NLP自然语言处理-文本表示篇
一、概述
文本表示是将自然语言转化为计算机能够理解的数值形式,是绝大多数自然语言处理(NLP)任务的基础步骤。
早期的文本表示方法(如词袋模型)通常将整段文本编码为一个向量。这类方法实现简单、计算高效,但存在明显的局限性表达语序和上下文语义的能力较弱。因此,现代NLP技术逐渐引入更加精细和表达力更强的文本表示方法,以更有效地建模语言的结构和含义。
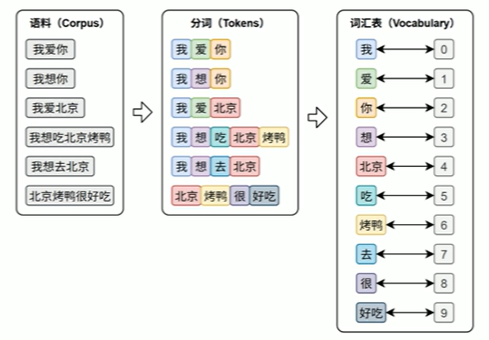
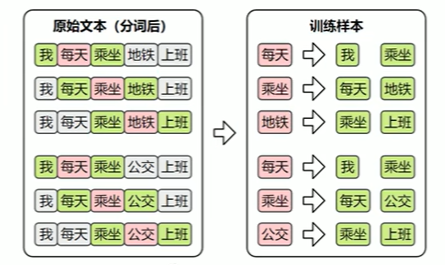
文本表示的第一步通常是分词和词表构建,如下图所示:
第一步:
分词(Tokenization)是将原始文本切分为若干具有独立语义的最小单元(即token)的过程,是所有NLP任务的起点。
tips:最小单元即可以是字,也可以是词
构建词表。
词汇表:在后续训练或预测过程中,模型会首先对输入文本进行分词,再通过词表将每个token映射为其对应的ID。接着,这些ID 会被输入嵌入层(EmbeddingLayer),转换为低维稠密的向量表示(即词向量)。
第二步:
每个词都有一个独立的词向量。
第三步:
把一系列的词向量给到序列模型。
分词的意义:
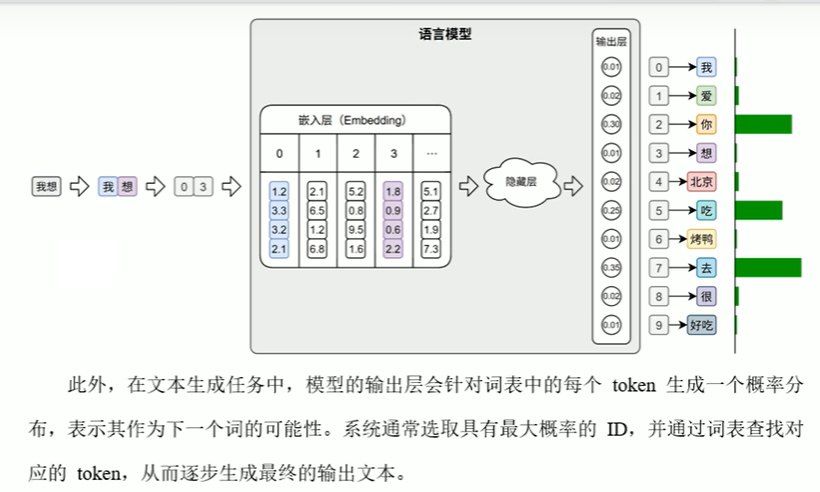
模型输入:输入层将词转换为词id,再可以在Embedding层中找到对应的词向量。
模型输出:输出层对预测目标值的预测为概率,对应每个词id,输出为概率最大的词。如图下所示:
二、分词:
不同语言由于语言结构、词边界的差异,其分词策略和算法也不尽相同,本节将分别介绍英文与中文中常见的分词方式。
1.英文分词
按照分词粒度的大小,可分为词级(Word-Level)分词、字符级(Character-Level)分词和子词级(Subword-Level)分词。下面逐一介绍
1.1词级分词
词级分词是指将文本按词语进行切分,是最传统、最直观的分词方式。在英文中,空格和标点往往是天然的分隔符。
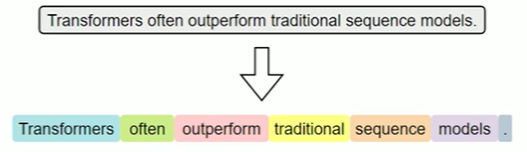
词级分词虽便于理解和实现,但在实际应用中容易出现0OV(Out-Of-Vocabulary,未登录词)问题。所谓OOV,是指在模型使用阶段,输入文本中出现了不在预先构建词表中的词语,常见的包括网络热词、专有名词、复合词及拼写变体等。由于模型无法识别这些词,通常会将其统一替换为特殊标记(如<UNK>),从而导致语义信息的丢失,影响模型的理解与预测能力。
1.2字符级分词
字符级分词(Character-level Tokenization)是以单个字符为最小单位进行分词的方法,文本中的每一个字母、数字、标点甚至空格,都会被视作一个独立的token。
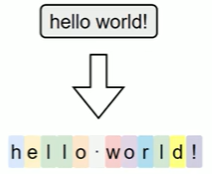
在这种分词方式下,词表仅由所有可能出现的字符组成,因此词表规模非常小,覆盖率极高,几乎不存在 OOV(Out-of-Vocabulary)问题。无论输入中出现什么样的新词或拼写变体,只要字符在词表中,都能被表示出来。 然而,由于单个字符本身语义信息极弱,模型必须依赖更长的上下文来推断词义和结构,这显著增加了建模难度和训练成本。此外,输入序列也会变得更长,影响模型效率。
1.3子词级分词
子词级分词是一种介于词级分词与字符级分词之间的分词方法,它将词语切分为更小的单元一一子词(subword),例如词根、前缀、后缀或常见词片段。与词级分词相比,子词分词可以显著缓解OOV问题;与字符级分词相比,它能更好地保留一定的语义结构。
子词分词的基本思想是:即使一个完整的词没有出现在词表中,只要它可以被拆分为词表中存在的子词单元,就可以被模型识别和表示,从而避免整体被替换为<UNK>。
