RAG分块:四大基准测试告诉你怎么切最靠谱
最近看了一篇博客,主要讲分块的基准测试,挺有意思。
递归拆分 512 tokens、10-20% 重叠,这套看似平庸的配置,跑赢了更聪明的语义分块。
2026 年四项独立基准给出了相同结论。
原文链接:https://blog.premai.io/rag-chunking-strategies-the-2026-benchmark-guide/
一、先说结论
做 RAG 的人大概都经历过这么个阶段:一开始按固定长度切文档,觉得太粗糙,然后换成语义分块,觉得这才智能,结果上线后发现回答质量反而掉了。
到底出了什么问题?
2026 年初,FloTorch、NVIDIA、Chroma Research 和 Superlinked VectorHub 四家机构分别发布了 RAG 分块策略的基准测试报告。
测试方法不同、数据集不同、评估指标也不同,但指向了同一个方向——递归字符拆分(Recursive Character Splitting)仍然是最稳的通用选择,而语义分块在实际答案生成上存在一个容易被忽视的陷阱。
这篇文章把四项测试的数据掰开了讲,帮你搞清楚:什么场景该用什么切法,以及那些听起来更高级的策略为什么不一定更好用。
二、语义分块的悖论:检索 91.9%,答案 54%
先看最反直觉的一组数据。
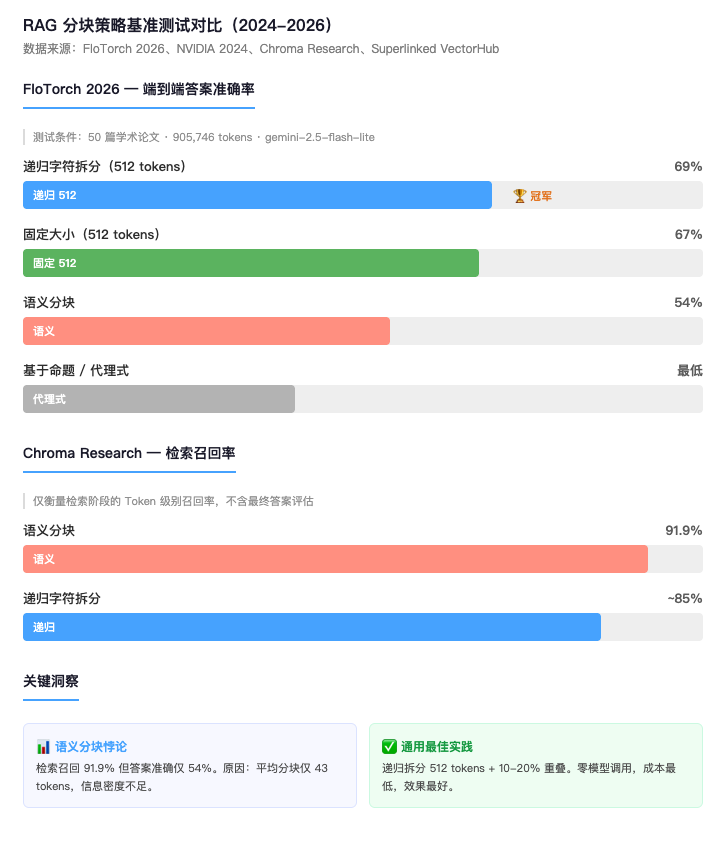
Chroma Research 的测试中,语义分块拿到了 91.9% 的 Token 级检索召回率——找到了几乎所有相关文本。听起来很棒。
但在 FloTorch 2026 年 2 月的端到端测试中(50 篇学术论文,覆盖 10 个学科,总计 905,746 tokens),语义分块的最终答案准确率只有 54%。
同一策略,一个 91.9%,一个 54%,差在哪里?
差在衡量的东西不一样。
Chroma 测的是能不能找到相关的文字片段,FloTorch 测的是大模型基于这些片段能不能给出正确答案。
语义分块的问题在于它产生的分块太碎了。
在 FloTorch 测试中平均每个分块只有 43 个 tokens,大约两三句话。这些微小片段确实和查询语义相关,但信息密度太低,大模型拿到手里拼不出完整答案。
换个比喻:你让人帮你找一本书里关于某个话题的内容。语义分块相当于把相关的句子一条条撕下来递给你,每条都相关,但你读完一堆纸条还是不知道原文在讲什么。
这个发现的实际意义是:不要单独看检索指标来评估分块策略,必须跑端到端的答案准确率。
三、四项基准测试的核心数据
逐个拆解一下。
FloTorch 2026(最大规模真实文档测试)
- 语料:50 篇学术论文,905,746 tokens,涵盖 10+ 学科
- 模型:gemini-2.5-flash-lite(生成),text-embedding-3-small(嵌入)
- 冠军:递归字符拆分 512 tokens,准确率 69%
- 固定大小 512 tokens 紧随其后,67%
- 语义分块 54%,基于命题的代理式分块垫底
