spring-ali-alibaba多agent时,人工介入(HITL)报错Resume request without a valid checkpoint!
在基于 Spring AI Alibaba 实践多 Agent(智能体)+ 人工介入(HITL,Human-in-the-Loop)功能时,很多开发者会遇到恢复执行阶段抛出IllegalStateException: Resume request without a valid checkpoint!的异常。本文将深度剖析问题根源,并提供可落地的解决方案。
问题现象
在多 Agent 串联执行(如 SequentialAgent 包含多个子 Agent)场景下,当某个子 Agent 触发人工介入审核(HITL)后,前端提交审核结果恢复执行时,系统抛出如下异常:
java.lang.IllegalStateException: Resume request without a valid checkpoint!
at com.alibaba.cloud.ai.graph.GraphRunnerContext.lambda$initializeFromResume$1(GraphRunnerContext.java:99)
at java.base/java.util.Optional.orElseThrow(Optional.java:403)
at com.alibaba.cloud.ai.graph.GraphRunnerContext.initializeFromResume(GraphRunnerContext.java:99)
at com.alibaba.cloud.ai.graph.GraphRunnerContext.<init>(GraphRunnerContext.java:87)
at com.alibaba.cloud.ai.graph.GraphRunner.lambda$run$0(GraphRunner.java:51)
at reactor.core.publisher.FluxDefer.subscribe(FluxDefer.java:46)
at reactor.core.publisher.Flux.subscribe(Flux.java:8891)
at reactor.core.publisher.FluxConcatArray$ConcatArraySubscriber.onComplete(FluxConcatArray.java:238)
先说结论
可以在LlmRoutingAgent等FlowAgent中加入Listener,然后在Listener.after方法中清除人工介入节点
import cn.hutool.core.collection.CollUtil;
import cn.hutool.extra.spring.SpringUtil;
import com.alibaba.cloud.ai.graph.GraphLifecycleListener;
import com.alibaba.cloud.ai.graph.RunnableConfig;
import com.alibaba.cloud.ai.graph.agent.Agent;
import com.alibaba.cloud.ai.graph.agent.flow.agent.FlowAgent;
import com.alibaba.cloud.ai.graph.utils.TypeRef;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
/**
* 清除人工介入节点listener
*
* @author Mright
* @version 1.0
* @since 2026/4/14
*/
public class ClearInterruptionMetadataMataListener implements GraphLifecycleListener {
@Override
public void after(String nodeId, Map<String, Object> state, RunnableConfig config, Long curTime) {
//从Spring中获取所有流程代理
Map<String, FlowAgent> flowAgentMap = SpringUtil.getBeansOfType(FlowAgent.class);
if (CollUtil.isEmpty(flowAgentMap)) {
return;
}
//获取所有子agent
List<Agent> subAgents = flowAgentMap.values().stream().flatMap(flowAgent -> flowAgent.subAgents().stream()).collect(Collectors.toList());