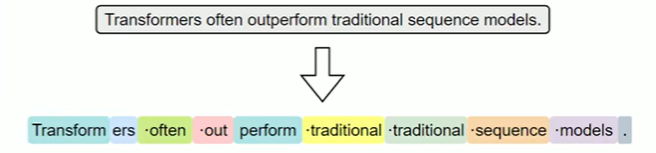
常见的子词分词算法包括 BPE (Byte Pair Encoding) 、WordPiece 和 Unigram Language Model。
其中,BPE是最早被广泛应用的子词分词方法。其基本思想是,在训练阶段,首先将语料中的词汇拆分为单个字符,构建初始词表;然后迭代地统计语料中出现频率最高的相邻字符对,将其合并为新的子词单元,并加入词表。这个过程持续进行,直到词表大小达到预设上限。 在分词阶段,BPE会根据构建好的词表和合并规则对新输入的文本进行处理。具体做法是:将文本拆分为最小单位(如字符或字节),然后按顺序应用训练中学习到的合并规则,逐步合并,直到无法继续。最终得到的就是由子词组成的分词结果。 详细的实现过程可参考Hugging Face提供的一篇优秀教程。
子词级分词己经成为现代英文NLP模型中的主流方法,如BERT、GPT等模型均采用了基于子词的分词机制。
tips:预训练模型都会提供对应配套的分词器,了解分词原理即可。
字节对编码(BPE)最初被开发为压缩文本的算法,然后在预训练GPT模型时被OpenAI用于tokenization。许多Transformer模型都使用它,包括GPT、GPT-2、RoBERTa、BART和DeBERTa。
tokenization 完成训练之后就可以对新的输入tokenization了,从某种意义上说,新的输入会依照以下步骤对新输入进行tokenization:
-
标准化:处理特殊符号和异常值等
-
预分词:对文本先按照特别简单的规则先拆成一个个单词
-
将单词拆分为单个字符:再将每一个单词拆成一个个字词分词
-
根据学习的合并规则,按顺序合并拆分的字符。
2.中文分词
尽管中文的语言结构与英文存在显著差异,我们仍可以借助“分词粒度”的视角,对中文的分词方式进行归类和分析。
2.1字符级分词
字符级分词是中文处理中最简单的一种方式,即将文本按照单个汉字进行切分,文本中的每一个汉字都被视为一个独立的token。
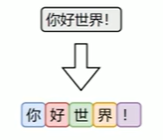
由于汉字本身通常具有独立语义,因此字符级分词在中文中具备天然的可行性。相比英文中的字符分词,中文的字符分词更加“语义友好”。
2.2词级分词
词级分词是将中文文本按照完整词语进行切分的传统方法,切分结果更贴近人类阅读习惯。
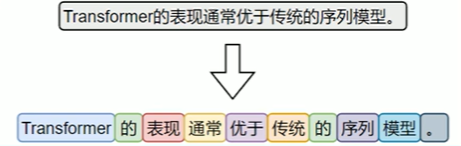
由于中文没有空格等天然词边界,词级分词通常依赖词典、规则或模型来识别词语边界。
2.3子词分词
虽然中文没有英文中的子词结构(如前缀、后缀、词根等入,但子词分词算法(如BPE)仍可直接应用于中文。它们以汉字为基本单位,通过学习语料中高频的字组合(如“自然”、“语言”、“处理”),自动构建子词词表。这种方式无需人工词典,具有较强的适应能力。
在当前主流的中文大模型(如通义千问、DeepSeek)中,子词分词己成为广泛采用的文本切分策略。
三、分词工具
3.1概述
目前市面上可用于中文分词的工具种类繁多,按照实现方式大致可以分为如下两类:
一类是基于词典或模型的传统方法,主要以“词”为单位进行切分; 另一类是基于子词建模算法(如BPE)的方式,从数据中自动学习高频字组合,构建子词词表。
前者的代表工具包括jieba、HanLP等,这些工具广泛应用于传统 NLP 任务中。 后者的代表工具包括 HuggingFace Tokenizer、SentencePiece、tiktoken 等,常用于大规模预训练语言模型中。
3.2jieba分词器
3.2.1概述
jieba是中文分词领域中应用广泛的开源工具之一,具有接口简洁、模式灵活、词典可扩展等特点,在各类传统NLP任务中依然具备良好的实用价值。
