为什么优化问题求解最终是HΔx=b 而非 Hx=b?
目录
对于观测方程:
其中,z为传感器的实际观测值;为观测模型,描述状态量x到观测值的映射;n为观测噪音,满足零均值高斯分布
。
优化问题目标函数为:
![]()
其中,为残差函数,定义为
,表示观测值与模型预测值的偏差。
1.只有线性最小二乘才是直接解Hx=b
当优化问题是线性的时候,我们确实可以一步到位解出全局最优解,形式就是Hx=b。当观测模型是线性函数时,可表示为
,此时:
- 残差函数:
- 目标函数:
- 对 x 求导并令导数为 0:
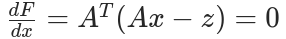
整理后得到线性方程组:
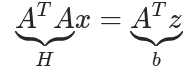
其中,![]() 为Hessian矩阵,线性场景下是常数矩阵(与 x 完全无关);
为Hessian矩阵,线性场景下是常数矩阵(与 x 完全无关);![]() 为信息向量,由观测值 z 直接计算得到;x为待求解的状态量(如位姿、速度、零偏)。
为信息向量,由观测值 z 直接计算得到;x为待求解的状态量(如位姿、速度、零偏)。
此时 H 是固定矩阵,我们可以通过 QR 分解、SVD 等方法一步求解全局最优的x。
2.核心演变原因:SLAM 中所有优化问题都是非线性的
SLAM 里没有纯线性的观测模型:
- 激光点云配准:点到线 / 面残差是位姿的非线性函数;
- IMU 预积分:残差是旋转、速度、零偏的高度非线性函数;
- 回环约束:相对位姿变换也是非线性的。
(1)非线性场景下的目标函数
对于非线性观测模型,目标函数是:
是非线性函数,目标函数为:
![]()
其中,为第 i 个观测的残差,
为第 i 个观测对应的非线性观测模型的估计值。
(2)为什么不能直接构造 Hx=b?
对非线性目标函数求导,得到的梯度为:
![]()
其中,![]() :第 i 个观测的雅可比矩阵,是关于 x 的函数(x 变化,
:第 i 个观测的雅可比矩阵,是关于 x 的函数(x 变化,![]() 也会变化)。
也会变化)。
上式整体是一个关于 x 的非线性方程组,无法将x单独移到一边写成的形式,所以没有解析解,无法像线性场景一样一步求出 x,只能用迭代数值方法求解。
3.迭代求解的核心思想:局部线性化 + 增量更新
我们无法一步找到全局最优的 x,但可以在当前状态估计值附近,把非线性函数做一阶泰勒展开,近似为线性函数,然后求解一个关于增量
的线性最小二乘问题,这就是
的来源。
(这也就要求我们需要提供一个较好的线性化展开点,防止优化问题陷入局部最优解)
(1)一阶泰勒展开(局部线性化)
在当前状态处,对非线性观测模型
做一阶泰勒近似:
![]()
其中,为第 k 次迭代的当前状态估计值,
为待求解的状态增量,表示对当前状态的修正量。
![]() 为观测模型在
为观测模型在处的雅可比矩阵,此时是常数矩阵(
已知)。
(2)代入目标函数,构造关于的线性最小二乘
残差函数在处的近似为:
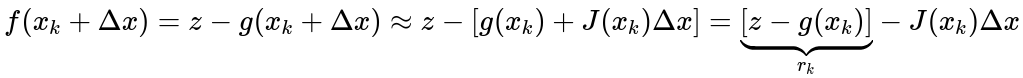
其中,![]() 为当前状态的残差向量。
为当前状态的残差向量。
将其代入目标函数,得到关于的近似线性最小二乘问题:
![]()
对求导并令导数为 0,可得:
![]()
整理后得到线性方程组:
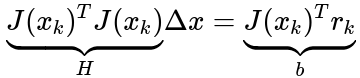
其中,![]() 由当前状态的雅可比计算得到,是常数矩阵,
由当前状态的雅可比计算得到,是常数矩阵,![]() 由当前状态的雅可比和残差计算得到。
由当前状态的雅可比和残差计算得到。
(3)迭代更新与收敛
求解得到后,更新状态:
![]()
重复上述「线性化→求解→更新状态」的步骤,直到
小于设定阈值,说明状态收敛,迭代结束。
4.SLAM场景下的应用
旋转通常使用旋转矩阵R或四元数q来表示,其属于李群,不满足加法封闭性。若两个旋转矩阵相加,得到的不再是合法的旋转矩阵(破坏正交性约束)。因此必须采用李代数增量扰动的方式:
![]()
其中,为当前的旋转矩阵,
为李代数(旋转向量)增量,对应
中的旋转部分,
代表李代数指数映射,将李代数增量转换为合法的旋转矩阵。
5.总结
首先,只有线性最小二乘才能直接解 ,因为线性模型的海森矩阵是常数矩阵,能一步求全局最优。但 SLAM 里的观测模型都是非线性的,比如激光配准、IMU 预积分的残差都是位姿的非线性函数,没法直接构造
。我们只能在当前状态估计值附近做一阶泰勒展开,把非线性问题转化为关于增量
的线性最小二乘问题,也就是
,然后迭代更新状态直到收敛。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 14
14 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)