人类算力的物理边界
引言
2025年,如果你站在美国硅谷的街头,或者走进中国的科技园,你会感觉到空气中都弥漫着一种焦躁的电流声。那是无数GPU全速运转的轰鸣,也是金钱在高温中剧烈燃烧的声音。
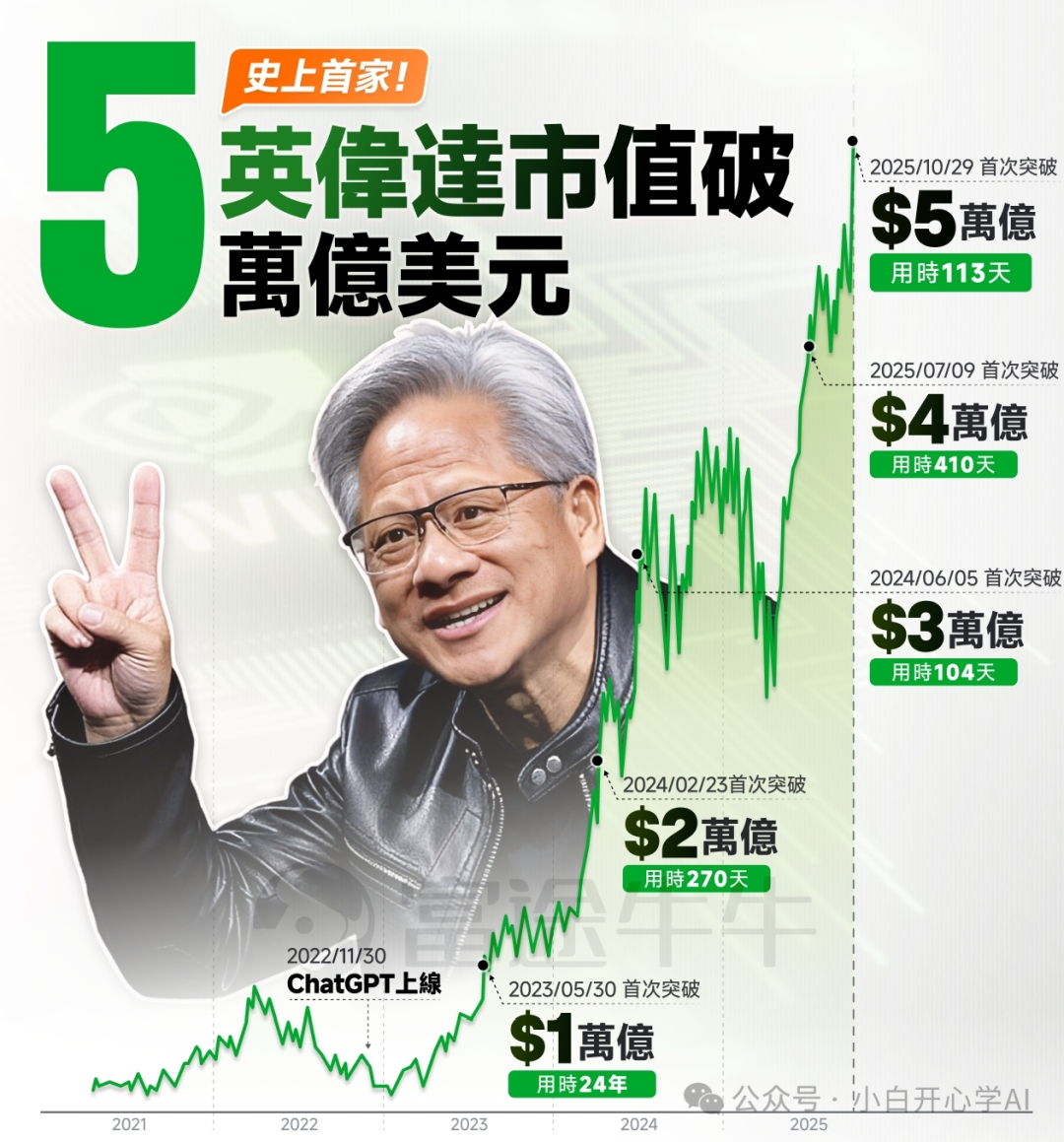
在这个算力即权力的时代,英伟达的市值突破了5万亿美元,GB300显卡成了比黄金更硬的通货,甚至被当成了贷款的抵押物。
从OpenAI到Meta,从字节到华为,所有的科技巨头都在进行一场史无前例的军备竞赛。
新闻标题里充斥着百万卡集群、十万亿参数这样的宏大叙事,仿佛只要我们堆叠足够多的显卡,连接足够粗的网线,那个全知全能的AGI(通用人工智能)就会在下一秒钟,从机房的轰鸣声中自然涌现。
但在这种狂热的表象下,我嗅到了一种深层的、近乎病态的焦虑。
这种焦虑首先来自于时间。
你知道为什么硅谷愿意开出千万美元的年薪,去争抢一个顶级的AI科学家吗?是他们真的那么值钱吗?