tips:详细文档介绍和案例说明,可前往 github:https://github.com/fxsjy/jieba
3.2.2安装
pip install jieba3.2.3分词模式
jieba分词器提供了多种分词模式,以适应不同的应用场景。
(1)精确模式(默认)[NLP] 试图将句子最精确地切开,适合文本分析。分词效果如下:

精确模式分词可使用jieba.cut 或者jieba.lcut 方法,前者返回一个生成器对象,后者返同一个list。 具体代码知下:
import jieba
text = '小明毕业于北京大学计算机系'
# 返回一个生成器
words_generator = jieba.cut(text)
for word in words_generator:
print(word)
# 返回一个列表
words_list = jieba.lcut(text)
print(word_list)tips : 生成器 : 一个特殊的迭代器
(2)全模式
把句子中所有的可以成词的词语都扫描出来,分词效果如下:

全模式分词可使用 jieba.cut 或者jieba.lcut,并将 cut_all参数设置为 True,具体代码如下:
import jieba
text = '小明毕业于北京大学计算机系'
# 返回一个生成器
words_generator = jieba.cut(text, cut_all=True)
for word in words_generator:
print(word)
# 返回一个列表
words_list = jieba.lcut(text, cut_all=True)
print(word_list)(3)搜索引擎模式
在精确模式基础上,对长词进一步切分,适合用于搜索引擎分词,分词效果如下:

可使用 jieba.cut_for_search 或者 jieba.lcut_for_search, 具体代码如下:
import jieba
text = '小明毕业于北京大学计算机系'
# 返回一个生成器
words_generator = jieba.cut_for_search(text)
for word in words_generator:
print(word)
# 返回一个列表
words_list = jieba.lcut_for_search(text)
print(word_list)(4)自定义词典
jieba支持用户自定义词典,以便包含jieba词库里没有的词,用于增强特定领域词汇的识别能力。 自定义词典的格式为 : 一个词占一行,每一行分三部分 : 词语、词频(可省略),词频决定某个词在分词时的优先级。词频越高被优先切分出来的概率越大)、词性标签(可省略,不影响分词结果),用空格隔开,顺序不可颠倒。例如:

可使用jieba.load_userdict(file_name)加载词典文件,也可以用jieba.add_word(word,freq=None,tag=None)与jieba.del_word(word)动态修改词典。
import jieba
jieba.load_userdict('dict.txt')
words_list = jieba.lcut('随着云计算技术的普及,越来越多企业开始采用云原生架构来部署服务,并借助大模型能力提升智能化水平,实现业务流程的自动化与智能决策。')
print(words_list)词性标签:
jieba 分词的词性标注基于 ICTCLAS 标准,共支持约 100 种词性标签。以下是完整、权威的词性表(含常用与完整)。
一、常用核心词性(日常 90% 场景)
| 标签 | 含义 | 示例 |
|---|---|---|
| n | 名词 | 苹果,电脑 |
| v | 动词 | 吃,运行 |
| a | 形容词 | 美丽,快 |
| d | 副词 | 非常,正在 |
