第11节:OpenLLM 性能优化【从理论到实战】
文章目录
前言
在生产环境中部署和服务大型语言模型(LLM)时,性能是决定用户体验、成本和系统可扩展性的关键因素。未经优化的LLM服务通常会面临显存爆炸、响应迟缓、资源利用率低下等挑战。本文将深入探讨OpenLLM的性能优化全链路,从瓶颈定位、核心优化技巧到生产级稳定性保障,提供一套可落地的实战方案。我们将结合理论分析、代码实操和性能数据对比,旨在帮助开发者和架构师构建高性能、高可用的LLM服务。
1.1 性能瓶颈分析与定位
在着手优化之前,准确识别和定位性能瓶颈是至关重要的第一步。盲目优化往往事倍功半。
常见性能瓶颈
-
显存不足 (Out of Memory, OOM)
- 现象:服务启动失败,或推理过程中进程崩溃,日志报错
CUDA out of memory。 - 根源:模型参数、激活值、KV缓存等总内存占用超出GPU物理显存容量。通常是加载了未经量化的超大模型(如FP16的70B模型),或批处理大小(Batch Size)设置过大。
- 现象:服务启动失败,或推理过程中进程崩溃,日志报错
-
推理速度慢 (High Latency)
- 现象:单个请求的响应时间(Time To First Token, TTFT 及生成每个Token的时间)过长。
- 根源:
- 计算瓶颈:模型本身计算量大,GPU算力不足。
- 内存带宽瓶颈:从显存读取模型权重的速度跟不上计算速度,常见于小参数量但访存密集型的场景。
- 输入输出(I/O)瓶颈:处理长上下文时,KV缓存读写、注意力计算开销剧增。
-
GPU利用率低 (Low GPU Utilization)
- 现象:使用
nvidia-smi或监控工具查看,GPU-Util 长期在低水平(如<30%)波动,而CPU或磁盘I/O可能繁忙。 - 根源:
- 数据加载瓶颈:预处理、分词、数据加载到GPU的流水线阻塞。
- 小批量或请求不足:动态批处理未生效,GPU计算核心大量时间处于空闲状态。
- 低效的内核实现:框架或自定义算子的计算内核未充分优化。
- 现象:使用
-
并发能力弱 (Low Throughput)
- 现象:系统能够处理单个请求,但当多个用户同时请求时,总体吞吐量(Tokens per Second)提升有限,甚至所有请求的延迟都大幅增加。
- 根源:
- 缺乏动态批处理:请求被串行处理,GPU计算资源未被复用。
- 服务端过载:请求队列管理不善,未设置合理的限流。
- 资源竞争:多个进程或容器共享GPU资源,引发显存或计算争用。
性能监控工具
1. OpenLLM 内置监控
OpenLLM Server 启动时,默认在指定端口(如 localhost:3000)提供了基础的Prometheus格式指标。
# 启动一个OpenLLM服务,并暴露指标端口
openllm start facebook/opt-1.3b --port 3000 --adapter-id my-adapter
# 指标默认可通过 /metrics 端点获取
curl http://localhost:3000/metrics
关键内置指标示例:
openllm_num_requests_total:总请求数。openllm_num_requests_inprogress:处理中的请求数。openllm_request_duration_seconds:请求持续时间分布。
2. Prometheus + Grafana 配置与指标分析
生产环境推荐使用完整的监控栈。
- Prometheus 配置 (
prometheus.yml)
global:
scrape_interval: 15s
scrape_configs:
- job_name: 'openllm'
static_configs:
- targets: ['your-openllm-host:3000'] # 替换为你的OpenLLM服务地址和端口
metrics_path: '/metrics'
Prometheus会定期从OpenLLM服务的/metrics端点拉取数据。
- Grafana 仪表板
导入或创建仪表板,监控以下核心指标:- 资源类:
GPU利用率 (%)、GPU显存占用 (MB)、系统内存、CPU使用率。 - 服务类:
请求率 (QPS)、平均/分位点延迟 (s)、吞吐量 (Tokens/s)、错误率。 - OpenLLM专项:
批处理大小、队列长度、缓存命中率。
- 资源类:
瓶颈定位方法
1. 日志分析
开启OpenLLM的调试日志,获取详细运行时信息。
OPENLLM_DEBUG=1 openllm start ...