不,是因为他们手里的那些GPU实在是太贵了,而且贬值得太快了。
想象一下,你花5亿美元搭建了一个H100集群。然而,哪怕你什么都不做,仅仅是把它们放在那里,每一秒钟,它们的价值都在以惊人的速度蒸发。18个月后,当下一代B200问世,你手里这些曾经的皇冠明珠,就会瞬间沦为算力低下的电子废铁。
这是一场与摩尔定律和财务规则的赛跑。
资本必须雇佣世界上最聪明的大脑,不惜一切代价,让这些昂贵的硅基芯片24小时全负荷运转,试图在它们变得一文不值之前,榨干每一滴算力,通过模型训练把电费和折旧转化成智能。
在这场游戏中,千万年薪的人类科学家,不过是用来伺候这些硅基怪兽、防止它们折旧亏本的高级保姆罢了。
但这还不是最疯狂的。如果说资本的焦虑是为了利润,那么大国和大厂的焦虑,则是为了生存。
你可能会问,投入几百上千亿美元去训练一个模型,真的能赚回来吗?
对于谷歌、微软、字节、阿里等大厂,对于中美两个超级大国来说,回报率这个词已经失效了。
这就好比当年的曼哈顿计划或者阿波罗登月。
没有人会去计算原子弹爆炸的瞬间能产生多少GDP,也没有人会问登上月球的第一步能带来多少广告收入。
因为这是一张通往未来的入场券。
在这场AI军备竞赛中,没有第二名。要么成为定义规则的神,要么成为被技术降维打击的凡人。
谁也无法承受在AI时代缺席的代价。那种恐惧,是对被时代抛弃、被对手碾压的终极恐惧。
正是这种不计代价的生存恐惧,和争分夺秒的折旧焦虑,共同交织成了一股巨大的洪流,裹挟着数以万亿计的资金、能源和最顶尖的人类智慧,疯狂地涌向同一个狭窄的出口。

边界条件
但是,作为一名计算流体力学(CFD)研究者以及和现实世界搏斗过十几年的工程师,当我看着这些指数级增长的曲线时,我却感到一阵困惑。
因为在物理世界里,没有任何一种指数增长是可以无限持续的。
在那个由纳维-斯托克斯方程(N-S 方程)统治的流体世界里,我学会的最重要的一课就是,边界条件决定一切。
当一架飞机试图突破音障时,空气阻力不会线性增加,而是会形成激波,阻力瞬间暴涨。
流体不能无限加速,系统不能无限扩张。任何物理系统,当它逼近某种极限时,都会遭遇客观的惩罚机制。
所以,当我们剥离掉那些眼花缭乱的商业包装,把视线从股价K线图移开,深入到芯片的微观结构,深入到电子在晶体管中跃迁的物理过程时,你会看到一幅完全不同的景象。
那不是一片无限广阔的蓝海,而是一条正在逼近悬崖的独木桥。

物理边界
当我戴着物理学的眼镜,去审视今天的 AI 算力系统时,我看到的不再是那些令人兴奋的增长曲线,而是一条条正在变得湍急、拥堵、甚至即将沸腾的数据洪流。
这股洪流正以前所未有的速度,撞向五堵看不见的、由宇宙基本法则构筑的叹息之墙:
第一堵墙,是光速的镣铐。
信号在硅片和光纤中传输是有延迟的。在纳秒级的芯片世界里,30厘米就是光速的永恒。
这道墙,锁死了集群的物理规模。
第二堵墙,是热力学的诅咒。
芯片上的电子在疯狂跳动中产生的热量,正在逼近材料融化的临界点。这也是为什么数据中心正变得像核电站一样热。
这道墙,锁死了单点算力的功率密度。
第三堵墙,是维度的囚笼。
摩尔定律已死,平面微缩走到尽头。我们被迫向3D空间堆叠,但原子不能无限挤压。
这道墙,锁死了晶体管的几何上限。
第四堵墙,是香农的极限。
我们在用64位浮点数模拟人脑的模糊信号,这本身就是巨大的浪费。信息传输的效率是有上限的,除非我们重新定义精度。
