏。
- 速度:较慢。因为在庞大且零散的堆内存中找一块合适大小的空间,需要花费时间,还可能产生内存碎片。
- 空间大小:非常大。受限于你的物理内存和操作系统,通常有几个 GB 甚至更多。
- 生命周期:跨作用域。只要你不去 delete 它,它就一直活着,可以在函数之间传递。
在代码中的体现(一般以指针形式出现):
void doSomething() {
// 在堆上申请空间,p 这个指针变量本身在栈上,但它指向的数据在堆上
Student* p = new Student("李四");
} // 函数执行完毕,栈上的指针 p 被自动销毁了!
// 但是!堆上的 Student("李四") 对象还在!你再也找不到它了,也无法销毁它 -> 内存泄漏!
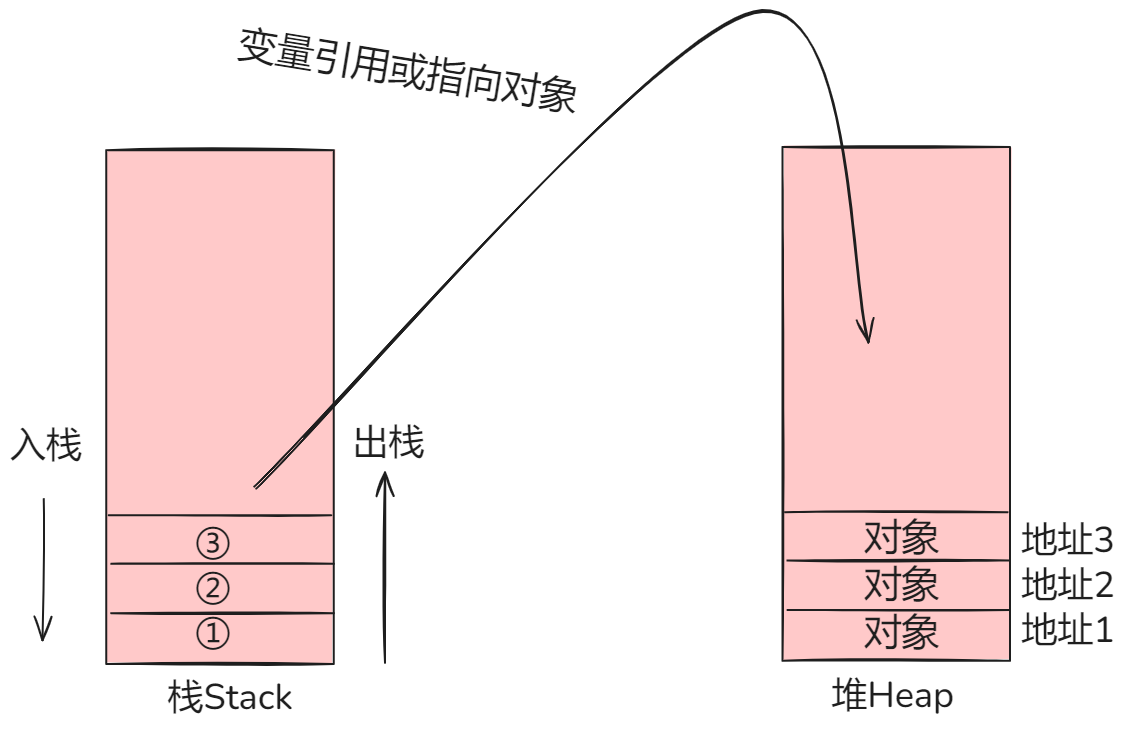
二者联系:RAII(资源获取即初始化)
栈上对象具有高速、自动管理生命周期的优点,但其容量太小;堆上对象具有大容量的优点,但其速度较慢,而且生命周期需要手动管理,容易发生内存泄漏。有没有一种方法,可以结合二者的优点呢?
有,这种方法就是RAII(Resource Acquisition Is Initialization,资源获取即初始化)
这种方法的核心思想就是把堆对象(资源)的生命周期绑定到栈对象上,随栈对象的构造而自动构造,随栈对象的解构而自动解构。其绑定关系如下图:
以下代码展示了一个ArrayWrapper使用RAII手法的示例:
#include <iostream>
#include <stdexcept>
class ArrayWrapper {
private:
int* m_data;
size_t m_size;
public:
ArrayWrapper(size_t size) : m_size(size), m_data(new int[size]) {
std::cout << "分配内存\n";
}
~ArrayWrapper() {
delete[] m_data;
std::cout << "释放内存\n";
}
// 简单提供个接口模拟使用
void doSomething() {}
};
void processModernStyle(bool has_error, bool throw_exception) {
ArrayWrapper vec(1000); // 1. 获取资源(绑定在 vec 的生命周期上)
// ---- 业务逻辑开始 ----
if (has_error) {
std::cout << "发现错误,需要提前退出\n";
return; // 直接 return,vec 离开作用域,析构函数自动调用,内存自动释放
}
if (throw_exception) {
std::cout << "发生异常\n";
throw std::runtime_error("崩溃了"); // 随便抛异常,C++ 栈展开机制保证 vec 析构函数依然被调用
}
// ---- 业务逻辑结束 ----
std::cout << "正常执行完毕\n";
// 正常退出,大括号结束,vec 析构,自动释放!
