体系结构论文(113):LLM-Powered EDA Log Analysis for Effective Design Debugging
LLM-Powered EDA Log Analysis for Effective Design Debugging 【伯克利25年报告】
- 问题背景
- 作者关注的是:综合和实现工具会生成大量、冗长、格式不统一的日志,里面其实包含了很多设计问题线索,但人工看起来非常费劲,尤其对新手不友好。论文希望用LLM自动完成日志理解、问题识别和修复建议生成。
- 第一部分:把乱七八糟的log先“结构化”
- 论文先研究如何从综合日志里提取表格、摘要和关键片段。
- 结论是:GPT-4o在“定向提取某张表”这件事上效果很好,尤其是在先给出表格语义描述的情况下,比纯规则方法更稳。
- 作者还提出了一个one-shot table extraction思路:先人工/一次性分割表格,再让GPT生成“这类表格的描述”,以后遇到新log就用这个描述去定位同类表格,再转成CSV。这个思路本质上是在做“表格模板语义复用”。
- 第二部分:比较两种调试路线——RAG vs 混合方法
- 作者把重点放在综合问题识别和HDL修复建议上,比较了两条路线:
- RAG-based方法:直接把log和HDL交给带检索的LLM。
- Hybrid方法:先用规则脚本过滤并分类典型问题,再把“提取后的问题列表 + HDL代码”交给GPT-4o分析。
- 实验结果非常明确:Hybrid方法显著优于RAG。
- RAG:检测准确率 56%,正确修复率 11%
- Hybrid:检测准确率 100%,正确修复率 89%
- 作者认为RAG的问题是:容易漏掉明显错误、容易产生假阳性、修复建议还经常很泛。Hybrid由于先做规则筛选,把输入“降噪”了,所以GPT能更聚焦真实问题。
- 第三部分:提出多智能体调试系统
- 在Hybrid基础上,论文进一步提出了一个多智能体debug框架,把任务拆成几个模块:
- Evaluator Agent:跑综合/仿真,拿真实工具反馈
- Log Structuring Agent:结构化日志
- Issue Analysis Agent:分析问题和根因
- HDL Repair Agent:给出代码修改建议
- 这个系统不是一次性回答,而是迭代调试:改代码 → 再综合 → 再分析 → 再修。这样比单轮问答更接近真实硬件debug流程。
一、INTRO
1.1 Motivation:作者为什么要研究“LLM分析EDA log”
1. 核心出发点
作者认为,现代EDA工具在综合和实现过程中会生成大量log,这些log里面其实藏着很多重要信息,比如:
- 设计决策是怎么做的
- 性能瓶颈在哪里
- 有没有潜在错误或不合理综合结果
但问题在于,这些信息并不直接以“结论”的形式给你,而是埋在大量冗长文本里。
2. 作者真正想强调的矛盾
这里的关键矛盾不是“没有信息”,而是:
- 信息很多
- 但人很难高效读出来
final report 只给摘要指标,但真正debug时,往往要回到详细log里找原因。尤其当设计出现“功能不符合预期”或者“综合后行为异常”时,详细log比最终汇总报告更有价值。
3. 为什么这会成为问题
作者指出三个现实困难:
- log 太长
- log 缺乏统一结构
- 不同工具/版本的格式差异很大
所以即使log里有答案,也不容易直接被设计者利用,尤其对经验不足的工程师或者学生更难。
4. 这一节想引出的论文主旨
因此作者提出:能不能让LLM来做三件事?
- 提取结构
- 识别问题
- 生成可能的修复建议
也就是说,这篇文章把它当成EDA日志解释器 + 调试辅助器。
1.2 EDA Log Challenges:EDA日志到底难在哪
这一节是对上一节问题的展开,作者把难点具体化了。
1. Accessibility and Usability:可访问性和可用性差
作者说综合log经常有成千上万行,其中很多是重复信息、辅助信息或上下文信息。
虽然工具会生成summary report,但如果想真正搞清楚问题,通常还是得:
- 手工翻log
- 或者自己写脚本去抓关键信息
这意味着调试成本很高,不能快速提炼 actionable insights。
你可以把这里理解成:
EDA工具给的是“原始证据”,不是“可执行结论”。
2. Formatting Variability:格式变化太大
不同EDA工具、不同供应商、甚至同一工具的不同版本,log格式都可能不同。
这会直接导致传统parser很难稳定工作,因为你写好的规则可能换个版本就失效。
这点其实很关键,它是在为后文“为什么不用纯规则方法”做铺垫。
3. Implicit Warnings:很多关键信号不是显式error
作者特别提到一种更麻烦的情况:
有些严重问题并不会以明确报错的形式出现,而只是“被动地记录”在log里,比如:
- inferred latch
- 不理想的综合约束
- 一些综合优化副作用
也就是说,log并不是总会明确告诉你“设计错了”,它更常见的是给出若干迹象,需要你自己推断这是不是问题。
EDA log 的难点在于它既冗长、又不统一、还经常不直接说人话。
所以如果有一种模型既能处理半结构化文本,又有一定语义理解能力,那它理论上就适合这个场景。
1.3 Large Language Models in EDA:为什么作者觉得LLM适合做这个
