[MICCAI 2025]Ophora: A Large-Scale Data-Driven Text-Guided Ophthalmic Surgical Video Generation Mode

论文代码:https://github.com/mar-cry/Ophora
目录
2.3.1. Comprehensive Data Curation
2.3.3. Progressive Video-Instruction Tuning
1. 心得
(1)合理利用大模型作为工具
2. 论文逐段精读
2.1. Abstract
①通过文本指导视频生成(text-guided video generation,T2V)可以解决眼科手术视频少的问题
2.2. Introduction
①现有T2V很难捕捉组织器械的精细互动
②作者设计了一个数据清洗管道,构建了数据集Ophora-160K,其中有超过16万个视频片段
2.3. Method
①整体框架:
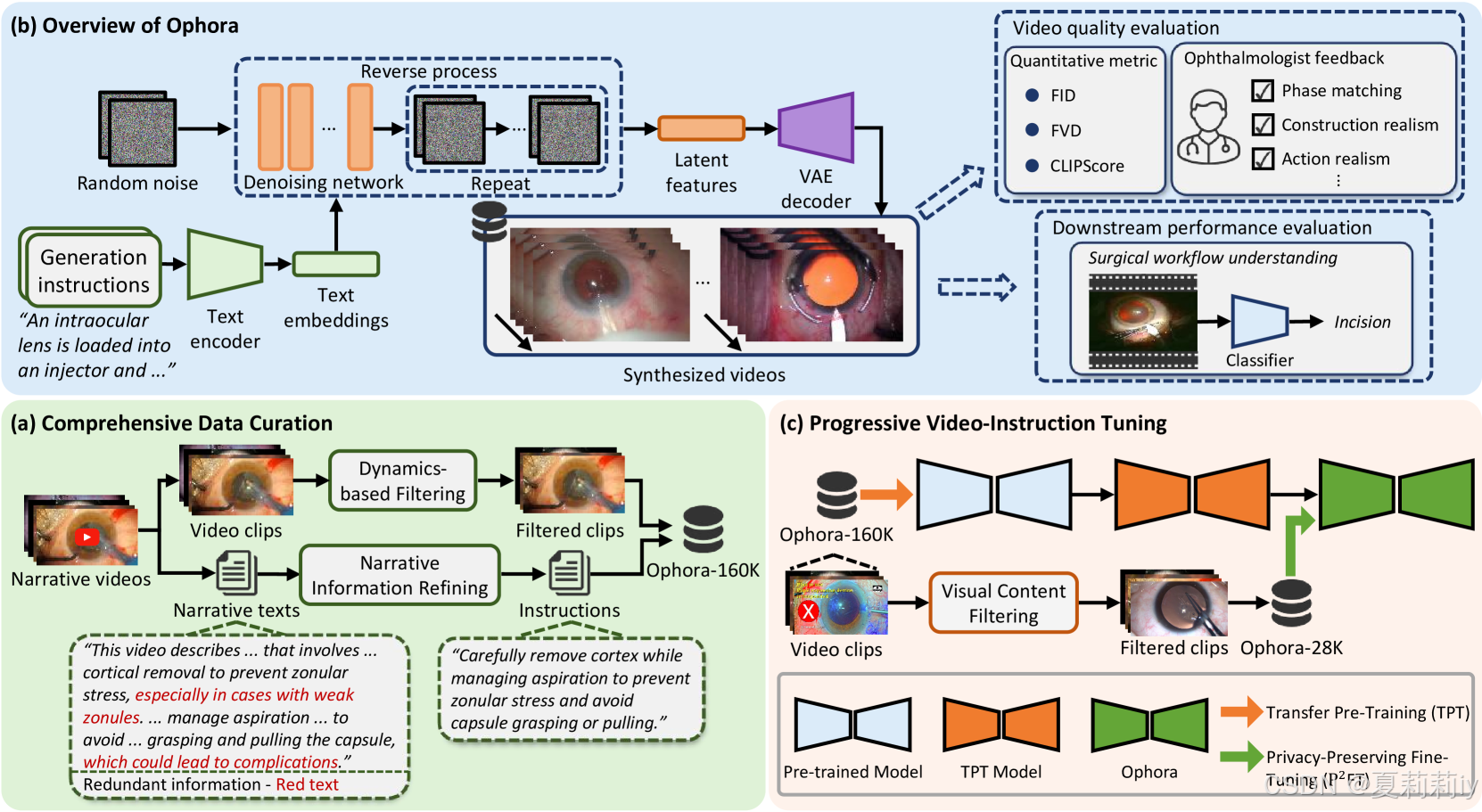