关注日志中的时间戳、推理步骤耗时、批处理合并信息、显存分配记录等。
2. 性能指标拆解
将端到端延迟(E2E Latency)拆解,定位耗时主要环节:
总延迟 = 网络延迟 + 预处理延迟 + 计算延迟(推理)+ 后处理延迟
- 计算延迟:进一步拆分为
首Token延迟(TTFT)和每Token延迟。TTFT高通常提示计算初始化或长上下文处理慢;每Token延迟高则可能受生成策略(如采样)或解码计算本身影响。 - GPU利用率监控:结合
nvtop或nvidia-smi dmon工具,观察GPU的sm(流多处理器)利用率和显存带宽利用率。高延迟+低利用率指向I/O或CPU瓶颈;高延迟+高利用率则可能是计算瓶颈。
实战步骤:
- 单请求基准测试:使用低并发,测量单个请求的延迟和资源使用,建立性能基线。
- 压力测试:使用工具(如
locust,wrk)逐步增加并发用户,观察吞吐量、延迟和GPU利用率的变化曲线。当吞吐量达到平台期而延迟急剧上升时,即为系统瓶颈点。 - 指标关联分析:在Grafana中,将GPU利用率曲线与请求率、批处理大小曲线叠加。观察是否“请求增多 -> 批处理增大 -> GPU利用率升高 -> 吞吐量线性增长”的理想关系被打破。
1.2 核心优化技巧实战
在准确定位瓶颈后,我们可以有针对性地实施优化。
模型层面优化
目标是减少模型对显存和计算资源的需求。
1. 量化 (Quantization)
量化是将模型权重和激活值从高精度(如FP32)转换为低精度(如INT8, INT4)的过程,能大幅减少显存占用和内存带宽压力。
- 使用
bitsandbytes进行 4-bit 量化加载
# 安装必要库: pip install transformers accelerate bitsandbytes
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
import torch
# 配置4位量化,使用NF4数据类型并采用双量化以进一步节省内存
bnb_config = BitsAndBytesConfig(
load_in_4bit=True, # 启用4位量化加载
bnb_4bit_quant_type="nf4", # 量化数据类型:NF4(NormalFloat4)或FP4
bnb_4bit_use_double_quant=True, # 启用双量化,对量化参数进行二次量化
bnb_4bit_compute_dtype=torch.bfloat16 # 计算时使用bfloat16,兼顾精度和速度
)
# 加载模型时传入量化配置
model_id = "facebook/opt-1.3b"
model = AutoModelForCausalLM.from_pretrained(
model_id,
quantization_config=bnb_config, # 关键:应用量化配置
device_map="auto", # 自动将模型层分布到可用GPU上
trust_remote_code=True
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
# 推理示例
inputs = tokenizer("中国的首都是", return_tensors="pt").to("cuda:0")
with torch.no_grad():
outputs = model.generate(**inputs, max_new_tokens=50)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
注释:load_in_4bit=True 是核心参数。device_map="auto" 允许模型在多个GPU间自动分配。量化会轻微损失精度,但通常对生成质量影响较小。
2. 模型压缩与蒸馏
- 剪枝 (Pruning):移除模型中冗余的权重(如小权重置零)。可通过
torch.nn.utils.prune或训练后剪枝工具实现。 - 知识蒸馏 (Knowledge Distillation):训练一个较小的“学生”模型来模仿一个大的“教师”模型的行为。Hugging Face的
transformers库对蒸馏有良好支持,但过程需要重新训练。
推理层面优化
目标是提高GPU计算效率和硬件利用率。