这一节是在回答:为什么偏偏是LLM,而不是普通脚本或传统NLP。
1. LLM和这个问题的匹配点
作者认为LLM擅长:
- summarization
- code generation
- pattern recognition
而EDA log恰好属于一种:
- 文本很多
- 结构不稳定
- 既有规则性又有语义性
的半结构化数据,因此LLM是有潜力的。
2. 作者概括的三个能力
(1)Pattern Recognition
LLM可以从很长的文本里识别出有意义的模式,比如:
- 哪一段像表格
- 哪一类warning对应哪种设计问题
- 不同信息之间是否有关联
(2)Scalable Analysis
大设计的log往往很长,没法一次全扔给模型。
作者认为可以把log分块处理,再结合检索或筛选机制,提升分析效率。
(3)User-Centric Interaction
这是LLM相对传统脚本很重要的一点。
以前工程师面对log,是“我去适应工具输出”;
用了LLM以后,可以变成“我直接问:这个log里有什么问题,为什么会这样,应该改哪里”。
也就是把EDA工具输出转换成更接近人的推理和问答方式。
1.4 Related Work:已有研究做到了什么,缺了什么
Rule-based approaches:传统规则方法
1. 传统方法是什么
传统EDA调试很多依赖:
- 人工看log
- regex / pattern matching
- 自定义脚本抓 warning/error
它们对“已知问题、固定格式”的场景是有效的。
2. 作者为什么不满意
作者认为规则方法有三个明显缺点:
- 脆弱:格式一变规则就坏
- 维护成本高:工具更新后要持续改脚本
- 理解能力弱:只能抓表面字符串,无法做更深层解释
尤其面对非标准、半结构化、甚至带有隐含语义的日志,规则方法很容易漏掉未知模式。
LLM/AI-based approaches:已有LLM方法
1. 作者先举了一个直接相关的工作
Qiu 等人的工作是:
- 先从Vivado编译log里抓出 error 行
- 再让 GPT-4 来解释错误并给出解决建议
这类方法的价值在于:
它已经证明了LLM可以辅助FPGA设计debug。
2. 作者指出它的局限
这个工作的问题是:
- 只处理显式标记为 error 的内容
- 一次只处理一个 error
- 更像“解释错误”,而不是系统性分析整个综合log
所以作者这篇论文想扩展它,从“单条error解释”走向:
- 更复杂log的结构化
- 隐式warning识别
- 更完整的问题定位与修复建议生成
这就是本文和前人的一个直接差异。
LLMs in other hardware contexts:LLM在硬件其他方向上的应用
作者把相关工作分成三类,这其实是在说明:
LLM+硬件设计已经不是空想,但log analysis这个点还没被充分做好。
(1)HDL Generation
作者列举了几篇做RTL/HDL自动生成的工作,比如:
- Chip-Chat
- AutoChip
- GPT4AIGChip
这些工作关注的是:
- 根据需求自动生成HDL
- 根据编译/仿真反馈迭代修RTL
- 用模板和prompt提高生成质量
说明LLM已经被广泛用于“写代码”这一侧。
(2)Debugging and Error Correction
这一类工作更接近本文,比如:
- RTLFixer:用RAG修复HDL语法错误
- HLS repair:针对工具不兼容/幻觉输出做自动修复
- MEIC:多智能体Verilog调试框架
这说明LLM已经开始从“生成代码”转向“改代码”和“debug代码”。
(3)Testing and Verification
作者还提到:
- Autobench
- VerilogReader
这些工作把LLM用到测试生成、coverage理解、verification辅助。
这进一步说明,LLM在硬件领域的落点很广:
- design generation
- debug / repair
- test / verification
而本文选的是其中的 EDA synthesis log analysis 这个切口。
1.5 Research Objectives
这一节是全文最重要的“任务书”。作者明确提出了三个目标。
目标一:Structuring Log Data
先把log结构化。因为如果输入本身乱,后面的问题识别和修复都不可靠。
作者这里主要做两件事:
(1)Table Extraction
识别并提取log中的结构化表格,比如:
- timing信息
- resource usage
- optimization细节
本质上是把原本散乱嵌在log中的结构化信息显式提出来。
(2)Chunking and Retrieval
把超长log拆成可处理的块,并通过RAG或规则匹配去找相关部分。
这一步的意义是:
- 解决上下文窗口限制
- 避免把整份log原样丢给模型
- 提高分析聚焦度
目标二:Identifying Issues and Guiding Debugging
在结构化基础上,进一步识别问题并指导调试。
(1)Issue Detection
比较:
- LLM-based 方法
- rule-based 方法
看看谁更适合识别综合中的典型问题、warning和不良综合结果。
(2)HDL and Constraint Suggestions