| m | 数词 | 一,第二 |
| q | 量词 | 个,次 |
| r | 代词 | 我,这 |
| c | 连词 | 和,因为 |
| p | 介词 | 在,关于 |
| u | 助词 | 的,了,吗 |
| t | 时间词 | 今天,早晨 |
| f | 方位词 | 上,左边 |
| s | 处所词 | 地下,门口 |
| y | 语气词 | 啊,呢 |
| e | 叹词 | 哎呀,喂 |
| o | 拟声词 | 叮咚,哗啦 |
| x | 未知 / 其他 | 符号,乱码 |
二、专有名词(命名实体)
| 标签 | 含义 |
|---|---|
| nr | 人名 |
| ns | 地名 |
| nt | 机构团体 |
| nz | 其他专名 |
三、完整词性标注表(含子类与语素)
-
名词类 (n)
-
n:名词
-
nr:人名
-
ns:地名
-
nt:机构团体
-
nz:其他专名
-
nl:名词性惯用语
-
ng:名词性语素
-
动词类 (v)
-
v:动词
-
vd:副动词
-
vn:名动词
-
vshi:动词 “是”
-
vyou:动词 “有”
-
vg:动词性语素
-
形容词类 (a)
-
a:形容词
-
ad:副形词
-
an:名形词
-
ag:形容词性语素
-
区别词 (b)
-
b:区别词(如:男、女、大型、慢性)
-
状态词 (z)
-
z:状态词(如:绿油油、黑不溜秋)
-
代词 (r)
-
r:代词
-
rr:人称代词
-
rz:指示代词
-
ry:疑问代词
-
副词 (d)
-
d:副词
-
dg:副语素
-
介词 (p)
-
p:介词
-
连词 (c)
-
c:连词
-
cc:并列连词
-
助词 (u)
-
u:助词
-
ule:了,喽
-
uguo:过
-
ude1:的,底
-
ude2:地
-
ude3:得
-
usuo:所
-
udeng:等,等等
-
uyy:一样,一般,似的
-
udh:的话
-
uls:来讲,来说,说来
-
uzhi:之
-
ulian:连
-
叹词 (e)
-
e:叹词
-
拟声词 (o)
-
o:拟声词
-
语气词 (y)
-
y:语气词
-
数词 (m)
-
m:数词
-
mq:数量词
-
量词 (q)
-
q:量词
-
时间词 (t)
-
t:时间词
-
tg:时间词性语素
-
方位词 (f)
-
f:方位词
-
处所词 (s)
-
s:处所词
-
语素 (g)
-
g:语素
-
字头 / 字尾 (h, k)
-
h:前缀(前接成分)
-
k:后缀(后接成分)
-
成语 / 习语 / 简称 (i, l, j)
-
i:成语
-
l:习用语
-
j:简称略语
-
字符串 / 字母 (x, w)
-
x:非语素字 / 未知
-
w:标点符号
四、词表示
4.1概述
在分词完成之后,文本被转换为一系列的token(词、子词或字符)。然而,这些符号本身对计算机而言是不可计算的。因此,为了让模型能够理解和处理文本,必须将这些token转换为计算机可以识别和操作的数值形式,这一步就是所谓的词表示(wordrepresentation)。
词表示的发展经历了从稀疏的one-hot编码,到稠密的语义化词向量,再到近年来的上下文相关的词表示。不同的词表示方法在表达能力、语义建模、上下文适应性等方面存在显著差异。
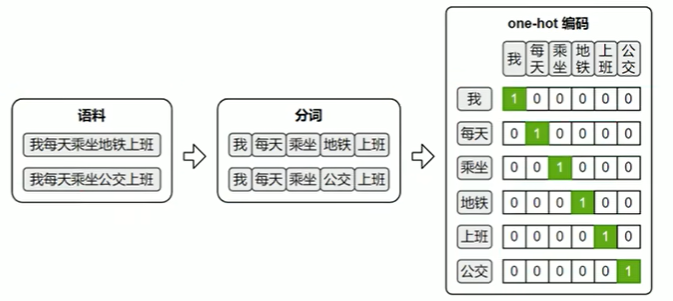
4.2One-hot编码
最早期的词向量表示方式是One-hot 编码:它将词汇表中的每个词映射为一个稀疏向量,向量的长度等于整个词表的大小。该词在对应的位置为1,其他位置为0。
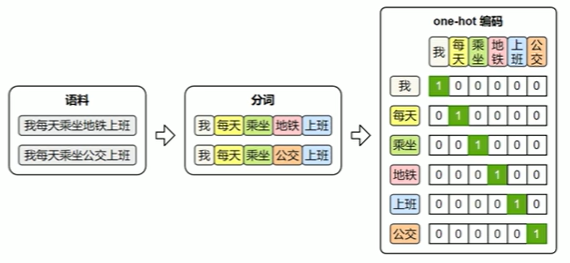
one-hot虽然实现简单、直观易懂,但它无法体现词与词之间的语义关系,且随着词表规模的扩大,向量维度会迅速膨胀,导致计算效率低下。因此,在实际自然语言处理任务中,one-hot 表示已经很少被直接使用。
