Harness Engineering 看这一篇就够了,5分钟带你完全掌握

一、你的AI智能体总在翻车?问题不在模型,而在你没给它造好"缰绳"
你大概率也遇到过这种情况——让AI写代码,它一开始很顺利。但跑着跑着就开始胡来,上下文耗尽、半成品堆积、明明没做完却宣布胜利。
你换了更强的模型,调了更精细的prompt。结果呢?还是老样子。
问题不在于AI不够聪明,而在于你一直在用错误的方式驾驭它。
二、一个反常识的真相
2026年初,有个新概念在工程圈迅速走红:Harness Engineering(驾驭工程)。
它的核心哲学只有八个字:人类掌舵,智能体执行。
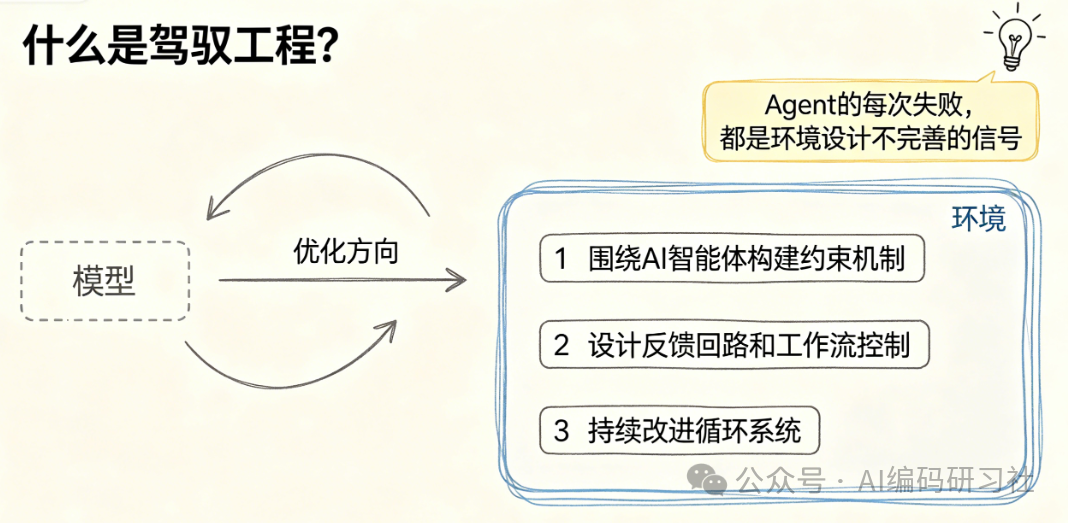
听起来很简单,但大多数人做反了——他们把全部精力花在优化模型上,却忽略了给AI打造一个能稳定运行的环境。
就像一匹野马。你不是去训练马的大脑,而是给它配上缰绳、马鞍和嚼子。让它跑得又快又稳,还不会失控。
这个概念由HashiCorp联合创始人Mitchell Hashimoto提出。六天后,OpenAI在百万行代码实验报告中正式采用这一术语。
一个月后,它成了开发者社区的高频词。
为什么?因为数据太震撼了。
三、LangChain的案例:不动模型,排名从30飙到5
LangChain团队做了一个实验
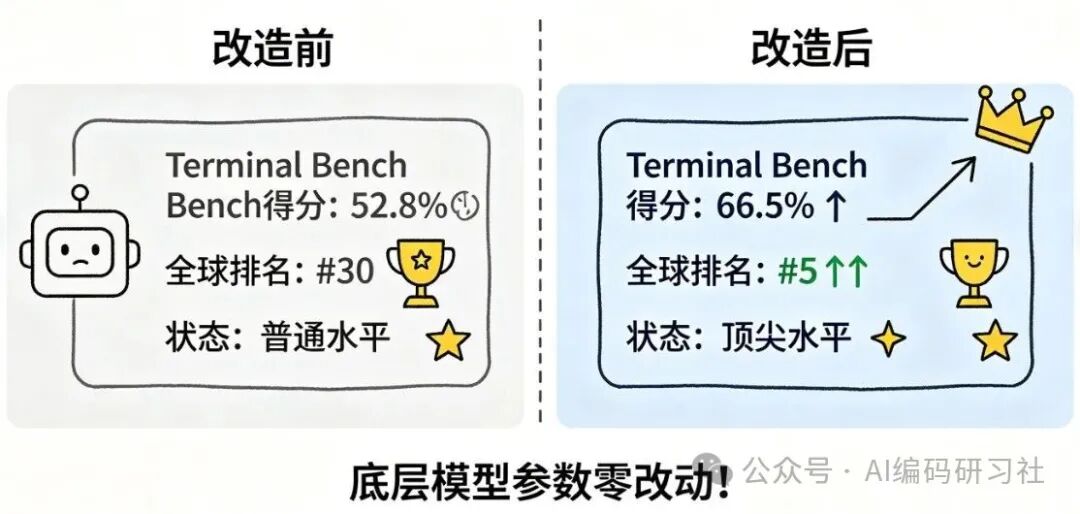
他们没有改动底层模型的任何参数。只是优化了外部驾驭环境:文档结构、验证回路、追踪系统。
结果?编码Agent在Terminal Bench 2.0的得分从52.8%飙升至66.5%,全球排名从第30位跃升至第5位。
五个独立团队也得出了相同结论:瓶颈不在模型智能,而在基础设施。
四、AI工程的三次跃迁
要理解Harness Engineering为何重要,得先看清楚我们是怎么一步步走到这里的。
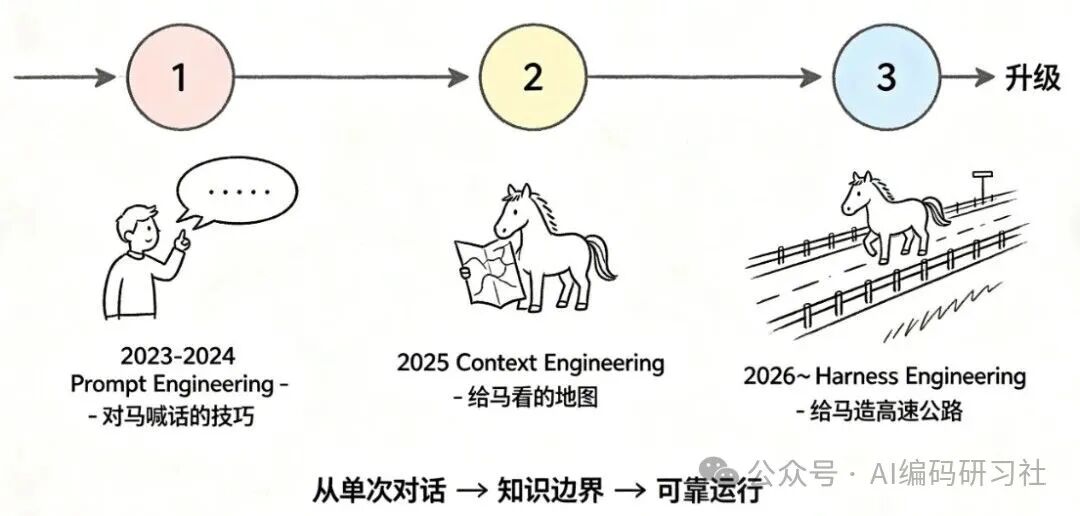
第一阶段:Prompt Engineering(2023-2024)
核心问题:怎么把话说清楚
优化的是输入措辞。解决的是单次对话质量。
就像对马喊话的技巧——你得知道怎么说,马才能听懂。
但这远远不够。
第二阶段:Context Engineering(2025)
核心问题:怎么给AI喂信息
优化的是信息输入。解决的是知识边界与幻觉。
就像给马看的地图——你得告诉它往哪走,才不会迷路。
但还是不够。
第三阶段:Harness Engineering(2026~)
核心问题:怎么让Agent可靠工作
优化的是运行环境。解决的是Agent可靠性与可持续性。
就像给马造一条高速公路,配上护栏、限速牌和加油站。
这才是降维打击。
五、Agent为什么会翻车?三种典型失败模式