让LLM不只是指出问题,还给出:
- HDL修改建议
- constraint修改建议
也就是说,从“分析log”走到“帮助修设计”。
目标三:Multi-Agent Debugging Framework
1. 为什么要multi-agent
作者认为,单次prompt虽然能做一些问题识别,但有几个问题:
- 推理不够稳定
- 容易幻觉
- 缺少模块化职责划分
- 不适合迭代闭环调试
所以要设计一个多智能体系统,把不同步骤拆开。
2. 它包含什么
作者提了两个重点:
(1)Modular Agent Roles
给不同agent分配明确任务,比如:
- 综合评估
- 日志结构化
- 问题分析
- HDL重写
好处是:
- 推理链更清晰
- 模块职责更专门
- 幻觉更少
(2)Feedback-Driven Refinement and AutoTA
系统不是一次改完,而是利用真实综合结果形成闭环:
- 综合
- 分析log
- 改HDL
- 再综合
- 再修正
二、Structuring Log Data
2.1 Experiments with Table Extraction
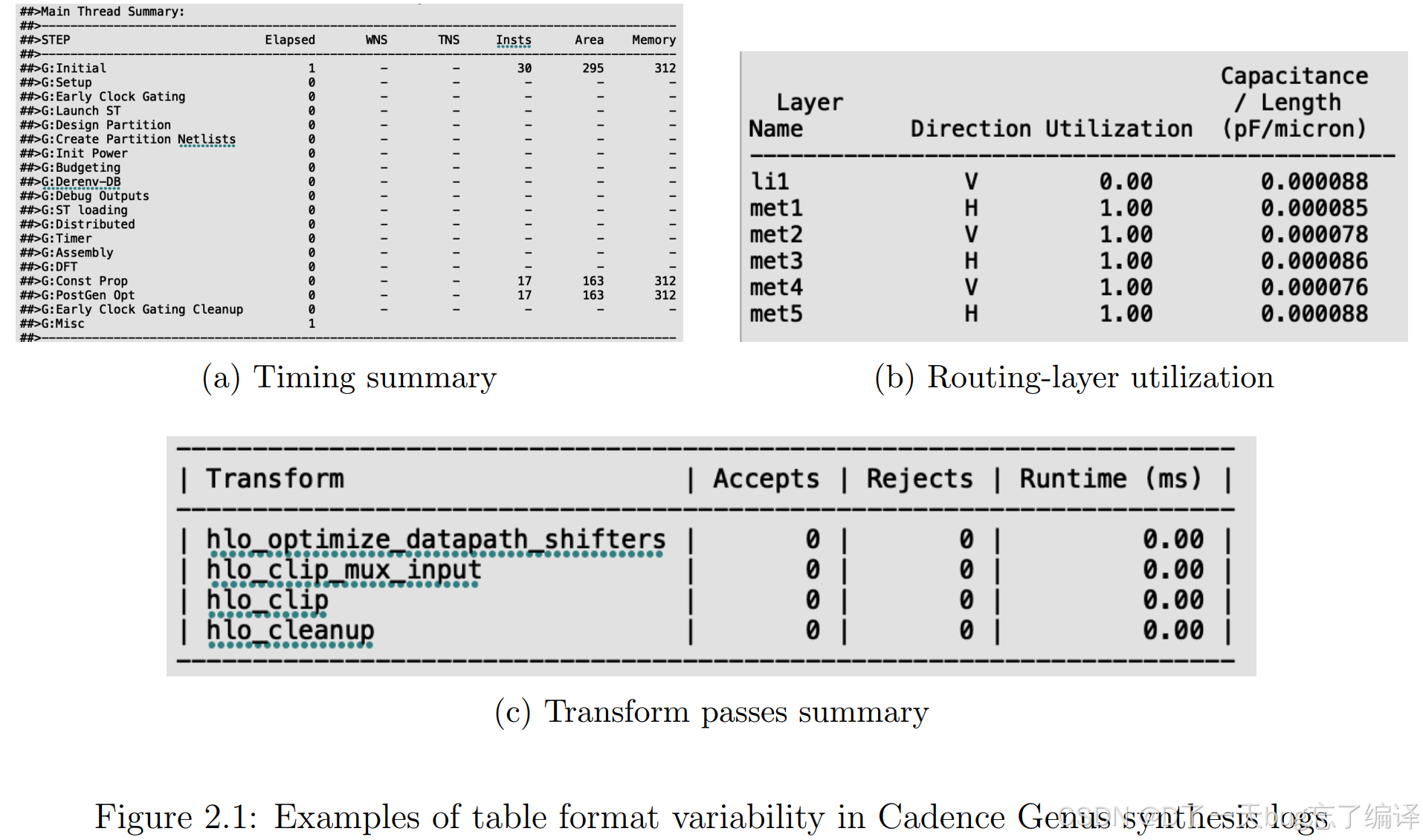
作者一开始把重点放在 Cadence Genus synthesis log 中的表格。原因很直接:
这些log里经常嵌着很多有价值的表格,比如:
- timing summary
- routing-layer utilization
- transform passes summary
但它们并不总是格式规整。图 2.1 就是在说明:即使同一工具的表格,格式也会变化很大。 比如:
- 分隔符不同
- 对齐方式不同
- 表头位置不同
- 前缀字符不同
- 有些带
## - 有些前面还夹着时间戳、路径等杂质
2.1.1 实验一:从干净log片段中提取单张表
1. 实验设置
给 ChatGPT 一个只包含单张文本表格的干净片段。
2. 实验结果
模型可以正确识别表格结构,并转成 CSV,准确率 100%。
3. 这说明什么
这说明在问题被大幅简化时,LLM 的表格结构识别能力是很强的。
也就是说,只要输入里:
- 表格边界清晰
- 周围噪声少
- 任务目标明确
LLM 很容易完成“识别列、抽取行、导出结构化格式”这件事。
4. 这一实验的意义
它是一个 baseline。
作者先证明:LLM不是完全看不懂EDA表格,至少在理想条件下它是能做对的。
2.1.2 实验二:从嵌在log消息中的表格里提取结构
1. 实验设置
这次不再给干净表格,而是给“嵌在复杂log中的表格”。
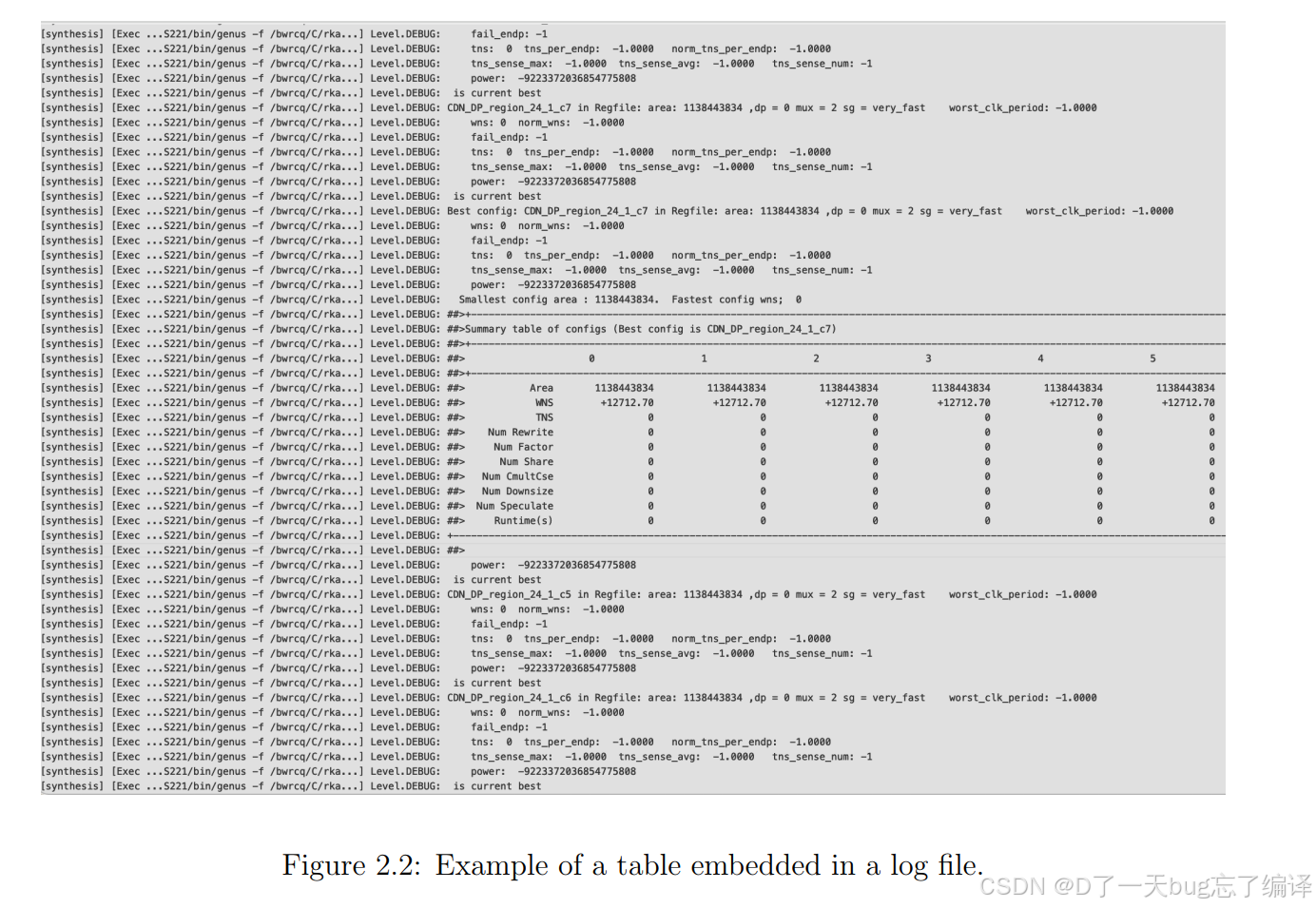
图 2.2 展示的情况很典型:
- 表格前后有大量综合消息
- 每行前面混着路径
- 有
HAMMER输出 - 有
## - 对齐不一致
- 表格上下有很多噪声文本
也就是说,模型要先做:
- 表格定位
- 再做表格解析
2. 实验结果
作者说 GPT 依然能把表格识别出来,并保持列和行结构完整,precision 100%。
作者没有让模型“自由发挥”,而是明确要求:
- 先识别列
- 再提取行列
- 再导成CSV
这说明一个重要点:
LLM在这类任务上并不是随便问都行,而是需要分阶段、约束清晰的prompt。
2.1.3 实验三:在多表格log中查找指定表格

1. 实验设置
给模型一个包含多张表的log,然后要求它找到其中某一张特定表。
这里不是直接给表格内容,而是给一个对表格的描述,比如这张表有哪些列、用途是什么。
2. 实验结果
作者发现:
- 如果先给出表格描述,让 GPT 去找对应表格,效果很好
- 对于“独特表格”,准确率达到 100%
- 但如果让 GPT 直接从log转CSV,它反而容易默认走 Python/regex 路线,准确率下降
3. 这说明的核心点
这一实验其实说明了一个很强的方法论结论:
“先定位,再提取” 明显优于 “端到端直接提取”。
也就是把任务拆成两步:
- 第一步:根据语义描述找到目标表格
- 第二步:把目标表格结构化输出
4. 为什么这样更好
因为直接让模型“从整份复杂log里找表并转CSV”,它要同时做三件事:
- 识别哪一段是表
- 判断哪一张是你要的
- 正确解析格式
这三件事一起做,难度很高,错误也容易传递。
但如果先给表格的“语义描述”,模型就不是瞎扫整个log,而是在做一种语义检索式定位。
这和后面 one-shot 方法直接连上了。
2.1.4 实验四:提取log中的所有表格
1. 实验设置
直接要求 GPT 从一个包含多张表的log里把所有表格都提出来。
2. 结果很差
作者说:
- 正确提取率不到 20%
- 返回结果里超过一半其实是把非表格文本错认成了表格
LLM擅长定向搜索,不擅长无约束全量枚举。
它直接决定了作者后面的方法设计:
不是让 GPT 去做“全日志全表格自动解析器”,而是让它做“已知目标类型的语义表格定位器”。
2.2 One-Shot Learning Approach for Table Extraction
1 为什么要提出 one-shot 方法
前面实验已经说明一个问题:
- 直接让 GPT 从复杂log里抓所有表,效果差
- 但如果先给描述,再让它找目标表,效果好
所以作者想到一个策略:
能不能把“表格描述”保存下来,作为以后检索同类表格的模板?
