在高通跃龙IQ-9075上部署端侧OCR工业仪表识别系统(1): PP-OCRv4模型导出与ONNX转换
前言
做工业项目的时候经常遇到一个需求——现场的压力表、温度计、流量计这些传统仪表没有数字输出接口,但产线又要求把读数采集上来做数据分析。以前的做法是装个摄像头,把图传到服务器上跑OCR,但延迟和带宽成本一直是痛点。
这次我们在高通跃龙IQ-9075平台上把PaddleOCR的PP-OCRv4模型跑通了,从拍摄到出识别结果全程在板端完成,不依赖云端。整个过程踩了不少坑,记录下来供大家参考。本系列分三篇:
- (一)PC端完成PP-OCRv4模型的导出和ONNX转换
- (二)QNN编译与模型转换
- (三)板端部署与实时识别效果验证
1. 系统整体架构
先看整体方案。整个OCR识别系统采用经典的“检测+识别”两阶段pipeline,部署架构如下:
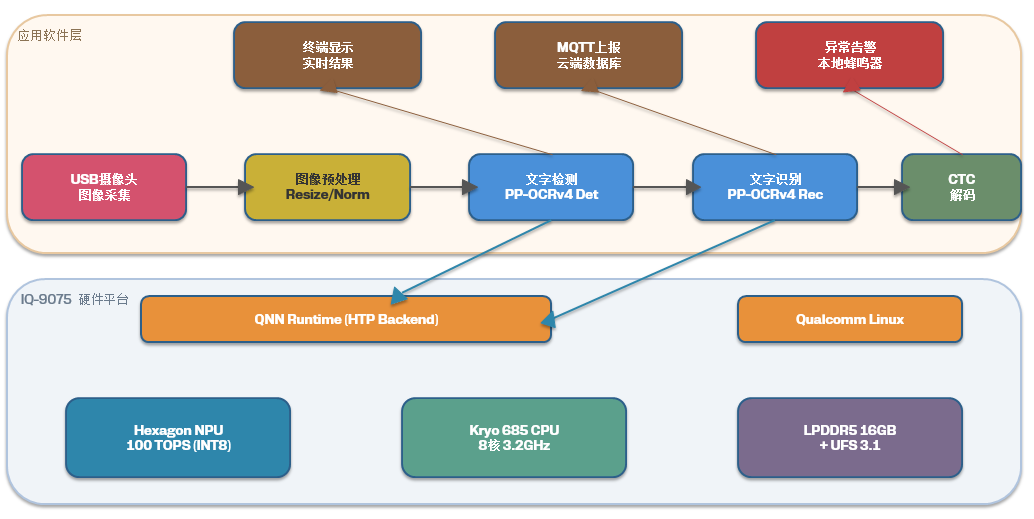
简单说就是:USB工业摄像头采集仪表图像,经过预处理后先跑文字检测模型(PP-OCRv4 Det)定位文字区域,把检测到的文字区域裁剪出来,再送进文字识别模型(PP-OCRv4 Rec)得到最终的文字内容。检测和识别模型全部跑在IQ-9075的Hexagon NPU上,利用QNN框架做加速。
核心硬件参数如下:
- SoC:高通跃龙IQ-9075(Qualcomm Dragonwing IQ-9075)
- NPU算力:100 TOPS(INT8)
- CPU:Kryo685,8核,主频最高3.2GHz
- 内存:板载16GB LPDDR5
- OS:Qualcomm Linux(Ubuntu 22.04 based)

2. 为什么选PP-OCRv4
选模型的时候对比了几个方案:
| 模型 | 检测模型大小 | 识别模型大小 | 中文支持 | ONNX导出 |
|---|---|---|---|---|
| PP-OCRv4 | 4.7MB | 10MB | 原生支持 | 官方支持 |
| EasyOCR | ~25MB | ~50MB | 支持 | 需手动转 |
| TrOCR | - | ~560MB | 需微调 | 支持 |
PP-OCRv4的优势很明显:模型小、中文效果好、官方直接提供ONNX导出工具。工业仪表场景下,数字和少量汉字的识别用PP-OCRv4完全够用。
3. 环境准备
3.1 PC端环境配置
模型导出在PC端(x86_64 Ubuntu 22.04)完成,需要安装以下依赖。
先创建一个干净的虚拟环境:
python3 -m venv ocr_export
source ocr_export/bin/activate
安装PaddlePaddle和PaddleOCR:
pip install paddlepaddle==3.0.0
pip install paddleocr==2.9.1
pip install paddle2onnx==1.3.1
pip install onnx==1.17.0
pip install onnxsim==0.4.36
验证安装是否成功:
python3 -c "import paddle; print(paddle.__version__)"
python3 -c "import paddleocr; print(paddleocr.__version__)"
输出应该分别是 3.0.0 和 2.9.1。
3.2 下载PP-OCRv4预训练模型
PP-OCRv4包含两个核心模型:文字检测模型(Det)和文字识别模型(Rec)。从PaddleOCR的GitHub仓库下载server版本的预训练权重:
mkdir -p ~/ocr_models && cd ~/ocr_models
wget https://paddleocr.bj.bcebos.com/PP-OCRv4/chinese/ch_PP-OCRv4_det_server_infer.tar
wget https://paddleocr.bj.bcebos.com/PP-OCRv4/chinese/ch_PP-OCRv4_rec_server_infer.tar
tar xf ch_PP-OCRv4_det_server_infer.tar
tar xf ch_PP-OCRv4_rec_server_infer.tar
解压后目录结构如下:
~/ocr_models/
├── ch_PP-OCRv4_det_server_infer/
│ ├── inference.pdmodel
│ ├── inference.pdiparams
│ └── inference.pdiparams.info
└── ch_PP-OCRv4_rec_server_infer/