这道墙,锁死了数据传输的效率。
第五堵墙,是收敛的黑洞。
当模型参数达到十万亿,训练过程就像是在一个高维的、充满噪声的曲面上寻找一粒沙。统计力学告诉我们,随机性可能会吞噬一切优化。
这道墙,锁死了智能涌现的数学边界。
资本市场在欢呼,因为他们相信Scaling Law(缩放定律)可以永远延续。
而工程师在颤抖,因为他们看到了Roofline Model(屋顶线模型)上,那些正在逼近的、由物理和数学共同编织的绝对边界。
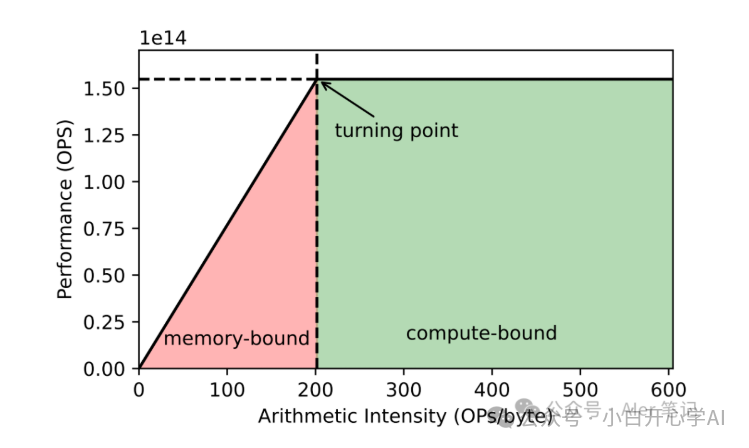
屋顶线模型
2009年,计算机科学家大卫·帕特森(David Patterson,2017年图灵奖得主)及其团队提出了一个极简的屋顶线模型(Roofline Model)。
这个模型听起来很学术,但它的本质,其实讲述了一个在饭店吃饭的故事。
忘记那些枯燥的TFLOPS和GB/s,我们把GPU想象成一家饭店,把算力和带宽变成我们最熟悉的吃饭场景。
在这个饭店里,决定你吃得爽不爽(性能高低)的,其实就是两个因素的博弈:
一是你吃饭的速度(计算核心的能力);
二是服务员上菜的速度(内存带宽的能力)。
这就会出现两种截然不同的情况:
情况一:烤全羊 vs 小甜点
-
大模型训练:
这就像是给你上了一道烤全羊。
服务员只跑了一趟,把羊端上来(数据搬运一次),但你要坐在那里啃上半天才能吃完(计算量巨大,反复迭代)。
这时候,服务员闲在旁边玩手机,你吃得满头大汗。
这就是算力瓶颈 (Compute-Bound)。
在这种情况下,上菜速度(带宽)再快也没用,限制你的是你吃羊肉的能力(芯片算力)。
谁的牙口好(H100 vs 910C),谁就先吃完走人。
-
大模型推理 :
这就像是吃法式前菜小甜点。
盘子很大,中间只有一口就能吞掉的小点心。
你一口就吃没了(计算极快),然后不得不拿着叉子,眼巴巴地等着服务员跑去厨房端下一盘。
这就是带宽瓶颈(Memory-Bound)。
在这种情况下,你的牙口再好(算力再强)也没用,因为你99%的时间都在等菜。
限制你的是服务员的腿脚利不利索(显存带宽)。
情况二:爆满的餐厅(GPU集群)
更糟糕的是,当我们把视角放大到万卡集群时,就像饭店里坐满了1万个客人。
这时候,厨房(显存)到餐桌(计算核心)的距离变远了,过道(互联带宽)变得拥挤不堪。
如果服务员端着菜被堵在路上,哪怕那是烤全羊,客人也得饿着肚子等。
这就是为什么英伟达要搞NVLink,华为要搞全光互联。
他们本质上都是在把饭店的过道修成高速公路,确保每一道菜都能在变凉之前,送到客人的餐桌上。

架构
现在,让我们把目光从令人眼花缭乱的GPU参数表上移开,看一眼芯片的物理本质。
过去五十年,我们一直信奉摩尔定律,相信只要把晶体管做得足够小,性能就能无限翻倍。
但现在,这列高速列车已经撞上了原子尺寸的物理墙。
台积电的3nm工艺,栅极宽度已经只有十几个硅原子的厚度。在这个尺度下,经典的物理学正在失效,量子隧穿效应开始接管一切。电子不再乖乖地在通道里流动,而是像幽灵一样穿墙而过,导致严重的漏电和发热。
为了对抗这种物理极限,为了维持算力每18个月翻一番的商业神话,英伟达和台积电不得不开始了一种极其暴力、也极其昂贵的堆料游戏。
你看B200,那真的是一颗芯片吗?