}
如果不使用RAII的手法,代码将变成这样,不仅代码可读性降低,而且很容易在出口处忘记delete导致异常:
#include <iostream>
#include <stdexcept>
void processOldDataStyle(bool has_error, bool throw_exception) {
int* data = new int[1000]; // 1. 获取资源
std::cout << "分配了内存\n";
// ---- 业务逻辑开始 ----
if (has_error) {
std::cout << "发现错误,需要提前退出!\n";
delete[] data; // 必须在每一个 return 前清理,忘掉就内存泄漏
return;
}
if (throw_exception) {
std::cout << "发生异常\n";
// 致命缺陷:如果这里抛出异常,后面的 delete 永远执行不到,内存必定泄漏
// 除非用 try-catch 把所有代码包起来并在 catch 里 delete,那代码会膨胀到无法阅读
throw std::runtime_error("崩溃了");
}
// ---- 业务逻辑结束 ----
std::cout << "正常执行完毕\n";
delete[] data; // 正常退出也要清理
}
显然,RAII带来了许多好处,实际上,大部分C++标准库都使用了RAII手法。当然,这里的资源不仅可以是堆上的内存,也可以是文件I/O、网络请求、数据库连接等等。
三、指针与引用
指针——不要轻易用指针
在c语言中,指针是极其常用的概念,c++中也有大量的库要求使用指针进行操作,但是对于其他情况,对我这样的新手而言,还是尽量做到能不用指针就不用指针(裸指针)。
裸指针
概念:指针是一个变量,其存储的值是另一个变量的内存地址。
语法:类型* 指针名 = &目标变量;
核心特点:
可以为空:可以赋值为 nullptr,表示不指向任何对象。
可以重定向:在生命周期内可以随时改变指向的对象。
支持指针算术运算:如 ptr++,常用于遍历数组。
需要手动内存管理:如果是 new 出来的内存,必须对应使用 delete,否则会导致内存泄漏。
有多级指针:如 int** pp。
智能指针
概念:现代 C++ 引入的类模板,用于自动管理动态分配的内存,遵循 RAII(资源获取即初始化)机制。它封装了原始指针,当智能指针的生命周期结束时,会自动销毁底层对象。位于 头文件中。
1. std::unique_ptr(独占指针)
特点:同一时刻只能有一个 unique_ptr 指向该对象。不可拷贝,只能移动。
场景:默认的首选智能指针,用于表示独占所有权。
开销:与原始指针大小相同,零额外开销。
2. std::shared_ptr(共享指针)
特点:内部使用引用计数。多个 shared_ptr 可以指向同一个对象。当最后一个 shared_ptr 被销毁时,对象才被释放。可拷贝。
场景:用于表示共享所有权(多个模块需要同时持有该对象的生命周期)。
开销:需要维护一个线程安全的引用计数块,有一定性能和内存开销。
3. std::weak_ptr(弱指针)
特点:它是 shared_ptr 的观察者,指向 shared_ptr 管理的对象,但不增加引用计数。使用前必须调用 lock() 提升为 shared_ptr 来判断对象是否存活。
场景:专门用于解决 shared_ptr 的循环引用问题(例如双向链表、观察者模式中的树形结构)。
引用——更安全的选择
概念:引用本质上是给一个已存在的变量起了一个别名。引用和被引用的变量共享同一块内存地址。
语法:类型& 引用名 = 目标变量;
操作引用的方式和操作目标变量完全相同。
核心特点:
必须在声明时初始化:不能定义空引用。
不可重定向:一旦绑定到一个对象,就不能再绑定到另一个对象(从一而终)。
没有空引用:这保证了使用引用时不需要像指针那样做判空处理。
示例:
#include <iostream>
using namespace std;
int main ()
{
// 声明简单的变量
int i;
double d;
// 声明引用变量
int& r = i;
double& s = d;
i = 5;
cout << "Value of i : " << i << endl;
cout << "Value of i reference : " << r << endl;
s = 11.7;
cout << "Value of d : " << d << endl;
cout << "Value of d reference : " << s << endl;
return 0;
}
四、函数
函数的执行逻辑
初学时常因为函数形参类型的多样而分不清各自的意义,按等效的方式理解也许会清晰许多:
bool test(int i, std::string s, std::vector<int> v) {
// ...
return true;
}
int main() {
std::vector<int> vec={1,2,3,4,5};
std::string str="Hello World";
int i32=114514;
bool result=test(i32,str,vec);
}
以上函数,在调用时的逻辑可看作以下过程:
int main() {
bool result;
//逻辑上相当于以下代码,但实际更优化
{
//传入参数
int i=i32;
std::string s=str;
std::vector<int> v=vec;
//...