├── inference.pdmodel
├── inference.pdiparams
└── inference.pdiparams.info
每个模型目录下有三个文件:.pdmodel是网络结构,.pdiparams是权重参数,.pdiparams.info是参数描述信息。
4. Paddle模型导出为ONNX
这一步是整个流程的关键。QNN工具链不直接支持Paddle格式,需要先转成ONNX中间格式。
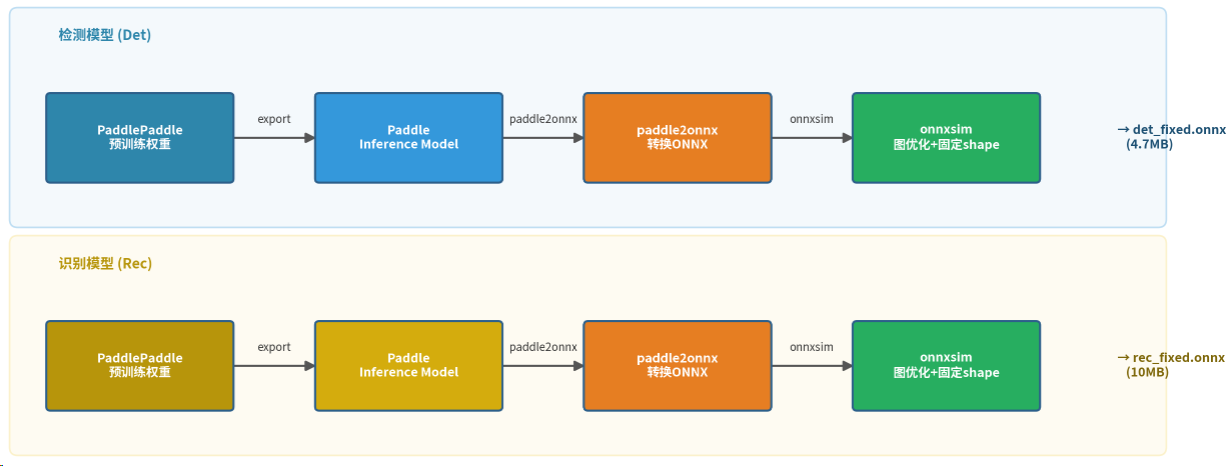
4.1 导出检测模型
检测模型的输入是一张图片,输出是文字区域的坐标。导出时需要固定输入shape,这对后续QNN编译很重要:
paddle2onnx \
--model_dir ~/ocr_models/ch_PP-OCRv4_det_server_infer \
--model_filename inference.pdmodel \
--params_filename inference.pdiparams \
--save_file ~/ocr_models/ch_ppocr_v4_det.onnx \
--opset_version 16 \
--enable_onnx_checker True
导出完成后用onnxsim做一次图优化,合并冗余的算子节点:
python3 -m onnxsim \
~/ocr_models/ch_ppocr_v4_det.onnx \
~/ocr_models/ch_ppocr_v4_det_sim.onnx
查看检测模型的输入输出:
python3 -c "
import onnx
model = onnx.load('/root/ocr_models/ch_ppocr_v4_det_sim.onnx')
print('输入:', [(i.name, [d.dim_value for d in i.type.tensor_type.shape.dim]) for i in model.graph.input])
print('输出:', [(o.name, [d.dim_value for d in o.type.tensor_type.shape.dim]) for o in model.graph.output])
print('节点数:', len(model.graph.node))
"
输出类似:
输入: [('x', [1, 3, 960, 960])]
输出: [('sigmoid_0.tmp_0', [1, 1, 960, 960])]
节点数: 267
检测模型的输入是 1×3×960×960 的图像张量(NCHW格式),输出是同尺寸的概率图,表示每个像素属于文字区域的概率。
4.2 导出识别模型
识别模型的输入是裁剪出的文字区域图片,输出是字符序列。PP-OCRv4的识别模型采用SVTR架构,输入高度固定为48像素,宽度按比例缩放:
paddle2onnx \
--model_dir ~/ocr_models/ch_PP-OCRv4_rec_server_infer \
--model_filename inference.pdmodel \
--params_filename inference.pdiparams \
--save_file ~/ocr_models/ch_ppocr_v4_rec.onnx \
--opset_version 16 \
--enable_onnx_checker True
同样做简化:
python3 -m onnxsim \
~/ocr_models/ch_ppocr_v4_rec.onnx \
~/ocr_models/ch_ppocr_v4_rec_sim.onnx
查看识别模型的输入输出:
python3 -c "
import onnx
model = onnx.load('/root/ocr_models/ch_ppocr_v4_rec_sim.onnx')
print('输入:', [(i.name, [d.dim_value for d in i.type.tensor_type.shape.dim]) for i in model.graph.input])
print('输出:', [(o.name, [d.dim_value for d in o.type.tensor_type.shape.dim]) for o in model.graph.output])
print('节点数:', len(model.graph.node))
"
输出类似:
输入: [('x', [1, 3, 48, 320])]
输出: [('softmax_0.tmp_0', [1, 40, 6625])]