不,它是两颗被强行拼在一起的芯片,加上8颗像高楼大厦一样堆叠起来的HBM(High Bandwidth Memory)内存。
它的面积已经大到了光刻机的极限(Reticle Limit),再大一点,我们就造不出来了。
它的功耗高达1000W!这是什么概念?一块小小的芯片,发热量相当于你家的一台电吹风。
一个机柜(NVL72)的功耗是120KW!这是什么概念?这相当于一个居民楼的用电量集中在一个衣柜大小的铁盒子里。
为了给它散热,我们甚至不得不把整个服务器泡在液体里。
这难道不是一种讽刺吗?
我们试图创造出像人脑一样智慧的硅基智能,但我们却在用核电站级别的能耗,去模拟一个只需要20W能量(人脑功耗)就能运行的生物神经网络。
我们是在用战术上的极致勤奋,更复杂的封装、更暴力的散热、更昂贵的互联,来掩盖我们在战略上的停滞。
那个残酷的事实是:冯·诺依曼架构没有变,硅基半导体的底层逻辑没有变。
我们并没有找到通往AGI的那条捷径,我们只是在旧的地图上,把油门踩到了油箱爆炸的边缘。
这,就是繁荣背后的危机。

方向
面对这五堵高墙,面对这场看似没有终点的军备竞赛,我们该如何看清未来的方向?
看财报吗?
财报里只有上一季度的利润,那是后视镜里的风景。
看新闻吗?
新闻里充斥着资本的噪音和做市商的狂欢,那是被扭曲的幻象。
在这个充满不确定性的时代,唯一能给我们提供确定性指引的,只有那个冷酷、沉默、却永不撒谎的第一性原理——物理定律。
只有理解了光速,你才能明白为什么华为要死磕全光互联,为什么万卡集群的延迟是如此致命。
只有理解了热力学,你才能看懂为什么液冷是必选项,为什么能效比终将取代峰值算力成为新的王座。
只有理解了空间几何,你才能参透为什么摩尔定律已死,而CoWoS(Chip on Wafer on Substrate)封装和HBM堆叠成为了延续硅基生命的唯一氧气管。
只有理解了信息熵,你才能洞察为什么英伟达敢把精度从FP32一路砍到 FP4,这是一场关于什么才是智能的数学赌博。
只有理解了统计力学,你才能预见为什么单纯增加参数量可能会撞上收敛墙,为什么在那个高维的、充满噪声的Loss曲面上,蛮力终将失效,算法的优雅才是唯一的救赎。
真正的算力革命,绝不是把GPU做得更大、更热、更贵。
未来,真正的革命,必然是对计算这个概念本身的重新定义。
在这个系列里,我们不讨论明天的股价,也不预测谁是最后的赢家。
我只想邀请你,剥离掉那些商业的包装,和我一起,带上工程师的卷尺,去丈量这五堵墙的厚度,去触摸人类算力的真实边界。
让我们回到物理学,去寻找那个唯一的答案。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 34
34 0
0- 0



 已为社区贡献27条内容
已为社区贡献27条内容

所有评论(0)