这就是这里的 one-shot learning。
注意,这个“one-shot”不是严格机器学习意义上的few-shot训练,而更像:
- 先对某类表做一次描述性学习
- 再把这个描述复用于新日志中的匹配与提取
本质上是一种语义模板复用机制。
2 这个方法的流程
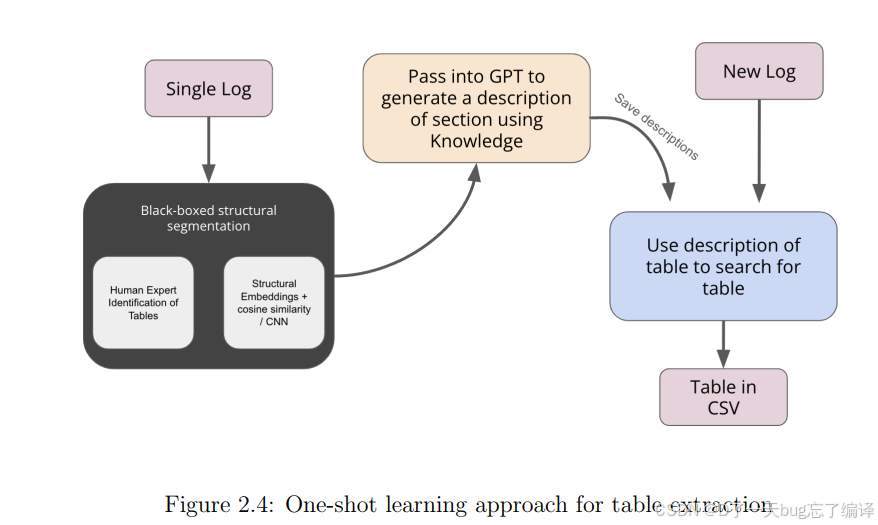
图 2.4 给出了完整流程,可以拆成四步。
步骤一:Table Segmentation
先把一个log里的表格分出来。
作者这里给了两种方式:
(1)Manual Annotation
在本文实验中,实际上是人工专家先把表格识别并分割出来。
也就是说,这一步目前还是人工完成的。
(2)Automated Detection(Conceptual)
作者提到未来可以考虑自动检测,比如:
- structural embeddings
- CNNs
但这部分目前没有真正验证,只是未来方向。
对这一步的理解
这说明作者的方法并没有完全解决“表格自动发现”的问题。
它解决的是:
一旦你有了样本表格,我怎么把这种表格类型迁移到新log里去找。
所以这更像一个半自动方案。
步骤二:Generating Table Descriptions Using GPT
对每张分割出来的表,让 ChatGPT 生成:
- 这张表是干什么的
- 它有哪些关键列
示例里给出的描述非常像“语义摘要”:
- 表格用途
- 关键字段含义
- 字段之间的统计意义
步骤三:Identifying Tables in New Log Files
在新log中,使用前面存储的表格描述去定位对应表格。
这一步的关键价值
因为新log中的同类表可能:
- 对齐方式变了
- 表头位置变了
- 前缀变了
- 格式微调了
如果用regex会很脆弱;
但如果用“表格语义 + 关键列描述”,GPT 仍然可能找到它。
这就是作者所谓的 format-agnostic。
步骤四:Extracting and Converting Tables to CSV
定位完成后,再让 GPT 把 raw text table 转成 CSV。
这一步的作用
它把最终结果落地为:
- 结构化数据
- 可进一步分析
- 可接入后续debug pipeline
所以完整链条是:
表格分割 → 表格语义描述生成 → 新log中语义检索定位 → CSV导出
作者认为这个方法的优势
作者总结了三个优势。
1. Robustness to Format Variations
因为不是靠死规则,而是靠语义理解,所以能适应格式变化。
2. Improved Extraction Accuracy
把“表格识别”和“表格解析”分开,避免一上来就全做导致错判。
3. Scalability to Multiple Table Types
一旦某类表的描述被建立起来,以后这种表可以持续识别。
2.3 Chunking and Retrieval for Efficient Log Processing
1. 为什么要 chunking
作者指出EDA log常常长到:
- 1万行
- 甚至100万行
显然无法直接塞进LLM上下文窗口。
所以必须先做 smart chunking,再考虑分析。
这里作者比较了两种思路:
- RAG
- rule-based extraction
2 RAG:作者是怎么理解RAG的
1. RAG是什么
作者给的是标准定义:
- 先从索引好的语料中检索相关内容
- 再把检索结果交给LLM生成解释、修复建议或总结
2. RAG的两个阶段
Retrieval Stage
根据query去向量数据库中搜索相关log块。
依赖 embeddings 做语义相似度匹配,而不是纯关键词匹配。
Generation Stage
把检索回来的块当上下文,交给LLM做生成。
3. 作者为什么会考虑RAG
因为理论上它能:
- 减少上下文压力
- 不用把整份log都给模型
- 还能利用语义相似性找相关片段
这在长log场景下看起来是很自然的选择。
3 Rule-Based Extraction
作者这里没有直接抛弃规则法,而是专门为常见设计问题设计了一个规则提取脚本。
1. 目标用户是谁
作者明确说是:
- novice designers
- 比如 Berkeley EECS 151 的学生
这说明作者关注的是高频共性错误,而不是工业级所有复杂corner case。
2. 脚本检测哪些问题
作者列了一组典型综合问题:
- Inferred Latches
- Multi-Driven Nets
- Optimized-Out Signals (Undriven)
- Combinational Loops
- Incorrect always @(*) Block Usage
- Register File with Excessive Write Ports
- Syntax Errors
- Unconnected Nets or Pins
- Unsynthesizable Constructs
- 以及它们的组合
3. 脚本怎么做
脚本流程有四步:
- 用预定义关键词模式扫描log
- 必要时抓取多行issue信息
- 每个issue只归到一个类别,避免重复
- 最后加一个 catch-all warning 类别兜底,避免漏掉未分类问题
4. 这套规则法的特点
作者承认它不如RAG灵活,但优点是:
- 快
- 可解释
- 对高频问题有效
- 还能随着工具语法演化,用GPT帮助更新pattern
三、Identifying Synthesis Log Issues and Debugging HDL
1. 现实问题背景
作者先举了一个很典型的教学场景:
在 EECS 151 实验课里,学生的设计可能:
- 功能仿真通过
- waveform 看起来也没问题
- 但烧到 FPGA 上就不工作
这时学生往往会花很多时间 debug,但不一定会认真看 synthesis log;
即使看了,也很难把 log 中的问题精确追溯到 HDL 源码。