4.3语义化词向量
传统的one-hot表示虽然结构简单,但它无法反映词语之间的语义关系,也无法衡量词与词之间的相似度。为了解决这个问题,研究者提出了Word2Vec模型,它通过对大规模语料的学习,为每个词生成一个具有语义意义的稠密向量表示。这些向量能够在连续空间中表达词与词之间的关系,使得“意思相近”的词在空间中距离更近。
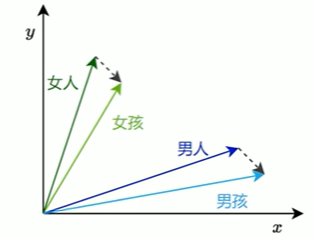
4.3.1Word2Vec概述
Word2Vec的设计理念源自“分布假设”——即一个词的含义由它周围的词决定。
基于这一假设,Word2Vec构建了一个简洁的神经网络模型,通过学习词与上下文之间的关系,自动为每个词生成一个能够反映语义特征的向量表示。
Word2Vec提供了两种典型的模型结构,用于实现对词向量的学习:
CBOW (Continuous Bag-of-Words)模型
输入是一个词的上下文(即前后若干个词),模型的目标是预测中间的目标词。

Skip-gram模型 输入是一个中心词,模型的目标是预测其上下文中的所有词(即前后若干个词)。
只要按照上述目标训练模型,就能得到语义化的词向量。
4.3.2Word2Vec原理
1)数据集
Word2Vec不依赖人工标注,而是直接利用大规模原始文本(如书籍、新闻、网页等)作为数据源,从中自动构造训练样本。 由于两种模型的输入和输出都是词语,因此首先需要对原始文本进行分词,将连续文本转换为token序列。 此外,模型无法直接处理文本符号,训练时仍需将词语转换为one-hot 编码,以便作为模型的输入和输出进行计算。
2)Skip-gram模型
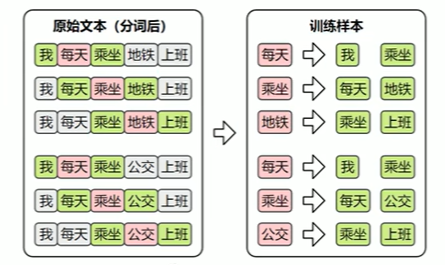
训练样本
Skip-Gram的目标是根据中间词预测上下文,所以其训练样本为:
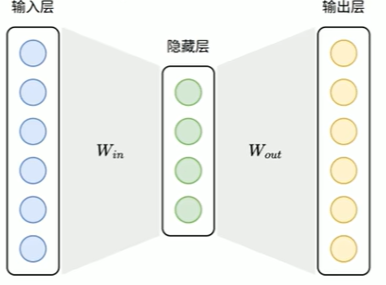
模型结构
Skip-Gram模型结构如下图所示:
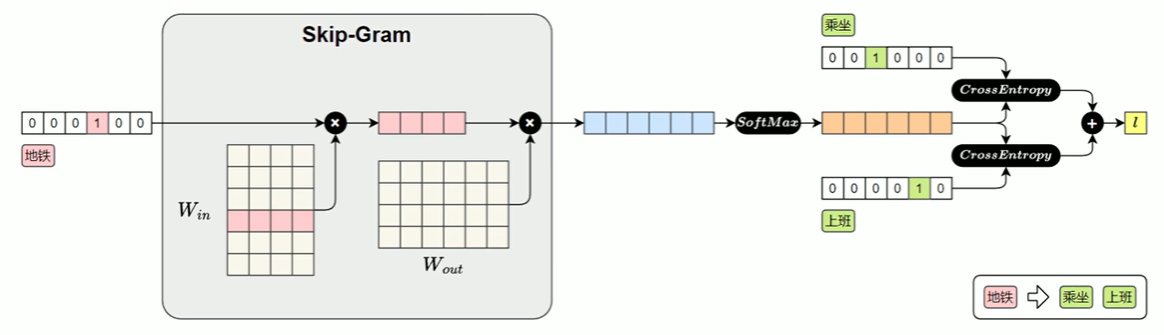
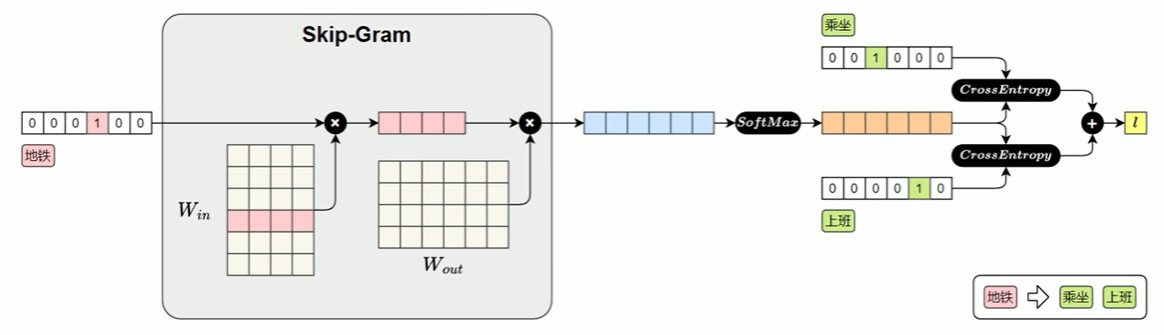
Skip-Gram模型损失值的计算图如下图所示:
总结:
输入中心词的独热编码 → 用 Win 生成中心词向量 → 用 Wout 生成全词得分 → SoftMax 转概率 → 用交叉熵计算和真实上下文词的误差 → 反向传播更新权重 → 最终得到词向量。
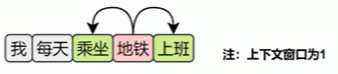
tips:真实训练就是不断重复下面这件事:
从语料里随机抓一个中心词(比如 “地铁”)
把它左右各抓 1~n 个词当上下文(比如 “乘坐”“上班”)
走一遍图里的流程:
输入 → 查词向量 → 预测上下文 → 算损失 →微调词向量
换下一个词,无限循环
词向量 = 词的 “语义坐标”,每个词一开始都是随机乱数,没有任何意义。
训练过程就是:让 “经常一起出现的词”,在向量空间里靠得更近。
2)Skip-gram模型
CBOW的目标是根据上下文预测中间词,所以其训练样本为:
训练样本
模型结构
CBOW模型结构如下图所示:
CBOW模型损失值的计算图如下图所示:
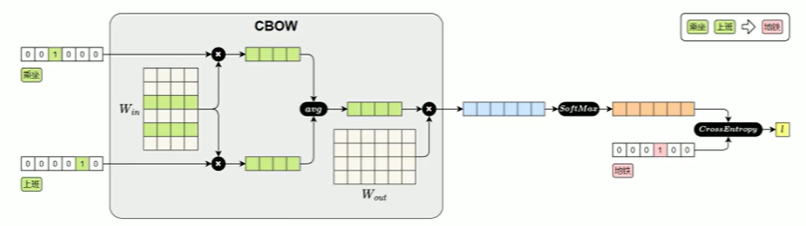
获取Word2Vec词向量
词向量的获取通常有两种方式:一种是直接使用他人公开发布的词向量,另一种是在特定语料上自行训练。 在实际工作中,无论是加载已有模型还是从零训练,都可借助Gensim来完成,它提供了便捷的接口来加载Word2Vec格式的词向量,也支持基于自有语料训练属于自己的词向量模型。 可执行以下命令安装Gensim