节点数: 354
识别模型输入是 1×3×48×320(高48、宽320),输出是 1×40×6625,其中40是序列长度,6625是字符字典大小(包含6623个中英文字符 + blank + padding)。
4.3 固定动态维度
PP-OCRv4原始模型的宽度维度是动态的,但QNN要求所有维度在编译时确定。需要用onnx工具把动态维度固定下来。
检测模型固定为 960×960:
python3 << 'PYEOF'
import onnx
from onnx.tools import update_model_dims
model = onnx.load("/root/ocr_models/ch_ppocr_v4_det_sim.onnx")
updated = update_model_dims.update_inputs_outputs_dims(
model,
{"x": [1, 3, 960, 960]},
{"sigmoid_0.tmp_0": [1, 1, 960, 960]}
)
onnx.save(updated, "/root/ocr_models/ch_ppocr_v4_det_fixed.onnx")
print("检测模型固定shape完成")
PYEOF
识别模型固定为 48×320:
python3 << 'PYEOF'
import onnx
from onnx.tools import update_model_dims
model = onnx.load("/root/ocr_models/ch_ppocr_v4_rec_sim.onnx")
updated = update_model_dims.update_inputs_outputs_dims(
model,
{"x": [1, 3, 48, 320]},
{"softmax_0.tmp_0": [1, 40, 6625]}
)
onnx.save(updated, "/root/ocr_models/ch_ppocr_v4_rec_fixed.onnx")
print("识别模型固定shape完成")
PYEOF
5. PC端验证ONNX模型
在送去做QNN转换之前,先在PC端验证一下ONNX模型的推理结果是否正确。准备一张工业仪表的测试图片(比如压力表的特写照片),运行以下脚本:
python3 << 'PYEOF'
import cv2
import numpy as np
import onnxruntime as ort
def preprocess_det(img, target_size=960):
h, w = img.shape[:2]
ratio = target_size / max(h, w)
new_h, new_w = int(h * ratio), int(w * ratio)
resized = cv2.resize(img, (new_w, new_h))
padded = np.zeros((target_size, target_size, 3), dtype=np.float32)
padded[:new_h, :new_w, :] = resized
padded = padded / 255.0
padded = (padded - np.array([0.485,0.456,0.406])) / np.array([0.229,0.224,0.225])
padded = padded.transpose(2,0,1)[np.newaxis,:].astype(np.float32)
return padded, ratio
img = cv2.imread("test_meter.jpg")
input_data, ratio = preprocess_det(img)
sess = ort.InferenceSession("/root/ocr_models/ch_ppocr_v4_det_fixed.onnx")
output = sess.run(None, {"x": input_data})
prob_map = output[0][0,0]
binary = (prob_map > 0.3).astype(np.uint8)
contours, _ = cv2.findContours(binary, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
print(f"检测到{len(contours)}个文字区域")
for i, cnt in enumerate(contours):
x,y,w,h = cv2.boundingRect(cnt)