作者想解决的不是“编译不过”的最简单问题,而是这种更麻烦的情况:
仿真没暴露问题,但综合/实现阶段已经产生了设计缺陷,最终导致 FPGA 上失效。
这类问题很适合看 synthesis log,但 log 太难读,于是就有了这一章的实验。
2. 作者是怎么构造实验的
作者实现了一个 streaming histogram 的 Verilog 设计,然后故意做多个变体,在这些变体里注入常见综合问题,比如:
- syntax errors
- inferred latches
- combinational loops
- 以及其他新手常见坑
3.1 Synthesis Log Debugging Using RAG
1. RAG 方案是怎么做的
作者用的是 ChatGPT 的 RAG-based CustomGPTs,把:
- synthesis log
- Verilog HDL code
作为 contextual knowledge 提供给模型,让模型自己去检索、分析并提出修复建议。
prompt 的特点
作者给的 prompt 其实已经不算弱了,甚至写得很具体:
- 不要泛泛搜 warning
- 要重点找常见问题关键词
- 比如 implicitly declared、has no driver、Latch inferred、multiple conflicting drivers、combinational loop
- 而且还要求找出具体信号,并给出 fix
这意味着:
如果 RAG 还是做不好,就不能简单怪 prompt 太烂。
因为作者已经在尽量引导它了。
2. RAG 的总体表现:不稳定、漏检多、假阳性高
作者说得很直接:
RAG 的结果是 mixed results。虽然能识别一些问题,但经常:
- 漏掉明显问题
- 即使反复提示关键词也漏
- 假阳性很多,经常报告不存在的问题
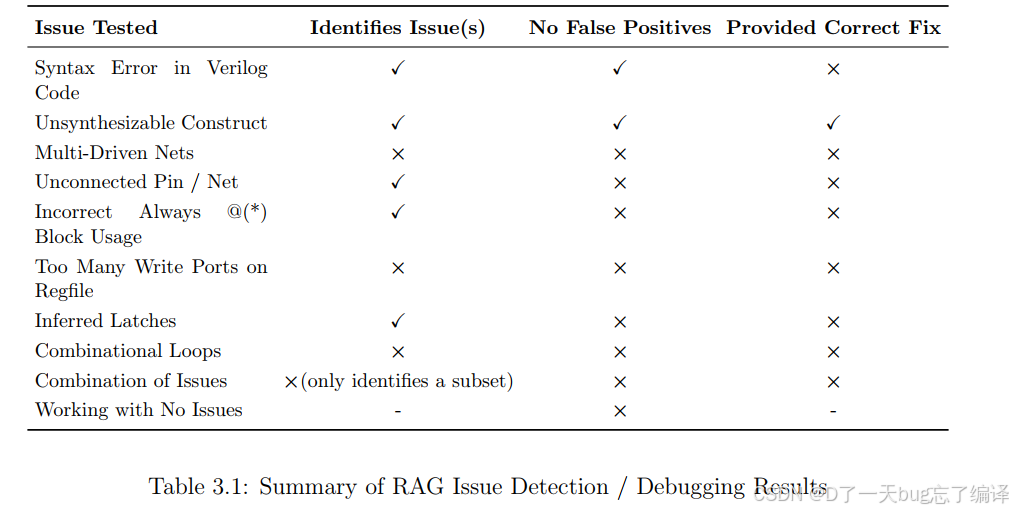
表 3.1 从三个维度评价每类问题:
- Identifies Issue(s):能不能发现这个问题
- No False Positives:会不会乱报
- Provided Correct Fix:修复建议对不对
RAG 的结果大致是:
能识别但修不好
- Syntax Error in Verilog Code:能识别,且不太乱报,但 fix 不对
- Unsynthesizable Construct:这一项相对较好,识别和 fix 都可以
经常识别失败
- Multi-Driven Nets:识别失败
- Too Many Write Ports on Regfile:识别失败
- Combinational Loops:识别失败
- Combination of Issues:只能识别一部分
经常乱报
- Unconnected Pin / Net
- Incorrect always @(*) Block Usage
- Inferred Latches
这些即使能抓到,也存在较多假阳性或修复不准的问题。
对“没问题的设计”也不可靠
对于 Working with No Issues,它仍然会报出问题。
这说明它没有形成稳定的“不要误报”的能力。
4. 作者总结的三类失败原因
(1)Failure to Identify Issues Even When Keywords Were Provided
这个问题非常致命。
作者举了一个例子:
明明 log 里就有和 multiple driver / driver-driver conflict 相关的关键词,但模型仍然说:
- 没有看到明确的 multiple drivers
- 没有发现 driver-driver conflicts
这说明什么
这说明 RAG 的问题不只是“知识不够”,而是检索和聚焦机制出了问题。
也就是说:
- query 有了
- 关键词有了
- 相关信息也在 log 里
- 但模型没有把它稳定检出来并用于推理
进一步理解
这非常像 RAG 常见的一个问题:
相关信息存在,但没有被正确召回,或者召回后没有被模型真正利用。
在EDA log这种高噪声、强局部线索的文本里,这个问题会被放大。
(2)High Rate of False Positives
作者给了几个非常典型的误报例子:
例1:多驱动误报
模型错误地说:
raddr[i]add_resultswdata[i]waddr[i]init_counterinit_done
都有 multiple drivers。
但真实情况只有 sum_results 和 query_count 两个信号有 multiple drivers。
例2:组合环与 missing driver 混淆
在 combinational loop 分析里,模型一边说“没有组合环”,一边又把一些内存相关元素说成 missing drivers,而且这个判断还是错的。
例3:把 “no latch inferred” 当成问题
作者甚至要在 prompt 里显式说明:
- “no latch inferred” 不是错误
不然模型会把它也当成 issue。
这说明什么
RAG 在这里的问题不是单纯“漏检”,而是:
它对 log 语句的语义极性判断不稳定。
也就是:
- “有 latch” 和 “没有 latch”
- “存在 driver conflict” 和 “不存在 conflict”
这种很基础的语义区分,它也可能搞错。
这在综合日志场景里非常危险,因为 log 中大量信息都是:
- warning / info 混杂
- 否定式表达很多
- 同一个关键词可能出现在正反两种上下文里
(3)Overly Generic Suggestions Even When Issues Were Identified
这类问题也很典型。
作者举的例子是:模型建议把 raddr 放进一个 always @(posedge clk or negedge rst_n) 里,并使用 next_raddr。