pip install gensim1)使用公开词向量 公开的中文词向量,可从 https://github.com/Egabedding/Chinese-Word-Vectors 下载,其提供了基于多个数据集训练得到的词向量。 词向量文件的格式为:第一行记录基本信息,包括两个整数,分别表示总词数和词向量维度。从第二行起,每一行表示一个词及其对应的词向量,格式为:词+向量的各个维度值。所有内容通过空格分隔,该格式已成为自然语言处理领域中广泛接受的约定俗成的通用格式。具体格式如下

可使用KeyedVectors.load_word2vec_fromat()加载上述词向量文件,具体代码如下。

上述代码使用的sgns.weibo.word.bz2词向量文件包含195202个词,每个词向量300维。该文件可从该网址下载。 词向量加载完后,便可使用如下API查询词向量
查看词向量维度
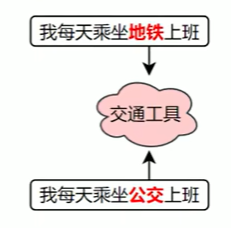
print(model.vector_size)查看某个词的向量
similarity = model.similarity('地铁','公交')
print('地铁 vs 公交 相似度: ',similarity)查看两个向量的相似度
similarity = model.similarity('地铁','公交')
print('地铁 vs 公交 相似度: ',similarity)model.similarity计算的是两个词向量的余弦相似度,计算公式如下
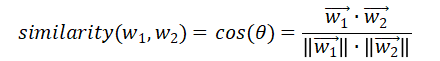
返回值介于[-1,1]。接近1表示高度相似,语义接近接近;接近0表示无明显相关;接近-1方向完全相反,极度不相似。
找出与某个词最相似的词
similar_words = model.most_similar(positive=["上班"], topn=5)
print(similar_words)
result = model.most_similar(positive=["爸爸", "女性"], negative=["男性"], topn=3)
print(result)
# '爸爸' - '男性' + '女性'1)自行训练词向量
(1)准备语料
Word2Vec的训练语料需要是已分词的文本序列,格式为:
sentences = [['我', '每天','乘坐', '地铁', '上班'], ['我','每天', '乘坐', '公交', '上班']](2)训练模型
gensim提供了十分方便的训练词向量的API——Word2Vec。
from gensim.models import Word2Vec
model = Word2Vec(
sentences, # 已分词的句子序列
vector_size=100, # 词向量维度
window=5, # 上下文窗口大小
min_count=2, # 最小词频(低于将被忽略)
sg=1, # 1:Skip-Gram,0:CBOW
workers=4 # 并行训练线程数
)(3)保存词向量
model.wv.save_word2vec_format('my_vectors.kv')(4)加载词向量
from gensim.models import KeyedVectors
my_model = KeyedVectors.load_word2vec_format('my_vectors.kv')完整案例如下:
数据集来源为ChineseNLPCorpus,格式CSV,具体结构如下
| cat | label | review |
|---|---|---|
| 书籍 | 1 | 感谢于歌先生为大家带来这么精彩的一本好书! |
| 书籍 | 0 | 这本书纸质不怎样,内容也不怎样。 |
| 水果 | 1 | 苹果酸甜可口,大小适中,好吃。 |