print(f"区域{i+1}: x={int(x/ratio)}, y={int(y/ratio)}, w={int(w/ratio)}, h={int(h/ratio)}")
PYEOF
如果能正确检测到仪表上的数字区域,说明ONNX模型导出没有问题。
6. 准备校准数据集
QNN量化需要校准数据集来确定激活值的动态范围。收集20-30张工业仪表的实拍图片,包含不同光照条件和不同仪表型号。
创建校准数据目录:
mkdir -p ~/ocr_models/calibration/det_input
mkdir -p ~/ocr_models/calibration/rec_input
用下面的脚本批量预处理校准图片:
python3 << 'PYEOF'
import cv2
import numpy as np
import glob
import os
det_out = os.path.expanduser("~/ocr_models/calibration/det_input")
raw_dir = os.path.expanduser("~/ocr_models/calibration/raw_images")
for idx, path in enumerate(sorted(glob.glob(f"{raw_dir}/*.jpg"))):
img = cv2.imread(path)
h, w = img.shape[:2]
ratio = 960 / max(h, w)
new_h, new_w = int(h * ratio), int(w * ratio)
resized = cv2.resize(img, (new_w, new_h))
padded = np.zeros((960, 960, 3), dtype=np.float32)
padded[:new_h, :new_w, :] = resized
padded = padded / 255.0
padded = (padded - np.array([0.485, 0.456, 0.406])) / np.array([0.229, 0.224, 0.225])
padded = padded.transpose(2, 0, 1).astype(np.float32)
padded.tofile(f"{det_out}/input_{idx:04d}.raw")
print(f"已处理: {os.path.basename(path)}")
print(f"共生成 {idx+1} 个检测模型校准文件")
PYEOF
识别模型的校准数据同理,从检测结果中裁剪出文字区域,resize到
48×320后保存为raw文件。这部分具体操作放到下篇文章里讲。
7. 导出产物清单
到这一步,PC端的工作基本完成了。最终在 ~/ocr_models/ 下应该有这些文件:
~/ocr_models/
├── ch_ppocr_v4_det_fixed.onnx # 检测模型(固定shape,约4.7MB)
├── ch_ppocr_v4_rec_fixed.onnx # 识别模型(固定shape,约10MB)
├── calibration/
│ ├── det_input/ # 检测模型校准数据(.raw文件)
│ └── rec_input/ # 识别模型校准数据(.raw文件)
└── ppocr_keys_v1.txt # 字符串字典文件(6623个字符)
字符串字典文件 ppocr_keys_v1.txt 从PaddleOCR仓库下载:
wget -O ~/ocr_models/ppocr_keys_v1.txt \
https://raw.githubusercontent.com/PaddlePaddle/PaddleOCR/release/2.9/ppocr/utils/ppocr_keys_v1.txt
8. 小结
本篇完成了PP-OCRv4模型从PaddlePaddle格式到ONNX格式的全部转换工作,包括:
- 搭建了PC端的PaddlePaddle + paddle2onnx环境
- 下载并解压了PP-OCRv4 server版检测和识别预训练模型
- 使用paddle2onnx工具将Paddle模型转为ONNX格式
- 用onnxsim做了图优化,并固定了动态维度
- 在PC端验证了ONNX模型的推理正确性
- 准备了QNN量化所需的校准数据集
下一篇将进入QNN编译环节——使用QNN SDK把ONNX模型编译为IQ-9075 NPU可执行的格式。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 13
13 0
0- 0



 已为社区贡献25条内容
已为社区贡献25条内容

所有评论(0)