递归拆分赢在哪里?它优先按段落(\n\n)切,其次按换行、空格逐级降级。
这意味着它尽可能保留了文本的自然边界,同时不依赖任何额外的模型调用。
零成本加成,效果最好。
NVIDIA 2024(金融文档专项)
- 语料:含 FinanceBench 在内的 5 个数据集
- 发现:页面级分块在金融报告上表现最好(准确率 0.648),因为财务报告的页面边界通常对应完整的表格或章节
- 1024 tokens 的大分块在 FinanceBench 上达到 57.9%
金融文档的启示:当文档自身的物理结构(分页、章节)承载了语义信息时,利用这种结构比按 token 数切更合理。
Chroma Research(检索阶段专项)
- 关注 Token 级检索召回率
- 语义分块 91.9%,检索阶段确实强
- 但正如上面说的,这个数字不等于最终答案质量
Superlinked VectorHub(嵌入模型对比)
- 句子级分割 + ColBERT v2 拿到最高 MRR 0.3123
- 说明分块策略和嵌入模型的选择是耦合的,换了模型可能结果完全不同
四、策略怎么选
策略这么多,怎么在自己的项目里做决策?
下面这张图是我按文档类型的选型速查,仅供参考。
核心思路就四步:
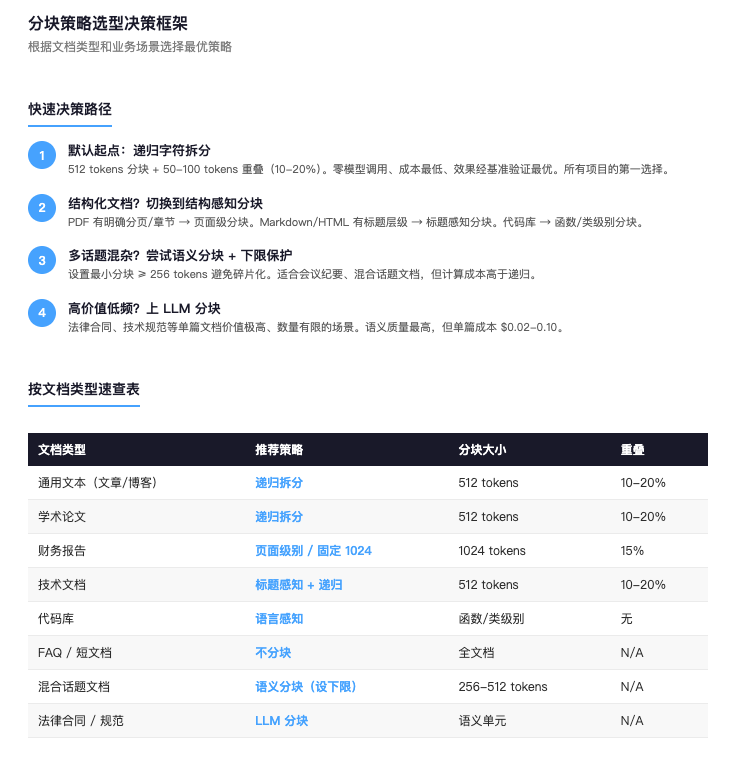
第一步:默认用递归字符拆分。
512 tokens 分块,50-100 tokens 重叠。这是经过基准验证的最稳默认值。不需要额外模型调用,处理速度快,成本低。大多数通用场景到这一步就够了。
第二步:有结构就用结构。
- PDF 报告有分页,用页面级分块。
- Markdown 文档有标题层级,用标题感知分块。
- 代码仓库,按函数或类切。前提是文档的结构边界确实承载了语义信息。
第三步:话题混杂才考虑语义分块。
会议纪要、多话题长文档,话题转换没有明显的格式标记,这时候语义分块的按话题自动断句能力才有用武之地。但一定要设最小分块下限(建议 ≥ 256 tokens),防止碎片化。
第四步:高价值场景上 LLM 分块。
法律合同、监管文件、技术规范这类文档,单篇价值极高,数量有限。让 LLM 判断语义完整单元,质量最高,对模型要求没那么高,单篇处理成本也很低了。
五、一些实操中容易踩的坑
坑一:重叠设太大。
有人把重叠设到 30-50%,想着多些上下文总没坏处。
实际上过大的重叠会导致索引膨胀,检索时返回大量重复内容,反而干扰大模型判断。10-20% 是多个测试验证过的甜区。
坑二:对自动分页的 PDF 用页面级分块。
很多 PDF 是从 Word 或网页导出的,分页完全是排版自动算的,和内容无关。
对这类 PDF 做页面级分块,等于按随机位置切,还不如老老实实递归拆分。
坑三:短文档也切。
FAQ 文档、产品说明这类几百字的短文本,切了反而丢信息。
Firecrawl 的测试数据表明,短文档直接整篇喂进去效果更好。
坑四:只测检索不测生成。
前面语义分块的例子已经说明了,检索指标好看不代表最终答案好。