但问题是:
rst_n根本不存在next_raddr根本不存在raddr本来就是故意用组合逻辑赋值的
即使模型识别到了“大致类型”的问题,它给的修法也常常是模板化、通用化、脱离当前代码上下文的。
换句话说,RAG 可能做到了:
- “知道 latch 常见修法是什么”
但没做到:
- “知道这个设计里该不该这么修”
- “知道当前设计有哪些真实存在的信号和状态结构”
这是一种 generic debugging advice,不是 context-grounded RTL repair。
5. 作者对 RAG 的最终判断
作者最后给出非常明确的结论:
RAG-based retrieval poorly suited for novice-focused synthesis debugging。
原因包括:
- 不能稳定检测问题
- 容易 hallucinate
- 依赖脆弱的 retrieval strategy
- 在教学场景中不够清晰、不可操作
一句话理解
作者并不是说 RAG 在所有硬件任务都不行,而是说:
在“新手综合日志调试”这个任务上,RAG 不可靠。
3.2 Hybrid Rule-Based Extraction and GPT-4o
这一节就是全文的方法高潮。
1. 作者为什么改用 Hybrid
原因很简单:
前面 RAG 最大的问题在于:
- 输入太乱
- 检索不稳定
- 模型容易被无关 warning 干扰
- 最后导致漏检和乱报
所以作者换了一个思路:
不要让 LLM 直接面对完整log,而是先用规则脚本把真正相关的问题提炼出来。
2. Hybrid 方法的结构
这个方法分两层。
第一层:Rule-Based Extraction
先用 Python 脚本扫描 synthesis log,把常见问题分门别类提取出来,比如:
- inferred latches
- multiple drivers
- combinational loops
同时:
- 减少噪声
- 每个问题唯一归类
- 最后附上兜底 warning 区段
第二层:GPT-4o 分析
再把两样东西一起给 GPT-4o:
- 规则脚本输出的 categorized issue list
- 对应的 Verilog source code
这和 RAG 的根本区别
RAG 是:
- “给你整个log,你自己去找问题”
Hybrid 是:
- “我先把疑似问题筛出来,再让你做解释、定位和修复建议”
3. prompt 有什么变化
Hybrid 的 prompt 更强调:
- 对给出的每个 synthesis issue 做分析
- 回到源代码中找相应部分
- 按固定格式输出:
- Problem Analysis
- Key Sections in the Code
- Detailed Explanation of the Issues
- Suggested Fixes
- Updated Code
- Explanations of the Fixes
作者在这里进一步把任务结构化了。
RAG 阶段更像“你自己查”;
Hybrid 阶段更像“我把病历整理好了,你来做诊断和治疗建议”。
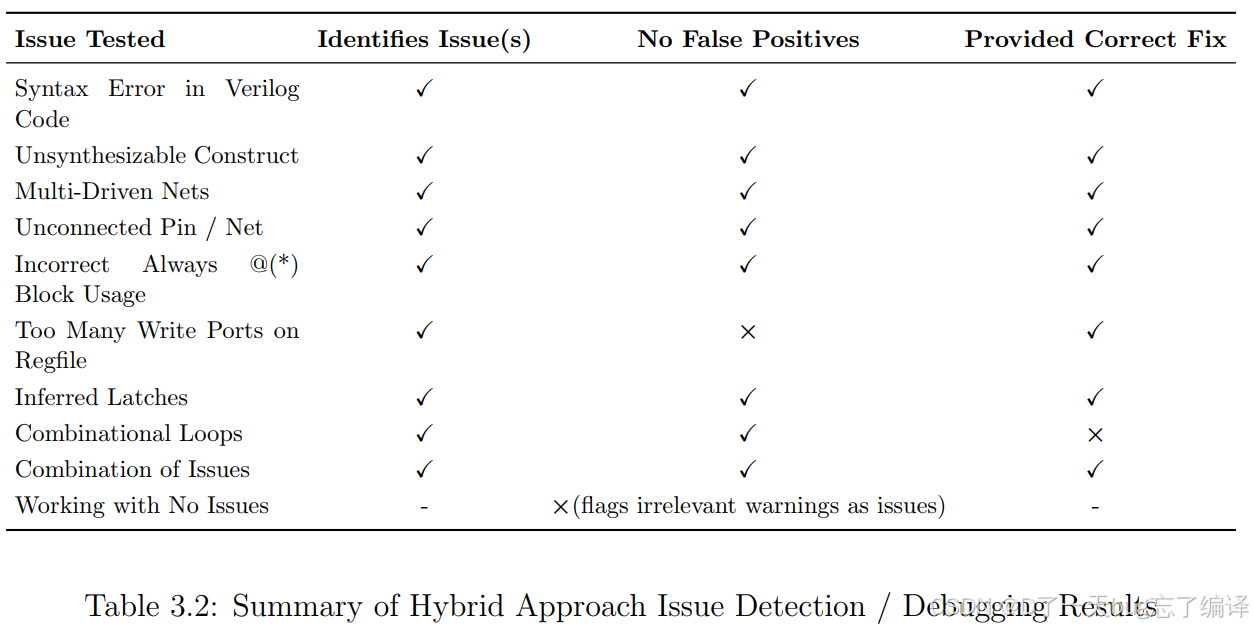
表 3.2 显示,Hybrid 在几乎所有项目上都明显优于 RAG:
仍有局部不足
- Too Many Write Ports on Regfile:能检测、能修,但仍有假阳性
- Combinational Loops:能检测、误报较少,但 fix 还不完全正确
- Working with No Issues:仍可能把不重要 warning 当问题
但整体已经好很多
至少它不再像 RAG 那样:
- 经常漏掉大问题
- 到处乱报
- 修法还脱离上下文
5. 作者总结的 Hybrid 优势
(1)Precise Issue Identification and Localization
作者给了一个组合环的例子。
模型准确指出问题出在:
assign partial_sums[0] = rdata[0];
generate
for (i = 1; i < N; i = i + 1) begin
assign partial_sums[i] = partial_sums[i-1] + rdata[i] + sum;
end
endgenerate
assign sum = partial_sums[N-1];
这里明显存在从 sum 回流到 partial_sums[i] 再回到 sum 的依赖。
Hybrid 能把这个位置直接指出来。
Hybrid 不只是知道“有 combinational loop”,而是能:
- 精确找到代码位置
- 解释为什么形成回路
这说明前面的规则预提取把问题空间缩小后,GPT-4o 能把更多推理能力用在代码定位上。
(2)Context-Aware Fix Suggestions
作者说,与 RAG 给模板化建议不同,Hybrid 会给出多个有效的、上下文相关的修法。
在 latch inference 的例子里,它给出两类方案:
修法1:默认组合赋值
在组合块开头加默认值,保证变量总被赋值,避免 latch。
修法2:改成时序逻辑
把更新移动到时钟触发块里,用同步逻辑避免时序问题。
(3)Grouping Related Warnings by Root Cause
这一点很有意思,也很像真正的工程debug思维。
作者举的例子是:
clk和clk_i不一致- 这一个根因引发了多个表面问题:
- undeclared signal
- missing drivers
- optimized-out registers
Hybrid 没有把这些分裂成互不相关的三堆碎片,而是把它们归并到同一个 root cause:
BlockRAM 实例化里用了错误时钟名。
(4)Reduced False Positives
作者明确说,structured input 明显降低了 hallucinations 和 misclassification。
