实战分享 | 基于 RPA+LLM 的 Boss 直聘智能招聘全流程系统架构设计
在企业招聘的日常工作中,HR 往往深陷于大量重复且机械的事务性工作:每天在招聘平台登录、批量发布岗位、给数百位候选人主动打招呼、反复解答基础岗位问题、筛选简历、协调面试时间、跟进面试反馈……
传统 RPA 工具只能解决固定流程的自动化,却无法应对招聘对话中复杂的意图理解、多轮沟通和动态场景切换。为此,基于实在智能 RPA 设计器 + Python + LangChain + DeepSeek 大模型 + Chroma 向量库技术栈,搭建了一套覆盖 Boss 直聘「岗位发布→候选人沟通→面试预约→面试反馈」全流程的智能招聘自动化系统。
本文将完整分享这套系统的架构设计、技术选型、核心模块实现与落地经验,实现 RPA+LLM 在招聘场景的工程化落地。
一、项目核心适用场景
这套系统专为 Boss 直聘平台的招聘全流程设计,核心覆盖以下业务场景:
- Boss 直聘账号登录与环境自动化管理
- 岗位批量发布、上下架与内容合规校验
- 候选人主动招呼与批量精准触达
- 全流程智能对话与候选人自动化初筛
- 面试时间预约、改期与取消全流程自动化
- 面试反馈跟进与招聘数据全链路归档
二、整体技术选型与设计原则
技术选型始终围绕低交付复杂度、高业务适配性、强稳定可控三大核心原则,既保证了系统的智能化能力,又兼顾了中小企业的快速落地需求,核心选型如下:
| 层级 / 组件 | 核心选型 | 选型理由与说明 |
|---|---|---|
| RPA 执行层 | 实在智能设计器 | 国内领先的 RPA 设计器,完美适配国内招聘平台的页面元素交互,零代码即可实现浏览器操作、文件上传下载、流程调度,解决了传统 Selenium 易被反爬、元素定位不稳定的痛点,是对接 Boss 直聘前端交互的核心执行载体。 |
| 大语言模型 | 华为云部署 - DeepSeek | 开源可商用、中文理解能力优异,推理性能出色,完美适配招聘场景的意图识别、对话生成、结构化输出需求。将模型推理与 RPA 执行解耦,既保证了 AI 能力的灵活迭代,又避免了 RPA 流程的臃肿。 |
| 核心开发语言 | Python 3.11 | 生态完善,完美兼容 LangGraph、RPA 组件调用、数据库操作与大模型接口封装,是 AI+RPA 场景的最优开发语言选择。 |
| AI 应用编排框架 | LangGraph | 一站式解决 Prompt 模板管理、大模型链式调用、结构化输出约束、对话记忆管理、RAG 检索编排等核心需求,大幅降低 AI 对话逻辑的开发与维护成本。 |
| 关系型数据库 | MySQL 8.0 | 稳定可靠,支持事务,用于存储岗位信息、候选人档案、聊天记录、面试安排、错误日志等核心业务数据,保证全流程可追溯、可审计。 |
| 向量数据库 | Chroma | 轻量易用,原生支持 Python 与 LangGraph,完美适配中小规模招聘知识语料的持久化存储与语义检索,无需复杂的集群部署,大幅降低初期落地门槛。 |
| 嵌入模型 | BAAI/bge-m3 | 中文场景 SOTA 级开源嵌入模型,支持多语言、多功能、多粒度检索,对招聘场景的长文本 JD、公司介绍、FAQ 问答有极强的语义表征能力,检索效果远超通用嵌入模型。 |
| 可选重排模型 | BAAI/bge-reranker-v2-m3 | 用于向量召回后的精排,进一步提升知识片段的匹配精度,保证 RAG 注入的内容与当前对话强相关,大幅降低大模型幻觉问题。 |
三、系统总体架构:四层一引擎核心设计
这套系统采用经典的分层架构设计,核心为 「四层一引擎」 架构体系,从上到下分别为:交互层、业务流程层、AI 引擎层、数据层,辅以贯穿全流程的主流程引擎,实现业务流与 AI 能力的深度融合。
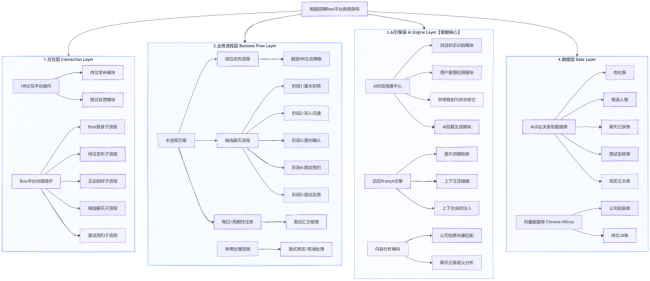
其中,AI 引擎层是系统的智能大脑(核心控制面),负责所有的意图理解、状态决策与内容生成;业务流程层是系统的执行骨架(流程执行面),负责全招聘流程的串联与分支切换;交互层是系统的手脚,负责与 Boss 直聘平台、HR 的人机交互;数据层是系统的记忆底座,负责所有业务数据与知识数据的持久化存储。