| 水果 | 0 | 不是很大,比较甜,不会回购,感觉加运费后不划算。 |
完成代码如下:
import jieba
from gensim.models import Word2Vec, KeyedVectors
import pandas as pd
df = pd.read_csv('online_shopping_10_cats.csv', encoding='utf-8', usecols=['review'])
sentences = [[token for token in jieba.lcut(review) if token.strip() != ''] for review in df["review"]]
model = Word2Vec(
sentences, # 已分词的句子序列
vector_size=100, # 词向量维度
window=5, # 上下文窗口大小
min_count=2, # 最小词频(低于将被忽略)
sg=1, # 1 = Skip-Gram,0 = CBOW
workers=4 # 并行训练线程数
)
model.wv.save_word2vec_format('my_vectors.kv')
my_model = KeyedVectors.load_word2vec_format('my_vectors.kv')
print(my_model)-
3.2应用Word2Vec词向量
训练好的词向量,通常用于初始化下游NLP任务的嵌入层。
在现代深度学习的 NLP 模型中,大多数任务的输入第一层都是嵌入层。本质上,嵌入层就是一个查找表(lookup table):输入是词在词汇表中的索引;输出是该词对应的向量表示。
嵌入层的参数矩阵可以有两种典型的初始化方式:
Ø 随机初始化**
模型训练开始时,嵌入向量是随机生成的,模型会通过反向传播逐步学习每个词的表示。
Ø 使用预训练词向量初始化**
加载训练好的词向量(如 Word2Vec)到嵌入层中作为初始参数,这样可以为模型注入丰富的语言知识,尤其在低资源任务中优势明显。并且,加载预训练词向量后,可选择是否让嵌入层继续参与训练。
下面以PyTorch为例,演示如何使用预训练词向量初始化Embedding层
核心API为nn.Embedding.from_pretrained
embedding_layer = nn.Embedding.from_pretrained(
embedding_matrix, # 词向量矩阵,形状为(num_embeddigns,embedding_dim)
# num_embeddigns = 分词数量
# embedding_dim = 词向量的维度
freeze=False # 是否冻结词向量
)以下是完整案例
import torch
import torch.nn as nn
from gensim.models import KeyedVectors
# 1. 加载预训练的 Word2Vec 模型
word_vectors = KeyedVectors.load_word2vec_format("my_vectors.kv")
# 2. 构建词表和词向量矩阵
word2index = word_vectors.key_to_index # 词到索引的映射
embedding_dim = word_vectors.vector_size # 词语向量维度
num_embeddings = len(word2index) # 词表大小
embedding_matrix = torch.zeros(num_embeddings, embedding_dim) # 构造词向量矩阵,形状为(词表大小,词向量维度大小)
for word, idx in word2index.items():