if (CollUtil.isEmpty(subAgents)) {
return;
}
//如果是子agent,则移除人工介入节点
///此处只需移除人工介入节点,无需移除check point,第一是没有提供check point修改的方法,第二是子图在执行时会新创建RunnerConfig,并将checkPoint置空
///参考com.alibaba.cloud.ai.graph.internal.node.SubCompiledGraphNodeAction.apply()和com.alibaba.cloud.ai.graph.agent.ReactAgent.AgentToSubCompiledGraphNodeAdapter.apply()
if (subAgents.stream().map(Agent::name).anyMatch(name -> name.equals(nodeId))) {
//移除人工介入节点
config.getMetadataAndRemove(RunnableConfig.HUMAN_FEEDBACK_METADATA_KEY, new TypeRef<>() {
});
}
}
}
将listner加入父agent
public FlowAgent answerAuditAgent(@Qualifier("openAiChatModel") ChatModel openAiChatModel) {
//compileConfig
CompileConfig compileConfig = CompileConfig.builder()
//清除人工介入信息Listener
.withLifecycleListener(new ClearInterruptionMetadataMataListener())
.build();
return SequentialAgent.builder()
.name("answer audit agent")
.description("评估llm生成的答案,使用Web,并改进响应以确保与真实世界保持一致")
.subAgents(List.of(criticAgent(openAiChatModel), reviserAgent(openAiChatModel)))
.saver(new MemorySaver())
.compileConfig(compileConfig)
.build();
}
参考issues
核心场景复现
智能体配置结构
本文以「答案审核场景」为例,配置两个子 Agent(编辑 Agent、调查 Agent),并通过 SequentialAgent 顺序执行:
@Bean("criticAgent")
public ReactAgent criticAgent(@Qualifier("openAiChatModel") ChatModel openAiChatModel) {
WebSearchTool webSearchTool = new WebSearchTool();
return ReactAgent.builder()
.model(openAiChatModel)
.tools(webSearchTool.getFunctionToolCallback())
.instruction(CRITIC_PROMPT_WORDS)
.description("专业编辑智能体,尽量减少对答案文本的修改,使其准确,同时保持整体结构、风格和长度与原文相似")
.name("critic agent")
.hooks(new CriticAgentModelHook(), new CriticAgentHook(), new HumanInTheLoopHook.Builder()
.approvalOn(webSearchTool.getToolName(), ToolConfig.builder()
.description("需要授权执行网页搜索")
.build())
.build())
.outputKey("critic_agent_output")
.saver(new MemorySaver())
.build();
}
@Bean("reviserAgent")
public ReactAgent reviserAgent(@Qualifier("openAiChatModel") ChatModel openAiChatModel) {
return ReactAgent.builder()
.name("reviser agent")
.model(openAiChatModel)
.description("专业的调查记者,擅长批判性思维和在高度可信的出版物上发表之前核实信息")
.instruction(REVISER_PROMPT_WORDS)