Anthropic工程师在长时间运行Agent的过程中,总结了三种典型的翻车姿势。
这正是Harness Engineering要解决的核心痛点。


失败模式1:试图一步到位
Agent倾向于在一个会话里把所有功能都做完。
结果是上下文窗口耗尽,留下一堆没有文档的半成品代码。下一个会话启动时,只能花大量时间猜测之前发生了什么。
所以关键不是让AI写得更快,而是让它学会分步执行。
失败模式2:过早宣布胜利
在项目后期,当部分功能已经完成后,Agent会环顾四周,看到已有进展就直接宣布任务完成——即使还有大量功能未实现。
这不是智能,这是偷懒。
失败模式3:过早标记功能完成
在没有明确提示的情况下,Agent写完代码就标记为完成,却没有做端到端测试。单元测试或curl命令通过了不代表功能真正可用。
更危险的是:智能体非常擅长模式复制。
代码库里有什么模式,它就忠实地复制并放大——包括坏模式和架构漂移。这意味着不加约束的Agent会以惊人的速度积累技术债务。
六、驾驭工程的四大护栏
综合OpenAI、Anthropic、LangChain和Martin Fowler的实践,Harness可以归纳为四个核心组件。
我把它们称为四根"护栏"
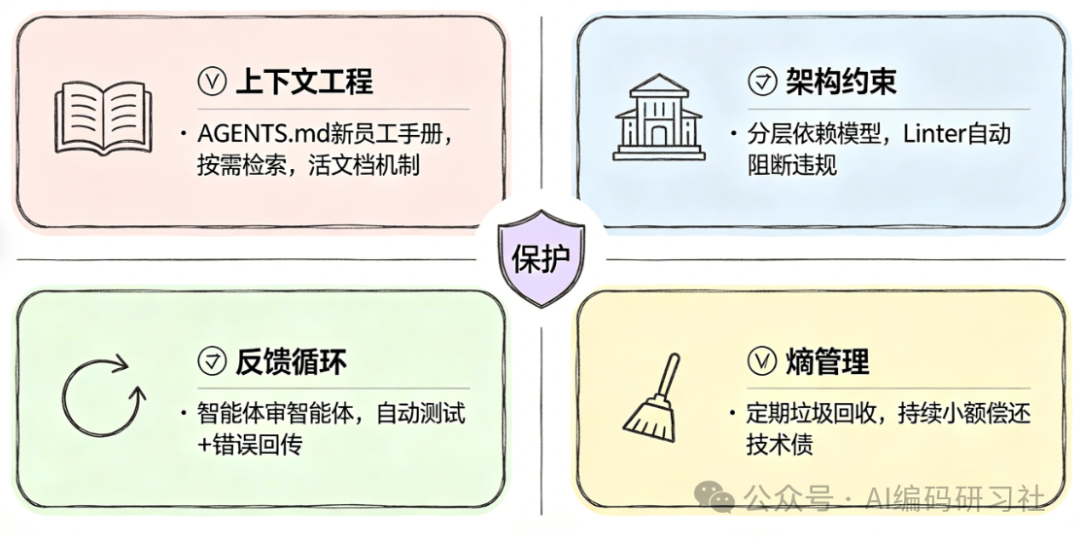
护栏一:上下文工程(Context Engineering)
就像给新员工一本详细的工作手册。
AGENTS.md是AI智能体进入代码仓库时看到的第一份指南。
但这不是一本静态的1000页说明书——上下文是稀缺资源,过多的指导反而会挤掉任务、代码和相关文档的空间,变成陈旧规则的坟场。
更好的做法是:提供一个稳定、小巧的入口点,然后教Agent根据当前任务按需检索和拉取更多的上下文。
Mitchell Hashimoto的Ghostty项目AGENTS.md里,每一行都对应一个历史Agent失败案例。
文档是活的反馈循环,不是静态制品。
护栏二:架构约束(Architecture Constraints)
这就是真正的"缰绳"。
OpenAI团队建立了严格的层级依赖模型:
Types → Config → Repo → Service → Runtime → UI下层不能反向依赖上层。所有架构规则被编码为自定义Linter规则,违反即CI阻止合并——无论代码是人写的还是AI写的。
有个关键细节:Linter的错误信息本身也是上下文工程。
它不只说你违反了规则X,而是解释为什么这个规则存在、正确做法是什么。这样Agent读到错误后就能自我理解并修正,不需要人类介入。
约束不是限制,而是为了让AI跑得更远。
护栏三:反馈循环(Feedback Loop)
智能体审智能体。
传统开发中,人类工程师负责代码审查(Code Review)。在驾驭工程中,这个工作变成了智能体对智能体的方式:Codex在本地审核自身更改,请求额外审查,循环往复直到通过。