1. 交互层:纯交互执行,无业务决策
交互层是系统与外部环境的唯一交互入口,只负责页面操作和信息的输入输出,不承载任何复杂的业务决策逻辑,核心职责包括:
- Boss 直聘平台侧:账号登录、岗位发布、主动招呼、候选人聊天、面试预约 / 改期 / 取消的页面操作执行
- HR 交互侧:通过钉钉、企业微信等平台,实现招聘流程通知、人工介入接管、异常流程处理
2. 业务流程层:全招聘流程的串联与管控
业务流程层是系统的业务核心,负责把「登录→岗位发布→候选人沟通→面试预约→面试反馈→归档」的完整招聘链路,拆解为可执行、可管控的子流程,并根据岗位类型、候选人沟通阶段、异常状态自动切换流程分支。
核心子流程分为三大类:
- 基础流程:Boss 登录子流程、岗位发布子流程、每日 / 周期性任务调度流程
- 核心招聘流程:主动招呼子流程、候选人聊天子流程、面试预约子流程
- 兜底流程:异常处理流程、面试修改 / 取消流程、人工介入接管流程
3. AI 引擎层:系统的智能核心,对话全流程调度
AI 引擎层是这套系统区别于传统 RPA 的核心,它的核心目标是把自由的招聘对话,转化为「可执行、可管控、可追溯」的结构化状态,实现对话的全流程智能调度。
核心功能模块包括:
- 对话状态识别模块:识别当前对话所处的招聘阶段,输出结构化状态标签
- 用户意图检测模块:精准识别候选人消息的核心意图,比如咨询薪资、拒绝岗位、申请改期等
- AI 对话调度中心:根据状态与意图,决策后续动作:继续追问、意向确认、发起预约、转人工、结束对话等
- 动态 Prompt 引擎:按当前对话状态,自动匹配对应的提示词模板,动态拼装岗位、候选人、上下文等信息
- 回复生成模块:基于 RAG 增强的上下文,生成符合约束的合规回复
- 上下文压缩器:解决长对话上下文溢出问题,保留核心对话信息
- 异常路由与状态修正模块:处理对话异常、模型幻觉、候选人答非所问等场景,修正对话状态,保证流程不中断
- 内容分析模块:负责招聘语料的语义分析、向量入库、检索匹配,为回复生成提供事实依据
4. 数据层:双库架构,兼顾事务安全与语义检索
数据层采用 「MySQL 关系型数据库 + Chroma 向量数据库」的双库架构,实现业务事务数据与知识语义数据的分离存储与协同调用:
- MySQL:存储核心业务事务数据,保证数据的一致性、可追溯性与审计能力
- Chroma:存储公司信息、岗位 JD、FAQ 问答、标准回复话术等知识语料的向量数据,为大模型提供精准的事实依据,解决幻觉问题
四、核心模块关键实现细节(落地干货)
1. 候选人聊天全流程阶段化管控,告别 “纯聊天” 式 AI
传统的 AI 招聘聊天,往往是大模型自由生成文本,极易脱离招聘目标,出现乱承诺、跑题、流程中断等问题。因此,核心设计思路是:AI 不做 “纯聊天”,只做 “流程内的对话调度”。
将候选人从触达到入职前的全流程,拆解为 5 个标准化阶段,每个阶段都有明确的业务目标与对话边界:
- 阶段 1:基本初筛:核心完成候选人的基础信息匹配(工作年限、学历、到岗时间、核心技能等),过滤不符合硬性要求的候选人
- 阶段 2:深入沟通:核心解答候选人的基础疑问,同步岗位核心信息、工作内容、薪资范围、公司情况等
- 阶段 3:意向确认:核心确认候选人的求职意向、到岗意愿,排除无效候选人,锁定高意向人群
- 阶段 4:面试预约:核心完成面试时间、面试形式、面试链接的协调与确认,自动同步到面试安排表
- 阶段 5:面试反馈:核心跟进面试结果,同步候选人面试反馈,推进后续 offer 流程或人才归档
关键设计:大模型的输出不是自由文本,而是 「结构化状态标签 + 合规回复文本」,每一轮对话都会先更新当前对话所处的阶段,再基于阶段目标生成回复,从根源上避免 AI 脱离招聘流程自由发挥。
2. 动态 Prompt 引擎:告别固定提示词,实现千人千面的精准对话
固定的 Prompt 模板,无法适配招聘场景中不同岗位、不同候选人、不同沟通阶段的需求,极易出现回复生硬、不符合当前场景的问题。我们设计了动态 Prompt 引擎,核心实现逻辑如下:
- 预设提示词模板库:按 5 个沟通阶段,分别预设对应的提示词模板,每个模板都明确了当前阶段的业务目标、回复约束、话术风格、禁止项
- 动态参数拼装:每一轮对话,系统都会自动从数据库中提取「当前岗位 JD 信息、候选人画像信息、最近 N 轮对话摘要、当前阶段约束条件、HR 预设话术风格」,拼接到对应阶段的模板中
- 实时上下文注入:通过 RAG 检索,将与当前对话强相关的公司信息、FAQ 标准回复注入 Prompt,保证回复的事实准确性
举个例子,当对话处于「面试预约阶段」,Prompt 会自动拼装岗位的面试流程、可预约的时间段、面试官信息、面试形式等参数,同时约束模型必须引导候选人确认固定的可选时间段,而不是自由协商时间,大幅提升面试预约的成功率。
3. 对话上下文压缩与记忆管理,解决长对话 Token 溢出与信息丢失问题
招聘对话往往会持续多轮,传统的全量对话历史拼接,不仅会导致 Token 消耗激增,还会出现上下文溢出、核心信息被稀释的问题。
解决方案是:不做全量历史拼接,只保留核心信息,长历史通过摘要 + 检索补全,核心设计如下:
- 固定保留核心信息:最近 3-5 轮的完整对话 + 当前对话阶段标签 + 候选人核心画像 + 岗位关键要求 + 回复约束条件
- 长对话历史处理:超过固定轮数的对话历史,通过大模型生成对话摘要,只保留与岗位匹配、意向确认相关的核心信息,丢弃无效闲聊内容
- 关键信息检索补全:当对话中提及历史沟通的关键信息(如之前约定的薪资、到岗时间),通过语义检索从历史聊天记录中召回对应的完整内容,注入上下文,保证信息的连贯性
这套方案,既大幅降低了 Token 消耗,又避免了长对话中核心信息的丢失,同时解决了上下文溢出的问题。
4. RAG 检索增强在招聘场景的落地,从根源上降低大模型幻觉
招聘场景中,大模型的幻觉是致命问题:比如乱承诺薪资、虚报公司福利、错误描述岗位职责,都会给企业带来合规风险与口碑问题。
通过 Chroma 向量数据库搭建了招聘专属的 RAG 检索体系,核心实现如下:
- 知识语料入库:将公司介绍、组织架构、岗位 JD、薪酬福利体系、招聘 FAQ、面试流程、标准回复话术等内容,拆分为标准化的知识片段,通过 bge-m3 模型生成向量,存入 Chroma 向量库
- 分层检索机制:每一轮回复生成前,先基于候选人的提问,通过向量相似度检索,召回 Top10 相关的知识片段;可选通过重排模型做精排,筛选出 Top3 最相关的内容
- 事实约束注入:将检索到的知识片段,作为唯一的事实依据,注入 Prompt 中,严格约束大模型:所有回复必须基于提供的事实内容,禁止编造任何未提供的信息
- 回复风控校验:回复生成后,系统会自动做敏感词检测、越权承诺检测、事实一致性校验,不通过的内容会自动触发改写,或直接拦截转人工处理
通过这套机制,将大模型的幻觉率降到了极低的水平,保证了招聘对话的合规性与准确性。
5. AI 对话闭环全流程实现
最终,我们将以上模块串联,形成了完整的 AI 对话闭环,每一轮对话都会执行以下标准化流程:
- 意图与状态识别:候选人消息进入 AI 对话调度中心,先通过意图分类器识别核心意图,同时判断当前对话所处的阶段,输出结构化的状态标签
- 流程路由决策:基于识别到的意图与状态,决策后续流程:继续当前阶段对话、切换阶段、发起面试预约、转人工介入、结束对话等
- 动态 Prompt 组装:根据决策结果,从模板库中调取对应模板,动态拼装岗位、候选人、上下文、约束条件等参数
- RAG 知识检索:基于当前对话内容,从 Chroma 向量库中检索相关的知识片段,做精排后注入 Prompt
- 回复生成与结构化输出:调用 DeepSeek 大模型生成回复,通过 LangChain 约束输出为「状态标签 + 回复文本」的结构化结果
- 风控校验与发送:对生成的回复做合规校验,通过后交由 RPA 执行层发送给候选人,同时更新数据库中的对话状态与聊天记录
五、核心数据结构设计
为了保证全流程的可追溯性与数据一致性,我们在 MySQL 中设计了 5 张核心业务表,覆盖全招聘流程的核心数据:
- 岗位表:存储岗位 ID、岗位名称、JD 内容、薪资范围、发布状态、所属 HR、创建时间、更新时间等核心信息
- 候选人表:存储候选人 ID、姓名、联系方式、工作年限、学历、核心技能、求职意向、当前沟通阶段、所属岗位、创建时间等核心档案信息
- 聊天记录表:存储对话 ID、候选人 ID、岗位 ID、对话轮次、发送方(AI/HR/ 候选人)、消息内容、对话状态、发送时间等全量对话数据
- 面试安排表:存储面试 ID、候选人 ID、岗位 ID、面试时间、面试形式、面试官、面试状态(待确认 / 已确认 / 已完成 / 已取消)、面试结果、创建时间等信息
- 错误日志表:存储流程 ID、错误模块、错误内容、错误时间、处理状态等信息,用于系统运维与问题排查
向量库 Chroma 则按集合进行划分,分为:公司信息集合、岗位 JD 集合、招聘 FAQ 集合、标准回复话术集合,每个集合都对应独立的嵌入模型与检索配置。
六、部署方案与落地建议
为了兼顾落地效率、稳定性与后续扩容能力,采用 「设计器前台执行 + Python 组件内嵌 + 数据库集中存储」的部署方式,具体如下:
- RPA 执行层:由实在智能设计器负责,部署在 HR 的办公终端或专属的 RPA 执行机上,负责所有的浏览器操作与页面交互
- AI 能力层:Python 组件内嵌到实在智能设计器中,通过 HTTP/SDK 方式调用部署在华为云服务器上的 DeepSeek 大模型,实现 AI 能力与 RPA 流程的解耦
- 数据存储层:MySQL 与 Chroma 作为独立服务,部署在统一的受控服务器环境中,实现数据的集中存储、统一管理与安全管控
- HR 交互侧:通过钉钉、企业微信等平台,承接招聘流程通知、异常告警、人工介入接管等需求,实现 AI 自动化与人工干预的无缝衔接
落地优化:
- 初期落地阶段:保持 Python 组件内嵌式实现,无需拆分微服务,大幅降低交付复杂度与运维成本,快速实现业务闭环
- 扩容迭代阶段:当招聘规模扩大、多 HR 多岗位并行时,可将 AI 逻辑逐步抽出为独立的 API 服务,实现多终端、多账号的并行调用
- 安全合规层面:所有候选人数据、聊天记录必须加密存储,严格遵守《个人信息保护法》,大模型调用需做数据脱敏,禁止将候选人隐私数据传入公网大模型
七、项目落地价值与效果
这套系统落地后,为企业招聘带来了显著的效率提升:
- 事务性工作自动化率超 85%:岗位发布、主动打招呼、简历初筛、基础问题解答、面试预约等重复工作,全部由系统自动化完成
- HR 人效提升 3 倍以上:HR 从大量的重复工作中解放出来,只需要聚焦于高意向候选人的深度沟通、面试甄选等核心工作
- 招聘周期大幅缩短:候选人触达、初筛、面试预约的响应时间从小时级缩短到分钟级,大幅提升候选人体验,降低人才流失率
- 招聘流程标准化:全流程的对话、筛选、预约都基于统一的标准执行,避免了不同 HR 的招聘标准不统一、回复不规范的问题
八、总结与后续优化方向
这套基于 RPA+LLM 的智能招聘系统,通过「四层一引擎」的架构设计,完美解决了传统招聘自动化工具只能处理固定流程、无法应对复杂对话的痛点,实现了 Boss 直聘招聘全流程的端到端自动化与智能化。
其核心优势在于,没有做 “为了 AI 而 AI” 的纯聊天机器人,而是始终围绕招聘业务的核心目标,将 AI 能力深度嵌入到招聘流程的每一个环节,用 AI 做流程的调度与决策,用 RPA 做流程的执行,实现了业务与技术的完美融合。
后续将在以下方向做持续优化:
- 多平台适配:扩展到猎聘、智联招聘等多个主流招聘平台,实现全平台的统一招聘管理
- 简历智能解析:引入 OCR 与文档解析能力,实现简历的自动解析、关键信息提取、人岗匹配度智能评分
- 招聘数据分析:搭建招聘数据看板,实现招聘转化率、渠道效果、HR 人效等数据的可视化分析与智能预警
- 多轮对话优化:基于历史对话数据,做微调优化,进一步提升对话的流畅度与招聘转化率

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 10
10 1
1- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)