与 RAG 常常把 benign warnings 误当关键错误不同,Hybrid 更能聚焦真正会破坏设计的问题。
LLM 的表现高度依赖输入形态。
不是同一个模型在任何输入方式下都一样。
当输入从:
- “整份复杂log”
变成:
- “规则筛选后的问题清单 + HDL源码”
模型表现会大幅提升。
3.3 Conclusion
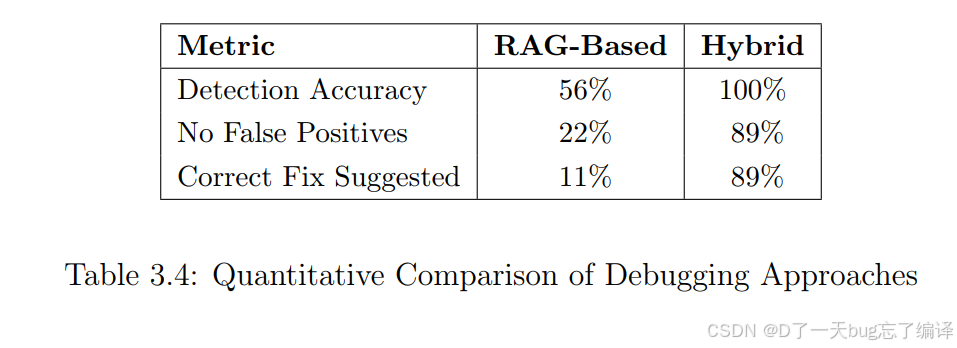
1. 定量结果
- Detection Accuracy:RAG 56%,Hybrid 100%
- No False Positives:RAG 22%,Hybrid 89%
- Correct Fix Suggested:RAG 11%,Hybrid 89%
2. 作者的结论
Hybrid:
- 更稳定
- 更少误报
- 更能给对的修复建议
四、Multi-Agent Debugging
1. 为什么前一章的 Hybrid 还不够
前一章已经证明了:
- 规则提取 + GPT-4o 比 RAG 强很多
但它本质上还是一种单轮分析:
- 给定 log 和代码
- 分析问题
- 给出修复建议
- 到此为止
作者认为单智能体/单轮方案的局限在于:
- 它是 monolithic 的,大量职责混在一起
- 没有 iterative reasoning
- 没有 modular control
- 尤其在 full-code rewrites 或复杂 debug cycles 中,可靠性和可解释性会下降
2. 作者提出的两个设计原则
(1)Separation of concerns
每个 agent 只负责一类任务,比如:
- synthesis evaluation
- log parsing
- issue diagnosis
- code rewriting
好处是:
- 模块边界更清晰
- 推理链条更可控
- 错误不容易一路传染下去
(2)Feedback-driven refinement
每轮修改后都重新拿真实综合反馈,再决定下一步怎么修。
这让系统更接近真实工程师的 debug 过程,而不是“一次性猜答案”。
4.1 System Architecture
作者把系统拆成 4 个 agent。
1. Evaluator Agent
职责
负责和综合工具交互,比如 Yosys,也可以接仿真工具,提供 ground-truth feedback。
作用
系统不是靠模型自己想象“这段代码可能没问题”,而是靠真实工具执行结果判断。
本质上
它是整个系统的“裁判”和“反馈源”。
2. Log Structuring Agent
职责
从 synthesis log 中提取结构化信息,比如:
- timing paths
- inferred latches
- resource usage
这里直接承接 Chapter 2 的 table parsing 和结构化处理。
作用
把原始log压缩成 downstream analysis 更容易用的 compact summary。
本质上
它相当于“日志预处理器”。
3. Issue Analysis Agent
职责
采用 hybrid 方法:
- 规则提取 relevant warnings/errors
- LLM 在上下文中解释这些问题,定位 root cause 和受影响模块
作用
它其实就是 Chapter 3 方法的核心封装版。
本质上
它是“问题诊断器”。
4. HDL Repair Agent
职责
根据识别出的问题,对 HDL 或 constraint 文件提出修改建议。
作者特别强调,这个 agent 是 conservative 的,只在有充分理由时才改。教学场景下甚至可以关闭,让学生自己改。
作用
它不是盲目大改代码,而是做“谨慎修复”。
本质上
它是“执行修复器”,但带保守约束。
5. 整个系统的逻辑关系
这 4 个 agent 串起来,其实就是:
工具跑综合 → 提取log结构 → 分析问题和根因 → 生成修复 → 再次综合验证
Implementation
作者说整个 iterative workflow 是一个 Python script 统筹实现的,负责协调:
- synthesis runs
- log extraction
- issue analysis
- code repair
而且每次迭代都会保存:
- intermediate logs
- 各版本 HDL
这样做的好处是:
- 可检查
- 可回溯
- 可比较不同轮次的修复效果
4.2 Evaluation and Results
1. 测试对象
作者选了 6 个设计,从简单组合逻辑到较复杂处理器都有:
- ALU
- FIFO
- GCD
- StreamingHistogram
- Button Parser + UART
- 3-stage RISC-V CPU
这样选的目的
就是看系统能不能覆盖:
- 小模块
- 状态机
- 含多模块耦合的较复杂设计
2. 每个设计里注入了什么问题
作者故意往每个设计里打入不同类型的 synthesis issues。
ALU
- syntax error
- unsynthesizable construct
- inferred latch
FIFO
- multi-driven net
- undriven control signal
- unconnected port on memory
GCD
- invalid synthesis constraints
- inferred latch
- optimized-out signal
- unconnected clock
StreamingHistogram
- combinational loops
- pipeline 中的 inferred latches
- undriven accumulation signal
- excessive register file ports