2.3.1. Comprehensive Data Curation
①作者认为OphClip这样的数据集收集到的教学语音是多余的
②并且现在很多数据集有镜头抖动或静止内容
③使用开源的LLM Qwen2.5-72B来去除无关信息并将这些信息转换为生成指令。作者手动选择十个标题并注释掉冗余信息,用这些去指导剩余的生成
④使用PySceneDetect工具来过滤,将视频变化次数小于2(静止)或大于100(剧烈抖动)的删掉(说实话我觉得这需要附带一点实验,我们都不知道PySceneDetect对于一个正常眼科手术视频会检测到多少次视频变化,这个变化非常的模糊,并不是一个精准的定义)
⑤从OphClip里删去分辨率低于720×480的片段,构建了一个大规模视频教学数据集Ophora-160K,包含约160K个剪辑级视频指令对
2.3.2. Overview of Ophora
①Ophra的主干:CogVideoX-2b(一个接受文本的扩散模型,包含3D VAE,T5文本编码器喝Transformer去噪网络)
②对于视频输入,其中
分别是帧数,高,宽,通道个数。VAE将他们压缩成
,其中
和
是缩放倍率。然后给它加个高斯噪声
:
③文本输入被T5编码器变成
④扩散优化:
其中表示训练集,
表示串联
⑤然后视觉嵌入被VAE重建
2.3.3. Progressive Video-Instruction Tuning
①使用整个Ophora-160K对主干网络进行预训练,同时保持 T5 和 VAE 冻结
②把个时间步均匀分给N个GPU,这样不会重复选择扩散学习
③以每帧1 FPS的速率在每个视频的第一帧和最后一帧之间采样,并将其输入到LVLM Qwen2.5-VL-72B中,以检测敏感信息的存在
2.4. Experiments
①数据集:Ophora-160K 包含 162,185 对视频教学对,均从 9,819 段眼科手术叙事视频中提取。所有片段的平均时长为5.54秒。 在数据预处理中,每个剪辑的大小调整为720×480并均匀采样为49帧。帧数少于49帧的片段会被填充为全零帧,直到达到49帧。 数据集分别分为80%和20%用于训练和测试。还有Ophora-28K,其中包含训练集中的28,175对剪辑指令。