• embedding_matrix[idx] = torch.tensor(word_vectors[word])
# 3. 构建 PyTorch 的嵌入层
embedding_layer = nn.Embedding.from_pretrained(
• embedding_matrix, # 词向量矩阵,形状为(num_embeddigns,embedding_dim)
• freeze=False # 是否冻结词向量
)
# 4. 示例:将词索引转换为向量
input_words = ["我", "喜欢", "乘坐", "地铁"] # 分词后的句子
input_indices = [word2index[word] for word in input_words] # token转为索引
input_tensor = torch.tensor([input_indices]) # 构造嵌入层输入张量
# 5. 查询嵌入(即词向量查找)
output = embedding_layer(input_tensor) # 通过嵌入层查找预训练词向量
print(output.shape) # 例如 torch.Size([1, 4, 100])上下文相关词表示
虽然像Word2Vec这样的模型已经能够为词语提供具有语义的向量表示,但是它只为每个词分配一个固定的向量表示,不论它在句中出现的语境如何。这种表示被称为静态词向量(static embeddings)。
然而,语言的表达极其灵活,一个词在不同上下文中可能有完全不同的含义。例如:

这时,使用同一个静态词向量去表示“苹果”,显然无法区分这两种语义。这就推动了上下文相关的词表示的发展。
上下文相关词表示(Contextual Word Representations),是指词语的向量表示会根据它所在的句子上下文动态变化,从而更好地捕捉其语义。一个具有代表性的模型是——ELMo。
该模型全称为 Embeddings from Language Models,发表于2018年2月。其基于LSTM 语言模型,使用上下文动态生成每个词的表示,每个词的向量由其前文和后文共同决定,是第一个被广泛应用于下游任务的上下文词向量模型。

Pycharm 自动生成推导式快捷函数
| 缩写 | 功能描述 | 生成的代码示例 |
|---|---|---|
itere |
生成带索引的 For 循环 (即你提到的 enumerate) |
for index, item in enumerate(iterable): |
compl |
生成列表推导式 (通常生成 x 或 item 的推导式) |
[item for item in iterable] |
main |
生成程序入口脚本 | if __name__ == '__main__': |
iter |
生成普通 For 循环 | for item in iterable: |
dictc |
生成字典推导式 | {key: value for key, value in dictionary.items()} |
setc |
生成集合推导式 | {item for item in iterable} |
try / tryf |
生成 Try-Except 异常处理块 | try: ... except Exception as e: |
class |
快速定义类 | class ClassName: |
def |
快速定义函数 | def function_name(): |
print |
快速生成打印语句 | print() |
psf |
生成 Python 文件头 (通常包含编码声明) | #!/usr/bin/env python ... |

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)