//返回值
result=true;
}
}
除了直接传对象、基本类型,引用、指针类型也可以按如上方式进行理解。不过,实际上编译器内部有很多优化,真实的函数调用过程优于第二份代码,以上例子仅用于语义理解,不表示内部真实执行逻辑。
五、左值和右值
顾名思义,一般上等号左边的是左值,等号右边的是右值。
左值
本质:在内存中有真实地址、并且生命周期较长(不是马上消失)的对象。
特征:你可以对它取地址(用 & 符号)。
举例:变量、指针
int a = 10; // a 是左值,它在内存有位置,&a 是合法的
a = 20; // a 可以放在等号左边被修改
int* ptr = &a; // 合法
右值
本质:没有固定内存地址,或者生命周期极短(用完就销毁)的临时数据。
特征:你不能对它取地址。
举例:字面量、计算结果、函数返回值
int b = 5; // 5 是右值(字面量,临时存在的数字)
int c = a + b; // a+b 的计算结果是个临时值,算完就扔,它是右值
// &(a + b); // 错误!编译器报错:无法获取临时值的地址
std::string getName() { return "张三"; }
// getName() // 返回的临时字符串对象,也是右值
// &getName(); // 错误!
左值引用
即一般的引用,和上文提到的那种一样。左值引用&不能绑定右值。
注:常量(const)左值引用,既可接受左值,又可接受右值,但在接受了右值之后就不可修改。这是为函数参数设计的。
右值引用
右值引用 &&专门绑定到那些临时的、马上要死的右值上。右值引用&&不能绑定左值。
int a = 10;
int&& rref = 10; // 右值引用,绑定到右值 10 (10是临时常数)
int&& rref2 = a + 5; // 右值引用,绑定到临时计算结果
为什么 C++ 要区分左右值
为了性能:移动语义
假设你有一个装了 1GB 数据的 std::vector。
std::vector<int> a = {1GB的数据};
std::vector<int> b = a; // 拷贝!极其慢!要把 1GB 复制一遍
如果 a 马上就要销毁了(比如是个函数返回的临时变量,是个右值),我们为什么还要辛苦地去复制 1GB?直接把 a 里面的内存指针“偷”过来给 b 不就行了吗?
为了告诉编译器“这是一个可以偷的临时对象”,C++ 引入了右值引用,用 && 表示。
std::vector<int> a = {1GB的数据};
// a 是左值(长久存在),用 & 接收
std::vector<int>& ref_a = a;
// std::move(a) 强行把 a 转换成右值,用 && 接收
std::vector<int>&& ref_b = std::move(a);
// 现在 a 被掏空了(变成了空壳),b 偷走了 a 的 1GB 内存。耗时几乎为 0!
左值引用常用来定义拷贝构造函数,表示从左值构造对象(同时不破坏原变量,需要拷贝),右值引用常用来定义移动构造函数,表示从右值构造对象(直接捕获右值,不发生拷贝),如下:
class MyString {
private:
char* m_data;
size_t m_size;
public:
// 构造与析构
MyString(const char* str) { /* 分配内存,复制字符串 */ }
~MyString() { delete[] m_data; }
// 1. 拷贝构造(传统:辛苦搬砖)
MyString(const MyString& other) {
m_size = other.m_size;
m_data = new char[m_size]; // 重新分配内存
memcpy(m_data, other.m_data, m_size); // 逐字节复制
std::cout << "深拷贝\n";
}
// 2. 移动构造(核心:合法偷窃)
// 注意参数类型是 &&(右值引用),表示我知道你是个临时对象,我可以偷你
MyString(MyString&& other) noexcept {
m_data = other.m_data; // 直接捕获指针
m_size = other.m_size;
// 关键步骤:把源对象的指针置空,防止它析构时把内存释放了,导致悬垂指针
other.m_data = nullptr;
other.m_size = 0;
std::cout << "移动构造\n";
}
};
这样编写大大提高了内存重用率,提升程序速度。
2026/5/10更新

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)