.hooks(new ReviserAgentModelHook(), new ReviserAgentHook())
.outputKey("reviser_agent_output")
.saver(new MemorySaver())
.build();
}
@Bean("answerAuditAgent")
public FlowAgent answerAuditAgent(@Qualifier("openAiChatModel") ChatModel openAiChatModel) {
return SequentialAgent.builder()
.name("answer audit agent")
.description("评估llm生成的答案,使用Web,并改进响应以确保与真实世界保持一致")
.subAgents(List.of(criticAgent(openAiChatModel), reviserAgent(openAiChatModel)))
.saver(new MemorySaver())
.build();
}
恢复执行的代码如下
/**
* 人工审核后恢复执行。
*/
@CrossOrigin(origins = "*")
@PostMapping(value = "/agent/stream/answerAudit/approval", consumes = MediaType.APPLICATION_JSON_VALUE, produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public Flux<ServerSentEvent<String>> resumeAfterApproval(@RequestBody ApprovalRequest request) {
try {
...
// 构建可恢复执行的RunnableConfig
RunnableConfig runnableConfig = RunnableConfig.builder()
.threadId(threadId)
.addHumanFeedback(updatedInterruptionMetadata)
.build();
//执行
return getServerSentEventFlux(answerAuditAgent.stream("", runnableConfig), threadId);
}
恢复执行时的逻辑是,将用户审核的信息组装成InterruptionMetadata,然后添加到RunnableConfig中。
人工介入执行流程分析
这里简化一下整个代码的执行链路,重点看以下几个代码的位置
父agent的Gragh构建
这是SequentialAgent构建核心父子agent节点的逻辑,前面FlowAgent的公共构建逻辑这里不贴出来,其主要链接的逻辑如下:
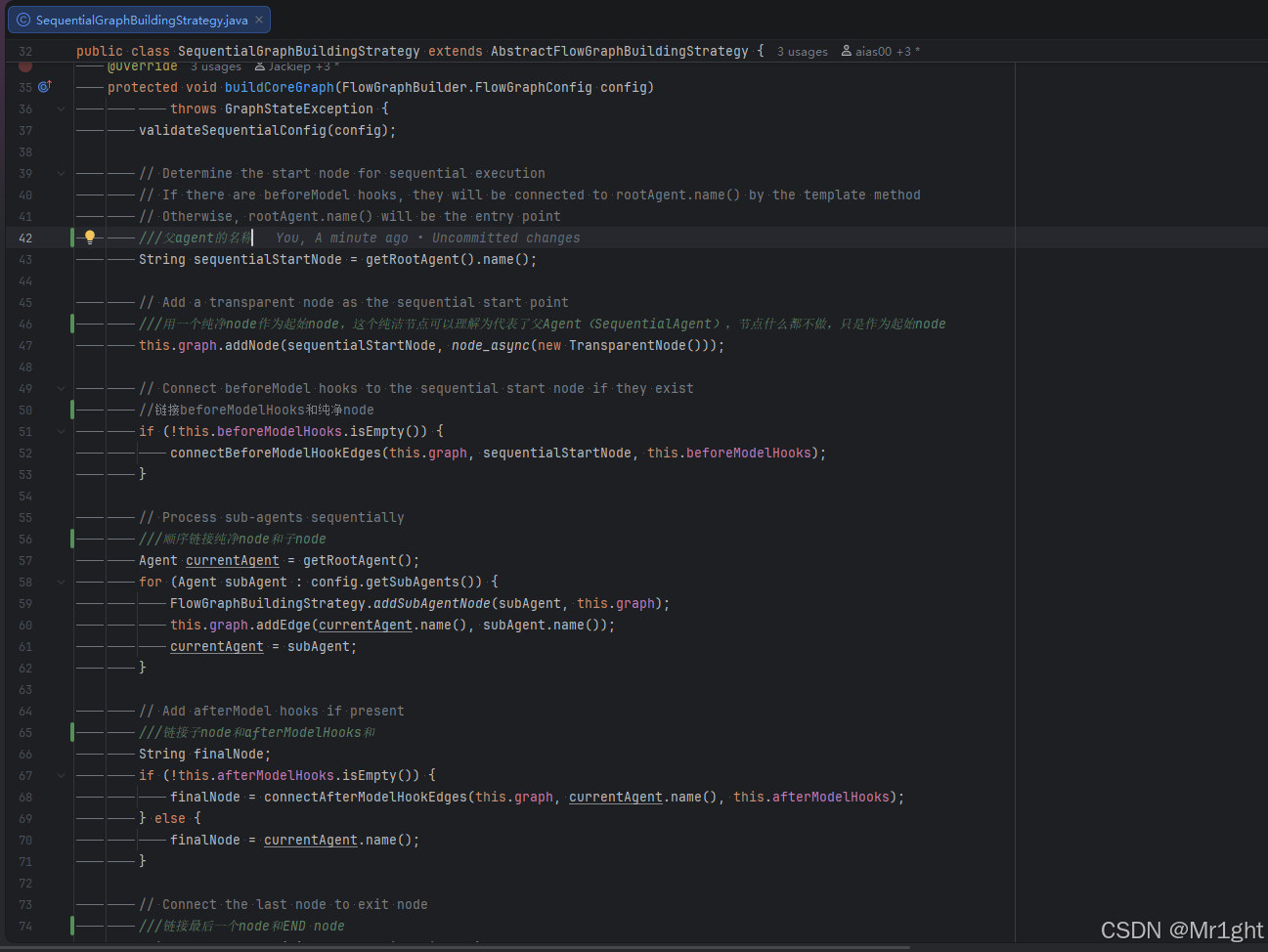
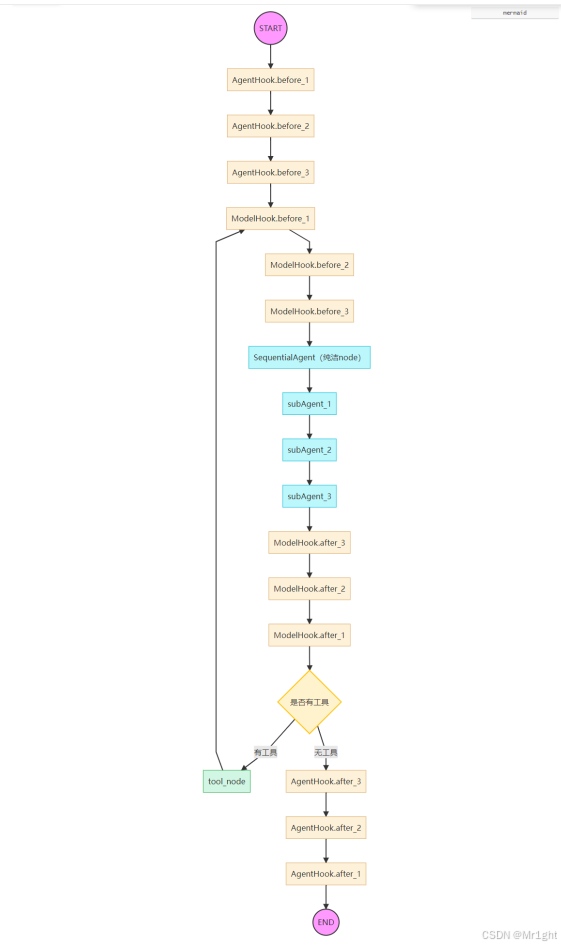
SubAgent构建新的RunnableConfig
这里分别贴出SubCompiledGraphNode和BaseAgent.as_node在执行时的核心代码
public record SubCompiledGraphNodeAction(String nodeId, CompileConfig parentCompileConfig,
CompiledGraph subGraph) implements AsyncNodeActionWithConfig, ResumableSubGraphAction {
@Override
public CompletableFuture<Map<String, Object>> apply(OverAllState state, RunnableConfig config) {
final boolean resumeSubgraph = config.metadata(resumeSubGraphId(nodeId), new TypeRef<Boolean>() {
}).orElse(false);
//config是父agent(SequentialAgent)传递进来的RunnableConfig,此处使用父config的内容重新构建了一个新的RunnableConfig,并清除了
//checkPointId和nextNode和context
RunnableConfig subGraphRunnableConfig = RunnableConfig.builder(config).checkPointId(null).nextNode(null).build();
subGraphRunnableConfig.clearContext();
....