反馈循环中的钩子可以运行预定义的测试套件,并在失败时带着错误信息循环回到模型。
如果AI写的测试用例通过了带有Bug的代码,Harness就会判定测试无效,强迫它重新思考测试边界。
这才是真正的自动化质量控制。
护栏四:熵管理(Entropy Management)
垃圾回收机制。
随着时间推移,软件系统会逐渐混乱(熵增),技术债务会积累。
OpenAI采用持续小额偿还的策略,而不是等问题严重时集中处理——他们把这个方法形象地称为"垃圾回收"。
具体措施:定期运行后台Codex任务扫描偏差、更新质量等级、发起针对性重构PR。
此外还有一个专门的Doc-gardening Agent(文档园丁代理),在后台自动扫描文档与代码的同步性。
技术债务就像高息贷款。越早还,代价越小。
七、核心洞见:Agent的每次失败,都是环境设计不完善的信号

Mitchell Hashimoto说过一句话:
"harness engineering is the idea that anytime you find an agent makes a mistake, you take the time to engineer a solution such that the agent will not make that mistake again in the future."
这句话的潜台词是:Agent的每一次失败,都是环境设计不完善的信号。
正确的回应不是换一个更强的模型,而是重新设计它运行的环境。
这才是Harness Engineering的本质。
八、所以,接下来你该做什么?

如果你正在使用AI智能体辅助开发,我建议你做三件事:
第一,建立AGENTS.md。
不要写成百科全书,写成"失败案例库"。每出现一次Agent犯错,就记录一条规则。让文档活起来。
第二,配置架构Linter。
把你的架构约束编码成自动检查规则。让AI在提交前就知道自己哪里错了,而不是等人来review。
第三,设置反馈循环。
让Agent自己审查自己的代码。跑测试,查边界,循环修正。直到通过为止。
这三件事加起来,可能只需要一个周末。
但它可能会彻底改变你和AI协作的方式。
最后,留一个问题给你
当你下次遇到Agent翻车时,你会怎么做?
是换一个更强的模型?
还是停下来想想:我该怎么重新设计它运行的环境?
有时候,好问题比好答案更有价值。
而你,现在已经知道了 Harness Engineering 的核心。
接下来,就看你怎么用了。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 12
12 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)