1. 动态批处理 (Dynamic Batching) 参数调优
OpenLLM Server 内置了动态批处理功能。优化关键在于调整相关启动参数。
# 启动OpenLLM服务时调整批处理相关参数
openllm start facebook/opt-1.3b \
--port 3000 \
--max-batch-size 16 \ # 最大批处理大小。增大可提升吞吐,但会增加延迟和显存占用
--batch-wait-timeout 0.1 \ # 批处理等待超时(秒)。在延迟和吞吐间权衡。较短时间利于低延迟,较长时间利于高吞吐
--max-concurrent-requests 100 # 最大并发请求数。控制服务负载
调优建议:通过压力测试,观察不同--max-batch-size和--batch-wait-timeout下,吞吐量和P99延迟的变化,找到业务可接受的平衡点。
2. KV缓存优化
自回归生成时,为避免重复计算,先前时间步的Key和Value向量被缓存。优化KV缓存能显著降低长序列生成的内存和计算开销。
- 选择高效的注意力实现:在启动时指定。
flash_attention_2(如果GPU支持) 通常是最快、最省内存的选择。
OPENLLM_BACKEND="vllm" openllm start ... # vLLM后端对PagedAttention有极佳的KV缓存管理
# 或对于transformers后端,在代码中设置
model.config._attn_implementation = "flash_attention_2"
- 调整KV缓存最大长度:根据业务场景中输入输出的最大长度合理设置,避免分配过大缓存。
# 在Hugging Face transformers生成参数中指定
outputs = model.generate(
**inputs,
max_new_tokens=512,
max_length=2048, # 控制总长度,间接影响KV缓存大小
use_cache=True # 确保启用缓存
)
3. 推理流水线设计
对于多GPU或混合CPU/GPU环境,可采用流水线并行(Pipeline Parallelism)将模型的不同层分配到不同设备上。
# 一个简化的流水线并行示例(使用transformers的device_map)
from transformers import AutoModelForCausalLM
import torch
model = AutoModelForCausalLM.from_pretrained(
"bigscience/bloomz-7b1",
device_map={
"transformer.h.0": "cuda:0",
"transformer.h.1": "cuda:0",
"transformer.h.2": "cuda:0",
"transformer.h.3": "cuda:1", # 将后续层分配到另一个GPU
"transformer.h.4": "cuda:1",
"transformer.h.5": "cuda:1",
"lm_head": "cuda:1"
},
torch_dtype=torch.float16,
)
更复杂的流水线调度可借助 DeepSpeed 或 vLLM 等框架。
资源层面优化
1. GPU资源调度
使用容器化(Docker)和编排工具(Kubernetes),结合GPU调度器(如NVIDIA K8s Device Plugin)实现资源的弹性分配和隔离。
2. 多GPU分布式推理
- 张量并行 (Tensor Parallelism):将单个权重矩阵切分到多个GPU上并行计算。适用于单卡无法放下的大模型。
# 使用vLLM启动张量并行推理(2个GPU)
python -m vllm.entrypoints.openai.api_server \
--model facebook/opt-13b \
--tensor-parallel-size 2 \
--served-model-name opt-13b
- 模型并行/流水线并行:如上文所述,将模型的不同部分放置于不同设备。
3. 内存管理优化
- 启用内存池:PyTorch的内存分配器会预留大量显存。对于需要频繁分配释放显存的服务,启用内存池可以提高效率、减少碎片。