//使用新构建的subGraphRunnableConfig执行此subAgent的核心逻辑
var fluxStream = subGraph.graphResponseStream(state, subGraphRunnableConfig);
....
return future;
}
}
BaseAgent分两类
A2ANode和ReactAgent
public AgentToSubCompiledGraphNodeAdapter(String nodeId, boolean includeContents, boolean returnReasoningContents,
CompiledGraph childGraph, String instruction, CompileConfig parentCompileConfig) {
this.nodeId = nodeId;
this.includeContents = includeContents;
this.returnReasoningContents = returnReasoningContents;
this.instruction = instruction;
this.childGraph = childGraph;
this.parentCompileConfig = parentCompileConfig;
}
@Override
public Map<String, Object> apply(OverAllState parentState, RunnableConfig config) throws Exception {
final boolean resumeSubgraph = config.metadata(resumeSubGraphId(nodeId), new TypeRef<Boolean>() {}).orElse(false);
//构建子agent的RunnableConfig
RunnableConfig subGraphRunnableConfig = getSubGraphRunnableConfig(config);
...
//使用新构建的subGraphRunnableConfig执行此subAgent的核心逻辑
subGraphResult = childGraph.graphResponseStream(stateForChild, subGraphRunnableConfig);
...
}
/**
* 构建子agent的RunnableConfig
**/
private RunnableConfig getSubGraphRunnableConfig(RunnableConfig config) {
//config是父agent(SequentialAgent)传递进来的RunnableConfig,此处使用父config的内容重新构建了一个新的RunnableConfig,并 //清除了checkPointId和nextNode和context
RunnableConfig subGraphRunnableConfig = RunnableConfig.builder(config)
.checkPointId(null)
.nextNode(null)
.addMetadata("_AGENT_", subGraphId(nodeId)) // subGraphId is the same as the name of the agent that created it
.build();
subGraphRunnableConfig.clearContext();
...
return subGraphRunnableConfig;
}
}
}
public class A2aNodeActionWithConfig implements NodeActionWithConfig {
@Override
public Map<String, Object> apply(OverAllState state, RunnableConfig config) throws Exception {
//构建子agent的RunnableConfig
RunnableConfig subGraphRunnableConfig = getSubGraphRunnableConfig(config);
if (streaming) {
AsyncGenerator<NodeOutput> generator = createStreamingGenerator(state, subGraphRunnableConfig);
// Convert AsyncGenerator to Flux using the new toFlux() method
Flux<GraphResponse<NodeOutput>> flux = toFlux(generator);
return Map.of(StringUtils.hasLength(this.outputKeyToParent) ? this.outputKeyToParent : "messages", flux);
}
else {
String requestPayload = buildSendMessageRequest(state, subGraphRunnableConfig);
String resultText = sendMessageToServer(this.agentCard, requestPayload);
Map<String, Object> resultMap = autoDetectAndParseResponse(resultText);
Map<String, Object> result = (Map<String, Object>) resultMap.get("result");
String responseText = extractResponseText(result);
return Map.of(this.outputKeyToParent, responseText);
}
}
private RunnableConfig getSubGraphRunnableConfig(RunnableConfig config) {
if (shareState) {
return config;
}
//config是父agent(SequentialAgent)传递进来的RunnableConfig,此处使用父config的内容重新构建了一个新的RunnableConfig,并 //清除了checkPointId和nextNode
return RunnableConfig.builder(config)
.threadId(config.threadId()
.map(threadId -> format("%s_%s", threadId, subGraphId()))
.orElseGet(this::subGraphId))
.nextNode(null)
.checkPointId(null)
.build();
}
}
父RunnableConfig传递了metadata到子RunnableConfig
可以看到三种构建子图的方式,都是新构建了RunnableConfig,并使用了父RunnableConfig的配置。这个时候就会把父RunnableConfig的metadata传递到子RunnableConfig中
public final class RunnableConfig implements HasMetadata<RunnableConfig.Builder> {
//RunnableConfig的builder
Builder(RunnableConfig config) {
//调用super构造参数赋值metadata
super(requireNonNull(config, "config cannot be null!").metadata);
this.threadId = config.threadId;
this.checkPointId = config.checkPointId;
this.nextNode = config.nextNode;
this.streamMode = config.streamMode;
this.store = config.store;
this.context = new ConcurrentHashMap<>(config.context);
}
//
protected Builder(Map<String, Object> metadata) {
//RunnableConfig.Builder的super构造
if (metadata != null && !metadata.isEmpty()) {
this.metadata = new HashMap<>(metadata);
}
}
}
中断逻辑
public class NodeExecutor extends BaseGraphExecutor {
/**
* Executes a node and handles its result.