评估分块策略,一定要跑端到端的 QA 评估。
六、LangChain 递归拆分实操
用 LangChain 实现推荐的默认策略,码量很小:
from langchain.text_splitter import RecursiveCharacterTextSplittersplitter = RecursiveCharacterTextSplitter( chunk_size=512, chunk_overlap=80, # 约 15% 重叠 separators=["\n\n", "\n", " ", ""], length_function=len, # 按字符计;用 tiktoken 可按 token 计)chunks = splitter.split_text(document_text)
如果要按 token 数切(更精确):
import tiktokenenc = tiktoken.encoding_for_model("gpt-4")splitter = RecursiveCharacterTextSplitter( chunk_size=512, chunk_overlap=80, separators=["\n\n", "\n", " ", ""], length_function=lambda text: len(enc.encode(text)),)
LlamaIndex 那边思路一样,用 SentenceSplitter 配合 chunk_size=512 和 chunk_overlap=80 即可。
七、总结
分块策略的选择可能没有想象中那么玄学。四大基准测试给出的信号很一致:
- 递归字符拆分 512 tokens + 10-20% 重叠,作为默认起点,跑赢了大多数更智能的替代方案
- 语义分块检索强但生成弱,根源是碎片化,如果用,一定设最小分块下限
- 结构化文档(金融报告、技术文档)优先利用文档自身结构
- 评估分块策略必须看端到端答案准确率,不能只看检索指标
别被"语义"“智能”"代理式"这些标签迷住了。
分块的目的是给大模型提供信息密度足够高、边界足够合理的上下文。有时候,最朴素的办法就是最管用的。
当然,把索引优化好,可以一定程度的去解决碎片化的问题。
假如你从2026年开始学大模型,按这个步骤走准能稳步进阶。
接下来告诉你一条最快的邪修路线,
3个月即可成为模型大师,薪资直接起飞。
阶段1:大模型基础

阶段2:RAG应用开发工程

阶段3:大模型Agent应用架构

阶段4:大模型微调与私有化部署

配套文档资源+全套AI 大模型 学习资料,朋友们如果需要可以微信扫描下方二维码免费领取【保证100%免费】👇👇





配套文档资源+全套AI 大模型 学习资料,朋友们如果需要可以微信扫描下方二维码免费领取【保证100%免费】👇👇


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 12
12 0
0- 0



 已为社区贡献127条内容
已为社区贡献127条内容

所有评论(0)