# 在服务启动脚本中设置
import torch
torch.cuda.memory._set_allocator_settings('max_split_size_mb:128') # 调整分配器策略
- 及时清理缓存:在请求处理间隔,调用
torch.cuda.empty_cache()释放未使用的缓存。但需注意,频繁调用此函数本身有开销。
优化效果验证
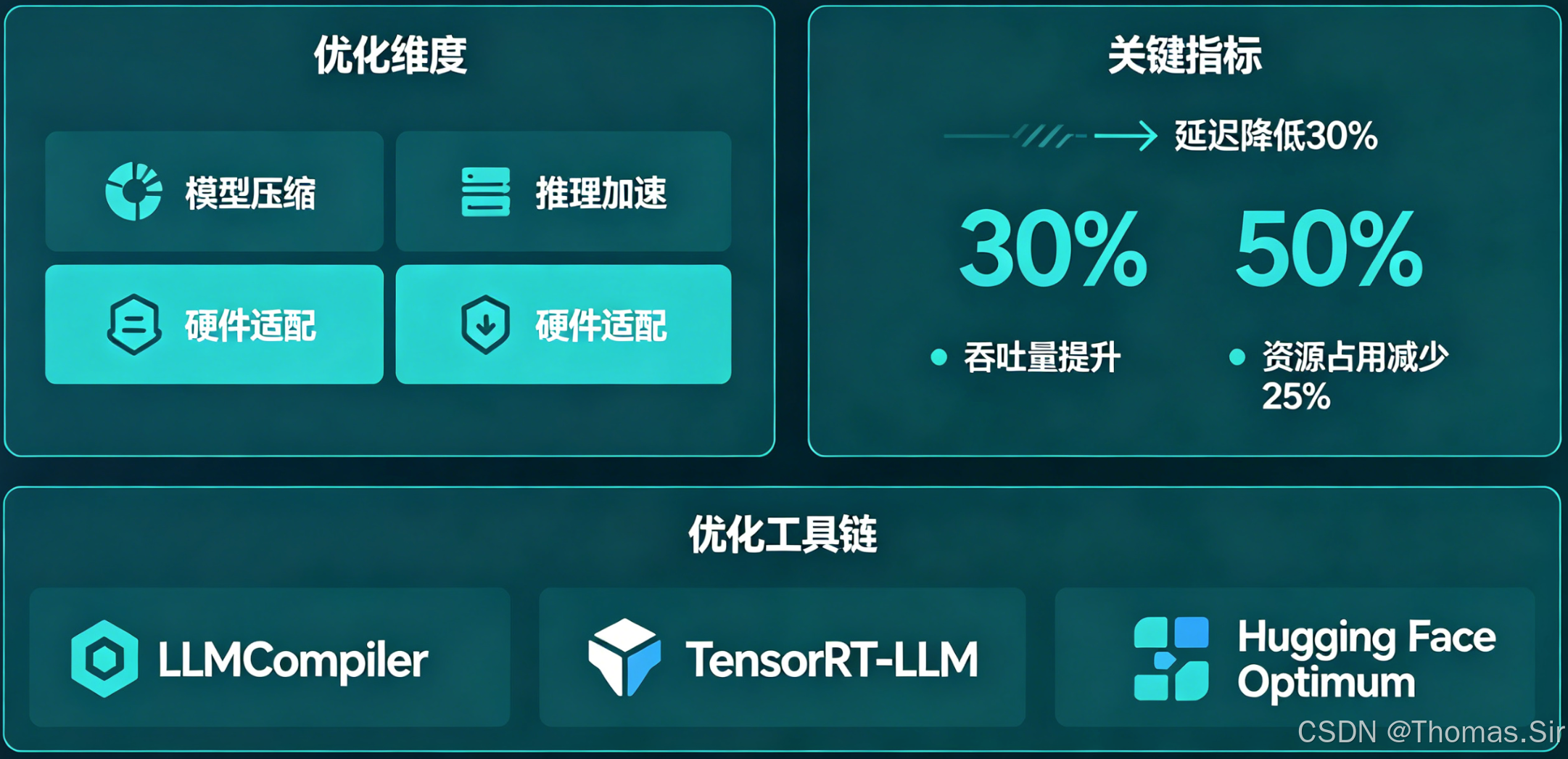
对上述优化策略进行组合测试,并量化其效果。以下为模拟的性能对比数据(基于OPT-2.7B模型,A10 GPU,输入长度256,输出长度128):
| 优化策略 | 显存占用 (GB) | 平均延迟 (ms/Token) | 吞吐量 (Tokens/s) | 备注 |
|---|---|---|---|---|
| 基线 (FP16) | 5.8 | 45 | 22 | 未优化,单请求 |
| + 4-bit 量化 | 3.1 (-46%) | 48 (+6%) | 21 (-5%) | 显存大幅下降,延迟/吞吐微损 |
| + 动态批处理 (size=8) | 3.1 | 52 | 152 (+590%) | 吞吐量获得巨大提升 |
| + vLLM (PagedAttention) | 3.0 | 38 (-16%) | 168 | 延迟降低,吞吐略有提升 |
| 综合优化 (量化+vLLM+批处理) | 3.0 | 41 | 180 (+718%) | 最佳综合表现 |
结论:模型量化是降低部署门槛(显存)的关键;动态批处理是提升吞吐量的最有效手段;使用vLLM等高性能推理引擎能进一步优化内存和计算效率。实践中需根据业务对延迟和吞吐的优先级,选择组合策略。
1.3 生产级稳定性优化
性能达标后,稳定性是服务长期运行的基石。
故障排查与恢复
常见错误与解决方案
-
模型下载失败
- 排查:网络连接、磁盘空间、Hugging Face令牌、模型ID是否正确。
- 解决:配置镜像源、使用离线模型文件(提前
openllm download)、设置重试机制和超时。
-
服务无法访问/启动失败
- 排查:
# 检查端口占用 lsof -i:3000 # 查看服务日志 journalctl -u openllm-service # 检查GPU驱动和CUDA nvidia-smi - 解决:变更端口、检查启动参数(如模型路径)、确保GPU环境正常、检查依赖库版本冲突。
- 排查:
-
推理过程中OOM
- 解决:
- 启用量化。
- 减少
--max-batch-size。 - 限制用户请求的
max_tokens。 - 实现请求的负载丢弃(Load Shedding)策略,当队列过长时拒绝新请求。
- 解决:
高可用配置
-
集群部署
部署多个OpenLLM服务实例,形成集群。可以使用Kubernetes Deployment进行管理。# kubernetes-deployment.yaml 示例片段 apiVersion: apps/v1 kind: Deployment metadata: name: openllm-deployment spec: replicas: 3 # 三个副本 selector: matchLabels: app: openllm template: metadata: labels: app: openllm spec: containers: - name: openllm image: your-openllm-image:tag args: ["start", "facebook/opt-1.3b", "--port", "3000"] ports: - containerPort: 3000 resources: limits: nvidia.com/gpu: 1 -
负载均衡
在服务集群前使用Nginx、HAProxy或K8s Service进行流量分发。# Nginx 配置示例 (nginx.conf 片段) http { upstream openllm_backend { server 10.0.1.10:3000; server 10.0.1.11:3000; server 10.0.1.12:3000; } server { listen 80; location / { proxy_pass http://openllm_backend; proxy_set_header Host $host; } } } -