* @param context the graph runner context
* @param resultValue the atomic reference to store the result value
* @return Flux of GraphResponse with node execution result
*/
private Flux<GraphResponse<NodeOutput>> executeNode(GraphRunnerContext context,
AtomicReference<Object> resultValue) {
try {
context.setCurrentNodeId(context.getNextNodeId());
String currentNodeId = context.getCurrentNodeId();
AsyncNodeActionWithConfig action = context.getNodeAction(currentNodeId);
if (action == null) {
return Flux.just(GraphResponse.error(RunnableErrors.missingNode.exception(currentNodeId)));
}
if (action instanceof InterruptableAction) {
//如果是中断节点
context.getConfig().metadata(RunnableConfig.STATE_UPDATE_METADATA_KEY).ifPresent(updateFromFeedback -> {
if (updateFromFeedback instanceof Map<?, ?>) {
context.mergeIntoCurrentState((Map<String, Object>) updateFromFeedback);
} else {
throw new RuntimeException();
}
});
//判断是否需要中断,调用的是InterruptableAction.interrupt方法,如果需要的话,会中断,会直接返回结束,并将InterruptionMetadata的内容返回
Optional<InterruptionMetadata> interruptMetadata = ((InterruptableAction) action)
.interrupt(currentNodeId, context.cloneState(context.getCurrentStateData()), context.getConfig());
if (interruptMetadata.isPresent()) {
resultValue.set(interruptMetadata.get());
return Flux.just(GraphResponse.done(interruptMetadata.get()));
}
}
context.doListeners(NODE_BEFORE, null);
//执行node的核心逻辑
CompletableFuture<Map<String, Object>> future = action.apply(context.getOverallState(),
context.getConfig());
//执行后的处理
return Mono.fromFuture(future)
.flatMapMany(updateState -> handleActionResult(context, updateState, resultValue))
.onErrorResume(error -> {
context.doListeners(ERROR, new Exception(error));
return Flux.just(GraphResponse.error(error));
});
}
catch (Exception e) {
return Flux.just(GraphResponse.error(e));
}
}
}
public class HumanInTheLoopHook extends ModelHook implements AsyncNodeActionWithConfig, InterruptableAction {
/**
* 判断有无需要审核项和审核信息
*
* @param nodeId The identifier of the current node being processed.
* @param state The current state of the agent.
* @param config The runnable configuration.
* @return
*/
@Override
public Optional<InterruptionMetadata> interrupt(String nodeId, OverAllState state, RunnableConfig config) {
AssistantMessage lastMessage = getLastAssistantMessage(state);
if (lastMessage == null || !lastMessage.hasToolCalls()) {
return Optional.empty();
}
//判断是否有审核信息
Optional<Object> feedback = config.metadata(RunnableConfig.HUMAN_FEEDBACK_METADATA_KEY);
if (feedback.isPresent()) {
if (!(feedback.get() instanceof InterruptionMetadata)) {
throw new IllegalArgumentException("Human feedback metadata must be of type InterruptionMetadata.");
}
//校验是否有审核结果
if (!validateFeedback((InterruptionMetadata) feedback.get(), lastMessage.getToolCalls())) {
//没有审核结果的逻辑,则InterruptionMetadata并返回
return buildInterruptionMetadata(state, lastMessage);
}
return Optional.empty();
}
// 2. If last message is AssistantMessage
//构建InterruptionMetadata
return buildInterruptionMetadata(state, lastMessage);
}
///构建InterruptionMetadata
private Optional<InterruptionMetadata> buildInterruptionMetadata(OverAllState state, AssistantMessage lastMessage) {
//是否需要中断
boolean needsInterruption = false;
InterruptionMetadata.Builder builder = InterruptionMetadata.builder(Hook.getFullHookName(this), state);
for (AssistantMessage.ToolCall toolCall : lastMessage.getToolCalls()) {
//如果本次需要调用的tool中包含需要人工介入的工具类,则构建审核信息并判定为需要审核,然后返回
if (approvalOn.containsKey(toolCall.name())) {
ToolConfig toolConfig = approvalOn.get(toolCall.name());
String description = toolConfig.getDescription();
String content = "The AI is requesting to use the tool: " + toolCall.name() + ".\n"
+ (description != null ? ("Description: " + description + "\n") : "")
+ "With the following arguments: " + toolCall.arguments() + "\n"
+ "Do you approve?";
// TODO, create a designated tool metadata field in InterruptionMetadata?