- disconnected reset
Button Parser + UART
- incorrect always block sensitivity list
- unconnected UART clock
- inferred latch on reset
- unused declared signal
3-stage RISC-V
- control FSM 中的 inferred latches
- undriven memory output
- multi-driven nets
- forwarding logic 中的 combinational loop
- unassigned signals
3. 比较方法
GPT-4o (single-pass)
基线方法:
一次性把 synthesis log 和 HDL 一起丢给 GPT-4o,没有反馈也没有迭代。
Multi-Agent (proposed)
作者提出的完整系统:
- synthesis
- issue extraction
- multi-step reasoning
- conservative HDL rewriting
关键差异
不是“模型不同”,而是系统流程不同。
4. 评测方式
每个设计、每种方法都跑 5 次独立实验,为了消除 LLM 输出波动。
评估指标包括:
- remaining synthesis warnings/errors
- 是否引入新的 functional(simulation) errors
- 定性评估修复质量
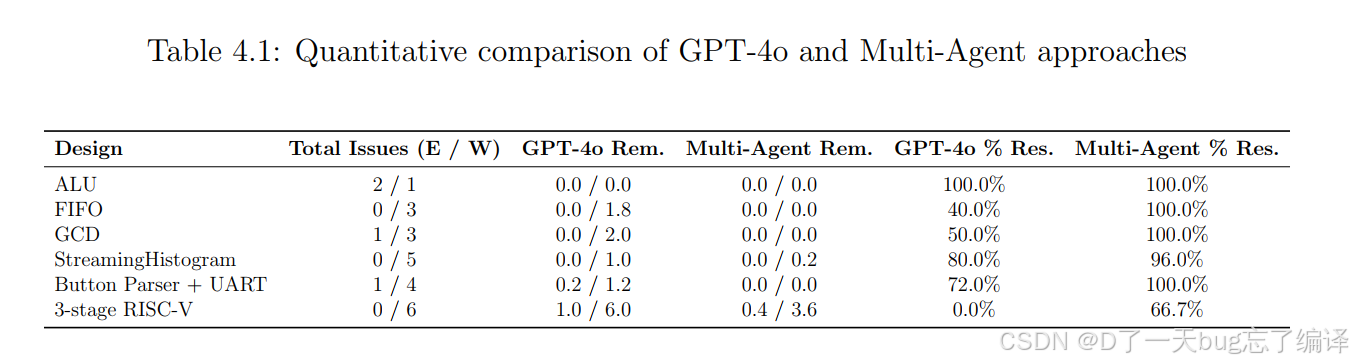
1. 总体结论
多智能体系统在所有设计上都优于单轮 GPT-4o,尤其在复杂设计上优势更明显。
2. 为什么 3-stage RISC-V 这么难
作者解释说这个处理器涉及:
- deeper feedback paths
- multiple interdependent modules
所以问题没有被完全修完,也暴露出未来还有改进空间。
3. 作者自己提炼的 takeaway
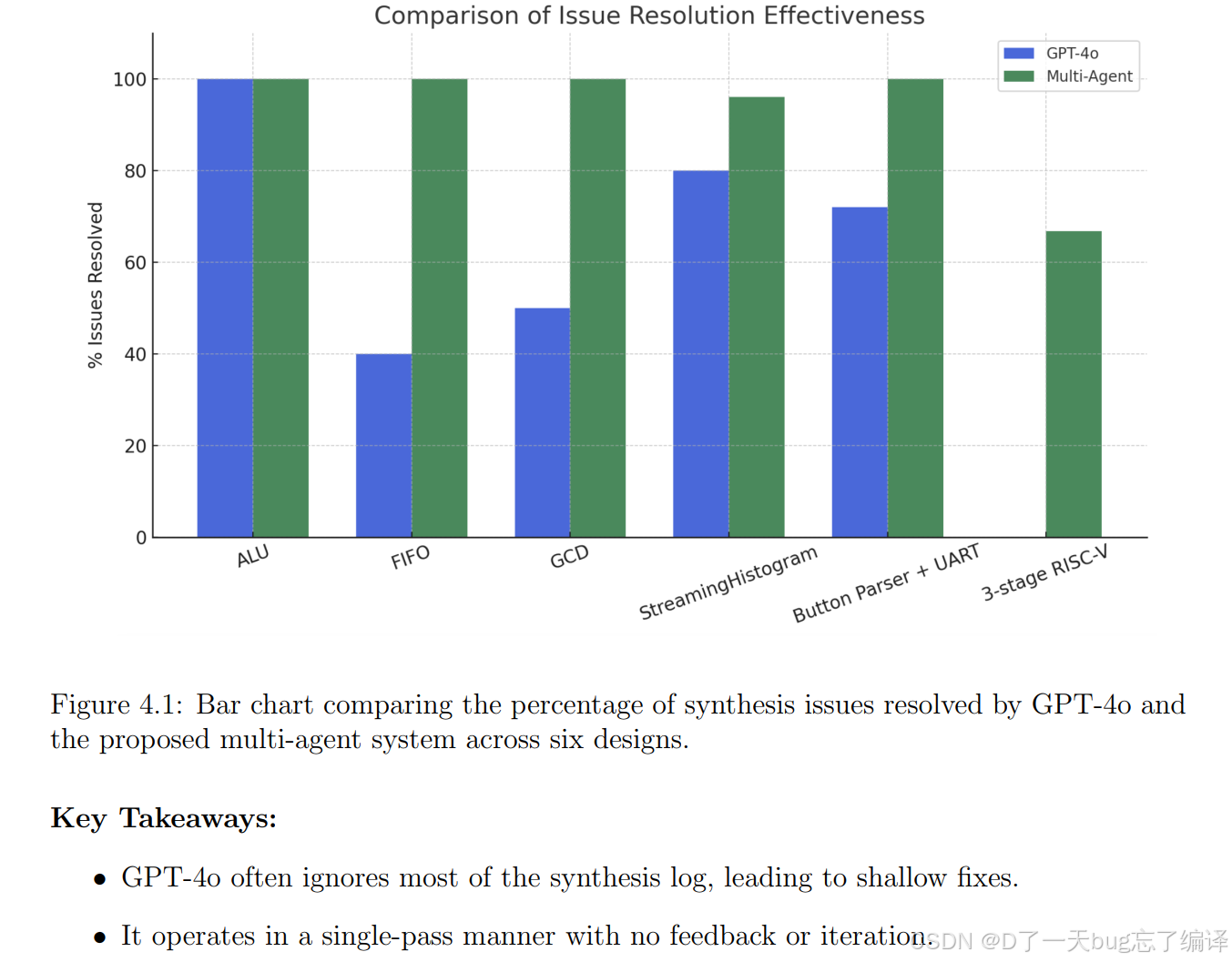
图 4.1 后面作者总结得很直接:
- GPT-4o 经常忽略大部分 synthesis log,所以修得很浅
- 它是 single-pass,没有 feedback 或 iteration
- multi-agent 系统使用 modular reasoning 和 real synthesis feedback
- iterative refinement 带来了更深、更安全、更完整的调试
4.3 AutoTA
这一节不是主系统性能提升,而是一个很有意思的“教育落地版”。
1. AutoTA 的定位
AutoTA 是一个面向 RTL 教学的轻量系统,目的是帮助学生:
- 理解 log messages
- 理解设计问题
- 获得 actionable suggestions
- 但不直接改他们的代码
这和 Multi-Agent 的区别
- Multi-Agent:强调自动修复与迭代闭环
- AutoTA:强调 explanatory feedback,帮助学生理解问题
2. AutoTA 是怎么做的
它复用了 Chapter 3 的 log extractor,然后用 GPT-4o-mini 生成结构化分析,包括:
- issue summary
- relevant code regions
- suggested fixes
- reasoning
而且输出特别强调清晰度,甚至支持 Markdown 渲染。
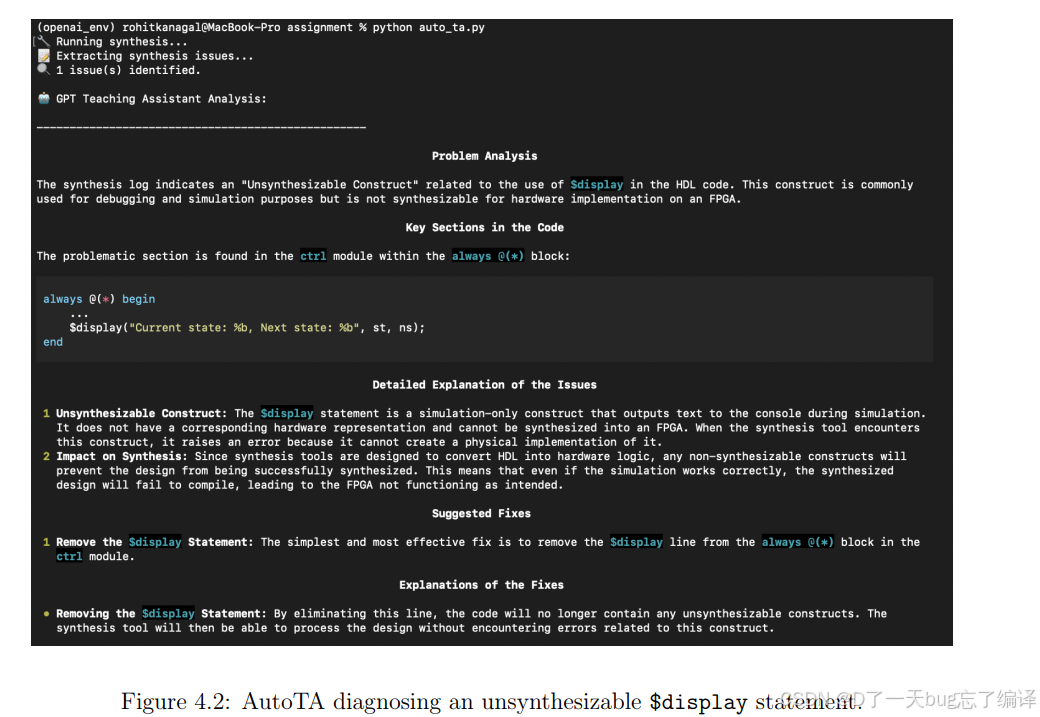
图 4.2 展示了 AutoTA 识别 unsynthesizable $display 语句的能力。
它能指出:
- 问题是什么
- 哪一行有问题
- 为什么这在仿真里可用,但不能综合到硬件里
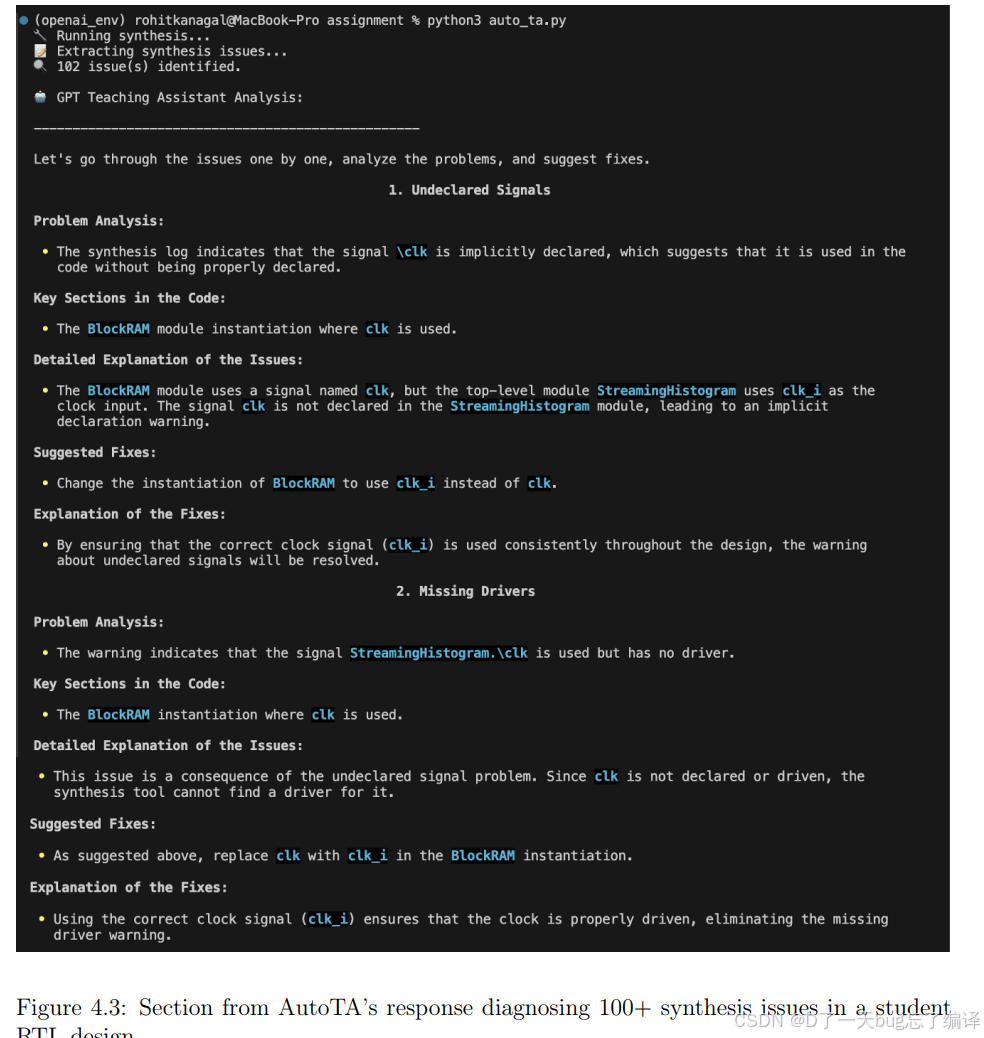
更有意思的是,作者说 AutoTA 能分析复杂学生设计中的 100+ synthesis issues,并集中归纳成 5 类核心问题。
具体包括:
(1)Undeclared Signal
BlockRAM 期待 clk,但顶层设计用的是 clk_i。
AutoTA 不只是指出 undeclared signal,还解释这是实例化接口名不一致导致的。
(2)Missing Drivers
由于 clk 没声明,进一步导致 clk 没有驱动。
AutoTA 能指出这其实是上一个问题的连锁结果。
(3)Latch Inference
raddr[7:0] 在 always @(*) 中条件赋值不完整,推断出 latch。
建议给默认赋值。
(4)Conflicting Drivers
两个 always block 同时驱动 sum_delay 和 query_count。
AutoTA 甚至建议把它们合并到一个 clocked process。
(5)Combinational Loop
sum 被用于 partial_sums[i] 的赋值,又回流形成环。
AutoTA 能解释回路形成机理,而不只是说“有 warning”。
这点非常重要
AutoTA 不只是列 100 条 warning,而是把它们压缩成少数几类根本性问题。
这对学生特别有价值,因为学生最怕“信息过载”。
5. 作者对 AutoTA 的评价
AutoTA 重在 understanding,而不是 automation。
它的价值是把 cryptic synthesis warnings 翻译成 meaningful feedback,促进学生反思。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 28
28 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)