②对于迁移预训练,使用AdamW优化器,学习率为1×10−4,批次大小为128,迭代次为65000,以实现足够的知识转移。 为了保护隐私,使用带有5×10−5学习率的同一优化器批量大小为128,以及4500次迭代以避免知识覆盖。所有实验均在A100 GPUs上进行。
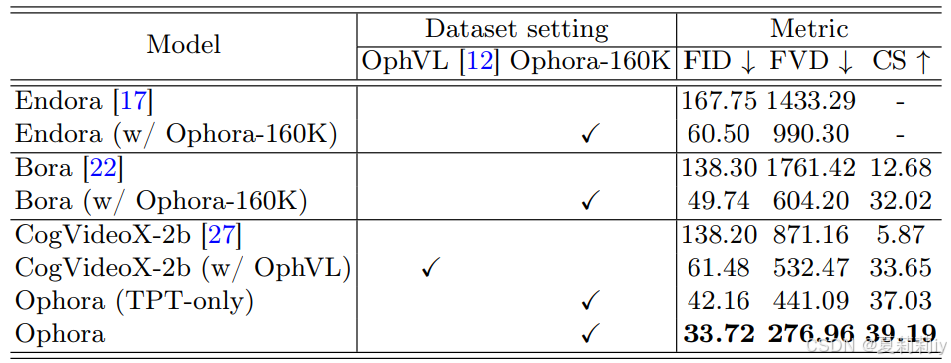
③对比实验和消融实验:
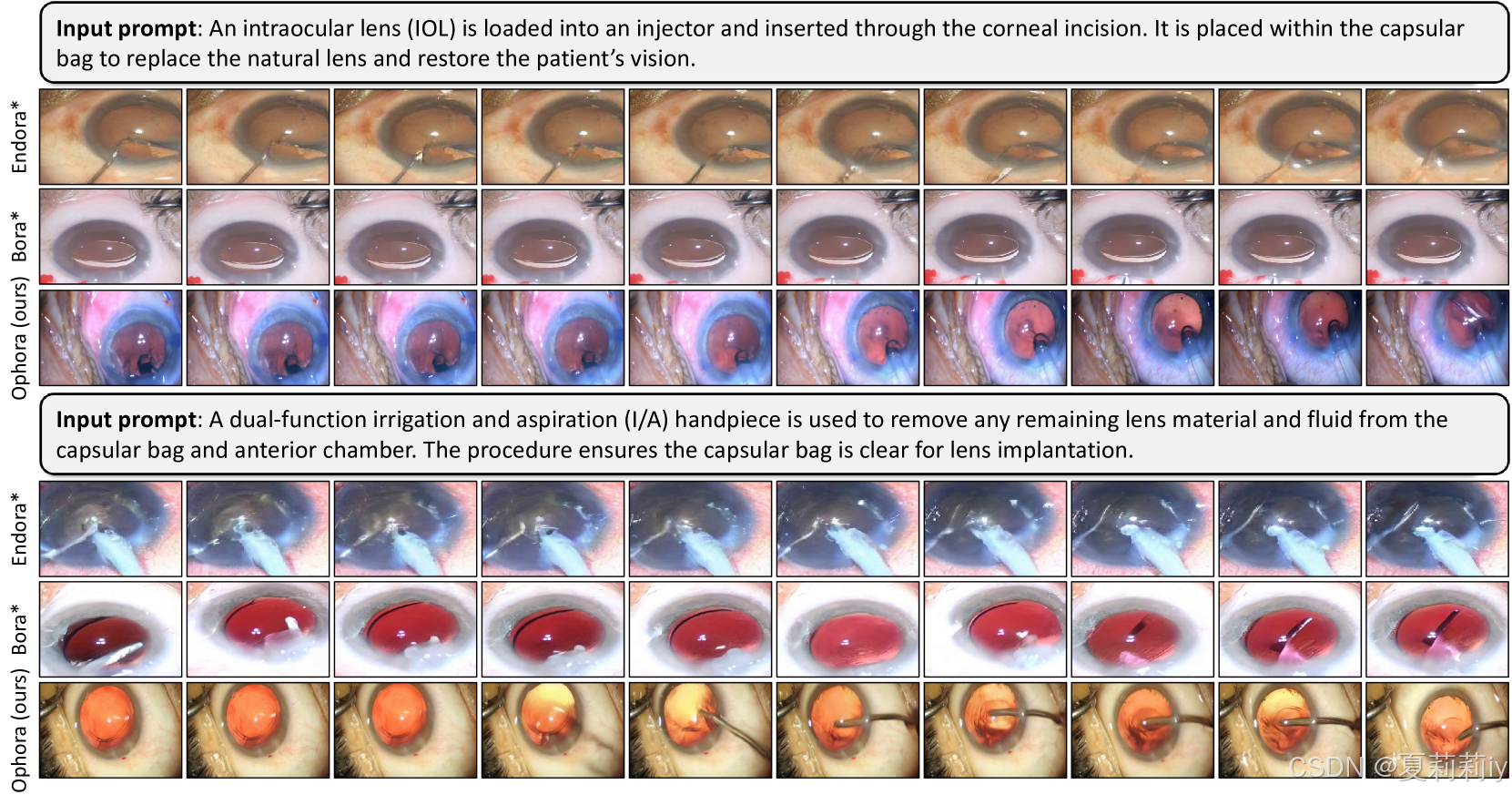
④可视化:
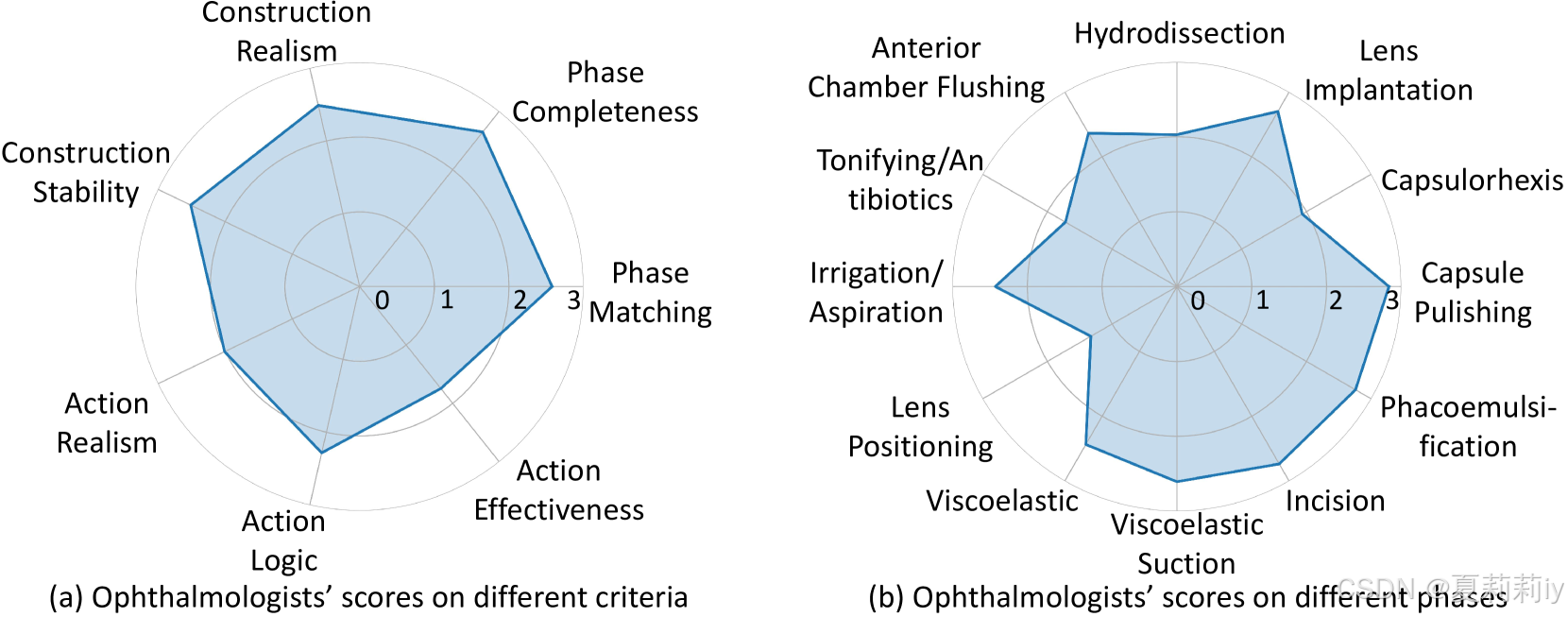
⑤根据医生编写的指令生成600个视频,然后医生评估:
⑥为OphNet每个类别生成100个视频之后,和Ophnet训练集一起训练带来的效果:
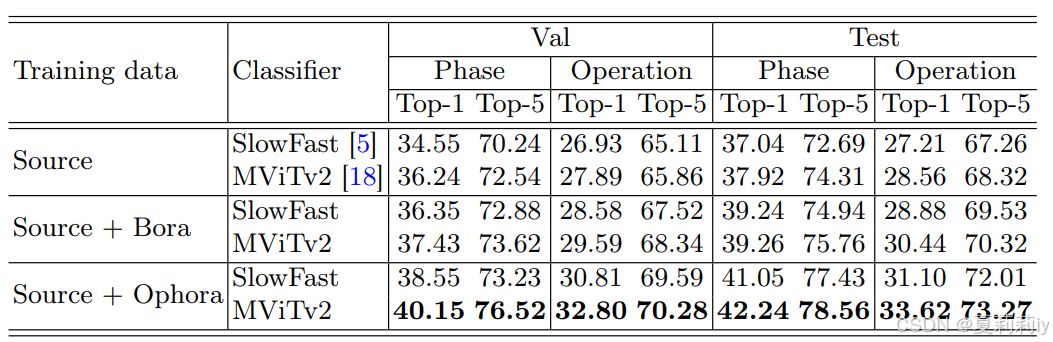
2.5. Conclusion
~

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)