builder.addToolFeedback(ToolFeedback.builder().id(toolCall.id())
.name(toolCall.name()).description(content).arguments(toolCall.arguments()).build())
.build();
needsInterruption = true;
} else {
builder.addToolsAutomaticallyApproved(toolCall);
}
}
return needsInterruption ? Optional.of(builder.build()) : Optional.empty();
}
/**
* 校验审核结果
*
* @param feedback 审核结果
* @param toolCalls 最后一次信息的工具调用
* @return
*/
private boolean validateFeedback(InterruptionMetadata feedback, List<AssistantMessage.ToolCall> toolCalls) {
if (feedback == null || feedback.toolFeedbacks() == null || feedback.toolFeedbacks().isEmpty()) {
return false;
}
List<InterruptionMetadata.ToolFeedback> toolFeedbacks = feedback.toolFeedbacks();
// 1. Tool calls in this step that actually require human approval (names defined in approvalOn)
//上次会话中需要被拦截的工具
List<AssistantMessage.ToolCall> toolCallsNeedingApproval = toolCalls.stream()
.filter(tc -> approvalOn.containsKey(tc.name()))
.toList();
// If no tool calls in this step require human approval, validation is trivially satisfied
if (toolCallsNeedingApproval.isEmpty()) {
return true;
}
// 2. For each tool call requiring approval, ensure corresponding feedback exists and its result is non-null
for (AssistantMessage.ToolCall call : toolCallsNeedingApproval) {
//获取审核结果
InterruptionMetadata.ToolFeedback matchedFeedback = toolFeedbacks.stream()
.filter(tf -> tf.getName().equals(call.name())
// Also validate id if ToolFeedback contains id field
&& call.id().equals(tf.getId()))
.findFirst()
.orElse(null);
if (matchedFeedback == null) {
log.warn("Missing feedback for tool {} (id={}); waiting for human input.",
call.name(), call.id());
return false;
}
// Ensure the feedback result is provided
//只要审核结果有,就通过前置校验,到后置校验再校验具体结果
if (matchedFeedback.getResult() == null) {
log.warn("Feedback result for tool {} (id={}) is null; waiting for human input.",
call.name(), call.id());
return false;
}
}
// 3. Optional: log unexpected or extra feedback entries that do not match any pending approval tool
for (InterruptionMetadata.ToolFeedback tf : toolFeedbacks) {
boolean matched = toolCallsNeedingApproval.stream()
.anyMatch(call -> call.name().equals(tf.getName()) && call.id().equals(tf.getId()));
if (!matched) {
log.warn("Ignoring unexpected tool feedback: name={}, id={}", tf.getName(), tf.getId());
}
}
return true;
}
}
保存checkPoint
public class NodeExecutor extends BaseGraphExecutor {
private Flux<GraphResponse<NodeOutput>> handleActionResult(GraphRunnerContext context,
Map<String, Object> updateState, AtomicReference<Object> resultValue) {
try {
...
//保存checkPoint到saver
NodeOutput output = context.buildNodeOutputAndAddCheckpoint(updateState);
...
context.doListeners(NODE_AFTER, null);
// Recursively call the main execution handler
return Flux.just(GraphResponse.of(output))
.concatWith(Flux.defer(() -> mainGraphExecutor.execute(context, resultValue)));
}
catch (Exception e) {
return Flux.just(GraphResponse.error(e));
}
}
}
public class GraphRunnerContext {
/**
* FIXME
* Below are duplicated methods. Need to have a unified way of streaming output
* to end user.