自动重启与健康检查
- 进程管理器:使用
systemd或supervisord托管OpenLLM进程,配置自动重启。
; supervisord.conf 示例片段 [program:openllm] command=openllm start facebook/opt-1.3b --port 3000 autostart=true autorestart=true stderr_logfile=/var/log/openllm.err.log- K8s健康检查:
# 在K8s Deployment的container配置中添加 livenessProbe: httpGet: path: /healthz # OpenLLM的健康检查端点 port: 3000 initialDelaySeconds: 60 periodSeconds: 10 readinessProbe: httpGet: path: /readyz # OpenLLM的就绪检查端点 port: 3000 initialDelaySeconds: 30 periodSeconds: 5 - 进程管理器:使用
日志与监控体系
-
关键日志配置
- 结构化日志(JSON格式),便于收集和分析。
OPENLLM_LOGGING_FORMAT="json" openllm start ...- 记录关键信息:请求ID、用户标识、模型名称、输入输出长度、耗时、错误码。
-
异常告警
基于Prometheus和Alertmanager设置告警规则。# prometheus-alert-rules.yml groups: - name: openllm_alerts rules: - alert: HighErrorRate expr: rate(openllm_request_failures_total[5m]) / rate(openllm_requests_total[5m]) > 0.05 for: 2m labels: severity: critical annotations: summary: "OpenLLM服务错误率过高" - alert: HighLatency expr: histogram_quantile(0.95, rate(openllm_request_duration_seconds_bucket[5m])) > 5 for: 5m labels: severity: warning annotations: summary: "OpenLLM服务P95延迟过高" -
性能趋势分析
- 在Grafana中建立长期性能仪表盘,追踪每日/每周的请求量、平均延迟、P99延迟、GPU利用率等核心指标的趋势。
- 建立容量规划看板,根据业务增长和性能消耗趋势,预测需要扩容的时间点。
- 关联业务指标(如用户满意度、调用量)与技术性能指标,评估优化工作的实际业务价值。
总结
优化OpenLLM服务的性能是一个从诊断到治疗,再到长期保健的系统性工程。我们首先需要利用专业的监控工具和科学的拆解方法,精准定位性能瓶颈究竟是源于显存、计算、I/O还是并发。随后,模型层面的量化、压缩技术是“瘦身”的基础,能显著降低部署门槛;推理层面的动态批处理、KV缓存优化和流水线设计则是“强心剂”,能极大提升吞吐和资源利用率;资源层面的合理调度是多卡和集群环境下的“扩展术”。
最后,任何优化成果都需要在生产环境的熔炉中检验。通过构建完善的故障恢复机制、高可用架构以及覆盖日志、监控、告警、趋势分析的稳定性保障体系,才能确保高性能的LLM服务能够持续、可靠地创造价值。记住,没有一劳永逸的优化配置,持续的监控、分析和调整,是应对不断变化的业务需求和技术栈演进的不二法门。
🌟 感谢您耐心阅读到这里!
💡 如果本文对您有所启发欢迎:
👍 点赞📌 收藏 📤 分享给更多需要的伙伴。
🗣️ 期待在评论区看到您的想法, 共同进步。
🔔 关注我,持续获取更多干货内容~
🤗 我们下篇文章见~

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 11
11 0
0- 0



 已为社区贡献229条内容
已为社区贡献229条内容

所有评论(0)