*/
public NodeOutput buildNodeOutputAndAddCheckpoint(Map<String, Object> updateStates) throws Exception {
//添加checkpoint
Optional<Checkpoint> cp = addCheckpoint(currentNodeId, nextNodeId);
//构建NodeOutput
return buildOutput(currentNodeId, updateStates, cp, false);
}
public Optional<Checkpoint> addCheckpoint(String nodeId, String nextNodeId) throws Exception {
//是否有checkpoint的存储器
if (compiledGraph.compileConfig.checkpointSaver().isPresent()) {
//将当前节点、整体信息、下一节点存到checkpoint中
var cp = Checkpoint.builder().nodeId(nodeId).state(cloneState(overallState.data())).nextNodeId(nextNodeId)
.build();
// Force checkPointId to null to ensure we append a new checkpoint instead of
// replacing the current one
//构建新的RunnableConfig
RunnableConfig appendConfig = RunnableConfig.builder(config).checkPointId(null).build();
//将checkpoint添加进存储器
this.config = compiledGraph.compileConfig.checkpointSaver().get().put(appendConfig, cp);
return Optional.of(cp);
}
return Optional.empty();
}
}
中断恢复逻辑
public GraphRunnerContext(OverAllState initialState, RunnableConfig config, CompiledGraph compiledGraph)
throws Exception {
this.compiledGraph = compiledGraph;
this.config = config;
//如果RunnableConfig的metadata中存在HITL的Key或者ckeckPointId不为空,则进入恢复执行逻辑
if (config.metadata(RunnableConfig.HUMAN_FEEDBACK_METADATA_KEY).isPresent() || config.checkPointId().isPresent()) {
initializeFromResume(initialState, config);
} else {
//否则进入start逻辑
initializeFromStart(initialState, config);
}
}
/**
* 恢复执行
*
* @param initialState
* @param config
*/
private void initializeFromResume(OverAllState initialState, RunnableConfig config) {
log.trace("RESUME REQUEST");
//从图中获取缓存saver
var saver = compiledGraph.compileConfig.checkpointSaver()
.orElseThrow(() -> new IllegalStateException("Resume request without a configured checkpoint saver!"));
//从saver中获取checkpoint
//先从存储中获取threadId对应的check point缓存,如果RunnableConfig有checkpoint id,则根据checkpoint id匹配,如果没有,则使用first checkpoint
var checkpoint = saver.get(config)
.orElseThrow(() -> new IllegalStateException("Resume request without a valid checkpoint!"));
var startCheckpointNextNodeAction = compiledGraph.getNodeAction(checkpoint.getNextNodeId());
if (startCheckpointNextNodeAction instanceof ResumableSubGraphAction resumableAction) {
// RESUME FORM SUBGRAPH DETECTED
this.config = RunnableConfig.builder(config)
.checkPointId(null) // Reset checkpoint id
.addMetadata(resumableAction.getResumeSubGraphId(), true) // add metadata for
// sub graph
.build();
this.config.clearContext();
} else {
// Reset checkpoint id
this.config = config.withCheckPointId(null);
}
this.currentNodeId = null;
//使用checkPoint的nodeId作为下一个节点,可以理解为从之前中断的位置恢复执行
this.nextNodeId = checkpoint.getNextNodeId();
//将存储的内容添加到本次的overallState中,可以理解为将之前中断位置的内容恢复
this.overallState = initialState.input(checkpoint.getState());
//恢复节点
this.resumeFrom = checkpoint.getNodeId();
log.trace("RESUME FROM {}", checkpoint.getNodeId());
}
从saver中获取checkPoint的逻辑
public class MemorySaver implements BaseCheckpointSaver {
final Map<String, LinkedList<Checkpoint>> _checkpointsByThread = new HashMap<>();
@Override
public final Optional<Checkpoint> get(RunnableConfig config) {
try {
return loadOrInitCheckpoints(config, checkpoints -> {
//RunnableConfig中是否有checkPointId,有则匹配并返回
if (config.checkPointId().isPresent()) {
return config.checkPointId()
.flatMap(id -> checkpoints.stream()
.filter(checkpoint -> checkpoint.getId().equals(id))
.findFirst());
}
//config中没有,则取存储的第一个
return getLast(checkpoints, config);
});
}
catch (Exception e) {
throw new RuntimeException(e);
}
}
protected final <T> T loadOrInitCheckpoints(RunnableConfig config,
TryFunction<LinkedList<Checkpoint>, T, Exception> transformer) throws Exception {
_lock.lock();
try {
var threadId = config.threadId().orElse(THREAD_ID_DEFAULT);
//通过RunnableConfig中的threadId查询存储的checkPoint信息
return transformer.tryApply(loadedCheckpoints(config, _checkpointsByThread.computeIfAbsent(threadId, k -> new LinkedList<>())));
}
finally {
_lock.unlock();
}
protected LinkedList<Checkpoint> loadedCheckpoints(RunnableConfig config, LinkedList<Checkpoint> checkpoints) throws Exception {
return checkpoints;
}
}
问题根源深度剖析
1. 核心链路:父→子 Agent 的 RunnableConfig 传递
父 Agent(SequentialAgent)执行时,会为每个子 Agent 创建新的RunnableConfig,但子 Config 会完整复制父 Config 的 Metadata(包括 HITL 相关的HUMAN_FEEDBACK_METADATA_KEY):
// RunnableConfig复制构造器核心逻辑
public final class RunnableConfig implements HasMetadata<RunnableConfig.Builder> {
Builder(RunnableConfig config) {
super(requireNonNull(config, "config cannot be null!").metadata); // 复制Metadata
this.threadId = config.threadId;
this.checkPointId = config.checkPointId;
this.nextNode = config.nextNode;
// 其他字段复制...
}
}
子 Agent 创建新 Config 时(如 SubCompiledGraphNode、ReactAgent、A2aNode),仅清空checkPointId/nextNode,但保留父 Config 的 Metadata:
// 子Agent构建新Config示例(SubCompiledGraphNode)
RunnableConfig subGraphRunnableConfig = RunnableConfig.builder(config)
.checkPointId(null)
.nextNode(null)
.build();
subGraphRunnableConfig.clearContext();
2. 恢复执行的判断逻辑
GraphRunnerContext初始化时,若检测到 Config 中包含HUMAN_FEEDBACK_METADATA_KEY(人工审核标识)或checkPointId,则进入「恢复执行流程」:
public GraphRunnerContext(OverAllState initialState, RunnableConfig config, CompiledGraph compiledGraph) {
if (config.metadata(HUMAN_FEEDBACK_METADATA_KEY).isPresent() || config.checkPointId().isPresent()) {
initializeFromResume(initialState, config); // 恢复流程
} else {
initializeFromStart(initialState, config); // 全新执行
}
}
恢复流程会从Saver中读取当前threadId对应的checkpoint:
private void initializeFromResume(OverAllState initialState, RunnableConfig config) {
var saver = compiledGraph.compileConfig.checkpointSaver()
.orElseThrow(() -> new IllegalStateException("无Checkpoint Saver配置!"));
// 关键:从Saver中获取checkpoint,获取不到则抛出核心异常
var checkpoint = saver.get(config)
.orElseThrow(() -> new IllegalStateException("Resume request without a valid checkpoint!"));
// 后续恢复节点/状态逻辑...
}
3. 报错本质:Metadata「污染」子 Agent
当第一个子 Agent(critic agent)完成人工审核恢复执行后,父 Config 中的HUMAN_FEEDBACK_METADATA_KEY会被传递到第二个子 Agent(reviser agent)的 Config 中。
此时第二个子 Agent 初始化GraphRunnerContext时,会误判为「恢复执行」,但该子 Agent 的Saver中并无对应的checkpoint(因为它从未触发过中断 / 保存),最终抛出Resume request without a valid checkpoint!。
核心总结
父 Agent 的 HITL Metadata 会传递给所有子 Agent → 非中断子 Agent 误进入恢复流程 → 无对应 checkpoint → 报错。
解决方案
核心思路
看源码可以发现,作者是在node执行的多个节点加上了listner的,而我们可以在父agent的Listener.after中加入判断,在每个子agent node执行完后,都清除一次父agent中的RunnableConfig.HUMAN_FEEDBACK_METADATA_KEY,就不会导致恢复内容污染下一个子agent了
/**
* Handles the action result and returns appropriate response.
* @param context the graph runner context
* @param updateState the updated state from the action
* @param resultValue the atomic reference to store the result value
* @return Flux of GraphResponse with action result handling
*/
private Flux<GraphResponse<NodeOutput>> handleActionResult(GraphRunnerContext context,
Map<String, Object> updateState, AtomicReference<Object> resultValue) {
...
//保存checkPoint到saver
NodeOutput output = context.buildNodeOutputAndAddCheckpoint(updateState);
//执行Listener.after
context.doListeners(NODE_AFTER, null);
...
}
关键说明
- 监听器的
after方法在每个节点执行完成后触发,精准清除子 Agent 对应的 HITL Metadata; - 子 Agent 执行时会重新创建
RunnableConfig并清空checkPointId,无需额外处理; - 仅清除父 Agent 的 Metadata,不影响子 Agent 自身的执行逻辑。
思考:
1.使用AgentHook.after?
可不可以在子agent中加入AgentHook.after对RunnableConfig.HUMAN_FEEDBACK_METADATA_KEY进行清理?
答案是:不可以
因为父agent的RunnableConfig和子agent的RunnableConfig并不共享,而AgentHook.after只能对子agent的matadata进行操作,不能做到清空父agent中的RunnableConfig.HUMAN_FEEDBACK_METADATA_KEY
2.使用AgentHook.before?
可不可以在子agent中加入AgentHook.before对RunnableConfig.HUMAN_FEEDBACK_METADATA_KEY进行清理?
答案是:不可以
因为报错的位置是在初始化GraphRunnerContext的时候,而node的执行是依赖GraphRunnerContext的,所以报错的时候,AgentHook.before还没有执行
参考资料
- Spring AI Alibaba 官方 Issue:https://github.com/alibaba/spring-ai-alibaba/issues/4466((我已将此方案回复在此issue下方)
- Spring AI Alibaba 多 Agent 执行流程源码:
com.alibaba.cloud.ai.graph包核心类(GraphRunnerContext、RunnableConfig、NodeExecutor等)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)